We found that 33.6% of the data are duplicate. Some data sources could include valid duplicates and in other cases these duplicates could point to problems in data collection. Duplicate samples resulting from faulty data collection, could derail machine learning processes that rely on splitting to independent training and validation folds. For example quick model scores, prediction power estimation and automatic hyper parameter tuning. Duplicate samples could be removed from the dataset using the Drop duplicates transform under Manage rows.
",
+ "severity": "high_sev"
+ },
+ {
+ "title": "Target leakage",
+ "warningText": "The feature reservation_status predicts the target extremely well on it's own. A feature this predictive often indicates an error called target leakage. The cause is typically data that is not available at time of prediction. For example, a duplicate of the target column in the dataset can result in target leakage.
Alternatively, if the machine learning task is \"easy\", then a single feature can have legitimately high prediction power. If you think that a single feature is very highly predictive, you don't need to do anything further. However, if you think there's target leakage, we recommended that you remove the highly predictive column from the dataset using the Drop column transform under Manage columns.
",
+ "severity": "high_sev"
+ }
+ ],
+ "col_stats": {
+ "hotel": {
+ "labels": [
+ "City Hotel",
+ "Resort Hotel"
+ ],
+ "label_counts": [
+ 79330,
+ 40060
+ ],
+ "cardinality": 2,
+ "max": null,
+ "min": null,
+ "median": null,
+ "mean": null,
+ "numeric_finite_count": 0,
+ "integer_count": 0,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "is_canceled": {
+ "labels": [
+ "0",
+ "1"
+ ],
+ "label_counts": [
+ 75166,
+ 44224
+ ],
+ "cardinality": 2,
+ "max": 1,
+ "min": 0,
+ "median": 0,
+ "mean": 0.37041628277075134,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "lead_time": {
+ "labels": [
+ "0",
+ "1",
+ "2",
+ "3",
+ "4",
+ "5",
+ "6",
+ "7",
+ "8",
+ "12",
+ "11",
+ "9",
+ "10",
+ "14",
+ "16",
+ "17",
+ "15",
+ "19",
+ "34",
+ "18",
+ "13",
+ "28",
+ "20",
+ "40",
+ "29",
+ "22",
+ "32",
+ "31",
+ "21",
+ "56",
+ "37",
+ "39",
+ "26",
+ "24",
+ "36",
+ "30",
+ "35",
+ "25",
+ "27",
+ "23",
+ "33",
+ "44",
+ "41",
+ "38",
+ "55",
+ "47",
+ "68",
+ "69",
+ "45",
+ "72",
+ "53",
+ "50",
+ "59",
+ "74",
+ "61",
+ "48",
+ "46",
+ "43",
+ "49",
+ "54",
+ "66",
+ "42",
+ "86",
+ "102",
+ "57",
+ "87",
+ "65",
+ "88",
+ "92",
+ "80",
+ "67",
+ "60",
+ "52",
+ "99",
+ "75",
+ "64",
+ "71",
+ "112",
+ "98",
+ "115",
+ "62",
+ "104",
+ "105",
+ "73",
+ "58",
+ "63",
+ "116",
+ "82",
+ "95",
+ "70",
+ "78",
+ "134",
+ "83",
+ "103",
+ "113",
+ "96",
+ "51",
+ "151",
+ "81",
+ "164"
+ ],
+ "label_counts": [
+ 6345,
+ 3460,
+ 2069,
+ 1816,
+ 1715,
+ 1565,
+ 1445,
+ 1331,
+ 1138,
+ 1079,
+ 1055,
+ 992,
+ 976,
+ 965,
+ 942,
+ 881,
+ 839,
+ 839,
+ 828,
+ 826,
+ 821,
+ 820,
+ 750,
+ 722,
+ 712,
+ 707,
+ 690,
+ 685,
+ 678,
+ 676,
+ 673,
+ 673,
+ 671,
+ 665,
+ 663,
+ 659,
+ 655,
+ 653,
+ 649,
+ 643,
+ 643,
+ 633,
+ 607,
+ 575,
+ 575,
+ 568,
+ 564,
+ 558,
+ 537,
+ 531,
+ 530,
+ 527,
+ 520,
+ 519,
+ 513,
+ 506,
+ 495,
+ 479,
+ 479,
+ 472,
+ 466,
+ 464,
+ 461,
+ 458,
+ 457,
+ 450,
+ 448,
+ 448,
+ 441,
+ 440,
+ 439,
+ 436,
+ 435,
+ 430,
+ 425,
+ 423,
+ 423,
+ 423,
+ 420,
+ 420,
+ 414,
+ 413,
+ 412,
+ 402,
+ 401,
+ 398,
+ 395,
+ 393,
+ 392,
+ 384,
+ 384,
+ 384,
+ 378,
+ 377,
+ 373,
+ 368,
+ 366,
+ 365,
+ 360,
+ 358
+ ],
+ "cardinality": 479,
+ "max": 737,
+ "min": 0,
+ "median": 69,
+ "mean": 104.01141636652986,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "arrival_date_year": {
+ "labels": [
+ "2016",
+ "2017",
+ "2015"
+ ],
+ "label_counts": [
+ 56707,
+ 40687,
+ 21996
+ ],
+ "cardinality": 3,
+ "max": 2017,
+ "min": 2015,
+ "median": 2016,
+ "mean": 2016.156554150264,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 10000,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "arrival_date_month": {
+ "labels": [
+ "August",
+ "July",
+ "May",
+ "October",
+ "April",
+ "June",
+ "September",
+ "March",
+ "February",
+ "November",
+ "December",
+ "January"
+ ],
+ "label_counts": [
+ 13877,
+ 12661,
+ 11791,
+ 11160,
+ 11089,
+ 10939,
+ 10508,
+ 9794,
+ 8068,
+ 6794,
+ 6780,
+ 5929
+ ],
+ "cardinality": 12,
+ "max": null,
+ "min": null,
+ "median": null,
+ "mean": null,
+ "numeric_finite_count": 0,
+ "integer_count": 0,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "arrival_date_week_number": {
+ "labels": [
+ "33",
+ "30",
+ "32",
+ "34",
+ "18",
+ "21",
+ "28",
+ "17",
+ "20",
+ "29",
+ "42",
+ "31",
+ "41",
+ "15",
+ "27",
+ "25",
+ "38",
+ "23",
+ "35",
+ "39",
+ "22",
+ "24",
+ "13",
+ "16",
+ "19",
+ "40",
+ "26",
+ "43",
+ "44",
+ "14",
+ "37",
+ "8",
+ "36",
+ "10",
+ "9",
+ "7",
+ "12",
+ "11",
+ "45",
+ "53",
+ "49",
+ "47",
+ "46",
+ "6",
+ "50",
+ "48",
+ "4",
+ "5",
+ "3",
+ "2",
+ "52",
+ "1",
+ "51"
+ ],
+ "label_counts": [
+ 3580,
+ 3087,
+ 3045,
+ 3040,
+ 2926,
+ 2854,
+ 2853,
+ 2805,
+ 2785,
+ 2763,
+ 2756,
+ 2741,
+ 2699,
+ 2689,
+ 2664,
+ 2663,
+ 2661,
+ 2621,
+ 2593,
+ 2581,
+ 2546,
+ 2498,
+ 2416,
+ 2405,
+ 2402,
+ 2397,
+ 2391,
+ 2352,
+ 2272,
+ 2264,
+ 2229,
+ 2216,
+ 2167,
+ 2149,
+ 2117,
+ 2109,
+ 2083,
+ 2070,
+ 1941,
+ 1816,
+ 1782,
+ 1685,
+ 1574,
+ 1508,
+ 1505,
+ 1504,
+ 1487,
+ 1387,
+ 1319,
+ 1218,
+ 1195,
+ 1047,
+ 933
+ ],
+ "cardinality": 53,
+ "max": 53,
+ "min": 1,
+ "median": 28,
+ "mean": 27.16517296255968,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "arrival_date_day_of_month": {
+ "labels": [
+ "17",
+ "5",
+ "15",
+ "25",
+ "26",
+ "9",
+ "12",
+ "16",
+ "2",
+ "19",
+ "20",
+ "18",
+ "24",
+ "28",
+ "8",
+ "3",
+ "30",
+ "6",
+ "14",
+ "27",
+ "21",
+ "4",
+ "13",
+ "7",
+ "1",
+ "23",
+ "11",
+ "22",
+ "29",
+ "10",
+ "31"
+ ],
+ "label_counts": [
+ 4406,
+ 4317,
+ 4196,
+ 4160,
+ 4147,
+ 4096,
+ 4087,
+ 4078,
+ 4055,
+ 4052,
+ 4032,
+ 4002,
+ 3993,
+ 3946,
+ 3921,
+ 3855,
+ 3853,
+ 3833,
+ 3819,
+ 3802,
+ 3767,
+ 3763,
+ 3745,
+ 3665,
+ 3626,
+ 3616,
+ 3599,
+ 3596,
+ 3580,
+ 3575,
+ 2208
+ ],
+ "cardinality": 31,
+ "max": 31,
+ "min": 1,
+ "median": 16,
+ "mean": 15.798241058715135,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "stays_in_weekend_nights": {
+ "labels": [
+ "0",
+ "2",
+ "1",
+ "4",
+ "3",
+ "6",
+ "5",
+ "8",
+ "7",
+ "9",
+ "10",
+ "12",
+ "13",
+ "16",
+ "14",
+ "18",
+ "19"
+ ],
+ "label_counts": [
+ 51998,
+ 33308,
+ 30626,
+ 1855,
+ 1259,
+ 153,
+ 79,
+ 60,
+ 19,
+ 11,
+ 7,
+ 5,
+ 3,
+ 3,
+ 2,
+ 1,
+ 1
+ ],
+ "cardinality": 17,
+ "max": 19,
+ "min": 0,
+ "median": 1,
+ "mean": 0.9275986263506156,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "stays_in_week_nights": {
+ "labels": [
+ "2",
+ "1",
+ "3",
+ "5",
+ "4",
+ "0",
+ "6",
+ "10",
+ "7",
+ "8",
+ "9",
+ "15",
+ "11",
+ "19",
+ "12",
+ "20",
+ "14",
+ "13",
+ "16",
+ "21",
+ "22",
+ "18",
+ "25",
+ "30",
+ "17",
+ "24",
+ "40",
+ "26",
+ "32",
+ "33",
+ "34",
+ "35",
+ "41",
+ "42",
+ "50"
+ ],
+ "label_counts": [
+ 33684,
+ 30310,
+ 22258,
+ 11077,
+ 9563,
+ 7645,
+ 1499,
+ 1036,
+ 1029,
+ 656,
+ 231,
+ 85,
+ 56,
+ 44,
+ 42,
+ 41,
+ 35,
+ 27,
+ 16,
+ 15,
+ 7,
+ 6,
+ 6,
+ 5,
+ 4,
+ 3,
+ 2,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1
+ ],
+ "cardinality": 35,
+ "max": 50,
+ "min": 0,
+ "median": 2,
+ "mean": 2.500301532791691,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "adults": {
+ "labels": [
+ "2",
+ "1",
+ "3",
+ "0",
+ "4",
+ "26",
+ "5",
+ "20",
+ "27",
+ "6",
+ "10",
+ "40",
+ "50",
+ "55"
+ ],
+ "label_counts": [
+ 89680,
+ 23027,
+ 6202,
+ 403,
+ 62,
+ 5,
+ 2,
+ 2,
+ 2,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1
+ ],
+ "cardinality": 14,
+ "max": 55,
+ "min": 0,
+ "median": 2,
+ "mean": 1.8564033838679956,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "children": {
+ "labels": [
+ "0.0",
+ "1.0",
+ "2.0",
+ "3.0",
+ "10.0"
+ ],
+ "label_counts": [
+ 110796,
+ 4861,
+ 3652,
+ 76,
+ 1
+ ],
+ "cardinality": 5,
+ "max": 10,
+ "min": 0,
+ "median": 0,
+ "mean": 0.10388990333874994,
+ "numeric_finite_count": 119386,
+ "integer_count": 119386,
+ "null_like_count": 4,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "babies": {
+ "labels": [
+ "0",
+ "1",
+ "2",
+ "9",
+ "10"
+ ],
+ "label_counts": [
+ 118473,
+ 900,
+ 15,
+ 1,
+ 1
+ ],
+ "cardinality": 5,
+ "max": 10,
+ "min": 0,
+ "median": 0,
+ "mean": 0.007948739425412514,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "meal": {
+ "labels": [
+ "BB",
+ "HB",
+ "SC",
+ "Undefined",
+ "FB"
+ ],
+ "label_counts": [
+ 92310,
+ 14463,
+ 10650,
+ 1169,
+ 798
+ ],
+ "cardinality": 5,
+ "max": null,
+ "min": null,
+ "median": null,
+ "mean": null,
+ "numeric_finite_count": 0,
+ "integer_count": 0,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "country": {
+ "labels": [
+ "PRT",
+ "GBR",
+ "FRA",
+ "ESP",
+ "DEU",
+ "ITA",
+ "IRL",
+ "BEL",
+ "BRA",
+ "NLD",
+ "USA",
+ "CHE",
+ "CN",
+ "AUT",
+ "SWE",
+ "CHN",
+ "POL",
+ "ISR",
+ "RUS",
+ "NOR",
+ "ROU",
+ "NULL",
+ "FIN",
+ "DNK",
+ "AUS",
+ "AGO",
+ "LUX",
+ "MAR",
+ "TUR",
+ "HUN",
+ "ARG",
+ "JPN",
+ "CZE",
+ "IND",
+ "KOR",
+ "GRC",
+ "DZA",
+ "SRB",
+ "HRV",
+ "MEX",
+ "EST",
+ "IRN",
+ "LTU",
+ "ZAF",
+ "BGR",
+ "NZL",
+ "COL",
+ "UKR",
+ "MOZ",
+ "CHL",
+ "SVK",
+ "THA",
+ "ISL",
+ "SVN",
+ "LVA",
+ "ARE",
+ "CYP",
+ "TWN",
+ "SAU",
+ "PHL",
+ "SGP",
+ "TUN",
+ "IDN",
+ "NGA",
+ "EGY",
+ "URY",
+ "LBN",
+ "HKG",
+ "PER",
+ "MYS",
+ "ECU",
+ "BLR",
+ "VEN",
+ "CPV",
+ "GEO",
+ "JOR",
+ "CRI",
+ "KAZ",
+ "GIB",
+ "MLT",
+ "OMN",
+ "AZE",
+ "KWT",
+ "MAC",
+ "QAT",
+ "DOM",
+ "IRQ",
+ "PAK",
+ "BIH",
+ "ALB",
+ "BGD",
+ "MDV",
+ "PRI",
+ "SEN",
+ "BOL",
+ "CMR",
+ "MKD",
+ "GNB",
+ "PAN",
+ "TJK"
+ ],
+ "label_counts": [
+ 48590,
+ 12129,
+ 10415,
+ 8568,
+ 7287,
+ 3766,
+ 3375,
+ 2342,
+ 2224,
+ 2104,
+ 2097,
+ 1730,
+ 1279,
+ 1263,
+ 1024,
+ 999,
+ 919,
+ 669,
+ 632,
+ 607,
+ 500,
+ 488,
+ 447,
+ 435,
+ 426,
+ 362,
+ 287,
+ 259,
+ 248,
+ 230,
+ 214,
+ 197,
+ 171,
+ 152,
+ 133,
+ 128,
+ 103,
+ 101,
+ 100,
+ 85,
+ 83,
+ 83,
+ 81,
+ 80,
+ 75,
+ 74,
+ 71,
+ 68,
+ 67,
+ 65,
+ 65,
+ 59,
+ 57,
+ 57,
+ 55,
+ 51,
+ 51,
+ 51,
+ 48,
+ 40,
+ 39,
+ 39,
+ 35,
+ 34,
+ 32,
+ 32,
+ 31,
+ 29,
+ 29,
+ 28,
+ 27,
+ 26,
+ 26,
+ 24,
+ 22,
+ 21,
+ 19,
+ 19,
+ 18,
+ 18,
+ 18,
+ 17,
+ 16,
+ 16,
+ 15,
+ 14,
+ 14,
+ 14,
+ 13,
+ 12,
+ 12,
+ 12,
+ 12,
+ 11,
+ 10,
+ 10,
+ 10,
+ 9,
+ 9,
+ 9
+ ],
+ "cardinality": 178,
+ "max": null,
+ "min": null,
+ "median": null,
+ "mean": null,
+ "numeric_finite_count": 0,
+ "integer_count": 0,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "market_segment": {
+ "labels": [
+ "Online TA",
+ "Offline TA/TO",
+ "Groups",
+ "Direct",
+ "Corporate",
+ "Complementary",
+ "Aviation",
+ "Undefined"
+ ],
+ "label_counts": [
+ 56477,
+ 24219,
+ 19811,
+ 12606,
+ 5295,
+ 743,
+ 237,
+ 2
+ ],
+ "cardinality": 8,
+ "max": null,
+ "min": null,
+ "median": null,
+ "mean": null,
+ "numeric_finite_count": 0,
+ "integer_count": 0,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "distribution_channel": {
+ "labels": [
+ "TA/TO",
+ "Direct",
+ "Corporate",
+ "GDS",
+ "Undefined"
+ ],
+ "label_counts": [
+ 97870,
+ 14645,
+ 6677,
+ 193,
+ 5
+ ],
+ "cardinality": 5,
+ "max": null,
+ "min": null,
+ "median": null,
+ "mean": null,
+ "numeric_finite_count": 0,
+ "integer_count": 0,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "is_repeated_guest": {
+ "labels": [
+ "0",
+ "1"
+ ],
+ "label_counts": [
+ 115580,
+ 3810
+ ],
+ "cardinality": 2,
+ "max": 1,
+ "min": 0,
+ "median": 0,
+ "mean": 0.03191222045397437,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "previous_cancellations": {
+ "labels": [
+ "0",
+ "1",
+ "2",
+ "3",
+ "24",
+ "11",
+ "4",
+ "26",
+ "25",
+ "6",
+ "5",
+ "19",
+ "14",
+ "13",
+ "21"
+ ],
+ "label_counts": [
+ 112906,
+ 6051,
+ 116,
+ 65,
+ 48,
+ 35,
+ 31,
+ 26,
+ 25,
+ 22,
+ 19,
+ 19,
+ 14,
+ 12,
+ 1
+ ],
+ "cardinality": 15,
+ "max": 26,
+ "min": 0,
+ "median": 0,
+ "mean": 0.08711784906608594,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "previous_bookings_not_canceled": {
+ "labels": [
+ "0",
+ "1",
+ "2",
+ "3",
+ "4",
+ "5",
+ "6",
+ "7",
+ "8",
+ "9",
+ "10",
+ "11",
+ "12",
+ "13",
+ "14",
+ "15",
+ "16",
+ "25",
+ "17",
+ "18",
+ "19",
+ "20",
+ "21",
+ "22",
+ "24",
+ "27",
+ "23",
+ "26",
+ "28",
+ "29",
+ "30",
+ "31",
+ "32",
+ "44",
+ "48",
+ "58",
+ "33",
+ "34",
+ "35",
+ "36",
+ "37",
+ "38",
+ "39",
+ "40",
+ "41",
+ "42",
+ "43",
+ "45",
+ "46",
+ "47",
+ "49",
+ "50",
+ "51",
+ "52",
+ "53",
+ "54",
+ "55",
+ "56",
+ "57",
+ "59",
+ "60",
+ "61",
+ "62",
+ "63",
+ "64",
+ "65",
+ "66",
+ "67",
+ "68",
+ "69",
+ "70",
+ "71",
+ "72"
+ ],
+ "label_counts": [
+ 115770,
+ 1542,
+ 580,
+ 333,
+ 229,
+ 181,
+ 115,
+ 88,
+ 70,
+ 60,
+ 53,
+ 43,
+ 37,
+ 30,
+ 28,
+ 21,
+ 20,
+ 17,
+ 16,
+ 14,
+ 13,
+ 12,
+ 12,
+ 10,
+ 9,
+ 9,
+ 7,
+ 7,
+ 7,
+ 6,
+ 4,
+ 2,
+ 2,
+ 2,
+ 2,
+ 2,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1
+ ],
+ "cardinality": 73,
+ "max": 72,
+ "min": 0,
+ "median": 0,
+ "mean": 0.13709690928888515,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "reserved_room_type": {
+ "labels": [
+ "A",
+ "D",
+ "E",
+ "F",
+ "G",
+ "B",
+ "C",
+ "H",
+ "P",
+ "L"
+ ],
+ "label_counts": [
+ 85994,
+ 19201,
+ 6535,
+ 2897,
+ 2094,
+ 1118,
+ 932,
+ 601,
+ 12,
+ 6
+ ],
+ "cardinality": 10,
+ "max": null,
+ "min": null,
+ "median": null,
+ "mean": null,
+ "numeric_finite_count": 0,
+ "integer_count": 0,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "assigned_room_type": {
+ "labels": [
+ "A",
+ "D",
+ "E",
+ "F",
+ "G",
+ "C",
+ "B",
+ "H",
+ "I",
+ "K",
+ "P",
+ "L"
+ ],
+ "label_counts": [
+ 74053,
+ 25322,
+ 7806,
+ 3751,
+ 2553,
+ 2375,
+ 2163,
+ 712,
+ 363,
+ 279,
+ 12,
+ 1
+ ],
+ "cardinality": 12,
+ "max": null,
+ "min": null,
+ "median": null,
+ "mean": null,
+ "numeric_finite_count": 0,
+ "integer_count": 0,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "booking_changes": {
+ "labels": [
+ "0",
+ "1",
+ "2",
+ "3",
+ "4",
+ "5",
+ "6",
+ "7",
+ "8",
+ "9",
+ "10",
+ "13",
+ "14",
+ "15",
+ "11",
+ "12",
+ "16",
+ "17",
+ "18",
+ "20",
+ "21"
+ ],
+ "label_counts": [
+ 101314,
+ 12701,
+ 3805,
+ 927,
+ 376,
+ 118,
+ 63,
+ 31,
+ 17,
+ 8,
+ 6,
+ 5,
+ 5,
+ 3,
+ 2,
+ 2,
+ 2,
+ 2,
+ 1,
+ 1,
+ 1
+ ],
+ "cardinality": 21,
+ "max": 21,
+ "min": 0,
+ "median": 0,
+ "mean": 0.22112404724013737,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "deposit_type": {
+ "labels": [
+ "No Deposit",
+ "Non Refund",
+ "Refundable"
+ ],
+ "label_counts": [
+ 104641,
+ 14587,
+ 162
+ ],
+ "cardinality": 3,
+ "max": null,
+ "min": null,
+ "median": null,
+ "mean": null,
+ "numeric_finite_count": 0,
+ "integer_count": 0,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "agent": {
+ "labels": [
+ "9.0",
+ "240.0",
+ "1.0",
+ "14.0",
+ "7.0",
+ "6.0",
+ "250.0",
+ "241.0",
+ "28.0",
+ "8.0",
+ "3.0",
+ "37.0",
+ "19.0",
+ "40.0",
+ "314.0",
+ "21.0",
+ "229.0",
+ "242.0",
+ "83.0",
+ "29.0",
+ "171.0",
+ "12.0",
+ "85.0",
+ "20.0",
+ "96.0",
+ "243.0",
+ "30.0",
+ "134.0",
+ "298.0",
+ "27.0",
+ "15.0",
+ "26.0",
+ "11.0",
+ "22.0",
+ "56.0",
+ "273.0",
+ "177.0",
+ "86.0",
+ "58.0",
+ "5.0",
+ "119.0",
+ "196.0",
+ "34.0",
+ "44.0",
+ "138.0",
+ "315.0",
+ "38.0",
+ "10.0",
+ "236.0",
+ "16.0",
+ "17.0",
+ "115.0",
+ "251.0",
+ "42.0",
+ "68.0",
+ "191.0",
+ "175.0",
+ "154.0",
+ "195.0",
+ "156.0",
+ "168.0",
+ "152.0",
+ "208.0",
+ "143.0",
+ "326.0",
+ "2.0",
+ "31.0",
+ "147.0",
+ "132.0",
+ "52.0",
+ "142.0",
+ "95.0",
+ "410.0",
+ "248.0",
+ "234.0",
+ "39.0",
+ "67.0",
+ "330.0",
+ "98.0",
+ "146.0",
+ "94.0",
+ "35.0",
+ "220.0",
+ "36.0",
+ "89.0",
+ "464.0",
+ "155.0",
+ "170.0",
+ "69.0",
+ "159.0",
+ "253.0",
+ "13.0",
+ "281.0",
+ "185.0",
+ "82.0",
+ "87.0",
+ "339.0",
+ "41.0",
+ "71.0",
+ "75.0"
+ ],
+ "label_counts": [
+ 31961,
+ 13922,
+ 7191,
+ 3640,
+ 3539,
+ 3290,
+ 2870,
+ 1721,
+ 1666,
+ 1514,
+ 1336,
+ 1230,
+ 1061,
+ 1039,
+ 927,
+ 875,
+ 786,
+ 780,
+ 696,
+ 683,
+ 607,
+ 578,
+ 554,
+ 540,
+ 537,
+ 514,
+ 484,
+ 482,
+ 472,
+ 450,
+ 402,
+ 401,
+ 395,
+ 382,
+ 375,
+ 349,
+ 347,
+ 338,
+ 335,
+ 330,
+ 304,
+ 301,
+ 294,
+ 292,
+ 287,
+ 284,
+ 274,
+ 260,
+ 247,
+ 246,
+ 241,
+ 225,
+ 220,
+ 211,
+ 211,
+ 198,
+ 195,
+ 193,
+ 193,
+ 190,
+ 184,
+ 183,
+ 173,
+ 172,
+ 165,
+ 162,
+ 162,
+ 156,
+ 143,
+ 137,
+ 137,
+ 135,
+ 133,
+ 131,
+ 128,
+ 127,
+ 127,
+ 125,
+ 124,
+ 124,
+ 114,
+ 109,
+ 104,
+ 100,
+ 99,
+ 98,
+ 94,
+ 93,
+ 90,
+ 89,
+ 87,
+ 82,
+ 82,
+ 78,
+ 77,
+ 77,
+ 77,
+ 75,
+ 73,
+ 73
+ ],
+ "cardinality": 333,
+ "max": 535,
+ "min": 1,
+ "median": 14,
+ "mean": 86.69338185346919,
+ "numeric_finite_count": 103050,
+ "integer_count": 103050,
+ "null_like_count": 16340,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "company": {
+ "labels": [
+ "NULL",
+ "40",
+ "223",
+ "67",
+ "45",
+ "153",
+ "174",
+ "219",
+ "281",
+ "154",
+ "405",
+ "233",
+ "51",
+ "94",
+ "47",
+ "135",
+ "169",
+ "242",
+ "331",
+ "348",
+ "498",
+ "110",
+ "38",
+ "20",
+ "280",
+ "342",
+ "91",
+ "197",
+ "62",
+ "68",
+ "218",
+ "270",
+ "195",
+ "202",
+ "148",
+ "9",
+ "113",
+ "307",
+ "204",
+ "238",
+ "269",
+ "308",
+ "86",
+ "385",
+ "72",
+ "343",
+ "365",
+ "43",
+ "144",
+ "178",
+ "221",
+ "46",
+ "337",
+ "418",
+ "179",
+ "227",
+ "366",
+ "424",
+ "477",
+ "507",
+ "81",
+ "407",
+ "78",
+ "88",
+ "216",
+ "286",
+ "150",
+ "209",
+ "523",
+ "122",
+ "251",
+ "292",
+ "396",
+ "143",
+ "163",
+ "290",
+ "31",
+ "103",
+ "183",
+ "193",
+ "127",
+ "397",
+ "408",
+ "525",
+ "12",
+ "120",
+ "263",
+ "268",
+ "274",
+ "346",
+ "367",
+ "485",
+ "82",
+ "112",
+ "203",
+ "355",
+ "390",
+ "428",
+ "92",
+ "130"
+ ],
+ "label_counts": [
+ 112593,
+ 927,
+ 784,
+ 267,
+ 250,
+ 215,
+ 149,
+ 141,
+ 138,
+ 133,
+ 119,
+ 114,
+ 99,
+ 87,
+ 72,
+ 66,
+ 65,
+ 62,
+ 61,
+ 59,
+ 58,
+ 52,
+ 51,
+ 50,
+ 48,
+ 48,
+ 48,
+ 47,
+ 47,
+ 46,
+ 43,
+ 43,
+ 38,
+ 38,
+ 37,
+ 37,
+ 36,
+ 36,
+ 34,
+ 33,
+ 33,
+ 33,
+ 32,
+ 30,
+ 30,
+ 29,
+ 29,
+ 29,
+ 27,
+ 27,
+ 27,
+ 26,
+ 25,
+ 25,
+ 24,
+ 24,
+ 24,
+ 24,
+ 23,
+ 23,
+ 23,
+ 22,
+ 22,
+ 22,
+ 21,
+ 21,
+ 19,
+ 19,
+ 19,
+ 18,
+ 18,
+ 18,
+ 18,
+ 17,
+ 17,
+ 17,
+ 17,
+ 16,
+ 16,
+ 16,
+ 15,
+ 15,
+ 15,
+ 15,
+ 14,
+ 14,
+ 14,
+ 14,
+ 14,
+ 14,
+ 14,
+ 14,
+ 14,
+ 13,
+ 13,
+ 13,
+ 13,
+ 13,
+ 13,
+ 12
+ ],
+ "cardinality": 353,
+ "max": 543,
+ "min": 6,
+ "median": 179,
+ "mean": 189.26673532440782,
+ "numeric_finite_count": 6797,
+ "integer_count": 6797,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "days_in_waiting_list": {
+ "labels": [
+ "0",
+ "39",
+ "58",
+ "44",
+ "31",
+ "35",
+ "46",
+ "69",
+ "63",
+ "50",
+ "87",
+ "38",
+ "111",
+ "45",
+ "101",
+ "41",
+ "77",
+ "223",
+ "62",
+ "3",
+ "98",
+ "22",
+ "122",
+ "15",
+ "48",
+ "28",
+ "91",
+ "176",
+ "17",
+ "96",
+ "56",
+ "187",
+ "391",
+ "68",
+ "60",
+ "75",
+ "93",
+ "21",
+ "65",
+ "236",
+ "19",
+ "33",
+ "42",
+ "147",
+ "162",
+ "178",
+ "20",
+ "10",
+ "40",
+ "27",
+ "34",
+ "4",
+ "25",
+ "57",
+ "120",
+ "160",
+ "47",
+ "80",
+ "215",
+ "79",
+ "108",
+ "24",
+ "32",
+ "43",
+ "99",
+ "174",
+ "49",
+ "61",
+ "70",
+ "6",
+ "9",
+ "125",
+ "85",
+ "207",
+ "330",
+ "379",
+ "59",
+ "71",
+ "1",
+ "150",
+ "55",
+ "224",
+ "259",
+ "14",
+ "5",
+ "8",
+ "11",
+ "53",
+ "113",
+ "2",
+ "107",
+ "7",
+ "13",
+ "16",
+ "26",
+ "12",
+ "18",
+ "23",
+ "64",
+ "97"
+ ],
+ "label_counts": [
+ 115692,
+ 227,
+ 164,
+ 141,
+ 127,
+ 96,
+ 94,
+ 89,
+ 83,
+ 80,
+ 80,
+ 76,
+ 71,
+ 65,
+ 65,
+ 63,
+ 63,
+ 61,
+ 60,
+ 59,
+ 59,
+ 56,
+ 55,
+ 54,
+ 52,
+ 50,
+ 50,
+ 50,
+ 47,
+ 46,
+ 45,
+ 45,
+ 45,
+ 42,
+ 41,
+ 40,
+ 40,
+ 37,
+ 35,
+ 35,
+ 30,
+ 30,
+ 30,
+ 30,
+ 30,
+ 30,
+ 29,
+ 28,
+ 28,
+ 26,
+ 26,
+ 25,
+ 25,
+ 25,
+ 25,
+ 25,
+ 24,
+ 24,
+ 21,
+ 20,
+ 20,
+ 19,
+ 19,
+ 19,
+ 19,
+ 19,
+ 18,
+ 18,
+ 18,
+ 16,
+ 16,
+ 16,
+ 15,
+ 15,
+ 15,
+ 15,
+ 14,
+ 13,
+ 12,
+ 11,
+ 10,
+ 10,
+ 10,
+ 9,
+ 8,
+ 7,
+ 7,
+ 6,
+ 6,
+ 5,
+ 5,
+ 4,
+ 4,
+ 4,
+ 4,
+ 3,
+ 3,
+ 3,
+ 3,
+ 3
+ ],
+ "cardinality": 128,
+ "max": 391,
+ "min": 0,
+ "median": 0,
+ "mean": 2.321149174972778,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "customer_type": {
+ "labels": [
+ "Transient",
+ "Transient-Party",
+ "Contract",
+ "Group"
+ ],
+ "label_counts": [
+ 89613,
+ 25124,
+ 4076,
+ 577
+ ],
+ "cardinality": 4,
+ "max": null,
+ "min": null,
+ "median": null,
+ "mean": null,
+ "numeric_finite_count": 0,
+ "integer_count": 0,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "adr": {
+ "labels": [
+ "62.0",
+ "75.0",
+ "90.0",
+ "65.0",
+ "0.0",
+ "80.0",
+ "95.0",
+ "120.0",
+ "100.0",
+ "85.0",
+ "110.0",
+ "60.0",
+ "130.0",
+ "48.0",
+ "115.0",
+ "70.0",
+ "99.0",
+ "140.0",
+ "126.0",
+ "108.0",
+ "170.0",
+ "160.0",
+ "89.0",
+ "68.0",
+ "105.0",
+ "135.0",
+ "79.2",
+ "89.1",
+ "117.0",
+ "62.8",
+ "109.0",
+ "88.0",
+ "72.0",
+ "94.5",
+ "79.0",
+ "66.0",
+ "98.0",
+ "96.0",
+ "55.0",
+ "67.0",
+ "101.5",
+ "58.0",
+ "125.0",
+ "81.0",
+ "74.8",
+ "35.0",
+ "107.1",
+ "40.0",
+ "76.5",
+ "50.0",
+ "80.75",
+ "104.0",
+ "78.0",
+ "150.0",
+ "64.0",
+ "84.0",
+ "130.5",
+ "30.0",
+ "85.5",
+ "45.0",
+ "96.3",
+ "144.0",
+ "86.0",
+ "42.0",
+ "43.0",
+ "80.1",
+ "119.0",
+ "90.95",
+ "129.0",
+ "54.0",
+ "72.25",
+ "116.1",
+ "87.0",
+ "36.0",
+ "56.0",
+ "107.0",
+ "39.0",
+ "139.5",
+ "139.0",
+ "93.6",
+ "112.67",
+ "88.4",
+ "180.0",
+ "105.3",
+ "122.4",
+ "114.0",
+ "46.0",
+ "73.0",
+ "153.0",
+ "37.8",
+ "125.1",
+ "106.0",
+ "109.8",
+ "76.0",
+ "38.0",
+ "121.5",
+ "190.0",
+ "162.0",
+ "93.0",
+ "118.0"
+ ],
+ "label_counts": [
+ 3754,
+ 2715,
+ 2473,
+ 2418,
+ 1959,
+ 1889,
+ 1661,
+ 1607,
+ 1573,
+ 1538,
+ 1525,
+ 1313,
+ 1275,
+ 1123,
+ 1080,
+ 1044,
+ 905,
+ 866,
+ 852,
+ 818,
+ 759,
+ 748,
+ 747,
+ 725,
+ 722,
+ 675,
+ 620,
+ 606,
+ 566,
+ 565,
+ 564,
+ 560,
+ 529,
+ 509,
+ 489,
+ 484,
+ 482,
+ 475,
+ 472,
+ 459,
+ 459,
+ 455,
+ 445,
+ 431,
+ 423,
+ 420,
+ 420,
+ 418,
+ 417,
+ 408,
+ 389,
+ 383,
+ 380,
+ 379,
+ 370,
+ 367,
+ 366,
+ 365,
+ 363,
+ 362,
+ 361,
+ 358,
+ 357,
+ 352,
+ 340,
+ 338,
+ 328,
+ 326,
+ 324,
+ 312,
+ 309,
+ 308,
+ 304,
+ 296,
+ 296,
+ 296,
+ 293,
+ 292,
+ 286,
+ 282,
+ 280,
+ 279,
+ 278,
+ 275,
+ 263,
+ 261,
+ 256,
+ 252,
+ 252,
+ 245,
+ 242,
+ 241,
+ 238,
+ 236,
+ 235,
+ 235,
+ 228,
+ 227,
+ 226,
+ 224
+ ],
+ "cardinality": 8879,
+ "max": 5400,
+ "min": -6.38,
+ "median": 94.575,
+ "mean": 101.83112153446686,
+ "numeric_finite_count": 119390,
+ "integer_count": 69874,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "required_car_parking_spaces": {
+ "labels": [
+ "0",
+ "1",
+ "2",
+ "3",
+ "8"
+ ],
+ "label_counts": [
+ 111974,
+ 7383,
+ 28,
+ 3,
+ 2
+ ],
+ "cardinality": 5,
+ "max": 8,
+ "min": 0,
+ "median": 0,
+ "mean": 0.06251779881062065,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "total_of_special_requests": {
+ "labels": [
+ "0",
+ "1",
+ "2",
+ "3",
+ "4",
+ "5"
+ ],
+ "label_counts": [
+ 70318,
+ 33226,
+ 12969,
+ 2497,
+ 340,
+ 40
+ ],
+ "cardinality": 6,
+ "max": 5,
+ "min": 0,
+ "median": 0,
+ "mean": 0.5713627607002262,
+ "numeric_finite_count": 119390,
+ "integer_count": 119390,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "reservation_status": {
+ "labels": [
+ "Check-Out",
+ "Canceled",
+ "No-Show"
+ ],
+ "label_counts": [
+ 75166,
+ 43017,
+ 1207
+ ],
+ "cardinality": 3,
+ "max": null,
+ "min": null,
+ "median": null,
+ "mean": null,
+ "numeric_finite_count": 0,
+ "integer_count": 0,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 0,
+ "datetime_non_float_count": 0,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ },
+ "reservation_status_date": {
+ "labels": [
+ "2015-10-21",
+ "2015-07-06",
+ "2016-11-25",
+ "2015-01-01",
+ "2016-01-18",
+ "2015-07-02",
+ "2016-12-07",
+ "2015-12-18",
+ "2016-02-09",
+ "2016-04-04",
+ "2017-01-24",
+ "2016-11-21",
+ "2016-03-15",
+ "2017-01-19",
+ "2017-02-02",
+ "2016-09-20",
+ "2016-04-17",
+ "2017-05-05",
+ "2015-09-09",
+ "2016-04-27",
+ "2016-06-20",
+ "2016-06-26",
+ "2016-09-06",
+ "2016-10-21",
+ "2017-04-21",
+ "2015-10-19",
+ "2016-03-14",
+ "2016-02-01",
+ "2016-02-14",
+ "2016-06-02",
+ "2015-11-17",
+ "2015-12-08",
+ "2016-03-18",
+ "2017-01-31",
+ "2016-09-15",
+ "2016-12-13",
+ "2017-01-20",
+ "2016-05-29",
+ "2016-12-12",
+ "2015-10-12",
+ "2016-10-10",
+ "2016-01-19",
+ "2016-01-06",
+ "2017-02-24",
+ "2016-07-13",
+ "2016-10-07",
+ "2017-02-15",
+ "2016-02-10",
+ "2017-02-28",
+ "2016-05-05",
+ "2017-01-12",
+ "2016-10-06",
+ "2016-10-16",
+ "2017-03-06",
+ "2016-09-25",
+ "2016-02-29",
+ "2017-03-26",
+ "2016-12-09",
+ "2016-12-11",
+ "2016-01-22",
+ "2017-05-25",
+ "2016-03-28",
+ "2017-01-02",
+ "2017-05-28",
+ "2017-02-06",
+ "2016-02-25",
+ "2017-04-09",
+ "2016-10-28",
+ "2017-01-06",
+ "2017-01-27",
+ "2015-07-23",
+ "2017-02-17",
+ "2016-03-27",
+ "2017-01-18",
+ "2017-07-04",
+ "2016-01-05",
+ "2017-04-05",
+ "2015-10-22",
+ "2015-11-22",
+ "2016-05-04",
+ "2017-02-19",
+ "2015-08-21",
+ "2016-06-17",
+ "2016-03-04",
+ "2016-04-15",
+ "2016-09-29",
+ "2016-05-16",
+ "2015-10-28",
+ "2016-09-26",
+ "2016-05-02",
+ "2017-05-02",
+ "2016-07-18",
+ "2016-09-02",
+ "2016-07-21",
+ "2015-09-30",
+ "2016-01-03",
+ "2016-05-08",
+ "2016-08-01",
+ "2017-02-03",
+ "2017-02-12"
+ ],
+ "label_counts": [
+ 1461,
+ 805,
+ 790,
+ 763,
+ 625,
+ 469,
+ 450,
+ 423,
+ 412,
+ 382,
+ 343,
+ 340,
+ 329,
+ 321,
+ 315,
+ 303,
+ 299,
+ 297,
+ 290,
+ 283,
+ 279,
+ 271,
+ 271,
+ 265,
+ 263,
+ 262,
+ 261,
+ 258,
+ 257,
+ 257,
+ 256,
+ 254,
+ 254,
+ 253,
+ 251,
+ 249,
+ 249,
+ 245,
+ 243,
+ 242,
+ 242,
+ 233,
+ 231,
+ 231,
+ 230,
+ 230,
+ 229,
+ 228,
+ 226,
+ 225,
+ 225,
+ 224,
+ 223,
+ 221,
+ 219,
+ 218,
+ 218,
+ 217,
+ 217,
+ 216,
+ 216,
+ 214,
+ 214,
+ 214,
+ 213,
+ 212,
+ 212,
+ 211,
+ 211,
+ 211,
+ 209,
+ 208,
+ 206,
+ 206,
+ 206,
+ 205,
+ 204,
+ 203,
+ 203,
+ 203,
+ 203,
+ 202,
+ 202,
+ 201,
+ 201,
+ 201,
+ 200,
+ 199,
+ 199,
+ 198,
+ 198,
+ 197,
+ 196,
+ 195,
+ 194,
+ 194,
+ 194,
+ 194,
+ 194,
+ 194
+ ],
+ "cardinality": 926,
+ "max": null,
+ "min": null,
+ "median": null,
+ "mean": null,
+ "numeric_finite_count": 0,
+ "integer_count": 0,
+ "null_like_count": 0,
+ "empty_count": 0,
+ "whitespace_count": 0,
+ "datetime_count": 10000,
+ "datetime_non_float_count": 10000,
+ "datetime_rows_parsed": 10000,
+ "nrows": 119390
+ }
+ },
+ "col_types": {
+ "hotel": "binary",
+ "lead_time": "numeric",
+ "arrival_date_year": "numeric",
+ "arrival_date_month": "categorical",
+ "arrival_date_week_number": "numeric",
+ "arrival_date_day_of_month": "numeric",
+ "stays_in_weekend_nights": "numeric",
+ "stays_in_week_nights": "numeric",
+ "adults": "numeric",
+ "children": "numeric",
+ "babies": "numeric",
+ "meal": "categorical",
+ "country": "categorical",
+ "market_segment": "categorical",
+ "distribution_channel": "categorical",
+ "is_repeated_guest": "binary",
+ "previous_cancellations": "numeric",
+ "previous_bookings_not_canceled": "numeric",
+ "reserved_room_type": "categorical",
+ "assigned_room_type": "categorical",
+ "booking_changes": "numeric",
+ "deposit_type": "categorical",
+ "agent": "numeric",
+ "company": "categorical",
+ "days_in_waiting_list": "numeric",
+ "customer_type": "categorical",
+ "adr": "numeric",
+ "required_car_parking_spaces": "numeric",
+ "total_of_special_requests": "numeric",
+ "reservation_status": "categorical",
+ "reservation_status_date": "datetime"
+ },
+ "target_encoded": [
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0
+ ],
+ "target_clean_encoded": [
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 1,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0
+ ],
+ "invalid_rows": [],
+ "problem_type": "BinaryClassification",
+ "y_map": {
+ "0": "0",
+ "1": "1"
+ }
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "9ed99534-7891-44ba-972c-849614c96e20",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "3f0710cd-8dd7-4721-adba-e2d82a5e72d0",
+ "type": "VISUALIZATION",
+ "operator": "sagemaker.visualizations.describe_0.1",
+ "parameters": {
+ "name": "Table Summary"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "9ed99534-7891-44ba-972c-849614c96e20",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "fa12c3e6-e04e-48db-aab6-f58cdcd3ecce",
+ "type": "VISUALIZATION",
+ "operator": "sagemaker.visualizations.target_leakage_0.1",
+ "parameters": {
+ "name": "Target Leakage (Pre Transform)",
+ "max_features": "40",
+ "problem_type": "classification",
+ "target": "is_canceled"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "9ed99534-7891-44ba-972c-849614c96e20",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "36283f7f-bfb7-45ad-86f6-d38e84b663a5",
+ "type": "VISUALIZATION",
+ "operator": "sagemaker.visualizations.feature_correlation_0.1",
+ "parameters": {
+ "name": "Linear Correlation",
+ "correlation_type": "linear"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "9ed99534-7891-44ba-972c-849614c96e20",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "7d95e093-5405-4f3a-8f05-91017fd834e5",
+ "type": "VISUALIZATION",
+ "operator": "sagemaker.visualizations.feature_correlation_0.1",
+ "parameters": {
+ "name": "Nonlinear (Pre Transform)",
+ "correlation_type": "non-linear"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "9ed99534-7891-44ba-972c-849614c96e20",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "ee7d131a-de63-4464-bd72-4d1c09109ed2",
+ "type": "VISUALIZATION",
+ "operator": "sagemaker.visualizations.multicolinearity_0.1",
+ "parameters": {
+ "name": "VIF",
+ "analysis": "Variance inflation factors"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "9ed99534-7891-44ba-972c-849614c96e20",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "84550733-c71d-4dc4-932f-7c71798fee86",
+ "type": "VISUALIZATION",
+ "operator": "sagemaker.visualizations.multicolinearity_0.1",
+ "parameters": {
+ "name": "PCA",
+ "analysis": "Principal component analysis"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "9ed99534-7891-44ba-972c-849614c96e20",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "6ee83b45-a177-4f75-ba42-5c7e66e1de3a",
+ "type": "VISUALIZATION",
+ "operator": "sagemaker.visualizations.multicolinearity_0.1",
+ "parameters": {
+ "name": "Lasso",
+ "lasso_parameters": {
+ "l1": 1,
+ "problem_type": "Classification",
+ "label": "is_canceled"
+ },
+ "analysis": "Lasso feature selection"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "9ed99534-7891-44ba-972c-849614c96e20",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "8948e57e-e6b5-4771-a7e1-35ae0d13b11e",
+ "type": "VISUALIZATION",
+ "operator": "sagemaker.visualizations.quick_model_0.1",
+ "parameters": {
+ "name": "Pre-Transform Model",
+ "label": "is_canceled"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "9ed99534-7891-44ba-972c-849614c96e20",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "a496c814-53e6-411c-b4ba-2ee960c52435",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.manage_columns_0.1",
+ "parameters": {
+ "operator": "Drop column",
+ "drop_column_parameters": {
+ "column_to_drop": [
+ "reservation_status",
+ "days_in_waiting_list",
+ "hotel",
+ "reserved_room_type",
+ "arrival_date_month",
+ "arrival_date_day_of_month",
+ "reservation_status_date",
+ "babies",
+ "arrival_date_week_number",
+ "arrival_date_year"
+ ]
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "9ed99534-7891-44ba-972c-849614c96e20",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "826a63c7-d23e-49f8-8b81-4647e07c0229",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.manage_columns_0.1",
+ "parameters": {
+ "operator": "Drop column",
+ "drop_column_parameters": {
+ "column_to_drop": [
+ "adults",
+ "agent"
+ ]
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "a496c814-53e6-411c-b4ba-2ee960c52435",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "ce47788a-bce5-49cc-b13a-9a32d624c926",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.manage_rows_0.1",
+ "parameters": {
+ "operator": "Drop duplicates",
+ "drop_duplicates_parameters": {},
+ "sort_parameters": {
+ "order": "Ascending"
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "826a63c7-d23e-49f8-8b81-4647e07c0229",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "96f94388-36fe-4372-8edd-60daec079500",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.handle_outliers_0.1",
+ "parameters": {
+ "operator": "Standard deviation numeric outliers",
+ "standard_deviation_numeric_outliers_parameters": {
+ "standard_deviations": 4,
+ "input_column": [
+ "lead_time",
+ "stays_in_weekend_nights",
+ "stays_in_week_nights",
+ "is_repeated_guest",
+ "previous_cancellations",
+ "previous_bookings_not_canceled",
+ "booking_changes",
+ "adr",
+ "total_of_special_requests",
+ "required_car_parking_spaces"
+ ],
+ "fix_method": "Remove"
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "ce47788a-bce5-49cc-b13a-9a32d624c926",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "b12dd105-782b-49f4-9698-3473a57a7251",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.handle_missing_0.1",
+ "parameters": {
+ "operator": "Fill missing",
+ "fill_missing_parameters": {
+ "input_column": [
+ "children"
+ ],
+ "fill_value": "0"
+ },
+ "impute_parameters": {
+ "column_type": "Numeric",
+ "numeric_parameters": {
+ "strategy": "Approximate Median"
+ }
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "96f94388-36fe-4372-8edd-60daec079500",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "4905c6d2-5ac1-4efc-bfc2-0db41eac9d78",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.handle_missing_0.1",
+ "parameters": {
+ "operator": "Fill missing",
+ "fill_missing_parameters": {
+ "input_column": [
+ "country"
+ ],
+ "fill_value": "PRT"
+ },
+ "impute_parameters": {
+ "column_type": "Numeric",
+ "numeric_parameters": {
+ "strategy": "Approximate Median"
+ }
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "b12dd105-782b-49f4-9698-3473a57a7251",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "fb157a48-c80d-41a7-bdaf-7062d5ef5723",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.custom_code_0.1",
+ "parameters": {
+ "operator": "Python (PySpark)",
+ "pyspark_parameters": {
+ "code": "from pyspark.sql.functions import when\n\ndf = df.withColumn('meal', when(df.meal == 'Undefined', 'BB').otherwise(df.meal))# Table is available as variable `df`\n"
+ },
+ "name": "MealsTranform"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "4905c6d2-5ac1-4efc-bfc2-0db41eac9d78",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "8114e62b-f341-4713-af7b-5af022ff768f",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.process_numeric_0.1",
+ "parameters": {
+ "operator": "Scale values",
+ "scale_values_parameters": {
+ "scaler": "Min-max scaler",
+ "min_max_scaler_parameters": {
+ "min": 0,
+ "max": 1,
+ "input_column": [
+ "lead_time",
+ "stays_in_weekend_nights",
+ "stays_in_week_nights",
+ "is_repeated_guest",
+ "previous_cancellations",
+ "previous_bookings_not_canceled",
+ "booking_changes",
+ "adr",
+ "total_of_special_requests",
+ "required_car_parking_spaces"
+ ]
+ },
+ "standard_scaler_parameters": {
+ "scale": true
+ }
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "fb157a48-c80d-41a7-bdaf-7062d5ef5723",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "5a1bb436-3fed-4e90-8fee-4b54bfc086f2",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.encode_categorical_0.1",
+ "parameters": {
+ "operator": "One-hot encode",
+ "one_hot_encode_parameters": {
+ "invalid_handling_strategy": "Keep",
+ "drop_last": false,
+ "output_style": "Columns",
+ "input_column": [
+ "meal",
+ "is_repeated_guest",
+ "market_segment",
+ "assigned_room_type",
+ "deposit_type",
+ "customer_type"
+ ]
+ },
+ "ordinal_encode_parameters": {
+ "invalid_handling_strategy": "Replace with NaN"
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "8114e62b-f341-4713-af7b-5af022ff768f",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "db7ff0f7-6ef8-4d7e-a676-359fe6574514",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.balance_data_0.1",
+ "parameters": {
+ "operator": "Random oversample",
+ "ratio": 1,
+ "smote_params": {
+ "num_neighbors": 5
+ },
+ "target_column": "is_canceled"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "5a1bb436-3fed-4e90-8fee-4b54bfc086f2",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "89e29e9a-61ab-4cf0-9516-f723cfaf85c8",
+ "type": "VISUALIZATION",
+ "operator": "sagemaker.visualizations.quick_model_0.1",
+ "parameters": {
+ "name": "Model (Post Transform)",
+ "label": "is_canceled"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "db7ff0f7-6ef8-4d7e-a676-359fe6574514",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "8c6c0988-f626-44a0-bc84-195de676cfd1",
+ "type": "DESTINATION",
+ "operator": "sagemaker.spark.s3_destination_0.1",
+ "name": "S3: Hotel-Bookings-Dataset",
+ "parameters": {
+ "output_config": {
+ "compression": "none",
+ "output_path": "s3://mlopsbucket12345/",
+ "output_content_type": "CSV",
+ "delimiter": ","
+ }
+ },
+ "inputs": [
+ {
+ "name": "default",
+ "node_id": "db7ff0f7-6ef8-4d7e-a676-359fe6574514",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ }
+ ]
+}
\ No newline at end of file
diff --git a/sagemaker-datawrangler/tabular-dataflow/README.md b/sagemaker-datawrangler/tabular-dataflow/README.md
new file mode 100644
index 0000000000..a5dd7b2429
--- /dev/null
+++ b/sagemaker-datawrangler/tabular-dataflow/README.md
@@ -0,0 +1,126 @@
+# Hotel Booking Demand Example
+
+
+
+## Background
+
+Amazon SageMaker helps data scientists and developers to prepare, build, train, and deploy machine learning models quickly by bringing together a broad set of purpose-built capabilities. This example shows how SageMaker can accelerate machine learning development during the data preprocessing stage to help process the hotel demand data and find relevant features for the training model to predict hotel cancellations.
+
+### Dataset
+
+
+
Dataset
+
+We will be using the [Hotel Booking Demand dataset](https://www.kaggle.com/jessemostipak/hotel-booking-demand) that is publically available. This data set contains booking information for a city hotel and a resort hotel, and includes information such as when the booking was made, length of stay, the number of adults, children, and/or babies, and the number of available parking spaces, among other things.
+
+The data needs to be downloaded from the locations specified, and uploaded to S3 bucket before we start the Data Preprocessing phase. Please follow the Experiment Steps outlined in later sections, to download the data and notebooks.
+
+
+## Description of the Columns
+
+
+
+| Column Name | Description |
+|---|---|
+| `hotel` | Type of the hotel (`H1` = Resort Hotel or `H2` = City Hotel) |
+| `is_canceled` | Value indicating if the booking was canceled (1) or not (0) |
+| `lead_time` | Number of days that elapsed between the entering date of the booking into the PMS and the arrival date |
+| `arrival_date_year` | Year of arrival date |
+| `arrival_date_month` | Month of arrival date |
+| `arrival_date_week_number` | Week number of year for arrival date |
+| `arrival_date_day_of_month` | Day of arrival date |
+| `stays_in_weekend_nights` | Number of weekend nights (Saturday or Sunday) the guest stayed or booked to stay at the hotel |
+| `stays_in_week_nights` | Number of week nights (Monday to Friday) the guest stayed or booked to stay at the hotel |
+| `adults` | Number of adults |
+| `children` | Number of children |
+| `babies` | Number of babies |
+| `meal` | Type of meal booked. Categories are presented in standard hospitality meal packages: `Undefined/SC` – no meal package; `BB` – Bed & Breakfast; `HB` – Half board (breakfast and one other meal – usually dinner); `FB` – Full board (breakfast, lunch and dinner) |
+| `country`| Country of origin. Categories are represented in the `ISO 3155–3:2013` format |
+|`market_segment`|Market segment designation. In categories, the term `TA` means “Travel Agents” and `TO` means “Tour Operators”|
+|`distribution_channel`|Booking distribution channel. The term `TA` means “Travel Agents” and `TO` means “Tour Operators”|
+|`is_repeated_guest`|Value indicating if the booking name was from a repeated guest (1) or not (0)|
+|`previous_cancellations`|Number of previous bookings that were cancelled by the customer prior to the current booking|
+|`previous_bookings_not_canceled`|Number of previous bookings not cancelled by the customer prior to the current booking|
+|`reserved_room_type`|Code of room type reserved. Code is presented instead of designation for anonymity reasons.|
+|`assigned_room_type`|Code for the type of room assigned to the booking. Sometimes the assigned room type differs from the reserved room type due to hotel operation reasons (e.g. overbooking) or by customer request. Code is presented instead of designation for anonymity reasons.|
+|`booking_changes`|Number of changes/amendments made to the booking from the moment the booking was entered on the PMS until the moment of check-in or cancellation|
+|`deposit_type`|Indication on if the customer made a deposit to guarantee the booking. This variable can assume three categories: No Deposit – no deposit was made; `Non Refund` – a deposit was made in the value of the total stay cost; `Refundable` – a deposit was made with a value under the total cost of stay.|
+|`agent`|ID of the travel agency that made the booking|
+|`company`|ID of the company/entity that made the booking or responsible for paying the booking. ID is presented instead of designation for anonymity reasons|
+|`days_in_waiting_list`|Number of days the booking was in the waiting list before it was confirmed to the customer|
+|`customer_type`|Type of booking, assuming one of four categories: `Contract` - when the booking has an allotment or other type of contract associated to it; `Group` – when the booking is associated to a group; `Transient` – when the booking is not part of a group or contract, and is not associated to other transient booking; `Transient-party` – when the booking is transient, but is associated to at least other transient booking|
+|`adr`|Average Daily Rate as defined by dividing the sum of all lodging transactions by the total number of staying nights|
+|`required_car_parking_spaces`|Number of car parking spaces required by the customer|
+|`total_of_special_requests`|Number of special requests made by the customer (e.g. twin bed or high floor)|
+|`reservation_status`|Reservation last status, assuming one of three categories: `Canceled` – booking was canceled by the customer; `Check-Out` – customer has checked in but already departed; `No-Show` – customer did not check-in and did inform the hotel of the reason why|
+|`reservation_status_date`|Date at which the last status was set. This variable can be used in conjunction with the ReservationStatus to understand when was the booking canceled or when did the customer checked-out of the hotel|
+
+---
+
+## Pre-requisites:
+
+ * We need to ensure dataset (tracks and ratings dataset) for ML is uploaded to a data source (instructions to download the dataset to Amazon S3 is available in the following section).
+ * Data source can be any one of the following options:
+ * S3
+ * Athena
+ * RedShift
+ * SnowFlake
+
+
+
+Data Source
+
+For this experiment the Data Source will be [Amazon S3](https://aws.amazon.com/s3/)
+
+
+
+## Experiment steps
+
+### Downloading the dataset
+
+* Ensure that you have a working [Amazon SageMaker Studio](https://aws.amazon.com/sagemaker/studio/) environment and that it has been updated.
+
+* Follow the steps below to download the dataset.
+1. Download the [Hotel Booking Demand dataset](https://www.kaggle.com/jessemostipak/hotel-booking-demand) from the specified location.
+2. Create a private S3 bucket to upload the dataset in. You can reference the instructions for bucket creaiton [here] https://docs.aws.amazon.com/AmazonS3/latest/userguide/create-bucket-overview.html
+3. Upload the data in step 1 to the bucket created in step 2. Steps to upload the data can be found [here] https://docs.aws.amazon.com/AmazonS3/latest/userguide/upload-objects.html
+4. Note the S3 URL for the file uploaded in Step 3 before moving to the next sextion. This data will be used as input to the Datawrangler. The S3 URL will be used in the next step.
+
+### Data Import from S3 to Data Wrangler
+The hotel-bookings.csv file uploaded in previous section needs to be imported in Data Wrangler as input. Please refer to **[Data Import from S3](data-import/Data-Import.md)** and follow steps for importing the data.
+
+### Exploratory Data Analysis
+Before applying various data transformations, we need to explore the data to find correlations, duplicate rows as well as target leakage. Please refer to **[Exploratory Data Analysis](data-exploraion/Data-Exploration.md)** and follow steps for Data exploration.
+
+### Data Transformation
+Based on the Data explorations carried out in previous step, we are now ready to apply transformations to the data. Please refer to **[Data Transformations](data-transformation/Data-Transformations.md)** and follow steps for Data Transformation.
+
+### Data Export
+Data Wrangler UI can also be used to export the transformed data to Amazon S3. To get started with this process, first let's create a destination node. Right click on the final transform on your data and choose `Add destination` → `Amazon S3`. Assign a name for your output data and choose the S3 location where you want the data to be stored and click Add destination button at the bottom as shown below.
+
+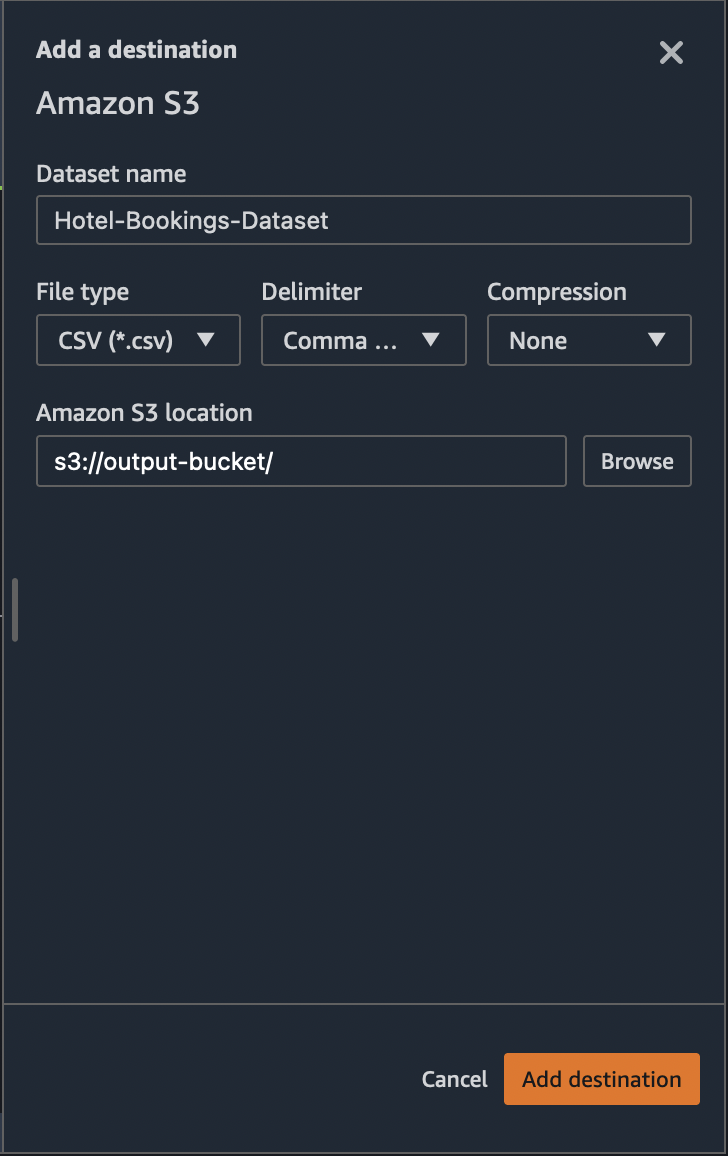
+
+This adds a destination node to our data flow. The destination node acts as a sink to your data flow.
+
+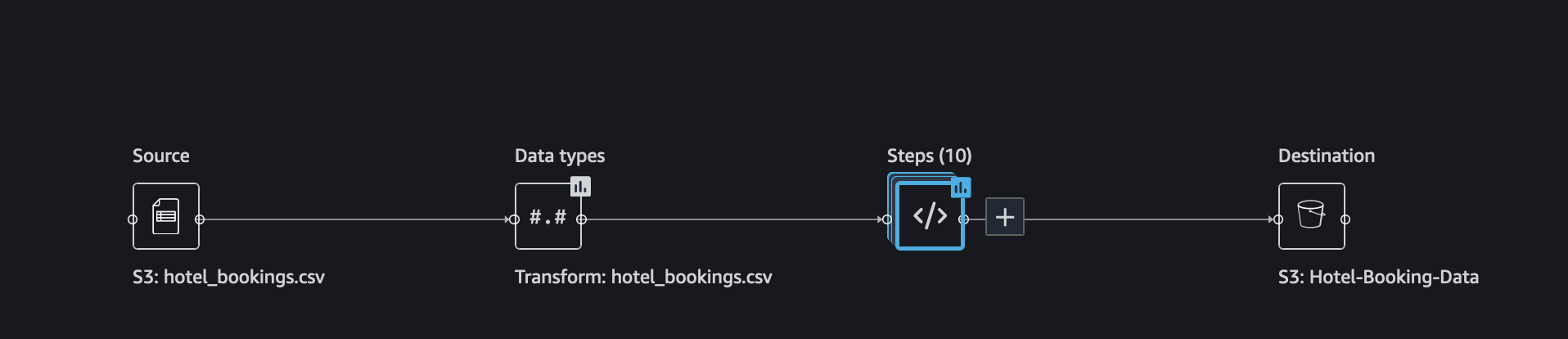
+
+Next, click on the Create job button in the upper right corner of the page. In the configuration page for the SageMaker Processing job we are about to create, choose the Instance type and Instance count for our processing cluster. Advance configuration is optional, where you can assign tags as needed and choose the appropriate Volume Size.
+
+
+
+Select `Run` to start the export job. The job created will have Job Name and Job ARN which can be used to search for the job status.
+
+
+
+The job created in the previous step will be available in the monitoring page for `SageMaker Processing job` as shown in the figure below.
+
+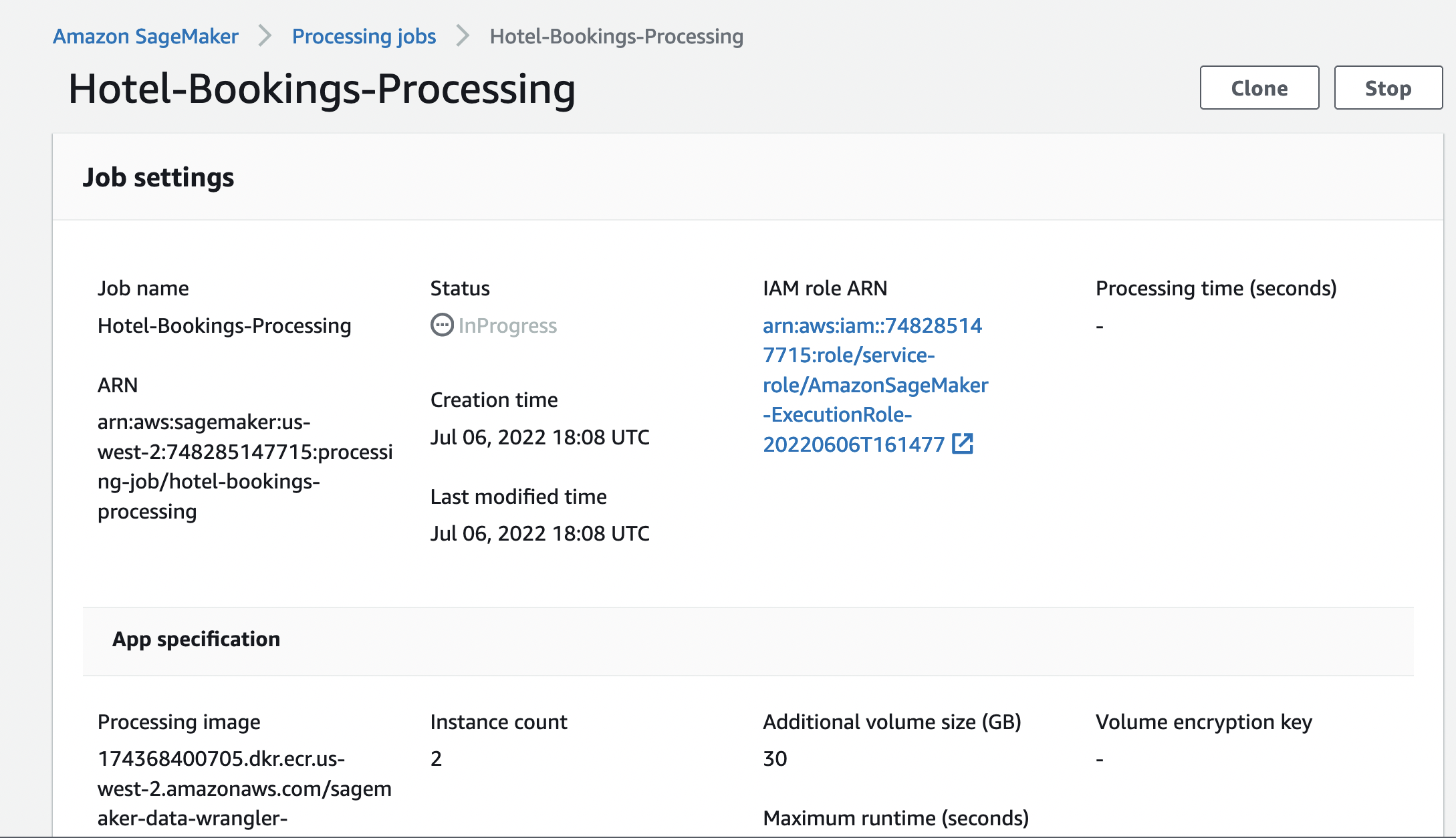
+
+After a certain time, the job will be complete. The image below shows the completed job. Exported data should be available in the output S3 bucket.
+
+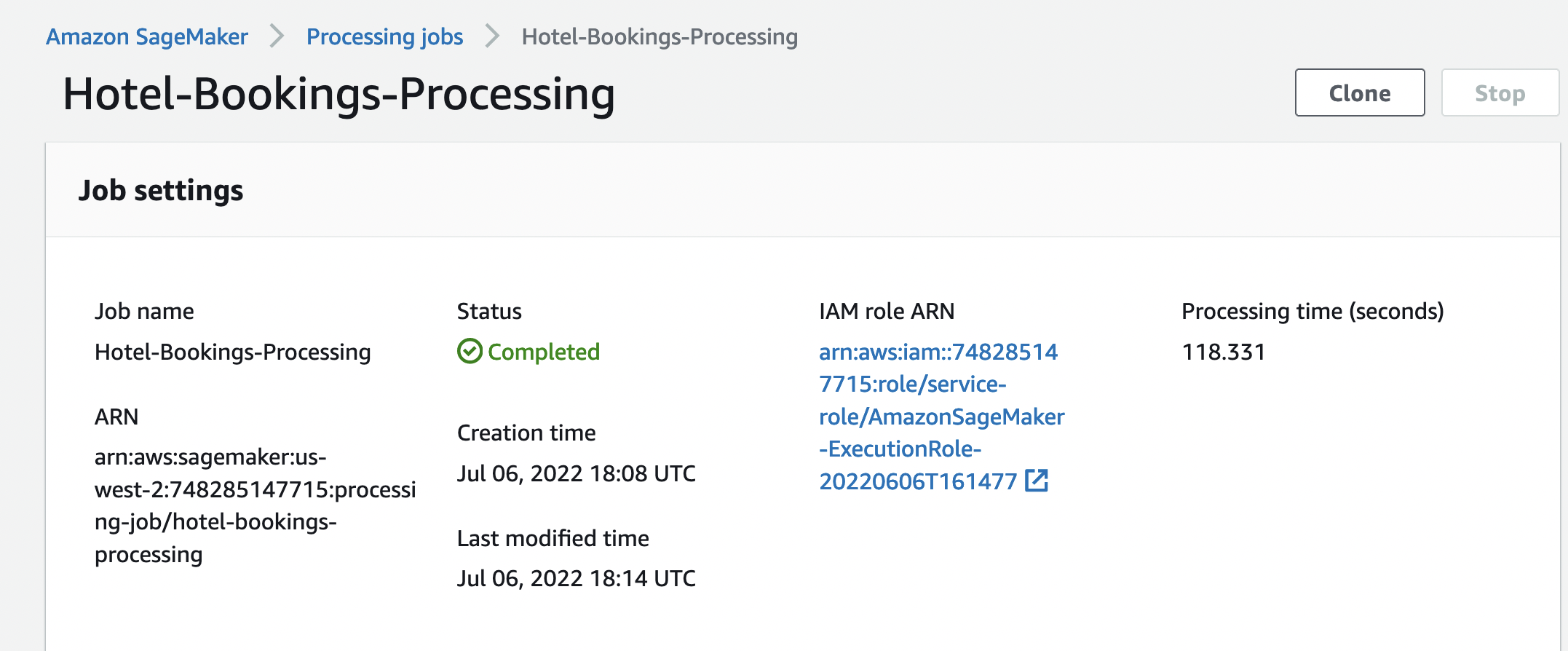
+
+
+ This exported data can now be used for running the ML Models
+
+ :bulb:**NOTE** - Also, you can import the [flow file](./Hotel-Bookings-Classification.flow) by following the steps [here](../import-flow.md)
diff --git a/sagemaker-datawrangler/tabular-dataflow/data-exploration/Data-Exploration.md b/sagemaker-datawrangler/tabular-dataflow/data-exploration/Data-Exploration.md
new file mode 100644
index 0000000000..4b4d6cec78
--- /dev/null
+++ b/sagemaker-datawrangler/tabular-dataflow/data-exploration/Data-Exploration.md
@@ -0,0 +1,242 @@
+## Exploratory Data Analysis
+
+### Analyze and Visualize
+
+Before we transform our raw features to make it ML ready for model building, lets analyze and visualize the booking cancellations dataset to detect features that are important to our problem and ones that are not. This can be achieved through Exploratory Data Analysis (EDA). Amazon SageMaker Data Wrangler includes built-in analyses that help you generate visualizations and data analyses in a few clicks. You can also create custom analyses using your own code.
+
+In order to apply an action on the imported data, select the **Add Analysis** option on right clicking the the **Data Types** block. As depicted in the figure below, you can see options to add a transform, perform an analysis, add a destination sink or export the steps as Jupyter notebook. You can also join and concatenate on the imported dataset with other datasets.
+
+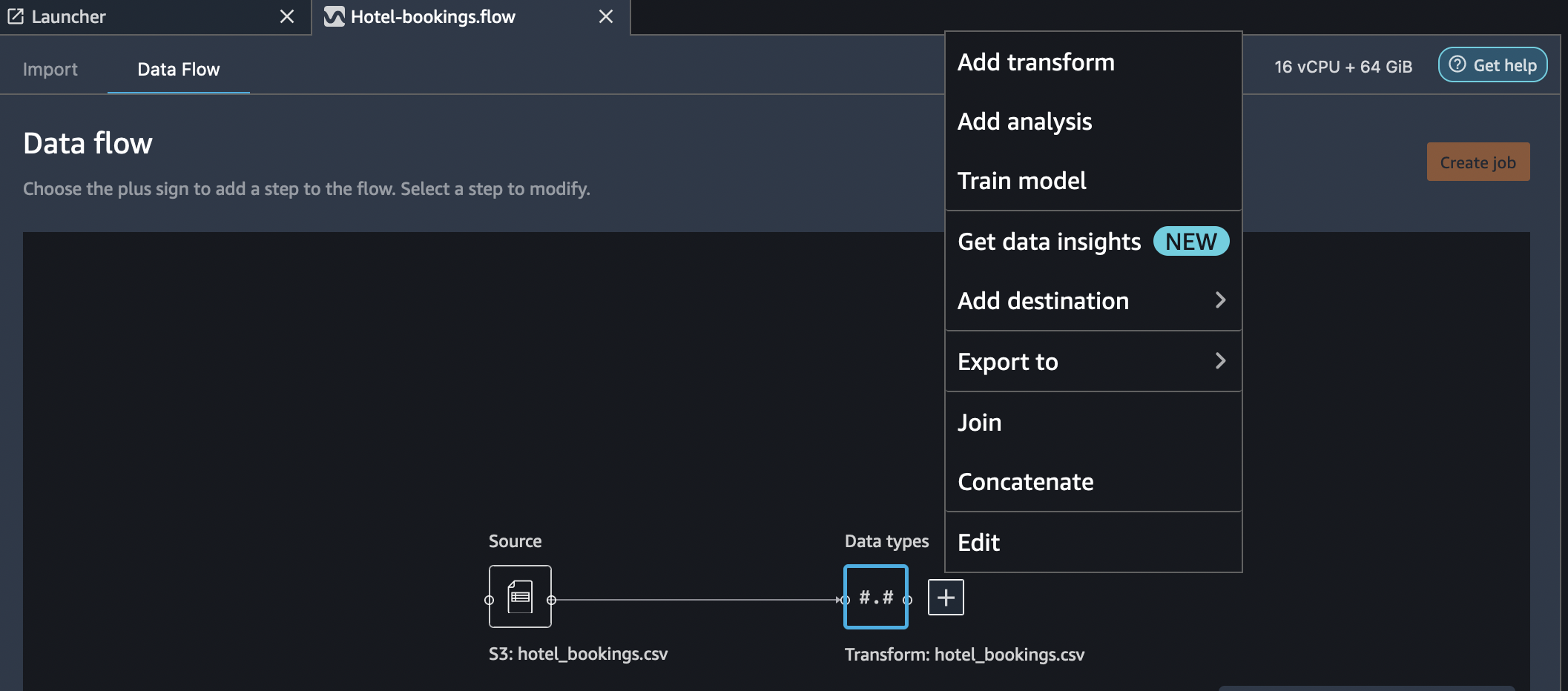
+
+On selecting Add Analysis, the Analysis pane os shown, where you can choose the analysis you want to perform.
+
+All analyses are generated using 100,000 rows of your dataset.
+
+You can add the following analysis to a dataframe:
+
+* Data visualizations, including histograms and scatter plots.
+* A quick summary of your dataset, including number of entries, minimum and maximum values (for numeric data), and most and least frequent categories (for categorical data).
+* A quick model of the dataset, which can be used to generate an importance score for each feature.
+* A target leakage report, which you can use to determine if one or more features are strongly correlated with your target feature.
+* A custom visualization using your own code.
+
+
+Following sections showcase few of the analysis techniques for the Hotel-bookings data.
+
+### Get Insights
+
+You can get the Data Insights report by selecting **Get Insights** option for the **Data Types** block as shown in the figure.
+
+
+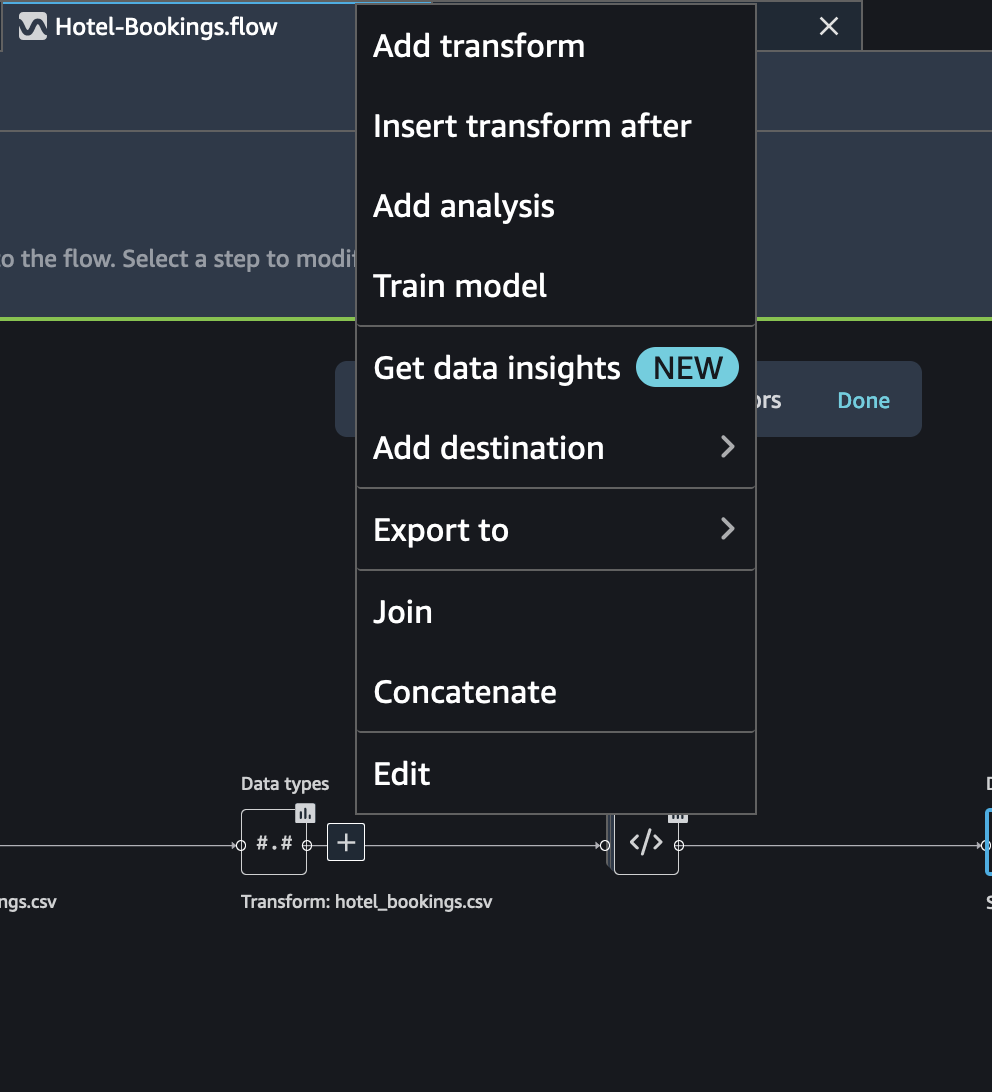
+
+Please select the following parameters and hit **Create**.
+ - `Target column`: `is-cancelled`
+ - `Problem type`: `Classification`
+
+After the report is generated, it outlines findings about statistics, duplicate rows, warnings, confusion matrix and feature summary. This can be a useful report before we start our detailed analysis.
+
+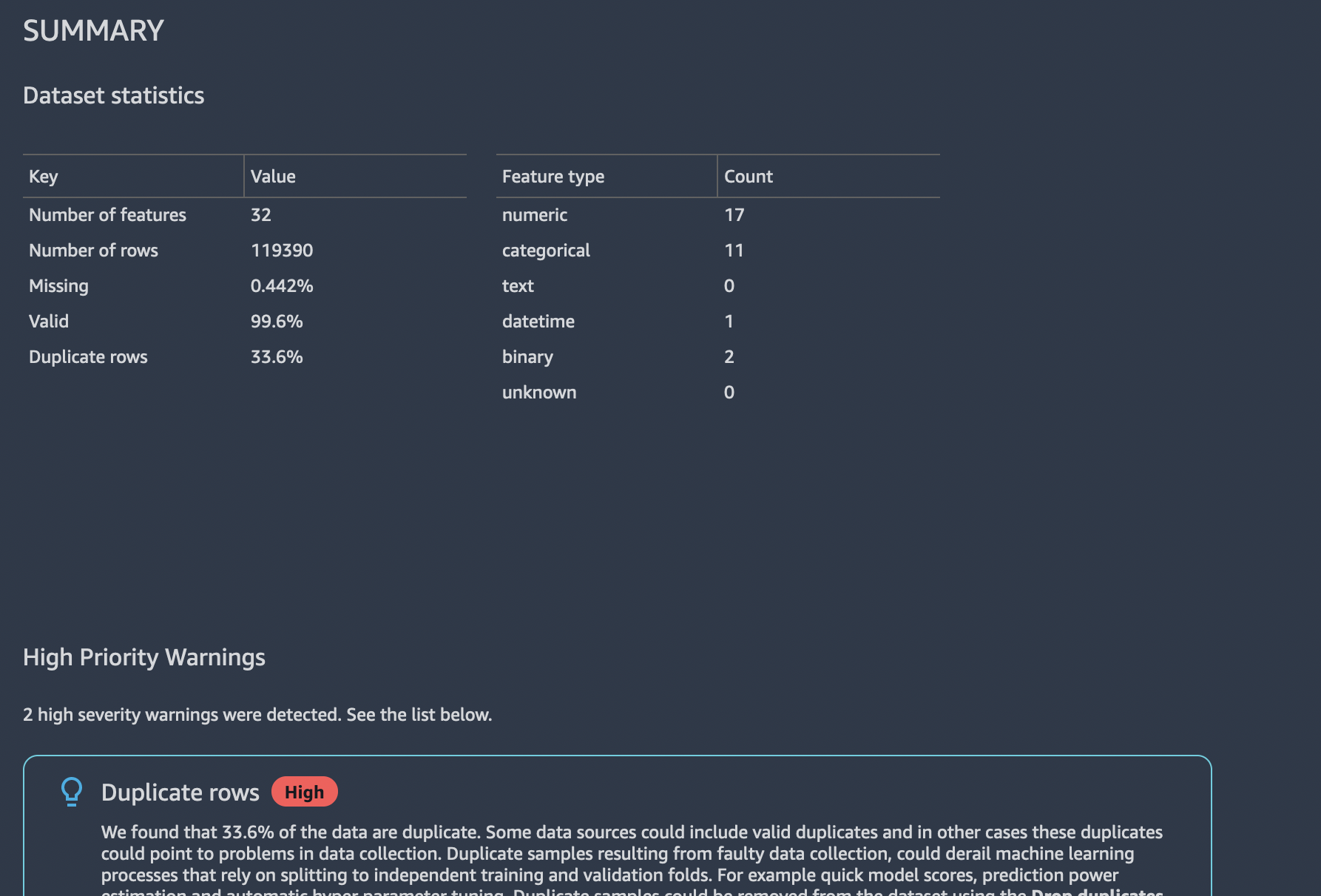
+
+
+
+### Table Summary
+
+Select **Table Summary** Analysis in the **Add Analysis** window.
+
+Please select the following parameters and hit **Preview**.
+- `Analysis name`: `Table Summary`
+
+Overall details of the data for various columsn is displayed as depicted in figure below.
+
+
+
+Select **Save** to save the analysis.
+
+
+### Target Leakage
+
+Target leakage occurs when there is data in a machine learning training dataset that is strongly correlated with the target label, but is not available in real-world data. For example, you may have a column in your dataset that serves as a proxy for the column you want to predict with your model.
+
+When you use the Target Leakage analysis, you specify the following:
+* **Target**: This is the feature about which you want your ML model to be able to make predictions.
+* **Problem type**: This is the ML problem type on which you are working. Problem type can either be classification or regression.
+* (Optional) **Max features**: This is the maximum number of features to present in the visualization, which shows features ranked by their risk of being target leakage.
+
+For classification, the target leakage analysis uses the area under the receiver operating characteristic, or AUC - ROC curve for each column, up to Max features. For regression, it uses a coefficient of determination, or R2 metric.
+
+The AUC - ROC curve provides a predictive metric, computed individually for each column using cross-validation, on a sample of up to around 1000 rows. A score of 1 indicates perfect predictive abilities, which often indicates target leakage. A score of 0.5 or lower indicates that the information on the column could not provide, on its own, any useful information towards predicting the target. Although it can happen that a column is uninformative on its own but is useful in predicting the target when used in tandem with other features, a low score could indicate the feature is redundant.
+
+To create a target leakage analysis, Select **Target Leakage** Analysis in the **Add Analysis** window.
+Please select the following parameters and hit **Preview**.
+- `Analysis name`: `Target Leakage`
+- `Max features` : `40`
+- `Target column`: `is-cancelled`
+- `Problem type`: `Classification`
+
+
+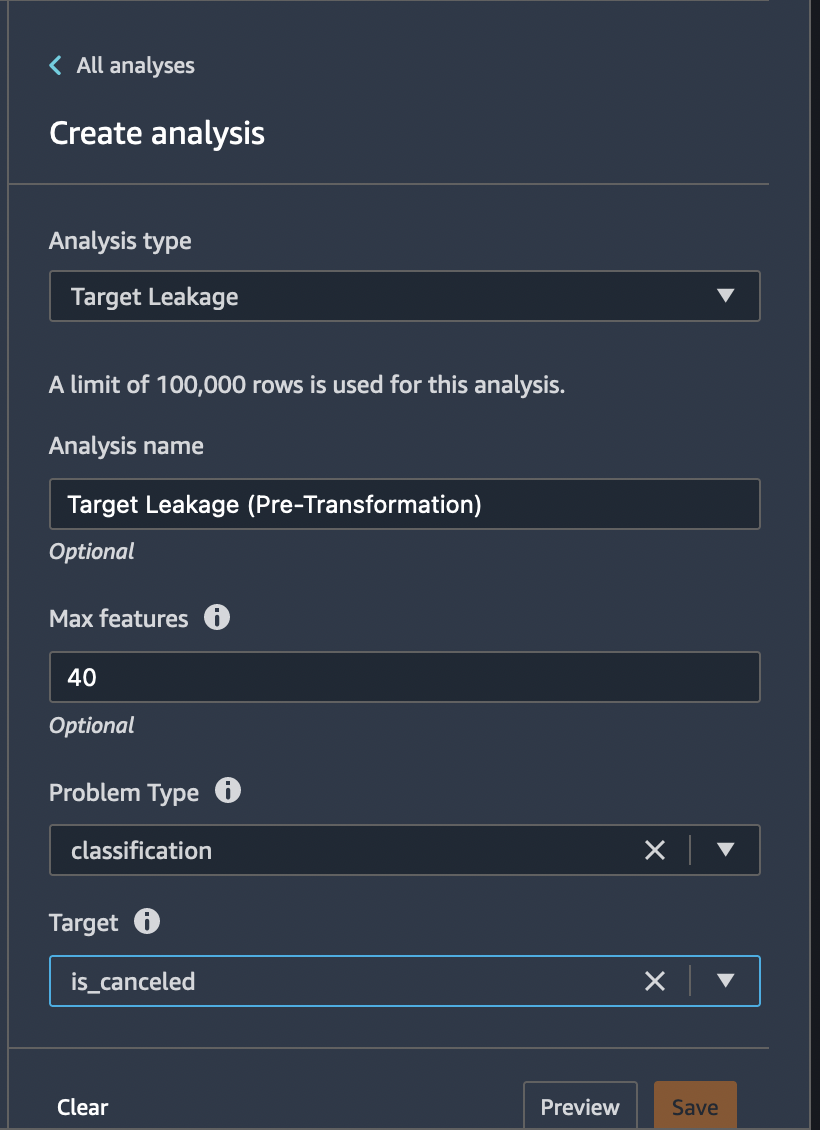
+
+
+For our example dataset, the image below shows a target leakage report for a hotel booking cancellation problem, that is, predicting if a person will cancel his hotel reservation or not. An AUC - ROC curve is used to calculate the predictive ability of 31 raw features, out of which `reservation_status` was determined to a target leakage. Also, features - `arrival_day_of_month`, `babies`, `reservation_status_date`, `arrival_date_month`, `reserved_room_type`, `hotel` and `days_in_waiting_list` were identified as redundant.
+
+The identified features can be fairly omitted as part of the transformations we will apply post this initial analysis.
+
+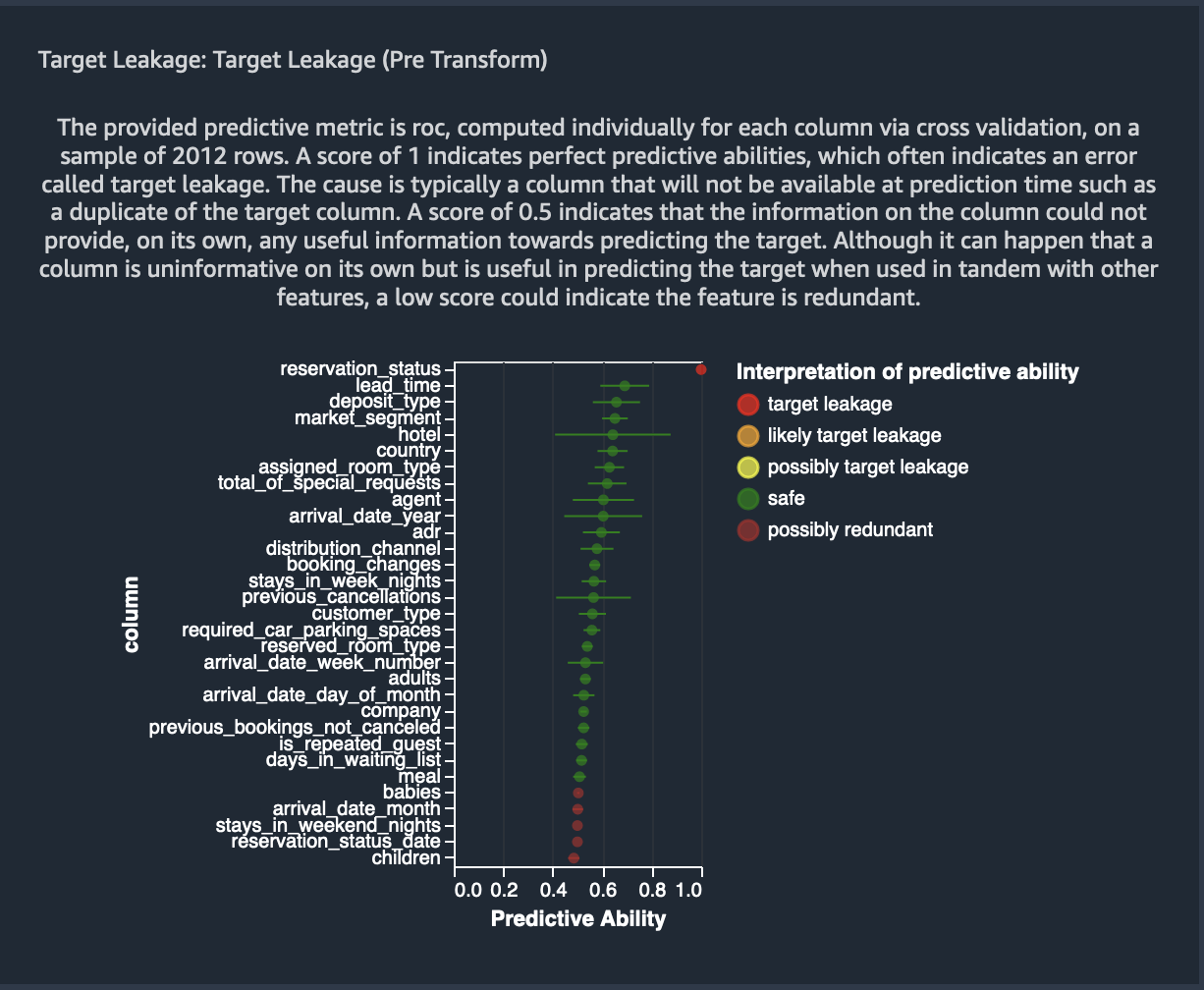
+
+Select **Save** to save the analysis.
+
+
+
+
+Next, with SageMaker Data Wrangler’s feature correlation visualization you can easily calculate the correlation of features in your data set and visualize them as a correlation matrix. We will look into 2 types of feature correlations and how to use them on our example dataset in hand.
+
+### Feature Correlation (Linear)
+
+Linear feature correlation is based on Pearson's correlation. Numeric to categorical correlation is calculated by encoding the categorical features as the floating point numbers that best predict the numeric feature before calculating Pearson's correlation. Linear categorical to categorical correlation is not supported.
+
+Numeric to numeric correlation is in the range [-1, 1] where 0 implies no correlation, 1 implies perfect correlation and -1 implies perfect inverse correlation. Numeric to categorical and categorical to categrical correlations are in the range [0, 1] where 0 implies no correlation and 1 implies perfect correlation.
+To create the analysis, choose **Feature Correlation** for the Analysis type and choose **linear** for Correlation type. Please select the following parameters and hit **Preview**.
+- `Analysis name`: `Linear Correlation`
+
+This analysis will take a few minutes to complete.
+
+Features that are not either numeric or categorical are ignored. The table below lists for each feature what is the most correlated feature to it.
+
+
+
+Based on the correlation values, we can see the top 6 feature pairs (as listed below) are strongly correlating with one another. Also, some of these features also showed up in the target analysis we did previously.
+
+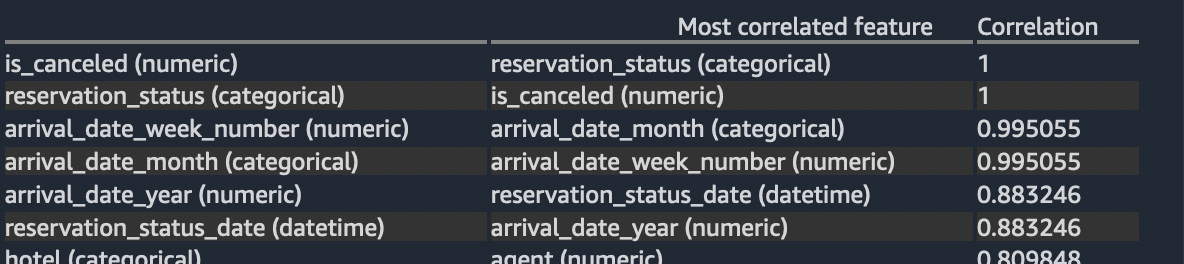
+
+P.S.: A limit of 100,000 rows is used for this analysis.
+
+Select **Save** to save the analysis.
+
+### Feature Correlation (Non-Linear)
+
+Non-linear feature correlation is based on Spearman's rank correlation. Numeric to categorical correlation is calculated by encoding the categorical features as the floating point numbers that best predict the numeric feature before calculating Spearman's rank correlation. Categorical to categorical correlation is based on the normalized Cramer's V test.
+
+Numeric to numeric correlation is in the range [-1, 1] where 0 implies no correlation, 1 implies perfect correlation and -1 implies perfect inverse correlation. Numeric to categorical and categorical to categrical correlations are in the range [0, 1] where 0 implies no correlation and 1 implies perfect correlation
+
+Features that are not either numeric or categorical are ignored.
+
+To create the analysis, choose **Feature Correlation** for the Analysis type and **non-linear** for Correlation type. Please select the following parameters and hit **Preview**.
+- `Analysis name`: `Non-Linear Correlation`
+
+This analysis will take a few minutes to complete.
+
+The table below lists for each feature what is the most correlated feature to it. You can see most of the top correlated feature pairs overlap with the previous two analyses.
+
+
+
+Select **Save** to save the analysis.
+
+### Multicolinearity (Variance Inflation Factors)
+
+Variance Inflation Factor (VIF) is a measure of colinearity among variables. It is calculated by solving a regression problem to predict one variable given the rest. A VIF score is a positive number that is greater or equal than 1, and a score of 1 means the variable is completely independent of the others. The larger the score, the more dependent it is. Since it is an inverse, it is possible for the VIF score to be infinite. Note that we cap the VIF score at 50. As a rule of thumb for cases where the number of samples is not abnormally small, a score of up to 5 means the variable is only moderatly correlated, and beyond 5 it is highly correlated.
+
+To create the analysis for VIF, choose **Multicollinearity** for Analysis type and choose **Variance inflation factors** for Analysis. Please select the following parameters and hit **Preview**.
+- `Analysis name`: `Variance Inflation Factors`
+
+This analysis will take a few minutes to complete.
+
+As per the above rule, we can eliminate the following feature columns from our feature set since they will not contribute effectively towards the prediction capability of the model that gets trained using these features.
+
+* `arrival_date_year`
+* `adults`, `agents`
+* `arrival_date_week_number`
+* `stays_in_week_nights`
+
+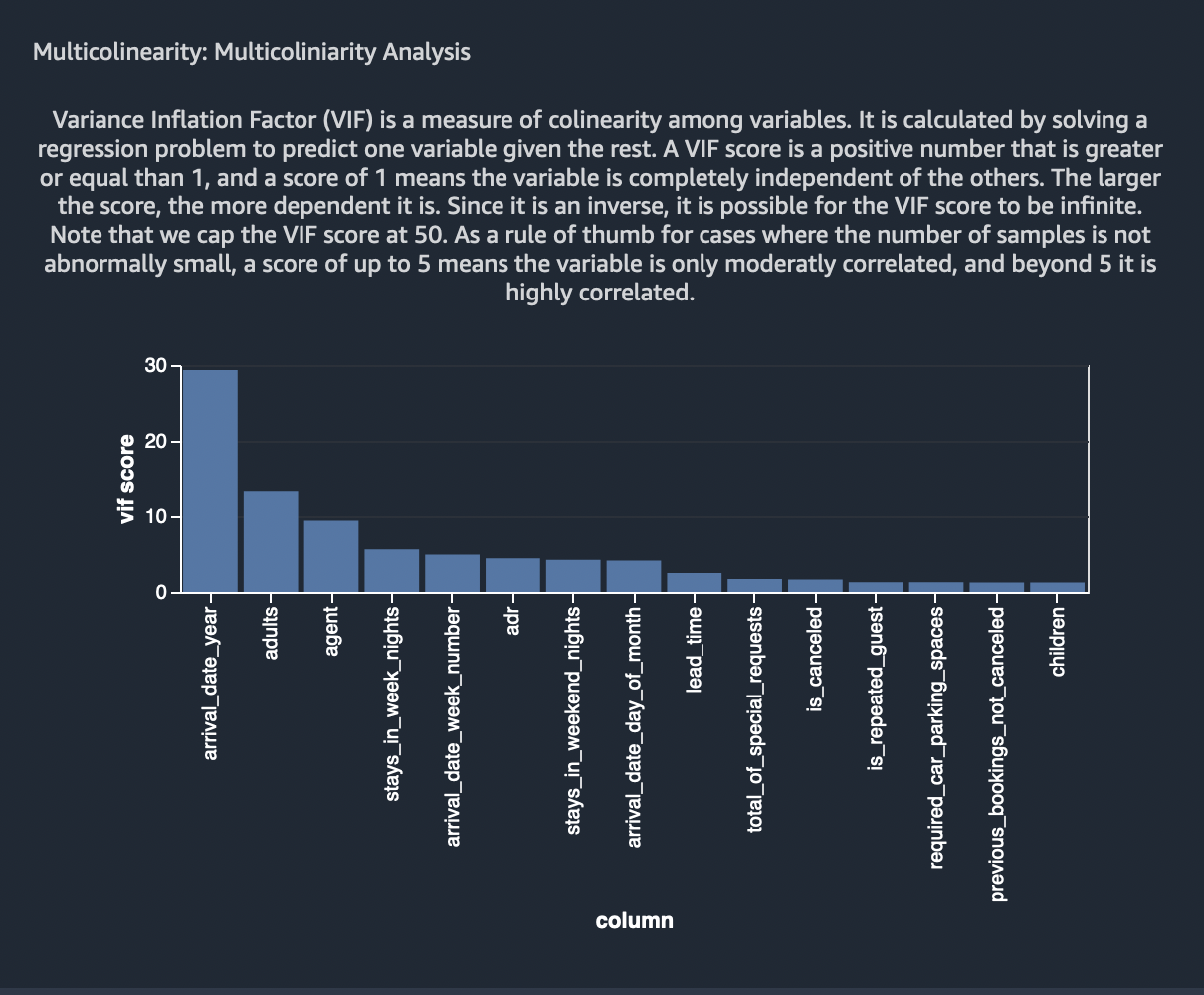
+
+Select **Save** to save the analysis.
+
+
+### Multicolinearity - Principal Component Analysis (PCA)
+
+Principal Component Analysis (PCA) measures the variance of the data along different directions in the feature space. The ordered list of variances, also known as the singular values, can inform about multicolinearity in our data. This list contains non-negative numbers. When the numbers are roughly uniform, the data has very few multicolinearities. However, when the opposite is true, the magnitude of the top values will dominate the rest. In order to avoid issues related to different scales, the individual features are standardized to have mean 0 and standard deviation 1 before applying PCA.
+
+To create the analysis for PCA, choose **Multicollinearity** for Analysis type and choose **Principal component analysis** for Analysis. Please select the following parameters and hit **Preview**.
+- `Analysis name`: `Principal Component Analysis`
+
+This analysis will take a few minutes to complete.
+
+As per the above rule, it is evident the numbers (variances) are not uniform hence confirming that the data has multicolinearies to fix. This has already been confirmed by our previous analysis.
+
+
+
+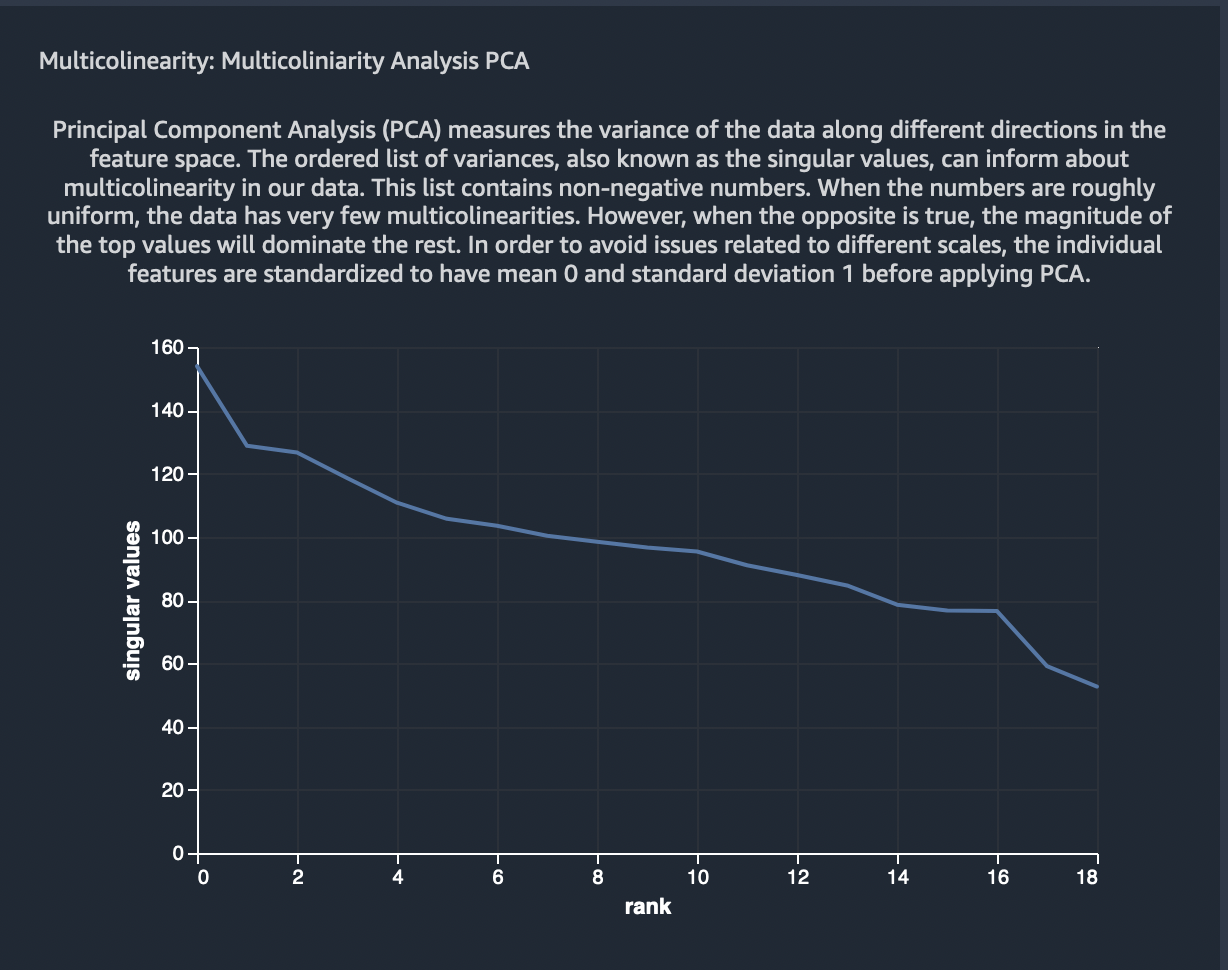
+
+Select **Save** to save the analysis.
+
+
+### Multicolinearity Lasso Feature Selection
+
+
+Lasso feature selection trains a linear classifier with L1 regularization (you can control the strength of L1 penalty by adjusting "L1 magnitude") that induces a sparse solution. The regressor provides a coefficient for each feature, and the absolute value of this coefficient could be interpreted as an importance score for that feature.
+
+To create the analysis for Lasso Feature Selection, choose **Multicollinearity** for Analysis type and choose **Lasso feature selection** for Analysis. Please select the following parameters and hit **Preview**.
+- `Analysis name`: `Non-Linear Correlation`
+- `L1 Magnitude`: `1`
+- `Problem Type`: `Classification`
+- `Label Column` : `is_cancelled`
+
+This analysis will take a few minutes to complete.
+
+
+The plot below provides features' importance scores (absolute coefficients) after training a classifier on a sample of the dataset (10k for large dataset). The training process includes a standardization of the features to have mean 0 and standard deviation 1 in order to avoid a skewed importance score due to different scales.
+
+The classifier obtained a roc_auc score: `0.639269142214666`.
+
+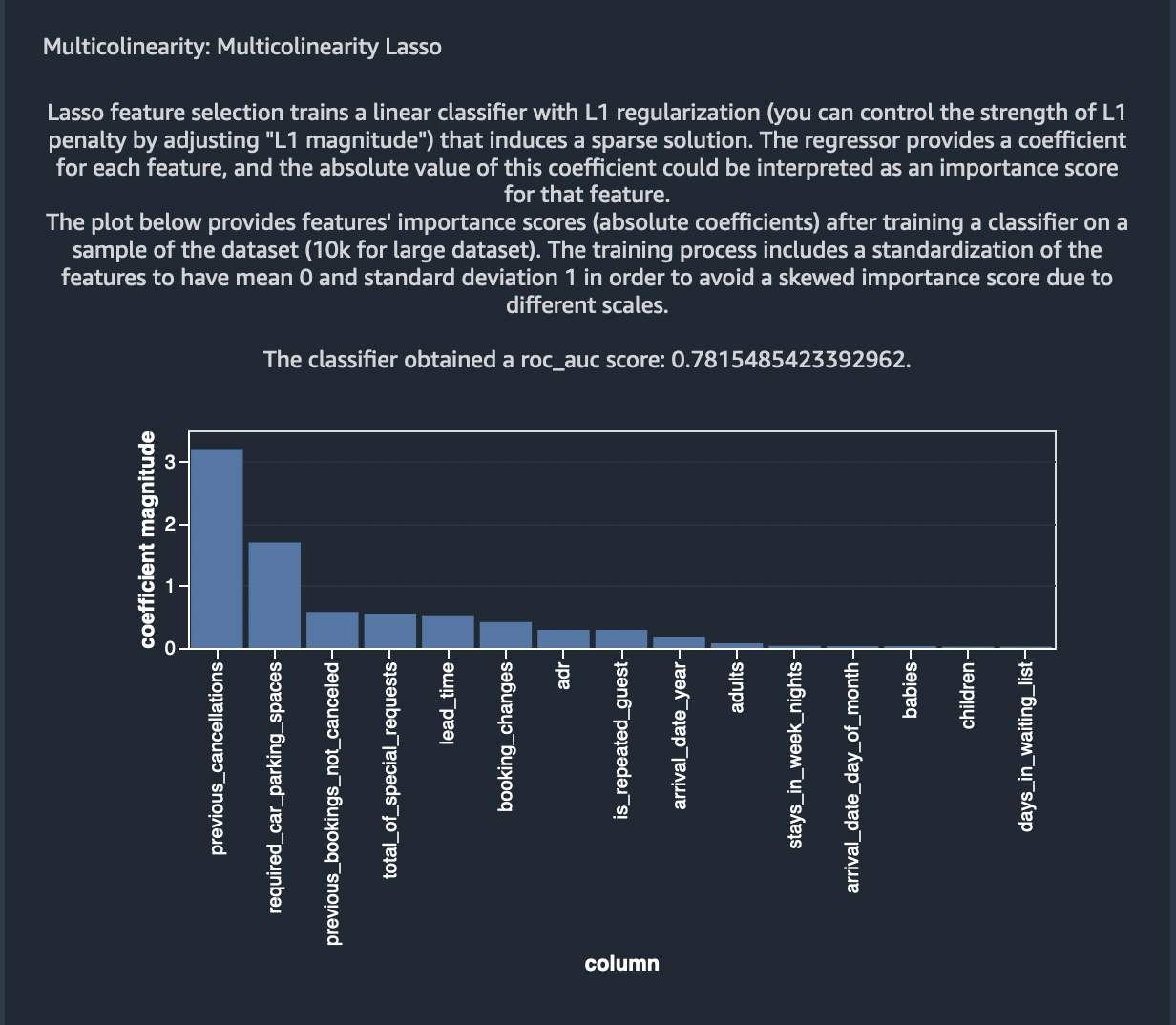
+
+Select **Save** to save the analysis.
+
+
+
+### Detect Duplicate Rows
+Next, with the new duplicate row detection visualization, you can quickly detect if your data set has any duplicate rows. To apply this analysis, choose **Duplicate rows** for Analysis type.
+
+From the figure bwlow, we can see almost ~33% of the rows in the dataset are duplicates.
+
+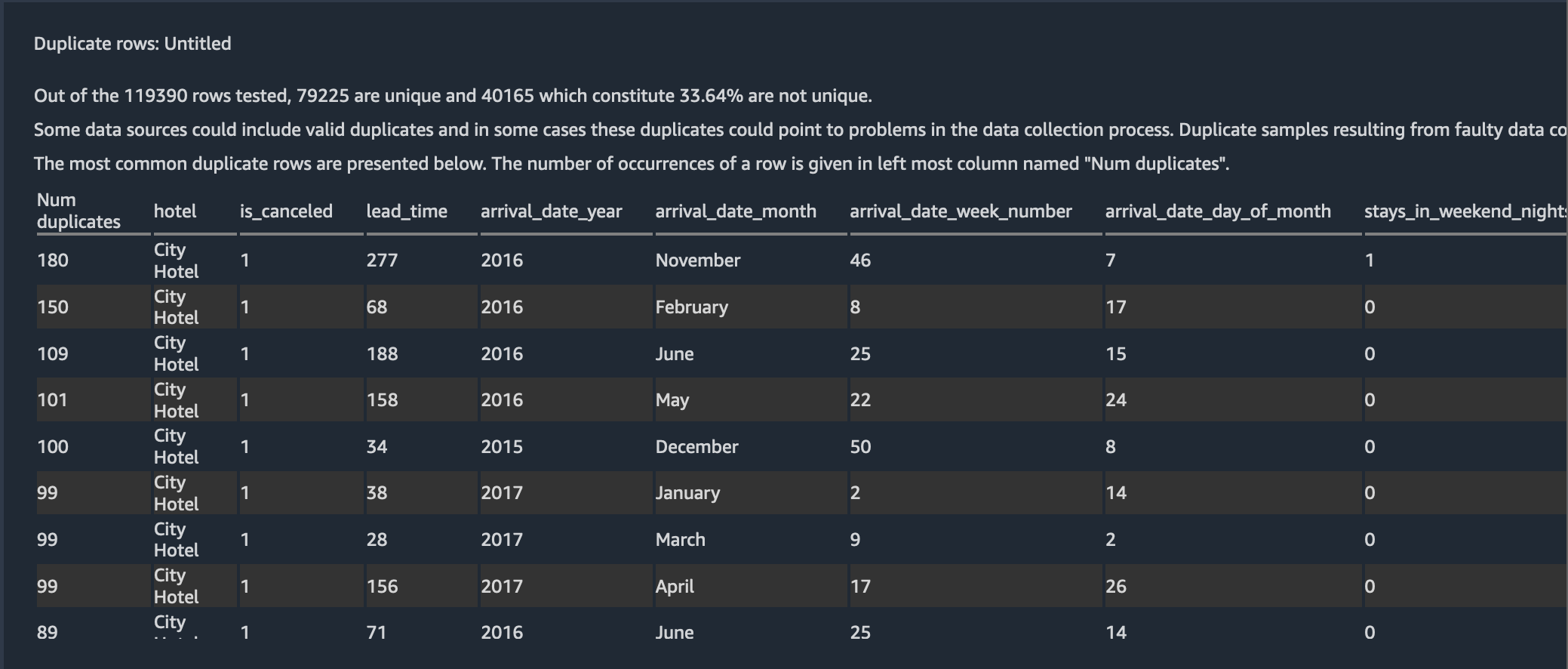
+
+
+
+### Quick Model
+
+We can create a quick model using the raw features to determine how good our features are, prior to applying transformations.
+
+Use the Quick Model visualization to quickly evaluate your data and produce importance scores for each feature. A feature importance score indicates how useful a feature is at predicting a target label. The feature importance score is between [0, 1] and a higher number indicates that the feature is more important to the whole dataset. On the top of the quick model chart, there is a model score. A classification problem shows an F1 score. A regression problem has a mean squared error (MSE) score.
+
+When you create a quick model chart, you select a dataset you want evaluated, and a target label against which you want feature importance to be compared. Data Wrangler does the following:
+* Infers the data types for the target label and each feature in the dataset selected.
+* Determines the problem type. Based on the number of distinct values in the label column, Data Wrangler determines if this is a regression or classification problem type. Data Wrangler sets a categorical threshold to 100. If there are more than 100 distinct values in the label column, Data Wrangler classifies it as a regression problem; otherwise, it is classified as a classification problem.
+* Pre-processes features and label data for training. The algorithm used requires encoding features to vector type and encoding labels to double type.
+* Trains a random forest algorithm with 70% of data. Spark’s RandomForestRegressor is used to train a model for regression problems. The RandomForestClassifier is used to train a model for classification problems.
+* Evaluates a random forest model with the remaining 30% of data. Data Wrangler evaluates classification models using an F1 score and evaluates regression models using an MSE (mean squared error) score.
+* Calculates feature importance for each feature using the Gini importance method.
+
+Let us create a prediction model on the fly for the problem for the booking cancellation problem using the raw crude features we started with in Data Wrangler's Quick Model option.
+
+Please choose **Quick Model** for Analysis type. Select the following parameters and hit **Preview**.
+- `Analysis name`: `Model pre-transform`
+
+This analysis will take a few minutes to complete.
+
+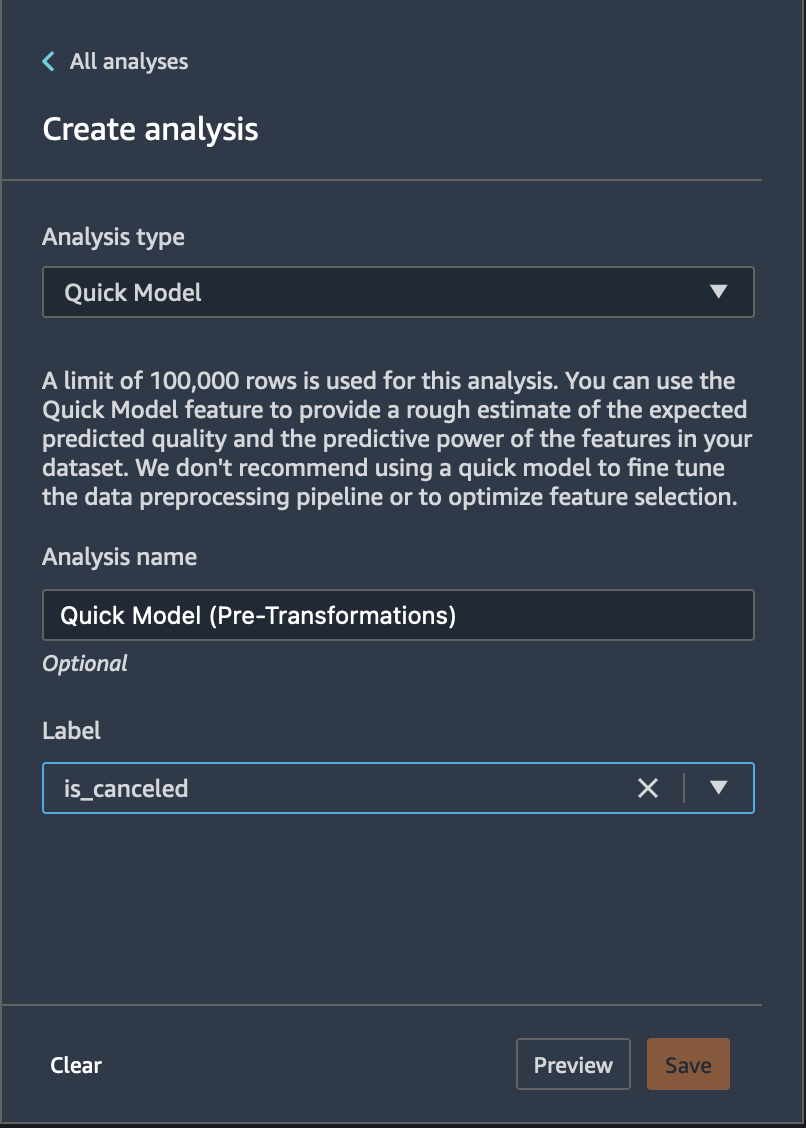
+
+A limit of 100,000 rows is used for this analysis. You can use the Quick Model feature to provide a rough estimate of the expected predicted quality and the predictive power of the features in your dataset.
+
+We can from the results below, Quick model was able to predict with an F1 score of 82% on the test set. But, this is misleading, given we haven't eliminated most of the feature columns that are a target leakage or redundant based on high colinearity. This is justified in the results below where the column `reservation_status` which is a target leakage ranked as the most important feature.
+
+
+
+
+Select **Save** to save the model.
+
+### Next Steps
+
+In the next section, we will apply post analysis transformations to fix the data of the various colinearity and other issues and re-generate a quick model and compare the differences. Please refer to **[Data Transformations](./Data-Transformations.md)** and follow steps for Data Transformation.
+
diff --git a/sagemaker-datawrangler/tabular-dataflow/data-exploration/index.rst b/sagemaker-datawrangler/tabular-dataflow/data-exploration/index.rst
new file mode 100644
index 0000000000..e3dc6e001d
--- /dev/null
+++ b/sagemaker-datawrangler/tabular-dataflow/data-exploration/index.rst
@@ -0,0 +1,408 @@
+Exploratory Data Analysis
+=========================
+
+Analyze and Visualize
+---------------------
+
+Before we transform our raw features to make it ML ready for model
+building, lets analyze and visualize the booking cancellations dataset
+to detect features that are important to our problem and ones that are
+not. This can be achieved through Exploratory Data Analysis (EDA).
+Amazon SageMaker Data Wrangler includes built-in analyses that help you
+generate visualizations and data analyses in a few clicks. You can also
+create custom analyses using your own code.
+
+In order to apply an action on the imported data, select the **Add
+Analysis** option on right clicking the the **Data Types** block. As
+depicted in the figure below, you can see options to add a transform,
+perform an analysis, add a destination sink or export the steps as
+Jupyter notebook. You can also join and concatenate on the imported
+dataset with other datasets.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/image-8.png
+
+
+
+
+On selecting Add Analysis, the Analysis pane os shown, where you can
+choose the analysis you want to perform.
+
+All analyses are generated using 100,000 rows of your dataset.
+
+You can add the following analysis to a dataframe:
+
+- Data visualizations, including histograms and scatter plots.
+- A quick summary of your dataset, including number of entries, minimum
+ and maximum values (for numeric data), and most and least frequent
+ categories (for categorical data).
+- A quick model of the dataset, which can be used to generate an
+ importance score for each feature.
+- A target leakage report, which you can use to determine if one or
+ more features are strongly correlated with your target feature.
+- A custom visualization using your own code.
+
+Following sections showcase few of the analysis techniques for the
+Hotel-bookings data.
+
+Get Insights
+------------
+
+You can get the Data Insights report by selecting **Get Insights**
+option for the **Data Types** block as shown in the figure.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/get-insights.png
+
+
+
+
+| Please select the following parameters and hit **Create**.
+| - ``Target column``: ``is-cancelled`` - ``Problem type``:
+ ``Classification``
+
+After the report is generated, it outlines findings about statistics,
+duplicate rows, warnings, confusion matrix and feature summary. This can
+be a useful report before we start our detailed analysis.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/get-insights-report.png
+
+
+
+Table Summary
+-------------
+
+Select **Table Summary** Analysis in the **Add Analysis** window.
+
+| Please select the following parameters and hit **Preview**.
+| - ``Analysis name``: ``Table Summary``
+
+Overall details of the data for various columsn is displayed as depicted
+in figure below.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/table-information.png
+
+
+
+Select **Save** to save the analysis.
+
+Target Leakage
+--------------
+
+Target leakage occurs when there is data in a machine learning training
+dataset that is strongly correlated with the target label, but is not
+available in real-world data. For example, you may have a column in your
+dataset that serves as a proxy for the column you want to predict with
+your model.
+
+When you use the Target Leakage analysis, you specify the following: \*
+**Target**: This is the feature about which you want your ML model to be
+able to make predictions. \* **Problem type**: This is the ML problem
+type on which you are working. Problem type can either be classification
+or regression. \* (Optional) **Max features**: This is the maximum
+number of features to present in the visualization, which shows features
+ranked by their risk of being target leakage.
+
+For classification, the target leakage analysis uses the area under the
+receiver operating characteristic, or AUC - ROC curve for each column,
+up to Max features. For regression, it uses a coefficient of
+determination, or R2 metric.
+
+The AUC - ROC curve provides a predictive metric, computed individually
+for each column using cross-validation, on a sample of up to around 1000
+rows. A score of 1 indicates perfect predictive abilities, which often
+indicates target leakage. A score of 0.5 or lower indicates that the
+information on the column could not provide, on its own, any useful
+information towards predicting the target. Although it can happen that a
+column is uninformative on its own but is useful in predicting the
+target when used in tandem with other features, a low score could
+indicate the feature is redundant.
+
+| To create a target leakage analysis, Select **Target Leakage**
+ Analysis in the **Add Analysis** window. Please select the following
+ parameters and hit **Preview**.
+| - ``Analysis name``: ``Target Leakage`` - ``Max features`` : ``40`` -
+ ``Target column``: ``is-cancelled`` - ``Problem type``:
+ ``Classification``
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/target-leakage-pre.png
+
+
+ image
+
+For our example dataset, the image below shows a target leakage report
+for a hotel booking cancellation problem, that is, predicting if a
+person will cancel his hotel reservation or not. An AUC - ROC curve is
+used to calculate the predictive ability of 31 raw features, out of
+which ``reservation_status`` was determined to a target leakage. Also,
+features - ``arrival_day_of_month``, ``babies``,
+``reservation_status_date``, ``arrival_date_month``,
+``reserved_room_type``, ``hotel`` and ``days_in_waiting_list`` were
+identified as redundant.
+
+The identified features can be fairly omitted as part of the
+transformations we will apply post this initial analysis.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/target-leakage.png
+
+
+Select **Save** to save the analysis.
+
+Next, with SageMaker Data Wrangler’s feature correlation visualization
+you can easily calculate the correlation of features in your data set
+and visualize them as a correlation matrix. We will look into 2 types of
+feature correlations and how to use them on our example dataset in hand.
+
+Feature Correlation (Linear)
+----------------------------
+
+Linear feature correlation is based on Pearson’s correlation. Numeric to
+categorical correlation is calculated by encoding the categorical
+features as the floating point numbers that best predict the numeric
+feature before calculating Pearson’s correlation. Linear categorical to
+categorical correlation is not supported.
+
+| Numeric to numeric correlation is in the range [-1, 1] where 0 implies
+ no correlation, 1 implies perfect correlation and -1 implies perfect
+ inverse correlation. Numeric to categorical and categorical to
+ categrical correlations are in the range [0, 1] where 0 implies no
+ correlation and 1 implies perfect correlation. To create the analysis,
+ choose **Feature Correlation** for the Analysis type and choose
+ **linear** for Correlation type. Please select the following
+ parameters and hit **Preview**.
+| - ``Analysis name``: ``Linear Correlation``
+
+This analysis will take a few minutes to complete.
+
+Features that are not either numeric or categorical are ignored. The
+table below lists for each feature what is the most correlated feature
+to it.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/linear-pre.png
+
+Based on the correlation values, we can see the top 6 feature pairs (as
+listed below) are strongly correlating with one another. Also, some of
+these features also showed up in the target analysis we did previously.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/linear-strongly-correlated.png
+
+
+P.S.: A limit of 100,000 rows is used for this analysis.
+
+Select **Save** to save the analysis.
+
+Feature Correlation (Non-Linear)
+--------------------------------
+
+Non-linear feature correlation is based on Spearman’s rank correlation.
+Numeric to categorical correlation is calculated by encoding the
+categorical features as the floating point numbers that best predict the
+numeric feature before calculating Spearman’s rank correlation.
+Categorical to categorical correlation is based on the normalized
+Cramer’s V test.
+
+Numeric to numeric correlation is in the range [-1, 1] where 0 implies
+no correlation, 1 implies perfect correlation and -1 implies perfect
+inverse correlation. Numeric to categorical and categorical to
+categrical correlations are in the range [0, 1] where 0 implies no
+correlation and 1 implies perfect correlation
+
+Features that are not either numeric or categorical are ignored.
+
+| To create the analysis, choose **Feature Correlation** for the
+ Analysis type and **non-linear** for Correlation type. Please select
+ the following parameters and hit **Preview**.
+| - ``Analysis name``: ``Non-Linear Correlation``
+
+This analysis will take a few minutes to complete.
+
+The table below lists for each feature what is the most correlated
+feature to it. You can see most of the top correlated feature pairs
+overlap with the previous two analyses.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/non-linear-pre.png
+
+
+Select **Save** to save the analysis.
+
+Multicolinearity (Variance Inflation Factors)
+---------------------------------------------
+
+Variance Inflation Factor (VIF) is a measure of colinearity among
+variables. It is calculated by solving a regression problem to predict
+one variable given the rest. A VIF score is a positive number that is
+greater or equal than 1, and a score of 1 means the variable is
+completely independent of the others. The larger the score, the more
+dependent it is. Since it is an inverse, it is possible for the VIF
+score to be infinite. Note that we cap the VIF score at 50. As a rule of
+thumb for cases where the number of samples is not abnormally small, a
+score of up to 5 means the variable is only moderatly correlated, and
+beyond 5 it is highly correlated.
+
+| To create the analysis for VIF, choose **Multicollinearity** for
+ Analysis type and choose **Variance inflation factors** for Analysis.
+ Please select the following parameters and hit **Preview**.
+| - ``Analysis name``: ``Variance Inflation Factors``
+
+This analysis will take a few minutes to complete.
+
+As per the above rule, we can eliminate the following feature columns
+from our feature set since they will not contribute effectively towards
+the prediction capability of the model that gets trained using these
+features.
+
+- ``arrival_date_year``
+- ``adults``, ``agents``
+- ``arrival_date_week_number``
+- ``stays_in_week_nights``
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/vif-pre.png
+
+
+Select **Save** to save the analysis.
+
+Multicolinearity - Principal Component Analysis (PCA)
+-----------------------------------------------------
+
+Principal Component Analysis (PCA) measures the variance of the data
+along different directions in the feature space. The ordered list of
+variances, also known as the singular values, can inform about
+multicolinearity in our data. This list contains non-negative numbers.
+When the numbers are roughly uniform, the data has very few
+multicolinearities. However, when the opposite is true, the magnitude of
+the top values will dominate the rest. In order to avoid issues related
+to different scales, the individual features are standardized to have
+mean 0 and standard deviation 1 before applying PCA.
+
+| To create the analysis for PCA, choose **Multicollinearity** for
+ Analysis type and choose **Principal component analysis** for
+ Analysis. Please select the following parameters and hit **Preview**.
+| - ``Analysis name``: ``Principal Component Analysis``
+
+This analysis will take a few minutes to complete.
+
+As per the above rule, it is evident the numbers (variances) are not
+uniform hence confirming that the data has multicolinearies to fix. This
+has already been confirmed by our previous analysis.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/pca-pre.png
+
+Select **Save** to save the analysis.
+
+Multicolinearity Lasso Feature Selection
+----------------------------------------
+
+Lasso feature selection trains a linear classifier with L1
+regularization (you can control the strength of L1 penalty by adjusting
+“L1 magnitude”) that induces a sparse solution. The regressor provides a
+coefficient for each feature, and the absolute value of this coefficient
+could be interpreted as an importance score for that feature.
+
+| To create the analysis for Lasso Feature Selection, choose
+ **Multicollinearity** for Analysis type and choose **Lasso feature
+ selection** for Analysis. Please select the following parameters and
+ hit **Preview**.
+| - ``Analysis name``: ``Non-Linear Correlation`` - ``L1 Magnitude``:
+ ``1`` - ``Problem Type``: ``Classification`` - ``Label Column`` :
+ ``is_cancelled``
+
+This analysis will take a few minutes to complete.
+
+The plot below provides features’ importance scores (absolute
+coefficients) after training a classifier on a sample of the dataset
+(10k for large dataset). The training process includes a standardization
+of the features to have mean 0 and standard deviation 1 in order to
+avoid a skewed importance score due to different scales.
+
+The classifier obtained a roc_auc score: ``0.639269142214666``.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/lasso-pre.png
+
+
+Select **Save** to save the analysis.
+
+Detect Duplicate Rows
+---------------------
+
+Next, with the new duplicate row detection visualization, you can
+quickly detect if your data set has any duplicate rows. To apply this
+analysis, choose **Duplicate rows** for Analysis type.
+
+From the figure bwlow, we can see almost ~33% of the rows in the dataset
+are duplicates.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/duplicate-rows.png
+
+
+Quick Model
+-----------
+
+We can create a quick model using the raw features to determine how good
+our features are, prior to applying transformations.
+
+Use the Quick Model visualization to quickly evaluate your data and
+produce importance scores for each feature. A feature importance score
+indicates how useful a feature is at predicting a target label. The
+feature importance score is between [0, 1] and a higher number indicates
+that the feature is more important to the whole dataset. On the top of
+the quick model chart, there is a model score. A classification problem
+shows an F1 score. A regression problem has a mean squared error (MSE)
+score.
+
+When you create a quick model chart, you select a dataset you want
+evaluated, and a target label against which you want feature importance
+to be compared. Data Wrangler does the following: \* Infers the data
+types for the target label and each feature in the dataset selected. \*
+Determines the problem type. Based on the number of distinct values in
+the label column, Data Wrangler determines if this is a regression or
+classification problem type. Data Wrangler sets a categorical threshold
+to 100. If there are more than 100 distinct values in the label column,
+Data Wrangler classifies it as a regression problem; otherwise, it is
+classified as a classification problem. \* Pre-processes features and
+label data for training. The algorithm used requires encoding features
+to vector type and encoding labels to double type. \* Trains a random
+forest algorithm with 70% of data. Spark’s RandomForestRegressor is used
+to train a model for regression problems. The RandomForestClassifier is
+used to train a model for classification problems. \* Evaluates a random
+forest model with the remaining 30% of data. Data Wrangler evaluates
+classification models using an F1 score and evaluates regression models
+using an MSE (mean squared error) score. \* Calculates feature
+importance for each feature using the Gini importance method.
+
+Let us create a prediction model on the fly for the problem for the
+booking cancellation problem using the raw crude features we started
+with in Data Wrangler’s Quick Model option.
+
+| Please choose **Quick Model** for Analysis type. Select the following
+ parameters and hit **Preview**.
+| - ``Analysis name``: ``Model pre-transform``
+
+This analysis will take a few minutes to complete.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/create-quick-model.png
+
+
+
+
+A limit of 100,000 rows is used for this analysis. You can use the Quick
+Model feature to provide a rough estimate of the expected predicted
+quality and the predictive power of the features in your dataset.
+
+We can from the results below, Quick model was able to predict with an
+F1 score of 82% on the test set. But, this is misleading, given we
+haven’t eliminated most of the feature columns that are a target leakage
+or redundant based on high colinearity. This is justified in the results
+below where the column ``reservation_status`` which is a target leakage
+ranked as the most important feature.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/quick-model-pre.png
+
+
+
+
+Select **Save** to save the model.
+
+Next Steps
+----------
+.. toctree::
+ :maxdepth: 1
+
+ ./data-transdormations/index
diff --git a/sagemaker-datawrangler/tabular-dataflow/data-import/Data-Import.md b/sagemaker-datawrangler/tabular-dataflow/data-import/Data-Import.md
new file mode 100644
index 0000000000..a71a73153d
--- /dev/null
+++ b/sagemaker-datawrangler/tabular-dataflow/data-import/Data-Import.md
@@ -0,0 +1,49 @@
+# Importing Dataset into Data Wrangler using SageMaker Studio
+
+Following steps outline how to import data into Sagemaker to be consumed by Data Wrangler
+
+
+
Steps to import data
+1. Initialize SageMaker Data Wrangler via SageMaker Studio UI. You can use any one of the options specified below.
+
+
+
+ -
Option 1. Use the Sage Maker Launcher screen as depicted here:
+
+ 
+
+ -
Option 2. You can use the SageMaker resources menu on the left, selecting Data Wrangler, and new flow
+
+ 
+ 
+ -
Option 3. You can also use the File -> New -> DataWrangler option as shown here
+
+ 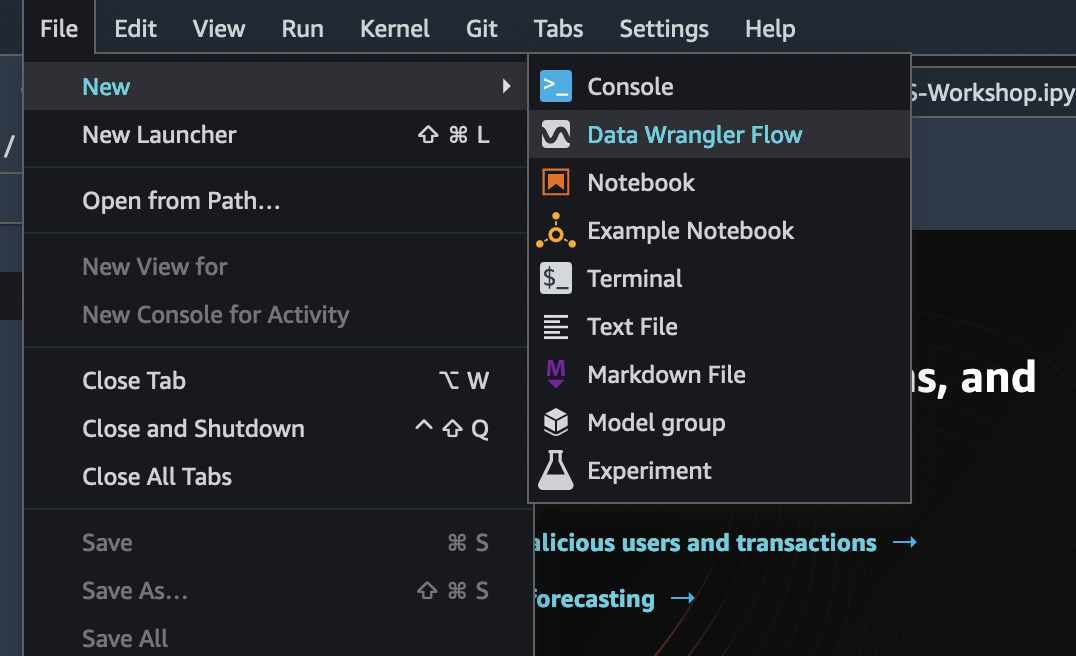
+2. Data Wrangler takes a few minutes to load.
+
+
+3. Once Data Wrangler is loaded, you should be able to see it under running instances and apps as shown below.
+
+
+
+4. Once Data Wrangler is up and running, you can see the following data flow interface with options for import, creating data flows and export as shown below.
+
+
+
+5. Make sure to rename the untitled.flow to your preference (for e.g., hotel-bookings.flow)
+
+6. Now you will have the option to select your data source. Because the data is in Amazon S3, select Amazon S3 to import data. Paste the S3 URL for the hotel-bookings.csv file into the search box below and hit go.
+
+
+
+7. Data Wrangler will show you a preview of the data. Select the CSV file from the drop down results. On the right pane, make sure COMMA is chosen as the delimiter and Sampling is *None*. Our data set is small enough to run Data Wrangler transformations on the full data set. If you have a large data set, consider using sampling. Finally select *Import* to import this dataset to Data Wrangler.
+
+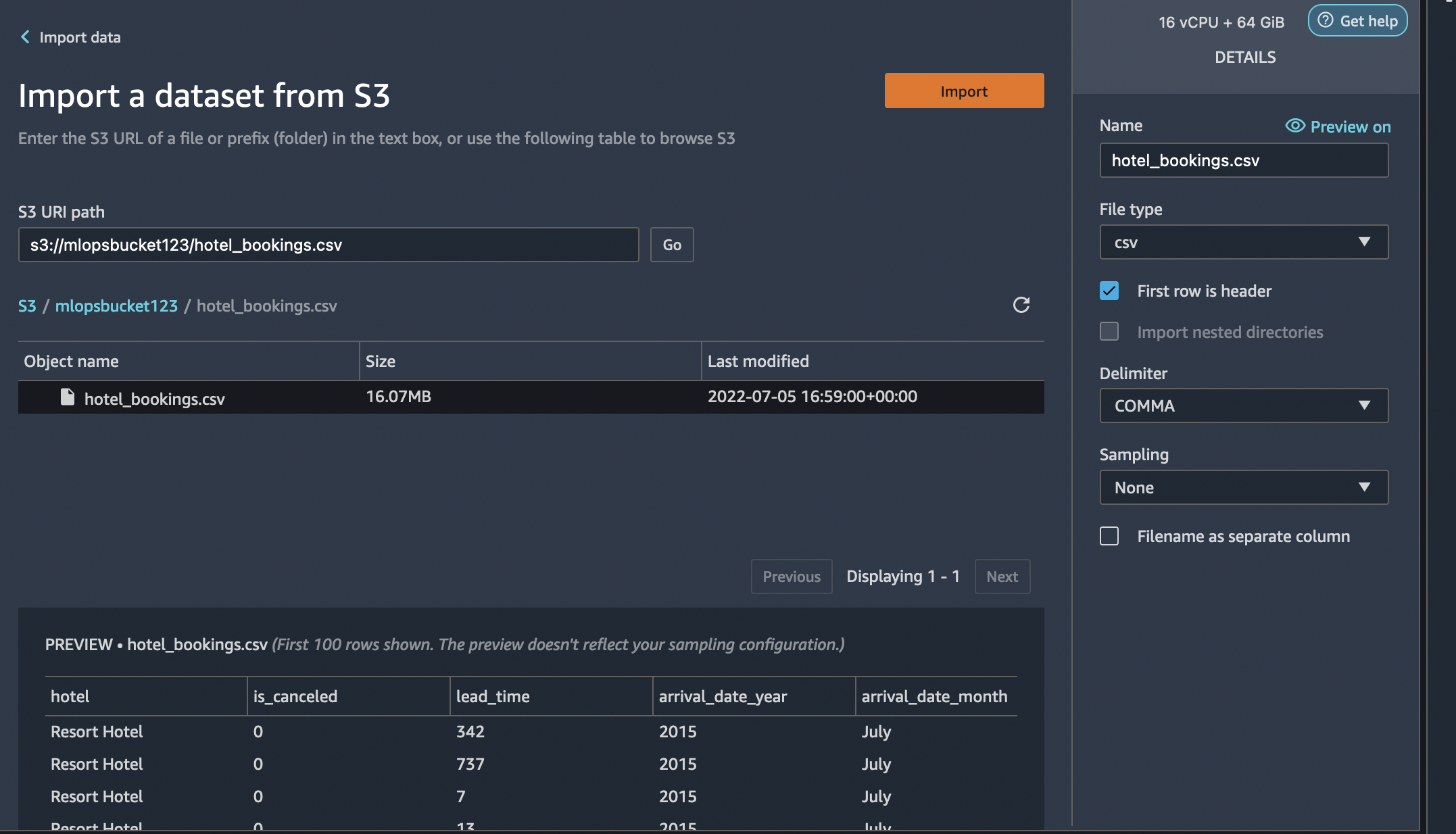
+
+8. Once the dataset is imported, Data Wrangler automatically validates the dataset and detects the data types. The flow editor now shows 2 blocks showcasing that the data was imported from a source and data types recognized. You are also allowed to edit the data types if needed.
+
+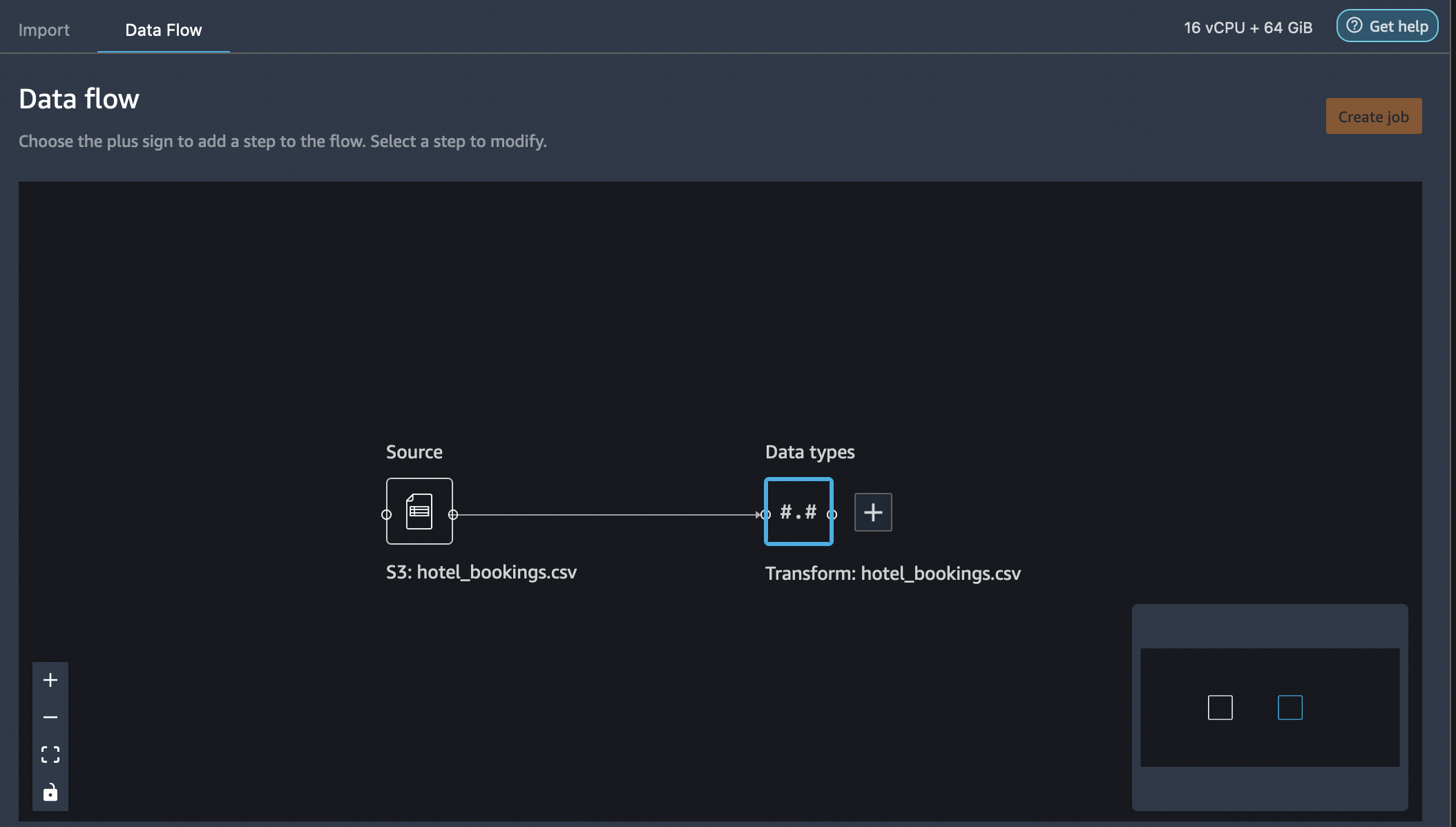
+
+### Next Steps
+
+As a next step, we will explore the data that we uploaded. Please refer to **[Exploratory Data Analysis](./Data-Exploration.md)** and follow steps for Data exploration.
diff --git a/sagemaker-datawrangler/tabular-dataflow/data-import/index.rst b/sagemaker-datawrangler/tabular-dataflow/data-import/index.rst
new file mode 100644
index 0000000000..76ce7141f4
--- /dev/null
+++ b/sagemaker-datawrangler/tabular-dataflow/data-import/index.rst
@@ -0,0 +1,87 @@
+Importing Dataset into Data Wrangler using SageMaker Studio
+===========================================================
+
+Following steps outline how to import data into Sagemaker to be consumed
+by Data Wrangler
+
+| Steps to import data
+| 1. Initialize SageMaker Data Wrangler via SageMaker Studio UI. You can
+ use any one of the options specified below.
+
+
+
+Option 1 : Use the Sage Maker Launcher screen
+--------------------------------------------
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/image-1.png
+
+
+Option 2 : You can use the SageMaker resources menu on the left, selecting Data Wrangler, and new flow
+----------------------------------------------------------------------------
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/image-1-1.png
+
+
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/image-1-2.png
+
+
+Option 3. : You can also use the File -> New -> DataWrangler option as shown here
+--------------------------------------------------------------------------------
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/image-1-3.png
+
+
+2. Data Wrangler takes a few minutes to load.
+
+|image|
+
+3. Once Data Wrangler is loaded, you should be able to see it
+under running instances and apps as shown below.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/image-3.png
+
+
+4. Once Data Wrangler is up and running, you can see the following data
+ flow interface with options for import, creating data flows and
+ export as shown below.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/image-4.png
+
+
+5. Make sure to rename the untitled.flow to your preference (for e.g.,
+ hotel-bookings.flow)
+
+6. Now you will have the option to select your data source. Because the
+ data is in Amazon S3, select Amazon S3 to import data. Paste the S3
+ URL for the hotel-bookings.csv file into the search box below and hit
+ go.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/image-5.png
+
+
+7. Data Wrangler will show you a preview of the data. Select the CSV
+ file from the drop down results. On the right pane, make sure COMMA
+ is chosen as the delimiter and Sampling is *None*. Our data set is
+ small enough to run Data Wrangler transformations on the full data
+ set. If you have a large data set, consider using sampling. Finally
+ select *Import* to import this dataset to Data Wrangler.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/image-6.png
+
+
+8. Once the dataset is imported, Data Wrangler automatically validates
+ the dataset and detects the data types. The flow editor now shows 2
+ blocks showcasing that the data was imported from a source and data
+ types recognized. You are also allowed to edit the data types if
+ needed.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/image-7.png
+
+
+Next Steps
+----------
+.. toctree::
+ :maxdepth: 1
+
+ ./data-exploration/index
+
diff --git a/sagemaker-datawrangler/tabular-dataflow/data-transformations/Data-Transformations.md b/sagemaker-datawrangler/tabular-dataflow/data-transformations/Data-Transformations.md
new file mode 100644
index 0000000000..d2a782f538
--- /dev/null
+++ b/sagemaker-datawrangler/tabular-dataflow/data-transformations/Data-Transformations.md
@@ -0,0 +1,195 @@
+# Data Transformations
+
+
+Based on the Data explorations carried out in previous step, we are now ready to apply transformations to the data.
+Amazon SageMaker Data Wrangler provides numerous ML data transforms to streamline cleaning, transforming, and featurizing your data. When you add a transform, it adds a step to the data flow. Each transform you add modifies your dataset and produces a new dataframe. All subsequent transforms apply to the resulting dataframe.
+
+Data Wrangler includes built-in transforms, which you can use to transform columns without any code. You can also add custom transformations using PySpark, Pandas, and PySpark SQL. Some transforms operate in place, while others create a new output column in your dataset.
+
+In order to apply an action on the imported data, select the **Add Transform** option on right clicking the the **Data Types** block. In the displayed window, select **Add Steps** to display **Add Transform** window.
+
+ 
+
+
+
+### Drop Columns
+ Now we will drop columns based on the analyses we performed in the previous section.
+
+- based on target leakage : drop `reservation_status`
+
+- redundant columns : drop columns that are redundant - `days_in_waiting_list`, `hotel`, `reserved_room_type`, `arrival_date_month`, `reservation_status_date`, `babies` and `arrival_date_day_of_month`
+
+- based on linear correlation results : drop columns `arrival_date_week_number`, `arrival_date_year` as correlation values for these feature (column) pairs are greater than the recommended threshold of 0.90.
+
+- based on non-linear correlation results: drop `reservation_status`. This column was already marked to be dropped based on Target leakage analysis.
+
+ we can drop all these columns in one go. To drop columns, choose **Manage columns** transform from the **Add Transform** window. Then select the **Drop column** option from **Manage columns** transform.
+
+Please select the the column names we want to drop as shown in the image below and hit **Preview**.
+
+
+ 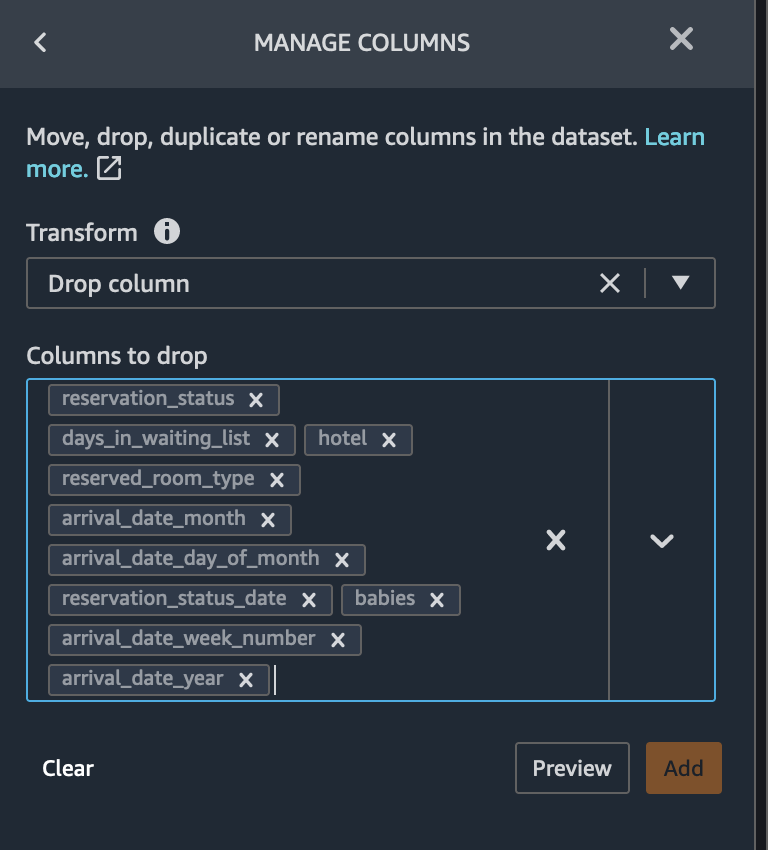
+
+If the Preview is OK, click **Add** to add the transform in the data flow.
+
+Further, based on the multi-colinearity analysis results, we can also drop the columns `adults` and `agent` for whom the variance inflation factor scores are greater than 5. Please select the the column names we want to drop and hit **Preview**.
+
+
+
+ 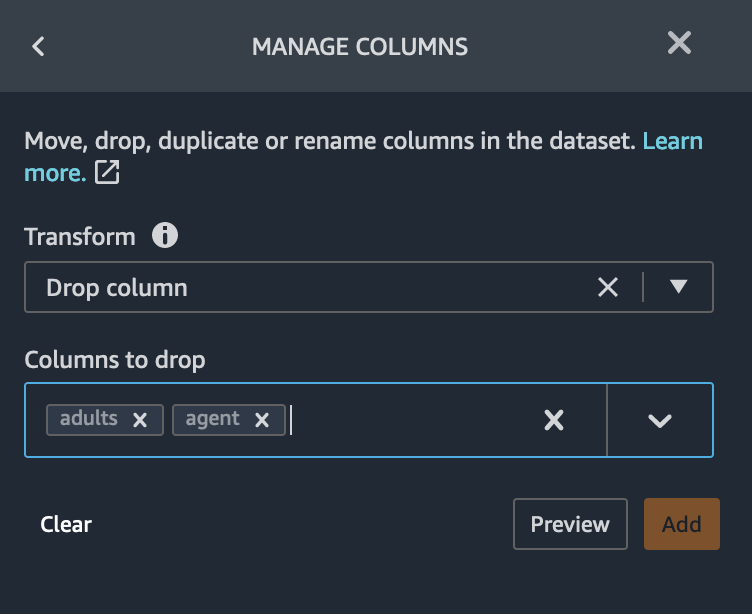
+
+ If the Preview is OK, click **Add** to add the transform in the data flow.
+
+
+### Drop Duplicate Rows
+To drop the duplicate rows that we identified based on the analysis we did in the previous section. To drop columns, choose **Manage rows** transform from the **Add Transform** window. Then select the **Drop duplicates** option from **Manage rows** transform and hit **Preview**.
+
+
+ 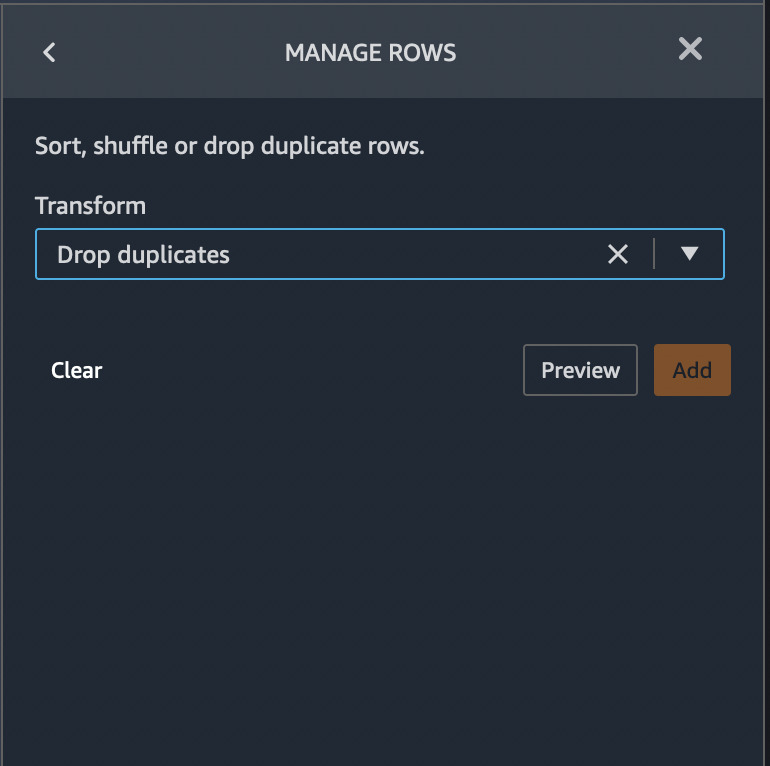
+
+ If the Preview is OK, click **Add** to add the transform in the data flow.
+
+
+### Handle Outliers
+An outlier can cause serious problems in statistical analysis. Machine learning models are sensitive to the distribution and range of feature values. Outliers, or rare values, can negatively impact model accuracy and lead to longer training times. When you define a Handle outliers transform step, the statistics used to detect outliers are generated on the data available in Data Wrangler when defining this step. These same statistics are used when running a Data Wrangler job.
+
+To handle outliers, choose **Handle outliers** transform from the **Add Transform** window.
+Please select the following parameters and hit **Preview**.
+
+- `Transform`: `Standard deviation numeric outliers`
+- `Fix method` : `Remove`
+- `Standard deviations`: `4`
+- `Input columns`: `lead_time`,`stays_in_weekend_nights`, `stays_in_weekday_nights`, `is_repeated_guest`, `prev_cancellations`, `prev_bookings_not_canceled`, `booking_changes`, `adr`, `total_of_specical_requests`, `required_car_parking_spaces`,
+
+
+
+
+
+
+ If the Preview is OK, click **Add** to add the transform in the data flow.
+
+
+### Handle Missing Values
+To handle outliers, choose **Handle missing values** transform from the **Add Transform** window. We can do the following to handle missing values in our feature columns using Data Wrangler.
+
+
+ - Missing values in **Children** column : Majority of the visitors were not accompanied by children and hence missing data can be replaced by number of children = 0.
+
+
+
+ Please hit **Preview** to look at the transform preview, and if it is OK, click **Add** to add the transform in the data flow.
+
+- Missing values in **Country** column
+Iterating through the country column reveals that most of the clients are from Europe. Therefore, all the missing values in the country column are replaced with the country of maximum occurrence - Portugal (PRT). Fill missing country column with `PRT` based on value counts
+
+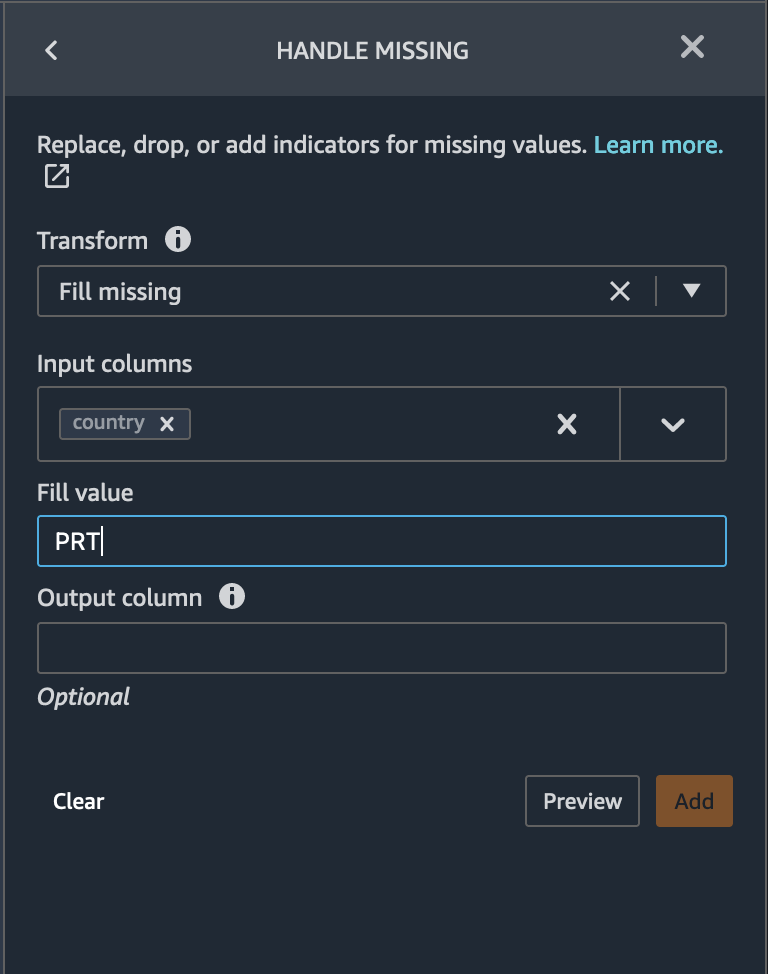
+
+Please hit **Preview** to look at the transform preview, and if it is OK, click **Add** to add the transform in the data flow.
+
+- Custom Transform - Meal type has Undefined category, changing the Undefined value to the most used which is BB by implementing a custom pyspark transform with two simple lines of code. This can be done by choosing **Custom transform** transform from the **Add Transform** window. Specify the name of the transform, and paste following code in the transform as shown in figure below.
+
+ 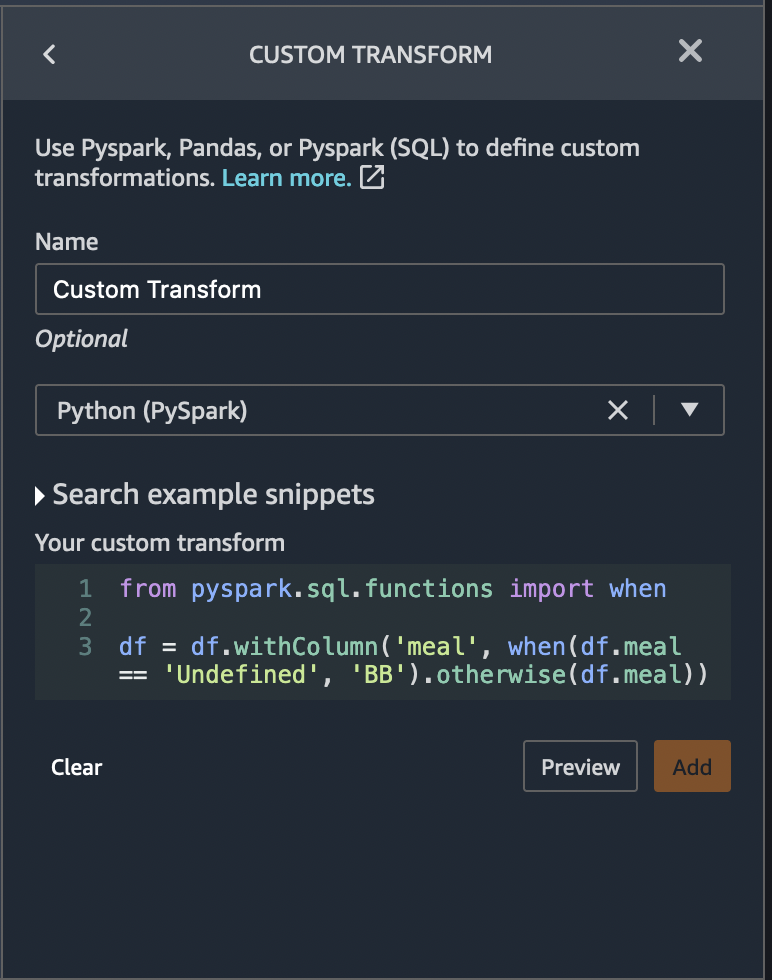
+
+
+```python
+from pyspark.sql.functions import when
+
+df = df.withColumn('meal', when(df.meal == 'Undefined', 'BB').otherwise(df.meal))
+```
+
+Please hit **Preview** to look at the transform preview, and if it is OK, click **Add** to add the transform in the data flow.
+
+ ### Numeric Normalization
+Normalization is a scaling technique in which values are shifted and rescaled so that they end up ranging between 0 and 1. It is also known as Min-Max scaling. Standardization is another scaling technique where the values are centered around the mean with a unit standard deviation. This means that the mean of the attribute becomes zero and the resultant distribution has a unit standard deviation.
+
+For our example use case, let's normalize the numeric feature columns to a standard scale [0,1].
+
+From Data Wrangler's list of pre-built transforms, choose **Process numeric**. Please select the following parameters and hit **Preview**.
+
+- `Transform`: `Scale values`
+- `Scalar` : `Min-max scalar`
+- `Min`: `0`
+- `Max`: `1`
+- `Input columns`: `lead_time`,`stays_in_weekend_nights`, `stays_in_weekday_nights`, `is_repeated_guest`, `prev_cancellations`, `prev_bookings_not_canceled`, `booking_changes`, `adr`, `total_of_specical_requests`, `required_car_parking_spaces`
+
+
+ 
+
+
+ If the Preview is OK, click **Add** to add the transform in the data flow.
+
+### Handle Categorical Data
+
+Categorical data is usually composed of a finite number of categories, where each category is represented with a string. Encoding categorical data is the process of creating a numerical representation for categories. With Data Wrangler, we can select Ordinal encode to encode categories into an integer between 0 and the total number of categories in the Input column you select. Select one-hot encoding or use similarity encoding when you have a large number of categorical variables and Noisy data.
+
+
+From Data Wrangler's list of pre-built transforms, choose **Encode Categorical**. Please select the following parameters and hit **Preview**.
+- `Transform`: `One-hot encode`
+- `Invalid handling strategy` : `Keep`
+- `Output style`: `Columns`
+- `Max`: `1`
+- `Input columns`: `meal`, `is_repeated_guest`, `market_segment`, `assigned_room_type`, `deposit_type`, `customer_type`
+
+
+
+ 
+
+
+ If the Preview is OK, click **Add** to add the transform in the data flow.
+
+
+### Balancing the target variable
+
+DataWrangler also helps to balance the target variable (column) for class imbalance. Let's presume the following for the negative and positive cases.
+
+ is_canceled = 0 (negative case)
+ is_canceled = 1 (positive case)
+
+In Data Wrangler, we can handle class imbalance using 3 different techniques.
+
+ - Random Undersample
+ - Random Oversample
+ - SMOTE
+
+From the Data Wrangler's transform pane, choose **Balance Data** as the transform. Please select the following parameters as shown in image below and hit **Preview**.
+- `Target column`: `is_canceled`
+- `Desiered ratio` : `1`
+- `Transform`: `Random oversample`
+
+ 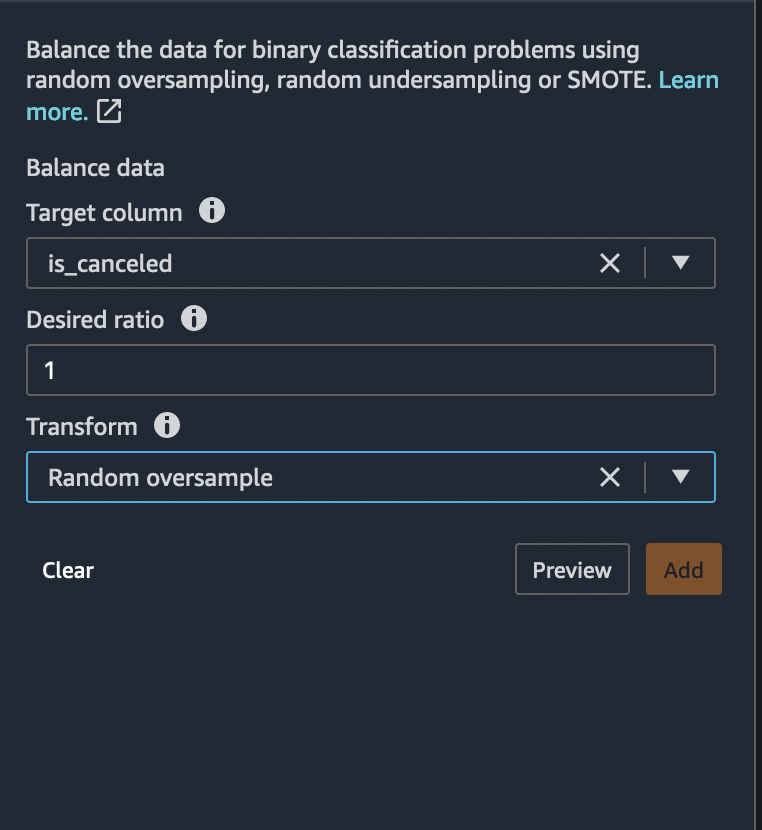
+
+
+ If the Preview is OK, click **Add** to add the transform in the data flow.
+
+The state of the classes before and after balancing is as follows:
+
+The ratio of positive to negative case = ~0.38
+
+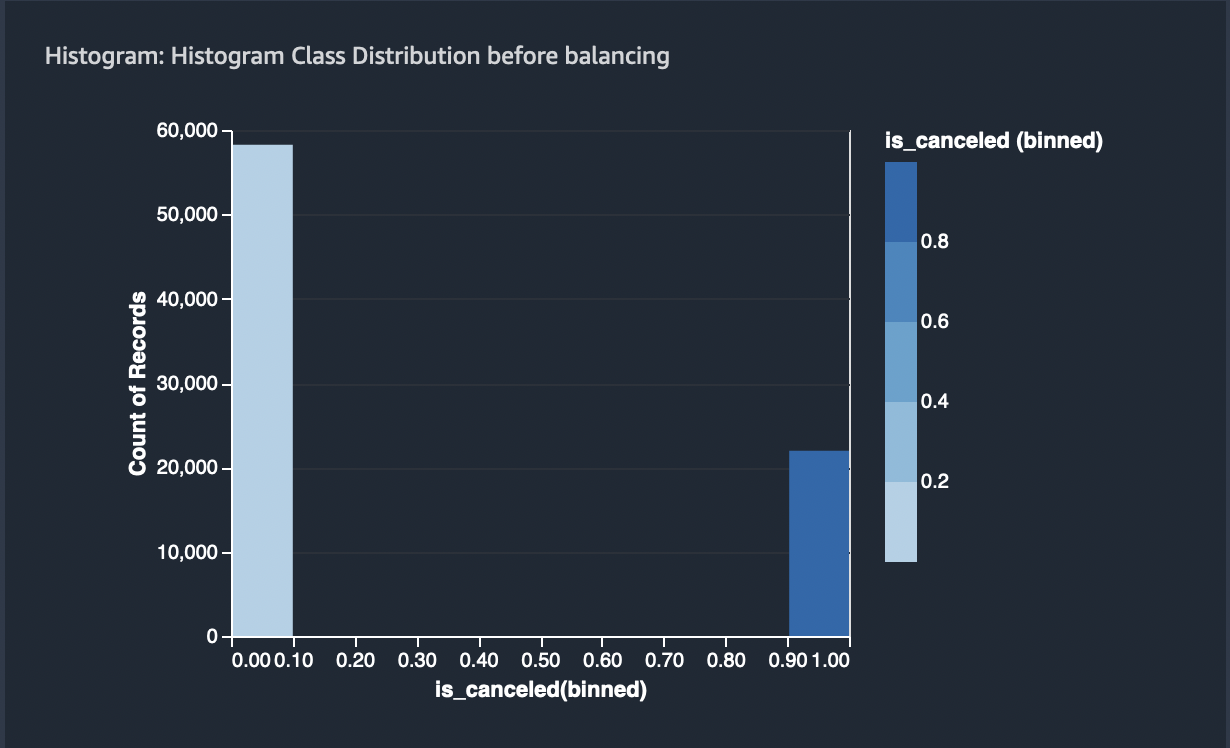
+
+
+After balancing, the ratio is 1
+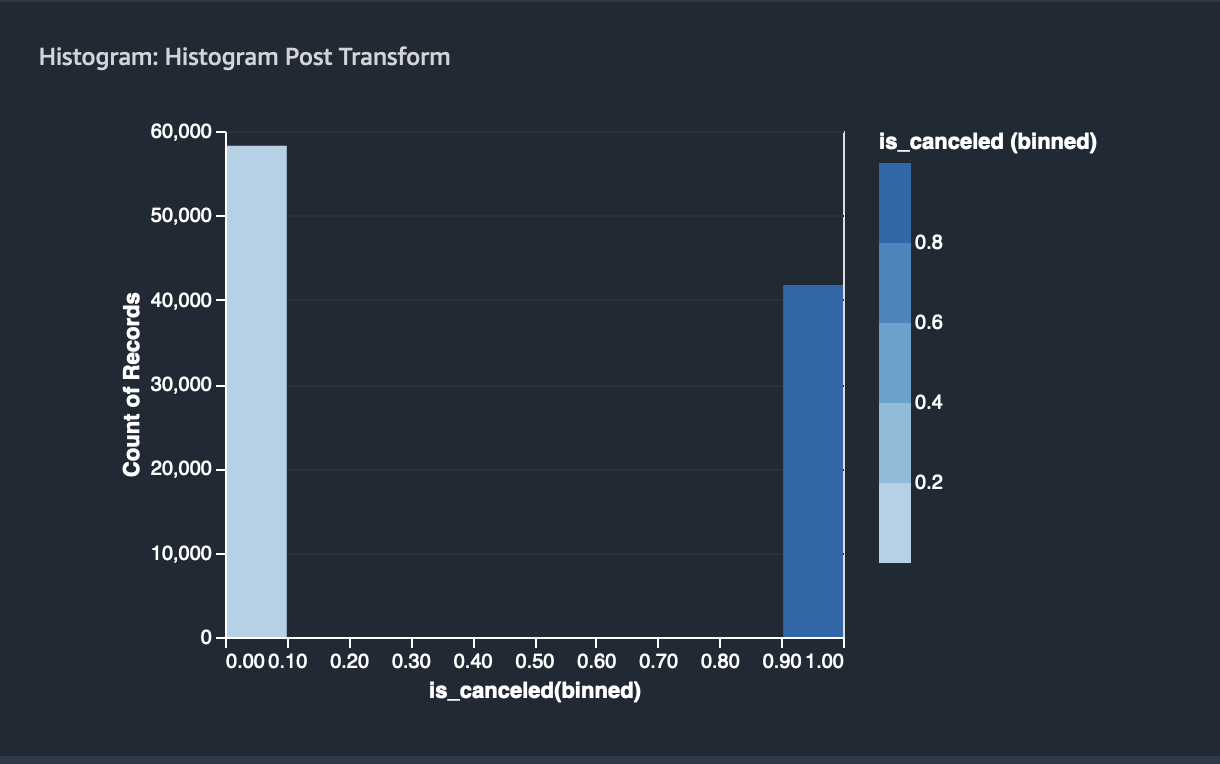
+
+### Quick Model
+Given, we have applied most of the needed transformations on our feature columns, we can now create a Quick Model again using the transformed features to identify the predictive ability of our features and take a look at their attribution towards prediction.
+
+It is a good practice to run a Quick Model everytime we make a set of feature transforms. Previously, we ran a Quick Model analysis using the raw features. The results of this previous run was mostly incorrect and misleading, given, we haven't fixed most of the correlation and other issues with our dataset.
+
+The below figure shows the results of the newly run Quick Model created using the transformed features. As you can see, the Quick Model achieved an F1 score of 62% on the test data. The top 5 most contributing features towards this score are as follows which is different from what we see previously.
+
+ lead_time
+ country
+ customer_type_Transient
+ required_car_parking_spaces
+ booking_changes
+
+Craete a quick model, similar to one we created in the **[Exploratory Data Analysis](./Data-Exploration.md)** step.
+
+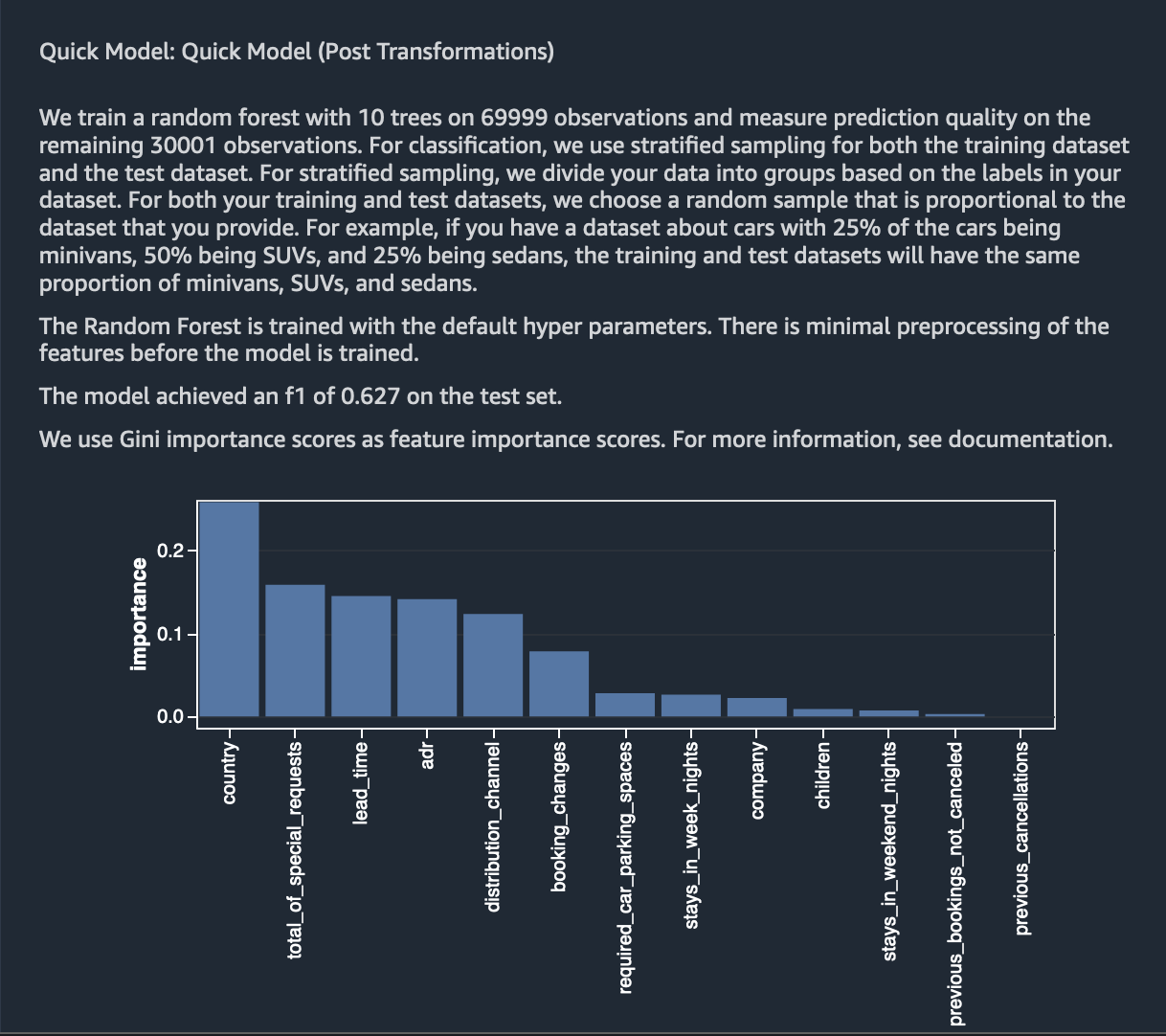
+
+Compare the model with the one created in Exploratory Data Analysis step.
+
+### Next Steps
+
+As a next step, we will export the transformed data for further use. Please refer to **[Readme](./README.md)** and follow steps for Data Export.
diff --git a/sagemaker-datawrangler/tabular-dataflow/data-transformations/index.rst b/sagemaker-datawrangler/tabular-dataflow/data-transformations/index.rst
new file mode 100644
index 0000000000..942304a959
--- /dev/null
+++ b/sagemaker-datawrangler/tabular-dataflow/data-transformations/index.rst
@@ -0,0 +1,301 @@
+Data Transformations
+====================
+
+Based on the Data explorations carried out in previous step, we are now
+ready to apply transformations to the data. Amazon SageMaker Data
+Wrangler provides numerous ML data transforms to streamline cleaning,
+transforming, and featurizing your data. When you add a transform, it
+adds a step to the data flow. Each transform you add modifies your
+dataset and produces a new dataframe. All subsequent transforms apply to
+the resulting dataframe.
+
+Data Wrangler includes built-in transforms, which you can use to
+transform columns without any code. You can also add custom
+transformations using PySpark, Pandas, and PySpark SQL. Some transforms
+operate in place, while others create a new output column in your
+dataset.
+
+In order to apply an action on the imported data, select the **Add
+Transform** option on right clicking the the **Data Types** block. In
+the displayed window, select **Add Steps** to display **Add Transform**
+window.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/add-transform.png
+
+
+Drop Columns
+------------
+
+Now we will drop columns based on the analyses we performed in the
+previous section.
+
+- based on target leakage : drop ``reservation_status``
+
+- redundant columns : drop columns that are redundant -
+ ``days_in_waiting_list``, ``hotel``, ``reserved_room_type``,
+ ``arrival_date_month``, ``reservation_status_date``, ``babies`` and
+ ``arrival_date_day_of_month``
+
+- based on linear correlation results : drop columns
+ ``arrival_date_week_number``, ``arrival_date_year`` as correlation
+ values for these feature (column) pairs are greater than the
+ recommended threshold of 0.90.
+
+- based on non-linear correlation results: drop ``reservation_status``.
+ This column was already marked to be dropped based on Target leakage
+ analysis.
+
+we can drop all these columns in one go. To drop columns, choose
+**Manage columns** transform from the **Add Transform** window. Then
+select the **Drop column** option from **Manage columns** transform.
+
+Please select the the column names we want to drop as shown in the image
+below and hit **Preview**.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/drop-columns.png
+
+If the Preview is OK, click **Add** to add the transform in the data
+flow.
+
+Further, based on the multi-colinearity analysis results, we can also
+drop the columns ``adults`` and ``agent`` for whom the variance
+inflation factor scores are greater than 5. Please select the the column
+names we want to drop and hit **Preview**.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/drop-more-cols.png
+
+If the Preview is OK, click **Add** to add the transform in the data
+flow.
+
+Drop Duplicate Rows
+-------------------
+
+We should drop the duplicate rows that we identified based on the analysis we
+did in the previous section. To drop columns, choose **Manage rows**
+transform from the **Add Transform** window. Then select the **Drop
+duplicates** option from **Manage rows** transform and hit **Preview**.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/drop-duplicates.png
+
+If the Preview is OK, click **Add** to add the transform in the data
+flow.
+
+Handle Outliers
+---------------
+
+An outlier can cause serious problems in statistical analysis. Machine
+learning models are sensitive to the distribution and range of feature
+values. Outliers, or rare values, can negatively impact model accuracy
+and lead to longer training times. When you define a Handle outliers
+transform step, the statistics used to detect outliers are generated on
+the data available in Data Wrangler when defining this step. These same
+statistics are used when running a Data Wrangler job.
+
+| To handle outliers, choose **Handle outliers** transform from the
+ **Add Transform** window.
+| Please select the following parameters and hit **Preview**.
+
+- ``Transform``: ``Standard deviation numeric outliers``
+- ``Fix method`` : ``Remove``
+- ``Standard deviations``: ``4``
+- ``Input columns``: ``lead_time``,\ ``stays_in_weekend_nights``,
+ ``stays_in_weekday_nights``, ``is_repeated_guest``,
+ ``prev_cancellations``, ``prev_bookings_not_canceled``,
+ ``booking_changes``, ``adr``, ``total_of_specical_requests``,
+ ``required_car_parking_spaces``,
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/handle-outliers.png
+
+
+If the Preview is OK, click **Add** to add the transform in the data
+flow.
+
+Handle Missing Values
+---------------------
+
+To handle outliers, choose **Handle missing values** transform from the
+**Add Transform** window. We can do the following to handle missing
+values in our feature columns using Data Wrangler.
+
+- Missing values in **Children** column : Majority of the visitors were
+ not accompanied by children and hence missing data can be replaced by
+ number of children = 0.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/fill-missing-children-val.png
+
+
+Please hit **Preview** to look at the transform preview, and if it is
+OK, click **Add** to add the transform in the data flow.
+
+- Missing values in **Country** column Iterating through the country
+ column reveals that most of the clients are from Europe. Therefore,
+ all the missing values in the country column are replaced with the
+ country of maximum occurrence - Portugal (PRT). Fill missing country
+ column with ``PRT`` based on value counts
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/fill-missing-country-val.png
+
+
+Please hit **Preview** to look at the transform preview, and if it is
+OK, click **Add** to add the transform in the data flow.
+
+- Custom Transform - Meal type has Undefined category, changing the
+ Undefined value to the most used which is BB by implementing a custom
+ pyspark transform with two simple lines of code. This can be done by
+ choosing **Custom transform** transform from the **Add Transform**
+ window. Specify the name of the transform, and paste following code
+ in the transform as shown in figure below.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/custom-pyspark-code.png
+
+.. code:: python
+
+ from pyspark.sql.functions import when
+
+ df = df.withColumn('meal', when(df.meal == 'Undefined', 'BB').otherwise(df.meal))
+
+Please hit **Preview** to look at the transform preview, and if it is
+OK, click **Add** to add the transform in the data flow.
+
+### Numeric Normalization Normalization is a scaling technique in which
+values are shifted and rescaled so that they end up ranging between 0
+and 1. It is also known as Min-Max scaling. Standardization is another
+scaling technique where the values are centered around the mean with a
+unit standard deviation. This means that the mean of the attribute
+becomes zero and the resultant distribution has a unit standard
+deviation.
+
+For our example use case, let’s normalize the numeric feature columns to
+a standard scale [0,1].
+
+From Data Wrangler’s list of pre-built transforms, choose **Process
+numeric**. Please select the following parameters and hit **Preview**.
+
+- ``Transform``: ``Scale values``
+- ``Scalar`` : ``Min-max scalar``
+- ``Min``: ``0``
+- ``Max``: ``1``
+- ``Input columns``: ``lead_time``,\ ``stays_in_weekend_nights``,
+ ``stays_in_weekday_nights``, ``is_repeated_guest``,
+ ``prev_cancellations``, ``prev_bookings_not_canceled``,
+ ``booking_changes``, ``adr``, ``total_of_specical_requests``,
+ ``required_car_parking_spaces``
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/min-max.png
+
+If the Preview is OK, click **Add** to add the transform in the data
+flow.
+
+Handle Categorical Data
+-----------------------
+
+Categorical data is usually composed of a finite number of categories,
+where each category is represented with a string. Encoding categorical
+data is the process of creating a numerical representation for
+categories. With Data Wrangler, we can select Ordinal encode to encode
+categories into an integer between 0 and the total number of categories
+in the Input column you select. Select one-hot encoding or use
+similarity encoding when you have a large number of categorical
+variables and Noisy data.
+
+| From Data Wrangler’s list of pre-built transforms, choose **Encode
+ Categorical**. Please select the following parameters and hit
+ **Preview**.
+| - ``Transform``: ``One-hot encode`` - ``Invalid handling strategy`` :
+ ``Keep`` - ``Output style``: ``Columns`` - ``Max``: ``1``
+| - ``Input columns``: ``meal``, ``is_repeated_guest``,
+ ``market_segment``, ``assigned_room_type``, ``deposit_type``,
+ ``customer_type``
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/categorical-one-hot.png
+
+
+If the Preview is OK, click **Add** to add the transform in the data
+flow.
+
+Balancing the target variable
+-----------------------------
+
+DataWrangler also helps to balance the target variable (column) for
+class imbalance. Let’s presume the following for the negative and
+positive cases.
+
+::
+
+ is_canceled = 0 (negative case)
+ is_canceled = 1 (positive case)
+
+In Data Wrangler, we can handle class imbalance using 3 different
+techniques.
+
+::
+
+ - Random Undersample
+ - Random Oversample
+ - SMOTE
+
+| From the Data Wrangler’s transform pane, choose **Balance Data** as
+ the transform. Please select the following parameters as shown in
+ image below and hit **Preview**.
+| - ``Target column``: ``is_canceled`` - ``Desiered ratio`` : ``1`` -
+ ``Transform``: ``Random oversample``
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/random-oversample.png
+
+
+If the Preview is OK, click **Add** to add the transform in the data
+flow.
+
+The state of the classes before and after balancing is as follows:
+
+The ratio of positive to negative case = ~0.38
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/class-before-balance.png
+
+
+After balancing, the ratio is 1 |post-balance|
+
+Quick Model
+-----------
+
+Given, we have applied most of the needed transformations on our feature
+columns, we can now create a Quick Model again using the transformed
+features to identify the predictive ability of our features and take a
+look at their attribution towards prediction.
+
+It is a good practice to run a Quick Model everytime we make a set of
+feature transforms. Previously, we ran a Quick Model analysis using the
+raw features. The results of this previous run was mostly incorrect and
+misleading, given, we haven’t fixed most of the correlation and other
+issues with our dataset.
+
+The below figure shows the results of the newly run Quick Model created
+using the transformed features. As you can see, the Quick Model achieved
+an F1 score of 62% on the test data. The top 5 most contributing
+features towards this score are as follows which is different from what
+we see previously.
+
+::
+
+ lead_time
+ country
+ customer_type_Transient
+ required_car_parking_spaces
+ booking_changes
+
+Craete a quick model, similar to one we created in the `Exploratory Data
+Analysis <./Data-Exploration.md>`__ step.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/quick-model-post.png
+
+Compare the model with the one created in Exploratory Data Analysis
+step.
+
+Next Steps
+----------
+
+As a next step, we will export the transformed data for further use.
+Please follow steps for Data
+Export.
+
+.. |post-balance| image:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/class-after-balance.png
diff --git a/sagemaker-datawrangler/tabular-dataflow/index.rst b/sagemaker-datawrangler/tabular-dataflow/index.rst
new file mode 100644
index 0000000000..8fc5c1a3d3
--- /dev/null
+++ b/sagemaker-datawrangler/tabular-dataflow/index.rst
@@ -0,0 +1,361 @@
+
+Tabular Dataflow Example
+========================
+This example provide quick walkthrough of how to aggregate and prepare
+data for Machine Learning using Amazon SageMaker Data Wrangler for
+Tabular dataset.
+
+Hotel Booking Demand Example
+----------------------------
+
+Background
+----------
+
+Amazon SageMaker helps data scientists and developers to prepare, build,
+train, and deploy machine learning models quickly by bringing together a
+broad set of purpose-built capabilities. This example shows how
+SageMaker can accelerate machine learning development during the data
+preprocessing stage to help process the hotel demand data and find
+relevant features for the training model to predict hotel cancellations.
+
+Dataset
+~~~~~~~
+
+.. raw:: html
+
+
+
+Dataset
+
+We are using the `Hotel Booking Demand
+dataset
`__
+that is publically available. This data set contains booking information
+for a city hotel and a resort hotel, and includes information such as
+when the booking was made, length of stay, the number of adults,
+children, and/or babies, and the number of available parking spaces,
+among other things.
+
+The data needs to be downloaded from the locations specified, and
+uploaded to S3 bucket before we start the Data Preprocessing phase.
+Please follow the Experiment Steps outlined in later sections, to
+download the data and notebooks.
+
+Description of the Columns
+--------------------------
+
++-----------------------------------+-----------------------------------+
+| Column Name | Description |
++===================================+===================================+
+| ``hotel`` | Type of the hotel (``H1`` = |
+| | Resort Hotel or ``H2`` = City |
+| | Hotel) |
++-----------------------------------+-----------------------------------+
+| ``is_canceled`` | Value indicating if the booking |
+| | was canceled (1) or not (0) |
++-----------------------------------+-----------------------------------+
+| ``lead_time`` | Number of days that elapsed |
+| | between the entering date of the |
+| | booking into the PMS and the |
+| | arrival date |
++-----------------------------------+-----------------------------------+
+| ``arrival_date_year`` | Year of arrival date |
++-----------------------------------+-----------------------------------+
+| ``arrival_date_month`` | Month of arrival date |
++-----------------------------------+-----------------------------------+
+| ``arrival_date_week_number`` | Week number of year for arrival |
+| | date |
++-----------------------------------+-----------------------------------+
+| ``arrival_date_day_of_month`` | Day of arrival date |
++-----------------------------------+-----------------------------------+
+| ``stays_in_weekend_nights`` | Number of weekend nights |
+| | (Saturday or Sunday) the guest |
+| | stayed or booked to stay at the |
+| | hotel |
++-----------------------------------+-----------------------------------+
+| ``stays_in_week_nights`` | Number of week nights (Monday to |
+| | Friday) the guest stayed or |
+| | booked to stay at the hotel |
++-----------------------------------+-----------------------------------+
+| ``adults`` | Number of adults |
++-----------------------------------+-----------------------------------+
+| ``children`` | Number of children |
++-----------------------------------+-----------------------------------+
+| ``babies`` | Number of babies |
++-----------------------------------+-----------------------------------+
+| ``meal`` | Type of meal booked. Categories |
+| | are presented in standard |
+| | hospitality meal packages: |
+| | ``Undefined/SC`` – no meal |
+| | package; ``BB`` – Bed & |
+| | Breakfast; ``HB`` – Half board |
+| | (breakfast and one other meal – |
+| | usually dinner); ``FB`` – Full |
+| | board (breakfast, lunch and |
+| | dinner) |
++-----------------------------------+-----------------------------------+
+| ``country`` | Country of origin. Categories are |
+| | represented in the |
+| | ``ISO 3155–3:2013`` format |
++-----------------------------------+-----------------------------------+
+| ``market_segment`` | Market segment designation. In |
+| | categories, the term ``TA`` means |
+| | “Travel Agents” and ``TO`` means |
+| | “Tour Operators” |
++-----------------------------------+-----------------------------------+
+| ``distribution_channel`` | Booking distribution channel. The |
+| | term ``TA`` means “Travel Agents” |
+| | and ``TO`` means “Tour Operators” |
++-----------------------------------+-----------------------------------+
+| ``is_repeated_guest`` | Value indicating if the booking |
+| | name was from a repeated guest |
+| | (1) or not (0) |
++-----------------------------------+-----------------------------------+
+| ``previous_cancellations`` | Number of previous bookings that |
+| | were cancelled by the customer |
+| | prior to the current booking |
++-----------------------------------+-----------------------------------+
+| ` | Number of previous bookings not |
+| `previous_bookings_not_canceled`` | cancelled by the customer prior |
+| | to the current booking |
++-----------------------------------+-----------------------------------+
+| ``reserved_room_type`` | Code of room type reserved. Code |
+| | is presented instead of |
+| | designation for anonymity |
+| | reasons. |
++-----------------------------------+-----------------------------------+
+| ``assigned_room_type`` | Code for the type of room |
+| | assigned to the booking. |
+| | Sometimes the assigned room type |
+| | differs from the reserved room |
+| | type due to hotel operation |
+| | reasons (e.g. overbooking) or by |
+| | customer request. Code is |
+| | presented instead of designation |
+| | for anonymity reasons. |
++-----------------------------------+-----------------------------------+
+| ``booking_changes`` | Number of changes/amendments made |
+| | to the booking from the moment |
+| | the booking was entered on the |
+| | PMS until the moment of check-in |
+| | or cancellation |
++-----------------------------------+-----------------------------------+
+| ``deposit_type`` | Indication on if the customer |
+| | made a deposit to guarantee the |
+| | booking. This variable can assume |
+| | three categories: No Deposit – no |
+| | deposit was made; ``Non Refund`` |
+| | – a deposit was made in the value |
+| | of the total stay cost; |
+| | ``Refundable`` – a deposit was |
+| | made with a value under the total |
+| | cost of stay. |
++-----------------------------------+-----------------------------------+
+| ``agent`` | ID of the travel agency that made |
+| | the booking |
++-----------------------------------+-----------------------------------+
+| ``company`` | ID of the company/entity that |
+| | made the booking or responsible |
+| | for paying the booking. ID is |
+| | presented instead of designation |
+| | for anonymity reasons |
++-----------------------------------+-----------------------------------+
+| ``days_in_waiting_list`` | Number of days the booking was in |
+| | the waiting list before it was |
+| | confirmed to the customer |
++-----------------------------------+-----------------------------------+
+| ``customer_type`` | Type of booking, assuming one of |
+| | four categories: ``Contract`` - |
+| | when the booking has an allotment |
+| | or other type of contract |
+| | associated to it; ``Group`` – |
+| | when the booking is associated to |
+| | a group; ``Transient`` – when the |
+| | booking is not part of a group or |
+| | contract, and is not associated |
+| | to other transient booking; |
+| | ``Transient-party`` – when the |
+| | booking is transient, but is |
+| | associated to at least other |
+| | transient booking |
++-----------------------------------+-----------------------------------+
+| ``adr`` | Average Daily Rate as defined by |
+| | dividing the sum of all lodging |
+| | transactions by the total number |
+| | of staying nights |
++-----------------------------------+-----------------------------------+
+| ``required_car_parking_spaces`` | Number of car parking spaces |
+| | required by the customer |
++-----------------------------------+-----------------------------------+
+| ``total_of_special_requests`` | Number of special requests made |
+| | by the customer (e.g. twin bed or |
+| | high floor) |
++-----------------------------------+-----------------------------------+
+| ``reservation_status`` | Reservation last status, assuming |
+| | one of three categories: |
+| | ``Canceled`` – booking was |
+| | canceled by the customer; |
+| | ``Check-Out`` – customer has |
+| | checked in but already departed; |
+| | ``No-Show`` – customer did not |
+| | check-in and did inform the hotel |
+| | of the reason why |
++-----------------------------------+-----------------------------------+
+| ``reservation_status_date`` | Date at which the last status was |
+| | set. This variable can be used in |
+| | conjunction with the |
+| | ReservationStatus to understand |
+| | when was the booking canceled or |
+| | when did the customer checked-out |
+| | of the hotel |
++-----------------------------------+-----------------------------------+
+
+--------------
+
+Pre-requisites:
+---------------
+
+- We need to ensure dataset (tracks and ratings dataset) for ML is
+ uploaded to a data source (instructions to download the dataset to
+ Amazon S3 is available in the following section).
+- Data source can be any one of the following options:
+
+ - S3
+ - Athena
+ - RedShift
+ - SnowFlake
+
+.. container:: alert alert-block alert-info
+
+ Data Source
+
+ For this experiment the Data Source will be `Amazon
+ S3 `__
+
+Experiment steps
+----------------
+
+Downloading the dataset
+~~~~~~~~~~~~~~~~~~~~~~~
+
+- Ensure that you have a working `Amazon SageMaker
+ Studio `__ environment and
+ that it has been updated.
+
+- Follow the steps below to download the dataset.
+
+1. Download the `Hotel Booking Demand
+ dataset `__
+ from the specified location.
+2. Create a private S3 bucket to upload the dataset in. You can
+ reference the instructions for bucket creaiton [here]
+ https://docs.aws.amazon.com/AmazonS3/latest/userguide/create-bucket-overview.html
+3. Upload the data in step 1 to the bucket created in step 2. Steps to
+ upload the data can be found [here]
+ https://docs.aws.amazon.com/AmazonS3/latest/userguide/upload-objects.html
+4. Note the S3 URL for the file uploaded in Step 3 before moving to the
+ next sextion. This data will be used as input to the Datawrangler.
+ The S3 URL will be used in the next step.
+
+Data Import from S3 to Data Wrangler
+------------------------------------
+
+
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Data Import from S3 to Data Wrangler
+
+ data-import/index
+
+
+Exploratory Data Analysis
+--------------------------
+
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Data Exploration from S3 to Data Wrangler
+
+ data-exploration/index
+
+Data Transformation
+-------------------
+
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Data transformations from S3 to Data Wrangler
+
+ data-transformations/index
+
+Data Export
+~~~~~~~~~~~
+
+Data Wrangler UI can also be used to export the transformed data to
+Amazon S3. To get started with this process, first let’s create a
+destination node. Right click on the final transform on your data and
+choose ``Add destination`` → ``Amazon S3``. Assign a name for your
+output data and choose the S3 location where you want the data to be
+stored and click Add destination button at the bottom as shown below.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/add-destination.png
+
+
+
+
+This adds a destination node to our data flow. The destination node acts
+as a sink to your data flow.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/destination.png
+
+
+
+Next, click on the Create job button in the upper right corner of the
+page. In the configuration page for the SageMaker Processing job we are
+about to create, choose the Instance type and Instance count for our
+processing cluster. Advance configuration is optional, where you can
+assign tags as needed and choose the appropriate Volume Size.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/configure-job.png
+
+
+
+
+Select ``Run`` to start the export job. The job created will have Job
+Name and Job ARN which can be used to search for the job status.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/create-job.png
+
+
+
+
+The job created in the previous step will be available in the monitoring
+page for ``SageMaker Processing job`` as shown in the figure below.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/processing-job.png
+
+
+
+
+After a certain time, the job will be complete. The image below shows
+the completed job. Exported data should be available in the output S3
+bucket.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/tabular-dataflow/complete-job.png
+
+
+
+This exported data can now be used for running the ML Models
+
+
+Import Dataflow
+----------------------------
+
+Here is the final `Flow file
+`__ available which you can directly import to expediate the process or validate the flow.
+
+Here are the steps to import the flow
+
+* Download the flow file
+
+* In Sagemaker Studio, drag and drop the flow file or use the upload button to browse the flow and upload
diff --git a/sagemaker-datawrangler/timeseries-dataflow/TS-Workshop-DataPreparation.flow b/sagemaker-datawrangler/timeseries-dataflow/TS-Workshop-DataPreparation.flow
new file mode 100644
index 0000000000..458de87e01
--- /dev/null
+++ b/sagemaker-datawrangler/timeseries-dataflow/TS-Workshop-DataPreparation.flow
@@ -0,0 +1,585 @@
+{
+ "metadata": {
+ "version": 1,
+ "disable_limits": false,
+ "instance_type": "ml.m5.4xlarge"
+ },
+ "parameters": [],
+ "nodes": [
+ {
+ "node_id": "8e286fbf-3ad5-4683-92fe-7c2e6f5c69b6",
+ "type": "SOURCE",
+ "operator": "sagemaker.s3_source_0.1",
+ "parameters": {
+ "dataset_definition": {
+ "__typename": "S3CreateDatasetDefinitionOutput",
+ "datasetSourceType": "S3",
+ "name": "trip_data",
+ "description": null,
+ "s3ExecutionContext": {
+ "__typename": "S3ExecutionContext",
+ "s3Uri": "s3://768746145684-us-east-1-dw-ts-lab/trip data/",
+ "s3ContentType": "parquet",
+ "s3HasHeader": true,
+ "s3FieldDelimiter": ",",
+ "s3DirIncludesNested": false,
+ "s3AddsFilenameColumn": false
+ }
+ }
+ },
+ "inputs": [],
+ "outputs": [
+ {
+ "name": "default",
+ "sampling": {
+ "sampling_method": "sample_by_limit",
+ "limit_rows": 50000
+ }
+ }
+ ]
+ },
+ {
+ "node_id": "bf119511-56d6-4b73-9bc2-d9026ee3a10d",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.infer_and_cast_type_0.1",
+ "parameters": {},
+ "trained_parameters": {
+ "schema": {
+ "store_and_fwd_flag": "string",
+ "VendorID": "long",
+ "tpep_pickup_datetime": "datetime",
+ "tpep_dropoff_datetime": "datetime",
+ "passenger_count": "long",
+ "trip_distance": "float",
+ "RatecodeID": "long",
+ "PULocationID": "long",
+ "DOLocationID": "long",
+ "payment_type": "long",
+ "fare_amount": "float",
+ "extra": "float",
+ "mta_tax": "float",
+ "tip_amount": "float",
+ "tolls_amount": "float",
+ "improvement_surcharge": "float",
+ "total_amount": "float",
+ "congestion_surcharge": "float",
+ "airport_fee": "float"
+ }
+ },
+ "inputs": [
+ {
+ "name": "default",
+ "node_id": "8e286fbf-3ad5-4683-92fe-7c2e6f5c69b6",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "ff490248-9beb-4bd9-8764-40409b93e59e",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.manage_columns_0.1",
+ "parameters": {
+ "operator": "Drop column",
+ "drop_column_parameters": {
+ "column_to_drop": [
+ "VendorID",
+ "RatecodeID",
+ "store_and_fwd_flag",
+ "DOLocationID",
+ "payment_type",
+ "fare_amount",
+ "extra",
+ "mta_tax",
+ "tolls_amount",
+ "improvement_surcharge",
+ "passenger_count",
+ "congestion_surcharge",
+ "airport_fee"
+ ]
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "bf119511-56d6-4b73-9bc2-d9026ee3a10d",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "27cabb74-7b37-4bc8-8611-e3f36e3bbcda",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.time_series_0.1",
+ "parameters": {
+ "Validate timestamps_parameters": {
+ "timestamp_column": "tpep_pickup_datetime",
+ "policy": "drop"
+ },
+ "operator": "Validate timestamps"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "ff490248-9beb-4bd9-8764-40409b93e59e",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "33b52060-f318-4a5d-8fe3-895d703a025b",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.time_series_0.1",
+ "parameters": {
+ "Validate timestamps_parameters": {
+ "timestamp_column": "tpep_dropoff_datetime",
+ "policy": "drop"
+ },
+ "operator": "Validate timestamps"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "27cabb74-7b37-4bc8-8611-e3f36e3bbcda",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "3fc0ab7a-94b8-46ad-be39-7b9786206261",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.custom_code_0.1",
+ "parameters": {
+ "operator": "Python (PySpark)",
+ "pyspark_parameters": {
+ "code": "# Table is available as variable `df`\nfrom pyspark.sql.functions import col, round\ndf = df.withColumn('duration', round((col(\"tpep_dropoff_datetime\").cast(\"long\")-col(\"tpep_pickup_datetime\").cast(\"long\"))/60,2))\ndf = df.drop(\"tpep_dropoff_datetime\")"
+ },
+ "name": "Duration_Transformation"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "33b52060-f318-4a5d-8fe3-895d703a025b",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "6f1de2ca-cf98-48c3-9bde-026fbf66399a",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.handle_missing_0.1",
+ "parameters": {
+ "operator": "Fill missing",
+ "fill_missing_parameters": {
+ "input_column": [
+ "PULocationID",
+ "tip_amount",
+ "total_amount"
+ ],
+ "fill_value": "0"
+ },
+ "impute_parameters": {
+ "column_type": "Numeric",
+ "numeric_parameters": {
+ "strategy": "Approximate Median"
+ }
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "3fc0ab7a-94b8-46ad-be39-7b9786206261",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "5eb611f2-2cd0-4a04-bdd3-221ead204bbc",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.time_series_0.1",
+ "parameters": {
+ "Handle missing_parameters": {
+ "hm_input_type_Along column_parameters": {
+ "hmac_output_column": "",
+ "hmac_id_column": "PULocationID",
+ "hmac_strategy": "Constant Value",
+ "hmac_leftovernans": "Fill with Forward/Backward feed",
+ "hmac_strategy_Constant Value_parameters": {
+ "hmac_custom_value": "0.0"
+ },
+ "hmac_sequence_column": "trip_distance",
+ "hmac_timestamp_column": "tpep_pickup_datetime"
+ },
+ "hm_input_type": "Along column"
+ },
+ "operator": "Handle missing"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "6f1de2ca-cf98-48c3-9bde-026fbf66399a",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "4d6ac70b-97d9-4688-930d-988d63238d07",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.custom_code_0.1",
+ "parameters": {
+ "operator": "Python (PySpark)",
+ "pyspark_parameters": {
+ "code": "# Table is available as variable `df`\ndf = df.filter(df.trip_distance >= 0)\ndf = df.filter(df.tip_amount >= 0)\ndf = df.filter(df.total_amount >= 0)\ndf = df.filter(df.duration >= 1)\ndf = df.filter((1 <= df.PULocationID) & (df.PULocationID <= 263))\ndf = df.filter((df.tpep_pickup_datetime >= \"2019-01-01 00:00:00\") & (df.tpep_pickup_datetime < \"2020-03-01 00:00:00\"))"
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "5eb611f2-2cd0-4a04-bdd3-221ead204bbc",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "22d3a3bc-1d23-451d-8b2c-8be6e0e9fca0",
+ "type": "VISUALIZATION",
+ "operator": "sagemaker.visualizations.describe_0.1",
+ "parameters": {
+ "name": "Cleaned Dataset Summary"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "4d6ac70b-97d9-4688-930d-988d63238d07",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "6681625c-0323-475a-8fac-443fe96da56a",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.handle_outliers_0.1",
+ "parameters": {
+ "operator": "Standard deviation numeric outliers",
+ "standard_deviation_numeric_outliers_parameters": {
+ "standard_deviations": 4,
+ "input_column": [
+ "trip_distance",
+ "tip_amount",
+ "total_amount",
+ "duration"
+ ],
+ "fix_method": "Remove"
+ }
+ },
+ "trained_parameters": {
+ "standard_deviation_numeric_outliers_parameters": [
+ {
+ "_hash": "10b2dff28011403357a5a7dd4a37e9bea91721a8",
+ "lower_threshold": -12.393631771918914,
+ "upper_threshold": 18.423848932384466,
+ "input_column": "trip_distance"
+ },
+ {
+ "_hash": "10b2dff28011403357a5a7dd4a37e9bea91721a8",
+ "lower_threshold": -8.711892476401351,
+ "upper_threshold": 12.165641974849178,
+ "input_column": "tip_amount"
+ },
+ {
+ "_hash": "10b2dff28011403357a5a7dd4a37e9bea91721a8",
+ "lower_threshold": -29.770794210538003,
+ "upper_threshold": 58.2552896798414,
+ "input_column": "total_amount"
+ },
+ {
+ "_hash": "10b2dff28011403357a5a7dd4a37e9bea91721a8",
+ "lower_threshold": -255.48697194000522,
+ "upper_threshold": 284.4440844902989,
+ "input_column": "duration"
+ }
+ ]
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "4d6ac70b-97d9-4688-930d-988d63238d07",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "31009b84-d667-427a-8649-a846f4370e99",
+ "type": "VISUALIZATION",
+ "operator": "sagemaker.visualizations.describe_0.1",
+ "parameters": {
+ "name": "Updated Table Summary"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "6681625c-0323-475a-8fac-443fe96da56a",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "a16da785-dc80-44c4-b426-fdd68972a317",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.custom_code_0.1",
+ "parameters": {
+ "operator": "Python (PySpark)",
+ "pyspark_parameters": {
+ "code": "# Table is available as variable `df`\nfrom pyspark.sql.functions import col, date_trunc\ndf = df.withColumn('pickup_time', date_trunc(\"hour\",col(\"tpep_pickup_datetime\")))\ndf = df.drop(\"tpep_pickup_datetime\")"
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "6681625c-0323-475a-8fac-443fe96da56a",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "2d851ed9-6e82-409c-a10f-f2869d53b9f9",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.custom_code_0.1",
+ "parameters": {
+ "operator": "Python (PySpark)",
+ "pyspark_parameters": {
+ "code": "# Table is available as variable `df`\nfrom pyspark.sql import functions as f\nfrom pyspark.sql import Window\ndf = df.withColumn('count', f.count('duration').over(Window.partitionBy([f.col(\"pickup_time\"), f.col(\"PULocationID\")])))"
+ }
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "a16da785-dc80-44c4-b426-fdd68972a317",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "ce8c8a4a-8161-4615-b222-a5d1cda8d674",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.time_series_0.1",
+ "parameters": {
+ "Resample_parameters": {
+ "frequency": {
+ "quantity": 1,
+ "offset_description": "Hourly"
+ },
+ "downsample": {
+ "non_numeric": "most common",
+ "numeric": "mean"
+ },
+ "upsample": {
+ "non_numeric": "ffill",
+ "numeric": "linear"
+ },
+ "timestamp_column": "pickup_time",
+ "id_column": "PULocationID"
+ },
+ "operator": "Resample"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "2d851ed9-6e82-409c-a10f-f2869d53b9f9",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "a7405baf-56f2-4ddc-8a7b-688f66e487da",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.time_series_0.1",
+ "parameters": {
+ "Featurize datetime_parameters": {
+ "output_column": "date",
+ "output_mode": "Ordinal",
+ "output_format": "Columns",
+ "infer_datetime_format": false,
+ "date_time_format": "",
+ "year": true,
+ "month": true,
+ "day": true,
+ "hour": true,
+ "minute": false,
+ "second": false,
+ "week_of_year": true,
+ "day_of_year": true,
+ "quarter": true,
+ "input_column": "pickup_time"
+ },
+ "operator": "Featurize datetime"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "ce8c8a4a-8161-4615-b222-a5d1cda8d674",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "51c5993e-56c5-43c6-8378-95c26037becd",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.time_series_0.1",
+ "parameters": {
+ "Lag features_parameters": {
+ "lag": 8,
+ "entire_window": true,
+ "drop_rows": false,
+ "entire_window_True_parameters": {
+ "flatten": true
+ },
+ "sequence_column": "count",
+ "id_column": "PULocationID",
+ "timestamp_column": "pickup_time"
+ },
+ "operator": "Lag features"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "a7405baf-56f2-4ddc-8a7b-688f66e487da",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "85f7158d-64d9-4cbe-b965-b18364eca536",
+ "type": "TRANSFORM",
+ "operator": "sagemaker.spark.time_series_0.1",
+ "parameters": {
+ "Rolling window features_parameters": {
+ "window_size": 8,
+ "flatten": true,
+ "strategy": "Minimal subset",
+ "sequence_column": "count",
+ "timestamp_column": "pickup_time",
+ "id_column": "PULocationID"
+ },
+ "operator": "Rolling window features"
+ },
+ "inputs": [
+ {
+ "name": "df",
+ "node_id": "51c5993e-56c5-43c6-8378-95c26037becd",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ },
+ {
+ "node_id": "f157eb91-0cd7-4c04-a023-e1be3f343b2e",
+ "type": "DESTINATION",
+ "operator": "sagemaker.spark.s3_destination_0.1",
+ "name": "S3: NYC_Export",
+ "parameters": {
+ "output_config": {
+ "compression": "none",
+ "output_path": "s3://768746145684-us-east-1-dw-ts-lab/",
+ "output_content_type": "CSV",
+ "delimiter": ","
+ }
+ },
+ "inputs": [
+ {
+ "name": "default",
+ "node_id": "85f7158d-64d9-4cbe-b965-b18364eca536",
+ "output_name": "default"
+ }
+ ],
+ "outputs": [
+ {
+ "name": "default"
+ }
+ ]
+ }
+ ]
+}
\ No newline at end of file
diff --git a/sagemaker-datawrangler/timeseries-dataflow/index.rst b/sagemaker-datawrangler/timeseries-dataflow/index.rst
new file mode 100644
index 0000000000..05cb0a9340
--- /dev/null
+++ b/sagemaker-datawrangler/timeseries-dataflow/index.rst
@@ -0,0 +1,1050 @@
+Timeseries Data Flow example
+===================================================
+This example provide quick walkthrough of how to aggregate and prepare data for Machine Learning using Amazon SageMaker Data Wrangler for Timeseries dataset.
+
+
+
+New York city(NYC) yellow cab time-series example
+-------------------------------------------------
+
+Our end goal for this lab is to prepare a time-series dataset and get it
+to a ready state for ML modeling. We will start with the New York city
+(NYC) yellow cab time-series dataset and work towards exploring,
+preparing and transforming the dataset to help us design a ML model that
+will predict the number of NYC yellow taxi pickups for any hour of the
+day and location. As part of the exercise, we will learn how to derive
+various insights about the trip like average tip value, average distance
+for the trip, etc.
+
+Data used in this demo: - Original data source for all open data from
+2008 to Current can be accessed here:
+https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page -
+AWS-hosted location:
+https://registry.opendata.aws/nyc-tlc-trip-records-pds/
+
+The taxi trip records include fields capturing pick-up and drop-off
+dates/times, pick-up and drop-off locations, trip distances, itemized
+fares, rate types, payment types, and driver-reported passenger counts.
+The raw data is split 1 month per file, per Yellow, Green, or ForHire
+from 2008 through 2020, with each file around 600 MB. The entire raw
+dataset is huge. For our lab, we will use 13 of these files of around a
+year’s worth of trip data and focus only on the iconic yellow cab trips.
+We picked trip data from Feb 2019 to Feb 2020 to avoid COVID effects.
+The data dictionary below describes the Yellow taxi trip data with raw
+feature column names and their respective descriptions. The picked
+dataset covers 13 months and encapsulates approximately 90 million
+trips.
+
+Instructions to download the dateset
+------------------------------------
+
+You can use SageMaker Data Wrangler to import data from the following
+data sources: Amazon Simple Storage Service (Amazon S3), Amazon Athena,
+Amazon Redshift, and Snowflake. The dataset that you import can include
+up to 1000 columns. For this lab, we will be using Amazon S3 as the
+preferred data source. Before we import the dataset into SageMaker Data
+Wrangler, let’s ensure we copy the dataset first from the publicly
+hosted location to our local S3 bucket in our own account.
+
+To copy the dataset, copy and execute the Python code below within
+SageMaker Studio. It is recommended to execute this code in a notebook
+setting. We also recommend to have your S3 bucket in the same region as
+SageMaker Data Wrangler.
+
+To create a SageMaker Studio notebook, from the launcher page, click on
+the **Notebook Python 3** options under **Notebooks and compute
+resources** as show in the figure below.
+
+Copy and paste the shared code snippet below into the launched
+notebook’s cell (shown below) and execute it by clicking on the play
+icon on the top bar.
+
+.. code:: python
+
+ import boto3
+ import json
+
+
+ # Setup
+ REGION = 'us-east-1'
+ account_id = boto3.client('sts').get_caller_identity().get('Account')
+ bucket_name = f'{account_id}-{REGION}-dw-ts-lab'
+
+
+ # Create S3 bucket to download dataset in your account
+ s3 = boto3.resource('s3')
+
+ if REGION == 'us-east-1':
+ s3.create_bucket(Bucket=bucket_name)
+ else:
+ s3.create_bucket(Bucket=bucket_name,CreateBucketConfiguration={'LocationConstraint': REGION})
+ # Copy dataset from public hosted location to your S3 bucket
+ trips = [
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-02.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-03.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-04.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-05.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-06.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-07.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-08.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-09.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-10.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-11.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-12.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2020-01.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2020-02.parquet'}
+ ]
+ for trip in trips:
+ s3.meta.client.copy(trip, bucket_name, trip['Key'])
+
+Now we have raw data in our S3 bucket and ready to explore it and build
+a training dataset
+
+Dataset Import
+--------------
+
+Our first step is to launch a new SageMaker Data Wrangler session and
+there are multiple ways how to do that. For example, use the following:
+
+Click File -> New -> Data Wrangler Flow
+
+Amazon SageMaker will start to provision a resources for you and you a
+could find a new Data Wrangler Flow file in a File Browser section
+
+Lets rename our new workflow: Right click on file -> Rename Data
+Wrangler Flow
+
+Put a new name, for example: ``TS-Workshop-DataPreparation.flow``
+
+In few minutes Data Wrangler will finish to provision resources and you
+could see “Import Data” screen. SageMaker Data Wrangler supports many
+data sources: Amazon S3, Amazon Athena, Amazon Redshift, Snowflake,
+Databricks. Our data already in S3, let’s import it by clicking “Amazon
+S3” button.
+
+You will see all your S3 buckets so please search for your bucket (if
+you used provided code the bucket will have a suffix dw-ts-lab)
+
+All the files required for this lab are in “trip data” folder, so let’s
+select it. SageMaker Data Wrangler will import all files from a folder
+and sample up to 100 MB of data for an interactive preview. On a right
+side menu you could customize import job settings like Name, File type,
+Delimiter, etc. More information about import process could be found
+`here `__.
+
+To finish setting up import step select “parquet” in “File type” drop
+down menu and press the orange button “Import”
+
+It will take a few minutes to import data and validate it. SageMaker
+Data Wrangler will automatically recognize data types. You should see
+“Validation complete 0 errors message”
+
+Change data types
+------------------
+
+First we will check the data types were correctly recognized. This might
+be necessary as Data Wrangler selects data types based on a sampled data
+which is limited to 50000 rows. Sampled data might potentially miss some
+variations.
+
+To add a data transformation step use the plus sign next to Data types
+and choose Edit data types as shown below.
+
+In our case several columns were incorrectly recognized: -
+``passenger_count`` (must be ``long`` instead of ``float``) -
+``RatecodeID`` (must be ``long`` instead of ``float``) - ``airport_fee``
+(must be ``float`` instead of ``long``)
+
+I know correct data types from dataset description. In real life you
+could also easily find such information. Let’s correct data types by
+selecting a correct type from a drop down menu.
+
+Click Preview and then Apply button.
+
+Click Back to data flow.
+
+Dataset preparation
+-------------------
+
+Drop columns
+------------
+
+Before we analyze data and do feature engineering we have to clean
+dataset and below steps show how to remove unwanted data.
+
+To re-iterate our business goal: Predict the number of NY City yellow
+taxi pickups in the next 24 hour for each pickup per hour zones and
+provide some insights for drivers like average tips, average distance,
+etc.
+
+As we are interested in per hour forecast we have to aggregate some
+features and remove features which are impossible to aggregate. For this
+purpose we don’t need the following columns:
+
+1. ``VendorID`` (A code indicating the TPEP provider that provided the
+ record)
+2. ``RatecodeID`` (The final rate code in effect at the end of the
+ trip)
+3. ``Store_and_fwd_flag`` (This flag indicates whether the trip record
+ was held in vehicle memory before sending to the vendor, aka “store
+ and forward,”because the vehicle did not have a connection to the
+ server)
+4. ``DOLocationID`` (TLC Taxi Zone in which the taximeter was
+ disengaged)
+5. ``Payment_type`` (A numeric code signifying how the passenger paid
+ for the trip)
+6. ``Fare_amount`` (The time-and-distance fare calculated by the meter)
+ - we will use total amount feature
+7. ``Extra`` (Miscellaneous extras and surcharges)
+8. ``MTA_tax`` (0.50 MTA tax that is automatically triggered based on
+ the metered rate in use)
+9. ``Tolls_amount`` (Total amount of all tolls paid in trip)
+10. ``Improvement_surcharge`` (improvement surcharge assessed trips at
+ the flag drop. The improvement surcharge began being levied in 2015)
+11. ``Passenger_count`` (This is a driver-entered value)
+12. ``congestion_surcharge`` (Total amount collected in trip for NYS
+ congestion surcharge)
+13. ``Airport_fee`` (Only at LaGuardia and John F. Kennedy Airports)
+
+To remove those columns: 1. Click the plus sign next to “Data types”
+element and choose Add transform.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/timeseries-dataflow/SelectAddTransform.png
+
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu.
+
+3. | Choose Manage columns.
+
+4. For Transform, choose Drop column and for Column to drop, choose all
+ mentioned above.
+
+5. Choose Preview
+
+6. Choose Add to save the step.
+
+Once transformation is applied on a sampled data you should see all
+current steps and a preview of a resulted dataset like show here.
+
+Click Back to data flow.
+
+Handle missing and invalid data in timestamps
+---------------------------------------------
+
+Missing data is a common problem in real life, it could be a result of
+data corruption, data loss or issues in data ingestion. The best
+practice is to verify the presence of any missing or invalid values and
+handle them appropriately.
+
+There are many different strategies how missing or invalid data could be
+handled, for example dropping rows with missing values or filling the
+missing values with static or calculated values. Depending on dataset
+size you could choose what to do: fix values or just drop them. The
+**Time Series - Handle missing** transform allows you to choose from
+multiple strategies.
+
+All future aggregations will be based on time stamps, so we have to make
+sure that we don’t have any rows with missing time stamps (
+``tpep_pickup_datetime`` and ``tpep_dropoff_datetime`` features).
+SageMaker Data Wrangler has several time series specific
+transformations, including **Validate timestamps** which checks for
+scenarios: 1. Checking timestamp column for any missing values. 2.
+Validate the timestamp columns for the desired timestamp format.
+
+To validate timestamps in ``tpep_dropoff_datetime`` and
+``tpep_pickup_datetime`` columns: 1. Click the plus sign next to “Drop
+columns” element and choose Add transform.
+
+
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/timeseries-dataflow/AddDateValidationTransform.png
+
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu.
+
+3. Choose Time Series.
+
+4. For Transform choose Validate Timestamps, For TimeStamp columns
+ choose ``tpep_pickup_datetime``, for Policy select drop.
+
+5. Choose Preview
+
+6. Choose Add to save the step.
+
+7. Repeat same steps again for ``tpep_dropoff_datetime`` column
+
+When you apply a transformation a sampled data you should see all
+current steps and a preview of a resulted dataset.
+
+Click Back to data flow.
+
+Feature engineering based on a timestamp with a custom transformation.
+----------------------------------------------------------------------
+
+At this stage we have pickup and drop-off timestamps, but we are more
+interested in pickup timestamp and ride duration. We have to create a
+new feature ``ride duration`` as a difference between pick up and drop
+off time in minutes. There is no built-in date difference transformation
+in a Data Wrangler, but we could create it with a custom transformation.
+The **Custom Transforms** allows you to use Pyspark, Pandas, or Pyspark
+(SQL) to define your own transformations. For all three options, you use
+the variable ``df`` to access a dataframe to which you want to apply the
+transform. You do not need to include a return statement.
+
+To create a custom transformation you have to: 1. Click the plus sign
+next to a collection of transformation elements and choose Add
+transform.
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu.
+
+3. Choose Custom transform.
+
+4. Name the transformation as “Duration_Transformation” - (naming is
+ optional but good to have a structure)
+
+5. In drop down menu select Python (PySpark) and use code below. This
+ code will import functions, calculate difference between two
+ timestamps by converting them to unix format (real number) and round
+ result and drop tpep_dropoff_datetime column
+
+ .. code:: python
+
+ from pyspark.sql.functions import col, round
+ df = df.withColumn('duration', round((col("tpep_dropoff_datetime").cast("long")-col("tpep_pickup_datetime").cast("long"))/60,2))
+ df = df.drop("tpep_dropoff_datetime")
+
+6. Choose Preview
+
+7. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all
+current steps and a preview of a resulted dataset with a new column
+duration and without column tpep_dropoff_datetime
+
+Click Back to data flow.
+
+Handling missing data in numeric attributes
+-------------------------------------------
+
+We already discussed what are missing values and why it is important to
+handle them. So far, we have been working with timestamps only. Now, we
+are going to handle missing values in the rest of attributes. We can
+exclude ``duration`` feature from this operation as it was calculated
+from timestamps in the previous step. As we discussed before, there are
+several ways to handle missing data: fill a static number or calculate a
+value (for example: median or mean for last 7 days). It might make sense
+to calculate a value if your time-series represents a continuous process
+like sensor reading or product sale quantity. In our case, all trips are
+independent from each other and we cannot calculate values based on
+previous trips as it might bring data bias and increase error. We can
+replace missing values with zeros or sometimes it might make sense to
+drop the entire row with missing values.
+
+Amazon Data Wrangler has two types of transformations to handle missing
+data: i) generic and ii) specifically designed for time series data.
+Here, we demonstrate how to use both of them and describe when to use
+each of these transformations.
+
+Handle missing data with the generic “Handle missing values” transformations
+~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+This transformation can be used if you want to: 1. Replace missing
+values with a same static value for all time series 2. Replace missing
+values with a calculated value and you have only one time series (for
+example: one sensor or one product in a shop)
+
+To create this transformation you have to: 1. Click the plus sign next
+to a collection of transformation elements and choose Add transform.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/timeseries-dataflow/AddTransformMissingGeneral.png
+
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu.
+
+3. Choose Handle Missing
+
+4. For “Transform” choose Fill missing
+
+5. For “inputs columns” choose ``PULocationID``, ``tip_amount``, and
+ ``total_amount``
+
+6. For “Fill value” put 0
+
+7. Choose Preview
+
+8. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all
+current steps and a preview of a resulted dataset.
+
+Handle missing data with special Time Series transformation
+~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+In real life datasets, we have many time-series in the same dataset and
+to separate them, we use some form of IDs. For example, sensor ID or
+item SKU. If we want to replace missing values with calculated values,
+for example mean for last 10 sensor observations, we must calculate it
+based on data for each time series independently. Instead of writing
+code, you could use the special Time Series transformation in Data
+Wrangler and get this easily done!.
+
+To create this transformation you have to: 1. Click “+ Add step” orange
+button in the TRANSFORMS menu.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/timeseries-dataflow/AddStep.png
+
+
+2. Choose Time Series
+
+3. For “Transform” choose Handle missing
+
+4. For “Time series input type” choose Along column
+
+5. For “Impute missing values for this column” choose ``trip_distance``
+
+6. For “Timestamp column” choose tpep_pickup_datetime
+
+7. For “ID column” choose PULocationID
+
+8. For “Method for imputing values” choose Constant value
+
+9. For “Custom value” put 0.0
+
+10. Choose Preview
+
+11. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all
+current steps until this point in time and get a preview of the
+resulting dataset.
+
+Filter rows with invalid data
+~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+Based on our understanding of the dataset until this point, we could
+also apply several filters to remove invalid or corrupt data from a
+business point of view. This will improve data quality even further and
+ensure we feed only correct data to our model training process.
+
+We can filter data based on following rules: 1. ``tpep_pickup_datetime``
+- have to be in range from 1 Jan 2019 (included) till 1 March 2020
+(excluded) 2. ``trip_distance`` - have to be greater than or equal to 0
+(only positive numbers) 3. ``tip_amount`` - have to be greater than or
+equal to 0 (only positive numbers) 4. ``total_amount`` - have to be
+greater than or equal to 0 (only positive numbers) 5. ``duration`` -
+have to be greater than or equal to 1 (we are not interested in super
+short trips). 6. ``PULocationID`` - have to be in the range (1 to 263).
+These are the assigned zones. For the sake of brevity, let’s use only
+the 1st ten location IDs for this workshop (see image below).
+
+There is no built-in filter transformation in Data Wrangler to handle
+these various constraints. Hence, we will create a custom
+transformation.
+
+To create a custom transformation, follow the steps below: 1. Click the
+plus sign next to a collection of transformation elements and choose Add
+transform.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/timeseries-dataflow/AddTransformFilter.png
+
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu.
+
+3. Choose Custom Transform.
+
+4. In drop down menu select Python (PySpark) and use code below. This
+ code will filter rows based on the specified conditions.
+
+ .. code:: python
+
+ df = df.filter(df.trip_distance >= 0)
+ df = df.filter(df.tip_amount >= 0)
+ df = df.filter(df.total_amount >= 0)
+ df = df.filter(df.duration >= 1)
+ df = df.filter((1 <= df.PULocationID) & (df.PULocationID <= 263))
+ df = df.filter((df.tpep_pickup_datetime >= "2019-01-01 00:00:00") & (df.tpep_pickup_datetime < "2020-03-01 00:00:00"))
+
+5. Choose Preview
+
+6. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all
+current steps until this point in time and get a preview of the
+resulting dataset.
+
+Quick analysis of dataset
+-------------------------
+
+Amazon SageMaker Data Wrangler includes built-in analysis that help you
+generate visualizations and data insights in a few clicks. You can
+either leverage the built-in analyses types we offer out of the box with
+the product or create your own custom analysis using your own code if
+needed. SageMaker Data Wrangler also provides automated insights by
+automatically performing exploratory and descriptive analyses behind the
+scenes on your data. It identifies hidden anomalies and red flags within
+your dataset and proposes prescriptive actions in the form of what
+transforms can be applied on what columns of your data to fix these
+issues.
+
+For this lab, let’s use the Table Summary built-in analysis type to
+quickly summarize our existing dataset in its current form. For the
+numeric columns, including long and float data, table summary reports
+the number of entries (``count``), minimum (``min``), maximum (``max``),
+mean, and standard deviation (``stddev``) for each column. For columns
+with non-numerical data, including columns with String, Boolean, or
+DateTime data, table summary reports the number of entries (``count``),
+least frequent value (``min``), and most frequent value (``max``).
+
+To create this analysis, follow the steps below: 1. Click the plus sign
+next to a collection of transformation elements and choose “Add
+analyses”.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/timeseries-dataflow/addFirstAnalyses.png
+
+
+2. In a “analyses type” drop down menu select “Table Summary” and
+ provide a name for “Analysis name”, for example: “Cleaned dataset
+ summary”
+
+3. Choose Preview
+
+4. Choose Add to save the analyses.
+
+5. You could find your first analyses on a “Analysis” tab. All future
+ visualizations will could be also found here.
+
+6. Click on analyses icon to open it.
+
+Let’s take a look at our results. The most interesting part is the
+summary for duration column: maximum value is 1439 and this is in
+minutes! 1439 minutes = almost 24 hours and this is definitely an issue
+which will reduce the quality of our model if this dataset is used in
+its current form. This looks more like an issue due to the prevalence of
+outliers in our dataset. Next, let’s see how to issue this issue using a
+built-in transform Data Wrangler offers.
+
+Handling outliers in numeric attributes
+---------------------------------------
+
+In statistics, an outlier is a data point that differs significantly
+from other observations in the same dataset. An outlier may be due to
+variability in the measurement or it may indicate experimental error.
+The latter are sometimes excluded from the dataset. For example, in our
+dataset we have the ``tip_amount`` feature and usually it is less than
+10 dollars, but due to an error in a data collection, some values can
+show thousands of dollar as a tip. Such data errors will skew statistics
+and aggregated values which will lead to a lower model accuracy.
+
+An outlier can cause serious problems in statistical analysis. Machine
+learning models are sensitive to the distribution and range of feature
+values. Outliers, or rare values, can negatively impact model accuracy
+and lead to longer training times. When you define a Handle outliers
+transform step, the statistics used to detect outliers are generated on
+the data available in Data Wrangler when defining this step. These same
+statistics are used when running a Data Wrangler job.
+
+SageMaker Data Wrangler supports several outliers detection and handle
+methods. We are going to use **Standard Deviation Numeric Outliers** and
+we remove all outliers as our dataset is big enough. This transform
+detects and fixes outliers in numeric features using the mean and
+standard deviation. You specify the number of standard deviations a
+value must vary from the mean to be considered an outlier. For example,
+if you specify 3 for standard deviations, a value falling more than 3
+standard deviations from the mean is considered an outlier.
+
+To create this transformation, follow the steps below: 1. Click the plus
+sign next to a collection of transformation elements and choose “Add
+transform”.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/timeseries-dataflow/AddTransformOutliers.png
+
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu.
+
+3. Choose Handle Outliers.
+
+4. For “Transform” choose “Standard deviation numeric outliers”
+
+5. For “Inputs columns” choose ``tip_amount``, ``total_amount``,
+ ``duration``, and ``trip_distance``
+
+6. For “Fix method” choose “Remove”
+
+7. For “Standard deviations” put 4
+
+8. Choose Preview
+
+9. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all
+current steps and a preview of resulted dataset.
+
+Optional: If you want, you could repeat the steps from our previous
+analysis (“Quick analysis of a current dataset”) to create a new table
+summary and check for the new maximum for the ``duration`` column. You
+can see, the new max value for duration is 243 minutes = just over an
+hour. This is more realistic for long trips than what we previously had.
+
+Grouping/Aggregating data
+-------------------------
+
+At this moment we have cleaned dataset by removing outliers, invalid
+values, and added new features. There are few more steps before we start
+training our forecasting model.
+
+As we are interested in a hourly forecast we have to count number of
+trips per hour per station and also aggregate (with mean) all metrics
+such as distance, duration, tip, total amount.
+
+Truncating timestamp
+~~~~~~~~~~~~~~~~~~~~
+
+We don’t need minutes and seconds in out timestamp, so we remove them.
+There is no built-in filter transformation in SageMaker Data Wrangler,
+so we create a custom transformation.
+
+To create a custom transformation, follow the steps below:: 1. Click the
+plus sign next to a collection of transformation elements and choose
+“Add transform”.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/timeseries-dataflow/addTrandformDate.png
+
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu.
+
+3. Choose Custom Transform.
+
+4. In drop down menu select Python (PySpark) and use code below. This
+ code will create a new column with a truncated timestamp and then
+ drop original pickup column.
+
+ .. code:: python
+
+ from pyspark.sql.functions import col, date_trunc
+ df = df.withColumn('pickup_time', date_trunc("hour",col("tpep_pickup_datetime")))
+ df = df.drop("tpep_pickup_datetime")
+
+5. Choose Preview
+
+6. Choose Add to save the step
+
+When you apply the transformation on sampled data, you can see all the
+current steps until this point in time and get a preview of the
+resulting dataset with a new column ``pickup_time`` and without the old
+column ``tpep_pickup_datetime``
+
+Count number of trips per hour per station
+~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+Currently, we have only piece of information about each trip, but we
+don’t know how many trips were made from each station per hour. The
+simplest way to do that is count number of records per stationID per
+hourly timestamp. While Amazon Data Wrangler provides GroupBy
+transformation. The built-in transformation doesn’t support grouping by
+multiple columns, so we use a custom transformation.
+
+To create a custom transformation you have to: 1. Click the plus sign
+next to a collection of transformation elements and choose “Add
+transform”.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/timeseries-dataflow/addTrandformDate.png
+
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu.
+
+3. Choose Custom Transform.
+
+4. In drop down menu select Python (PySpark) and use code below. This
+ code will create a new column with a number of trips from each
+ location for each timestamp.
+
+ .. code:: python
+
+ from pyspark.sql import functions as f
+ from pyspark.sql import Window
+ df = df.withColumn('count', f.count('duration').over(Window.partitionBy([f.col("pickup_time"), f.col("PULocationID")])))
+
+5. Choose Preview
+
+6. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all
+current steps and a preview of a resulted dataset with a new column
+count.
+
+Resample time series
+--------------------
+
+Now, we are ready to make a final aggregation! We want to aggregate all
+rows by a combination of ``PULocationID`` and ``pickup_time`` columns,
+while features should be replaced by mean value for each combination.
+
+We use special built-in Time Series transformation **Resample**. The
+Resample transformation changes the frequency of the time series
+observations to a specified granularity. It also comes with both
+upsampling and downsampling options. Applying upsampling increases the
+frequency of the observations, for example from daily to hourly, whereas
+downsampling decreases the frequency of the observations, for example
+from hourly to daily.
+
+To create this transformation, follow the steps below: 1. Click the plus
+sign next to a collection of transformation elements and choose Add
+transform.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/timeseries-dataflow/AddResample.png
+
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu.
+
+3. Choose Time Series.
+
+4. For “Transform” choose “Resample”
+
+5. For “Timestamp” choose ``pickup_time``
+
+6. For “ID column” choose ``PULocationID``
+
+7. For “Frequency unit” choose “Hourly”
+
+8. For “Frequency quantity” put 1
+
+9. For “Method to aggregate numeric values” choose “mean”
+
+10. Use default values for the rest of parameters
+
+11. Choose Preview
+
+12. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all
+current steps and a preview of a resulted dataset.
+
+.. _resample-time-series-1:
+
+Resample time series
+--------------------
+
+Now we are ready to make a final aggregation! We aggregate all rows by
+combination of ``PULocationID`` and ``pickup_time`` timestamp while
+features should be replaced by mean value for each combination.
+
+We use special built-in Time Series transformation **Resample**. The
+Resample transformation changes the frequency of the time series
+observations to a specified granularity. It also comes with both
+upsampling and downsampling options. Applying upsampling increases the
+frequency of the observations, for example from daily to hourly, whereas
+downsampling decreases the frequency of the observations, for example
+from hourly to daily.
+
+To create this transformation you have to: 1. Click the plus sign next
+to a collection of transformation elements and choose Add transform.
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/timeseries-dataflow/AddResample.png
+
+
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu.
+
+3. Choose Time Series.
+
+4. For “Transform” choose “Resample”
+
+5. For “Timestamp” choose pickup_time
+
+6. For “ID column” choose “PULocationID”
+
+7. For “Frequency unit” choose “Hourly”
+
+8. For “Frequency quantity” put 1
+
+9. For “Method to aggregate numeric values” choose “mean”
+
+10. Use default values for the rest of parameters
+
+11. Choose Preview
+
+12. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all
+current steps until this point in time and get a preview of the
+resulting dataset.
+
+`here `__.
+
+Featurize Date Time
+-------------------
+
+“Featurize datetime” time series transformation will add the month, day
+of the month, day of the year, week of the year, hour and quarter
+features to our dataset. Because we’re providing the date/time
+components as separate features, we enable ML algorithms to detect
+signals and patterns for improving prediction accuracy.
+
+To create this transformation you have to: 1. Click the plus sign next
+to a collection of transformation elements and choose Add transform
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu
+
+3. Choose Time Series
+
+ - For “Transform” choose “Featurize date/time”
+
+ - For “Input Column” choose ``pickup_time``
+
+ - For “Output Column” enter “date”
+
+ - For “Output mode” choose “Ordinal”
+
+ - For “Output format” choose “Columns”
+
+ - For date/time features to extract, select Year, Month, Day, Hour,
+ Week of year, Day of year, and Quarter.
+
+4. Choose Preview
+
+5. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all
+current steps until this point in time and get a preview of the
+resulting dataset.
+
+Click “Back to data flow” to head back to the block diagram editor
+window.
+
+Lag feature
+-----------
+
+Next let’s create lag features for the target column count. Lag features
+in time-series analysis are values at prior timestamps that are
+considered helpful in inferring future values. They also help identify
+**autocorrelation**, also known as serial correlation, patterns in the
+residual series by quantifying the relationship of the observation with
+observations at previous time steps. Autocorrelation is similar to
+regular correlation but between the values in a series and its past
+values. It forms the basis for the **autoregressive forecasting** models
+in the **ARIMA** series.
+
+With SageMaker Data Wrangler’s Lag feature transform, you can easily
+create lag features n periods apart. Additionally, we often want to
+create multiple lag features at different lags and let the model decide
+the most meaningful features. For such a scenario, the **Lag features**
+transform helps create multiple lag columns over a specified window
+size.
+
+To create this transformation, follow the steps below: 1. Click the plus
+sign next to a collection of transformation elements and choose Add
+transform.
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu.
+
+3. Choose Time Series
+
+ - For “Transform” choose “Lag features”
+
+ - For “Generate lag features for this column” choose “count”
+
+ - For “ID column” enter “PULocationID”
+
+ - For “Timestamp Column” choose “pickup_time”
+
+ - For Lag, enter 8. You could try to use different values, maybe 24
+ hours in our case makes more sense.
+
+ - Because we’re interested in observing up to the previous 8 lag
+ values, let’s select Include the entire lag window.
+
+ - To create a new column for each lag value, select Flatten the
+ output
+
+4. Choose Preview
+
+5. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all
+current steps and a preview of a resulted dataset.
+
+Rolling window features
+-----------------------
+
+We can also calculate meaningful statistical summaries across a range of
+values and include them as input features. Let’s extract common
+statistical time series features.
+
+Data Wrangler implements automatic time series feature extraction
+capabilities using the open source ``tsfresh`` package. With the time
+series feature extraction transforms, you can automate the feature
+extraction process. This eliminates the time and effort otherwise spent
+manually implementing signal processing libraries. We will extract
+features using the **Rolling window** features transform. This method
+computes statistical properties across a set of observations defined by
+the window size.
+
+To create this transformation you have to: 1. Click the plus sign next
+to a collection of transformation elements and choose Add transform
+
+2. Click “+ Add step” orange button in the TRANSFORMS menu.
+
+3. Choose Time Series
+
+ - For “Transform” choose “Rolling window features”
+
+ - For “Generate rolling window features for this column” choose
+ “count”
+
+ - For “Timestamp Column” choose “pickup_time”
+
+ - For “ID column” enter ``PULocationID``
+
+ - For “Window size”, enter 8. You could try to use different values,
+ maybe 24 hours in our case makes more sense.
+
+ - Select Flatten to create a new column for each computed feature.
+
+ - Choose “Strategy” as “Minimal subset”. This strategy extracts
+ eight features that are useful in downstream analyses. Other
+ strategies include Efficient Subset, Custom subset, and All
+ features.
+
+4. Choose Preview
+
+5. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all
+current steps until this point in time and get a preview of the
+resulting dataset.
+
+Click “Back to data flow” to head back to the block diagram editor
+window.
+
+Export Data
+-----------
+
+At this stage, we have a new dataset that is cleaned and transformed
+with newly engineered features. This dataset can be used for forecasting
+either using open source libraries/frameworks or AWS services like
+`Amazon SageMaker
+Autopilot `__, `Amazon
+SageMaker Canvas `__ or
+`Amazon Forecast `__.
+
+Given, we had only used a sample of the dataset for creating our data
+preparation and transformation recipe so far, what need to do next is to
+apply the same recipe (data flow) on our entire dataset and scale the
+whole process in a distributed fashion. Amazon Data Wrangler let’s you
+do this in multiple ways. You can export your data flow: 1/ as a
+processing job, 2/ as a SageMaker pipeline step, or 3/ as a Python
+script. You can also kick-off these distributed jobs via the UI without
+writing any code using Data Wrangler’s destination node option. The
+export options are also facilitated via SageMaker Studio notebooks
+(Jupyter). Additionally, the transformed features can also be ingested
+directly to SageMaker Feature Store.
+
+For this lab, we will see how to use the destination nodes option to
+export the transformed features to S3 via a distributed PySpark job
+powered by SageMaker Processing.
+
+Exporting to S3 using Destination Nodes
+~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+This option creates a SageMaker processing job which uses the data flow
+(recipe) we have created previously to kick-off a distributed processing
+job on the “entire” dataset saving the results to a specified S3 bucket.
+
+Additionally, you can also drop columns if needed right before the
+export step. For the sake of brevity and to simplify the prediction
+problem statement, let’s drop all columns except three columns
+``pickup_time``, ``count``, ``PULocationID``. Here count is the target
+variable we will try to predict. ``pickup_time`` and ``PULocationID``
+will be our feature columns used for modeling. To create the model, we
+will be using SageMaker Autopilot. This will be covered in the next 2
+sections.
+
+Follow the next steps to setup export to S3. 1. Click the plus sign next
+to a collection of transformation elements and choose **“Add
+destination” -> “Amazon S3”**
+
+.. figure:: https://s3.amazonaws.com/sagemaker-sample-files/images/sagemaker-datawrangler/timeseries-dataflow/addDestination.png
+
+
+2. Provide parameters for S3 destination:
+
+ - Dataset name - name for new dataset, for example used “NYC_export”
+ - File type - CSV
+ - Delimiter - Comma
+ - Compression - none
+ - Amazon S3 location - You can use the same bucket name which we
+ created at the beginning
+
+3. Click “Add destination” orange button
+
+4. Now your dataflow has a final step and you see a new “Create job”
+ orange button. Click it.
+
+5. Provide a “Job name” or keep autogenerated option and select
+ “destination”. We have only one “S3:NYC_export”, but you might have
+ multiple destinations from different steps in your workflow. Leave a
+ “KMS key ARN” field empty and click “Next” orange button.
+
+6. Now your have to provide configuration for a compute capacity for a
+ job. You can keep all defaults values:
+
+ - For Instance type use “ml.m5.4xlarge”
+ - For Instance count use “2”
+ - You can explore “Additional configuration”, but keep them without
+ change.
+ - Click “Run” orange button
+
+7. Now your job is started and it takes about 1 hour to process 6 GB of
+ data according to our Data Wrangler processing flow. Cost for this
+ job will be around 2 USD as “ml.m5.4xlarge” cost 0.922 USD per hour
+ and we are using two of them.
+
+8. If you click on the job name you will be redirected to a new window
+ with the job details. On the job details page you see all parameters
+ from a previous steps.
+
+Approximately in one hour you should see that job status changed to
+“Completed” and you could also check “Processing time (seconds)” value.
+
+Now you could close job details page.
+
+Check Processed output
+----------------------
+
+After the SageMaker Data Wrangler processing job is completed, we can
+check the results saved in our destination S3 bucket.
+
+At this stage, you have designed a data flow for data processing and
+feature engineering and successfully launched it. Of course it is not
+mandatory to always run a job by clicking on the “Run” button. You could
+also automate it, but this is a topic of another workshop in this
+series!
+
+.. container:: alert alert-info
+
+ 💡 Congratulations! You reached the end of this part. Now you know
+ how to use Amazon SageMaker Data Wrangler for time series dataset
+ preparation!
+
+ ::
+
+Import Dataflow
+----------------------------
+
+Here is the final `Flow file
+`__ available which you can directly import to expediate the process or validate the flow.
+
+Here are the steps to import the flow
+
+* Download the flow file
+
+* In Sagemaker Studio, drag and drop the flow file or use the upload button to browse the flow and upload
+
+
+Clean up
+-----------------------------------------------------
+
+- Delete artifacts in S3.
+- Delete data flow file in SageMaker Studio.
+- Stop active SageMaker Data Wrangler instance.
+- Delete SageMaker user profile and domain (optional).
diff --git a/sagemaker-datawrangler/timeseries-dataflow/readme.md b/sagemaker-datawrangler/timeseries-dataflow/readme.md
new file mode 100644
index 0000000000..21ad358746
--- /dev/null
+++ b/sagemaker-datawrangler/timeseries-dataflow/readme.md
@@ -0,0 +1,780 @@
+# Amazon SageMaker Data Wrangler time series workshop
+
+Our end goal for this lab is to prepare a time-series dataset and get it to a ready state for ML modeling. We will start with the New York city (NYC) yellow cab time-series dataset and work towards exploring, preparing and transforming the dataset to help us design a ML model that will predict the number of NYC yellow taxi pickups for any hour of the day and location. As part of the exercise, we will learn how to derive various insights about the trip like average tip value, average distance for the trip, etc.
+
+Data used in this demo:
+- Original data source for all open data from 2008 to Current can be accessed here: https://www1.nyc.gov/site/tlc/about/tlc-trip-record-data.page
+- AWS-hosted location: https://registry.opendata.aws/nyc-tlc-trip-records-pds/
+
+The taxi trip records include fields capturing pick-up and drop-off dates/times, pick-up and drop-off locations, trip distances, itemized fares, rate types, payment types, and driver-reported passenger counts. The raw data is split 1 month per file, per Yellow, Green, or ForHire from 2008 through 2020, with each file around 600 MB. The entire raw dataset is huge. For our lab, we will use 13 of these files of around a year's worth of trip data and focus only on the iconic yellow cab trips. We picked trip data from Feb 2019 to Feb 2020 to avoid COVID effects. The data dictionary below describes the Yellow taxi trip data with raw feature column names and their respective descriptions. The picked dataset covers 13 months and encapsulates approximately 90 million trips.
+
+ +
+
+## Instructions to download the dateset
+You can use SageMaker Data Wrangler to import data from the following data sources: Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift, and Snowflake. The dataset that you import can include up to 1000 columns. For this lab, we will be using Amazon S3 as the preferred data source. Before we import the dataset into SageMaker Data Wrangler, let's ensure we copy the dataset first from the publicly hosted location to our local S3 bucket in our own account.
+
+To copy the dataset, copy and execute the Python code below within SageMaker Studio. It is recommended to execute this code in a notebook setting. We also recommend to have your S3 bucket in the same region as SageMaker Data Wrangler.
+
+To create a SageMaker Studio notebook, from the launcher page, click on the ***Notebook Python 3*** options under ***Notebooks and compute resources*** as show in the figure below.
+
+
+
+
+## Instructions to download the dateset
+You can use SageMaker Data Wrangler to import data from the following data sources: Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift, and Snowflake. The dataset that you import can include up to 1000 columns. For this lab, we will be using Amazon S3 as the preferred data source. Before we import the dataset into SageMaker Data Wrangler, let's ensure we copy the dataset first from the publicly hosted location to our local S3 bucket in our own account.
+
+To copy the dataset, copy and execute the Python code below within SageMaker Studio. It is recommended to execute this code in a notebook setting. We also recommend to have your S3 bucket in the same region as SageMaker Data Wrangler.
+
+To create a SageMaker Studio notebook, from the launcher page, click on the ***Notebook Python 3*** options under ***Notebooks and compute resources*** as show in the figure below.
+
+ +
+Copy and paste the shared code snippet below into the launched notebook's cell (shown below) and execute it by clicking on the play icon on the top bar.
+
+
+
+Copy and paste the shared code snippet below into the launched notebook's cell (shown below) and execute it by clicking on the play icon on the top bar.
+
+ +
+
+```python
+import boto3
+import json
+
+
+# Setup
+REGION = 'us-east-1'
+account_id = boto3.client('sts').get_caller_identity().get('Account')
+bucket_name = f'{account_id}-{REGION}-dw-ts-lab'
+
+
+# Create S3 bucket to download dataset in your account
+s3 = boto3.resource('s3')
+
+if REGION == 'us-east-1':
+ s3.create_bucket(Bucket=bucket_name)
+else:
+ s3.create_bucket(Bucket=bucket_name,CreateBucketConfiguration={'LocationConstraint': REGION})
+ # Copy dataset from public hosted location to your S3 bucket
+trips = [
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-02.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-03.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-04.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-05.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-06.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-07.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-08.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-09.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-10.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-11.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-12.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2020-01.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2020-02.parquet'}
+]
+for trip in trips:
+ s3.meta.client.copy(trip, bucket_name, trip['Key'])
+```
+
+Now we have raw data in our S3 bucket and ready to explore it and build a training dataset
+
+## Dataset Import
+
+Our first step is to launch a new SageMaker Data Wrangler session and there are multiple ways how to do that. For example, use the following:
+
+Click File -> New -> Data Wrangler Flow
+
+
+
+
+```python
+import boto3
+import json
+
+
+# Setup
+REGION = 'us-east-1'
+account_id = boto3.client('sts').get_caller_identity().get('Account')
+bucket_name = f'{account_id}-{REGION}-dw-ts-lab'
+
+
+# Create S3 bucket to download dataset in your account
+s3 = boto3.resource('s3')
+
+if REGION == 'us-east-1':
+ s3.create_bucket(Bucket=bucket_name)
+else:
+ s3.create_bucket(Bucket=bucket_name,CreateBucketConfiguration={'LocationConstraint': REGION})
+ # Copy dataset from public hosted location to your S3 bucket
+trips = [
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-02.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-03.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-04.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-05.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-06.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-07.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-08.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-09.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-10.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-11.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2019-12.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2020-01.parquet'},
+ {'Bucket': 'nyc-tlc', 'Key': 'trip data/yellow_tripdata_2020-02.parquet'}
+]
+for trip in trips:
+ s3.meta.client.copy(trip, bucket_name, trip['Key'])
+```
+
+Now we have raw data in our S3 bucket and ready to explore it and build a training dataset
+
+## Dataset Import
+
+Our first step is to launch a new SageMaker Data Wrangler session and there are multiple ways how to do that. For example, use the following:
+
+Click File -> New -> Data Wrangler Flow
+
+  +
+Amazon SageMaker will start to provision a resources for you and you a could find a new Data Wrangler Flow file in a File Browser section
+
+
+
+Amazon SageMaker will start to provision a resources for you and you a could find a new Data Wrangler Flow file in a File Browser section
+
+  +
+Lets rename our new workflow: Right click on file -> Rename Data Wrangler Flow
+
+
+
+Lets rename our new workflow: Right click on file -> Rename Data Wrangler Flow
+
+ +
+Put a new name, for example: `TS-Workshop-DataPreparation.flow`
+
+
+
+Put a new name, for example: `TS-Workshop-DataPreparation.flow`
+
+ +
+In few minutes Data Wrangler will finish to provision resources and you could see "Import Data" screen.
+SageMaker Data Wrangler supports many data sources: Amazon S3, Amazon Athena, Amazon Redshift, Snowflake, Databricks.
+Our data already in S3, let's import it by clicking "Amazon S3" button.
+
+
+
+
+In few minutes Data Wrangler will finish to provision resources and you could see "Import Data" screen.
+SageMaker Data Wrangler supports many data sources: Amazon S3, Amazon Athena, Amazon Redshift, Snowflake, Databricks.
+Our data already in S3, let's import it by clicking "Amazon S3" button.
+
+
+ +
+You will see all your S3 buckets so please search for your bucket (if you used provided code the bucket will have a suffix dw-ts-lab)
+
+
+
+You will see all your S3 buckets so please search for your bucket (if you used provided code the bucket will have a suffix dw-ts-lab)
+
+ +
+All the files required for this lab are in "trip data" folder, so let's select it. SageMaker Data Wrangler will import all files from a folder and sample up to 100 MB of data for an interactive preview. On a right side menu you could customize import job settings like Name, File type, Delimiter, etc. More information about import process could be found [here](https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler-import.html).
+
+
+To finish setting up import step select "parquet" in "File type" drop down menu and press the orange button "Import"
+
+
+
+All the files required for this lab are in "trip data" folder, so let's select it. SageMaker Data Wrangler will import all files from a folder and sample up to 100 MB of data for an interactive preview. On a right side menu you could customize import job settings like Name, File type, Delimiter, etc. More information about import process could be found [here](https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler-import.html).
+
+
+To finish setting up import step select "parquet" in "File type" drop down menu and press the orange button "Import"
+
+ +
+
+It will take a few minutes to import data and validate it. SageMaker Data Wrangler will automatically recognize data types. You should see "Validation complete 0 errors message"
+
+
+
+
+It will take a few minutes to import data and validate it. SageMaker Data Wrangler will automatically recognize data types. You should see "Validation complete 0 errors message"
+
+ +
+
+# Change data types
+
+First we will check the data types were correctly recognized. This might be necessary as Data Wrangler selects data types based on a sampled data which is limited to 50000 rows. Sampled data might potentially miss some variations.
+
+
+To add a data transformation step use the plus sign next to Data types and choose Edit data types as shown below.
+
+
+
+
+# Change data types
+
+First we will check the data types were correctly recognized. This might be necessary as Data Wrangler selects data types based on a sampled data which is limited to 50000 rows. Sampled data might potentially miss some variations.
+
+
+To add a data transformation step use the plus sign next to Data types and choose Edit data types as shown below.
+
+ +
+
+In our case several columns were incorrectly recognized:
+- `passenger_count` (must be `long` instead of `float`)
+- `RatecodeID` (must be `long` instead of `float`)
+- `airport_fee` (must be `float` instead of `long`)
+
+I know correct data types from dataset description. In real life you could also easily find such information. Let's correct data types by selecting a correct type from a drop down menu.
+
+
+
+
+In our case several columns were incorrectly recognized:
+- `passenger_count` (must be `long` instead of `float`)
+- `RatecodeID` (must be `long` instead of `float`)
+- `airport_fee` (must be `float` instead of `long`)
+
+I know correct data types from dataset description. In real life you could also easily find such information. Let's correct data types by selecting a correct type from a drop down menu.
+
+ +
+
+Click Preview and then Apply button.
+
+Click Back to data flow.
+
+# Dataset preparation
+## Drop columns
+
+Before we analyze data and do feature engineering we have to clean dataset and below steps show how to remove unwanted data.
+
+To re-iterate our business goal:
+Predict the number of NY City yellow taxi pickups in the next 24 hour for each pickup per hour zones and provide some insights for drivers like average tips, average distance, etc.
+
+As we are interested in per hour forecast we have to aggregate some features and remove features which are impossible to aggregate. For this purpose we don't need the following columns:
+
+1. `VendorID` (A code indicating the TPEP provider that provided the record)
+2. `RatecodeID` (The final rate code in effect at the end of the trip)
+3. `Store_and_fwd_flag` (This flag indicates whether the trip record was held in vehicle memory before sending to the vendor, aka “store and forward,”because the vehicle did not have a connection to the server)
+4. `DOLocationID` (TLC Taxi Zone in which the taximeter was disengaged)
+5. `Payment_type` (A numeric code signifying how the passenger paid for the trip)
+6. `Fare_amount` (The time-and-distance fare calculated by the meter) - we will use total amount feature
+7. `Extra` (Miscellaneous extras and surcharges)
+8. `MTA_tax` (0.50 MTA tax that is automatically triggered based on the metered rate in use)
+9. `Tolls_amount` (Total amount of all tolls paid in trip)
+10. `Improvement_surcharge` (improvement surcharge assessed trips at the flag drop. The improvement surcharge began being levied in 2015)
+11. `Passenger_count` (This is a driver-entered value)
+12. `congestion_surcharge` (Total amount collected in trip for NYS congestion surcharge)
+13. `Airport_fee` (Only at LaGuardia and John F. Kennedy Airports)
+
+To remove those columns:
+1. Click the plus sign next to "Data types" element and choose Add transform.
+
+
+
+
+Click Preview and then Apply button.
+
+Click Back to data flow.
+
+# Dataset preparation
+## Drop columns
+
+Before we analyze data and do feature engineering we have to clean dataset and below steps show how to remove unwanted data.
+
+To re-iterate our business goal:
+Predict the number of NY City yellow taxi pickups in the next 24 hour for each pickup per hour zones and provide some insights for drivers like average tips, average distance, etc.
+
+As we are interested in per hour forecast we have to aggregate some features and remove features which are impossible to aggregate. For this purpose we don't need the following columns:
+
+1. `VendorID` (A code indicating the TPEP provider that provided the record)
+2. `RatecodeID` (The final rate code in effect at the end of the trip)
+3. `Store_and_fwd_flag` (This flag indicates whether the trip record was held in vehicle memory before sending to the vendor, aka “store and forward,”because the vehicle did not have a connection to the server)
+4. `DOLocationID` (TLC Taxi Zone in which the taximeter was disengaged)
+5. `Payment_type` (A numeric code signifying how the passenger paid for the trip)
+6. `Fare_amount` (The time-and-distance fare calculated by the meter) - we will use total amount feature
+7. `Extra` (Miscellaneous extras and surcharges)
+8. `MTA_tax` (0.50 MTA tax that is automatically triggered based on the metered rate in use)
+9. `Tolls_amount` (Total amount of all tolls paid in trip)
+10. `Improvement_surcharge` (improvement surcharge assessed trips at the flag drop. The improvement surcharge began being levied in 2015)
+11. `Passenger_count` (This is a driver-entered value)
+12. `congestion_surcharge` (Total amount collected in trip for NYS congestion surcharge)
+13. `Airport_fee` (Only at LaGuardia and John F. Kennedy Airports)
+
+To remove those columns:
+1. Click the plus sign next to "Data types" element and choose Add transform.
+
+  +
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+  +
+
+3. Choose Manage columns. \
+
+
+
+
+3. Choose Manage columns. \
+
+  +
+
+4. For Transform, choose Drop column and for Column to drop, choose all mentioned above.
+
+
+
+
+4. For Transform, choose Drop column and for Column to drop, choose all mentioned above.
+
+  +
+
+5. Choose Preview
+6. Choose Add to save the step.
+
+Once transformation is applied on a sampled data you should see all current steps and a preview of a resulted dataset like show here.
+
+
+
+
+5. Choose Preview
+6. Choose Add to save the step.
+
+Once transformation is applied on a sampled data you should see all current steps and a preview of a resulted dataset like show here.
+
+  +
+Click Back to data flow.
+
+## Handle missing and invalid data in timestamps
+Missing data is a common problem in real life, it could be a result of data corruption, data loss or issues in data ingestion. The best practice is to verify the presence of any missing or invalid values and handle them appropriately.
+
+There are many different strategies how missing or invalid data could be handled, for example dropping rows with missing values or filling the missing values with static or calculated values. Depending on dataset size you could choose what to do: fix values or just drop them. The **Time Series - Handle missing** transform allows you to choose from multiple strategies.
+
+All future aggregations will be based on time stamps, so we have to make sure that we don't have any rows with missing time stamps ( `tpep_pickup_datetime` and `tpep_dropoff_datetime` features). SageMaker Data Wrangler has several time series specific transformations, including **Validate timestamps** which checks for scenarios:
+1. Checking timestamp column for any missing values.
+2. Validate the timestamp columns for the desired timestamp format.
+
+To validate timestamps in `tpep_dropoff_datetime` and `tpep_pickup_datetime` columns:
+1. Click the plus sign next to "Drop columns" element and choose Add transform.
+
+
+
+Click Back to data flow.
+
+## Handle missing and invalid data in timestamps
+Missing data is a common problem in real life, it could be a result of data corruption, data loss or issues in data ingestion. The best practice is to verify the presence of any missing or invalid values and handle them appropriately.
+
+There are many different strategies how missing or invalid data could be handled, for example dropping rows with missing values or filling the missing values with static or calculated values. Depending on dataset size you could choose what to do: fix values or just drop them. The **Time Series - Handle missing** transform allows you to choose from multiple strategies.
+
+All future aggregations will be based on time stamps, so we have to make sure that we don't have any rows with missing time stamps ( `tpep_pickup_datetime` and `tpep_dropoff_datetime` features). SageMaker Data Wrangler has several time series specific transformations, including **Validate timestamps** which checks for scenarios:
+1. Checking timestamp column for any missing values.
+2. Validate the timestamp columns for the desired timestamp format.
+
+To validate timestamps in `tpep_dropoff_datetime` and `tpep_pickup_datetime` columns:
+1. Click the plus sign next to "Drop columns" element and choose Add transform.
+
+ 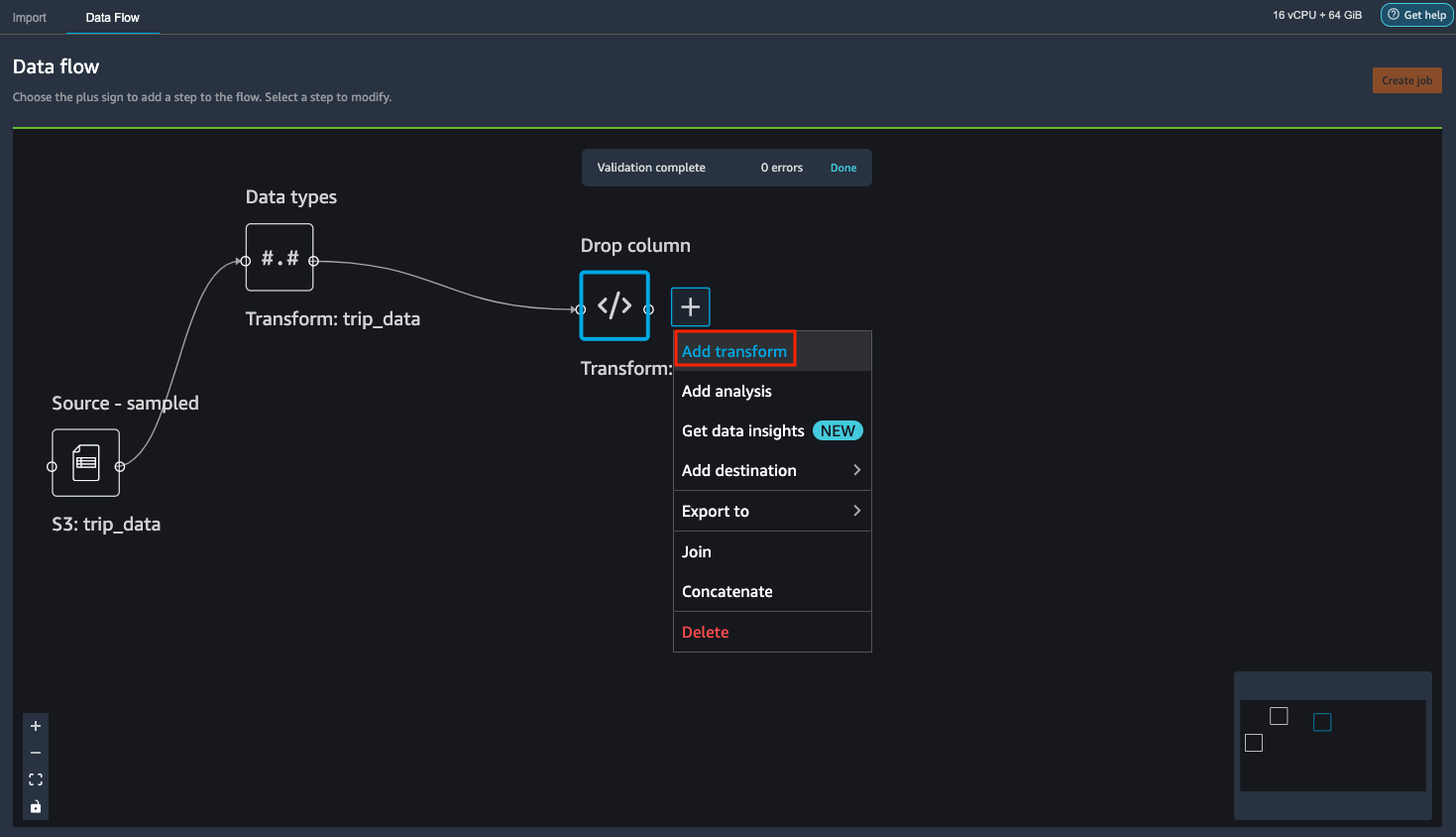 +
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Time Series.
+
+
+
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Time Series.
+
+  +
+4. For Transform choose Validate Timestamps, For TimeStamp columns choose `tpep_pickup_datetime`, for Policy select drop.
+
+
+
+4. For Transform choose Validate Timestamps, For TimeStamp columns choose `tpep_pickup_datetime`, for Policy select drop.
+
+  +
+5. Choose Preview
+6. Choose Add to save the step.
+7. Repeat same steps again for `tpep_dropoff_datetime` column
+
+When you apply a transformation a sampled data you should see all current steps and a preview of a resulted dataset.
+
+
+
+5. Choose Preview
+6. Choose Add to save the step.
+7. Repeat same steps again for `tpep_dropoff_datetime` column
+
+When you apply a transformation a sampled data you should see all current steps and a preview of a resulted dataset.
+
+ +
+Click Back to data flow.
+
+
+## Feature engineering based on a timestamp with a custom transformation.
+
+At this stage we have pickup and drop-off timestamps, but we are more interested in pickup timestamp and ride duration. We have to create a new feature `ride duration` as a difference between pick up and drop off time in minutes. There is no built-in date difference transformation in a Data Wrangler, but we could create it with a custom transformation. The **Custom Transforms** allows you to use Pyspark, Pandas, or Pyspark (SQL) to define your own transformations. For all three options, you use the variable `df` to access a dataframe to which you want to apply the transform. You do not need to include a return statement.
+
+To create a custom transformation you have to:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform.
+
+
+
+Click Back to data flow.
+
+
+## Feature engineering based on a timestamp with a custom transformation.
+
+At this stage we have pickup and drop-off timestamps, but we are more interested in pickup timestamp and ride duration. We have to create a new feature `ride duration` as a difference between pick up and drop off time in minutes. There is no built-in date difference transformation in a Data Wrangler, but we could create it with a custom transformation. The **Custom Transforms** allows you to use Pyspark, Pandas, or Pyspark (SQL) to define your own transformations. For all three options, you use the variable `df` to access a dataframe to which you want to apply the transform. You do not need to include a return statement.
+
+To create a custom transformation you have to:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform.
+
+  +
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Custom transform.
+
+
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Custom transform.
+
+  +
+4. Name the transformation as "Duration_Transformation" - (naming is optional but good to have a structure)
+5. In drop down menu select Python (PySpark) and use code below. This code will import functions, calculate difference between two timestamps by converting them to unix format (real number) and round result and drop tpep_dropoff_datetime column
+
+ ```Python
+ from pyspark.sql.functions import col, round
+ df = df.withColumn('duration', round((col("tpep_dropoff_datetime").cast("long")-col("tpep_pickup_datetime").cast("long"))/60,2))
+ df = df.drop("tpep_dropoff_datetime")
+ ```
+
+
+4. Name the transformation as "Duration_Transformation" - (naming is optional but good to have a structure)
+5. In drop down menu select Python (PySpark) and use code below. This code will import functions, calculate difference between two timestamps by converting them to unix format (real number) and round result and drop tpep_dropoff_datetime column
+
+ ```Python
+ from pyspark.sql.functions import col, round
+ df = df.withColumn('duration', round((col("tpep_dropoff_datetime").cast("long")-col("tpep_pickup_datetime").cast("long"))/60,2))
+ df = df.drop("tpep_dropoff_datetime")
+ ```
+  +
+6. Choose Preview
+7. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all current steps and a preview of a resulted dataset with a new column duration and without column tpep_dropoff_datetime
+
+
+
+6. Choose Preview
+7. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all current steps and a preview of a resulted dataset with a new column duration and without column tpep_dropoff_datetime
+
+  +
+Click Back to data flow.
+
+## Handling missing data in numeric attributes
+
+We already discussed what are missing values and why it is important to handle them. So far, we have been working with timestamps only. Now, we are going to handle missing values in the rest of attributes. We can exclude `duration` feature from this operation as it was calculated from timestamps in the previous step. As we discussed before, there are several ways to handle missing data: fill a static number or calculate a value (for example: median or mean for last 7 days). It might make sense to calculate a value if your time-series represents a continuous process like sensor reading or product sale quantity. In our case, all trips are independent from each other and we cannot calculate values based on previous trips as it might bring data bias and increase error. We can replace missing values with zeros or sometimes it might make sense to drop the entire row with missing values.
+
+Amazon Data Wrangler has two types of transformations to handle missing data: i) generic and ii) specifically designed for time series data. Here, we demonstrate how to use both of them and describe when to use each of these transformations.
+
+### Handle missing data with the generic "Handle missing values" transformations
+
+This transformation can be used if you want to:
+1. Replace missing values with a same static value for all time series
+2. Replace missing values with a calculated value and you have only one time series (for example: one sensor or one product in a shop)
+
+To create this transformation you have to:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform.
+
+
+
+Click Back to data flow.
+
+## Handling missing data in numeric attributes
+
+We already discussed what are missing values and why it is important to handle them. So far, we have been working with timestamps only. Now, we are going to handle missing values in the rest of attributes. We can exclude `duration` feature from this operation as it was calculated from timestamps in the previous step. As we discussed before, there are several ways to handle missing data: fill a static number or calculate a value (for example: median or mean for last 7 days). It might make sense to calculate a value if your time-series represents a continuous process like sensor reading or product sale quantity. In our case, all trips are independent from each other and we cannot calculate values based on previous trips as it might bring data bias and increase error. We can replace missing values with zeros or sometimes it might make sense to drop the entire row with missing values.
+
+Amazon Data Wrangler has two types of transformations to handle missing data: i) generic and ii) specifically designed for time series data. Here, we demonstrate how to use both of them and describe when to use each of these transformations.
+
+### Handle missing data with the generic "Handle missing values" transformations
+
+This transformation can be used if you want to:
+1. Replace missing values with a same static value for all time series
+2. Replace missing values with a calculated value and you have only one time series (for example: one sensor or one product in a shop)
+
+To create this transformation you have to:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform.
+
+  +
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Handle Missing
+
+
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Handle Missing
+
+  +
+4. For "Transform" choose Fill missing
+
+5. For "inputs columns" choose `PULocationID`, `tip_amount`, and `total_amount`
+
+6. For "Fill value" put 0
+
+
+
+4. For "Transform" choose Fill missing
+
+5. For "inputs columns" choose `PULocationID`, `tip_amount`, and `total_amount`
+
+6. For "Fill value" put 0
+
+  +
+7. Choose Preview
+8. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all current steps and a preview of a resulted dataset.
+
+
+
+7. Choose Preview
+8. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all current steps and a preview of a resulted dataset.
+
+ +
+### Handle missing data with special Time Series transformation
+
+In real life datasets, we have many time-series in the same dataset and to separate them, we use some form of IDs. For example, sensor ID or item SKU. If we want to replace missing values with calculated values, for example mean for last 10 sensor observations, we must calculate it based on data for each time series independently. Instead of writing code, you could use the special Time Series transformation in Data Wrangler and get this easily done!.
+
+To create this transformation you have to:
+1. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+
+2. Choose Time Series
+
+
+
+3. For "Transform" choose Handle missing
+
+4. For "Time series input type" choose Along column
+
+5. For "Impute missing values for this column" choose `trip_distance`
+
+6. For "Timestamp column" choose tpep_pickup_datetime
+
+7. For "ID column" choose PULocationID
+
+8. For "Method for imputing values" choose Constant value
+
+9. For "Custom value" put 0.0
+
+
+
+### Handle missing data with special Time Series transformation
+
+In real life datasets, we have many time-series in the same dataset and to separate them, we use some form of IDs. For example, sensor ID or item SKU. If we want to replace missing values with calculated values, for example mean for last 10 sensor observations, we must calculate it based on data for each time series independently. Instead of writing code, you could use the special Time Series transformation in Data Wrangler and get this easily done!.
+
+To create this transformation you have to:
+1. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+
+2. Choose Time Series
+
+
+
+3. For "Transform" choose Handle missing
+
+4. For "Time series input type" choose Along column
+
+5. For "Impute missing values for this column" choose `trip_distance`
+
+6. For "Timestamp column" choose tpep_pickup_datetime
+
+7. For "ID column" choose PULocationID
+
+8. For "Method for imputing values" choose Constant value
+
+9. For "Custom value" put 0.0
+
+  +
+10. Choose Preview
+11. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all current steps until this point in time and get a preview of the resulting dataset.
+
+
+
+10. Choose Preview
+11. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all current steps until this point in time and get a preview of the resulting dataset.
+
+ +
+### Filter rows with invalid data
+
+Based on our understanding of the dataset until this point, we could also apply several filters to remove invalid or corrupt data from a business point of view. This will improve data quality even further and ensure we feed only correct data to our model training process.
+
+We can filter data based on following rules:
+1. `tpep_pickup_datetime` - have to be in range from 1 Jan 2019 (included) till 1 March 2020 (excluded)
+2. `trip_distance` - have to be greater than or equal to 0 (only positive numbers)
+3. `tip_amount` - have to be greater than or equal to 0 (only positive numbers)
+4. `total_amount` - have to be greater than or equal to 0 (only positive numbers)
+5. `duration` - have to be greater than or equal to 1 (we are not interested in super short trips).
+6. `PULocationID` - have to be in the range (1 to 263). These are the assigned zones. For the sake of brevity, let's use only the 1st ten location IDs for this workshop (see image below).
+
+
+
+### Filter rows with invalid data
+
+Based on our understanding of the dataset until this point, we could also apply several filters to remove invalid or corrupt data from a business point of view. This will improve data quality even further and ensure we feed only correct data to our model training process.
+
+We can filter data based on following rules:
+1. `tpep_pickup_datetime` - have to be in range from 1 Jan 2019 (included) till 1 March 2020 (excluded)
+2. `trip_distance` - have to be greater than or equal to 0 (only positive numbers)
+3. `tip_amount` - have to be greater than or equal to 0 (only positive numbers)
+4. `total_amount` - have to be greater than or equal to 0 (only positive numbers)
+5. `duration` - have to be greater than or equal to 1 (we are not interested in super short trips).
+6. `PULocationID` - have to be in the range (1 to 263). These are the assigned zones. For the sake of brevity, let's use only the 1st ten location IDs for this workshop (see image below).
+
+ +
+There is no built-in filter transformation in Data Wrangler to handle these various constraints. Hence, we will create a custom transformation.
+
+To create a custom transformation, follow the steps below:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform.
+
+
+
+There is no built-in filter transformation in Data Wrangler to handle these various constraints. Hence, we will create a custom transformation.
+
+To create a custom transformation, follow the steps below:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform.
+
+  +
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Custom Transform.
+
+
+
+4. In drop down menu select Python (PySpark) and use code below. This code will filter rows based on the specified conditions.
+
+ ```Python
+ df = df.filter(df.trip_distance >= 0)
+ df = df.filter(df.tip_amount >= 0)
+ df = df.filter(df.total_amount >= 0)
+ df = df.filter(df.duration >= 1)
+ df = df.filter((1 <= df.PULocationID) & (df.PULocationID <= 263))
+ df = df.filter((df.tpep_pickup_datetime >= "2019-01-01 00:00:00") & (df.tpep_pickup_datetime < "2020-03-01 00:00:00"))
+ ```
+
+
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Custom Transform.
+
+
+
+4. In drop down menu select Python (PySpark) and use code below. This code will filter rows based on the specified conditions.
+
+ ```Python
+ df = df.filter(df.trip_distance >= 0)
+ df = df.filter(df.tip_amount >= 0)
+ df = df.filter(df.total_amount >= 0)
+ df = df.filter(df.duration >= 1)
+ df = df.filter((1 <= df.PULocationID) & (df.PULocationID <= 263))
+ df = df.filter((df.tpep_pickup_datetime >= "2019-01-01 00:00:00") & (df.tpep_pickup_datetime < "2020-03-01 00:00:00"))
+ ```
+
+  +
+
+5. Choose Preview
+6. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all current steps until this point in time and get a preview of the resulting dataset.
+
+
+
+
+5. Choose Preview
+6. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all current steps until this point in time and get a preview of the resulting dataset.
+
+ +
+## Quick analysis of dataset
+
+Amazon SageMaker Data Wrangler includes built-in analysis that help you generate visualizations and data insights in a few clicks. You can either leverage the built-in analyses types we offer out of the box with the product or create your own custom analysis using your own code if needed. SageMaker Data Wrangler also provides automated insights by automatically performing exploratory and descriptive analyses behind the scenes on your data. It identifies hidden anomalies and red flags within your dataset and proposes prescriptive actions in the form of what transforms can be applied on what columns of your data to fix these issues.
+
+For this lab, let's use the Table Summary built-in analysis type to quickly summarize our existing dataset in its current form. For the numeric columns, including long and float data, table summary reports the number of entries (`count`), minimum (`min`), maximum (`max`), mean, and standard deviation (`stddev`) for each column. For columns with non-numerical data, including columns with String, Boolean, or DateTime data, table summary reports the number of entries (`count`), least frequent value (`min`), and most frequent value (`max`).
+
+To create this analysis, follow the steps below:
+1. Click the plus sign next to a collection of transformation elements and choose "Add analyses".
+
+
+
+## Quick analysis of dataset
+
+Amazon SageMaker Data Wrangler includes built-in analysis that help you generate visualizations and data insights in a few clicks. You can either leverage the built-in analyses types we offer out of the box with the product or create your own custom analysis using your own code if needed. SageMaker Data Wrangler also provides automated insights by automatically performing exploratory and descriptive analyses behind the scenes on your data. It identifies hidden anomalies and red flags within your dataset and proposes prescriptive actions in the form of what transforms can be applied on what columns of your data to fix these issues.
+
+For this lab, let's use the Table Summary built-in analysis type to quickly summarize our existing dataset in its current form. For the numeric columns, including long and float data, table summary reports the number of entries (`count`), minimum (`min`), maximum (`max`), mean, and standard deviation (`stddev`) for each column. For columns with non-numerical data, including columns with String, Boolean, or DateTime data, table summary reports the number of entries (`count`), least frequent value (`min`), and most frequent value (`max`).
+
+To create this analysis, follow the steps below:
+1. Click the plus sign next to a collection of transformation elements and choose "Add analyses".
+
+  +
+2. In a "analyses type" drop down menu select "Table Summary" and provide a name for "Analysis name", for example: "Cleaned dataset summary"
+
+
+
+2. In a "analyses type" drop down menu select "Table Summary" and provide a name for "Analysis name", for example: "Cleaned dataset summary"
+
+  +
+3. Choose Preview
+
+4. Choose Add to save the analyses.
+
+5. You could find your first analyses on a "Analysis" tab. All future visualizations will could be also found here.
+
+
+
+3. Choose Preview
+
+4. Choose Add to save the analyses.
+
+5. You could find your first analyses on a "Analysis" tab. All future visualizations will could be also found here.
+
+  +
+6. Click on analyses icon to open it.
+
+Let's take a look at our results. The most interesting part is the summary for duration column: maximum value is 1439 and this is in minutes! 1439 minutes = almost 24 hours and this is definitely an issue which will reduce the quality of our model if this dataset is used in its current form. This looks more like an issue due to the prevalence of outliers in our dataset. Next, let's see how to issue this issue using a built-in transform Data Wrangler offers.
+
+
+
+6. Click on analyses icon to open it.
+
+Let's take a look at our results. The most interesting part is the summary for duration column: maximum value is 1439 and this is in minutes! 1439 minutes = almost 24 hours and this is definitely an issue which will reduce the quality of our model if this dataset is used in its current form. This looks more like an issue due to the prevalence of outliers in our dataset. Next, let's see how to issue this issue using a built-in transform Data Wrangler offers.
+
+  +
+## Handling outliers in numeric attributes
+
+In statistics, an outlier is a data point that differs significantly from other observations in the same dataset. An outlier may be due to variability in the measurement or it may indicate experimental error. The latter are sometimes excluded from the dataset. For example, in our dataset we have the `tip_amount` feature and usually it is less than 10 dollars, but due to an error in a data collection, some values can show thousands of dollar as a tip. Such data errors will skew statistics and aggregated values which will lead to a lower model accuracy.
+
+An outlier can cause serious problems in statistical analysis. Machine learning models are sensitive to the distribution and range of feature values. Outliers, or rare values, can negatively impact model accuracy and lead to longer training times. When you define a Handle outliers transform step, the statistics used to detect outliers are generated on the data available in Data Wrangler when defining this step. These same statistics are used when running a Data Wrangler job.
+
+SageMaker Data Wrangler supports several outliers detection and handle methods. We are going to use **Standard Deviation Numeric Outliers** and we remove all outliers as our dataset is big enough. This transform detects and fixes outliers in numeric features using the mean and standard deviation. You specify the number of standard deviations a value must vary from the mean to be considered an outlier. For example, if you specify 3 for standard deviations, a value falling more than 3 standard deviations from the mean is considered an outlier.
+
+To create this transformation, follow the steps below:
+1. Click the plus sign next to a collection of transformation elements and choose "Add transform".
+
+
+
+## Handling outliers in numeric attributes
+
+In statistics, an outlier is a data point that differs significantly from other observations in the same dataset. An outlier may be due to variability in the measurement or it may indicate experimental error. The latter are sometimes excluded from the dataset. For example, in our dataset we have the `tip_amount` feature and usually it is less than 10 dollars, but due to an error in a data collection, some values can show thousands of dollar as a tip. Such data errors will skew statistics and aggregated values which will lead to a lower model accuracy.
+
+An outlier can cause serious problems in statistical analysis. Machine learning models are sensitive to the distribution and range of feature values. Outliers, or rare values, can negatively impact model accuracy and lead to longer training times. When you define a Handle outliers transform step, the statistics used to detect outliers are generated on the data available in Data Wrangler when defining this step. These same statistics are used when running a Data Wrangler job.
+
+SageMaker Data Wrangler supports several outliers detection and handle methods. We are going to use **Standard Deviation Numeric Outliers** and we remove all outliers as our dataset is big enough. This transform detects and fixes outliers in numeric features using the mean and standard deviation. You specify the number of standard deviations a value must vary from the mean to be considered an outlier. For example, if you specify 3 for standard deviations, a value falling more than 3 standard deviations from the mean is considered an outlier.
+
+To create this transformation, follow the steps below:
+1. Click the plus sign next to a collection of transformation elements and choose "Add transform".
+
+  +
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Handle Outliers.
+
+
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Handle Outliers.
+
+  +
+4. For "Transform" choose "Standard deviation numeric outliers"
+5. For "Inputs columns" choose `tip_amount`, `total_amount`, `duration`, and `trip_distance`
+6. For "Fix method" choose "Remove"
+7. For "Standard deviations" put 4
+
+
+
+4. For "Transform" choose "Standard deviation numeric outliers"
+5. For "Inputs columns" choose `tip_amount`, `total_amount`, `duration`, and `trip_distance`
+6. For "Fix method" choose "Remove"
+7. For "Standard deviations" put 4
+
+  +
+8. Choose Preview
+9. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all current steps and a preview of resulted dataset.
+
+
+
+8. Choose Preview
+9. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all current steps and a preview of resulted dataset.
+
+ +
+
+Optional: If you want, you could repeat the steps from our previous analysis ("Quick analysis of a current dataset") to create a new table summary and check for the new maximum for the `duration` column. You can see, the new max value for duration is 243 minutes = just over an hour. This is more realistic for long trips than what we previously had.
+
+
+
+
+Optional: If you want, you could repeat the steps from our previous analysis ("Quick analysis of a current dataset") to create a new table summary and check for the new maximum for the `duration` column. You can see, the new max value for duration is 243 minutes = just over an hour. This is more realistic for long trips than what we previously had.
+
+ +
+## Grouping/Aggregating data
+At this moment we have cleaned dataset by removing outliers, invalid values, and added new features. There are few more steps before we start training our forecasting model.
+
+As we are interested in a hourly forecast we have to count number of trips per hour per station and also aggregate (with mean) all metrics such as distance, duration, tip, total amount.
+
+### Truncating timestamp
+We don't need minutes and seconds in out timestamp, so we remove them. There is no built-in filter transformation in SageMaker Data Wrangler, so we create a custom transformation.
+
+To create a custom transformation, follow the steps below::
+1. Click the plus sign next to a collection of transformation elements and choose "Add transform".
+
+
+
+## Grouping/Aggregating data
+At this moment we have cleaned dataset by removing outliers, invalid values, and added new features. There are few more steps before we start training our forecasting model.
+
+As we are interested in a hourly forecast we have to count number of trips per hour per station and also aggregate (with mean) all metrics such as distance, duration, tip, total amount.
+
+### Truncating timestamp
+We don't need minutes and seconds in out timestamp, so we remove them. There is no built-in filter transformation in SageMaker Data Wrangler, so we create a custom transformation.
+
+To create a custom transformation, follow the steps below::
+1. Click the plus sign next to a collection of transformation elements and choose "Add transform".
+
+ 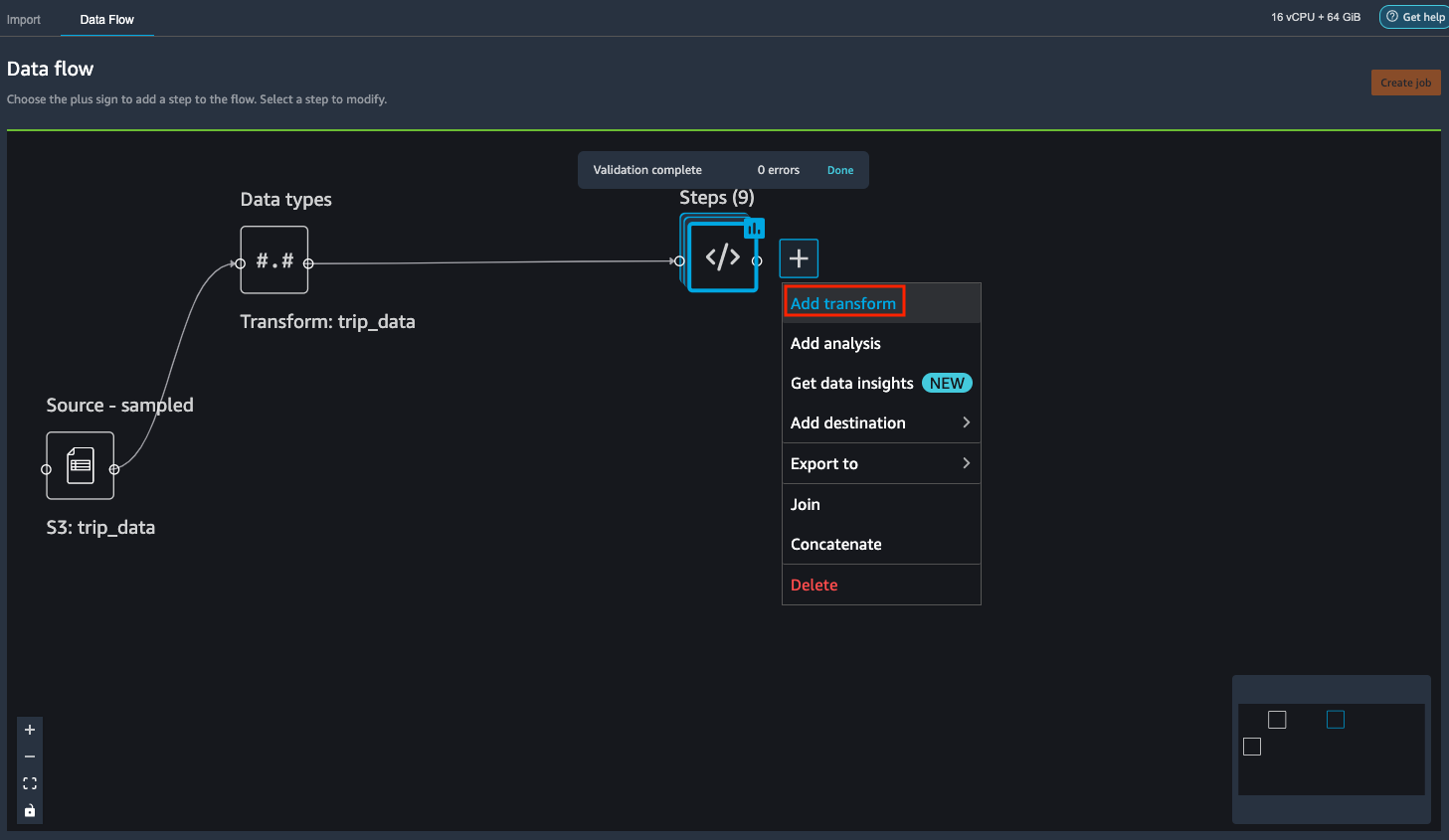 +
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Custom Transform.
+
+
+
+4. In drop down menu select Python (PySpark) and use code below. This code will create a new column with a truncated timestamp and then drop original pickup column.
+
+ ```Python
+ from pyspark.sql.functions import col, date_trunc
+ df = df.withColumn('pickup_time', date_trunc("hour",col("tpep_pickup_datetime")))
+ df = df.drop("tpep_pickup_datetime")
+ ```
+
+
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Custom Transform.
+
+
+
+4. In drop down menu select Python (PySpark) and use code below. This code will create a new column with a truncated timestamp and then drop original pickup column.
+
+ ```Python
+ from pyspark.sql.functions import col, date_trunc
+ df = df.withColumn('pickup_time', date_trunc("hour",col("tpep_pickup_datetime")))
+ df = df.drop("tpep_pickup_datetime")
+ ```
+
+  +
+5. Choose Preview
+
+6. Choose Add to save the step
+
+When you apply the transformation on sampled data, you can see all the current steps until this point in time and get a preview of the resulting dataset with a new column `pickup_time` and without the old column `tpep_pickup_datetime`
+
+
+
+5. Choose Preview
+
+6. Choose Add to save the step
+
+When you apply the transformation on sampled data, you can see all the current steps until this point in time and get a preview of the resulting dataset with a new column `pickup_time` and without the old column `tpep_pickup_datetime`
+
+ +
+### Count number of trips per hour per station
+Currently, we have only piece of information about each trip, but we don't know how many trips were made from each station per hour. The simplest way to do that is count number of records per stationID per hourly timestamp. While Amazon Data Wrangler provides GroupBy transformation. The built-in transformation doesn't support grouping by multiple columns, so we use a custom transformation.
+
+To create a custom transformation you have to:
+1. Click the plus sign next to a collection of transformation elements and choose "Add transform".
+
+
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Custom Transform.
+
+
+
+4. In drop down menu select Python (PySpark) and use code below. This code will create a new column with a number of trips from each location for each timestamp.
+
+ ```Python
+ from pyspark.sql import functions as f
+ from pyspark.sql import Window
+ df = df.withColumn('count', f.count('duration').over(Window.partitionBy([f.col("pickup_time"), f.col("PULocationID")])))
+ ```
+
+
+
+### Count number of trips per hour per station
+Currently, we have only piece of information about each trip, but we don't know how many trips were made from each station per hour. The simplest way to do that is count number of records per stationID per hourly timestamp. While Amazon Data Wrangler provides GroupBy transformation. The built-in transformation doesn't support grouping by multiple columns, so we use a custom transformation.
+
+To create a custom transformation you have to:
+1. Click the plus sign next to a collection of transformation elements and choose "Add transform".
+
+
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Custom Transform.
+
+
+
+4. In drop down menu select Python (PySpark) and use code below. This code will create a new column with a number of trips from each location for each timestamp.
+
+ ```Python
+ from pyspark.sql import functions as f
+ from pyspark.sql import Window
+ df = df.withColumn('count', f.count('duration').over(Window.partitionBy([f.col("pickup_time"), f.col("PULocationID")])))
+ ```
+
+  +
+5. Choose Preview
+6. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all current steps and a preview of a resulted dataset with a new column count.
+
+
+
+5. Choose Preview
+6. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all current steps and a preview of a resulted dataset with a new column count.
+
+ +
+## Resample time series
+Now, we are ready to make a final aggregation! We want to aggregate all rows by a combination of `PULocationID` and `pickup_time` columns, while features should be replaced by mean value for each combination.
+
+We use special built-in Time Series transformation **Resample**. The Resample transformation changes the frequency of the time series observations to a specified granularity. It also comes with both upsampling and downsampling options. Applying upsampling increases the frequency of the observations, for example from daily to hourly, whereas downsampling decreases the frequency of the observations, for example from hourly to daily.
+
+To create this transformation, follow the steps below:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform.
+
+
+
+## Resample time series
+Now, we are ready to make a final aggregation! We want to aggregate all rows by a combination of `PULocationID` and `pickup_time` columns, while features should be replaced by mean value for each combination.
+
+We use special built-in Time Series transformation **Resample**. The Resample transformation changes the frequency of the time series observations to a specified granularity. It also comes with both upsampling and downsampling options. Applying upsampling increases the frequency of the observations, for example from daily to hourly, whereas downsampling decreases the frequency of the observations, for example from hourly to daily.
+
+To create this transformation, follow the steps below:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform.
+
+ 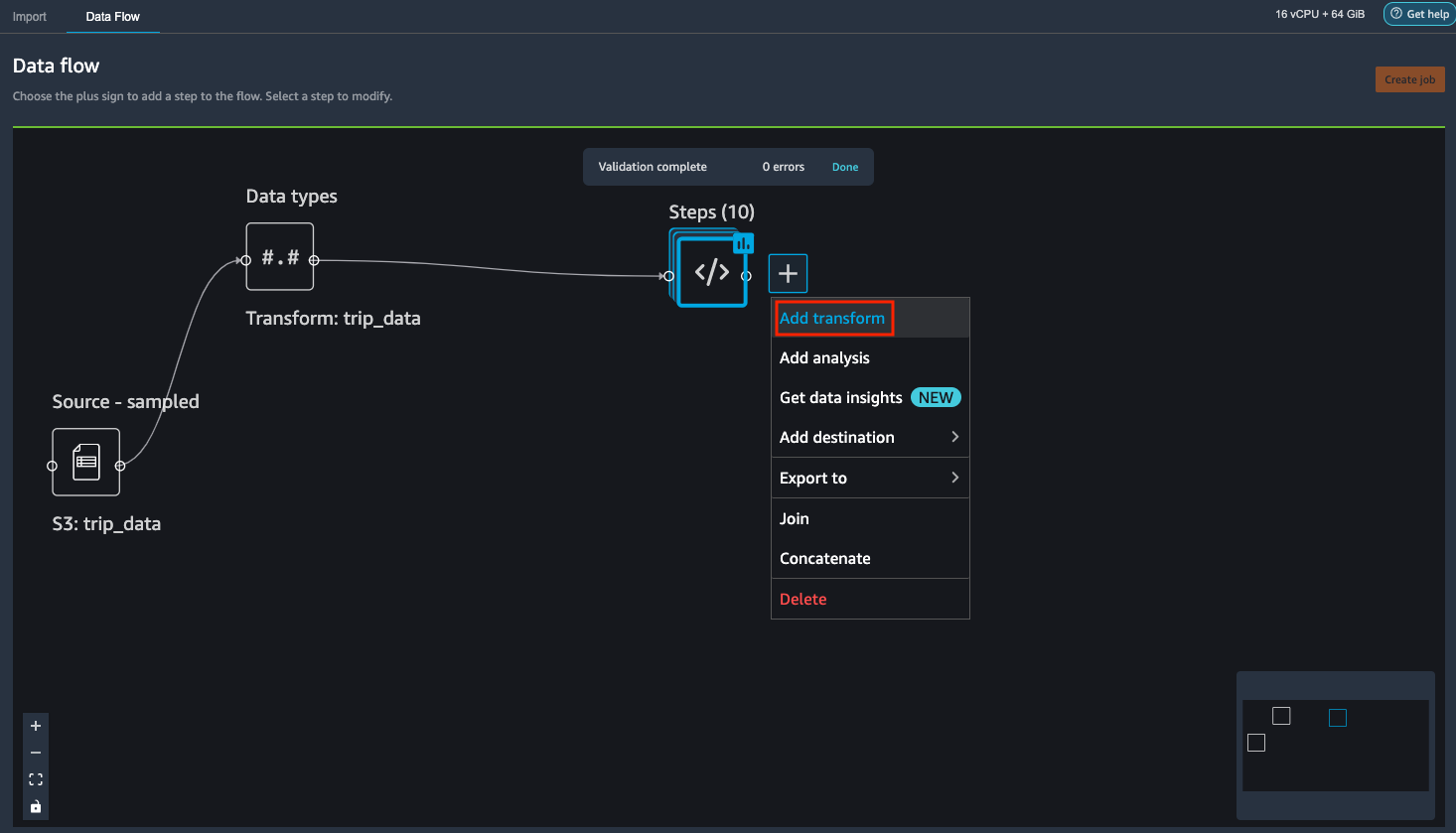 +
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+
+3. Choose Time Series.
+
+
+
+4. For "Transform" choose "Resample"
+5. For "Timestamp" choose `pickup_time`
+6. For "ID column" choose `PULocationID`
+7. For "Frequency unit" choose "Hourly"
+8. For "Frequency quantity" put 1
+9. For "Method to aggregate numeric values" choose "mean"
+10. Use default values for the rest of parameters
+
+
+
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+
+3. Choose Time Series.
+
+
+
+4. For "Transform" choose "Resample"
+5. For "Timestamp" choose `pickup_time`
+6. For "ID column" choose `PULocationID`
+7. For "Frequency unit" choose "Hourly"
+8. For "Frequency quantity" put 1
+9. For "Method to aggregate numeric values" choose "mean"
+10. Use default values for the rest of parameters
+
+  +
+11. Choose Preview
+12. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all current steps and a preview of a resulted dataset.
+
+
+
+11. Choose Preview
+12. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all current steps and a preview of a resulted dataset.
+
+ +
+## Resample time series
+Now we are ready to make a final aggregation! We aggregate all rows by combination of `PULocationID` and `pickup_time` timestamp while features should be replaced by mean value for each combination.
+
+We use special built-in Time Series transformation **Resample**. The Resample transformation changes the frequency of the time series observations to a specified granularity. It also comes with both upsampling and downsampling options. Applying upsampling increases the frequency of the observations, for example from daily to hourly, whereas downsampling decreases the frequency of the observations, for example from hourly to daily.
+
+To create this transformation you have to:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform.
+
+
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Time Series.
+
+
+
+4. For "Transform" choose "Resample"
+5. For "Timestamp" choose pickup_time
+6. For "ID column" choose "PULocationID"
+7. For "Frequency unit" choose "Hourly"
+8. For "Frequency quantity" put 1
+9. For "Method to aggregate numeric values" choose "mean"
+10. Use default values for the rest of parameters
+
+
+
+11. Choose Preview
+12. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all current steps until this point in time and get a preview of the resulting dataset.
+
+
+
+[here](https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler-import.html).
+
+## Featurize Date Time
+
+"Featurize datetime" time series transformation will add the month, day of the month, day of the year, week of the year, hour and quarter features to our dataset. Because we’re providing the date/time components as separate features, we enable ML algorithms to detect signals and patterns for improving prediction accuracy.
+
+To create this transformation you have to:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu
+
+
+
+3. Choose Time Series
+
+
+
+ * For "Transform" choose "Featurize date/time"
+ * For "Input Column" choose `pickup_time`
+ * For "Output Column" enter "date"
+ * For "Output mode" choose "Ordinal"
+ * For "Output format" choose "Columns"
+ * For date/time features to extract, select Year, Month, Day, Hour, Week of year, Day of year, and Quarter.
+
+
+
+## Resample time series
+Now we are ready to make a final aggregation! We aggregate all rows by combination of `PULocationID` and `pickup_time` timestamp while features should be replaced by mean value for each combination.
+
+We use special built-in Time Series transformation **Resample**. The Resample transformation changes the frequency of the time series observations to a specified granularity. It also comes with both upsampling and downsampling options. Applying upsampling increases the frequency of the observations, for example from daily to hourly, whereas downsampling decreases the frequency of the observations, for example from hourly to daily.
+
+To create this transformation you have to:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform.
+
+
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Time Series.
+
+
+
+4. For "Transform" choose "Resample"
+5. For "Timestamp" choose pickup_time
+6. For "ID column" choose "PULocationID"
+7. For "Frequency unit" choose "Hourly"
+8. For "Frequency quantity" put 1
+9. For "Method to aggregate numeric values" choose "mean"
+10. Use default values for the rest of parameters
+
+
+
+11. Choose Preview
+12. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all current steps until this point in time and get a preview of the resulting dataset.
+
+
+
+[here](https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler-import.html).
+
+## Featurize Date Time
+
+"Featurize datetime" time series transformation will add the month, day of the month, day of the year, week of the year, hour and quarter features to our dataset. Because we’re providing the date/time components as separate features, we enable ML algorithms to detect signals and patterns for improving prediction accuracy.
+
+To create this transformation you have to:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu
+
+
+
+3. Choose Time Series
+
+
+
+ * For "Transform" choose "Featurize date/time"
+ * For "Input Column" choose `pickup_time`
+ * For "Output Column" enter "date"
+ * For "Output mode" choose "Ordinal"
+ * For "Output format" choose "Columns"
+ * For date/time features to extract, select Year, Month, Day, Hour, Week of year, Day of year, and Quarter.
+
+  +
+4. Choose Preview
+5. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all current steps until this point in time and get a preview of the resulting dataset.
+
+Click "Back to data flow" to head back to the block diagram editor window.
+
+## Lag feature
+Next let’s create lag features for the target column count. Lag features in time-series analysis are values at prior timestamps that are considered helpful in inferring future values. They also help identify **autocorrelation**, also known as serial correlation, patterns in the residual series by quantifying the relationship of the observation with observations at previous time steps. Autocorrelation is similar to regular correlation but between the values in a series and its past values. It forms the basis for the **autoregressive forecasting** models in the **ARIMA** series.
+
+With SageMaker Data Wrangler's Lag feature transform, you can easily create lag features n periods apart. Additionally, we often want to create multiple lag features at different lags and let the model decide the most meaningful features. For such a scenario, the **Lag features** transform helps create multiple lag columns over a specified window size.
+
+To create this transformation, follow the steps below:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform.
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Time Series
+
+
+
+ * For "Transform" choose "Lag features"
+ * For "Generate lag features for this column" choose "count"
+ * For "ID column" enter "PULocationID"
+ * For "Timestamp Column" choose "pickup_time"
+ * For Lag, enter 8. You could try to use different values, maybe 24 hours in our case makes more sense.
+ * Because we’re interested in observing up to the previous 8 lag values, let’s select Include the entire lag window.
+ * To create a new column for each lag value, select Flatten the output
+
+
+
+4. Choose Preview
+5. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all current steps until this point in time and get a preview of the resulting dataset.
+
+Click "Back to data flow" to head back to the block diagram editor window.
+
+## Lag feature
+Next let’s create lag features for the target column count. Lag features in time-series analysis are values at prior timestamps that are considered helpful in inferring future values. They also help identify **autocorrelation**, also known as serial correlation, patterns in the residual series by quantifying the relationship of the observation with observations at previous time steps. Autocorrelation is similar to regular correlation but between the values in a series and its past values. It forms the basis for the **autoregressive forecasting** models in the **ARIMA** series.
+
+With SageMaker Data Wrangler's Lag feature transform, you can easily create lag features n periods apart. Additionally, we often want to create multiple lag features at different lags and let the model decide the most meaningful features. For such a scenario, the **Lag features** transform helps create multiple lag columns over a specified window size.
+
+To create this transformation, follow the steps below:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform.
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Time Series
+
+
+
+ * For "Transform" choose "Lag features"
+ * For "Generate lag features for this column" choose "count"
+ * For "ID column" enter "PULocationID"
+ * For "Timestamp Column" choose "pickup_time"
+ * For Lag, enter 8. You could try to use different values, maybe 24 hours in our case makes more sense.
+ * Because we’re interested in observing up to the previous 8 lag values, let’s select Include the entire lag window.
+ * To create a new column for each lag value, select Flatten the output
+
+  +
+4. Choose Preview
+5. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all current steps and a preview of a resulted dataset.
+
+
+
+4. Choose Preview
+5. Choose Add to save the step.
+
+When transformation is applied on a sampled data you should see all current steps and a preview of a resulted dataset.
+
+  +
+## Rolling window features
+We can also calculate meaningful statistical summaries across a range of values and include them as input features. Let’s extract common statistical time series features.
+
+Data Wrangler implements automatic time series feature extraction capabilities using the open source `tsfresh` package. With the time series feature extraction transforms, you can automate the feature extraction process. This eliminates the time and effort otherwise spent manually implementing signal processing libraries. We will extract features using the **Rolling window** features transform. This method computes statistical properties across a set of observations defined by the window size.
+
+To create this transformation you have to:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Time Series
+
+
+
+ * For "Transform" choose "Rolling window features"
+ * For "Generate rolling window features for this column" choose "count"
+ * For "Timestamp Column" choose "pickup_time"
+ * For "ID column" enter `PULocationID`
+ * For "Window size", enter 8. You could try to use different values, maybe 24 hours in our case makes more sense.
+ * Select Flatten to create a new column for each computed feature.
+ * Choose "Strategy" as "Minimal subset". This strategy extracts eight features that are useful in downstream analyses. Other strategies include Efficient Subset, Custom subset, and All features.
+
+
+
+## Rolling window features
+We can also calculate meaningful statistical summaries across a range of values and include them as input features. Let’s extract common statistical time series features.
+
+Data Wrangler implements automatic time series feature extraction capabilities using the open source `tsfresh` package. With the time series feature extraction transforms, you can automate the feature extraction process. This eliminates the time and effort otherwise spent manually implementing signal processing libraries. We will extract features using the **Rolling window** features transform. This method computes statistical properties across a set of observations defined by the window size.
+
+To create this transformation you have to:
+1. Click the plus sign next to a collection of transformation elements and choose Add transform
+
+2. Click "+ Add step" orange button in the TRANSFORMS menu.
+
+
+
+3. Choose Time Series
+
+
+
+ * For "Transform" choose "Rolling window features"
+ * For "Generate rolling window features for this column" choose "count"
+ * For "Timestamp Column" choose "pickup_time"
+ * For "ID column" enter `PULocationID`
+ * For "Window size", enter 8. You could try to use different values, maybe 24 hours in our case makes more sense.
+ * Select Flatten to create a new column for each computed feature.
+ * Choose "Strategy" as "Minimal subset". This strategy extracts eight features that are useful in downstream analyses. Other strategies include Efficient Subset, Custom subset, and All features.
+
+  +
+4. Choose Preview
+5. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all current steps until this point in time and get a preview of the resulting dataset.
+
+
+
+4. Choose Preview
+5. Choose Add to save the step.
+
+When this transformation is applied on the dataset, you can see all current steps until this point in time and get a preview of the resulting dataset.
+
+ +
+Click "Back to data flow" to head back to the block diagram editor window.
+
+## Export Data
+At this stage, we have a new dataset that is cleaned and transformed with newly engineered features. This dataset can be used for forecasting either using open source libraries/frameworks or AWS services like [Amazon SageMaker Autopilot](https://aws.amazon.com/sagemaker/autopilot/), [Amazon SageMaker Canvas](https://aws.amazon.com/sagemaker/canvas/) or [Amazon Forecast](https://aws.amazon.com/forecast/).
+
+Given, we had only used a sample of the dataset for creating our data preparation and transformation recipe so far, what need to do next is to apply the same recipe (data flow) on our entire dataset and scale the whole process in a distributed fashion. Amazon Data Wrangler let's you do this in multiple ways. You can export your data flow: 1/ as a processing job, 2/ as a SageMaker pipeline step, or 3/ as a Python script. You can also kick-off these distributed jobs via the UI without writing any code using Data Wrangler's destination node option. The export options are also facilitated via SageMaker Studio notebooks (Jupyter). Additionally, the transformed features can also be ingested directly to SageMaker Feature Store.
+
+For this lab, we will see how to use the destination nodes option to export the transformed features to S3 via a distributed PySpark job powered by SageMaker Processing.
+
+### Exporting to S3 using Destination Nodes
+This option creates a SageMaker processing job which uses the data flow (recipe) we have created previously to kick-off a distributed processing job on the "entire" dataset saving the results to a specified S3 bucket.
+
+Additionally, you can also drop columns if needed right before the export step. For the sake of brevity and to simplify the prediction problem statement, let's drop all columns except three columns `pickup_time`, `count`, `PULocationID`. Here count is the target variable we will try to predict. `pickup_time` and `PULocationID` will be our feature columns used for modeling. To create the model, we will be using SageMaker Autopilot. This will be covered in the next 2 sections.
+
+Follow the next steps to setup export to S3.
+1. Click the plus sign next to a collection of transformation elements and choose **"Add destination" -> "Amazon S3"**
+
+
+
+Click "Back to data flow" to head back to the block diagram editor window.
+
+## Export Data
+At this stage, we have a new dataset that is cleaned and transformed with newly engineered features. This dataset can be used for forecasting either using open source libraries/frameworks or AWS services like [Amazon SageMaker Autopilot](https://aws.amazon.com/sagemaker/autopilot/), [Amazon SageMaker Canvas](https://aws.amazon.com/sagemaker/canvas/) or [Amazon Forecast](https://aws.amazon.com/forecast/).
+
+Given, we had only used a sample of the dataset for creating our data preparation and transformation recipe so far, what need to do next is to apply the same recipe (data flow) on our entire dataset and scale the whole process in a distributed fashion. Amazon Data Wrangler let's you do this in multiple ways. You can export your data flow: 1/ as a processing job, 2/ as a SageMaker pipeline step, or 3/ as a Python script. You can also kick-off these distributed jobs via the UI without writing any code using Data Wrangler's destination node option. The export options are also facilitated via SageMaker Studio notebooks (Jupyter). Additionally, the transformed features can also be ingested directly to SageMaker Feature Store.
+
+For this lab, we will see how to use the destination nodes option to export the transformed features to S3 via a distributed PySpark job powered by SageMaker Processing.
+
+### Exporting to S3 using Destination Nodes
+This option creates a SageMaker processing job which uses the data flow (recipe) we have created previously to kick-off a distributed processing job on the "entire" dataset saving the results to a specified S3 bucket.
+
+Additionally, you can also drop columns if needed right before the export step. For the sake of brevity and to simplify the prediction problem statement, let's drop all columns except three columns `pickup_time`, `count`, `PULocationID`. Here count is the target variable we will try to predict. `pickup_time` and `PULocationID` will be our feature columns used for modeling. To create the model, we will be using SageMaker Autopilot. This will be covered in the next 2 sections.
+
+Follow the next steps to setup export to S3.
+1. Click the plus sign next to a collection of transformation elements and choose **"Add destination" -> "Amazon S3"**
+
+ 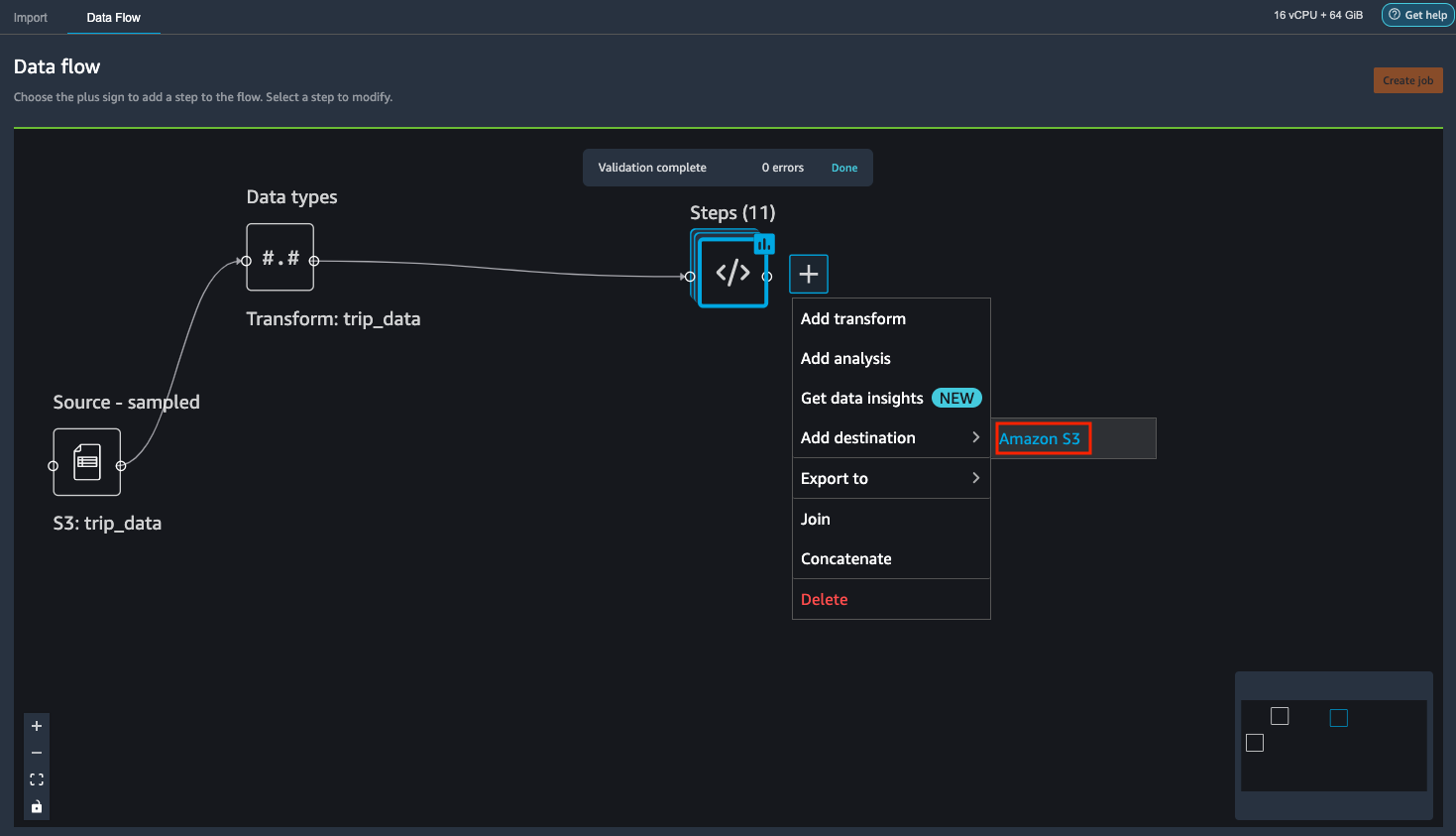 +
+2. Provide parameters for S3 destination:
+ * Dataset name - name for new dataset, for example used "NYC_export"
+ * File type - CSV
+ * Delimiter - Comma
+ * Compression - none
+ * Amazon S3 location - You can use the same bucket name which we created at the beginning
+
+3. Click "Add destination" orange button
+
+
+
+2. Provide parameters for S3 destination:
+ * Dataset name - name for new dataset, for example used "NYC_export"
+ * File type - CSV
+ * Delimiter - Comma
+ * Compression - none
+ * Amazon S3 location - You can use the same bucket name which we created at the beginning
+
+3. Click "Add destination" orange button
+
+  +
+4. Now your dataflow has a final step and you see a new "Create job" orange button. Click it.
+
+
+
+4. Now your dataflow has a final step and you see a new "Create job" orange button. Click it.
+
+  +
+5. Provide a "Job name" or keep autogenerated option and select "destination". We have only one "S3:NYC_export", but you might have multiple destinations from different steps in your workflow. Leave a "KMS key ARN" field empty and click "Next" orange button.
+
+
+
+5. Provide a "Job name" or keep autogenerated option and select "destination". We have only one "S3:NYC_export", but you might have multiple destinations from different steps in your workflow. Leave a "KMS key ARN" field empty and click "Next" orange button.
+
+  +
+6. Now your have to provide configuration for a compute capacity for a job. You can keep all defaults values:
+ * For Instance type use "ml.m5.4xlarge"
+ * For Instance count use "2"
+ * You can explore "Additional configuration", but keep them without change.
+ * Click "Run" orange button
+
+
+
+6. Now your have to provide configuration for a compute capacity for a job. You can keep all defaults values:
+ * For Instance type use "ml.m5.4xlarge"
+ * For Instance count use "2"
+ * You can explore "Additional configuration", but keep them without change.
+ * Click "Run" orange button
+
+  +
+7. Now your job is started and it takes about 1 hour to process 6 GB of data according to our Data Wrangler processing flow. Cost for this job will be around 2 USD as "ml.m5.4xlarge" cost 0.922 USD per hour and we are using two of them.
+
+
+
+7. Now your job is started and it takes about 1 hour to process 6 GB of data according to our Data Wrangler processing flow. Cost for this job will be around 2 USD as "ml.m5.4xlarge" cost 0.922 USD per hour and we are using two of them.
+
+  +
+8. If you click on the job name you will be redirected to a new window with the job details. On the job details page you see all parameters from a previous steps.
+
+
+
+8. If you click on the job name you will be redirected to a new window with the job details. On the job details page you see all parameters from a previous steps.
+
+  +
+Approximately in one hour you should see that job status changed to "Completed" and you could also check "Processing time (seconds)" value.
+
+
+
+Approximately in one hour you should see that job status changed to "Completed" and you could also check "Processing time (seconds)" value.
+
+ +
+Now you could close job details page.
+
+## Check Processed output
+After the SageMaker Data Wrangler processing job is completed, we can check the results saved in our destination S3 bucket.
+
+At this stage, you have designed a data flow for data processing and feature engineering and successfully launched it. Of course it is not mandatory to always run a job by clicking on the "Run" button. You could also automate it, but this is a topic of another workshop in this series!
+
+
+
+Now you could close job details page.
+
+## Check Processed output
+After the SageMaker Data Wrangler processing job is completed, we can check the results saved in our destination S3 bucket.
+
+At this stage, you have designed a data flow for data processing and feature engineering and successfully launched it. Of course it is not mandatory to always run a job by clicking on the "Run" button. You could also automate it, but this is a topic of another workshop in this series!
+
+ 💡
+Congratulations!
+ You reached the end of this part. Now you know how to use Amazon SageMaker Data Wrangler for time series dataset preparation!
+
+ You can now move to an optional advanced time series transformation exercise
+
+
+# Clean up (Only if not planning to do the Advanced part of the timeseries exercise)
+
+* Delete artifacts in S3.
+* Delete data flow file in SageMaker Studio.
+* Stop active SageMaker Data Wrangler instance.
+* Delete SageMaker user profile and domain (optional).
diff --git a/sagemaker-datawrangler/uploadflow.png b/sagemaker-datawrangler/uploadflow.png
new file mode 100644
index 0000000000..43b8fe2c03
Binary files /dev/null and b/sagemaker-datawrangler/uploadflow.png differ
diff --git a/sagemaker-debugger/index.rst b/sagemaker-debugger/index.rst
index 615494960d..b8b19f0019 100644
--- a/sagemaker-debugger/index.rst
+++ b/sagemaker-debugger/index.rst
@@ -25,6 +25,7 @@ Profiling
debugger_interactive_analysis_profiling/interactive_analysis_profiling_data
tensorflow_nlp_sentiment_analysis/sentiment-analysis-tf-distributed-training-bringyourownscript
+ pytorch_profiling/pt-resnet-profiling-single-gpu-single-node
----
@@ -77,6 +78,7 @@ TensorFlow 1.x
tensorflow_action_on_rule/detect_stalled_training_job_and_stop
tensorflow_action_on_rule/tf-mnist-stop-training-job
tensorflow_keras_custom_rule/tf-keras-custom-rule
+ tensorflow_action_on_rule/detect_stalled_training_job_and_actions
PyTorch
diff --git a/sagemaker-debugger/model_specific_realtime_analysis/cnn_class_activation_maps/cnn_class_activation_maps.ipynb b/sagemaker-debugger/model_specific_realtime_analysis/cnn_class_activation_maps/cnn_class_activation_maps.ipynb
index 0bd3a5f04f..653b95e4e4 100644
--- a/sagemaker-debugger/model_specific_realtime_analysis/cnn_class_activation_maps/cnn_class_activation_maps.ipynb
+++ b/sagemaker-debugger/model_specific_realtime_analysis/cnn_class_activation_maps/cnn_class_activation_maps.ipynb
@@ -80,7 +80,7 @@
" image.register_hook(self.backward_hook(\"image\"))\n",
" \n",
" def forward_hook(self, module, inputs, outputs):\n",
- " module_name = self.module_maps[module] \n",
+ " module_name = module._module_name\n",
" self._write_inputs(module_name, inputs)\n",
" \n",
" #register outputs for backward pass. this is expensive, so we will only do it during EVAL mode\n",
@@ -326,6 +326,16 @@
"Before starting the SageMaker training job, we need to install some libraries. We will use `smdebug` library to read, filter and analyze raw tensors that are stored in Amazon S3. We will use `opencv-python` library to plot saliency maps as heatmap."
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fab25828",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!apt-get update && apt-get install -y python3-opencv"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
@@ -570,8 +580,8 @@
" role=role,\n",
" train_instance_type=\"ml.p3.2xlarge\",\n",
" train_instance_count=1,\n",
- " framework_version=\"1.3.1\",\n",
- " py_version=\"py3\",\n",
+ " framework_version=\"1.12.0\",\n",
+ " py_version=\"py38\",\n",
" hyperparameters={\n",
" \"epochs\": 5,\n",
" \"batch_size_train\": 64,\n",
@@ -1325,9 +1335,9 @@
],
"metadata": {
"kernelspec": {
- "display_name": "Environment (conda_pytorch_p36)",
+ "display_name": "Python 3.8.11 64-bit ('3.8.11')",
"language": "python",
- "name": "conda_pytorch_p36"
+ "name": "python3"
},
"language_info": {
"codemirror_mode": {
@@ -1339,7 +1349,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.6.10"
+ "version": "3.8.11"
},
"papermill": {
"default_parameters": {},
diff --git a/sagemaker-debugger/model_specific_realtime_analysis/cnn_class_activation_maps/entry_point/custom_hook.py b/sagemaker-debugger/model_specific_realtime_analysis/cnn_class_activation_maps/entry_point/custom_hook.py
index 1c445eb15f..8e94b15a88 100644
--- a/sagemaker-debugger/model_specific_realtime_analysis/cnn_class_activation_maps/entry_point/custom_hook.py
+++ b/sagemaker-debugger/model_specific_realtime_analysis/cnn_class_activation_maps/entry_point/custom_hook.py
@@ -10,7 +10,7 @@ def image_gradients(self, image):
image.register_hook(self.backward_hook("image"))
def forward_hook(self, module, inputs, outputs):
- module_name = self.module_maps[module]
+ module_name = module._module_name
self._write_inputs(module_name, inputs)
# register outputs for backward pass. this is expensive, so we will only do it during EVAL mode
diff --git a/sagemaker-debugger/model_specific_realtime_analysis/cnn_class_activation_maps/entry_point/train.py b/sagemaker-debugger/model_specific_realtime_analysis/cnn_class_activation_maps/entry_point/train.py
index c5e57b9429..d45ab2a3a0 100644
--- a/sagemaker-debugger/model_specific_realtime_analysis/cnn_class_activation_maps/entry_point/train.py
+++ b/sagemaker-debugger/model_specific_realtime_analysis/cnn_class_activation_maps/entry_point/train.py
@@ -81,6 +81,7 @@ def train_model(epochs, batch_size_train, batch_size_val):
# create custom hook that has a customized forward function, so that we can get gradients of outputs
hook = custom_hook.CustomHook.create_from_json_file()
hook.register_module(model)
+ hook.register_loss(loss_function)
# get the dataloaders for train and test data
train_loader, val_loader = get_dataloaders(batch_size_train, batch_size_val)
diff --git a/sagemaker-debugger/pytorch_iterative_model_pruning/iterative_model_pruning_alexnet.ipynb b/sagemaker-debugger/pytorch_iterative_model_pruning/iterative_model_pruning_alexnet.ipynb
index 37b1970e2c..ff5ab416fd 100644
--- a/sagemaker-debugger/pytorch_iterative_model_pruning/iterative_model_pruning_alexnet.ipynb
+++ b/sagemaker-debugger/pytorch_iterative_model_pruning/iterative_model_pruning_alexnet.ipynb
@@ -251,7 +251,7 @@
"# name of experiment\n",
"timestep = datetime.now()\n",
"timestep = timestep.strftime(\"%d-%m-%Y-%H-%M-%S\")\n",
- "experiment_name = timestep + \"-model-pruning-experiment\"\n",
+ "experiment_name = timestep + \"-alexnet-model-pruning-experiment\"\n",
"\n",
"# create experiment\n",
"Experiment.create(\n",
@@ -372,12 +372,12 @@
"estimator = PyTorch(\n",
" role=sagemaker.get_execution_role(),\n",
" instance_count=1,\n",
- " instance_type=\"ml.p2.xlarge\",\n",
+ " instance_type=\"ml.p3.2xlarge\",\n",
" volume_size=400,\n",
" source_dir=\"src\",\n",
" entry_point=\"train.py\",\n",
- " framework_version=\"1.6\",\n",
- " py_version=\"py3\",\n",
+ " framework_version=\"1.12\",\n",
+ " py_version=\"py38\",\n",
" metric_definitions=[\n",
" {\"Name\": \"train:loss\", \"Regex\": \"loss:(.*?)\"},\n",
" {\"Name\": \"eval:acc\", \"Regex\": \"acc:(.*?)\"},\n",
diff --git a/sagemaker-debugger/pytorch_iterative_model_pruning/iterative_model_pruning_resnet.ipynb b/sagemaker-debugger/pytorch_iterative_model_pruning/iterative_model_pruning_resnet.ipynb
index 9d4049371b..2c08e08870 100644
--- a/sagemaker-debugger/pytorch_iterative_model_pruning/iterative_model_pruning_resnet.ipynb
+++ b/sagemaker-debugger/pytorch_iterative_model_pruning/iterative_model_pruning_resnet.ipynb
@@ -216,7 +216,7 @@
"# name of experiment\n",
"timestep = datetime.now()\n",
"timestep = timestep.strftime(\"%d-%m-%Y-%H-%M-%S\")\n",
- "experiment_name = timestep + \"-model-pruning-experiment\"\n",
+ "experiment_name = timestep + \"resnet-model-pruning-experiment\"\n",
"\n",
"# create experiment\n",
"Experiment.create(\n",
@@ -340,8 +340,8 @@
" volume_size=400,\n",
" source_dir=\"src\",\n",
" entry_point=\"train.py\",\n",
- " framework_version=\"1.6\",\n",
- " py_version=\"py3\",\n",
+ " framework_version=\"1.12\",\n",
+ " py_version=\"py38\",\n",
" metric_definitions=[\n",
" {\"Name\": \"train:loss\", \"Regex\": \"loss:(.*?)\"},\n",
" {\"Name\": \"eval:acc\", \"Regex\": \"acc:(.*?)\"},\n",
diff --git a/sagemaker-debugger/pytorch_model_debugging/pytorch_script_change_smdebug.ipynb b/sagemaker-debugger/pytorch_model_debugging/pytorch_script_change_smdebug.ipynb
index 46cfd0be7b..8ae6dcc438 100644
--- a/sagemaker-debugger/pytorch_model_debugging/pytorch_script_change_smdebug.ipynb
+++ b/sagemaker-debugger/pytorch_model_debugging/pytorch_script_change_smdebug.ipynb
@@ -98,13 +98,13 @@
"\n",
"Tensors that debug hook captures are stored in S3 location specified by you. There are two ways you can configure Amazon SageMaker Debugger for storage:\n",
"\n",
- " 1. **Zero code change**: If you use any of SageMaker provided [Deep Learning containers](https://docs.aws.amazon.com/sagemaker/latest/dg/pre-built-containers-frameworks-deep-learning.html) then you don't need to make any changes to your training script for tensors to be stored. Amazon SageMaker Debugger will use the configuration you provide in the framework `Estimator` to save tensors in the fashion you specify.\n",
+ " 1. **Zero code change (DEPRECATED for PyTorch versions >= 1.12)**: If you use any of SageMaker provided [Deep Learning containers](https://docs.aws.amazon.com/sagemaker/latest/dg/pre-built-containers-frameworks-deep-learning.html) then you don't need to make any changes to your training script for tensors to be stored. Amazon SageMaker Debugger will use the configuration you provide in the framework `Estimator` to save tensors in the fashion you specify.\n",
" \n",
" **Note**: In case of PyTorch training, Debugger collects output tensors in GLOBAL mode by default. In other words, this option does not distinguish output tensors from different phases within an epoch, such as training phase and validation phase.\n",
" \n",
" 2. **Script change**: Use the SageMaker Debugger client library, SMDebug, and customize training scripts to save the specific tensors you want at different frequencies and configurations. Refer to the [DeveloperGuide](https://github.com/awslabs/sagemaker-debugger/tree/master/docs) for details on how to use SageMaker Debugger with your choice of framework in your training script.\n",
" \n",
- "In this notebook, we choose the second option to properly save the output tensors from different training phases.\n",
+ "In this notebook, we choose the second option to properly save the output tensors from different training phases since we're using PyTorch=1.12\n",
"\n",
"### Analysis of tensors\n",
"\n",
@@ -289,19 +289,20 @@
" ```\n",
"\n",
"\n",
- "- **Step 4**: In the `main()` function, create the SMDebug hook and register to the model.\n",
+ "- **Step 4**: In the `main()` function, create the SMDebug hook and register to the model and loss function.\n",
"\n",
" ```python\n",
" hook = smd.Hook.create_from_json_file()\n",
" hook.register_hook(model)\n",
+ " hook.register_loss(loss_fn)\n",
" ```\n",
"\n",
"\n",
"- **Step 4**: In the `main()` function, pass the SMDebug hook to the `train()` and `test()` functions in the epoch loop.\n",
"\n",
" ```python\n",
- " train(args, model, device, train_loader, optimizer, epoch, hook)\n",
- " test(model, device, test_loader, hook)\n",
+ " train(args, model, loss_fn, device, train_loader, optimizer, epoch, hook)\n",
+ " test(model, device, loss_fn, test_loader, hook)\n",
" ```"
]
},
@@ -983,7 +984,7 @@
},
"outputs": [],
"source": [
- "len(trial.tensor(\"nll_loss_output_0\").steps(mode=ModeKeys.TRAIN))"
+ "len(trial.tensor(\"NLLLoss_output_0\").steps(mode=ModeKeys.TRAIN))"
]
},
{
@@ -1002,7 +1003,7 @@
},
"outputs": [],
"source": [
- "len(trial.tensor(\"nll_loss_output_0\").steps(mode=ModeKeys.EVAL))"
+ "len(trial.tensor(\"NLLLoss_output_0\").steps(mode=ModeKeys.EVAL))"
]
},
{
@@ -1116,7 +1117,7 @@
},
"outputs": [],
"source": [
- "plot_tensor(trial, \"nll_loss_output_0\")"
+ "plot_tensor(trial, \"NLLLoss_output_0\")"
]
},
{
@@ -1142,7 +1143,7 @@
"RuleEvaluationConditionMet: Evaluation of the rule Overfit at step 4000 resulted in the condition being met\n",
"```\n",
"\n",
- "Based on this rule evaluation and the plot above, we can conclude that the training job has an overfit issue. While the `nll_loss_output_0` line is decreasing, the `val_nll_loss_output_0` line is fluctuating and not decreasing. \n",
+ "Based on this rule evaluation and the plot above, we can conclude that the training job has an overfit issue. While the `NLLLoss_output_0` line is decreasing, the `val_NLLLoss_output_0` line is fluctuating and not decreasing. \n",
"\n",
"To resolve the overfit problem, you need to consider using or double-checking the following techniques:\n",
"\n",
@@ -1277,9 +1278,9 @@
"metadata": {
"instance_type": "ml.g4dn.xlarge",
"kernelspec": {
- "display_name": "Environment (conda_pytorch_p36)",
+ "display_name": "Python 3.8.11 64-bit ('3.8.11')",
"language": "python",
- "name": "conda_pytorch_p36"
+ "name": "python3"
},
"language_info": {
"codemirror_mode": {
@@ -1291,7 +1292,7 @@
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
- "version": "3.6.10"
+ "version": "3.8.11"
},
"papermill": {
"default_parameters": {},
@@ -1310,4 +1311,4 @@
},
"nbformat": 4,
"nbformat_minor": 5
-}
\ No newline at end of file
+}
diff --git a/sagemaker-debugger/pytorch_model_debugging/scripts/pytorch_mnist.py b/sagemaker-debugger/pytorch_model_debugging/scripts/pytorch_mnist.py
index d4342e3566..e9e43ffd08 100644
--- a/sagemaker-debugger/pytorch_model_debugging/scripts/pytorch_mnist.py
+++ b/sagemaker-debugger/pytorch_model_debugging/scripts/pytorch_mnist.py
@@ -74,7 +74,7 @@ def forward(self, x):
return output
-def train(args, model, device, train_loader, optimizer, epoch, hook):
+def train(args, model, loss_fn, device, train_loader, optimizer, epoch, hook):
model.train()
# =================================================#
# 2. Set the SMDebug hook for the training phase. #
@@ -84,12 +84,12 @@ def train(args, model, device, train_loader, optimizer, epoch, hook):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
- loss = F.nll_loss(output, target)
+ loss = loss_fn(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print(
- "Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(
+ "Train Epoch: {} [{}/{} ({:.0f}%)]\t Loss: {:.6f}".format(
epoch,
batch_idx * len(data),
len(train_loader.dataset),
@@ -101,7 +101,7 @@ def train(args, model, device, train_loader, optimizer, epoch, hook):
break
-def test(model, device, test_loader, hook):
+def test(model, loss_fn, device, test_loader, hook):
model.eval()
# ===================================================#
# 3. Set the SMDebug hook for the validation phase. #
@@ -113,7 +113,7 @@ def test(model, device, test_loader, hook):
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
- test_loss += F.nll_loss(output, target, reduction="sum").item() # sum up batch loss
+ test_loss += loss_fn(output, target).item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
@@ -201,12 +201,14 @@ def main():
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
model = Net().to(device)
+ loss_fn = nn.NLLLoss()
# ======================================================#
# 4. Register the SMDebug hook to save output tensors. #
# ======================================================#
hook = smd.Hook.create_from_json_file()
hook.register_hook(model)
+ hook.register_loss(loss_fn)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
@@ -215,8 +217,8 @@ def main():
# ===========================================================#
# 5. Pass the SMDebug hook to the train and test functions. #
# ===========================================================#
- train(args, model, device, train_loader, optimizer, epoch, hook)
- test(model, device, test_loader, hook)
+ train(args, model, loss_fn, device, train_loader, optimizer, epoch, hook)
+ test(model, loss_fn, device, test_loader, hook)
scheduler.step()
if args.save_model:
diff --git a/sagemaker-debugger/pytorch_profiling/entry_point/pt_res50_cifar10_distributed.py b/sagemaker-debugger/pytorch_profiling/entry_point/pt_res50_cifar10_distributed.py
index 384333ce45..cc2e60f047 100644
--- a/sagemaker-debugger/pytorch_profiling/entry_point/pt_res50_cifar10_distributed.py
+++ b/sagemaker-debugger/pytorch_profiling/entry_point/pt_res50_cifar10_distributed.py
@@ -53,6 +53,7 @@ def train(batch_size, epoch, net, hook, device, local_rank):
epoch_times = []
if hook:
+ hook.register_module(net)
hook.register_loss(loss_optim)
# train the model
diff --git a/sagemaker-debugger/pytorch_profiling/entry_point/pt_res50_cifar10_horovod_dataloader.py b/sagemaker-debugger/pytorch_profiling/entry_point/pt_res50_cifar10_horovod_dataloader.py
index 0a46a6dabd..290baf6738 100644
--- a/sagemaker-debugger/pytorch_profiling/entry_point/pt_res50_cifar10_horovod_dataloader.py
+++ b/sagemaker-debugger/pytorch_profiling/entry_point/pt_res50_cifar10_horovod_dataloader.py
@@ -101,6 +101,7 @@ def train(batch_size, epoch, net, hook, args, local_rank):
print("START VALIDATING")
if hook:
+ hook.register_module(net)
hook.set_mode(modes.EVAL)
test_sampler.set_epoch(i)
net.eval()
diff --git a/sagemaker-debugger/pytorch_profiling/entry_point/pytorch_res50_cifar10_dataloader.py b/sagemaker-debugger/pytorch_profiling/entry_point/pytorch_res50_cifar10_dataloader.py
index 095cd57032..6636b67979 100644
--- a/sagemaker-debugger/pytorch_profiling/entry_point/pytorch_res50_cifar10_dataloader.py
+++ b/sagemaker-debugger/pytorch_profiling/entry_point/pytorch_res50_cifar10_dataloader.py
@@ -75,6 +75,7 @@ def train(args, net, device):
epoch_times = []
if hook:
+ hook.register_module(net)
hook.register_loss(loss_optim)
# train the model
diff --git a/sagemaker-experiments/index.rst b/sagemaker-experiments/index.rst
index 6d08a5f809..4a9b522e2a 100644
--- a/sagemaker-experiments/index.rst
+++ b/sagemaker-experiments/index.rst
@@ -35,3 +35,11 @@ Search
:maxdepth: 1
../advanced_functionality/search/ml_experiment_management_using_search
+
+Hyperparameter Tuning Job
+=========================
+
+.. toctree::
+ :maxdepth: 1
+
+ associate-hyper-parameter-tuning-job/associate-hyperparameter-tuning-job
diff --git a/sagemaker-experiments/mnist-handwritten-digits-classification-experiment/mnist-handwritten-digits-classification-experiment.ipynb b/sagemaker-experiments/mnist-handwritten-digits-classification-experiment/mnist-handwritten-digits-classification-experiment.ipynb
index 4acb4f7629..d396fb5bdf 100644
--- a/sagemaker-experiments/mnist-handwritten-digits-classification-experiment/mnist-handwritten-digits-classification-experiment.ipynb
+++ b/sagemaker-experiments/mnist-handwritten-digits-classification-experiment/mnist-handwritten-digits-classification-experiment.ipynb
@@ -2,7 +2,16 @@
"cells": [
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 0.018859,
+ "end_time": "2022-04-18T00:27:16.418021",
+ "exception": false,
+ "start_time": "2022-04-18T00:27:16.399162",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"# Run a SageMaker Experiment with MNIST Handwritten Digits Classification\n",
"\n",
@@ -39,7 +48,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 0.018686,
+ "end_time": "2022-04-18T00:27:16.455927",
+ "exception": false,
+ "start_time": "2022-04-18T00:27:16.437241",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"## Install modules"
]
@@ -47,7 +65,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:27:16.498560Z",
+ "iopub.status.busy": "2022-04-18T00:27:16.497781Z",
+ "iopub.status.idle": "2022-04-18T00:27:16.500039Z",
+ "shell.execute_reply": "2022-04-18T00:27:16.500519Z"
+ },
+ "papermill": {
+ "duration": 0.025799,
+ "end_time": "2022-04-18T00:27:16.500670",
+ "exception": false,
+ "start_time": "2022-04-18T00:27:16.474871",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"import sys"
@@ -55,7 +88,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 0.019204,
+ "end_time": "2022-04-18T00:27:16.539083",
+ "exception": false,
+ "start_time": "2022-04-18T00:27:16.519879",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"### Install the SageMaker Experiments Python SDK"
]
@@ -63,7 +105,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:27:16.582163Z",
+ "iopub.status.busy": "2022-04-18T00:27:16.581507Z",
+ "iopub.status.idle": "2022-04-18T00:27:18.732886Z",
+ "shell.execute_reply": "2022-04-18T00:27:18.731593Z"
+ },
+ "papermill": {
+ "duration": 2.175113,
+ "end_time": "2022-04-18T00:27:18.733009",
+ "exception": false,
+ "start_time": "2022-04-18T00:27:16.557896",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"!{sys.executable} -m pip install sagemaker-experiments==0.1.35"
@@ -71,7 +128,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 0.020485,
+ "end_time": "2022-04-18T00:27:18.774120",
+ "exception": false,
+ "start_time": "2022-04-18T00:27:18.753635",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"### Install PyTorch"
]
@@ -79,7 +145,23 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:27:18.826656Z",
+ "iopub.status.busy": "2022-04-18T00:27:18.823942Z",
+ "iopub.status.idle": "2022-04-18T00:30:31.050771Z",
+ "shell.execute_reply": "2022-04-18T00:30:31.050056Z"
+ },
+ "papermill": {
+ "duration": 192.25645,
+ "end_time": "2022-04-18T00:30:31.050890",
+ "exception": false,
+ "start_time": "2022-04-18T00:27:18.794440",
+ "status": "completed"
+ },
+ "scrolled": true,
+ "tags": []
+ },
"outputs": [],
"source": [
"# PyTorch version needs to be the same in both the notebook instance and the training job container\n",
@@ -92,7 +174,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 1.097451,
+ "end_time": "2022-04-18T00:30:33.138064",
+ "exception": false,
+ "start_time": "2022-04-18T00:30:32.040613",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"## Setup"
]
@@ -100,7 +191,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:30:35.335151Z",
+ "iopub.status.busy": "2022-04-18T00:30:35.271802Z",
+ "iopub.status.idle": "2022-04-18T00:30:38.949477Z",
+ "shell.execute_reply": "2022-04-18T00:30:38.950150Z"
+ },
+ "papermill": {
+ "duration": 4.792811,
+ "end_time": "2022-04-18T00:30:38.950328",
+ "exception": false,
+ "start_time": "2022-04-18T00:30:34.157517",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"import time\n",
@@ -128,18 +234,43 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:30:41.152153Z",
+ "iopub.status.busy": "2022-04-18T00:30:41.151285Z",
+ "iopub.status.idle": "2022-04-18T00:30:42.253546Z",
+ "shell.execute_reply": "2022-04-18T00:30:42.253098Z"
+ },
+ "papermill": {
+ "duration": 2.294368,
+ "end_time": "2022-04-18T00:30:42.253653",
+ "exception": false,
+ "start_time": "2022-04-18T00:30:39.959285",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"sm_sess = sagemaker.Session()\n",
"sess = sm_sess.boto_session\n",
"sm = sm_sess.sagemaker_client\n",
- "role = get_execution_role()"
+ "role = get_execution_role()\n",
+ "region = sess.region_name"
]
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 1.20861,
+ "end_time": "2022-04-18T00:30:44.261610",
+ "exception": false,
+ "start_time": "2022-04-18T00:30:43.053000",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"## Download the dataset\n",
"We download the MNIST handwritten digits dataset, and then apply a transformation on each image."
@@ -148,7 +279,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:30:46.451896Z",
+ "iopub.status.busy": "2022-04-18T00:30:46.450986Z",
+ "iopub.status.idle": "2022-04-18T00:30:49.864469Z",
+ "shell.execute_reply": "2022-04-18T00:30:49.864897Z"
+ },
+ "papermill": {
+ "duration": 4.528502,
+ "end_time": "2022-04-18T00:30:49.865034",
+ "exception": false,
+ "start_time": "2022-04-18T00:30:45.336532",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"bucket = sm_sess.default_bucket()\n",
@@ -184,7 +330,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 0.586926,
+ "end_time": "2022-04-18T00:30:50.860446",
+ "exception": false,
+ "start_time": "2022-04-18T00:30:50.273520",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"View an example image from the dataset."
]
@@ -192,7 +347,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:30:53.140056Z",
+ "iopub.status.busy": "2022-04-18T00:30:53.139171Z",
+ "iopub.status.idle": "2022-04-18T00:30:53.646029Z",
+ "shell.execute_reply": "2022-04-18T00:30:53.645594Z"
+ },
+ "papermill": {
+ "duration": 1.689988,
+ "end_time": "2022-04-18T00:30:53.646180",
+ "exception": false,
+ "start_time": "2022-04-18T00:30:51.956192",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"plt.imshow(train_set.data[2].numpy())"
@@ -200,7 +370,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 1.012717,
+ "end_time": "2022-04-18T00:30:55.859085",
+ "exception": false,
+ "start_time": "2022-04-18T00:30:54.846368",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"After transforming the images in the dataset, we upload it to S3."
]
@@ -208,7 +387,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:30:58.636462Z",
+ "iopub.status.busy": "2022-04-18T00:30:58.635236Z",
+ "iopub.status.idle": "2022-04-18T00:31:02.394223Z",
+ "shell.execute_reply": "2022-04-18T00:31:02.394609Z"
+ },
+ "papermill": {
+ "duration": 4.954501,
+ "end_time": "2022-04-18T00:31:02.394743",
+ "exception": false,
+ "start_time": "2022-04-18T00:30:57.440242",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"inputs = sagemaker.Session().upload_data(path=\"mnist\", bucket=bucket, key_prefix=prefix)"
@@ -216,7 +410,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 1.097592,
+ "end_time": "2022-04-18T00:31:04.456979",
+ "exception": false,
+ "start_time": "2022-04-18T00:31:03.359387",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"Now let's track the parameters from the data pre-processing step."
]
@@ -224,7 +427,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:31:06.655465Z",
+ "iopub.status.busy": "2022-04-18T00:31:06.654595Z",
+ "iopub.status.idle": "2022-04-18T00:31:07.240604Z",
+ "shell.execute_reply": "2022-04-18T00:31:07.239833Z"
+ },
+ "papermill": {
+ "duration": 1.694509,
+ "end_time": "2022-04-18T00:31:07.240769",
+ "exception": false,
+ "start_time": "2022-04-18T00:31:05.546260",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"with Tracker.create(display_name=\"Preprocessing\", sagemaker_boto_client=sm) as tracker:\n",
@@ -240,7 +458,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 1.105926,
+ "end_time": "2022-04-18T00:31:09.463393",
+ "exception": false,
+ "start_time": "2022-04-18T00:31:08.357467",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"## Step 1: Set up the Experiment\n",
"\n",
@@ -249,7 +476,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 1.093129,
+ "end_time": "2022-04-18T00:31:11.653260",
+ "exception": false,
+ "start_time": "2022-04-18T00:31:10.560131",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"### Create an Experiment"
]
@@ -257,7 +493,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:31:14.036680Z",
+ "iopub.status.busy": "2022-04-18T00:31:14.036097Z",
+ "iopub.status.idle": "2022-04-18T00:31:14.095063Z",
+ "shell.execute_reply": "2022-04-18T00:31:14.094320Z"
+ },
+ "papermill": {
+ "duration": 1.326994,
+ "end_time": "2022-04-18T00:31:14.095209",
+ "exception": false,
+ "start_time": "2022-04-18T00:31:12.768215",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"mnist_experiment = Experiment.create(\n",
@@ -270,7 +521,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 1.125119,
+ "end_time": "2022-04-18T00:31:16.263389",
+ "exception": false,
+ "start_time": "2022-04-18T00:31:15.138270",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"## Step 2: Track Experiment\n",
"### Now create a Trial for each training run to track its inputs, parameters, and metrics.\n",
@@ -280,7 +540,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:31:18.563017Z",
+ "iopub.status.busy": "2022-04-18T00:31:18.562409Z",
+ "iopub.status.idle": "2022-04-18T00:31:18.637727Z",
+ "shell.execute_reply": "2022-04-18T00:31:18.637141Z"
+ },
+ "papermill": {
+ "duration": 1.281791,
+ "end_time": "2022-04-18T00:31:18.637855",
+ "exception": false,
+ "start_time": "2022-04-18T00:31:17.356064",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"from sagemaker.pytorch import PyTorch, PyTorchModel"
@@ -289,7 +564,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:31:20.939373Z",
+ "iopub.status.busy": "2022-04-18T00:31:20.938430Z",
+ "iopub.status.idle": "2022-04-18T00:31:20.940663Z",
+ "shell.execute_reply": "2022-04-18T00:31:20.941065Z"
+ },
+ "papermill": {
+ "duration": 1.18469,
+ "end_time": "2022-04-18T00:31:20.941201",
+ "exception": false,
+ "start_time": "2022-04-18T00:31:19.756511",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"hidden_channel_trial_name_map = {}"
@@ -297,7 +587,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 1.690973,
+ "end_time": "2022-04-18T00:31:23.651931",
+ "exception": false,
+ "start_time": "2022-04-18T00:31:21.960958",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"If you want to run the following five training jobs in parallel, you may need to increase your resource limit. Here we run them sequentially."
]
@@ -305,7 +604,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:31:25.855290Z",
+ "iopub.status.busy": "2022-04-18T00:31:25.854387Z",
+ "iopub.status.idle": "2022-04-18T00:31:25.856228Z",
+ "shell.execute_reply": "2022-04-18T00:31:25.856672Z"
+ },
+ "papermill": {
+ "duration": 1.10193,
+ "end_time": "2022-04-18T00:31:25.857106",
+ "exception": false,
+ "start_time": "2022-04-18T00:31:24.755176",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"preprocessing_trial_component = tracker.trial_component"
@@ -314,7 +628,23 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:31:28.047401Z",
+ "iopub.status.busy": "2022-04-18T00:31:28.046591Z",
+ "iopub.status.idle": "2022-04-18T00:54:55.222696Z",
+ "shell.execute_reply": "2022-04-18T00:54:55.223525Z"
+ },
+ "papermill": {
+ "duration": 1408.284911,
+ "end_time": "2022-04-18T00:54:55.223686",
+ "exception": false,
+ "start_time": "2022-04-18T00:31:26.938775",
+ "status": "completed"
+ },
+ "scrolled": true,
+ "tags": []
+ },
"outputs": [],
"source": [
"for i, num_hidden_channel in enumerate([2, 5, 10, 20, 32]):\n",
@@ -375,7 +705,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 0.464007,
+ "end_time": "2022-04-18T00:54:56.173858",
+ "exception": false,
+ "start_time": "2022-04-18T00:54:55.709851",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"### Compare the model training runs for an experiment\n",
"\n",
@@ -384,7 +723,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 0.403776,
+ "end_time": "2022-04-18T00:54:56.987527",
+ "exception": false,
+ "start_time": "2022-04-18T00:54:56.583751",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"### Some Simple Analyses"
]
@@ -392,7 +740,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:54:57.808976Z",
+ "iopub.status.busy": "2022-04-18T00:54:57.808166Z",
+ "iopub.status.idle": "2022-04-18T00:54:57.810404Z",
+ "shell.execute_reply": "2022-04-18T00:54:57.810812Z"
+ },
+ "papermill": {
+ "duration": 0.415803,
+ "end_time": "2022-04-18T00:54:57.810945",
+ "exception": false,
+ "start_time": "2022-04-18T00:54:57.395142",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"search_expression = {\n",
@@ -409,7 +772,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:54:58.633855Z",
+ "iopub.status.busy": "2022-04-18T00:54:58.624955Z",
+ "iopub.status.idle": "2022-04-18T00:54:58.635871Z",
+ "shell.execute_reply": "2022-04-18T00:54:58.636463Z"
+ },
+ "papermill": {
+ "duration": 0.430927,
+ "end_time": "2022-04-18T00:54:58.636603",
+ "exception": false,
+ "start_time": "2022-04-18T00:54:58.205676",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"trial_component_analytics = ExperimentAnalytics(\n",
@@ -426,7 +804,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:54:59.461683Z",
+ "iopub.status.busy": "2022-04-18T00:54:59.460118Z",
+ "iopub.status.idle": "2022-04-18T00:54:59.583688Z",
+ "shell.execute_reply": "2022-04-18T00:54:59.583260Z"
+ },
+ "papermill": {
+ "duration": 0.5529,
+ "end_time": "2022-04-18T00:54:59.583802",
+ "exception": false,
+ "start_time": "2022-04-18T00:54:59.030902",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"trial_component_analytics.dataframe()"
@@ -434,7 +827,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 0.418856,
+ "end_time": "2022-04-18T00:55:00.410510",
+ "exception": false,
+ "start_time": "2022-04-18T00:54:59.991654",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"To isolate and measure the impact of change in hidden channels on model accuracy, we vary the number of hidden channel and fix the value for other hyperparameters.\n",
"\n",
@@ -444,7 +846,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:55:01.341853Z",
+ "iopub.status.busy": "2022-04-18T00:55:01.341153Z",
+ "iopub.status.idle": "2022-04-18T00:55:01.364915Z",
+ "shell.execute_reply": "2022-04-18T00:55:01.365729Z"
+ },
+ "papermill": {
+ "duration": 0.550558,
+ "end_time": "2022-04-18T00:55:01.365871",
+ "exception": false,
+ "start_time": "2022-04-18T00:55:00.815313",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"lineage_table = ExperimentAnalytics(\n",
@@ -466,7 +883,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:55:02.222247Z",
+ "iopub.status.busy": "2022-04-18T00:55:02.221601Z",
+ "iopub.status.idle": "2022-04-18T00:55:02.298149Z",
+ "shell.execute_reply": "2022-04-18T00:55:02.297691Z"
+ },
+ "papermill": {
+ "duration": 0.526539,
+ "end_time": "2022-04-18T00:55:02.298270",
+ "exception": false,
+ "start_time": "2022-04-18T00:55:01.771731",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"lineage_table.dataframe()"
@@ -476,9 +908,37 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "## Deploy an endpoint for the best training job / trial component\n",
+ "## Push best training job model to model registry\n",
+ "Now we take the best model and push it to [model registry](#https://docs.aws.amazon.com/sagemaker/latest/dg/model-registry.html)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Step 1: Create a model package group."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import time\n",
"\n",
- "Now we take the best model and deploy it to an endpoint so it is available to perform inference."
+ "model_package_group_name = \"mnist-handwritten-digit-classification\" + str(round(time.time()))\n",
+ "model_package_group_input_dict = {\n",
+ " \"ModelPackageGroupName\": model_package_group_name,\n",
+ " \"ModelPackageGroupDescription\": \"Sample model package group\",\n",
+ "}\n",
+ "\n",
+ "create_model_package_group_response = sm.create_model_package_group(\n",
+ " **model_package_group_input_dict\n",
+ ")\n",
+ "model_package_arn = create_model_package_group_response[\"ModelPackageGroupArn\"]\n",
+ "\n",
+ "print(f\"ModelPackageGroup Arn : {model_package_arn}\")"
]
},
{
@@ -487,10 +947,52 @@
"metadata": {},
"outputs": [],
"source": [
- "# Pulling best based on sort in the analytics/dataframe, so first is best....\n",
+ "model_package_arn"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Step 2: Get the best model training job from SageMaker experiments API"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "scrolled": true
+ },
+ "outputs": [],
+ "source": [
"best_trial_component_name = trial_component_analytics.dataframe().iloc[0][\"TrialComponentName\"]\n",
- "best_trial_component = TrialComponent.load(best_trial_component_name)\n",
- "\n",
+ "best_trial_component = TrialComponent.load(best_trial_component_name)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "best_trial_component.trial_component_name"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Step 3: Register the best model.\n",
+ "By default, the model is registered with the `approval_status` set to `PendingManualApproval`. Users can then use API to manually approve the model based on any criteria set for model evaluation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# create model object\n",
"model_data = best_trial_component.output_artifacts[\"SageMaker.ModelArtifact\"].value\n",
"env = {\n",
" \"hidden_channels\": str(int(best_trial_component.parameters[\"hidden_channels\"])),\n",
@@ -506,32 +1008,186 @@
" sagemaker_session=sagemaker.Session(sagemaker_client=sm),\n",
" framework_version=\"1.1.0\",\n",
" name=best_trial_component.trial_component_name,\n",
- ")\n",
- "\n",
- "predictor = model.deploy(instance_type=\"ml.m5.xlarge\", initial_instance_count=1)"
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_package = model.register(\n",
+ " content_types=[\"*\"],\n",
+ " response_types=[\"application/json\"],\n",
+ " inference_instances=[\"ml.m5.xlarge\"],\n",
+ " transform_instances=[\"ml.m5.xlarge\"],\n",
+ " description=\"MNIST image classification model\",\n",
+ " approval_status=\"PendingManualApproval\",\n",
+ " model_package_group_name=model_package_group_name,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### Step 4: Verify model has been registered."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sm.describe_model_package_group(ModelPackageGroupName=model_package_group_name)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "## check model version\n",
+ "sm.list_model_packages(ModelPackageGroupName=model_package_group_name)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_package_arn = sm.list_model_packages(ModelPackageGroupName=model_package_group_name)[\n",
+ " \"ModelPackageSummaryList\"\n",
+ "][0][\"ModelPackageArn\"]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "### Update the model status to approved\n",
+ "model_package_update_input_dict = {\n",
+ " \"ModelPackageArn\": model_package_arn,\n",
+ " \"ModelApprovalStatus\": \"Approved\",\n",
+ "}\n",
+ "model_package_update_response = sm.update_model_package(**model_package_update_input_dict)"
]
},
{
"cell_type": "markdown",
+ "metadata": {
+ "papermill": {
+ "duration": 0.46695,
+ "end_time": "2022-04-18T00:55:03.317414",
+ "exception": false,
+ "start_time": "2022-04-18T00:55:02.850464",
+ "status": "completed"
+ },
+ "tags": []
+ },
+ "source": [
+ "## Deploy an endpoint for the lastest approved version of the model from model registry\n",
+ "\n",
+ "Now we take the best model and deploy it to an endpoint so it is available to perform inference."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {},
+ "outputs": [],
+ "source": [
+ "from datetime import datetime\n",
+ "\n",
+ "now = datetime.now()\n",
+ "time = now.strftime(\"%m-%d-%Y-%H-%M-%S\")\n",
+ "print(\"time:\", time)\n",
+ "endpoint_name = f\"cnn-mnist-{time}\"\n",
+ "endpoint_name"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_package.deploy(\n",
+ " initial_instance_count=1, instance_type=\"ml.m5.xlarge\", endpoint_name=endpoint_name\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "papermill": {
+ "duration": 0.421451,
+ "end_time": "2022-04-18T00:57:06.742170",
+ "exception": false,
+ "start_time": "2022-04-18T00:57:06.320719",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"## Cleanup\n",
"\n",
"Once we're done, clean up the endpoint to prevent unnecessary billing."
]
},
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:57:07.570445Z",
+ "iopub.status.busy": "2022-04-18T00:57:07.569847Z",
+ "iopub.status.idle": "2022-04-18T00:57:07.821433Z",
+ "shell.execute_reply": "2022-04-18T00:57:07.821854Z"
+ },
+ "papermill": {
+ "duration": 0.672295,
+ "end_time": "2022-04-18T00:57:07.822030",
+ "exception": false,
+ "start_time": "2022-04-18T00:57:07.149735",
+ "status": "completed"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "sagemaker_client = boto3.client(\"sagemaker\", region_name=region)\n",
+ "# Delete endpoint\n",
+ "sagemaker_client.delete_endpoint(EndpointName=endpoint_name)"
+ ]
+ },
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
- "predictor.delete_endpoint()"
+ "sagemaker_client.delete_endpoint_config(EndpointConfigName=endpoint_name)"
]
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 0.409404,
+ "end_time": "2022-04-18T00:57:08.629472",
+ "exception": false,
+ "start_time": "2022-04-18T00:57:08.220068",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"Trial components can exist independently of trials and experiments. You might want keep them if you plan on further exploration. If not, delete all experiment artifacts."
]
@@ -539,7 +1195,22 @@
{
"cell_type": "code",
"execution_count": null,
- "metadata": {},
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-04-18T00:57:09.463759Z",
+ "iopub.status.busy": "2022-04-18T00:57:09.463185Z",
+ "iopub.status.idle": "2022-04-18T00:57:36.442713Z",
+ "shell.execute_reply": "2022-04-18T00:57:36.442286Z"
+ },
+ "papermill": {
+ "duration": 27.406126,
+ "end_time": "2022-04-18T00:57:36.442825",
+ "exception": false,
+ "start_time": "2022-04-18T00:57:09.036699",
+ "status": "completed"
+ },
+ "tags": []
+ },
"outputs": [],
"source": [
"mnist_experiment.delete_all(action=\"--force\")"
@@ -547,7 +1218,16 @@
},
{
"cell_type": "markdown",
- "metadata": {},
+ "metadata": {
+ "papermill": {
+ "duration": 0.422378,
+ "end_time": "2022-04-18T00:57:37.349802",
+ "exception": false,
+ "start_time": "2022-04-18T00:57:36.927424",
+ "status": "completed"
+ },
+ "tags": []
+ },
"source": [
"## Contact\n",
"Submit any questions or issues to https://github.com/aws/sagemaker-experiments/issues or mention @aws/sagemakerexperimentsadmin "
@@ -557,9 +1237,9 @@
"metadata": {
"instance_type": "ml.t3.medium",
"kernelspec": {
- "display_name": "conda_pytorch_p36",
+ "display_name": "Python 3 (Data Science)",
"language": "python",
- "name": "conda_pytorch_p36"
+ "name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:us-west-2:236514542706:image/datascience-1.0"
},
"language_info": {
"codemirror_mode": {
@@ -572,8 +1252,22 @@
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.7.10"
+ },
+ "papermill": {
+ "default_parameters": {},
+ "duration": 1822.995915,
+ "end_time": "2022-04-18T00:57:38.382694",
+ "environment_variables": {},
+ "exception": null,
+ "input_path": "mnist-handwritten-digits-classification-experiment.ipynb",
+ "output_path": "/opt/ml/processing/output/mnist-handwritten-digits-classification-experiment-2022-04-18-00-12-36.ipynb",
+ "parameters": {
+ "kms_key": "arn:aws:kms:us-west-2:000000000000:1234abcd-12ab-34cd-56ef-1234567890ab"
+ },
+ "start_time": "2022-04-18T00:27:15.386779",
+ "version": "2.3.4"
}
},
"nbformat": 4,
- "nbformat_minor": 4
-}
+ "nbformat_minor": 5
+}
\ No newline at end of file
diff --git a/sagemaker-experiments/mnist-handwritten-digits-classification-experiment/mnist-handwritten-digits-classification-experiment_outputs.ipynb b/sagemaker-experiments/mnist-handwritten-digits-classification-experiment/mnist-handwritten-digits-classification-experiment_outputs.ipynb
index 679af65223..4ef99eda56 100644
--- a/sagemaker-experiments/mnist-handwritten-digits-classification-experiment/mnist-handwritten-digits-classification-experiment_outputs.ipynb
+++ b/sagemaker-experiments/mnist-handwritten-digits-classification-experiment/mnist-handwritten-digits-classification-experiment_outputs.ipynb
@@ -1,14 +1,42 @@
{
"cells": [
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "id": "bbf887c3",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-08-10T21:51:36.923656Z",
+ "iopub.status.busy": "2022-08-10T21:51:36.922829Z",
+ "iopub.status.idle": "2022-08-10T21:51:36.925154Z",
+ "shell.execute_reply": "2022-08-10T21:51:36.924640Z"
+ },
+ "papermill": {
+ "duration": 0.03168,
+ "end_time": "2022-08-10T21:51:36.925267",
+ "exception": false,
+ "start_time": "2022-08-10T21:51:36.893587",
+ "status": "completed"
+ },
+ "tags": [
+ "injected-parameters"
+ ]
+ },
+ "outputs": [],
+ "source": [
+ "# Parameters\n",
+ "kms_key = \"arn:aws:kms:us-west-2:000000000000:1234abcd-12ab-34cd-56ef-1234567890ab\"\n"
+ ]
+ },
{
"cell_type": "markdown",
- "id": "0506553a",
+ "id": "daf4a537",
"metadata": {
"papermill": {
- "duration": 0.018859,
- "end_time": "2022-04-18T00:27:16.418021",
+ "duration": 0.02532,
+ "end_time": "2022-08-10T21:51:36.976044",
"exception": false,
- "start_time": "2022-04-18T00:27:16.399162",
+ "start_time": "2022-08-10T21:51:36.950724",
"status": "completed"
},
"tags": []
@@ -49,13 +77,13 @@
},
{
"cell_type": "markdown",
- "id": "ded7b57b",
+ "id": "aa27e803",
"metadata": {
"papermill": {
- "duration": 0.018686,
- "end_time": "2022-04-18T00:27:16.455927",
+ "duration": 0.024762,
+ "end_time": "2022-08-10T21:51:37.025914",
"exception": false,
- "start_time": "2022-04-18T00:27:16.437241",
+ "start_time": "2022-08-10T21:51:37.001152",
"status": "completed"
},
"tags": []
@@ -67,19 +95,19 @@
{
"cell_type": "code",
"execution_count": 2,
- "id": "33aa6eef",
+ "id": "e28e990c",
"metadata": {
"execution": {
- "iopub.execute_input": "2022-04-18T00:27:16.498560Z",
- "iopub.status.busy": "2022-04-18T00:27:16.497781Z",
- "iopub.status.idle": "2022-04-18T00:27:16.500039Z",
- "shell.execute_reply": "2022-04-18T00:27:16.500519Z"
+ "iopub.execute_input": "2022-08-10T21:51:37.080060Z",
+ "iopub.status.busy": "2022-08-10T21:51:37.079380Z",
+ "iopub.status.idle": "2022-08-10T21:51:37.081711Z",
+ "shell.execute_reply": "2022-08-10T21:51:37.082190Z"
},
"papermill": {
- "duration": 0.025799,
- "end_time": "2022-04-18T00:27:16.500670",
+ "duration": 0.031316,
+ "end_time": "2022-08-10T21:51:37.082361",
"exception": false,
- "start_time": "2022-04-18T00:27:16.474871",
+ "start_time": "2022-08-10T21:51:37.051045",
"status": "completed"
},
"tags": []
@@ -91,13 +119,13 @@
},
{
"cell_type": "markdown",
- "id": "871cbff2",
+ "id": "bb0a6ed2",
"metadata": {
"papermill": {
- "duration": 0.019204,
- "end_time": "2022-04-18T00:27:16.539083",
+ "duration": 0.025572,
+ "end_time": "2022-08-10T21:51:37.132910",
"exception": false,
- "start_time": "2022-04-18T00:27:16.519879",
+ "start_time": "2022-08-10T21:51:37.107338",
"status": "completed"
},
"tags": []
@@ -109,19 +137,19 @@
{
"cell_type": "code",
"execution_count": 3,
- "id": "f8353931",
+ "id": "48d95e9e",
"metadata": {
"execution": {
- "iopub.execute_input": "2022-04-18T00:27:16.582163Z",
- "iopub.status.busy": "2022-04-18T00:27:16.581507Z",
- "iopub.status.idle": "2022-04-18T00:27:18.732886Z",
- "shell.execute_reply": "2022-04-18T00:27:18.731593Z"
+ "iopub.execute_input": "2022-08-10T21:51:37.187720Z",
+ "iopub.status.busy": "2022-08-10T21:51:37.186921Z",
+ "iopub.status.idle": "2022-08-10T21:51:39.214241Z",
+ "shell.execute_reply": "2022-08-10T21:51:39.213790Z"
},
"papermill": {
- "duration": 2.175113,
- "end_time": "2022-04-18T00:27:18.733009",
+ "duration": 2.056402,
+ "end_time": "2022-08-10T21:51:39.214365",
"exception": false,
- "start_time": "2022-04-18T00:27:16.557896",
+ "start_time": "2022-08-10T21:51:37.157963",
"status": "completed"
},
"tags": []
@@ -131,53 +159,54 @@
"name": "stdout",
"output_type": "stream",
"text": [
- "Collecting sagemaker-experiments==0.1.35\r\n"
+ "/opt/conda/lib/python3.7/site-packages/secretstorage/dhcrypto.py:16: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead\r\n",
+ " from cryptography.utils import int_from_bytes\r\n",
+ "/opt/conda/lib/python3.7/site-packages/secretstorage/util.py:25: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead\r\n",
+ " from cryptography.utils import int_from_bytes\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- " Downloading sagemaker_experiments-0.1.35-py3-none-any.whl (42 kB)\r\n",
- "\u001b[?25l\r",
- "\u001b[K |███████▊ | 10 kB 29.6 MB/s eta 0:00:01\r",
- "\u001b[K |███████████████▌ | 20 kB 33.3 MB/s eta 0:00:01\r",
- "\u001b[K |███████████████████████▎ | 30 kB 4.6 MB/s eta 0:00:01\r",
- "\u001b[K |███████████████████████████████ | 40 kB 5.8 MB/s eta 0:00:01\r",
- "\u001b[K |████████████████████████████████| 42 kB 1.2 MB/s \r\n",
- "\u001b[?25hRequirement already satisfied: boto3>=1.16.27 in /opt/conda/lib/python3.6/site-packages (from sagemaker-experiments==0.1.35) (1.20.7)\r\n",
- "Requirement already satisfied: botocore<1.24.0,>=1.23.7 in /opt/conda/lib/python3.6/site-packages (from boto3>=1.16.27->sagemaker-experiments==0.1.35) (1.23.7)\r\n",
- "Requirement already satisfied: s3transfer<0.6.0,>=0.5.0 in /opt/conda/lib/python3.6/site-packages (from boto3>=1.16.27->sagemaker-experiments==0.1.35) (0.5.2)\r\n",
- "Requirement already satisfied: jmespath<1.0.0,>=0.7.1 in /opt/conda/lib/python3.6/site-packages (from boto3>=1.16.27->sagemaker-experiments==0.1.35) (0.10.0)\r\n",
- "Requirement already satisfied: python-dateutil<3.0.0,>=2.1 in /opt/conda/lib/python3.6/site-packages (from botocore<1.24.0,>=1.23.7->boto3>=1.16.27->sagemaker-experiments==0.1.35) (2.8.1)\r\n",
- "Requirement already satisfied: urllib3<1.27,>=1.25.4 in /opt/conda/lib/python3.6/site-packages (from botocore<1.24.0,>=1.23.7->boto3>=1.16.27->sagemaker-experiments==0.1.35) (1.25.11)\r\n",
- "Requirement already satisfied: six>=1.5 in /opt/conda/lib/python3.6/site-packages (from python-dateutil<3.0.0,>=2.1->botocore<1.24.0,>=1.23.7->boto3>=1.16.27->sagemaker-experiments==0.1.35) (1.15.0)\r\n"
+ "Collecting sagemaker-experiments==0.1.35\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "Installing collected packages: sagemaker-experiments\r\n",
- " Attempting uninstall: sagemaker-experiments\r\n",
- " Found existing installation: sagemaker-experiments 0.1.7\r\n",
- " Uninstalling sagemaker-experiments-0.1.7:\r\n"
+ " Downloading sagemaker_experiments-0.1.35-py3-none-any.whl (42 kB)\r\n",
+ "\u001b[?25l\r",
+ "\u001b[K |███████▊ | 10 kB 27.7 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████▌ | 20 kB 30.3 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████▎ | 30 kB 13.5 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████████ | 40 kB 6.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 42 kB 1.3 MB/s \r\n",
+ "\u001b[?25hRequirement already satisfied: boto3>=1.16.27 in /opt/conda/lib/python3.7/site-packages (from sagemaker-experiments==0.1.35) (1.20.47)\r\n",
+ "Requirement already satisfied: botocore<1.24.0,>=1.23.47 in /opt/conda/lib/python3.7/site-packages (from boto3>=1.16.27->sagemaker-experiments==0.1.35) (1.23.47)\r\n",
+ "Requirement already satisfied: jmespath<1.0.0,>=0.7.1 in /opt/conda/lib/python3.7/site-packages (from boto3>=1.16.27->sagemaker-experiments==0.1.35) (0.10.0)\r\n",
+ "Requirement already satisfied: s3transfer<0.6.0,>=0.5.0 in /opt/conda/lib/python3.7/site-packages (from boto3>=1.16.27->sagemaker-experiments==0.1.35) (0.5.0)\r\n",
+ "Requirement already satisfied: urllib3<1.27,>=1.25.4 in /opt/conda/lib/python3.7/site-packages (from botocore<1.24.0,>=1.23.47->boto3>=1.16.27->sagemaker-experiments==0.1.35) (1.26.6)\r\n",
+ "Requirement already satisfied: python-dateutil<3.0.0,>=2.1 in /opt/conda/lib/python3.7/site-packages (from botocore<1.24.0,>=1.23.47->boto3>=1.16.27->sagemaker-experiments==0.1.35) (2.8.1)\r\n",
+ "Requirement already satisfied: six>=1.5 in /opt/conda/lib/python3.7/site-packages (from python-dateutil<3.0.0,>=2.1->botocore<1.24.0,>=1.23.47->boto3>=1.16.27->sagemaker-experiments==0.1.35) (1.14.0)\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- " Successfully uninstalled sagemaker-experiments-0.1.7\r\n"
+ "Installing collected packages: sagemaker-experiments\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\u001b[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\r\n",
- "sagemaker-pytorch-training 1.3.3 requires sagemaker-experiments==0.1.7; python_version >= \"3.6\", but you have sagemaker-experiments 0.1.35 which is incompatible.\u001b[0m\r\n",
- "Successfully installed sagemaker-experiments-0.1.35\r\n"
+ "Successfully installed sagemaker-experiments-0.1.35\r\n",
+ "\u001b[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\u001b[0m\r\n",
+ "\u001b[33mWARNING: You are using pip version 21.1.3; however, version 22.2.2 is available.\r\n",
+ "You should consider upgrading via the '/opt/conda/bin/python3 -m pip install --upgrade pip' command.\u001b[0m\r\n"
]
}
],
@@ -187,13 +216,13 @@
},
{
"cell_type": "markdown",
- "id": "b9e90f18",
+ "id": "61554eb6",
"metadata": {
"papermill": {
- "duration": 0.020485,
- "end_time": "2022-04-18T00:27:18.774120",
+ "duration": 0.026241,
+ "end_time": "2022-08-10T21:51:39.267292",
"exception": false,
- "start_time": "2022-04-18T00:27:18.753635",
+ "start_time": "2022-08-10T21:51:39.241051",
"status": "completed"
},
"tags": []
@@ -205,24 +234,35 @@
{
"cell_type": "code",
"execution_count": 4,
- "id": "027a7dfb",
+ "id": "c6ee2c7c",
"metadata": {
"execution": {
- "iopub.execute_input": "2022-04-18T00:27:18.826656Z",
- "iopub.status.busy": "2022-04-18T00:27:18.823942Z",
- "iopub.status.idle": "2022-04-18T00:30:31.050771Z",
- "shell.execute_reply": "2022-04-18T00:30:31.050056Z"
+ "iopub.execute_input": "2022-08-10T21:51:39.328441Z",
+ "iopub.status.busy": "2022-08-10T21:51:39.327536Z",
+ "iopub.status.idle": "2022-08-10T21:53:52.966696Z",
+ "shell.execute_reply": "2022-08-10T21:53:52.965951Z"
},
"papermill": {
- "duration": 192.25645,
- "end_time": "2022-04-18T00:30:31.050890",
+ "duration": 133.673326,
+ "end_time": "2022-08-10T21:53:52.966874",
"exception": false,
- "start_time": "2022-04-18T00:27:18.794440",
+ "start_time": "2022-08-10T21:51:39.293548",
"status": "completed"
},
+ "scrolled": true,
"tags": []
},
"outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "/opt/conda/lib/python3.7/site-packages/secretstorage/dhcrypto.py:16: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead\r\n",
+ " from cryptography.utils import int_from_bytes\r\n",
+ "/opt/conda/lib/python3.7/site-packages/secretstorage/util.py:25: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead\r\n",
+ " from cryptography.utils import int_from_bytes\r\n"
+ ]
+ },
{
"name": "stdout",
"output_type": "stream",
@@ -234,17 +274,17 @@
"name": "stdout",
"output_type": "stream",
"text": [
- " Downloading torch-1.1.0-cp36-cp36m-manylinux1_x86_64.whl (676.9 MB)\r\n",
+ " Downloading torch-1.1.0-cp37-cp37m-manylinux1_x86_64.whl (676.9 MB)\r\n",
"\u001b[?25l\r",
- "\u001b[K | | 10 kB 3.0 MB/s eta 0:03:47\r",
- "\u001b[K | | 20 kB 4.0 MB/s eta 0:02:50\r",
- "\u001b[K | | 30 kB 4.5 MB/s eta 0:02:33\r",
- "\u001b[K | | 40 kB 3.5 MB/s eta 0:03:16\r",
- "\u001b[K | | 51 kB 4.0 MB/s eta 0:02:50\r",
- "\u001b[K | | 61 kB 4.0 MB/s eta 0:02:51\r",
- "\u001b[K | | 71 kB 4.3 MB/s eta 0:02:38\r",
- "\u001b[K | | 81 kB 4.9 MB/s eta 0:02:20\r",
- "\u001b[K | | 92 kB 5.2 MB/s eta 0:02:12\r",
+ "\u001b[K | | 10 kB 6.2 MB/s eta 0:01:50\r",
+ "\u001b[K | | 20 kB 6.3 MB/s eta 0:01:47\r",
+ "\u001b[K | | 30 kB 6.2 MB/s eta 0:01:49\r",
+ "\u001b[K | | 40 kB 4.2 MB/s eta 0:02:41\r",
+ "\u001b[K | | 51 kB 4.6 MB/s eta 0:02:29\r",
+ "\u001b[K | | 61 kB 5.4 MB/s eta 0:02:06\r",
+ "\u001b[K | | 71 kB 5.3 MB/s eta 0:02:07\r",
+ "\u001b[K | | 81 kB 6.0 MB/s eta 0:01:53\r",
+ "\u001b[K | | 92 kB 6.4 MB/s eta 0:01:45\r",
"\u001b[K | | 102 kB 5.7 MB/s eta 0:01:59\r",
"\u001b[K | | 112 kB 5.7 MB/s eta 0:01:59\r",
"\u001b[K | | 122 kB 5.7 MB/s eta 0:01:59\r",
@@ -286,7 +326,14 @@
"\u001b[K | | 491 kB 5.7 MB/s eta 0:01:59\r",
"\u001b[K | | 501 kB 5.7 MB/s eta 0:01:59\r",
"\u001b[K | | 512 kB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K | | 522 kB 5.7 MB/s eta 0:01:59\r",
+ "\u001b[K | | 522 kB 5.7 MB/s eta 0:01:59"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
"\u001b[K | | 532 kB 5.7 MB/s eta 0:01:59\r",
"\u001b[K | | 542 kB 5.7 MB/s eta 0:01:59\r",
"\u001b[K | | 552 kB 5.7 MB/s eta 0:01:59\r",
@@ -301,14 +348,7 @@
"\u001b[K | | 645 kB 5.7 MB/s eta 0:01:59\r",
"\u001b[K | | 655 kB 5.7 MB/s eta 0:01:59\r",
"\u001b[K | | 665 kB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K | | 675 kB 5.7 MB/s eta 0:01:59"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
+ "\u001b[K | | 675 kB 5.7 MB/s eta 0:01:59\r",
"\u001b[K | | 686 kB 5.7 MB/s eta 0:01:59\r",
"\u001b[K | | 696 kB 5.7 MB/s eta 0:01:59\r",
"\u001b[K | | 706 kB 5.7 MB/s eta 0:01:59\r",
@@ -632,7 +672,14 @@
"\u001b[K |▏ | 4.0 MB 5.7 MB/s eta 0:01:59\r",
"\u001b[K |▏ | 4.0 MB 5.7 MB/s eta 0:01:59\r",
"\u001b[K |▏ | 4.0 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.0 MB 5.7 MB/s eta 0:01:59\r",
+ "\u001b[K |▏ | 4.0 MB 5.7 MB/s eta 0:01:59"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
"\u001b[K |▏ | 4.0 MB 5.7 MB/s eta 0:01:59\r",
"\u001b[K |▏ | 4.0 MB 5.7 MB/s eta 0:01:59\r",
"\u001b[K |▏ | 4.0 MB 5.7 MB/s eta 0:01:59\r",
@@ -671,69 +718,62 @@
"\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:59\r",
"\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:59\r",
"\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:59"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
- "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.7 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.7 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.7 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.7 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▏ | 4.7 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.7 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.7 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.7 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.7 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:59\r",
- "\u001b[K |▎ | 5.0 MB 5.7 MB/s eta 0:01:59\r",
+ "\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.4 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.5 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.6 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.7 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.7 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.7 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.7 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▏ | 4.7 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.7 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.7 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.7 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.7 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.8 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 4.9 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▎ | 5.0 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▎ | 5.0 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▎ | 5.0 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▎ | 5.0 MB 5.7 MB/s eta 0:01:58\r",
@@ -1067,7 +1107,14 @@
"\u001b[K |▍ | 8.3 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▍ | 8.4 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▍ | 8.4 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▍ | 8.4 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▍ | 8.4 MB 5.7 MB/s eta 0:01:58"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
"\u001b[K |▍ | 8.4 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▍ | 8.4 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▍ | 8.4 MB 5.7 MB/s eta 0:01:58\r",
@@ -1098,14 +1145,7 @@
"\u001b[K |▍ | 8.7 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▍ | 8.7 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▍ | 8.7 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▍ | 8.7 MB 5.7 MB/s eta 0:01:58"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
+ "\u001b[K |▍ | 8.7 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▍ | 8.7 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▍ | 8.7 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▍ | 8.7 MB 5.7 MB/s eta 0:01:58\r",
@@ -1242,61 +1282,61 @@
"\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:58\r",
"\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:58\r",
- "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:58\r",
+ "\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.1 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.2 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.3 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.4 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.5 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▌ | 10.6 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▌ | 10.7 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▌ | 10.7 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▌ | 10.7 MB 5.7 MB/s eta 0:01:57\r",
@@ -1492,7 +1532,14 @@
"\u001b[K |▋ | 12.6 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▋ | 12.6 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▋ | 12.6 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▋ | 12.7 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▋ | 12.7 MB 5.7 MB/s eta 0:01:57"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
"\u001b[K |▋ | 12.7 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▋ | 12.7 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▋ | 12.7 MB 5.7 MB/s eta 0:01:57\r",
@@ -1539,14 +1586,7 @@
"\u001b[K |▋ | 13.1 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▋ | 13.1 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▋ | 13.1 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▋ | 13.1 MB 5.7 MB/s eta 0:01:57"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
+ "\u001b[K |▋ | 13.1 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▋ | 13.1 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▋ | 13.2 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▋ | 13.2 MB 5.7 MB/s eta 0:01:57\r",
@@ -1641,7 +1681,14 @@
"\u001b[K |▋ | 14.1 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▋ | 14.1 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▋ | 14.1 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 14.1 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▊ | 14.1 MB 5.7 MB/s eta 0:01:57"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
"\u001b[K |▊ | 14.1 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▊ | 14.1 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▊ | 14.1 MB 5.7 MB/s eta 0:01:57\r",
@@ -1805,61 +1852,68 @@
"\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:57\r",
"\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:57\r",
- "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:57\r",
+ "\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.8 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:56"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 15.9 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.0 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.1 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.2 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▊ | 16.3 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |▊ | 16.4 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |▊ | 16.4 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |▊ | 16.4 MB 5.7 MB/s eta 0:01:56\r",
@@ -1985,14 +2039,7 @@
"\u001b[K |▉ | 17.6 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |▉ | 17.6 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |▉ | 17.6 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |▉ | 17.6 MB 5.7 MB/s eta 0:01:56"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
+ "\u001b[K |▉ | 17.6 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |▉ | 17.6 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |▉ | 17.7 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |▉ | 17.7 MB 5.7 MB/s eta 0:01:56\r",
@@ -2024,7 +2071,14 @@
"\u001b[K |▉ | 17.9 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |▉ | 17.9 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |▉ | 18.0 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |▉ | 18.0 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |▉ | 18.0 MB 5.7 MB/s eta 0:01:56"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
"\u001b[K |▉ | 18.0 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |▉ | 18.0 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |▉ | 18.0 MB 5.7 MB/s eta 0:01:56\r",
@@ -2288,7 +2342,14 @@
"\u001b[K |█ | 20.6 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |█ | 20.6 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |█ | 20.7 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 20.7 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |█ | 20.7 MB 5.7 MB/s eta 0:01:56"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
"\u001b[K |█ | 20.7 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |█ | 20.7 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |█ | 20.7 MB 5.7 MB/s eta 0:01:56\r",
@@ -2369,67 +2430,60 @@
"\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:56\r",
"\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:56"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
- "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:56\r",
- "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:56\r",
+ "\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.5 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.6 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.7 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.8 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 21.9 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█ | 22.0 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█ | 22.1 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█ | 22.1 MB 5.7 MB/s eta 0:01:55\r",
@@ -2503,7 +2557,14 @@
"\u001b[K |█ | 22.8 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█ | 22.8 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█ | 22.8 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█ | 22.8 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█ | 22.8 MB 5.7 MB/s eta 0:01:55"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
"\u001b[K |█ | 22.8 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█ | 22.8 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█ | 22.8 MB 5.7 MB/s eta 0:01:55\r",
@@ -2650,7 +2711,14 @@
"\u001b[K |█▏ | 24.3 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▏ | 24.3 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▏ | 24.3 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▏ | 24.3 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█▏ | 24.3 MB 5.7 MB/s eta 0:01:55"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
"\u001b[K |█▏ | 24.3 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▏ | 24.3 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▏ | 24.3 MB 5.7 MB/s eta 0:01:55\r",
@@ -2664,14 +2732,7 @@
"\u001b[K |█▏ | 24.4 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▏ | 24.4 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▏ | 24.4 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▏ | 24.4 MB 5.7 MB/s eta 0:01:55"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
+ "\u001b[K |█▏ | 24.4 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▏ | 24.5 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▏ | 24.5 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▏ | 24.5 MB 5.7 MB/s eta 0:01:55\r",
@@ -2824,7 +2885,14 @@
"\u001b[K |█▎ | 26.0 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▎ | 26.0 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▎ | 26.0 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 26.0 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█▎ | 26.0 MB 5.7 MB/s eta 0:01:55"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
"\u001b[K |█▎ | 26.0 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▎ | 26.0 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▎ | 26.0 MB 5.7 MB/s eta 0:01:55\r",
@@ -2920,14 +2988,7 @@
"\u001b[K |█▎ | 27.0 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▎ | 27.0 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▎ | 27.0 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.0 MB 5.7 MB/s eta 0:01:55"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
+ "\u001b[K |█▎ | 27.0 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▎ | 27.0 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▎ | 27.0 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▎ | 27.0 MB 5.7 MB/s eta 0:01:55\r",
@@ -2946,60 +3007,60 @@
"\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:55\r",
"\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:55\r",
- "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:55\r",
+ "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.2 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.3 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.4 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.5 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.6 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▎ | 27.7 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▎ | 27.8 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▎ | 27.8 MB 5.7 MB/s eta 0:01:54\r",
@@ -3081,7 +3142,14 @@
"\u001b[K |█▍ | 28.5 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▍ | 28.5 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▍ | 28.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 28.6 MB 5.7 MB/s eta 0:01:54\r",
+ "\u001b[K |█▍ | 28.6 MB 5.7 MB/s eta 0:01:54"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
"\u001b[K |█▍ | 28.6 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▍ | 28.6 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▍ | 28.6 MB 5.7 MB/s eta 0:01:54\r",
@@ -3163,14 +3231,7 @@
"\u001b[K |█▍ | 29.4 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▍ | 29.4 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▍ | 29.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 29.4 MB 5.7 MB/s eta 0:01:54"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
+ "\u001b[K |█▍ | 29.4 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▍ | 29.4 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▍ | 29.4 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▍ | 29.4 MB 5.7 MB/s eta 0:01:54\r",
@@ -3259,8211 +3320,66086 @@
"\u001b[K |█▍ | 30.3 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▍ | 30.3 MB 5.7 MB/s eta 0:01:54\r",
"\u001b[K |█▍ | 30.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▍ | 30.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 30.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 31.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.2 MB 5.7 MB/s eta 0:01:54"
+ "\u001b[K |█▍ | 30.3 MB 5.7 MB/s eta 0:01:54"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█▍ | 30.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▍ | 30.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 30.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 31.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.1 MB 86.0 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█▌ | 32.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▌ | 32.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 32.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 32.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 32.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 32.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 33.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.2 MB 86.0 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█▋ | 34.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 34.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▋ | 35.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 35.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.3 MB 86.0 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█▊ | 36.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.7 MB 86.0 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█▊ | 36.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 36.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▊ | 37.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 37.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.0 MB 86.0 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█▉ | 38.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 38.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |█▉ | 39.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.0 MB 86.0 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██ | 40.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 40.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 41.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.2 MB 86.0 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██ | 42.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 42.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 43.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██ | 44.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.7 MB 86.0 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██▏ | 44.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 44.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 45.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 46.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 47.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 47.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 47.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 47.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 47.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▏ | 47.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.4 MB 86.0 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██▎ | 47.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 47.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 48.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.0 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.1 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.2 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▎ | 49.3 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.4 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.5 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.6 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.7 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.8 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 49.9 MB 86.0 MB/s eta 0:00:08\r",
+ "\u001b[K |██▍ | 50.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█▌ | 32.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.5 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.6 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.7 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.8 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▌ | 32.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 32.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 32.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 32.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 32.9 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.0 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.1 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.2 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.3 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.4 MB 5.7 MB/s eta 0:01:54\r",
- "\u001b[K |█▋ | 33.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.6 MB 5.7 MB/s eta 0:01:53"
+ " |██▍ | 50.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 50.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▍ | 51.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 51.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.4 MB 101.3 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██▌ | 52.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 52.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 53.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 54.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 54.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 54.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 54.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 54.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 54.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 54.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 54.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 54.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▌ | 54.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.5 MB 101.3 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██▋ | 54.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 54.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 55.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.4 MB 101.3 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██▋ | 56.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▋ | 56.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 56.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 57.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▊ | 58.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 58.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.1 MB 101.3 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██▉ | 59.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 59.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.8 MB 101.3 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██▉ | 60.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 60.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |██▉ | 61.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.5 MB 101.3 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███ | 61.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 61.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 62.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.0 MB 101.3 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███ | 63.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 63.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.7 MB 101.3 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███ | 64.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 64.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.7 MB 101.3 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███ | 65.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███ | 65.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 65.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 66.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.3 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.4 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.5 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.6 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.7 MB 101.3 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███▏ | 67.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.7 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.8 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 67.9 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.0 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.1 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▏ | 68.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▎ | 68.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▎ | 68.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▎ | 68.2 MB 101.3 MB/s eta 0:00:07\r",
+ "\u001b[K |███▎ | 68.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 68.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 69.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.3 MB 147.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███▎ | 70.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▎ | 70.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 70.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 71.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.3 MB 147.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███▍ | 72.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▍ | 72.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 72.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 72.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 72.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 72.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 72.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 72.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 72.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 72.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 72.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 73.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.5 MB 147.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███▌ | 74.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 74.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▌ | 75.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 75.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.7 MB 147.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███▋ | 76.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 76.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▋ | 77.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 77.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.2 MB 147.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███▊ | 78.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 78.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▊ | 79.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 79.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 79.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 79.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 79.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.1 MB 147.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███▉ | 80.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 80.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 81.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |███▉ | 82.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.4 MB 147.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████ | 82.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 82.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 83.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.5 MB 147.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████ | 84.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 84.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 85.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.5 MB 147.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████ | 86.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.8 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 86.9 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████ | 87.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.0 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.1 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.2 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.3 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.4 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.5 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.6 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.7 MB 147.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████▏ | 87.7 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.7 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.7 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.7 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.7 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.7 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.8 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.8 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.8 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.8 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.8 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.8 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.8 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.8 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.8 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.8 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.9 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.9 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.9 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.9 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.9 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.9 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.9 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.9 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 87.9 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.0 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.0 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.0 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.0 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.0 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.0 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.0 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.0 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.0 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.0 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.1 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.1 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.1 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.1 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.1 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.1 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.1 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.1 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.1 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.1 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.2 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.2 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.2 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.2 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.2 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.2 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.2 MB 147.3 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████▏ | 88.2 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.2 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.2 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.3 MB 147.3 MB/s eta 0:00:04\r",
+ "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.3 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.3 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.3 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.3 MB 1.3 MB/s eta 0:07:37\r",
+ "\u001b[K |████▏ | 89.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▏ | 89.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:36"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:36\r",
+ "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▎ | 91.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:35\r",
+ "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:34"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:34\r",
+ "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:33"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 94.0 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 94.0 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 94.0 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 94.0 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 94.0 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▍ | 94.0 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.0 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.0 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.0 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.0 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:33\r",
+ "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:32"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:32\r",
+ "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▌ | 96.4 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:31\r",
+ "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.0 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.1 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.2 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.3 MB 1.3 MB/s eta 0:07:30\r",
+ "\u001b[K |████▋ | 98.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.4 MB 1."
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.7 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.7 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.7 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.7 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.7 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▋ | 98.7 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.7 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.7 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.7 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.7 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.8 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.8 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.8 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.8 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.8 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.8 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.8 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.8 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.8 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.8 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.9 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.9 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.9 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.9 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.9 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.9 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.9 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.9 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.9 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 98.9 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.0 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.0 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.0 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.0 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.0 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.0 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.0 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.0 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.0 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.1 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.1 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.1 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.1 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.1 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.1 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.1 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.1 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.1 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.1 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.2 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.2 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.2 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.2 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.2 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.2 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.2 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.2 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.2 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.2 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.3 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.4 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.5 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.6 MB 1.3 MB/s eta 0:07:29\r",
+ "\u001b[K |████▊ | 99.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.9 MB 1.3 MB/s eta 0:07:28"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████▊ | 99.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 99.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.0 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.0 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.0 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.0 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.0 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.0 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.0 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.0 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.0 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.0 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.1 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.1 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.1 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.1 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.1 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.1 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.1 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.1 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.1 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.1 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.2 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.2 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.2 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.2 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.2 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.2 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.2 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.2 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.2 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.2 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.3 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.3 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.3 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.3 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.3 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.3 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.3 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.3 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.3 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.4 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.4 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.4 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.4 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.4 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.4 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.4 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.4 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.4 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.4 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.5 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.5 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.5 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.5 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.5 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.5 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.5 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.5 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.5 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.5 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.6 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.7 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.8 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.9 MB 1.3 MB/s eta 0:07:28\r",
+ "\u001b[K |████▊ | 100.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 100.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 100.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 100.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 100.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 100.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 101.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 101.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 101.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 101.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 101.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 101.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 101.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 101.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 101.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 101.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▊ | 101.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.3 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.3 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.3 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.3 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.3 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.3 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.3 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.3 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.3 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.3 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.4 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.4 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.4 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.4 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.4 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.4 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.4 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.4 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.4 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.4 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.5 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.5 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.5 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.5 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.5 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.5 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.5 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.5 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.5 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.6 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.6 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.6 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.6 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.6 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.6 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.6 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.6 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.6 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.6 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.7 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.7 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.7 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.7 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.7 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.7 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.7 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.7 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.7 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.7 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.8 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.8 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.8 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.8 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.8 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.8 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.8 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.8 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.8 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.8 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 101.9 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.0 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.1 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.2 MB 1.3 MB/s eta 0:07:27\r",
+ "\u001b[K |████▉ | 102.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.3 MB 1.3 MB/s eta 0:07:26"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████▉ | 102.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.5 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.5 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.5 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.5 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.5 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.5 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.5 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.5 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.5 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.5 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.6 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.6 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.6 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.6 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.6 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.6 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.6 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.6 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.6 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.6 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.7 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.7 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.7 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.7 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.7 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.7 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.7 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.7 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.7 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.7 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.8 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.8 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.8 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.8 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.8 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.8 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.8 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.8 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.8 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.9 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.9 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.9 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.9 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.9 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.9 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.9 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.9 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.9 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 102.9 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.0 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.0 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.0 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.0 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.0 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.0 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.0 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.0 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.0 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.0 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.1 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.1 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.1 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.1 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.1 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.1 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.1 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.1 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.1 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.1 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.2 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.3 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |████▉ | 103.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |█████ | 103.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |█████ | 103.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |█████ | 103.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |█████ | 103.4 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |█████ | 103.5 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |█████ | 103.5 MB 1.3 MB/s eta 0:07:26\r",
+ "\u001b[K |█████ | 103.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.8 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.8 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.8 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.8 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.8 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.8 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.8 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.8 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.8 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.8 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.9 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.9 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.9 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.9 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.9 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.9 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.9 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.9 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.9 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 103.9 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.0 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.0 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.0 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.0 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.0 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.0 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.0 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.0 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.0 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.0 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.1 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.1 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.1 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.1 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.1 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.1 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.1 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.1 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.1 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.2 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.2 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.2 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.2 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.2 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.2 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.2 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.2 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.2 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.2 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.3 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.3 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.3 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.3 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.3 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.3 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.3 MB 1.3 MB/s eta 0:07:25"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████ | 104.3 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.3 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.3 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.4 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.4 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.4 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.4 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.4 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.4 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.4 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.4 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.4 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.4 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.5 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.6 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.7 MB 1.3 MB/s eta 0:07:25\r",
+ "\u001b[K |█████ | 104.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 104.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.1 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.1 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.1 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.1 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.1 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.1 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.1 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.1 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.1 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.1 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.2 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.2 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.2 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.2 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.2 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.2 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.2 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.2 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.2 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.2 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.3 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.3 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.3 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.3 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.3 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.3 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.3 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.3 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.3 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.3 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.4 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.4 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.4 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.4 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.4 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.4 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.4 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.4 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.4 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.5 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.5 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.5 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.5 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.5 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.5 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.5 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.5 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.5 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.5 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.6 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.6 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.6 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.6 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.6 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.6 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.6 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.6 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.6 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.6 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.7 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.7 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.7 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.7 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.7 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.7 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.7 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.7 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.7 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.7 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.8 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 105.9 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 106.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 106.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 106.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 106.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 106.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 106.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 106.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 106.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 106.0 MB 1.3 MB/s eta 0:07:24\r",
+ "\u001b[K |█████ | 106.0 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.4 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.4 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.4 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.4 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.4 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.4 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.4 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.4 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.4 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.4 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.5 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.5 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.5 MB 1.3 MB/s eta 0:07:23"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████ | 106.5 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.5 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.5 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.5 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.5 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.5 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.5 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.6 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.6 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.6 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.6 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.6 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.6 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.6 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.6 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.6 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.6 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.7 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.7 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.7 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.7 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.7 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.7 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.7 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.7 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.7 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.8 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.8 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.8 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.8 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.8 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.8 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.8 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.8 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.8 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.8 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.9 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.9 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.9 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.9 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.9 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.9 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.9 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.9 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.9 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 106.9 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.0 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.0 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.0 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.0 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.0 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.0 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.0 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.0 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.0 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.0 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.1 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.2 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.3 MB 1.3 MB/s eta 0:07:23\r",
+ "\u001b[K |█████ | 107.3 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.3 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.7 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.7 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.7 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.7 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.7 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.7 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.7 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.7 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.7 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.7 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.8 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.8 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.8 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.8 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.8 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.8 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.8 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.8 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.8 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.8 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.9 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.9 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.9 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.9 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.9 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.9 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.9 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.9 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 107.9 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.0 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.0 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.0 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.0 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.0 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.0 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.0 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.0 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.0 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.0 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.1 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.1 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.1 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.1 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.1 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████ | 108.1 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.1 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.1 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.1 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.1 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.2 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.2 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.2 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.2 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.2 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.2 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.2 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.2 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.2 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.2 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.3 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.3 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.3 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.3 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.3 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.3 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.3 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.3 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.3 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.3 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.4 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.5 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.6 MB 1.3 MB/s eta 0:07:22\r",
+ "\u001b[K |█████▏ | 108.6 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.6 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.6 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.7 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.7 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.7 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.7 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.7 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.7 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.7 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.7 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.7 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.7 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.8 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.8 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.8 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.8 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.8 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.8 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.8 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.8 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.8 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.9 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.9 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.9 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.9 MB 1.3 MB/s eta 0:07:21"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████▏ | 108.9 MB 1.3 MB/s eta 0:07:21\r",
+ "\u001b[K |█████▏ | 108.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 108.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 108.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 108.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 108.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.2 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.2 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.2 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.2 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.2 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.2 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.2 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.2 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.2 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.3 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.3 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.3 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.3 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.3 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.3 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.3 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.3 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.3 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.3 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.4 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.4 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.4 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.4 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.4 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.4 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.4 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.4 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.4 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.4 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.5 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.5 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.5 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.5 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.5 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.5 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.5 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.5 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.5 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.5 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.6 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.6 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.6 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.6 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.6 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.6 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.6 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.6 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.6 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.6 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.7 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.7 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.7 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.7 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.7 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.7 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.7 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.7 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.7 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.8 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.8 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.8 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.8 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.8 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.8 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.8 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.8 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.8 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.8 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 109.9 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.0 MB 1.3 MB/s eta 0:07:12"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████▏ | 110.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.0 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.1 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.2 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.2 MB 1.3 MB/s eta 0:07:12\r",
+ "\u001b[K |█████▏ | 110.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▏ | 110.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.6 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.6 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.6 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.6 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.6 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.6 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.6 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.6 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.6 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.6 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.7 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.7 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.7 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.7 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.7 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.7 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.7 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.7 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.7 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.7 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.8 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.8 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.8 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.8 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.8 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.8 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.8 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.8 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.8 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.8 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.9 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.9 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.9 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.9 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.9 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.9 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.9 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.9 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 110.9 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.0 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.0 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.0 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.0 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.0 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.0 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.0 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.0 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.0 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.0 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.1 MB 1.3 MB/s eta 0:07:11"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████▎ | 111.1 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.1 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.1 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.1 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.1 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.1 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.1 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.1 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.1 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.2 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.3 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.4 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.5 MB 1.3 MB/s eta 0:07:11\r",
+ "\u001b[K |█████▎ | 111.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.9 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.9 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.9 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.9 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.9 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.9 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.9 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.9 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.9 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 111.9 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.0 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.0 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.0 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.0 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.0 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.0 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.0 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.0 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.0 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.0 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.1 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.1 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.1 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.1 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.1 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.1 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.1 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.1 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.1 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.1 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.2 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.2 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.2 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.2 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.2 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.2 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.2 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.2 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.2 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.3 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.3 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.3 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.3 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.3 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.3 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.3 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.3 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.3 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.3 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.4 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.4 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.4 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.4 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.4 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.4 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.4 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.4 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.4 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.4 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.5 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.6 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.7 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.8 MB 1.3 MB/s eta 0:07:10\r",
+ "\u001b[K |█████▎ | 112.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.8 MB 1.3 MB/s eta 0:07:09"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████▍ | 112.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 112.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.2 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.2 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.2 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.2 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.2 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.2 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.2 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.2 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.2 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.2 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.3 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.3 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.3 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.3 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.3 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.3 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.3 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.3 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.3 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.3 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.4 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.4 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.4 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.4 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.4 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.4 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.4 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.4 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.4 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.4 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.5 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.5 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.5 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.5 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.5 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.5 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.5 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.5 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.5 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.6 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.6 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.6 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.6 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.6 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.6 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.6 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.6 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.6 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.6 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.7 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.7 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.7 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.7 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.7 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.7 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.7 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.7 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.7 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.7 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.8 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 113.9 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.0 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.1 MB 1.3 MB/s eta 0:07:09\r",
+ "\u001b[K |█████▍ | 114.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.5 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.5 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.5 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.5 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.5 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.5 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.5 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.5 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.5 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.5 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.6 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.6 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.6 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.6 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.6 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.6 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.6 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.6 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.6 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.6 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.7 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.7 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.7 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.7 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.7 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.7 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.7 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.7 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.7 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.7 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.8 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.8 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.8 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.8 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.8 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.8 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.8 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.8 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.8 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.9 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.9 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.9 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.9 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.9 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.9 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.9 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.9 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.9 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 114.9 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.0 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.0 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.0 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.0 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.0 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.0 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.0 MB 1.3 MB/s eta 0:07:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████▍ | 115.0 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.0 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.0 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.1 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▍ | 115.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.2 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.3 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.4 MB 1.3 MB/s eta 0:07:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████▌ | 115.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.4 MB 1.3 MB/s eta 0:07:08\r",
+ "\u001b[K |█████▌ | 115.4 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.4 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.8 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.8 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.8 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.8 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.8 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.8 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.8 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.8 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.8 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.8 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.9 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.9 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.9 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.9 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.9 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.9 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.9 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.9 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.9 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 115.9 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.0 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.0 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.0 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.0 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.0 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.0 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.0 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.0 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.0 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.0 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.1 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.1 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.1 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.1 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.1 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.1 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.1 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.1 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.1 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.2 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.2 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.2 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.2 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.2 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.2 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.2 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.2 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.2 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.2 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.3 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.3 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.3 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.3 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.3 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.3 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.3 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.3 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.3 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.3 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.4 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.4 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.4 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.4 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.4 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.4 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.4 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.4 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.4 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.4 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.5 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.6 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.7 MB 1.3 MB/s eta 0:07:07\r",
+ "\u001b[K |█████▌ | 116.7 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ "
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ " | 116.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 116.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.1 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.1 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.1 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.1 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.1 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.1 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.1 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.1 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.1 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.1 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.2 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.2 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.2 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.2 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.2 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.2 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.2 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.2 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.2 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.2 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.3 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.3 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.3 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.3 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.3 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.3 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.3 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.3 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.3 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.5 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.5 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.5 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.5 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.5 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▌ | 117.5 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.5 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.5 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.5 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.5 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:07:06\r",
+ "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:07:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:07:05\r",
+ "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▋ | 119.9 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:07:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:07:04\r",
+ "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ "
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ " | 121.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:07:03\r",
+ "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▊ | 122.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:07:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:07:02\r",
+ "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |█████▉ | 124.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:07:01\r",
+ "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:07:00"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:07:00\r",
+ "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:59\r",
+ "\u001b[K |██████ | 126.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 126.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ "
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ " | 127.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 127.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 128.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.1 MB 72.4 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████ | 129.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████ | 129.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 129.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.8 MB 72.4 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████▏ | 130.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 130.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▏ | 131.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 131.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.5 MB 72.4 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████▎ | 132.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 132.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 133.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▎ | 134.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 134.9 MB 72.4 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████▍ | 134.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 135.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▍ | 136.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.9 MB 72.4 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████▌ | 136.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 136.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.1 "
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.8 MB 72.4 MB/s eta"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ " 0:00:08\r",
+ "\u001b[K |██████▌ | 137.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 137.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.0 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.1 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.2 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.3 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.4 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.5 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.6 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▌ | 138.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.7 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.8 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 138.9 MB 72.4 MB/s eta 0:00:08\r",
+ "\u001b[K |██████▋ | 139.0 MB 126 kB/s eta 1:10:55\r",
+ "\u001b[K |██████▋ | 139.0 MB 126 kB/s eta 1:10:55\r",
+ "\u001b[K |██████▋ | 139.0 MB 126 kB/s eta 1:10:55\r",
+ "\u001b[K |██████▋ | 139.0 MB 126 kB/s eta 1:10:55\r",
+ "\u001b[K |██████▋ | 139.0 MB 126 kB/s eta 1:10:54\r",
+ "\u001b[K |██████▋ | 139.0 MB 126 kB/s eta 1:10:54\r",
+ "\u001b[K |██████▋ | 139.0 MB 126 kB/s eta 1:10:54\r",
+ "\u001b[K |██████▋ | 139.0 MB 126 kB/s eta 1:10:54\r",
+ "\u001b[K |██████▋ | 139.0 MB 126 kB/s eta 1:10:54\r",
+ "\u001b[K |██████▋ | 139.0 MB 126 kB/s eta 1:10:54\r",
+ "\u001b[K |██████▋ | 139.1 MB 126 kB/s eta 1:10:54\r",
+ "\u001b[K |██████▋ | 139.1 MB 126 kB/s eta 1:10:54\r",
+ "\u001b[K |██████▋ | 139.1 MB 126 kB/s eta 1:10:54\r",
+ "\u001b[K |██████▋ | 139.1 MB 126 kB/s eta 1:10:54\r",
+ "\u001b[K |██████▋ | 139.1 MB 126 kB/s eta 1:10:54\r",
+ "\u001b[K |██████▋ | 139.1 MB 126 kB/s eta 1:10:54\r",
+ "\u001b[K |██████▋ | 139.1 MB 126 kB/s eta 1:10:53\r",
+ "\u001b[K |██████▋ | 139.1 MB 126 kB/s eta 1:10:53\r",
+ "\u001b[K |██████▋ | 139.1 MB 126 kB/s eta 1:10:53\r",
+ "\u001b[K |██████▋ | 139.2 MB 126 kB/s eta 1:10:53\r",
+ "\u001b[K |██████▋ | 139.2 MB 126 kB/s eta 1:10:53\r",
+ "\u001b[K |██████▋ | 139.2 MB 126 kB/s eta 1:10:53\r",
+ "\u001b[K |██████▋ | 139.2 MB 126 kB/s eta 1:10:53\r",
+ "\u001b[K |██████▋ | 139.2 MB 126 kB/s eta 1:10:53\r",
+ "\u001b[K |██████▋ | 139.2 MB 126 kB/s eta 1:10:53"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████▋ | 139.2 MB 126 kB/s eta 1:10:53\r",
+ "\u001b[K |██████▋ | 139.2 MB 126 kB/s eta 1:10:53\r",
+ "\u001b[K |██████▋ | 139.2 MB 126 kB/s eta 1:10:53\r",
+ "\u001b[K |██████▋ | 139.2 MB 126 kB/s eta 1:10:53\r",
+ "\u001b[K |██████▋ | 139.3 MB 126 kB/s eta 1:10:52\r",
+ "\u001b[K |██████▋ | 139.3 MB 126 kB/s eta 1:10:52\r",
+ "\u001b[K |██████▋ | 139.3 MB 126 kB/s eta 1:10:52\r",
+ "\u001b[K |██████▋ | 139.3 MB 126 kB/s eta 1:10:52\r",
+ "\u001b[K |██████▋ | 139.3 MB 126 kB/s eta 1:10:52\r",
+ "\u001b[K |██████▋ | 139.3 MB 126 kB/s eta 1:10:52\r",
+ "\u001b[K |██████▋ | 139.3 MB 126 kB/s eta 1:10:52\r",
+ "\u001b[K |██████▋ | 139.3 MB 126 kB/s eta 1:10:52\r",
+ "\u001b[K |██████▋ | 139.3 MB 126 kB/s eta 1:10:52\r",
+ "\u001b[K |██████▋ | 139.3 MB 126 kB/s eta 1:10:52\r",
+ "\u001b[K |██████▋ | 139.4 MB 126 kB/s eta 1:10:52\r",
+ "\u001b[K |██████▋ | 139.4 MB 126 kB/s eta 1:10:52\r",
+ "\u001b[K |██████▋ | 139.4 MB 126 kB/s eta 1:10:51\r",
+ "\u001b[K |██████▋ | 139.4 MB 126 kB/s eta 1:10:51\r",
+ "\u001b[K |██████▋ | 139.4 MB 126 kB/s eta 1:10:51\r",
+ "\u001b[K |██████▋ | 139.4 MB 126 kB/s eta 1:10:51\r",
+ "\u001b[K |██████▋ | 139.4 MB 126 kB/s eta 1:10:51\r",
+ "\u001b[K |██████▋ | 139.4 MB 126 kB/s eta 1:10:51\r",
+ "\u001b[K |██████▋ | 139.4 MB 126 kB/s eta 1:10:51\r",
+ "\u001b[K |██████▋ | 139.4 MB 126 kB/s eta 1:10:51\r",
+ "\u001b[K |██████▋ | 139.5 MB 126 kB/s eta 1:10:51\r",
+ "\u001b[K |██████▋ | 139.5 MB 126 kB/s eta 1:10:51\r",
+ "\u001b[K |██████▋ | 139.5 MB 126 kB/s eta 1:10:51\r",
+ "\u001b[K |██████▋ | 139.5 MB 126 kB/s eta 1:10:51\r",
+ "\u001b[K |██████▋ | 139.5 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.5 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.5 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.5 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.5 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.6 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.6 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.6 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.6 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.6 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.6 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.6 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.6 MB 126 kB/s eta 1:10:50\r",
+ "\u001b[K |██████▋ | 139.6 MB 126 kB/s eta 1:10:49\r",
+ "\u001b[K |██████▋ | 139.6 MB 126 kB/s eta 1:10:49\r",
+ "\u001b[K |██████▋ | 139.7 MB 126 kB/s eta 1:10:49\r",
+ "\u001b[K |██████▋ | 139.7 MB 126 kB/s eta 1:10:49\r",
+ "\u001b[K |██████▋ | 139.7 MB 126 kB/s eta 1:10:49\r",
+ "\u001b[K |██████▋ | 139.7 MB 126 kB/s eta 1:10:49\r",
+ "\u001b[K |██████▋ | 139.7 MB 126 kB/s eta 1:10:49\r",
+ "\u001b[K |██████▋ | 139.7 MB 126 kB/s eta 1:10:49\r",
+ "\u001b[K |██████▋ | 139.7 MB 126 kB/s eta 1:10:49\r",
+ "\u001b[K |██████▋ | 139.7 MB 126 kB/s eta 1:10:49\r",
+ "\u001b[K |██████▋ | 139.7 MB 126 kB/s eta 1:10:49\r",
+ "\u001b[K |██████▋ | 139.7 MB 126 kB/s eta 1:10:49\r",
+ "\u001b[K |██████▋ | 139.8 MB 126 kB/s eta 1:10:48\r",
+ "\u001b[K |██████▋ | 139.8 MB 126 kB/s eta 1:10:48\r",
+ "\u001b[K |██████▋ | 139.8 MB 126 kB/s eta 1:10:48\r",
+ "\u001b[K |██████▋ | 139.8 MB 126 kB/s eta 1:10:48\r",
+ "\u001b[K |██████▋ | 139.8 MB 126 kB/s eta 1:10:48\r",
+ "\u001b[K |██████▋ | 139.8 MB 126 kB/s eta 1:10:48\r",
+ "\u001b[K |██████▋ | 139.8 MB 126 kB/s eta 1:10:48\r",
+ "\u001b[K |██████▋ | 139.8 MB 126 kB/s eta 1:10:48\r",
+ "\u001b[K |██████▋ | 139.8 MB 126 kB/s eta 1:10:48\r",
+ "\u001b[K |██████▋ | 139.8 MB 126 kB/s eta 1:10:48\r",
+ "\u001b[K |██████▋ | 139.9 MB 126 kB/s eta 1:10:48\r",
+ "\u001b[K |██████▋ | 139.9 MB 126 kB/s eta 1:10:48\r",
+ "\u001b[K |██████▋ | 139.9 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 139.9 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 139.9 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 139.9 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 139.9 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 139.9 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 139.9 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 140.0 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 140.0 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 140.0 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 140.0 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 140.0 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 140.0 MB 126 kB/s eta 1:10:47\r",
+ "\u001b[K |██████▋ | 140.0 MB 126 kB/s eta 1:10:46"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████▋ | 140.0 MB 126 kB/s eta 1:10:46\r",
+ "\u001b[K |██████▋ | 140.0 MB 126 kB/s eta 1:10:46\r",
+ "\u001b[K |██████▋ | 140.0 MB 126 kB/s eta 1:10:46\r",
+ "\u001b[K |██████▋ | 140.1 MB 126 kB/s eta 1:10:46\r",
+ "\u001b[K |██████▋ | 140.1 MB 126 kB/s eta 1:10:46\r",
+ "\u001b[K |██████▋ | 140.1 MB 126 kB/s eta 1:10:46\r",
+ "\u001b[K |██████▋ | 140.1 MB 126 kB/s eta 1:10:46\r",
+ "\u001b[K |██████▋ | 140.1 MB 126 kB/s eta 1:10:46\r",
+ "\u001b[K |██████▋ | 140.1 MB 126 kB/s eta 1:10:46\r",
+ "\u001b[K |██████▋ | 140.1 MB 126 kB/s eta 1:10:46\r",
+ "\u001b[K |██████▋ | 140.1 MB 126 kB/s eta 1:10:46\r",
+ "\u001b[K |██████▋ | 140.1 MB 126 kB/s eta 1:10:45\r",
+ "\u001b[K |██████▋ | 140.1 MB 126 kB/s eta 1:10:45\r",
+ "\u001b[K |██████▋ | 140.2 MB 126 kB/s eta 1:10:45\r",
+ "\u001b[K |██████▋ | 140.2 MB 126 kB/s eta 1:10:45\r",
+ "\u001b[K |██████▋ | 140.2 MB 126 kB/s eta 1:10:45\r",
+ "\u001b[K |██████▋ | 140.2 MB 126 kB/s eta 1:10:45\r",
+ "\u001b[K |██████▋ | 140.2 MB 126 kB/s eta 1:10:45\r",
+ "\u001b[K |██████▋ | 140.2 MB 126 kB/s eta 1:10:45\r",
+ "\u001b[K |██████▋ | 140.2 MB 126 kB/s eta 1:10:45\r",
+ "\u001b[K |██████▋ | 140.2 MB 126 kB/s eta 1:10:45\r",
+ "\u001b[K |██████▋ | 140.2 MB 126 kB/s eta 1:10:45\r",
+ "\u001b[K |██████▋ | 140.2 MB 126 kB/s eta 1:10:45\r",
+ "\u001b[K |██████▋ | 140.3 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.3 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.3 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.3 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.3 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.3 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.3 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.3 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.3 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.3 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.4 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.4 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.4 MB 126 kB/s eta 1:10:44\r",
+ "\u001b[K |██████▋ | 140.4 MB 126 kB/s eta 1:10:43\r",
+ "\u001b[K |██████▋ | 140.4 MB 126 kB/s eta 1:10:43\r",
+ "\u001b[K |██████▋ | 140.4 MB 126 kB/s eta 1:10:43\r",
+ "\u001b[K |██████▋ | 140.4 MB 126 kB/s eta 1:10:43\r",
+ "\u001b[K |██████▋ | 140.4 MB 126 kB/s eta 1:10:43\r",
+ "\u001b[K |██████▋ | 140.4 MB 126 kB/s eta 1:10:43\r",
+ "\u001b[K |██████▋ | 140.5 MB 126 kB/s eta 1:10:43\r",
+ "\u001b[K |██████▋ | 140.5 MB 126 kB/s eta 1:10:43\r",
+ "\u001b[K |██████▋ | 140.5 MB 126 kB/s eta 1:10:43\r",
+ "\u001b[K |██████▋ | 140.5 MB 126 kB/s eta 1:10:43\r",
+ "\u001b[K |██████▋ | 140.5 MB 126 kB/s eta 1:10:43\r",
+ "\u001b[K |██████▋ | 140.5 MB 126 kB/s eta 1:10:43\r",
+ "\u001b[K |██████▋ | 140.5 MB 126 kB/s eta 1:10:42\r",
+ "\u001b[K |██████▋ | 140.5 MB 126 kB/s eta 1:10:42\r",
+ "\u001b[K |██████▋ | 140.5 MB 126 kB/s eta 1:10:42\r",
+ "\u001b[K |██████▋ | 140.5 MB 126 kB/s eta 1:10:42\r",
+ "\u001b[K |██████▋ | 140.6 MB 126 kB/s eta 1:10:42\r",
+ "\u001b[K |██████▋ | 140.6 MB 126 kB/s eta 1:10:42\r",
+ "\u001b[K |██████▋ | 140.6 MB 126 kB/s eta 1:10:42\r",
+ "\u001b[K |██████▋ | 140.6 MB 126 kB/s eta 1:10:42\r",
+ "\u001b[K |██████▋ | 140.6 MB 126 kB/s eta 1:10:42\r",
+ "\u001b[K |██████▋ | 140.6 MB 126 kB/s eta 1:10:42\r",
+ "\u001b[K |██████▋ | 140.6 MB 126 kB/s eta 1:10:42\r",
+ "\u001b[K |██████▋ | 140.6 MB 126 kB/s eta 1:10:42\r",
+ "\u001b[K |██████▋ | 140.6 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.6 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.7 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.7 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.7 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.7 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.7 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.7 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.7 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.7 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.7 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.7 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.8 MB 126 kB/s eta 1:10:41\r",
+ "\u001b[K |██████▋ | 140.8 MB 126 kB/s eta 1:10:40\r",
+ "\u001b[K |██████▋ | 140.8 MB 126 kB/s eta 1:10:40\r",
+ "\u001b[K |██████▋ | 140.8 MB 126 kB/s eta 1:10:40\r",
+ "\u001b[K |██████▋ | 140.8 MB 126 kB/s eta 1:10:40\r",
+ "\u001b[K |██████▋ | 140.8 MB 126 kB/s eta 1:10:40\r",
+ "\u001b[K |██████▋ | 140.8 MB 126 kB/s eta 1:10:40\r",
+ "\u001b[K |██████▋ | 140.8 MB 126 kB/s eta 1:10:40\r",
+ "\u001b[K |██████▋ | 140.8 MB 126 kB/s eta 1:10:40\r",
+ "\u001b[K |██████▋ | 140.9 MB 126 kB/s eta 1:10:40\r",
+ "\u001b[K |██████▋ | 140.9 MB 126 kB/s eta 1:10:40\r",
+ "\u001b[K |██████▋ | 140.9 MB 126 kB/s eta 1:10:40\r",
+ "\u001b[K |██████▋ | 140.9 MB 126 kB/s eta 1:10:40\r",
+ "\u001b[K |██████▋ | 140.9 MB 126 kB/s eta 1:10:39\r",
+ "\u001b[K |██████▋ | 140.9 MB 126 kB/s eta 1:10:39\r",
+ "\u001b[K |██████▋ | 140.9 MB 126 kB/s eta 1:10:39\r",
+ "\u001b[K |██████▋ | 140.9 MB 126 kB/s eta 1:10:39\r",
+ "\u001b[K |██████▋ | 140.9 MB 126 kB/s eta 1:10:39\r",
+ "\u001b[K |██████▋ | 140.9 MB 126 kB/s eta 1:10:39\r",
+ "\u001b[K |██████▋ | 141.0 MB 126 kB/s eta 1:10:39\r",
+ "\u001b[K |██████▋ | 141.0 MB 126 kB/s eta 1:10:39\r",
+ "\u001b[K |██████▋ | 141.0 MB 126 kB/s eta 1:10:39\r",
+ "\u001b[K |██████▋ | 141.0 MB 126 kB/s eta 1:10:39\r",
+ "\u001b[K |██████▋ | 141.0 MB 126 kB/s eta 1:10:39\r",
+ "\u001b[K |██████▋ | 141.0 MB 126 kB/s eta 1:10:39\r",
+ "\u001b[K |██████▋ | 141.0 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.0 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.0 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.0 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.1 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.1 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.1 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.1 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.1 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.1 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.1 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.1 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.1 MB 126 kB/s eta 1:10:38\r",
+ "\u001b[K |██████▊ | 141.1 MB 126 kB/s eta 1:10:37\r",
+ "\u001b[K |██████▊ | 141.2 MB 126 kB/s eta 1:10:37\r",
+ "\u001b[K |██████▊ | 141.2 MB 126 kB/s eta 1:10:37\r",
+ "\u001b[K |██████▊ | 141.2 MB 126 kB/s eta 1:10:37\r",
+ "\u001b[K |██████▊ | 141.2 MB 126 kB/s eta 1:10:37\r",
+ "\u001b[K |██████▊ | 141.2 MB 126 kB/s eta 1:10:37\r",
+ "\u001b[K |██████▊ | 141.2 MB 126 kB/s eta 1:10:37\r",
+ "\u001b[K |██████▊ | 141.2 MB 126 kB/s eta 1:10:37\r",
+ "\u001b[K |██████▊ | 141.2 MB 126 kB/s eta 1:10:37\r",
+ "\u001b[K |██████▊ | 141.2 MB 126 kB/s eta 1:10:37\r",
+ "\u001b[K |██████▊ | 141.3 MB 126 kB/s eta 1:10:37\r",
+ "\u001b[K |██████▊ | 141.3 MB 126 kB/s eta 1:10:37"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████▊ | 141.3 MB 126 kB/s eta 1:10:36\r",
+ "\u001b[K |██████▊ | 141.3 MB 126 kB/s eta 1:10:36\r",
+ "\u001b[K |██████▊ | 141.3 MB 126 kB/s eta 1:10:36\r",
+ "\u001b[K |██████▊ | 141.3 MB 126 kB/s eta 1:10:36\r",
+ "\u001b[K |██████▊ | 141.3 MB 126 kB/s eta 1:10:36\r",
+ "\u001b[K |██████▊ | 141.3 MB 126 kB/s eta 1:10:36\r",
+ "\u001b[K |██████▊ | 141.3 MB 126 kB/s eta 1:10:36\r",
+ "\u001b[K |██████▊ | 141.3 MB 126 kB/s eta 1:10:36\r",
+ "\u001b[K |██████▊ | 141.4 MB 126 kB/s eta 1:10:36\r",
+ "\u001b[K |██████▊ | 141.4 MB 126 kB/s eta 1:10:36\r",
+ "\u001b[K |██████▊ | 141.4 MB 126 kB/s eta 1:10:36\r",
+ "\u001b[K |██████▊ | 141.4 MB 126 kB/s eta 1:10:36\r",
+ "\u001b[K |██████▊ | 141.4 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.4 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.4 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.4 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.4 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.4 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.5 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.5 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.5 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.5 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.5 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.5 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.5 MB 126 kB/s eta 1:10:35\r",
+ "\u001b[K |██████▊ | 141.5 MB 126 kB/s eta 1:10:34\r",
+ "\u001b[K |██████▊ | 141.5 MB 126 kB/s eta 1:10:34\r",
+ "\u001b[K |██████▊ | 141.5 MB 126 kB/s eta 1:10:34\r",
+ "\u001b[K |██████▊ | 141.6 MB 126 kB/s eta 1:10:34\r",
+ "\u001b[K |██████▊ | 141.6 MB 126 kB/s eta 1:10:34\r",
+ "\u001b[K |██████▊ | 141.6 MB 126 kB/s eta 1:10:34\r",
+ "\u001b[K |██████▊ | 141.6 MB 126 kB/s eta 1:10:34\r",
+ "\u001b[K |██████▊ | 141.6 MB 126 kB/s eta 1:10:34\r",
+ "\u001b[K |██████▊ | 141.6 MB 126 kB/s eta 1:10:34\r",
+ "\u001b[K |██████▊ | 141.6 MB 126 kB/s eta 1:10:34\r",
+ "\u001b[K |██████▊ | 141.6 MB 126 kB/s eta 1:10:34\r",
+ "\u001b[K |██████▊ | 141.6 MB 126 kB/s eta 1:10:34\r",
+ "\u001b[K |██████▊ | 141.6 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.7 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.7 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.7 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.7 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.7 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.7 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.7 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.7 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.7 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.8 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.8 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.8 MB 126 kB/s eta 1:10:33\r",
+ "\u001b[K |██████▊ | 141.8 MB 126 kB/s eta 1:10:32\r",
+ "\u001b[K |██████▊ | 141.8 MB 126 kB/s eta 1:10:32\r",
+ "\u001b[K |██████▊ | 141.8 MB 126 kB/s eta 1:10:32\r",
+ "\u001b[K |██████▊ | 141.8 MB 126 kB/s eta 1:10:32\r",
+ "\u001b[K |██████▊ | 141.8 MB 126 kB/s eta 1:10:32\r",
+ "\u001b[K |██████▊ | 141.8 MB 126 kB/s eta 1:10:32\r",
+ "\u001b[K |██████▊ | 141.8 MB 126 kB/s eta 1:10:32\r",
+ "\u001b[K |██████▊ | 141.9 MB 126 kB/s eta 1:10:32\r",
+ "\u001b[K |██████▊ | 141.9 MB 126 kB/s eta 1:10:32\r",
+ "\u001b[K |██████▊ | 141.9 MB 126 kB/s eta 1:10:32\r",
+ "\u001b[K |██████▊ | 141.9 MB 126 kB/s eta 1:10:32\r",
+ "\u001b[K |██████▊ | 141.9 MB 126 kB/s eta 1:10:32\r",
+ "\u001b[K |██████▊ | 141.9 MB 126 kB/s eta 1:10:31\r",
+ "\u001b[K |██████▊ | 141.9 MB 126 kB/s eta 1:10:31\r",
+ "\u001b[K |██████▊ | 141.9 MB 126 kB/s eta 1:10:31\r",
+ "\u001b[K |██████▊ | 141.9 MB 126 kB/s eta 1:10:31\r",
+ "\u001b[K |██████▊ | 141.9 MB 126 kB/s eta 1:10:31\r",
+ "\u001b[K |██████▊ | 142.0 MB 126 kB/s eta 1:10:31\r",
+ "\u001b[K |██████▊ | 142.0 MB 126 kB/s eta 1:10:31\r",
+ "\u001b[K |██████▊ | 142.0 MB 126 kB/s eta 1:10:31\r",
+ "\u001b[K |██████▊ | 142.0 MB 126 kB/s eta 1:10:31\r",
+ "\u001b[K |██████▊ | 142.0 MB 126 kB/s eta 1:10:31\r",
+ "\u001b[K |██████▊ | 142.0 MB 126 kB/s eta 1:10:31\r",
+ "\u001b[K |██████▊ | 142.0 MB 126 kB/s eta 1:10:31\r",
+ "\u001b[K |██████▊ | 142.0 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.0 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.0 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.1 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.1 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.1 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.1 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.1 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.1 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.1 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.1 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.1 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.2 MB 126 kB/s eta 1:10:30\r",
+ "\u001b[K |██████▊ | 142.2 MB 126 kB/s eta 1:10:29\r",
+ "\u001b[K |██████▊ | 142.2 MB 126 kB/s eta 1:10:29\r",
+ "\u001b[K |██████▊ | 142.2 MB 126 kB/s eta 1:10:29\r",
+ "\u001b[K |██████▊ | 142.2 MB 126 kB/s eta 1:10:29\r",
+ "\u001b[K |██████▊ | 142.2 MB 126 kB/s eta 1:10:29\r",
+ "\u001b[K |██████▊ | 142.2 MB 126 kB/s eta 1:10:29\r",
+ "\u001b[K |██████▊ | 142.2 MB 126 kB/s eta 1:10:29\r",
+ "\u001b[K |██████▊ | 142.2 MB 126 kB/s eta 1:10:29\r",
+ "\u001b[K |██████▊ | 142.2 MB 126 kB/s eta 1:10:29\r",
+ "\u001b[K |██████▊ | 142.3 MB 126 kB/s eta 1:10:29\r",
+ "\u001b[K |██████▊ | 142.3 MB 126 kB/s eta 1:10:29\r",
+ "\u001b[K |██████▊ | 142.3 MB 126 kB/s eta 1:10:29\r",
+ "\u001b[K |██████▊ | 142.3 MB 126 kB/s eta 1:10:28\r",
+ "\u001b[K |██████▊ | 142.3 MB 126 kB/s eta 1:10:28\r",
+ "\u001b[K |██████▊ | 142.3 MB 126 kB/s eta 1:10:28\r",
+ "\u001b[K |██████▊ | 142.3 MB 126 kB/s eta 1:10:28\r",
+ "\u001b[K |██████▊ | 142.3 MB 126 kB/s eta 1:10:28\r",
+ "\u001b[K |██████▊ | 142.3 MB 126 kB/s eta 1:10:28\r",
+ "\u001b[K |██████▊ | 142.3 MB 126 kB/s eta 1:10:28\r",
+ "\u001b[K |██████▊ | 142.4 MB 126 kB/s eta 1:10:28\r",
+ "\u001b[K |██████▊ | 142.4 MB 126 kB/s eta 1:10:28\r",
+ "\u001b[K |██████▊ | 142.4 MB 126 kB/s eta 1:10:28\r",
+ "\u001b[K |██████▊ | 142.4 MB 126 kB/s eta 1:10:28\r",
+ "\u001b[K |██████▊ | 142.4 MB 126 kB/s eta 1:10:28\r",
+ "\u001b[K |██████▊ | 142.4 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.4 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.4 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.4 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.4 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.5 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.5 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.5 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.5 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.5 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.5 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.5 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.5 MB 126 kB/s eta 1:10:27\r",
+ "\u001b[K |██████▊ | 142.5 MB 126 kB/s eta 1:10:26\r",
+ "\u001b[K |██████▊ | 142.6 MB 126 kB/s eta 1:10:26\r",
+ "\u001b[K |██████▊ | 142.6 MB 126 kB/s eta 1:10:26\r",
+ "\u001b[K |██████▊ | 142.6 MB 126 kB/s eta 1:10:26\r",
+ "\u001b[K |██████▊ | 142.6 MB 126 kB/s eta 1:10:26\r",
+ "\u001b[K |██████▊ | 142.6 MB 126 kB/s eta 1:10:26\r",
+ "\u001b[K |██████▊ | 142.6 MB 126 kB/s eta 1:10:26\r",
+ "\u001b[K |██████▊ | 142.6 MB 126 kB/s eta 1:10:26\r",
+ "\u001b[K |██████▊ | 142.6 MB 126 kB/s eta 1:10:26\r",
+ "\u001b[K |██████▊ | 142.6 MB 126 kB/s eta 1:10:26\r",
+ "\u001b[K |██████▊ | 142.6 MB 126 kB/s eta 1:10:26\r",
+ "\u001b[K |██████▊ | 142.7 MB 126 kB/s eta 1:10:26\r",
+ "\u001b[K |██████▊ | 142.7 MB 126 kB/s eta 1:10:25\r",
+ "\u001b[K |██████▊ | 142.7 MB 126 kB/s eta 1:10:25\r",
+ "\u001b[K |██████▊ | 142.7 MB 126 kB/s eta 1:10:25\r",
+ "\u001b[K |██████▊ | 142.7 MB 126 kB/s eta 1:10:25\r",
+ "\u001b[K |██████▊ | 142.7 MB 126 kB/s eta 1:10:25\r",
+ "\u001b[K |██████▊ | 142.7 MB 126 kB/s eta 1:10:25\r",
+ "\u001b[K |██████▊ | 142.7 MB 126 kB/s eta 1:10:25\r",
+ "\u001b[K |██████▊ | 142.7 MB 126 kB/s eta 1:10:25\r",
+ "\u001b[K |██████▊ | 142.7 MB 126 kB/s eta 1:10:25\r",
+ "\u001b[K |██████▊ | 142.8 MB 126 kB/s eta 1:10:25\r",
+ "\u001b[K |██████▊ | 142.8 MB 126 kB/s eta 1:10:25\r",
+ "\u001b[K |██████▊ | 142.8 MB 126 kB/s eta 1:10:25\r",
+ "\u001b[K |██████▊ | 142.8 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.8 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.8 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.8 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.8 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.8 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.8 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.9 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.9 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.9 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.9 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.9 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.9 MB 126 kB/s eta 1:10:24\r",
+ "\u001b[K |██████▊ | 142.9 MB 126 kB/s eta 1:10:23\r",
+ "\u001b[K |██████▊ | 142.9 MB 126 kB/s eta 1:10:23\r",
+ "\u001b[K |██████▊ | 142.9 MB 126 kB/s eta 1:10:23\r",
+ "\u001b[K |██████▊ | 143.0 MB 126 kB/s eta 1:10:23\r",
+ "\u001b[K |██████▊ | 143.0 MB 126 kB/s eta 1:10:23\r",
+ "\u001b[K |██████▊ | 143.0 MB 126 kB/s eta 1:10:23\r",
+ "\u001b[K |██████▊ | 143.0 MB 126 kB/s eta 1:10:23\r",
+ "\u001b[K |██████▊ | 143.0 MB 126 kB/s eta 1:10:23\r",
+ "\u001b[K |██████▊ | 143.0 MB 126 kB/s eta 1:10:23"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████▊ | 143.0 MB 126 kB/s eta 1:10:23\r",
+ "\u001b[K |██████▊ | 143.0 MB 126 kB/s eta 1:10:23\r",
+ "\u001b[K |██████▊ | 143.0 MB 126 kB/s eta 1:10:23\r",
+ "\u001b[K |██████▊ | 143.0 MB 126 kB/s eta 1:10:22\r",
+ "\u001b[K |██████▊ | 143.1 MB 126 kB/s eta 1:10:22\r",
+ "\u001b[K |██████▊ | 143.1 MB 126 kB/s eta 1:10:22\r",
+ "\u001b[K |██████▊ | 143.1 MB 126 kB/s eta 1:10:22\r",
+ "\u001b[K |██████▊ | 143.1 MB 126 kB/s eta 1:10:22\r",
+ "\u001b[K |██████▊ | 143.1 MB 126 kB/s eta 1:10:22\r",
+ "\u001b[K |██████▊ | 143.1 MB 126 kB/s eta 1:10:22\r",
+ "\u001b[K |██████▊ | 143.1 MB 126 kB/s eta 1:10:22\r",
+ "\u001b[K |██████▊ | 143.1 MB 126 kB/s eta 1:10:22\r",
+ "\u001b[K |██████▊ | 143.1 MB 126 kB/s eta 1:10:22\r",
+ "\u001b[K |██████▊ | 143.1 MB 126 kB/s eta 1:10:22\r",
+ "\u001b[K |██████▊ | 143.2 MB 126 kB/s eta 1:10:22\r",
+ "\u001b[K |██████▊ | 143.2 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.2 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.2 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.2 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.2 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.2 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.2 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.2 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.2 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.3 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.3 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.3 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.3 MB 126 kB/s eta 1:10:21\r",
+ "\u001b[K |██████▊ | 143.3 MB 126 kB/s eta 1:10:20\r",
+ "\u001b[K |██████▊ | 143.3 MB 126 kB/s eta 1:10:20\r",
+ "\u001b[K |██████▊ | 143.3 MB 126 kB/s eta 1:10:20\r",
+ "\u001b[K |██████▊ | 143.3 MB 126 kB/s eta 1:10:20\r",
+ "\u001b[K |██████▊ | 143.3 MB 126 kB/s eta 1:10:20\r",
+ "\u001b[K |██████▊ | 143.3 MB 126 kB/s eta 1:10:20\r",
+ "\u001b[K |██████▊ | 143.4 MB 126 kB/s eta 1:10:20\r",
+ "\u001b[K |██████▉ | 143.4 MB 126 kB/s eta 1:10:20\r",
+ "\u001b[K |██████▉ | 143.4 MB 126 kB/s eta 1:10:20\r",
+ "\u001b[K |██████▉ | 143.4 MB 126 kB/s eta 1:10:20\r",
+ "\u001b[K |██████▉ | 143.4 MB 126 kB/s eta 1:10:20\r",
+ "\u001b[K |██████▉ | 143.4 MB 126 kB/s eta 1:10:20\r",
+ "\u001b[K |██████▉ | 143.4 MB 126 kB/s eta 1:10:19\r",
+ "\u001b[K |██████▉ | 143.4 MB 126 kB/s eta 1:10:19\r",
+ "\u001b[K |██████▉ | 143.4 MB 126 kB/s eta 1:10:19\r",
+ "\u001b[K |██████▉ | 143.5 MB 126 kB/s eta 1:10:19\r",
+ "\u001b[K |██████▉ | 143.5 MB 126 kB/s eta 1:10:19\r",
+ "\u001b[K |██████▉ | 143.5 MB 126 kB/s eta 1:10:19\r",
+ "\u001b[K |██████▉ | 143.5 MB 126 kB/s eta 1:10:19\r",
+ "\u001b[K |██████▉ | 143.5 MB 126 kB/s eta 1:10:19\r",
+ "\u001b[K |██████▉ | 143.5 MB 126 kB/s eta 1:10:19\r",
+ "\u001b[K |██████▉ | 143.5 MB 126 kB/s eta 1:10:19\r",
+ "\u001b[K |██████▉ | 143.5 MB 126 kB/s eta 1:10:19\r",
+ "\u001b[K |██████▉ | 143.5 MB 126 kB/s eta 1:10:19\r",
+ "\u001b[K |██████▉ | 143.5 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.6 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.6 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.6 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.6 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.6 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.6 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.6 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.6 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.6 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.6 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.7 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.7 MB 126 kB/s eta 1:10:18\r",
+ "\u001b[K |██████▉ | 143.7 MB 126 kB/s eta 1:10:17\r",
+ "\u001b[K |██████▉ | 143.7 MB 126 kB/s eta 1:10:17\r",
+ "\u001b[K |██████▉ | 143.7 MB 126 kB/s eta 1:10:17\r",
+ "\u001b[K |██████▉ | 143.7 MB 126 kB/s eta 1:10:17\r",
+ "\u001b[K |██████▉ | 143.7 MB 126 kB/s eta 1:10:17\r",
+ "\u001b[K |██████▉ | 143.7 MB 126 kB/s eta 1:10:17\r",
+ "\u001b[K |██████▉ | 143.7 MB 126 kB/s eta 1:10:17\r",
+ "\u001b[K |██████▉ | 143.7 MB 126 kB/s eta 1:10:17\r",
+ "\u001b[K |██████▉ | 143.8 MB 126 kB/s eta 1:10:17\r",
+ "\u001b[K |██████▉ | 143.8 MB 126 kB/s eta 1:10:17\r",
+ "\u001b[K |██████▉ | 143.8 MB 126 kB/s eta 1:10:17\r",
+ "\u001b[K |██████▉ | 143.8 MB 126 kB/s eta 1:10:17\r",
+ "\u001b[K |██████▉ | 143.8 MB 126 kB/s eta 1:10:16\r",
+ "\u001b[K |██████▉ | 143.8 MB 126 kB/s eta 1:10:16\r",
+ "\u001b[K |██████▉ | 143.8 MB 126 kB/s eta 1:10:16\r",
+ "\u001b[K |██████▉ | 143.8 MB 126 kB/s eta 1:10:16\r",
+ "\u001b[K |██████▉ | 143.8 MB 126 kB/s eta 1:10:16\r",
+ "\u001b[K |██████▉ | 143.9 MB 126 kB/s eta 1:10:16\r",
+ "\u001b[K |██████▉ | 143.9 MB 126 kB/s eta 1:10:16\r",
+ "\u001b[K |██████▉ | 143.9 MB 126 kB/s eta 1:10:16\r",
+ "\u001b[K |██████▉ | 143.9 MB 126 kB/s eta 1:10:16\r",
+ "\u001b[K |██████▉ | 143.9 MB 126 kB/s eta 1:10:16\r",
+ "\u001b[K |██████▉ | 143.9 MB 126 kB/s eta 1:10:16\r",
+ "\u001b[K |██████▉ | 143.9 MB 126 kB/s eta 1:10:16\r",
+ "\u001b[K |██████▉ | 143.9 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 143.9 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 143.9 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 144.0 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 144.0 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 144.0 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 144.0 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 144.0 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 144.0 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 144.0 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 144.0 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 144.0 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 144.0 MB 126 kB/s eta 1:10:15\r",
+ "\u001b[K |██████▉ | 144.1 MB 126 kB/s eta 1:10:14\r",
+ "\u001b[K |██████▉ | 144.1 MB 126 kB/s eta 1:10:14\r",
+ "\u001b[K |██████▉ | 144.1 MB 126 kB/s eta 1:10:14\r",
+ "\u001b[K |██████▉ | 144.1 MB 126 kB/s eta 1:10:14\r",
+ "\u001b[K |██████▉ | 144.1 MB 126 kB/s eta 1:10:14\r",
+ "\u001b[K |██████▉ | 144.1 MB 126 kB/s eta 1:10:14\r",
+ "\u001b[K |██████▉ | 144.1 MB 126 kB/s eta 1:10:14\r",
+ "\u001b[K |██████▉ | 144.1 MB 126 kB/s eta 1:10:14\r",
+ "\u001b[K |██████▉ | 144.1 MB 126 kB/s eta 1:10:14\r",
+ "\u001b[K |██████▉ | 144.1 MB 126 kB/s eta 1:10:14\r",
+ "\u001b[K |██████▉ | 144.2 MB 126 kB/s eta 1:10:14\r",
+ "\u001b[K |██████▉ | 144.2 MB 126 kB/s eta 1:10:14\r",
+ "\u001b[K |██████▉ | 144.2 MB 126 kB/s eta 1:10:13\r",
+ "\u001b[K |██████▉ | 144.2 MB 126 kB/s eta 1:10:13\r",
+ "\u001b[K |██████▉ | 144.2 MB 126 kB/s eta 1:10:13\r",
+ "\u001b[K |██████▉ | 144.2 MB 126 kB/s eta 1:10:13\r",
+ "\u001b[K |██████▉ | 144.2 MB 126 kB/s eta 1:10:13\r",
+ "\u001b[K |██████▉ | 144.2 MB 126 kB/s eta 1:10:13\r",
+ "\u001b[K |██████▉ | 144.2 MB 126 kB/s eta 1:10:13\r",
+ "\u001b[K |██████▉ | 144.3 MB 126 kB/s eta 1:10:13\r",
+ "\u001b[K |██████▉ | 144.3 MB 126 kB/s eta 1:10:13\r",
+ "\u001b[K |██████▉ | 144.3 MB 126 kB/s eta 1:10:13\r",
+ "\u001b[K |██████▉ | 144.3 MB 126 kB/s eta 1:10:13\r",
+ "\u001b[K |██████▉ | 144.3 MB 126 kB/s eta 1:10:13\r",
+ "\u001b[K |██████▉ | 144.3 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.3 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.3 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.3 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.3 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.4 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.4 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.4 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.4 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.4 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.4 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.4 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.4 MB 126 kB/s eta 1:10:12\r",
+ "\u001b[K |██████▉ | 144.4 MB 126 kB/s eta 1:10:11\r",
+ "\u001b[K |██████▉ | 144.4 MB 126 kB/s eta 1:10:11\r",
+ "\u001b[K |██████▉ | 144.5 MB 126 kB/s eta 1:10:11\r",
+ "\u001b[K |██████▉ | 144.5 MB 126 kB/s eta 1:10:11\r",
+ "\u001b[K |██████▉ | 144.5 MB 126 kB/s eta 1:10:11\r",
+ "\u001b[K |██████▉ | 144.5 MB 126 kB/s eta 1:10:11\r",
+ "\u001b[K |██████▉ | 144.5 MB 126 kB/s eta 1:10:11\r",
+ "\u001b[K |██████▉ | 144.5 MB 126 kB/s eta 1:10:11\r",
+ "\u001b[K |██████▉ | 144.5 MB 126 kB/s eta 1:10:11\r",
+ "\u001b[K |██████▉ | 144.5 MB 126 kB/s eta 1:10:11\r",
+ "\u001b[K |██████▉ | 144.5 MB 126 kB/s eta 1:10:11\r",
+ "\u001b[K |██████▉ | 144.5 MB 126 kB/s eta 1:10:11\r",
+ "\u001b[K |██████▉ | 144.6 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.6 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.6 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.6 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.6 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.6 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.6 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.6 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.6 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.7 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.7 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.7 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.7 MB 126 kB/s eta 1:10:10\r",
+ "\u001b[K |██████▉ | 144.7 MB 126 kB/s eta 1:10:09\r",
+ "\u001b[K |██████▉ | 144.7 MB 126 kB/s eta 1:10:09\r",
+ "\u001b[K |██████▉ | 144.7 MB 126 kB/s eta 1:10:09\r",
+ "\u001b[K |██████▉ | 144.7 MB 126 kB/s eta 1:10:09\r",
+ "\u001b[K |██████▉ | 144.7 MB 126 kB/s eta 1:10:09\r",
+ "\u001b[K |██████▉ | 144.7 MB 126 kB/s eta 1:10:09\r",
+ "\u001b[K |██████▉ | 144.8 MB 126 kB/s eta 1:10:09\r",
+ "\u001b[K |██████▉ | 144.8 MB 126 kB/s eta 1:10:09\r",
+ "\u001b[K |██████▉ | 144.8 MB 126 kB/s eta 1:10:09\r",
+ "\u001b[K |██████▉ | 144.8 MB 126 kB/s eta 1:10:09\r",
+ "\u001b[K |██████▉ | 144.8 MB 126 kB/s eta 1:10:09\r",
+ "\u001b[K |██████▉ | 144.8 MB 126 kB/s eta 1:10:09\r",
+ "\u001b[K |██████▉ | 144.8 MB 126 kB/s eta 1:10:08\r",
+ "\u001b[K |██████▉ | 144.8 MB 126 kB/s eta 1:10:08\r",
+ "\u001b[K |██████▉ | 144.8 MB 126 kB/s eta 1:10:08\r",
+ "\u001b[K |██████▉ | 144.8 MB 126 kB/s eta 1:10:08\r",
+ "\u001b[K |██████▉ | 144.9 MB 126 kB/s eta 1:10:08\r",
+ "\u001b[K |██████▉ | 144.9 MB 126 kB/s eta 1:10:08\r",
+ "\u001b[K |██████▉ | 144.9 MB 126 kB/s eta 1:10:08\r",
+ "\u001b[K |██████▉ | 144.9 MB 126 kB/s eta 1:10:08\r",
+ "\u001b[K |██████▉ | 144.9 MB 126 kB/s eta 1:10:08\r",
+ "\u001b[K |██████▉ | 144.9 MB 126 kB/s eta 1:10:08\r",
+ "\u001b[K |██████▉ | 144.9 MB 126 kB/s eta 1:10:08\r",
+ "\u001b[K |██████▉ | 144.9 MB 126 kB/s eta 1:10:08\r",
+ "\u001b[K |██████▉ | 144.9 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 144.9 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 145.0 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 145.0 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 145.0 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 145.0 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 145.0 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 145.0 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 145.0 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 145.0 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 145.0 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 145.0 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 145.1 MB 126 kB/s eta 1:10:07\r",
+ "\u001b[K |██████▉ | 145.1 MB 126 kB/s eta 1:10:06\r",
+ "\u001b[K |██████▉ | 145.1 MB 126 kB/s eta 1:10:06\r",
+ "\u001b[K |██████▉ | 145.1 MB 126 kB/s eta 1:10:06\r",
+ "\u001b[K |██████▉ | 145.1 MB 126 kB/s eta 1:10:06\r",
+ "\u001b[K |██████▉ | 145.1 MB 126 kB/s eta 1:10:06\r",
+ "\u001b[K |██████▉ | 145.1 MB 126 kB/s eta 1:10:06\r",
+ "\u001b[K |██████▉ | 145.1 MB 126 kB/s eta 1:10:06\r",
+ "\u001b[K |██████▉ | 145.1 MB 126 kB/s eta 1:10:06\r",
+ "\u001b[K |██████▉ | 145.2 MB 126 kB/s eta 1:10:06\r",
+ "\u001b[K |██████▉ | 145.2 MB 126 kB/s eta 1:10:06\r",
+ "\u001b[K |██████▉ | 145.2 MB 126 kB/s eta 1:10:06\r",
+ "\u001b[K |██████▉ | 145.2 MB 126 kB/s eta 1:10:06\r",
+ "\u001b[K |██████▉ | 145.2 MB 126 kB/s eta 1:10:05\r",
+ "\u001b[K |██████▉ | 145.2 MB 126 kB/s eta 1:10:05\r",
+ "\u001b[K |██████▉ | 145.2 MB 126 kB/s eta 1:10:05\r",
+ "\u001b[K |██████▉ | 145.2 MB 126 kB/s eta 1:10:05\r",
+ "\u001b[K |██████▉ | 145.2 MB 126 kB/s eta 1:10:05\r",
+ "\u001b[K |██████▉ | 145.2 MB 126 kB/s eta 1:10:05\r",
+ "\u001b[K |██████▉ | 145.3 MB 126 kB/s eta 1:10:05\r",
+ "\u001b[K |██████▉ | 145.3 MB 126 kB/s eta 1:10:05\r",
+ "\u001b[K |██████▉ | 145.3 MB 126 kB/s eta 1:10:05\r",
+ "\u001b[K |██████▉ | 145.3 MB 126 kB/s eta 1:10:05\r",
+ "\u001b[K |██████▉ | 145.3 MB 126 kB/s eta 1:10:05\r",
+ "\u001b[K |██████▉ | 145.3 MB 126 kB/s eta 1:10:05\r",
+ "\u001b[K |██████▉ | 145.3 MB 126 kB/s eta 1:10:04\r",
+ "\u001b[K |██████▉ | 145.3 MB 126 kB/s eta 1:10:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████▉ | 145.3 MB 126 kB/s eta 1:10:04\r",
+ "\u001b[K |██████▉ | 145.3 MB 126 kB/s eta 1:10:04\r",
+ "\u001b[K |██████▉ | 145.4 MB 126 kB/s eta 1:10:04\r",
+ "\u001b[K |██████▉ | 145.4 MB 126 kB/s eta 1:10:04\r",
+ "\u001b[K |██████▉ | 145.4 MB 126 kB/s eta 1:10:04\r",
+ "\u001b[K |██████▉ | 145.4 MB 126 kB/s eta 1:10:04\r",
+ "\u001b[K |██████▉ | 145.4 MB 126 kB/s eta 1:10:04\r",
+ "\u001b[K |██████▉ | 145.4 MB 126 kB/s eta 1:10:04\r",
+ "\u001b[K |██████▉ | 145.4 MB 126 kB/s eta 1:10:04\r",
+ "\u001b[K |██████▉ | 145.4 MB 126 kB/s eta 1:10:04\r",
+ "\u001b[K |██████▉ | 145.4 MB 126 kB/s eta 1:10:04\r",
+ "\u001b[K |██████▉ | 145.4 MB 126 kB/s eta 1:10:03\r",
+ "\u001b[K |██████▉ | 145.5 MB 126 kB/s eta 1:10:03\r",
+ "\u001b[K |██████▉ | 145.5 MB 126 kB/s eta 1:10:03\r",
+ "\u001b[K |██████▉ | 145.5 MB 126 kB/s eta 1:10:03\r",
+ "\u001b[K |██████▉ | 145.5 MB 126 kB/s eta 1:10:03\r",
+ "\u001b[K |██████▉ | 145.5 MB 126 kB/s eta 1:10:03\r",
+ "\u001b[K |██████▉ | 145.5 MB 126 kB/s eta 1:10:03\r",
+ "\u001b[K |██████▉ | 145.5 MB 126 kB/s eta 1:10:03\r",
+ "\u001b[K |██████▉ | 145.5 MB 126 kB/s eta 1:10:03\r",
+ "\u001b[K |██████▉ | 145.5 MB 126 kB/s eta 1:10:03\r",
+ "\u001b[K |██████▉ | 145.6 MB 126 kB/s eta 1:10:03\r",
+ "\u001b[K |██████▉ | 145.6 MB 126 kB/s eta 1:10:03\r",
+ "\u001b[K |██████▉ | 145.6 MB 126 kB/s eta 1:10:02\r",
+ "\u001b[K |██████▉ | 145.6 MB 126 kB/s eta 1:10:02\r",
+ "\u001b[K |██████▉ | 145.6 MB 126 kB/s eta 1:10:02\r",
+ "\u001b[K |██████▉ | 145.6 MB 126 kB/s eta 1:10:02\r",
+ "\u001b[K |██████▉ | 145.6 MB 126 kB/s eta 1:10:02\r",
+ "\u001b[K |██████▉ | 145.6 MB 126 kB/s eta 1:10:02\r",
+ "\u001b[K |██████▉ | 145.6 MB 126 kB/s eta 1:10:02\r",
+ "\u001b[K |██████▉ | 145.6 MB 126 kB/s eta 1:10:02\r",
+ "\u001b[K |██████▉ | 145.7 MB 126 kB/s eta 1:10:02\r",
+ "\u001b[K |██████▉ | 145.7 MB 126 kB/s eta 1:10:02\r",
+ "\u001b[K |██████▉ | 145.7 MB 126 kB/s eta 1:10:02\r",
+ "\u001b[K |██████▉ | 145.7 MB 126 kB/s eta 1:10:02\r",
+ "\u001b[K |██████▉ | 145.7 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |██████▉ | 145.7 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |██████▉ | 145.7 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |███████ | 145.7 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |███████ | 145.7 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |███████ | 145.7 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |███████ | 145.8 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |███████ | 145.8 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |███████ | 145.8 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |███████ | 145.8 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |███████ | 145.8 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |███████ | 145.8 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |███████ | 145.8 MB 126 kB/s eta 1:10:01\r",
+ "\u001b[K |███████ | 145.8 MB 126 kB/s eta 1:10:00\r",
+ "\u001b[K |███████ | 145.8 MB 126 kB/s eta 1:10:00\r",
+ "\u001b[K |███████ | 145.8 MB 126 kB/s eta 1:10:00\r",
+ "\u001b[K |███████ | 145.9 MB 126 kB/s eta 1:10:00\r",
+ "\u001b[K |███████ | 145.9 MB 126 kB/s eta 1:10:00\r",
+ "\u001b[K |███████ | 145.9 MB 126 kB/s eta 1:10:00\r",
+ "\u001b[K |███████ | 145.9 MB 126 kB/s eta 1:10:00\r",
+ "\u001b[K |███████ | 145.9 MB 126 kB/s eta 1:10:00\r",
+ "\u001b[K |███████ | 145.9 MB 126 kB/s eta 1:10:00\r",
+ "\u001b[K |███████ | 145.9 MB 126 kB/s eta 1:10:00\r",
+ "\u001b[K |███████ | 145.9 MB 126 kB/s eta 1:10:00\r",
+ "\u001b[K |███████ | 145.9 MB 126 kB/s eta 1:10:00\r",
+ "\u001b[K |███████ | 146.0 MB 126 kB/s eta 1:09:59\r",
+ "\u001b[K |███████ | 146.0 MB 126 kB/s eta 1:09:59\r",
+ "\u001b[K |███████ | 146.0 MB 126 kB/s eta 1:09:59\r",
+ "\u001b[K |███████ | 146.0 MB 126 kB/s eta 1:09:59\r",
+ "\u001b[K |███████ | 146.0 MB 126 kB/s eta 1:09:59\r",
+ "\u001b[K |███████ | 146.0 MB 126 kB/s eta 1:09:59\r",
+ "\u001b[K |███████ | 146.0 MB 126 kB/s eta 1:09:59\r",
+ "\u001b[K |███████ | 146.0 MB 126 kB/s eta 1:09:59\r",
+ "\u001b[K |███████ | 146.0 MB 126 kB/s eta 1:09:59\r",
+ "\u001b[K |███████ | 146.0 MB 126 kB/s eta 1:09:59\r",
+ "\u001b[K |███████ | 146.1 MB 126 kB/s eta 1:09:59\r",
+ "\u001b[K |███████ | 146.1 MB 126 kB/s eta 1:09:59\r",
+ "\u001b[K |███████ | 146.1 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.1 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.1 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.1 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.1 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.1 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.1 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.1 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.2 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.2 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.2 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.2 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.2 MB 126 kB/s eta 1:09:58\r",
+ "\u001b[K |███████ | 146.2 MB 126 kB/s eta 1:09:57\r",
+ "\u001b[K |███████ | 146.2 MB 126 kB/s eta 1:09:57\r",
+ "\u001b[K |███████ | 146.2 MB 126 kB/s eta 1:09:57\r",
+ "\u001b[K |███████ | 146.2 MB 126 kB/s eta 1:09:57\r",
+ "\u001b[K |███████ | 146.2 MB 126 kB/s eta 1:09:57\r",
+ "\u001b[K |███████ | 146.3 MB 126 kB/s eta 1:09:57\r",
+ "\u001b[K |███████ | 146.3 MB 126 kB/s eta 1:09:57\r",
+ "\u001b[K |███████ | 146.3 MB 126 kB/s eta 1:09:57\r",
+ "\u001b[K |███████ | 146.3 MB 126 kB/s eta 1:09:57\r",
+ "\u001b[K |███████ | 146.3 MB 126 kB/s eta 1:09:57\r",
+ "\u001b[K |███████ | 146.3 MB 126 kB/s eta 1:09:57\r",
+ "\u001b[K |███████ | 146.3 MB 126 kB/s eta 1:09:57\r",
+ "\u001b[K |███████ | 146.3 MB 126 kB/s eta 1:09:56\r",
+ "\u001b[K |███████ | 146.3 MB 126 kB/s eta 1:09:56\r",
+ "\u001b[K |███████ | 146.4 MB 126 kB/s eta 1:09:56\r",
+ "\u001b[K |███████ | 146.4 MB 126 kB/s eta 1:09:56\r",
+ "\u001b[K |███████ | 146.4 MB 126 kB/s eta 1:09:56\r",
+ "\u001b[K |███████ | 146.4 MB 126 kB/s eta 1:09:56\r",
+ "\u001b[K |███████ | 146.4 MB 126 kB/s eta 1:09:56\r",
+ "\u001b[K |███████ | 146.4 MB 126 kB/s eta 1:09:56\r",
+ "\u001b[K |███████ | 146.4 MB 126 kB/s eta 1:09:56\r",
+ "\u001b[K |███████ | 146.4 MB 126 kB/s eta 1:09:56\r",
+ "\u001b[K |███████ | 146.4 MB 126 kB/s eta 1:09:56\r",
+ "\u001b[K |███████ | 146.4 MB 126 kB/s eta 1:09:56\r",
+ "\u001b[K |███████ | 146.5 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.5 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.5 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.5 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.5 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.5 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.5 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.5 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.5 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.5 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.6 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.6 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.6 MB 126 kB/s eta 1:09:55\r",
+ "\u001b[K |███████ | 146.6 MB 126 kB/s eta 1:09:54\r",
+ "\u001b[K |███████ | 146.6 MB 126 kB/s eta 1:09:54\r",
+ "\u001b[K |███████ | 146.6 MB 126 kB/s eta 1:09:54\r",
+ "\u001b[K |███████ | 146.6 MB 126 kB/s eta 1:09:54\r",
+ "\u001b[K |███████ | 146.6 MB 126 kB/s eta 1:09:54\r",
+ "\u001b[K |███████ | 146.6 MB 126 kB/s eta 1:09:54\r",
+ "\u001b[K |███████ | 146.6 MB 126 kB/s eta 1:09:54\r",
+ "\u001b[K |███████ | 146.7 MB 126 kB/s eta 1:09:54\r",
+ "\u001b[K |███████ | 146.7 MB 126 kB/s eta 1:09:54\r",
+ "\u001b[K |███████ | 146.7 MB 126 kB/s eta 1:09:54\r",
+ "\u001b[K |███████ | 146.7 MB 126 kB/s eta 1:09:54\r",
+ "\u001b[K |███████ | 146.7 MB 126 kB/s eta 1:09:54\r",
+ "\u001b[K |███████ | 146.7 MB 126 kB/s eta 1:09:53\r",
+ "\u001b[K |███████ | 146.7 MB 126 kB/s eta 1:09:53\r",
+ "\u001b[K |███████ | 146.7 MB 126 kB/s eta 1:09:53\r",
+ "\u001b[K |███████ | 146.7 MB 126 kB/s eta 1:09:53\r",
+ "\u001b[K |███████ | 146.7 MB 126 kB/s eta 1:09:53\r",
+ "\u001b[K |███████ | 146.8 MB 126 kB/s eta 1:09:53\r",
+ "\u001b[K |███████ | 146.8 MB 126 kB/s eta 1:09:53\r",
+ "\u001b[K |███████ | 146.8 MB 126 kB/s eta 1:09:53\r",
+ "\u001b[K |███████ | 146.8 MB 126 kB/s eta 1:09:53\r",
+ "\u001b[K |███████ | 146.8 MB 126 kB/s eta 1:09:53\r",
+ "\u001b[K |███████ | 146.8 MB 126 kB/s eta 1:09:53\r",
+ "\u001b[K |███████ | 146.8 MB 126 kB/s eta 1:09:53\r",
+ "\u001b[K |███████ | 146.8 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 146.8 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 146.9 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 146.9 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 146.9 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 146.9 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 146.9 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 146.9 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 146.9 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 146.9 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 146.9 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 146.9 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 147.0 MB 126 kB/s eta 1:09:52\r",
+ "\u001b[K |███████ | 147.0 MB 126 kB/s eta 1:09:51\r",
+ "\u001b[K |███████ | 147.0 MB 126 kB/s eta 1:09:51\r",
+ "\u001b[K |███████ | 147.0 MB 126 kB/s eta 1:09:51\r",
+ "\u001b[K |███████ | 147.0 MB 126 kB/s eta 1:09:51\r",
+ "\u001b[K |███████ | 147.0 MB 126 kB/s eta 1:09:51\r",
+ "\u001b[K |███████ | 147.0 MB 126 kB/s eta 1:09:51\r",
+ "\u001b[K |███████ | 147.0 MB 126 kB/s eta 1:09:51\r",
+ "\u001b[K |███████ | 147.0 MB 126 kB/s eta 1:09:51\r",
+ "\u001b[K |███████ | 147.0 MB 126 kB/s eta 1:09:51\r",
+ "\u001b[K |███████ | 147.1 MB 126 kB/s eta 1:09:51\r",
+ "\u001b[K |███████ | 147.1 MB 126 kB/s eta 1:09:51\r",
+ "\u001b[K |███████ | 147.1 MB 126 kB/s eta 1:09:51\r",
+ "\u001b[K |███████ | 147.1 MB 126 kB/s eta 1:09:50\r",
+ "\u001b[K |███████ | 147.1 MB 126 kB/s eta 1:09:50\r",
+ "\u001b[K |███████ | 147.1 MB 126 kB/s eta 1:09:50\r",
+ "\u001b[K |███████ | 147.1 MB 126 kB/s eta 1:09:50\r",
+ "\u001b[K |███████ | 147.1 MB 126 kB/s eta 1:09:50\r",
+ "\u001b[K |███████ | 147.1 MB 126 kB/s eta 1:09:50\r",
+ "\u001b[K |███████ | 147.1 MB 126 kB/s eta 1:09:50\r",
+ "\u001b[K |███████ | 147.2 MB 126 kB/s eta 1:09:50\r",
+ "\u001b[K |███████ | 147.2 MB 126 kB/s eta 1:09:50\r",
+ "\u001b[K |███████ | 147.2 MB 126 kB/s eta 1:09:50\r",
+ "\u001b[K |███████ | 147.2 MB 126 kB/s eta 1:09:50\r",
+ "\u001b[K |███████ | 147.2 MB 126 kB/s eta 1:09:50\r",
+ "\u001b[K |███████ | 147.2 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.2 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.2 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.2 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.3 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.3 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.3 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.3 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.3 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.3 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.3 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.3 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.3 MB 126 kB/s eta 1:09:49\r",
+ "\u001b[K |███████ | 147.3 MB 126 kB/s eta 1:09:48\r",
+ "\u001b[K |███████ | 147.4 MB 126 kB/s eta 1:09:48\r",
+ "\u001b[K |███████ | 147.4 MB 126 kB/s eta 1:09:48\r",
+ "\u001b[K |███████ | 147.4 MB 126 kB/s eta 1:09:48\r",
+ "\u001b[K |███████ | 147.4 MB 126 kB/s eta 1:09:48\r",
+ "\u001b[K |███████ | 147.4 MB 126 kB/s eta 1:09:48\r",
+ "\u001b[K |███████ | 147.4 MB 126 kB/s eta 1:09:48\r",
+ "\u001b[K |███████ | 147.4 MB 126 kB/s eta 1:09:48\r",
+ "\u001b[K |███████ | 147.4 MB 126 kB/s eta 1:09:48\r",
+ "\u001b[K |███████ | 147.4 MB 126 kB/s eta 1:09:48\r",
+ "\u001b[K |███████ | 147.4 MB 126 kB/s eta 1:09:48\r",
+ "\u001b[K |███████ | 147.5 MB 126 kB/s eta 1:09:48\r",
+ "\u001b[K |███████ | 147.5 MB 126 kB/s eta 1:09:47\r",
+ "\u001b[K |███████ | 147.5 MB 126 kB/s eta 1:09:47\r",
+ "\u001b[K |███████ | 147.5 MB 126 kB/s eta 1:09:47\r",
+ "\u001b[K |███████ | 147.5 MB 126 kB/s eta 1:09:47"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████ | 147.5 MB 126 kB/s eta 1:09:47\r",
+ "\u001b[K |███████ | 147.5 MB 126 kB/s eta 1:09:47\r",
+ "\u001b[K |███████ | 147.5 MB 126 kB/s eta 1:09:47\r",
+ "\u001b[K |███████ | 147.5 MB 126 kB/s eta 1:09:47\r",
+ "\u001b[K |███████ | 147.5 MB 126 kB/s eta 1:09:47\r",
+ "\u001b[K |███████ | 147.6 MB 126 kB/s eta 1:09:47\r",
+ "\u001b[K |███████ | 147.6 MB 126 kB/s eta 1:09:47\r",
+ "\u001b[K |███████ | 147.6 MB 126 kB/s eta 1:09:47\r",
+ "\u001b[K |███████ | 147.6 MB 126 kB/s eta 1:09:47\r",
+ "\u001b[K |███████ | 147.6 MB 126 kB/s eta 1:09:46\r",
+ "\u001b[K |███████ | 147.6 MB 126 kB/s eta 1:09:46\r",
+ "\u001b[K |███████ | 147.6 MB 126 kB/s eta 1:09:46\r",
+ "\u001b[K |███████ | 147.6 MB 126 kB/s eta 1:09:46\r",
+ "\u001b[K |███████ | 147.6 MB 126 kB/s eta 1:09:46\r",
+ "\u001b[K |███████ | 147.7 MB 126 kB/s eta 1:09:46\r",
+ "\u001b[K |███████ | 147.7 MB 126 kB/s eta 1:09:46\r",
+ "\u001b[K |███████ | 147.7 MB 126 kB/s eta 1:09:46\r",
+ "\u001b[K |███████ | 147.7 MB 126 kB/s eta 1:09:46\r",
+ "\u001b[K |███████ | 147.7 MB 126 kB/s eta 1:09:46\r",
+ "\u001b[K |███████ | 147.7 MB 126 kB/s eta 1:09:46\r",
+ "\u001b[K |███████ | 147.7 MB 126 kB/s eta 1:09:46\r",
+ "\u001b[K |███████ | 147.7 MB 126 kB/s eta 1:09:45\r",
+ "\u001b[K |███████ | 147.7 MB 126 kB/s eta 1:09:45\r",
+ "\u001b[K |███████ | 147.7 MB 126 kB/s eta 1:09:45\r",
+ "\u001b[K |███████ | 147.8 MB 126 kB/s eta 1:09:45\r",
+ "\u001b[K |███████ | 147.8 MB 126 kB/s eta 1:09:45\r",
+ "\u001b[K |███████ | 147.8 MB 126 kB/s eta 1:09:45\r",
+ "\u001b[K |███████ | 147.8 MB 126 kB/s eta 1:09:45\r",
+ "\u001b[K |███████ | 147.8 MB 126 kB/s eta 1:09:45\r",
+ "\u001b[K |███████ | 147.8 MB 126 kB/s eta 1:09:45\r",
+ "\u001b[K |███████ | 147.8 MB 126 kB/s eta 1:09:45\r",
+ "\u001b[K |███████ | 147.8 MB 126 kB/s eta 1:09:45\r",
+ "\u001b[K |███████ | 147.8 MB 126 kB/s eta 1:09:45\r",
+ "\u001b[K |███████ | 147.8 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 147.9 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 147.9 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 147.9 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 147.9 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 147.9 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 147.9 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 147.9 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 147.9 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 147.9 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 147.9 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 148.0 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 148.0 MB 126 kB/s eta 1:09:44\r",
+ "\u001b[K |███████ | 148.0 MB 126 kB/s eta 1:09:43\r",
+ "\u001b[K |███████ | 148.0 MB 126 kB/s eta 1:09:43\r",
+ "\u001b[K |███████ | 148.0 MB 126 kB/s eta 1:09:43\r",
+ "\u001b[K |███████ | 148.0 MB 126 kB/s eta 1:09:43\r",
+ "\u001b[K |███████ | 148.0 MB 126 kB/s eta 1:09:43\r",
+ "\u001b[K |███████ | 148.0 MB 126 kB/s eta 1:09:43\r",
+ "\u001b[K |███████ | 148.0 MB 126 kB/s eta 1:09:43\r",
+ "\u001b[K |███████ | 148.0 MB 126 kB/s eta 1:09:43\r",
+ "\u001b[K |███████ | 148.1 MB 126 kB/s eta 1:09:43\r",
+ "\u001b[K |███████ | 148.1 MB 126 kB/s eta 1:09:43\r",
+ "\u001b[K |███████ | 148.1 MB 126 kB/s eta 1:09:43\r",
+ "\u001b[K |███████ | 148.1 MB 126 kB/s eta 1:09:43\r",
+ "\u001b[K |███████ | 148.1 MB 126 kB/s eta 1:09:42\r",
+ "\u001b[K |███████ | 148.1 MB 126 kB/s eta 1:09:42\r",
+ "\u001b[K |███████ | 148.1 MB 126 kB/s eta 1:09:42\r",
+ "\u001b[K |███████ | 148.1 MB 126 kB/s eta 1:09:42\r",
+ "\u001b[K |███████ | 148.1 MB 126 kB/s eta 1:09:42\r",
+ "\u001b[K |███████ | 148.2 MB 126 kB/s eta 1:09:42\r",
+ "\u001b[K |███████ | 148.2 MB 126 kB/s eta 1:09:42\r",
+ "\u001b[K |███████ | 148.2 MB 126 kB/s eta 1:09:42\r",
+ "\u001b[K |███████ | 148.2 MB 126 kB/s eta 1:09:42\r",
+ "\u001b[K |███████ | 148.2 MB 126 kB/s eta 1:09:42\r",
+ "\u001b[K |███████ | 148.2 MB 126 kB/s eta 1:09:42\r",
+ "\u001b[K |███████ | 148.2 MB 126 kB/s eta 1:09:42\r",
+ "\u001b[K |███████ | 148.2 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.2 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.2 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.3 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.3 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.3 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.3 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.3 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.3 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.3 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.3 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.3 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.3 MB 126 kB/s eta 1:09:41\r",
+ "\u001b[K |███████ | 148.4 MB 126 kB/s eta 1:09:40\r",
+ "\u001b[K |███████ | 148.4 MB 126 kB/s eta 1:09:40\r",
+ "\u001b[K |███████ | 148.4 MB 126 kB/s eta 1:09:40\r",
+ "\u001b[K |███████ | 148.4 MB 126 kB/s eta 1:09:40\r",
+ "\u001b[K |███████ | 148.4 MB 126 kB/s eta 1:09:40\r",
+ "\u001b[K |███████ | 148.4 MB 126 kB/s eta 1:09:40\r",
+ "\u001b[K |███████ | 148.4 MB 126 kB/s eta 1:09:40\r",
+ "\u001b[K |███████ | 148.4 MB 126 kB/s eta 1:09:40\r",
+ "\u001b[K |███████ | 148.4 MB 126 kB/s eta 1:09:40\r",
+ "\u001b[K |███████ | 148.4 MB 126 kB/s eta 1:09:40\r",
+ "\u001b[K |███████ | 148.5 MB 126 kB/s eta 1:09:40\r",
+ "\u001b[K |███████ | 148.5 MB 126 kB/s eta 1:09:40\r",
+ "\u001b[K |███████ | 148.5 MB 126 kB/s eta 1:09:39\r",
+ "\u001b[K |███████ | 148.5 MB 126 kB/s eta 1:09:39\r",
+ "\u001b[K |███████ | 148.5 MB 126 kB/s eta 1:09:39\r",
+ "\u001b[K |███████ | 148.5 MB 126 kB/s eta 1:09:39\r",
+ "\u001b[K |███████ | 148.5 MB 126 kB/s eta 1:09:39\r",
+ "\u001b[K |███████ | 148.5 MB 126 kB/s eta 1:09:39\r",
+ "\u001b[K |███████ | 148.5 MB 126 kB/s eta 1:09:39\r",
+ "\u001b[K |███████ | 148.6 MB 126 kB/s eta 1:09:39\r",
+ "\u001b[K |███████ | 148.6 MB 126 kB/s eta 1:09:39\r",
+ "\u001b[K |███████ | 148.6 MB 126 kB/s eta 1:09:39\r",
+ "\u001b[K |███████ | 148.6 MB 126 kB/s eta 1:09:39\r",
+ "\u001b[K |███████ | 148.6 MB 126 kB/s eta 1:09:39\r",
+ "\u001b[K |███████ | 148.6 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.6 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.6 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.6 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.6 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.7 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.7 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.7 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.7 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.7 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.7 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.7 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.7 MB 126 kB/s eta 1:09:38\r",
+ "\u001b[K |███████ | 148.7 MB 126 kB/s eta 1:09:37\r",
+ "\u001b[K |███████ | 148.7 MB 126 kB/s eta 1:09:37\r",
+ "\u001b[K |███████ | 148.8 MB 126 kB/s eta 1:09:37\r",
+ "\u001b[K |███████ | 148.8 MB 126 kB/s eta 1:09:37\r",
+ "\u001b[K |███████ | 148.8 MB 126 kB/s eta 1:09:37\r",
+ "\u001b[K |███████ | 148.8 MB 126 kB/s eta 1:09:37\r",
+ "\u001b[K |███████ | 148.8 MB 126 kB/s eta 1:09:37\r",
+ "\u001b[K |███████ | 148.8 MB 126 kB/s eta 1:09:37\r",
+ "\u001b[K |███████ | 148.8 MB 126 kB/s eta 1:09:37\r",
+ "\u001b[K |███████ | 148.8 MB 126 kB/s eta 1:09:37\r",
+ "\u001b[K |███████ | 148.8 MB 126 kB/s eta 1:09:37\r",
+ "\u001b[K |███████ | 148.8 MB 126 kB/s eta 1:09:37\r",
+ "\u001b[K |███████ | 148.9 MB 126 kB/s eta 1:09:36\r",
+ "\u001b[K |███████ | 148.9 MB 126 kB/s eta 1:09:36\r",
+ "\u001b[K |███████ | 148.9 MB 126 kB/s eta 1:09:36\r",
+ "\u001b[K |███████ | 148.9 MB 126 kB/s eta 1:09:36\r",
+ "\u001b[K |███████ | 148.9 MB 126 kB/s eta 1:09:36\r",
+ "\u001b[K |███████ | 148.9 MB 126 kB/s eta 1:09:36\r",
+ "\u001b[K |███████ | 148.9 MB 126 kB/s eta 1:09:36\r",
+ "\u001b[K |███████ | 148.9 MB 126 kB/s eta 1:09:36\r",
+ "\u001b[K |███████ | 148.9 MB 126 kB/s eta 1:09:36\r",
+ "\u001b[K |███████ | 149.0 MB 126 kB/s eta 1:09:36\r",
+ "\u001b[K |███████ | 149.0 MB 126 kB/s eta 1:09:36\r",
+ "\u001b[K |███████ | 149.0 MB 126 kB/s eta 1:09:36\r",
+ "\u001b[K |███████ | 149.0 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.0 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.0 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.0 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.0 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.0 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.0 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.1 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.1 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.1 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.1 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.1 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.1 MB 126 kB/s eta 1:09:35\r",
+ "\u001b[K |███████ | 149.1 MB 126 kB/s eta 1:09:34\r",
+ "\u001b[K |███████ | 149.1 MB 126 kB/s eta 1:09:34\r",
+ "\u001b[K |███████ | 149.1 MB 126 kB/s eta 1:09:34\r",
+ "\u001b[K |███████ | 149.1 MB 126 kB/s eta 1:09:34\r",
+ "\u001b[K |███████ | 149.2 MB 126 kB/s eta 1:09:34\r",
+ "\u001b[K |███████ | 149.2 MB 126 kB/s eta 1:09:34\r",
+ "\u001b[K |███████ | 149.2 MB 126 kB/s eta 1:09:34\r",
+ "\u001b[K |███████ | 149.2 MB 126 kB/s eta 1:09:34\r",
+ "\u001b[K |███████ | 149.2 MB 126 kB/s eta 1:09:34\r",
+ "\u001b[K |███████ | 149.2 MB 126 kB/s eta 1:09:34\r",
+ "\u001b[K |███████ | 149.2 MB 126 kB/s eta 1:09:34\r",
+ "\u001b[K |███████ | 149.2 MB 126 kB/s eta 1:09:34\r",
+ "\u001b[K |███████ | 149.2 MB 126 kB/s eta 1:09:33\r",
+ "\u001b[K |███████ | 149.2 MB 126 kB/s eta 1:09:33\r",
+ "\u001b[K |███████ | 149.3 MB 126 kB/s eta 1:09:33\r",
+ "\u001b[K |███████ | 149.3 MB 126 kB/s eta 1:09:33\r",
+ "\u001b[K |███████ | 149.3 MB 126 kB/s eta 1:09:33\r",
+ "\u001b[K |███████ | 149.3 MB 126 kB/s eta 1:09:33\r",
+ "\u001b[K |███████ | 149.3 MB 126 kB/s eta 1:09:33\r",
+ "\u001b[K |███████ | 149.3 MB 126 kB/s eta 1:09:33\r",
+ "\u001b[K |███████ | 149.3 MB 126 kB/s eta 1:09:33\r",
+ "\u001b[K |███████ | 149.3 MB 126 kB/s eta 1:09:33\r",
+ "\u001b[K |███████ | 149.3 MB 126 kB/s eta 1:09:33"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████ | 149.4 MB 126 kB/s eta 1:09:33\r",
+ "\u001b[K |███████ | 149.4 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.4 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.4 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.4 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.4 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.4 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.4 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.4 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.4 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.5 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.5 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.5 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.5 MB 126 kB/s eta 1:09:32\r",
+ "\u001b[K |███████ | 149.5 MB 126 kB/s eta 1:09:31\r",
+ "\u001b[K |███████ | 149.5 MB 126 kB/s eta 1:09:31\r",
+ "\u001b[K |███████ | 149.5 MB 126 kB/s eta 1:09:31\r",
+ "\u001b[K |███████ | 149.5 MB 126 kB/s eta 1:09:31\r",
+ "\u001b[K |███████ | 149.5 MB 126 kB/s eta 1:09:31\r",
+ "\u001b[K |███████ | 149.5 MB 126 kB/s eta 1:09:31\r",
+ "\u001b[K |███████ | 149.6 MB 126 kB/s eta 1:09:31\r",
+ "\u001b[K |███████ | 149.6 MB 126 kB/s eta 1:09:31\r",
+ "\u001b[K |███████ | 149.6 MB 126 kB/s eta 1:09:31\r",
+ "\u001b[K |███████ | 149.6 MB 126 kB/s eta 1:09:31\r",
+ "\u001b[K |███████ | 149.6 MB 126 kB/s eta 1:09:31\r",
+ "\u001b[K |███████ | 149.6 MB 126 kB/s eta 1:09:31\r",
+ "\u001b[K |███████ | 149.6 MB 126 kB/s eta 1:09:30\r",
+ "\u001b[K |███████ | 149.6 MB 126 kB/s eta 1:09:30\r",
+ "\u001b[K |███████ | 149.6 MB 126 kB/s eta 1:09:30\r",
+ "\u001b[K |███████ | 149.6 MB 126 kB/s eta 1:09:30\r",
+ "\u001b[K |███████ | 149.7 MB 126 kB/s eta 1:09:30\r",
+ "\u001b[K |███████ | 149.7 MB 126 kB/s eta 1:09:30\r",
+ "\u001b[K |███████ | 149.7 MB 126 kB/s eta 1:09:30\r",
+ "\u001b[K |███████ | 149.7 MB 126 kB/s eta 1:09:30\r",
+ "\u001b[K |███████ | 149.7 MB 126 kB/s eta 1:09:30\r",
+ "\u001b[K |███████ | 149.7 MB 126 kB/s eta 1:09:30\r",
+ "\u001b[K |███████ | 149.7 MB 126 kB/s eta 1:09:30\r",
+ "\u001b[K |███████ | 149.7 MB 126 kB/s eta 1:09:30\r",
+ "\u001b[K |███████ | 149.7 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.7 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.8 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.8 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.8 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.8 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.8 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.8 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.8 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.8 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.8 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.9 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.9 MB 126 kB/s eta 1:09:29\r",
+ "\u001b[K |███████ | 149.9 MB 126 kB/s eta 1:09:28\r",
+ "\u001b[K |███████ | 149.9 MB 126 kB/s eta 1:09:28\r",
+ "\u001b[K |███████ | 149.9 MB 126 kB/s eta 1:09:28\r",
+ "\u001b[K |███████ | 149.9 MB 126 kB/s eta 1:09:28\r",
+ "\u001b[K |███████ | 149.9 MB 126 kB/s eta 1:09:28\r",
+ "\u001b[K |███████ | 149.9 MB 126 kB/s eta 1:09:28\r",
+ "\u001b[K |███████ | 149.9 MB 126 kB/s eta 1:09:28\r",
+ "\u001b[K |███████ | 149.9 MB 126 kB/s eta 1:09:28\r",
+ "\u001b[K |███████ | 150.0 MB 126 kB/s eta 1:09:28\r",
+ "\u001b[K |███████ | 150.0 MB 126 kB/s eta 1:09:28\r",
+ "\u001b[K |███████ | 150.0 MB 126 kB/s eta 1:09:28\r",
+ "\u001b[K |███████ | 150.0 MB 126 kB/s eta 1:09:28\r",
+ "\u001b[K |███████ | 150.0 MB 126 kB/s eta 1:09:27\r",
+ "\u001b[K |███████ | 150.0 MB 126 kB/s eta 1:09:27\r",
+ "\u001b[K |███████ | 150.0 MB 126 kB/s eta 1:09:27\r",
+ "\u001b[K |███████ | 150.0 MB 126 kB/s eta 1:09:27\r",
+ "\u001b[K |███████ | 150.0 MB 126 kB/s eta 1:09:27\r",
+ "\u001b[K |███████ | 150.0 MB 126 kB/s eta 1:09:27\r",
+ "\u001b[K |███████ | 150.1 MB 126 kB/s eta 1:09:27\r",
+ "\u001b[K |███████ | 150.1 MB 126 kB/s eta 1:09:27\r",
+ "\u001b[K |███████ | 150.1 MB 126 kB/s eta 1:09:27\r",
+ "\u001b[K |███████ | 150.1 MB 126 kB/s eta 1:09:27\r",
+ "\u001b[K |███████ | 150.1 MB 126 kB/s eta 1:09:27\r",
+ "\u001b[K |███████ | 150.1 MB 126 kB/s eta 1:09:27\r",
+ "\u001b[K |███████ | 150.1 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.1 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.1 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.1 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.2 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.2 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.2 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.2 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.2 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.2 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.2 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.2 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.2 MB 126 kB/s eta 1:09:26\r",
+ "\u001b[K |███████ | 150.3 MB 126 kB/s eta 1:09:25\r",
+ "\u001b[K |███████ | 150.3 MB 126 kB/s eta 1:09:25\r",
+ "\u001b[K |███████ | 150.3 MB 126 kB/s eta 1:09:25\r",
+ "\u001b[K |███████ | 150.3 MB 126 kB/s eta 1:09:25\r",
+ "\u001b[K |███████ | 150.3 MB 126 kB/s eta 1:09:25\r",
+ "\u001b[K |███████ | 150.3 MB 126 kB/s eta 1:09:25\r",
+ "\u001b[K |███████ | 150.3 MB 126 kB/s eta 1:09:25\r",
+ "\u001b[K |███████ | 150.3 MB 126 kB/s eta 1:09:25\r",
+ "\u001b[K |███████ | 150.3 MB 126 kB/s eta 1:09:25\r",
+ "\u001b[K |███████ | 150.3 MB 126 kB/s eta 1:09:25\r",
+ "\u001b[K |███████ | 150.4 MB 126 kB/s eta 1:09:25\r",
+ "\u001b[K |███████ | 150.4 MB 126 kB/s eta 1:09:25\r",
+ "\u001b[K |███████ | 150.4 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████ | 150.4 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████ | 150.4 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████ | 150.4 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████ | 150.4 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████▏ | 150.4 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████▏ | 150.4 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████▏ | 150.4 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████▏ | 150.5 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████▏ | 150.5 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████▏ | 150.5 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████▏ | 150.5 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████▏ | 150.5 MB 126 kB/s eta 1:09:24\r",
+ "\u001b[K |███████▏ | 150.5 MB 126 kB/s eta 1:09:23\r",
+ "\u001b[K |███████▏ | 150.5 MB 126 kB/s eta 1:09:23\r",
+ "\u001b[K |███████▏ | 150.5 MB 126 kB/s eta 1:09:23\r",
+ "\u001b[K |███████▏ | 150.5 MB 126 kB/s eta 1:09:23\r",
+ "\u001b[K |███████▏ | 150.5 MB 126 kB/s eta 1:09:23\r",
+ "\u001b[K |███████▏ | 150.6 MB 126 kB/s eta 1:09:23\r",
+ "\u001b[K |███████▏ | 150.6 MB 126 kB/s eta 1:09:23\r",
+ "\u001b[K |███████▏ | 150.6 MB 126 kB/s eta 1:09:23\r",
+ "\u001b[K |███████▏ | 150.6 MB 126 kB/s eta 1:09:23\r",
+ "\u001b[K |███████▏ | 150.6 MB 126 kB/s eta 1:09:23\r",
+ "\u001b[K |███████▏ | 150.6 MB 126 kB/s eta 1:09:23\r",
+ "\u001b[K |███████▏ | 150.6 MB 126 kB/s eta 1:09:23\r",
+ "\u001b[K |███████▏ | 150.6 MB 126 kB/s eta 1:09:22\r",
+ "\u001b[K |███████▏ | 150.6 MB 126 kB/s eta 1:09:22\r",
+ "\u001b[K |███████▏ | 150.7 MB 126 kB/s eta 1:09:22\r",
+ "\u001b[K |███████▏ | 150.7 MB 126 kB/s eta 1:09:22\r",
+ "\u001b[K |███████▏ | 150.7 MB 126 kB/s eta 1:09:22\r",
+ "\u001b[K |███████▏ | 150.7 MB 126 kB/s eta 1:09:22\r",
+ "\u001b[K |███████▏ | 150.7 MB 126 kB/s eta 1:09:22\r",
+ "\u001b[K |███████▏ | 150.7 MB 126 kB/s eta 1:09:22\r",
+ "\u001b[K |███████▏ | 150.7 MB 126 kB/s eta 1:09:22\r",
+ "\u001b[K |███████▏ | 150.7 MB 126 kB/s eta 1:09:22\r",
+ "\u001b[K |███████▏ | 150.7 MB 126 kB/s eta 1:09:22\r",
+ "\u001b[K |███████▏ | 150.7 MB 126 kB/s eta 1:09:22\r",
+ "\u001b[K |███████▏ | 150.8 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.8 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.8 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.8 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.8 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.8 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.8 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.8 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.8 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.8 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.9 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.9 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.9 MB 126 kB/s eta 1:09:21\r",
+ "\u001b[K |███████▏ | 150.9 MB 126 kB/s eta 1:09:20\r",
+ "\u001b[K |███████▏ | 150.9 MB 126 kB/s eta 1:09:20\r",
+ "\u001b[K |███████▏ | 150.9 MB 126 kB/s eta 1:09:20\r",
+ "\u001b[K |███████▏ | 150.9 MB 126 kB/s eta 1:09:20\r",
+ "\u001b[K |███████▏ | 150.9 MB 126 kB/s eta 1:09:20\r",
+ "\u001b[K |███████▏ | 150.9 MB 126 kB/s eta 1:09:20\r",
+ "\u001b[K |███████▏ | 150.9 MB 126 kB/s eta 1:09:20\r",
+ "\u001b[K |███████▏ | 151.0 MB 126 kB/s eta 1:09:20\r",
+ "\u001b[K |███████▏ | 151.0 MB 126 kB/s eta 1:09:20\r",
+ "\u001b[K |███████▏ | 151.0 MB 126 kB/s eta 1:09:20\r",
+ "\u001b[K |███████▏ | 151.0 MB 126 kB/s eta 1:09:20\r",
+ "\u001b[K |███████▏ | 151.0 MB 126 kB/s eta 1:09:20\r",
+ "\u001b[K |███████▏ | 151.0 MB 126 kB/s eta 1:09:19\r",
+ "\u001b[K |███████▏ | 151.0 MB 126 kB/s eta 1:09:19\r",
+ "\u001b[K |███████▏ | 151.0 MB 126 kB/s eta 1:09:19\r",
+ "\u001b[K |███████▏ | 151.0 MB 126 kB/s eta 1:09:19\r",
+ "\u001b[K |███████▏ | 151.1 MB 126 kB/s eta 1:09:19\r",
+ "\u001b[K |███████▏ | 151.1 MB 126 kB/s eta 1:09:19\r",
+ "\u001b[K |███████▏ | 151.1 MB 126 kB/s eta 1:09:19\r",
+ "\u001b[K |███████▏ | 151.1 MB 126 kB/s eta 1:09:19\r",
+ "\u001b[K |███████▏ | 151.1 MB 126 kB/s eta 1:09:19\r",
+ "\u001b[K |███████▏ | 151.1 MB 126 kB/s eta 1:09:19\r",
+ "\u001b[K |███████▏ | 151.1 MB 126 kB/s eta 1:09:19\r",
+ "\u001b[K |███████▏ | 151.1 MB 126 kB/s eta 1:09:19\r",
+ "\u001b[K |███████▏ | 151.1 MB 126 kB/s eta 1:09:18\r",
+ "\u001b[K |███████▏ | 151.1 MB 126 kB/s eta 1:09:18\r",
+ "\u001b[K |███████▏ | 151.2 MB 126 kB/s eta 1:09:18\r",
+ "\u001b[K |███████▏ | 151.2 MB 126 kB/s eta 1:09:18\r",
+ "\u001b[K |███████▏ | 151.2 MB 126 kB/s eta 1:09:18\r",
+ "\u001b[K |███████▏ | 151.2 MB 126 kB/s eta 1:09:18\r",
+ "\u001b[K |███████▏ | 151.2 MB 126 kB/s eta 1:09:18"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████▏ | 151.2 MB 126 kB/s eta 1:09:18\r",
+ "\u001b[K |███████▏ | 151.2 MB 126 kB/s eta 1:09:18\r",
+ "\u001b[K |███████▏ | 151.2 MB 126 kB/s eta 1:09:18\r",
+ "\u001b[K |███████▏ | 151.2 MB 126 kB/s eta 1:09:18\r",
+ "\u001b[K |███████▏ | 151.2 MB 126 kB/s eta 1:09:18\r",
+ "\u001b[K |███████▏ | 151.3 MB 126 kB/s eta 1:09:18\r",
+ "\u001b[K |███████▏ | 151.3 MB 126 kB/s eta 1:09:17\r",
+ "\u001b[K |███████▏ | 151.3 MB 126 kB/s eta 1:09:17\r",
+ "\u001b[K |███████▏ | 151.3 MB 126 kB/s eta 1:09:17\r",
+ "\u001b[K |███████▏ | 151.3 MB 126 kB/s eta 1:09:17\r",
+ "\u001b[K |███████▏ | 151.3 MB 126 kB/s eta 1:09:17\r",
+ "\u001b[K |███████▏ | 151.3 MB 126 kB/s eta 1:09:17\r",
+ "\u001b[K |███████▏ | 151.3 MB 126 kB/s eta 1:09:17\r",
+ "\u001b[K |███████▏ | 151.3 MB 126 kB/s eta 1:09:17\r",
+ "\u001b[K |███████▏ | 151.3 MB 126 kB/s eta 1:09:17\r",
+ "\u001b[K |███████▏ | 151.4 MB 126 kB/s eta 1:09:17\r",
+ "\u001b[K |███████▏ | 151.4 MB 126 kB/s eta 1:09:17\r",
+ "\u001b[K |███████▏ | 151.4 MB 126 kB/s eta 1:09:17\r",
+ "\u001b[K |███████▏ | 151.4 MB 126 kB/s eta 1:09:16\r",
+ "\u001b[K |███████▏ | 151.4 MB 126 kB/s eta 1:09:16\r",
+ "\u001b[K |███████▏ | 151.4 MB 126 kB/s eta 1:09:16\r",
+ "\u001b[K |███████▏ | 151.4 MB 126 kB/s eta 1:09:16\r",
+ "\u001b[K |███████▏ | 151.4 MB 126 kB/s eta 1:09:16\r",
+ "\u001b[K |███████▏ | 151.4 MB 126 kB/s eta 1:09:16\r",
+ "\u001b[K |███████▏ | 151.4 MB 126 kB/s eta 1:09:16\r",
+ "\u001b[K |███████▏ | 151.5 MB 126 kB/s eta 1:09:16\r",
+ "\u001b[K |███████▏ | 151.5 MB 126 kB/s eta 1:09:16\r",
+ "\u001b[K |███████▏ | 151.5 MB 126 kB/s eta 1:09:16\r",
+ "\u001b[K |███████▏ | 151.5 MB 126 kB/s eta 1:09:16\r",
+ "\u001b[K |███████▏ | 151.5 MB 126 kB/s eta 1:09:16\r",
+ "\u001b[K |███████▏ | 151.5 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.5 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.5 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.5 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.6 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.6 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.6 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.6 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.6 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.6 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.6 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.6 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.6 MB 126 kB/s eta 1:09:15\r",
+ "\u001b[K |███████▏ | 151.6 MB 126 kB/s eta 1:09:14\r",
+ "\u001b[K |███████▏ | 151.7 MB 126 kB/s eta 1:09:14\r",
+ "\u001b[K |███████▏ | 151.7 MB 126 kB/s eta 1:09:14\r",
+ "\u001b[K |███████▏ | 151.7 MB 126 kB/s eta 1:09:14\r",
+ "\u001b[K |███████▏ | 151.7 MB 126 kB/s eta 1:09:14\r",
+ "\u001b[K |███████▏ | 151.7 MB 126 kB/s eta 1:09:14\r",
+ "\u001b[K |███████▏ | 151.7 MB 126 kB/s eta 1:09:14\r",
+ "\u001b[K |███████▏ | 151.7 MB 126 kB/s eta 1:09:14\r",
+ "\u001b[K |███████▏ | 151.7 MB 126 kB/s eta 1:09:14\r",
+ "\u001b[K |███████▏ | 151.7 MB 126 kB/s eta 1:09:14\r",
+ "\u001b[K |███████▏ | 151.7 MB 126 kB/s eta 1:09:14\r",
+ "\u001b[K |███████▏ | 151.8 MB 126 kB/s eta 1:09:14\r",
+ "\u001b[K |███████▏ | 151.8 MB 126 kB/s eta 1:09:13\r",
+ "\u001b[K |███████▏ | 151.8 MB 126 kB/s eta 1:09:13\r",
+ "\u001b[K |███████▏ | 151.8 MB 126 kB/s eta 1:09:13\r",
+ "\u001b[K |███████▏ | 151.8 MB 126 kB/s eta 1:09:13\r",
+ "\u001b[K |███████▏ | 151.8 MB 126 kB/s eta 1:09:13\r",
+ "\u001b[K |███████▏ | 151.8 MB 126 kB/s eta 1:09:13\r",
+ "\u001b[K |███████▏ | 151.8 MB 126 kB/s eta 1:09:13\r",
+ "\u001b[K |███████▏ | 151.8 MB 126 kB/s eta 1:09:13\r",
+ "\u001b[K |███████▏ | 151.8 MB 126 kB/s eta 1:09:13\r",
+ "\u001b[K |███████▏ | 151.9 MB 126 kB/s eta 1:09:13\r",
+ "\u001b[K |███████▏ | 151.9 MB 126 kB/s eta 1:09:13\r",
+ "\u001b[K |███████▏ | 151.9 MB 126 kB/s eta 1:09:13\r",
+ "\u001b[K |███████▏ | 151.9 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 151.9 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 151.9 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 151.9 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 151.9 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 151.9 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 152.0 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 152.0 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 152.0 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 152.0 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 152.0 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 152.0 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 152.0 MB 126 kB/s eta 1:09:12\r",
+ "\u001b[K |███████▏ | 152.0 MB 126 kB/s eta 1:09:11\r",
+ "\u001b[K |███████▏ | 152.0 MB 126 kB/s eta 1:09:11\r",
+ "\u001b[K |███████▏ | 152.0 MB 126 kB/s eta 1:09:11\r",
+ "\u001b[K |███████▏ | 152.1 MB 126 kB/s eta 1:09:11\r",
+ "\u001b[K |███████▏ | 152.1 MB 126 kB/s eta 1:09:11\r",
+ "\u001b[K |███████▏ | 152.1 MB 126 kB/s eta 1:09:11\r",
+ "\u001b[K |███████▏ | 152.1 MB 126 kB/s eta 1:09:11\r",
+ "\u001b[K |███████▏ | 152.1 MB 126 kB/s eta 1:09:11\r",
+ "\u001b[K |███████▏ | 152.1 MB 126 kB/s eta 1:09:11\r",
+ "\u001b[K |███████▏ | 152.1 MB 126 kB/s eta 1:09:11\r",
+ "\u001b[K |███████▏ | 152.1 MB 126 kB/s eta 1:09:11\r",
+ "\u001b[K |███████▏ | 152.1 MB 126 kB/s eta 1:09:11\r",
+ "\u001b[K |███████▏ | 152.1 MB 126 kB/s eta 1:09:10\r",
+ "\u001b[K |███████▏ | 152.2 MB 126 kB/s eta 1:09:10\r",
+ "\u001b[K |███████▏ | 152.2 MB 126 kB/s eta 1:09:10\r",
+ "\u001b[K |███████▏ | 152.2 MB 126 kB/s eta 1:09:10\r",
+ "\u001b[K |███████▏ | 152.2 MB 126 kB/s eta 1:09:10\r",
+ "\u001b[K |███████▏ | 152.2 MB 126 kB/s eta 1:09:10\r",
+ "\u001b[K |███████▏ | 152.2 MB 126 kB/s eta 1:09:10\r",
+ "\u001b[K |███████▏ | 152.2 MB 126 kB/s eta 1:09:10\r",
+ "\u001b[K |███████▏ | 152.2 MB 126 kB/s eta 1:09:10\r",
+ "\u001b[K |███████▏ | 152.2 MB 126 kB/s eta 1:09:10\r",
+ "\u001b[K |███████▏ | 152.2 MB 126 kB/s eta 1:09:10\r",
+ "\u001b[K |███████▏ | 152.3 MB 126 kB/s eta 1:09:10\r",
+ "\u001b[K |███████▏ | 152.3 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.3 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.3 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.3 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.3 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.3 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.3 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.3 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.4 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.4 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.4 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.4 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.4 MB 126 kB/s eta 1:09:09\r",
+ "\u001b[K |███████▏ | 152.4 MB 126 kB/s eta 1:09:08\r",
+ "\u001b[K |███████▏ | 152.4 MB 126 kB/s eta 1:09:08\r",
+ "\u001b[K |███████▏ | 152.4 MB 126 kB/s eta 1:09:08\r",
+ "\u001b[K |███████▏ | 152.4 MB 126 kB/s eta 1:09:08\r",
+ "\u001b[K |███████▏ | 152.4 MB 126 kB/s eta 1:09:08\r",
+ "\u001b[K |███████▏ | 152.5 MB 126 kB/s eta 1:09:08\r",
+ "\u001b[K |███████▏ | 152.5 MB 126 kB/s eta 1:09:08\r",
+ "\u001b[K |███████▏ | 152.5 MB 126 kB/s eta 1:09:08\r",
+ "\u001b[K |███████▏ | 152.5 MB 126 kB/s eta 1:09:08\r",
+ "\u001b[K |███████▏ | 152.5 MB 126 kB/s eta 1:09:08\r",
+ "\u001b[K |███████▏ | 152.5 MB 126 kB/s eta 1:09:08\r",
+ "\u001b[K |███████▏ | 152.5 MB 126 kB/s eta 1:09:08\r",
+ "\u001b[K |███████▏ | 152.5 MB 126 kB/s eta 1:09:07\r",
+ "\u001b[K |███████▏ | 152.5 MB 126 kB/s eta 1:09:07\r",
+ "\u001b[K |███████▏ | 152.5 MB 126 kB/s eta 1:09:07\r",
+ "\u001b[K |███████▏ | 152.6 MB 126 kB/s eta 1:09:07\r",
+ "\u001b[K |███████▏ | 152.6 MB 126 kB/s eta 1:09:07\r",
+ "\u001b[K |███████▏ | 152.6 MB 126 kB/s eta 1:09:07\r",
+ "\u001b[K |███████▏ | 152.6 MB 126 kB/s eta 1:09:07\r",
+ "\u001b[K |███████▏ | 152.6 MB 126 kB/s eta 1:09:07\r",
+ "\u001b[K |███████▏ | 152.6 MB 126 kB/s eta 1:09:07\r",
+ "\u001b[K |███████▏ | 152.6 MB 126 kB/s eta 1:09:07\r",
+ "\u001b[K |███████▏ | 152.6 MB 126 kB/s eta 1:09:07\r",
+ "\u001b[K |███████▏ | 152.6 MB 126 kB/s eta 1:09:07\r",
+ "\u001b[K |███████▏ | 152.6 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▏ | 152.7 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▏ | 152.7 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▏ | 152.7 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▏ | 152.7 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▏ | 152.7 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▏ | 152.7 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▏ | 152.7 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▏ | 152.7 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▏ | 152.7 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▏ | 152.8 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▏ | 152.8 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▎ | 152.8 MB 126 kB/s eta 1:09:06\r",
+ "\u001b[K |███████▎ | 152.8 MB 126 kB/s eta 1:09:05\r",
+ "\u001b[K |███████▎ | 152.8 MB 126 kB/s eta 1:09:05\r",
+ "\u001b[K |███████▎ | 152.8 MB 126 kB/s eta 1:09:05\r",
+ "\u001b[K |███████▎ | 152.8 MB 126 kB/s eta 1:09:05\r",
+ "\u001b[K |███████▎ | 152.8 MB 126 kB/s eta 1:09:05\r",
+ "\u001b[K |███████▎ | 152.8 MB 126 kB/s eta 1:09:05\r",
+ "\u001b[K |███████▎ | 152.8 MB 126 kB/s eta 1:09:05\r",
+ "\u001b[K |███████▎ | 152.9 MB 126 kB/s eta 1:09:05\r",
+ "\u001b[K |███████▎ | 152.9 MB 126 kB/s eta 1:09:05\r",
+ "\u001b[K |███████▎ | 152.9 MB 126 kB/s eta 1:09:05\r",
+ "\u001b[K |███████▎ | 152.9 MB 126 kB/s eta 1:09:05\r",
+ "\u001b[K |███████▎ | 152.9 MB 126 kB/s eta 1:09:05\r",
+ "\u001b[K |███████▎ | 152.9 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 152.9 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 152.9 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 152.9 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 152.9 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 153.0 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 153.0 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 153.0 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 153.0 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 153.0 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 153.0 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 153.0 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 153.0 MB 126 kB/s eta 1:09:04\r",
+ "\u001b[K |███████▎ | 153.0 MB 126 kB/s eta 1:09:03\r",
+ "\u001b[K |███████▎ | 153.0 MB 126 kB/s eta 1:09:03\r",
+ "\u001b[K |███████▎ | 153.1 MB 126 kB/s eta 1:09:03\r",
+ "\u001b[K |███████▎ | 153.1 MB 126 kB/s eta 1:09:03\r",
+ "\u001b[K |███████▎ | 153.1 MB 126 kB/s eta 1:09:03\r",
+ "\u001b[K |███████▎ | 153.1 MB 126 kB/s eta 1:09:03\r",
+ "\u001b[K |███████▎ | 153.1 MB 126 kB/s eta 1:09:03\r",
+ "\u001b[K |███████▎ | 153.1 MB 126 kB/s eta 1:09:03\r",
+ "\u001b[K |███████▎ | 153.1 MB 126 kB/s eta 1:09:03\r",
+ "\u001b[K |███████▎ | 153.1 MB 126 kB/s eta 1:09:03\r",
+ "\u001b[K |███████▎ | 153.1 MB 126 kB/s eta 1:09:03\r",
+ "\u001b[K |███████▎ | 153.1 MB 126 kB/s eta 1:09:03\r",
+ "\u001b[K |███████▎ | 153.2 MB 126 kB/s eta 1:09:02\r",
+ "\u001b[K |███████▎ | 153.2 MB 126 kB/s eta 1:09:02\r",
+ "\u001b[K |███████▎ | 153.2 MB 126 kB/s eta 1:09:02\r",
+ "\u001b[K |███████▎ | 153.2 MB 126 kB/s eta 1:09:02\r",
+ "\u001b[K |███████▎ | 153.2 MB 126 kB/s eta 1:09:02\r",
+ "\u001b[K |███████▎ | 153.2 MB 126 kB/s eta 1:09:02\r",
+ "\u001b[K |███████▎ | 153.2 MB 126 kB/s eta 1:09:02\r",
+ "\u001b[K |███████▎ | 153.2 MB 126 kB/s eta 1:09:02\r",
+ "\u001b[K |███████▎ | 153.2 MB 126 kB/s eta 1:09:02\r",
+ "\u001b[K |███████▎ | 153.3 MB 126 kB/s eta 1:09:02\r",
+ "\u001b[K |███████▎ | 153.3 MB 126 kB/s eta 1:09:02\r",
+ "\u001b[K |███████▎ | 153.3 MB 126 kB/s eta 1:09:02\r",
+ "\u001b[K |███████▎ | 153.3 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.3 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.3 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.3 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.3 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.3 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.3 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.4 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.4 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.4 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.4 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.4 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.4 MB 126 kB/s eta 1:09:01\r",
+ "\u001b[K |███████▎ | 153.4 MB 126 kB/s eta 1:09:00\r",
+ "\u001b[K |███████▎ | 153.4 MB 126 kB/s eta 1:09:00\r",
+ "\u001b[K |███████▎ | 153.4 MB 126 kB/s eta 1:09:00\r",
+ "\u001b[K |███████▎ | 153.4 MB 126 kB/s eta 1:09:00\r",
+ "\u001b[K |███████▎ | 153.5 MB 126 kB/s eta 1:09:00\r",
+ "\u001b[K |███████▎ | 153.5 MB 126 kB/s eta 1:09:00\r",
+ "\u001b[K |███████▎ | 153.5 MB 126 kB/s eta 1:09:00\r",
+ "\u001b[K |███████▎ | 153.5 MB 126 kB/s eta 1:09:00\r",
+ "\u001b[K |███████▎ | 153.5 MB 126 kB/s eta 1:09:00\r",
+ "\u001b[K |███████▎ | 153.5 MB 126 kB/s eta 1:09:00\r",
+ "\u001b[K |███████▎ | 153.5 MB 126 kB/s eta 1:09:00\r",
+ "\u001b[K |███████▎ | 153.5 MB 126 kB/s eta 1:09:00\r",
+ "\u001b[K |███████▎ | 153.5 MB 126 kB/s eta 1:08:59\r",
+ "\u001b[K |███████▎ | 153.5 MB 126 kB/s eta 1:08:59\r",
+ "\u001b[K |███████▎ | 153.6 MB 126 kB/s eta 1:08:59\r",
+ "\u001b[K |███████▎ | 153.6 MB 126 kB/s eta 1:08:59\r",
+ "\u001b[K |███████▎ | 153.6 MB 126 kB/s eta 1:08:59\r",
+ "\u001b[K |███████▎ | 153.6 MB 126 kB/s eta 1:08:59\r",
+ "\u001b[K |███████▎ | 153.6 MB 126 kB/s eta 1:08:59\r",
+ "\u001b[K |███████▎ | 153.6 MB 126 kB/s eta 1:08:59\r",
+ "\u001b[K |███████▎ | 153.6 MB 126 kB/s eta 1:08:59\r",
+ "\u001b[K |███████▎ | 153.6 MB 126 kB/s eta 1:08:59\r",
+ "\u001b[K |███████▎ | 153.6 MB 126 kB/s eta 1:08:59\r",
+ "\u001b[K |███████▎ | 153.7 MB 126 kB/s eta 1:08:59\r",
+ "\u001b[K |███████▎ | 153.7 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.7 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.7 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.7 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.7 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.7 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.7 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.7 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.7 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.8 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.8 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.8 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.8 MB 126 kB/s eta 1:08:58\r",
+ "\u001b[K |███████▎ | 153.8 MB 126 kB/s eta 1:08:57\r",
+ "\u001b[K |███████▎ | 153.8 MB 126 kB/s eta 1:08:57\r",
+ "\u001b[K |███████▎ | 153.8 MB 126 kB/s eta 1:08:57\r",
+ "\u001b[K |███████▎ | 153.8 MB 126 kB/s eta 1:08:57\r",
+ "\u001b[K |███████▎ | 153.8 MB 126 kB/s eta 1:08:57"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████▎ | 153.8 MB 126 kB/s eta 1:08:57\r",
+ "\u001b[K |███████▎ | 153.9 MB 126 kB/s eta 1:08:57\r",
+ "\u001b[K |███████▎ | 153.9 MB 126 kB/s eta 1:08:57\r",
+ "\u001b[K |███████▎ | 153.9 MB 126 kB/s eta 1:08:57\r",
+ "\u001b[K |███████▎ | 153.9 MB 126 kB/s eta 1:08:57\r",
+ "\u001b[K |███████▎ | 153.9 MB 126 kB/s eta 1:08:57\r",
+ "\u001b[K |███████▎ | 153.9 MB 126 kB/s eta 1:08:57\r",
+ "\u001b[K |███████▎ | 153.9 MB 126 kB/s eta 1:08:56\r",
+ "\u001b[K |███████▎ | 153.9 MB 126 kB/s eta 1:08:56\r",
+ "\u001b[K |███████▎ | 153.9 MB 126 kB/s eta 1:08:56\r",
+ "\u001b[K |███████▎ | 153.9 MB 126 kB/s eta 1:08:56\r",
+ "\u001b[K |███████▎ | 154.0 MB 126 kB/s eta 1:08:56\r",
+ "\u001b[K |███████▎ | 154.0 MB 126 kB/s eta 1:08:56\r",
+ "\u001b[K |███████▎ | 154.0 MB 126 kB/s eta 1:08:56\r",
+ "\u001b[K |███████▎ | 154.0 MB 126 kB/s eta 1:08:56\r",
+ "\u001b[K |███████▎ | 154.0 MB 126 kB/s eta 1:08:56\r",
+ "\u001b[K |███████▎ | 154.0 MB 126 kB/s eta 1:08:56\r",
+ "\u001b[K |███████▎ | 154.0 MB 126 kB/s eta 1:08:56\r",
+ "\u001b[K |███████▎ | 154.0 MB 126 kB/s eta 1:08:56\r",
+ "\u001b[K |███████▎ | 154.0 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.1 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.1 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.1 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.1 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.1 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.1 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.1 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.1 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.1 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.1 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.2 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.2 MB 126 kB/s eta 1:08:55\r",
+ "\u001b[K |███████▎ | 154.2 MB 126 kB/s eta 1:08:54\r",
+ "\u001b[K |███████▎ | 154.2 MB 126 kB/s eta 1:08:54\r",
+ "\u001b[K |███████▎ | 154.2 MB 126 kB/s eta 1:08:54\r",
+ "\u001b[K |███████▎ | 154.2 MB 126 kB/s eta 1:08:54\r",
+ "\u001b[K |███████▎ | 154.2 MB 126 kB/s eta 1:08:54\r",
+ "\u001b[K |███████▎ | 154.2 MB 126 kB/s eta 1:08:54\r",
+ "\u001b[K |███████▎ | 154.2 MB 126 kB/s eta 1:08:54\r",
+ "\u001b[K |███████▎ | 154.2 MB 126 kB/s eta 1:08:54\r",
+ "\u001b[K |███████▎ | 154.3 MB 126 kB/s eta 1:08:54\r",
+ "\u001b[K |███████▎ | 154.3 MB 126 kB/s eta 1:08:54\r",
+ "\u001b[K |███████▎ | 154.3 MB 126 kB/s eta 1:08:54\r",
+ "\u001b[K |███████▎ | 154.3 MB 126 kB/s eta 1:08:54\r",
+ "\u001b[K |███████▎ | 154.3 MB 126 kB/s eta 1:08:53\r",
+ "\u001b[K |███████▎ | 154.3 MB 126 kB/s eta 1:08:53\r",
+ "\u001b[K |███████▎ | 154.3 MB 126 kB/s eta 1:08:53\r",
+ "\u001b[K |███████▎ | 154.3 MB 126 kB/s eta 1:08:53\r",
+ "\u001b[K |███████▎ | 154.3 MB 126 kB/s eta 1:08:53\r",
+ "\u001b[K |███████▎ | 154.3 MB 126 kB/s eta 1:08:53\r",
+ "\u001b[K |███████▎ | 154.4 MB 126 kB/s eta 1:08:53\r",
+ "\u001b[K |███████▎ | 154.4 MB 126 kB/s eta 1:08:53\r",
+ "\u001b[K |███████▎ | 154.4 MB 126 kB/s eta 1:08:53\r",
+ "\u001b[K |███████▎ | 154.4 MB 126 kB/s eta 1:08:53\r",
+ "\u001b[K |███████▎ | 154.4 MB 126 kB/s eta 1:08:53\r",
+ "\u001b[K |███████▎ | 154.4 MB 126 kB/s eta 1:08:53\r",
+ "\u001b[K |███████▎ | 154.4 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.4 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.4 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.4 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.5 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.5 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.5 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.5 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.5 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.5 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.5 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.5 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.5 MB 126 kB/s eta 1:08:52\r",
+ "\u001b[K |███████▎ | 154.6 MB 126 kB/s eta 1:08:51\r",
+ "\u001b[K |███████▎ | 154.6 MB 126 kB/s eta 1:08:51\r",
+ "\u001b[K |███████▎ | 154.6 MB 126 kB/s eta 1:08:51\r",
+ "\u001b[K |███████▎ | 154.6 MB 126 kB/s eta 1:08:51\r",
+ "\u001b[K |███████▎ | 154.6 MB 126 kB/s eta 1:08:51\r",
+ "\u001b[K |███████▎ | 154.6 MB 126 kB/s eta 1:08:51\r",
+ "\u001b[K |███████▎ | 154.6 MB 126 kB/s eta 1:08:51\r",
+ "\u001b[K |███████▎ | 154.6 MB 126 kB/s eta 1:08:51\r",
+ "\u001b[K |███████▎ | 154.6 MB 126 kB/s eta 1:08:51\r",
+ "\u001b[K |███████▎ | 154.6 MB 126 kB/s eta 1:08:51\r",
+ "\u001b[K |███████▎ | 154.7 MB 126 kB/s eta 1:08:51\r",
+ "\u001b[K |███████▎ | 154.7 MB 126 kB/s eta 1:08:51\r",
+ "\u001b[K |███████▎ | 154.7 MB 126 kB/s eta 1:08:50\r",
+ "\u001b[K |███████▎ | 154.7 MB 126 kB/s eta 1:08:50\r",
+ "\u001b[K |███████▎ | 154.7 MB 126 kB/s eta 1:08:50\r",
+ "\u001b[K |███████▎ | 154.7 MB 126 kB/s eta 1:08:50\r",
+ "\u001b[K |███████▎ | 154.7 MB 126 kB/s eta 1:08:50\r",
+ "\u001b[K |███████▎ | 154.7 MB 126 kB/s eta 1:08:50\r",
+ "\u001b[K |███████▎ | 154.7 MB 126 kB/s eta 1:08:50\r",
+ "\u001b[K |███████▎ | 154.7 MB 126 kB/s eta 1:08:50\r",
+ "\u001b[K |███████▎ | 154.8 MB 126 kB/s eta 1:08:50\r",
+ "\u001b[K |███████▎ | 154.8 MB 126 kB/s eta 1:08:50\r",
+ "\u001b[K |███████▎ | 154.8 MB 126 kB/s eta 1:08:50\r",
+ "\u001b[K |███████▎ | 154.8 MB 126 kB/s eta 1:08:50\r",
+ "\u001b[K |███████▎ | 154.8 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.8 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.8 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.8 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.8 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.8 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.9 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.9 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.9 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.9 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.9 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.9 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.9 MB 126 kB/s eta 1:08:49\r",
+ "\u001b[K |███████▎ | 154.9 MB 126 kB/s eta 1:08:48\r",
+ "\u001b[K |███████▎ | 154.9 MB 126 kB/s eta 1:08:48\r",
+ "\u001b[K |███████▎ | 155.0 MB 126 kB/s eta 1:08:48\r",
+ "\u001b[K |███████▎ | 155.0 MB 126 kB/s eta 1:08:48\r",
+ "\u001b[K |███████▎ | 155.0 MB 126 kB/s eta 1:08:48\r",
+ "\u001b[K |███████▎ | 155.0 MB 126 kB/s eta 1:08:48\r",
+ "\u001b[K |███████▎ | 155.0 MB 126 kB/s eta 1:08:48\r",
+ "\u001b[K |███████▎ | 155.0 MB 126 kB/s eta 1:08:48\r",
+ "\u001b[K |███████▎ | 155.0 MB 126 kB/s eta 1:08:48\r",
+ "\u001b[K |███████▎ | 155.0 MB 126 kB/s eta 1:08:48\r",
+ "\u001b[K |███████▎ | 155.0 MB 126 kB/s eta 1:08:48\r",
+ "\u001b[K |███████▎ | 155.0 MB 126 kB/s eta 1:08:48\r",
+ "\u001b[K |███████▎ | 155.1 MB 126 kB/s eta 1:08:47\r",
+ "\u001b[K |███████▎ | 155.1 MB 126 kB/s eta 1:08:47\r",
+ "\u001b[K |███████▎ | 155.1 MB 126 kB/s eta 1:08:47\r",
+ "\u001b[K |███████▎ | 155.1 MB 126 kB/s eta 1:08:47\r",
+ "\u001b[K |███████▎ | 155.1 MB 126 kB/s eta 1:08:47\r",
+ "\u001b[K |███████▎ | 155.1 MB 126 kB/s eta 1:08:47\r",
+ "\u001b[K |███████▎ | 155.1 MB 126 kB/s eta 1:08:47\r",
+ "\u001b[K |███████▍ | 155.1 MB 126 kB/s eta 1:08:47\r",
+ "\u001b[K |███████▍ | 155.1 MB 126 kB/s eta 1:08:47\r",
+ "\u001b[K |███████▍ | 155.1 MB 126 kB/s eta 1:08:47\r",
+ "\u001b[K |███████▍ | 155.2 MB 126 kB/s eta 1:08:47\r",
+ "\u001b[K |███████▍ | 155.2 MB 126 kB/s eta 1:08:47\r",
+ "\u001b[K |███████▍ | 155.2 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.2 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.2 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.2 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.2 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.2 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.2 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.2 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.3 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.3 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.3 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.3 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.3 MB 126 kB/s eta 1:08:46\r",
+ "\u001b[K |███████▍ | 155.3 MB 126 kB/s eta 1:08:45\r",
+ "\u001b[K |███████▍ | 155.3 MB 126 kB/s eta 1:08:45\r",
+ "\u001b[K |███████▍ | 155.3 MB 126 kB/s eta 1:08:45\r",
+ "\u001b[K |███████▍ | 155.3 MB 126 kB/s eta 1:08:45\r",
+ "\u001b[K |███████▍ | 155.4 MB 126 kB/s eta 1:08:45\r",
+ "\u001b[K |███████▍ | 155.4 MB 126 kB/s eta 1:08:45\r",
+ "\u001b[K |███████▍ | 155.4 MB 126 kB/s eta 1:08:45\r",
+ "\u001b[K |███████▍ | 155.4 MB 126 kB/s eta 1:08:45\r",
+ "\u001b[K |███████▍ | 155.4 MB 126 kB/s eta 1:08:45\r",
+ "\u001b[K |███████▍ | 155.4 MB 126 kB/s eta 1:08:45\r",
+ "\u001b[K |███████▍ | 155.4 MB 126 kB/s eta 1:08:45\r",
+ "\u001b[K |███████▍ | 155.4 MB 126 kB/s eta 1:08:45\r",
+ "\u001b[K |███████▍ | 155.4 MB 126 kB/s eta 1:08:44\r",
+ "\u001b[K |███████▍ | 155.4 MB 126 kB/s eta 1:08:44\r",
+ "\u001b[K |███████▍ | 155.5 MB 126 kB/s eta 1:08:44\r",
+ "\u001b[K |███████▍ | 155.5 MB 126 kB/s eta 1:08:44\r",
+ "\u001b[K |███████▍ | 155.5 MB 126 kB/s eta 1:08:44\r",
+ "\u001b[K |███████▍ | 155.5 MB 126 kB/s eta 1:08:44\r",
+ "\u001b[K |███████▍ | 155.5 MB 126 kB/s eta 1:08:44\r",
+ "\u001b[K |███████▍ | 155.5 MB 126 kB/s eta 1:08:44\r",
+ "\u001b[K |███████▍ | 155.5 MB 126 kB/s eta 1:08:44\r",
+ "\u001b[K |███████▍ | 155.5 MB 126 kB/s eta 1:08:44\r",
+ "\u001b[K |███████▍ | 155.5 MB 126 kB/s eta 1:08:44\r",
+ "\u001b[K |███████▍ | 155.5 MB 126 kB/s eta 1:08:44\r",
+ "\u001b[K |███████▍ | 155.6 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.6 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.6 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.6 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.6 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.6 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.6 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.6 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.6 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.6 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.7 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.7 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.7 MB 126 kB/s eta 1:08:43\r",
+ "\u001b[K |███████▍ | 155.7 MB 126 kB/s eta 1:08:42\r",
+ "\u001b[K |███████▍ | 155.7 MB 126 kB/s eta 1:08:42\r",
+ "\u001b[K |███████▍ | 155.7 MB 126 kB/s eta 1:08:42\r",
+ "\u001b[K |███████▍ | 155.7 MB 126 kB/s eta 1:08:42\r",
+ "\u001b[K |███████▍ | 155.7 MB 126 kB/s eta 1:08:42\r",
+ "\u001b[K |███████▍ | 155.7 MB 126 kB/s eta 1:08:42\r",
+ "\u001b[K |███████▍ | 155.8 MB 126 kB/s eta 1:08:42\r",
+ "\u001b[K |███████▍ | 155.8 MB 126 kB/s eta 1:08:42\r",
+ "\u001b[K |███████▍ | 155.8 MB 126 kB/s eta 1:08:42\r",
+ "\u001b[K |███████▍ | 155.8 MB 126 kB/s eta 1:08:42\r",
+ "\u001b[K |███████▍ | 155.8 MB 126 kB/s eta 1:08:42\r",
+ "\u001b[K |███████▍ | 155.8 MB 126 kB/s eta 1:08:42\r",
+ "\u001b[K |███████▍ | 155.8 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.8 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.8 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.8 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.9 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.9 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.9 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.9 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.9 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.9 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.9 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.9 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.9 MB 126 kB/s eta 1:08:41\r",
+ "\u001b[K |███████▍ | 155.9 MB 126 kB/s eta 1:08:40\r",
+ "\u001b[K |███████▍ | 156.0 MB 126 kB/s eta 1:08:40\r",
+ "\u001b[K |███████▍ | 156.0 MB 126 kB/s eta 1:08:40\r",
+ "\u001b[K |███████▍ | 156.0 MB 126 kB/s eta 1:08:40\r",
+ "\u001b[K |███████▍ | 156.0 MB 126 kB/s eta 1:08:40\r",
+ "\u001b[K |███████▍ | 156.0 MB 126 kB/s eta 1:08:40\r",
+ "\u001b[K |███████▍ | 156.0 MB 126 kB/s eta 1:08:40\r",
+ "\u001b[K |███████▍ | 156.0 MB 126 kB/s eta 1:08:40\r",
+ "\u001b[K |███████▍ | 156.0 MB 126 kB/s eta 1:08:40\r",
+ "\u001b[K |███████▍ | 156.0 MB 126 kB/s eta 1:08:40\r",
+ "\u001b[K |███████▍ | 156.0 MB 126 kB/s eta 1:08:40\r",
+ "\u001b[K |███████▍ | 156.1 MB 126 kB/s eta 1:08:40\r",
+ "\u001b[K |███████▍ | 156.1 MB 126 kB/s eta 1:08:39\r",
+ "\u001b[K |███████▍ | 156.1 MB 126 kB/s eta 1:08:39\r",
+ "\u001b[K |███████▍ | 156.1 MB 126 kB/s eta 1:08:39\r",
+ "\u001b[K |███████▍ | 156.1 MB 126 kB/s eta 1:08:39\r",
+ "\u001b[K |███████▍ | 156.1 MB 126 kB/s eta 1:08:39\r",
+ "\u001b[K |███████▍ | 156.1 MB 126 kB/s eta 1:08:39\r",
+ "\u001b[K |███████▍ | 156.1 MB 126 kB/s eta 1:08:39\r",
+ "\u001b[K |███████▍ | 156.1 MB 126 kB/s eta 1:08:39\r",
+ "\u001b[K |███████▍ | 156.1 MB 126 kB/s eta 1:08:39\r",
+ "\u001b[K |███████▍ | 156.2 MB 126 kB/s eta 1:08:39\r",
+ "\u001b[K |███████▍ | 156.2 MB 126 kB/s eta 1:08:39\r",
+ "\u001b[K |███████▍ | 156.2 MB 126 kB/s eta 1:08:39\r",
+ "\u001b[K |███████▍ | 156.2 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.2 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.2 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.2 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.2 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.2 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.3 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.3 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.3 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.3 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.3 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.3 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.3 MB 126 kB/s eta 1:08:38\r",
+ "\u001b[K |███████▍ | 156.3 MB 126 kB/s eta 1:08:37\r",
+ "\u001b[K |███████▍ | 156.3 MB 126 kB/s eta 1:08:37"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████▍ | 156.3 MB 126 kB/s eta 1:08:37\r",
+ "\u001b[K |███████▍ | 156.4 MB 126 kB/s eta 1:08:37\r",
+ "\u001b[K |███████▍ | 156.4 MB 126 kB/s eta 1:08:37\r",
+ "\u001b[K |███████▍ | 156.4 MB 126 kB/s eta 1:08:37\r",
+ "\u001b[K |███████▍ | 156.4 MB 126 kB/s eta 1:08:37\r",
+ "\u001b[K |███████▍ | 156.4 MB 126 kB/s eta 1:08:37\r",
+ "\u001b[K |███████▍ | 156.4 MB 126 kB/s eta 1:08:37\r",
+ "\u001b[K |███████▍ | 156.4 MB 126 kB/s eta 1:08:37\r",
+ "\u001b[K |███████▍ | 156.4 MB 126 kB/s eta 1:08:37\r",
+ "\u001b[K |███████▍ | 156.4 MB 126 kB/s eta 1:08:37\r",
+ "\u001b[K |███████▍ | 156.4 MB 126 kB/s eta 1:08:36\r",
+ "\u001b[K |███████▍ | 156.5 MB 126 kB/s eta 1:08:36\r",
+ "\u001b[K |███████▍ | 156.5 MB 126 kB/s eta 1:08:36\r",
+ "\u001b[K |███████▍ | 156.5 MB 126 kB/s eta 1:08:36\r",
+ "\u001b[K |███████▍ | 156.5 MB 126 kB/s eta 1:08:36\r",
+ "\u001b[K |███████▍ | 156.5 MB 126 kB/s eta 1:08:36\r",
+ "\u001b[K |███████▍ | 156.5 MB 126 kB/s eta 1:08:36\r",
+ "\u001b[K |███████▍ | 156.5 MB 126 kB/s eta 1:08:36\r",
+ "\u001b[K |███████▍ | 156.5 MB 126 kB/s eta 1:08:36\r",
+ "\u001b[K |███████▍ | 156.5 MB 126 kB/s eta 1:08:36\r",
+ "\u001b[K |███████▍ | 156.5 MB 126 kB/s eta 1:08:36\r",
+ "\u001b[K |███████▍ | 156.6 MB 126 kB/s eta 1:08:36\r",
+ "\u001b[K |███████▍ | 156.6 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.6 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.6 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.6 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.6 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.6 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.6 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.6 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.7 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.7 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.7 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.7 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.7 MB 126 kB/s eta 1:08:35\r",
+ "\u001b[K |███████▍ | 156.7 MB 126 kB/s eta 1:08:34\r",
+ "\u001b[K |███████▍ | 156.7 MB 126 kB/s eta 1:08:34\r",
+ "\u001b[K |███████▍ | 156.7 MB 126 kB/s eta 1:08:34\r",
+ "\u001b[K |███████▍ | 156.7 MB 126 kB/s eta 1:08:34\r",
+ "\u001b[K |███████▍ | 156.7 MB 126 kB/s eta 1:08:34\r",
+ "\u001b[K |███████▍ | 156.8 MB 126 kB/s eta 1:08:34\r",
+ "\u001b[K |███████▍ | 156.8 MB 126 kB/s eta 1:08:34\r",
+ "\u001b[K |███████▍ | 156.8 MB 126 kB/s eta 1:08:34\r",
+ "\u001b[K |███████▍ | 156.8 MB 126 kB/s eta 1:08:34\r",
+ "\u001b[K |███████▍ | 156.8 MB 126 kB/s eta 1:08:34\r",
+ "\u001b[K |███████▍ | 156.8 MB 126 kB/s eta 1:08:34\r",
+ "\u001b[K |███████▍ | 156.8 MB 126 kB/s eta 1:08:34\r",
+ "\u001b[K |███████▍ | 156.8 MB 126 kB/s eta 1:08:33\r",
+ "\u001b[K |███████▍ | 156.8 MB 126 kB/s eta 1:08:33\r",
+ "\u001b[K |███████▍ | 156.8 MB 126 kB/s eta 1:08:33\r",
+ "\u001b[K |███████▍ | 156.9 MB 126 kB/s eta 1:08:33\r",
+ "\u001b[K |███████▍ | 156.9 MB 126 kB/s eta 1:08:33\r",
+ "\u001b[K |███████▍ | 156.9 MB 126 kB/s eta 1:08:33\r",
+ "\u001b[K |███████▍ | 156.9 MB 126 kB/s eta 1:08:33\r",
+ "\u001b[K |███████▍ | 156.9 MB 126 kB/s eta 1:08:33\r",
+ "\u001b[K |███████▍ | 156.9 MB 126 kB/s eta 1:08:33\r",
+ "\u001b[K |███████▍ | 156.9 MB 126 kB/s eta 1:08:33\r",
+ "\u001b[K |███████▍ | 156.9 MB 126 kB/s eta 1:08:33\r",
+ "\u001b[K |███████▍ | 156.9 MB 126 kB/s eta 1:08:33\r",
+ "\u001b[K |███████▍ | 156.9 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.0 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.0 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.0 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.0 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.0 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.0 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.0 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.0 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.0 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.1 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.1 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.1 MB 126 kB/s eta 1:08:32\r",
+ "\u001b[K |███████▍ | 157.1 MB 126 kB/s eta 1:08:31\r",
+ "\u001b[K |███████▍ | 157.1 MB 126 kB/s eta 1:08:31\r",
+ "\u001b[K |███████▍ | 157.1 MB 126 kB/s eta 1:08:31\r",
+ "\u001b[K |███████▍ | 157.1 MB 126 kB/s eta 1:08:31\r",
+ "\u001b[K |███████▍ | 157.1 MB 126 kB/s eta 1:08:31\r",
+ "\u001b[K |███████▍ | 157.1 MB 126 kB/s eta 1:08:31\r",
+ "\u001b[K |███████▍ | 157.1 MB 126 kB/s eta 1:08:31\r",
+ "\u001b[K |███████▍ | 157.2 MB 126 kB/s eta 1:08:31\r",
+ "\u001b[K |███████▍ | 157.2 MB 126 kB/s eta 1:08:31\r",
+ "\u001b[K |███████▍ | 157.2 MB 126 kB/s eta 1:08:31\r",
+ "\u001b[K |███████▍ | 157.2 MB 126 kB/s eta 1:08:31\r",
+ "\u001b[K |███████▍ | 157.2 MB 126 kB/s eta 1:08:31\r",
+ "\u001b[K |███████▍ | 157.2 MB 126 kB/s eta 1:08:30\r",
+ "\u001b[K |███████▍ | 157.2 MB 126 kB/s eta 1:08:30\r",
+ "\u001b[K |███████▍ | 157.2 MB 126 kB/s eta 1:08:30\r",
+ "\u001b[K |███████▍ | 157.2 MB 126 kB/s eta 1:08:30\r",
+ "\u001b[K |███████▍ | 157.2 MB 126 kB/s eta 1:08:30\r",
+ "\u001b[K |███████▍ | 157.3 MB 126 kB/s eta 1:08:30\r",
+ "\u001b[K |███████▍ | 157.3 MB 126 kB/s eta 1:08:30\r",
+ "\u001b[K |███████▍ | 157.3 MB 126 kB/s eta 1:08:30\r",
+ "\u001b[K |███████▍ | 157.3 MB 126 kB/s eta 1:08:30\r",
+ "\u001b[K |███████▍ | 157.3 MB 126 kB/s eta 1:08:30\r",
+ "\u001b[K |███████▍ | 157.3 MB 126 kB/s eta 1:08:30\r",
+ "\u001b[K |███████▍ | 157.3 MB 126 kB/s eta 1:08:30\r",
+ "\u001b[K |███████▍ | 157.3 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.3 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.3 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.4 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.4 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.4 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.4 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.4 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.4 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.4 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.4 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.4 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.5 MB 126 kB/s eta 1:08:29\r",
+ "\u001b[K |███████▍ | 157.5 MB 126 kB/s eta 1:08:28\r",
+ "\u001b[K |███████▌ | 157.5 MB 126 kB/s eta 1:08:28\r",
+ "\u001b[K |███████▌ | 157.5 MB 126 kB/s eta 1:08:28\r",
+ "\u001b[K |███████▌ | 157.5 MB 126 kB/s eta 1:08:28\r",
+ "\u001b[K |███████▌ | 157.5 MB 126 kB/s eta 1:08:28\r",
+ "\u001b[K |███████▌ | 157.5 MB 126 kB/s eta 1:08:28\r",
+ "\u001b[K |███████▌ | 157.5 MB 126 kB/s eta 1:08:28\r",
+ "\u001b[K |███████▌ | 157.5 MB 126 kB/s eta 1:08:28\r",
+ "\u001b[K |███████▌ | 157.5 MB 126 kB/s eta 1:08:28\r",
+ "\u001b[K |███████▌ | 157.6 MB 126 kB/s eta 1:08:28\r",
+ "\u001b[K |███████▌ | 157.6 MB 126 kB/s eta 1:08:28\r",
+ "\u001b[K |███████▌ | 157.6 MB 126 kB/s eta 1:08:28\r",
+ "\u001b[K |███████▌ | 157.6 MB 126 kB/s eta 1:08:27\r",
+ "\u001b[K |███████▌ | 157.6 MB 126 kB/s eta 1:08:27\r",
+ "\u001b[K |███████▌ | 157.6 MB 126 kB/s eta 1:08:27\r",
+ "\u001b[K |███████▌ | 157.6 MB 126 kB/s eta 1:08:27\r",
+ "\u001b[K |███████▌ | 157.6 MB 126 kB/s eta 1:08:27\r",
+ "\u001b[K |███████▌ | 157.6 MB 126 kB/s eta 1:08:27\r",
+ "\u001b[K |███████▌ | 157.6 MB 126 kB/s eta 1:08:27\r",
+ "\u001b[K |███████▌ | 157.7 MB 126 kB/s eta 1:08:27\r",
+ "\u001b[K |███████▌ | 157.7 MB 126 kB/s eta 1:08:27\r",
+ "\u001b[K |███████▌ | 157.7 MB 126 kB/s eta 1:08:27\r",
+ "\u001b[K |███████▌ | 157.7 MB 126 kB/s eta 1:08:27\r",
+ "\u001b[K |███████▌ | 157.7 MB 126 kB/s eta 1:08:27\r",
+ "\u001b[K |███████▌ | 157.7 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.7 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.7 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.7 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.7 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.8 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.8 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.8 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.8 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.8 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.8 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.8 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.8 MB 126 kB/s eta 1:08:26\r",
+ "\u001b[K |███████▌ | 157.8 MB 126 kB/s eta 1:08:25\r",
+ "\u001b[K |███████▌ | 157.8 MB 126 kB/s eta 1:08:25\r",
+ "\u001b[K |███████▌ | 157.9 MB 126 kB/s eta 1:08:25\r",
+ "\u001b[K |███████▌ | 157.9 MB 126 kB/s eta 1:08:25\r",
+ "\u001b[K |███████▌ | 157.9 MB 126 kB/s eta 1:08:25\r",
+ "\u001b[K |███████▌ | 157.9 MB 126 kB/s eta 1:08:25\r",
+ "\u001b[K |███████▌ | 157.9 MB 126 kB/s eta 1:08:25\r",
+ "\u001b[K |███████▌ | 157.9 MB 126 kB/s eta 1:08:25\r",
+ "\u001b[K |███████▌ | 157.9 MB 126 kB/s eta 1:08:25\r",
+ "\u001b[K |███████▌ | 157.9 MB 126 kB/s eta 1:08:25\r",
+ "\u001b[K |███████▌ | 157.9 MB 126 kB/s eta 1:08:25\r",
+ "\u001b[K |███████▌ | 158.0 MB 126 kB/s eta 1:08:25\r",
+ "\u001b[K |███████▌ | 158.0 MB 126 kB/s eta 1:08:24\r",
+ "\u001b[K |███████▌ | 158.0 MB 126 kB/s eta 1:08:24\r",
+ "\u001b[K |███████▌ | 158.0 MB 126 kB/s eta 1:08:24\r",
+ "\u001b[K |███████▌ | 158.0 MB 126 kB/s eta 1:08:24\r",
+ "\u001b[K |███████▌ | 158.0 MB 126 kB/s eta 1:08:24\r",
+ "\u001b[K |███████▌ | 158.0 MB 126 kB/s eta 1:08:24\r",
+ "\u001b[K |███████▌ | 158.0 MB 126 kB/s eta 1:08:24\r",
+ "\u001b[K |███████▌ | 158.0 MB 126 kB/s eta 1:08:24\r",
+ "\u001b[K |███████▌ | 158.0 MB 126 kB/s eta 1:08:24\r",
+ "\u001b[K |███████▌ | 158.1 MB 126 kB/s eta 1:08:24\r",
+ "\u001b[K |███████▌ | 158.1 MB 126 kB/s eta 1:08:24\r",
+ "\u001b[K |███████▌ | 158.1 MB 126 kB/s eta 1:08:24\r",
+ "\u001b[K |███████▌ | 158.1 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.1 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.1 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.1 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.1 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.1 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.1 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.2 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.2 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.2 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.2 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.2 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.2 MB 126 kB/s eta 1:08:23\r",
+ "\u001b[K |███████▌ | 158.2 MB 126 kB/s eta 1:08:22\r",
+ "\u001b[K |███████▌ | 158.2 MB 126 kB/s eta 1:08:22\r",
+ "\u001b[K |███████▌ | 158.2 MB 126 kB/s eta 1:08:22\r",
+ "\u001b[K |███████▌ | 158.2 MB 126 kB/s eta 1:08:22\r",
+ "\u001b[K |███████▌ | 158.3 MB 126 kB/s eta 1:08:22"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████▌ | 158.3 MB 126 kB/s eta 1:08:22\r",
+ "\u001b[K |███████▌ | 158.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 158.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▌ | 159.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 159.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.5 MB 76.8 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████▋ | 160.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 160.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 161.9 MB 76.8 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████▋ | 162.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▋ | 162.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 162.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 163.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.3 MB 76.8 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████▊ | 164.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▊ | 164.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 164.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 165.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.8 MB 76.8 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████▉ | 166.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |███████▉ | 166.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 166.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 166.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 166.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 166.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 166.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 166.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 166.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 166.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.5 MB 76.8 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████ | 167.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 167.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.6 MB 76.8 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████ | 168.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 168.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 169.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.7 MB 76.8 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████ | 170.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 170.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████ | 171.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 171.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 172.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.3 MB 76.8 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████▏ | 173.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▏ | 173.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 173.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 173.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 173.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 174.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.4 MB 76.8 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████▎ | 175.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 175.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▎ | 176.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 176.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.9 MB 76.8 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████▍ | 177.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 177.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▍ | 178.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 178.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.3 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.4 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.5 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.6 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.7 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.8 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 179.9 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.0 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.1 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.2 MB 76.8 MB/s eta 0:00:07\r",
+ "\u001b[K |████████▌ | 180.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.4 MB 30.0 MB/s eta 0:00:17"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████▌ | 180.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 180.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 181.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▌ | 181.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 181.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.1 MB 30.0 MB/s eta 0:00:17"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████▋ | 182.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 182.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▋ | 183.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.7 MB 30.0 MB/s eta 0:00:17"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████▊ | 183.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 183.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 184.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.2 MB 30.0 MB/s eta 0:00:17"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████▊ | 185.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▊ | 185.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 185.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 186.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.5 MB 30.0 MB/s eta 0:00:17"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████▉ | 187.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 187.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 188.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 188.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 188.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 188.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 188.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 188.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |████████▉ | 188.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 188.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.4 MB 30.0 MB/s eta 0:00:17"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████ | 189.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 189.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 190.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.4 MB 30.0 MB/s eta 0:00:17"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████ | 191.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 191.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████ | 192.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.9 MB 30.0 MB/s eta 0:00:17"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████▏ | 192.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 192.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 193.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 194.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 195.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 195.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 195.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 195.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 195.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 195.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 195.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 195.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 195.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 195.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▏ | 195.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.3 MB 30.0 MB/s eta 0:00:17"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████▎ | 195.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.8 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 195.9 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.0 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.1 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.2 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.3 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.4 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.5 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.6 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.7 MB 30.0 MB/s eta 0:00:17\r",
+ "\u001b[K |█████████▎ | 196.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 196.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.1 MB 30.0 MB/s eta 0:00:16"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████▎ | 197.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▎ | 197.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.7 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.8 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 197.9 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.0 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.1 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.2 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.3 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.4 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.5 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.6 MB 30.0 MB/s eta 0:00:16\r",
+ "\u001b[K |█████████▍ | 198.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.9 MB 83.7 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████▍ | 198.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 198.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▍ | 199.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 199.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.4 MB 83.7 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████▌ | 200.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.9 MB 83.7 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████▌ | 200.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 200.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.9 MB 83.7 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████▌ | 201.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 201.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▌ | 202.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ "
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ " | 202.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 202.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 203.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▋ | 204.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.6 MB 83.7 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████▊ | 204.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 204.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 205.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.6 MB 83.7 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████▊ | 206.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▊ | 206.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 206.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 206.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 206.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 206.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 206.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 206.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 206.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 206.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 206.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 206.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 206.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 206.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 207.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.9 MB 83.7 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████▉ | 208.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 208.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████▉ | 209.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 209.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.4 MB 83.7 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████ | 210.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 210.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 211.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.5 MB 83.7 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████ | 212.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 212.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████ | 213.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 213.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 213.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 213.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 213.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 213.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 213.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 213.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.4 MB 83.7 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████▏ | 214.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 214.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.4 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.5 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.6 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.7 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.8 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 215.9 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.0 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.1 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.2 MB 83.7 "
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▏ | 216.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▎ | 216.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▎ | 216.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▎ | 216.2 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▎ | 216.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▎ | 216.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▎ | 216.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▎ | 216.3 MB 83.7 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████▎ | 216.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 216.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.9 MB 71.1 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████▎ | 217.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 217.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▎ | 218.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 218.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.6 MB 71.1 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████▍ | 219.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 219.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▍ | 220.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 220.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 220.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 220.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 221.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.0 MB 71.1 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████▌ | 222.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 222.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▌ | 223.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.6 MB 71.1 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████▋ | 223.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 223.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 224.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.3 MB 71.1 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████▋ | 225.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▋ | 225.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 225.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 226.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.5 MB 71.1 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████▊ | 227.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 227.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 228.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 228.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▊ | 228.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 228.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.5 MB 71.1 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████▉ | 229.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 229.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |██████████▉ | 230.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 230.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.4 MB 71.1 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████ | 231.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 231.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.8 MB 71.1 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████ | 232.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 232.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.6 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.7 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.8 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 233.9 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.0 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.1 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.2 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.3 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.4 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.5 MB 71.1 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████ | 234.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.6 MB 79.2 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████ | 234.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 234.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 235.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 235.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 235.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 235.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 235.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 235.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████ | 235.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 235.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.6 MB 79.2 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████▏ | 236.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 236.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▏ | 237.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 237.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.7 MB 79.2 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████▎ | 238.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 238.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▎ | 239.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 239.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.8 MB 79.2 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████▍ | 240.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 240.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 241.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▍ | 242.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.9 MB 79.2 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████▌ | 242.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 242.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 243.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▌ | 244.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 244.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.7 MB 79.2 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████▋ | 245.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 245.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▋ | 246.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 246.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.6 MB 79.2 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████▊ | 247.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 247.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 248.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▊ | 249.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.5 MB 79.2 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████▉ | 249.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 249.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 250.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████▉ | 251.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.5 MB 79.2 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████ | 251.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 251.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.4 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.5 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.6 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.7 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.8 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 252.9 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.0 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.1 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.2 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.3 MB 79.2 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.3 MB 72.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████ | 253.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 253.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 254.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.5 MB 72.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████ | 255.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 255.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████ | 256.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 256.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.5 MB 72.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████▏ | 257.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 257.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▏ | 258.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.9 MB 72.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████▎ | 258.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 258.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 259.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.8 MB 72.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████▎ | 260.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▎ | 260.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 260.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 260.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 260.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 260.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 260.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 260.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 260.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 261.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.5 MB 72.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████▍ | 262.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 262.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▍ | 263.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 263.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.6 MB 72.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████▌ | 264.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 264.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▌ | 265.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 265.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.3 MB 72.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████▋ | 266.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 266.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▋ | 267.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 267.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.2 MB 72.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████▊ | 268.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 268.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 269.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▊ | 270.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.4 MB 72.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████▉ | 270.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.8 MB 72.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████▉ | 270.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 270.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.0 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.1 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.2 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.3 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.4 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.5 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.6 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.7 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.8 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.9 MB 72.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████▉ | 271.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 271.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████▉ | 272.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 272.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.8 MB 108.8 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████ | 273.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 273.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 274.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.2 MB 108.8 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████ | 275.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 275.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 276.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████ | 277.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.7 MB 108.8 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████▏ | 277.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 277.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 278.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▏ | 279.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 279.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.0 MB 108.8 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████▎ | 280.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 280.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 281.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 282.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 282.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 282.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 282.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 282.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 282.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 282.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▎ | 282.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.1 MB 108.8 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████▍ | 282.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 282.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 283.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▍ | 284.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.4 MB 108.8 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████▌ | 284.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 284.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 285.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█▋ | 33.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 33.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 34.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▋ | 35.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.9 MB 5.7 MB/s eta 0:01:53"
+ " |█████████████▌ | 286.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▌ | 286.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.8 MB 108.8 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████▋ | 286.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 286.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 287.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.9 MB 108.8 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████▋ | 288.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 288.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▋ | 289.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.4 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.5 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.6 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.7 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.8 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 289.9 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.0 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.1 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.2 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.3 MB 108.8 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████▊ | 290.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.6 MB 70.4 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████▊ | 290.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 290.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▊ | 291.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 291.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ "
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ " | 292.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 292.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.7 MB 70.4 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████▉ | 293.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████▉ | 293.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 293.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 294.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.9 MB 70.4 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████ | 295.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 295.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 296.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█▊ | 35.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 35.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 36.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▊ | 37.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 37.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.2 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.3 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.4 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.5 MB 5.7 MB/s eta 0:01:53"
+ " |██████████████ | 297.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 297.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████ | 298.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 298.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.1 MB 70.4 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████▏ | 299.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 299.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▏ | 300.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 300.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 300.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 300.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 300.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 300.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 300.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 300.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 300.9 MB 70.4 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████▎ | 300.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 300.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 300.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 301.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.1 MB 70.4 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████▎ | 302.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 302.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▎ | 303.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.7 MB 70.4 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████▍ | 303.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 303.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█▉ | 38.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.5 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.6 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.7 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.8 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 38.9 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.0 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.1 MB 5.7 MB/s eta 0:01:53\r",
- "\u001b[K |█▉ | 39.1 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.1 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.1 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.2 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.2 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.2 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.2 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.2 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.2 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.2 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.2 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.2 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.2 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.3 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.3 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.3 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.3 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.3 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.3 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.3 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.3 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.3 MB 5.7 MB/s eta 0:01:52\r",
- "\u001b[K |█▉ | 39.4 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.4 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.4 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.4 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.4 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.4 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.4 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.4 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.4 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.4 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.5 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.5 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.5 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.5 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.5 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.5 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.5 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.5 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.5 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.5 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.6 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.6 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.6 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.6 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.6 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.6 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.6 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.6 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.6 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.6 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.7 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.7 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.7 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.7 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.7 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.7 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.7 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.7 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.7 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.8 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.8 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.8 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.8 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.8 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.8 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.8 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.8 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.8 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.8 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.9 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.9 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.9 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.9 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.9 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.9 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.9 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.9 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.9 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |█▉ | 39.9 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.0 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.0 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.0 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.0 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.0 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.0 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.0 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.0 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.0 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.0 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.1 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.1 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.1 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.1 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.1 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.1 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.1 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.1 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.1 MB 1.3 MB/s eta 0:07:59\r",
- "\u001b[K |██ | 40.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.5 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.5 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.5 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.5 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.5 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.5 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.5 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.5 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.5 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.6 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.6 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.6 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.6 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.6 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.6 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.6 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.6 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.6 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.6 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.7 MB 1.3 MB/s eta 0:07:58"
+ " |██████████████▍ | 304.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 304.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.2 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.3 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.4 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▍ | 305.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.5 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.6 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.7 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.8 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 305.9 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.0 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.1 MB 70.4 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████▌ | 306.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.3 MB 79.0 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████▌ | 306.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 306.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▌ | 307.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 307.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 307.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 307.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 307.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 307.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 307.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 307.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.2 MB 79.0 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████▋ | 308.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 308.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.9 MB 79.0 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████▋ | 309.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 309.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▋ | 310.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 310.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 311.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.0 MB 79.0 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████▊ | 312.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▊ | 312.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 312.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 313.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |████�"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██ | 40.7 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.7 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.7 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.7 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.7 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.7 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.7 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.7 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.7 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.8 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.8 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.8 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.8 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.8 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.8 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.8 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.8 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.8 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.8 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.9 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.9 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.9 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.9 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.9 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.9 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.9 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.9 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.9 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 40.9 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.0 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.0 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.0 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.0 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.0 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.0 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.0 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.0 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.0 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.1 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.1 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.1 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.1 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.1 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.1 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.1 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.1 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.1 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.1 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.2 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.3 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.4 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.5 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.5 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.5 MB 1.3 MB/s eta 0:07:58\r",
- "\u001b[K |██ | 41.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.9 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.9 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.9 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.9 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.9 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.9 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.9 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.9 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.9 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 41.9 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.0 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.0 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.0 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.0 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.0 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.0 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.0 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.0 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.0 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.0 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.1 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.1 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.1 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.1 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.1 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.1 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.1 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.1 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.1 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.1 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.2 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.2 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.2 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.2 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.2 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.2 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.2 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.2 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.2 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.3 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.3 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.3 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.3 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.3 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.3 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.3 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.3 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.3 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.3 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.4 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.4 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.4 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.4 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.4 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.4 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.4 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.4 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.4 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.4 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.5 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.6 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.7 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.8 MB 1.3 MB/s eta 0:07:57\r",
- "\u001b[K |██ | 42.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 42.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 42.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 42.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 42.9 MB 1.3 MB/s eta 0:07:56"
+ "�█████████▉ | 314.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████▉ | 314.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 314.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.7 MB 79.0 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████ | 315.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 315.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 316.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.2 MB 79.0 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████ | 317.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 317.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.7 MB 79.0 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████ | 318.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 318.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████ | 319.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 319.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.5 MB 79.0 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████▏ | 320.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 320.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 321.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 322.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 322.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▏ | 322.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██ | 42.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 42.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 42.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 42.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 42.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 42.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 42.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 42.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 42.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.2 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.2 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.2 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.2 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.2 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.2 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.2 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.2 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.2 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.2 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.3 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.3 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.3 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.3 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.3 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.3 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.3 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.3 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.3 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.3 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.4 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.4 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.4 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.4 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.4 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.4 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.4 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.4 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.4 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.4 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.5 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.5 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.5 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.5 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.5 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.5 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.5 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.5 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.5 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.6 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.6 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.6 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.6 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.6 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.6 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.6 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.6 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.6 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.6 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.7 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.7 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.7 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.7 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.7 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.7 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.7 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.7 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.7 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.7 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.8 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 43.9 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.0 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.1 MB 1.3 MB/s eta 0:07:56\r",
- "\u001b[K |██ | 44.1 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.6 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.6 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.6 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.6 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.6 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.6 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.6 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.6 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.6 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██ | 44.6 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.7 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.7 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.7 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.7 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.7 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.7 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.7 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.7 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.7 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.7 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.8 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.8 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.8 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.8 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.8 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.8 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.8 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.8 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.8 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.9 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.9 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.9 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.9 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.9 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.9 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.9 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.9 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.9 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 44.9 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.0 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.0 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.0 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.0 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.0 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.0 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.0 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.0 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.0 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.0 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.1 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.1 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.1 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.1 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.1 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.1 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.1 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.1 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.1 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.1 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.2 MB 1.3 MB/s eta 0:07:55"
+ " |███████████████▎ | 322.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.7 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.8 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 322.9 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.0 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.1 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.2 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.3 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.4 MB 79.0 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████▎ | 323.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.4 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.5 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.6 MB 79.0 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 323.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▎ | 324.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 324.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.3 MB 74.1 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████▍ | 325.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 325.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▍ | 326.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 326.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.4 MB 74.1 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████▌ | 327.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 327.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.9 MB 74.1 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████▌ | 328.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 328.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 329.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 329.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 329.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 329.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 329.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 329.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 329.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▌ | 329.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 329.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 33"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "0.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 330.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▋ | 331.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 331.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.1 MB 74.1 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████▊ | 332.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 332.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▊ | 333.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 333.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.0 MB 74.1 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████▉ | 334.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 334.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.5 MB 74.1 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████▉ | 335.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 335.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████▉ | 336.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 336.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.0 MB 74.1 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████ | 337.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 337.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.7 MB 74.1 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████ | 338.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 338.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 339.9 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.0 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.1 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.2 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.3 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.4 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.5 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.6 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.6 MB 74.1 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████ | 340.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.7 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████ | 340.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████▏ | 340.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████▏ | 340.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████▏ | 340.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████▏ | 340.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████▏ | 340.8 MB 74.1 MB/s eta 0:00:05\r",
+ "\u001b[K |████████████████▏ | 340.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 340.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 340.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 340.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 340.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 340.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 340.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 340.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 340.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 340.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 341.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 342.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████�"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██▏ | 45.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.2 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.3 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.4 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.5 MB 1.3 MB/s eta 0:07:55\r",
- "\u001b[K |██▏ | 45.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.9 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.9 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.9 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.9 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.9 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.9 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.9 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.9 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.9 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 45.9 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.0 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.0 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.0 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.0 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.0 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.0 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.0 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.0 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.0 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.0 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.1 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.1 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.1 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.1 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.1 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.1 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.1 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.1 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.1 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.2 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.2 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.2 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.2 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.2 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.2 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.2 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.2 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.2 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.2 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.3 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.3 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.3 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.3 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.3 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.3 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.3 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.3 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.3 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.3 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.4 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.4 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.4 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.4 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.4 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.4 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.4 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.4 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.4 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.4 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.5 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.6 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.7 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.8 MB 1.3 MB/s eta 0:07:54\r",
- "\u001b[K |██▏ | 46.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 46.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 46.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 46.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 46.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 46.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 46.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 46.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 46.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 46.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 46.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 46.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 46.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 47.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 47.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 47.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 47.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 47.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▏ | 47.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.2 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.2 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.2 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.2 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.2 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.2 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.2 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.2 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.2 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.2 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.3 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.3 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.3 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.3 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.3 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.3 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.3 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.3 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.3 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.3 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.4 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.4 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.4 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.4 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.4 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.4 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.4 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.4 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.4 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.5 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.5 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.5 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.5 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.5 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.5 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.5 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.5 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.5 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.5 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.6 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.6 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.6 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.6 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.6 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.6 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.6 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.6 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.6 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.6 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.7 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.7 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.7 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.7 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.7 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.7 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.7 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.7 MB 1.3 MB/s eta 0:07:53"
+ "��██████▏ | 343.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▏ | 343.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 343.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.2 MB 139.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████▎ | 344.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 344.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▎ | 345.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.5 MB 139.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████▍ | 345.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 345.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.8 MB 139.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████▍ | 346.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.9 MB 139.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████▍ | 346.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 346.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▍ | 347.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 347.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 347.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 347.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 347.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 347.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 347.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 347.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 347.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 347.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 347.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 347.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.0 MB 139.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████▌ | 348.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 348.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.9 MB 139.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████▌ | 349.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 349.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▌ | 350.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.9 MB 139.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████▋ | 350.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 350.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 351.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▋ | 352.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 352.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.3 MB 139.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████▊ | 353.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 353.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▊ | 354.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 354.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 354.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 354.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 354.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 354.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 354.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.0 MB 139.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████▉ | 355.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.7 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.8 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 355.9 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.0 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.1 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.2 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.3 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.4 MB 139.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████▉ | 356.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.4 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.5 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.6 MB 139.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 356.6 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.6 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.7 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.7 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.7 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.7 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.7 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.7 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.7 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.7 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.7 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.8 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.8 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.8 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.8 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.8 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.8 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.8 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.8 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.8 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.8 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.9 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.9 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.9 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.9 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.9 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.9 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.9 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.9 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.9 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 356.9 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 357.0 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 357.0 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 357.0 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 357.0 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 357.0 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 357.0 MB 106.6 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████▉ | 357.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████▉ | 357.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 357.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.7 MB 106.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████ | 358.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████�"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██▎ | 47.7 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.7 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.8 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 47.9 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.0 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.1 MB 1.3 MB/s eta 0:07:53\r",
- "\u001b[K |██▎ | 48.1 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.5 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.5 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.5 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.5 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.5 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.5 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.5 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.5 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.5 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.5 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.6 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.6 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.6 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.6 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.6 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.6 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.6 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.6 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.6 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.7 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.7 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.7 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.7 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.7 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.7 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.7 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.7 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.7 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.7 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.8 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.8 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.8 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.8 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.8 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.8 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.8 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.8 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.8 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.8 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.9 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.9 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.9 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.9 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.9 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.9 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.9 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.9 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.9 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 48.9 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.0 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.0 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.0 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.0 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.0 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.0 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.0 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.0 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.0 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.0 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.1 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.1 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.1 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.1 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.1 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.1 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.1 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.1 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.1 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.2 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▎ | 49.3 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.4 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.5 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.5 MB 1.3 MB/s eta 0:07:52\r",
- "\u001b[K |██▍ | 49.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | "
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "49.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.9 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.9 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.9 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.9 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.9 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.9 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.9 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.9 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 49.9 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.0 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.0 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.0 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.0 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.0 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.0 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.0 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.0 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.0 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.0 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.1 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.1 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.1 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.1 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.1 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.1 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.1 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.1 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.1 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.1 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.2 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.2 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.2 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.2 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.2 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.2 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.2 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.2 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.2 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.2 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.3 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.3 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.3 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.3 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.3 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.3 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.3 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.3 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.3 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.4 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.4 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.4 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.4 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.4 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.4 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.4 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.4 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.4 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.4 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.5 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.6 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.7 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.8 MB 1.3 MB/s eta 0:07:51\r",
- "\u001b[K |██▍ | 50.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 50.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.2 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.2 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.2 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.2 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.2 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.2 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.2 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.2 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.2 MB 1.3 MB/s eta 0:07:50"
+ "��███████ | 358.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 358.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 359.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.6 MB 106.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████ | 360.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 360.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████ | 361.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 361.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.9 MB 106.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████▏ | 362.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 362.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 363.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▏ | 364.3 MB 106.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████▏ | 364.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 364.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K "
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ " |█████████████████▎ | 365.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 365.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▎ | 366.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 366.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.1 MB 106.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████▍ | 367.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 367.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 368.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 369.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 369.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 369.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▍ | 369.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.3 MB 106.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████▌ | 369.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 369.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 370.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.0 MB 106.6 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████▌ | 371.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▌ | 371.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.6 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.7 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.8 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 371.9 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.0 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.1 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.2 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.3 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.4 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.5 MB 106.6 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████▋ | 372.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.6 MB 61.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████▋ | 372.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 372.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.0 MB 61.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████▋ | 373.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▋ | 373.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 373.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.0 MB 61.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████▊ | 374.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 374.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.9 MB 61.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████▊ | 375.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 375.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 376.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 376.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 376.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 376.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 376.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 376.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 376.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 376.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▊ | 376.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 376.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.0 MB 61.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████▉ | 377.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 377.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.1 MB 61.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████▉ | 378.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |█████████████████▉ | 378.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 378.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 379.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.3 MB 61.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████ | 380.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 380.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |████�"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██▍ | 51.3 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.3 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.3 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.3 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.3 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.3 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.3 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.3 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.3 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.3 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.4 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.4 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.4 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.4 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.4 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.4 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.4 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.4 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.4 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.4 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.5 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.5 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.5 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.5 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.5 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.5 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.5 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.5 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.5 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.5 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.6 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.6 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.6 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.6 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.6 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.6 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.6 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.6 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.6 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.7 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.7 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.7 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.7 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.7 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▍ | 51.7 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.7 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.7 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.7 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.7 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.8 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 51.9 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.0 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.1 MB 1.3 MB/s eta 0:07:50\r",
- "\u001b[K |██▌ | 52.1 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.5 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.5 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.5 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.5 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.5 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.5 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.5 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.5 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.5 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.6 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.6 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.6 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.6 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.6 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.6 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.6 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.6 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.6 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.6 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.7 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.7 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.7 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.7 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.7 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.7 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.7 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.7 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.7 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.7 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.8 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.8 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.8 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.8 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.8 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.8 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.8 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.8 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.8 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.8 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.9 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.9 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.9 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.9 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.9 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.9 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.9 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.9 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 52.9 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.0 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.0 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.0 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.0 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.0 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.0 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.0 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.0 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.0 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.0 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.1 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.1 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.1 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.1 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.1 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.1 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.1 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.1 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.1 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.1 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.2 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.3 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.4 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.5 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.5 MB 1.3 MB/s eta 0:07:49\r",
- "\u001b[K |██▌ | 53.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.8 MB 1.3 MB/s eta 0:07:48"
+ "�█████████████ | 381.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 381.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 382.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.0 MB 61.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████ | 383.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████ | 383.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 383.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.4 MB 61.3 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████▏ | 384.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 384.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.0 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.1 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.2 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.3 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▏ | 385.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.4 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.5 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.6 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.7 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.8 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.9 MB 61.3 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.9 MB 63.7 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████▎ | 385.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 385.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 386.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.6 MB 63.7 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████▎ | 387.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▎ | 387.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 387.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.1 MB 63.7 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████▍ | 388.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.5 MB 63.7 "
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██▌ | 53.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.9 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.9 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.9 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.9 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.9 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.9 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.9 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.9 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.9 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 53.9 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 54.0 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 54.0 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 54.0 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 54.0 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 54.0 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 54.0 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 54.0 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 54.0 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 54.0 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▌ | 54.0 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.1 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.1 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.1 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.1 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.1 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.1 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.1 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.1 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.1 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.1 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.2 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.2 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.2 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.2 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.2 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.2 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.2 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.2 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.2 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.3 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.3 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.3 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.3 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.3 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.3 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.3 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.3 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.3 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.3 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.4 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.4 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.4 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.4 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.4 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.4 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.4 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.4 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.4 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.4 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.5 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.6 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.7 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.8 MB 1.3 MB/s eta 0:07:48\r",
- "\u001b[K |██▋ | 54.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 54.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.2 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.2 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.2 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.2 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.2 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.2 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.2 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.2 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.2 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.2 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.3 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.3 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.3 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.3 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.3 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.3 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.3 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.3 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.3 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.3 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.4 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.4 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.4 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.4 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.4 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.4 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.4 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.4 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.4 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.4 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.5 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.5 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.5 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.5 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.5 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.5 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.5 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.5 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.5 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.6 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.6 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.6 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.6 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.6 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.6 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.6 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.6 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.6 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.6 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.7 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.7 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.7 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.7 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.7 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.7 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.7 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.7 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.7 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.7 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.8 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 55.9 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.0 MB 1.3 MB/s eta 0:07:47"
+ "MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 388.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.9 MB 63.7 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████▍ | 389.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 389.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▍ | 390.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 390.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.5 MB 63.7 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████▌ | 391.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 391.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▌ | 392.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 392.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██▋ | 56.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.0 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.1 MB 1.3 MB/s eta 0:07:47\r",
- "\u001b[K |██▋ | 56.1 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.1 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▋ | 56.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.5 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.5 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.5 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.5 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.5 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.5 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.5 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.5 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.5 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.5 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.6 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.6 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.6 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.6 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.6 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.6 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.6 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.6 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.6 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.6 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.7 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.7 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.7 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.7 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.7 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.7 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.7 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.7 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.7 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.8 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.8 MB 1.3 MB/s eta 0:07:46"
+ " |██████████████████▋ | 393.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 393.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.8 MB 63.7 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████▋ | 394.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▋ | 394.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 394.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 394.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 394.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 394.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 394.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 394.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 394.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 394.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 394.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 394.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 394.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 395.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.6 MB 63.7 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████▊ | 396.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 396.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▊ | 397.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██▊ | 56.8 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.8 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.8 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.8 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.8 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.8 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.8 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.8 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.9 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.9 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.9 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.9 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.9 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.9 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.9 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.9 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.9 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 56.9 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.0 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.0 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.0 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.0 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.0 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.0 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.0 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.0 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.0 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.0 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.1 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.1 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.1 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.1 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.1 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.1 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.1 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.1 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.1 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.1 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.2 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.3 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.4 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.5 MB 1.3 MB/s eta 0:07:46\r",
- "\u001b[K |██▊ | 57.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.9 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.9 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.9 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.9 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.9 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.9 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.9 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.9 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.9 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 57.9 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.0 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.0 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.0 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.0 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.0 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.0 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.0 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.0 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.0 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.1 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.1 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.1 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.1 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.1 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.1 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.1 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.1 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.1 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.1 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.2 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.2 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.2 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.2 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.2 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.2 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.2 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.2 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.2 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.2 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.3 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.3 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.3 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.3 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.3 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.3 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.3 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.3 MB 1.3 MB/s eta 0:07:45"
+ " |██████████████████▉ | 397.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.3 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.4 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.5 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.6 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.7 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.8 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 397.9 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.0 MB 63.7 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████▉ | 398.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.0 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.1 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.2 MB 63.7 MB/s eta 0:00:05\r",
+ "\u001b[K |██████████████████▉ | 398.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 398.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |██████████████████▉ | 399.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 399.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.1 MB 136.2 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████ | 400.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 400.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.4 MB 136.2 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████ | 401.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 401.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 402.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.4 MB 136.2 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████ | 403.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ "
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ " | 403.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.6 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.7 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████�"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██▊ | 58.3 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.3 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.4 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.4 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.4 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.4 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.4 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.4 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.4 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.4 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.4 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.4 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.5 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.6 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▊ | 58.7 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▉ | 58.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▉ | 58.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▉ | 58.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▉ | 58.8 MB 1.3 MB/s eta 0:07:45\r",
- "\u001b[K |██▉ | 58.8 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.8 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.8 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.8 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.8 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.8 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.9 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.9 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.9 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.9 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.9 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.9 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.9 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.9 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 58.9 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.0 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.0 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.0 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.0 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.0 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.0 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.0 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.0 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.0 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.0 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.1 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.1 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.1 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.1 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.1 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.1 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.1 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.1 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.1 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.1 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.2 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.2 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.2 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.2 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.2 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.2 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.2 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.2 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.2 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.2 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.3 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.3 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.3 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.3 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.3 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.3 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.3 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.3 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.3 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.4 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.4 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.4 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.4 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.4 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.4 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.4 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.4 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.4 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.4 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.5 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.5 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.5 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.5 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.5 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.5 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.5 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.5 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.5 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.5 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.6 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.6 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.6 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.6 MB 1.3 MB/s eta 0:07:44\r",
- "\u001b[K |██▉ | 59.6 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.6 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.6 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.6 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.6 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.6 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.7 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.7 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.7 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.7 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.7 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.7 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.7 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.7 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.7 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.8 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.8 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.8 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.8 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.8 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.8 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.8 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.8 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.8 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.8 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.9 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.9 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.9 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.9 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.9 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.9 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.9 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.9 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.9 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 59.9 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.0 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.0 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.0 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.0 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.0 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.0 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.0 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.0 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.0 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.0 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.1 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.1 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.1 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.1 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.1 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.1 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.1 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.1 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.1 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.1 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.2 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.2 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.2 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.2 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.2 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.2 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.2 MB 1.4 MB/s eta 0:07:29\r",
- "\u001b[K |██▉ | 60.2 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.2 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.7 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.7 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.7 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.7 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.7 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.7 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.7 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.7 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.7 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.7 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.8 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.8 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.8 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.8 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.8 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.8 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.8 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.8 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.8 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.8 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.9 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.9 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.9 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.9 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.9 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.9 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.9 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.9 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.9 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 60.9 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.0 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.0 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.0 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.0 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.0 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.0 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.0 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.0 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.0 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.1 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.1 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.1 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.1 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.1 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |██▉ | 61.1 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.1 MB 1.4 MB/s eta 0:07:28"
+ "�███████ | 403.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.8 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |�"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "��██████████████████ | 403.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 403.9 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.0 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.1 MB"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ " 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.1 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████ | 404.2 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.3 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.4 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.5 MB 136.2 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████▏ | 404.5 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.5 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.6 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.6 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.6 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.6 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.6 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.6 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.6 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.6 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.6 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.6 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.7 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.7 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.7 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.7 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.7 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.7 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.7 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.7 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.7 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.7 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.8 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.8 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.8 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.8 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.8 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.8 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.8 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.8 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.8 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.8 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.9 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.9 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.9 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.9 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.9 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.9 MB 136.2 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████▏ | 404.9 MB 550 kB/s eta 0:08:15\r",
+ "\u001b[K |███████████████████▏ | 404.9 MB 550 kB/s eta 0:08:15\r",
+ "\u001b[K |███████████████████▏ | 404.9 MB 550 kB/s eta 0:08:15\r",
+ "\u001b[K |███████████████████▏ | 405.0 MB 550 kB/s eta 0:08:15\r",
+ "\u001b[K |███████████████████▏ | 405.0 MB 550 kB/s eta 0:08:15\r",
+ "\u001b[K |███████████████████▏ | 405.0 MB 550 kB/s eta 0:08:15\r",
+ "\u001b[K |███████████████████▏ | 405.0 MB 550 kB/s eta 0:08:15\r",
+ "\u001b[K |███████████████████▏ | 405.0 MB 550 kB/s eta 0:08:15\r",
+ "\u001b[K |███████████████████▏ | 405.0 MB 550 kB/s eta 0:08:15\r",
+ "\u001b[K |███████████████████▏ | 405.0 MB 550 kB/s eta 0:08:15\r",
+ "\u001b[K |███████████████████▏ | 405.0 MB 550 kB/s eta 0:08:15\r",
+ "\u001b[K |███████████████████▏ | 405.0 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.0 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.1 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.1 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.1 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.1 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.1 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.1 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.1 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.1 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.1 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.1 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.2 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.2 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.2 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.2 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.2 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.2 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.2 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.2 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.2 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.2 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.3 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.3 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.3 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.3 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.3 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.3 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.3 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.3 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.3 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.4 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.4 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.4 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.4 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.4 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.4 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.4 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.4 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.4 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.4 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.5 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.5 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.5 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.5 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.5 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.5 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.5 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.5 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.5 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.5 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.6 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.6 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.6 MB 550 kB/s eta 0:08:14\r",
+ "\u001b[K |███████████████████▏ | 405.6 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.6 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.6 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.6 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.6 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.6 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.6 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.7 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.7 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.7 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.7 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.7 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.7 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.7 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.7 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.7 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.7 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.8 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.8 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.8 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.8 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.8 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.8 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.8 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.8 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.8 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.9 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.9 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.9 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.9 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.9 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.9 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.9 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.9 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.9 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 405.9 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.0 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.0 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.0 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.0 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.0 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.0 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.0 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.0 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.0 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.0 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.1 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.1 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.1 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.1 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.1 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.1 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.1 MB 550 kB/s eta 0:08:13\r",
+ "\u001b[K |███████████████████▏ | 406.1 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.1 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.1 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.2 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.2 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.2 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.2 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.2 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.2 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.2 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.2 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.2 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.3 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.3 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.3 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.3 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.3 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.3 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.3 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.3 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.3 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.3 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.4 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.4 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.4 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.4 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.4 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.4 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.4 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.4 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.4 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.4 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.5 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.5 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.5 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.5 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.5 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.5 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.5 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.5 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.5 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.5 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.6 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.6 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.6 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▏ | 406.6 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▎ | 406.6 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▎ | 406.6 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▎ | 406.6 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▎ | 406.6 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▎ | 406.6 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▎ | 406.7 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▎ | 406.7 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▎ | 406.7 MB 550 kB/s eta 0:08:12\r",
+ "\u001b[K |███████████████████▎ | 406.7 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.7 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.7 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.7 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.7 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.7 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.7 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.8 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.8 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.8 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.8 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.8 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.8 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.8 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.8 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.8 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.8 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.9 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.9 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.9 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.9 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.9 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.9 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.9 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.9 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.9 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 406.9 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.0 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.0 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.0 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.0 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.0 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.0 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.0 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.0 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.0 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.1 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.1 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.1 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.1 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.1 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.1 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.1 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.1 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.1 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.1 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.2 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.2 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.2 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.2 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.2 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.2 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.2 MB 550 kB/s eta 0:08:11\r",
+ "\u001b[K |███████████████████▎ | 407.2 MB 550 kB/s eta 0:08:11"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████▎ | 407.2 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.2 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.3 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.3 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.3 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.3 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.3 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.3 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.3 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.3 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.3 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.3 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.4 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.4 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.4 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.4 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.4 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.4 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.4 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.4 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.4 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.4 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.5 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.5 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.5 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.5 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.5 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.5 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.5 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.5 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.5 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.6 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.6 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.6 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.6 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.6 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.6 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.6 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.6 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.6 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.6 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.7 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.7 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.7 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.7 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.7 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.7 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.7 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.7 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.7 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.7 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.8 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.8 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.8 MB 550 kB/s eta 0:08:10\r",
+ "\u001b[K |███████████████████▎ | 407.8 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.8 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.8 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.8 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.8 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.8 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.8 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.9 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.9 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.9 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.9 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.9 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.9 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.9 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.9 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 407.9 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.0 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.0 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.0 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.0 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.0 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.0 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.0 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.0 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.0 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.0 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.1 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.1 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.1 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.1 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.1 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.1 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.1 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.1 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.1 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.1 MB 550 kB/s eta 0:08:09"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████▎ | 408.2 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.2 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.2 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.2 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.2 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.2 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.2 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.2 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.2 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.2 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.3 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.3 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.3 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.3 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.3 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.3 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.3 MB 550 kB/s eta 0:08:09\r",
+ "\u001b[K |███████████████████▎ | 408.3 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.3 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.4 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.4 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.4 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.4 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.4 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.4 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.4 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.4 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.4 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.4 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.5 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.5 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.5 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.5 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.5 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.5 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.5 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.5 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.5 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.5 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.6 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.6 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.6 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.6 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.6 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.6 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.6 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.6 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.6 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.6 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.7 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.7 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.7 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.7 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.7 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.7 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.7 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.7 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.7 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.8 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.8 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.8 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.8 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.8 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.8 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.8 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.8 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.8 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.8 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.9 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.9 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.9 MB 550 kB/s eta 0:08:08\r",
+ "\u001b[K |███████████████████▎ | 408.9 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▎ | 408.9 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▎ | 408.9 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▎ | 408.9 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▎ | 408.9 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▎ | 408.9 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▎ | 408.9 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.0 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.0 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.0 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.0 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.0 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.0 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.0 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.0 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.0 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.0 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.1 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.1 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.1 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.1 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.1 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.1 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.1 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.1 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.1 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.1 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.2 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.2 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.2 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.2 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.2 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.2 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.2 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.2 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.2 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.3 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.3 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.3 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.3 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.3 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.3 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.3 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.3 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.3 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.3 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.4 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.4 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.4 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.4 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.4 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.4 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.4 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.4 MB 550 kB/s eta 0:08:07\r",
+ "\u001b[K |███████████████████▍ | 409.4 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.4 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.5 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.5 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.5 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.5 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.5 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.5 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.5 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.5 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.5 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.5 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.6 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.6 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.6 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.6 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.6 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.6 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.6 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.6 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.6 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.7 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.7 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.7 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.7 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.7 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.7 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.7 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.7 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.7 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.7 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.8 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.8 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.8 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.8 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.8 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.8 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.8 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.8 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.8 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.8 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.9 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.9 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.9 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.9 MB 550 kB/s eta 0:08:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████▍ | 409.9 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.9 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.9 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.9 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.9 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 409.9 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 410.0 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 410.0 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 410.0 MB 550 kB/s eta 0:08:06\r",
+ "\u001b[K |███████████████████▍ | 410.0 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.0 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.0 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.0 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.0 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.0 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.1 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.1 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.1 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.1 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.1 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.1 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.1 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.1 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.1 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.1 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.2 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.2 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.2 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.2 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.2 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.2 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.2 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.2 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.2 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.2 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.3 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.3 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.3 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.3 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.3 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.3 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.3 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.3 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.3 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.3 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.4 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.4 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.4 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.4 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.4 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.4 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.4 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.4 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.4 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.4 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.5 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.5 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.5 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.5 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.5 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.5 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.5 MB 550 kB/s eta 0:08:05\r",
+ "\u001b[K |███████████████████▍ | 410.5 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.5 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.6 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.6 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.6 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.6 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.6 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.6 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.6 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.6 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.6 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.6 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.7 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.7 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.7 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.7 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.7 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.7 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.7 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.7 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.7 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.7 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.8 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.8 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.8 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.8 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.8 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.8 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.8 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.8 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.8 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.8 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.9 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.9 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.9 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.9 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.9 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.9 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.9 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.9 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 410.9 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.0 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.0 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.0 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.0 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.0 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.0 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.0 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.0 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.0 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.0 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.1 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.1 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.1 MB 550 kB/s eta 0:08:04\r",
+ "\u001b[K |███████████████████▍ | 411.1 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.1 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.1 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.1 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.1 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.1 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.1 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.2 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.2 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.2 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.2 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.2 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.2 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.2 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.2 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.2 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.2 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.3 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.3 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.3 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▍ | 411.3 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.3 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.3 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.3 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.3 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.3 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.4 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.4 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.4 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.4 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.4 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.4 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.4 MB 550 kB/s eta 0:08:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████▌ | 411.4 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.4 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.4 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.5 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.5 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.5 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.5 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.5 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.5 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.5 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.5 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.5 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.5 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.6 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.6 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.6 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.6 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.6 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.6 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.6 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.6 MB 550 kB/s eta 0:08:03\r",
+ "\u001b[K |███████████████████▌ | 411.6 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.6 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.7 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.7 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.7 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.7 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.7 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.7 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.7 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.7 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.7 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.8 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.8 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.8 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.8 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.8 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.8 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.8 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.8 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.8 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.8 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.9 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.9 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.9 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.9 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.9 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.9 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.9 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.9 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.9 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 411.9 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 412.0 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 412.0 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 412.0 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 412.0 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 412.0 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 412.0 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 412.0 MB 550 kB/s eta 0:08:02\r",
+ "\u001b[K |███████████████████▌ | 412.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 412.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.2 MB 22.8 MB/s eta 0:00:12"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████▌ | 413.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▌ | 413.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 413.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.9 MB 22.8 MB/s eta 0:00:12"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████▋ | 414.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 414.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 415.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 416.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 416.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 416.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▋ | 416.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.9 MB 22.8 MB/s eta 0:00:12"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████▊ | 416.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 416.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 417.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▊ | 418.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 418.9 MB 22.8 MB/s eta 0:00:12"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████▉ | 419.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 419.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████▉ | 420.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |█████████████████�"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |███ | 61.1 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.1 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.1 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.2 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.2 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.2 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.2 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.2 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.2 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.2 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.2 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.2 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.2 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.3 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.4 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.5 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.6 MB 1.4 MB/s eta 0:07:28\r",
- "\u001b[K |███ | 61.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 61.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.1 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.1 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.1 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.1 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.1 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.1 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.1 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.1 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.1 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.1 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.2 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.2 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.2 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.2 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.2 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.2 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.2 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.2 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.2 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.2 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.3 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.3 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.3 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.3 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.3 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.3 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.3 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.3 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.3 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.4 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.4 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.4 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.4 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.4 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.4 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.4 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.4 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.4 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.4 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.5 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.5 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.5 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.5 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.5 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.5 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.5 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.5 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.5 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.5 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.6 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.7 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.8 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 62.9 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 63.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 63.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 63.0 MB 1.4 MB/s eta 0:07:27\r",
- "\u001b[K |███ | 63.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.4 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.4 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.4 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.4 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.4 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.4 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.4 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.4 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.4 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.4 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.5 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.5 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.5 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.5 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.5 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.5 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.5 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.5 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.5 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.5 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.6 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.6 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.6 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.6 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.6 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.6 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.6 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.6 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.6 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.7 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.7 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.7 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.7 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.7 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.7 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.7 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.7 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.7 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.7 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.8 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.8 MB 1.4 MB/s eta 0:07:26"
+ "��██ | 420.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 420.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 421.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.3 MB 22.8 MB/s eta 0:00:12"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████ | 422.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 422.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 423.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.2 MB 22.8 MB/s eta 0:00:12"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████ | 424.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 424.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.0 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.1 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.2 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.3 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████ | 425.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.4 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.5 MB 22.8 MB/s eta 0:00:12"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████▏ | 425.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.5 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.6 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.7 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.8 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.9 MB 22.8 MB/s eta 0:00:12\r",
+ "\u001b[K |████████████████████▏ | 425.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 426.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.0 MB 22.8 MB/s eta 0:00:11"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████▏ | 427.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▏ | 427.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 427.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.4 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.5 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.6 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.7 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.8 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 428.9 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.0 MB 22.8 MB/s eta 0:00:11"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████▎ | 429.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.0 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.1 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.2 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.3 MB 22.8 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████▎ | 429.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 429.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▎ | 430.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.2 MB 75.2 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████▍ | 430.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 430.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.7 MB 75.2 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████▍ | 431.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 431.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▍ | 432.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 432.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.7 MB 75.2 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████▌ | 433.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 433.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▌ | 434.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.9 MB 75.2 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████▋ | 434.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 434.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 435.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.5 MB 75.2 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████▋ | 436.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 436.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▋ | 437.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.9 MB 75.2 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████▊ | 437.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 437.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 438.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▊ | 439.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 439.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.0 MB 75.2 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████▉ | 440.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 440.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.4 MB 75.2 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████▉ | 441.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████▉ | 441.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 441.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 441.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 441.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 441.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 441.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 441.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 441.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 441.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 441.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 441.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 442.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.0 MB 75.2 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████ | 443.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 443.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.0 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.1 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.2 MB 75.2 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████ | 444.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.2 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.3 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.4 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.5 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.6 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.7 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.8 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.9 MB 75.2 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 444.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 445.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.1 MB 68.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████ | 446.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████ | 446.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 446.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.7 MB 68.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████▏ | 447.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 447.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▏ | 448.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 448.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 448.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 448.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 448.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 448.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.7 MB 68.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████▎ | 449.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 449.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 450.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▎ | 451.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.6 MB 68.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████▍ | 451.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 451.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 452.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▍ | 453.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.7 MB 68.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████▌ | 453.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 453.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 454.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "█▌ | 455.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▌ | 455.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 456.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.0 MB 68.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████▋ | 457.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 457.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▋ | 458.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.6 MB 68.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████▊ | 458.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 458.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 459.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.4 MB 68.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████▊ | 460.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▊ | 460.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.8 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 460.9 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.0 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.1 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.2 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.3 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.4 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.5 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.6 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.7 MB 68.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████▉ | 461.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.7 MB 68.9 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████▉ | 461.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.8 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.8 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.8 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.8 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.8 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.8 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.8 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.8 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.8 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.8 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.9 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.9 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.9 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.9 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.9 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.9 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.9 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.9 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.9 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 461.9 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.0 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.0 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.0 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.0 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.0 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.0 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.0 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.0 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.0 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.0 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.1 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.1 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.1 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.1 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.1 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.1 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.1 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.1 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.1 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.2 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.2 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.2 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.2 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.2 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.2 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.2 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.2 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.2 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.2 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.3 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.3 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.3 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.3 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.3 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.3 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.3 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.3 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.3 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.3 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.4 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.4 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.4 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.4 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.4 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.4 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.4 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.4 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.4 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.4 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.5 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.5 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.5 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.5 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.5 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.5 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.5 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.5 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.5 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.6 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.6 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.6 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.6 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.6 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.6 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.6 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.6 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.6 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.6 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.7 MB 1.2 MB/s eta 0:03:01"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████▉ | 462.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.7 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.8 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.8 MB 1.2 MB/s eta 0:03:01\r",
+ "\u001b[K |█████████████████████▉ | 462.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 462.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 463.0 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 463.0 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 463.0 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 463.0 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 463.0 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |█████████████████████▉ | 463.0 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.0 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.0 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.0 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.0 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.1 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.1 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.1 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.1 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.1 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.1 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.1 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.1 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.1 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.1 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.2 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.2 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.2 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.2 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.2 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.2 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.2 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.2 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.2 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.2 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.3 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.3 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.3 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.3 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.3 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.3 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.3 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.3 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.3 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.3 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.4 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.4 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.4 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.4 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.4 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.4 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.4 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.4 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.4 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.5 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.5 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.5 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.5 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.5 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.5 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.5 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.5 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.5 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.5 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.6 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.6 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.6 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.6 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.6 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.6 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.6 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.6 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.6 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.6 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.7 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.7 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.7 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.7 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.7 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.7 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.7 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.7 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.7 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.7 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.8 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 463.9 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 464.0 MB 1.2 MB/s eta 0:03:00\r",
+ "\u001b[K |██████████████████████ | 464.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.2 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.2 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.2 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.2 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.2 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.2 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.2 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.2 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.2 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.3 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.3 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.3 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.3 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.3 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.3 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.3 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.3 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.3 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.3 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.4 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.4 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.4 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.4 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.4 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.4 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.4 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.4 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.4 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.4 MB 1.2 MB/s eta 0:02:59"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████ | 464.5 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.5 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.5 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.5 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.5 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.5 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.5 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.5 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.5 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.5 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.6 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.6 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.6 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.6 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.6 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.6 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.6 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.6 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.6 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.7 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.7 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.7 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.7 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.7 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.7 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.7 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.7 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.7 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.7 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.8 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.8 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.8 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.8 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.8 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.8 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.8 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.8 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.8 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.8 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.9 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.9 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.9 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.9 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.9 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.9 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.9 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.9 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.9 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 464.9 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.0 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.1 MB 1.2 MB/s eta 0:02:59\r",
+ "\u001b[K |██████████████████████ | 465.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.4 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.4 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.4 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.4 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.4 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.4 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.4 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.4 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.4 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.4 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.5 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.5 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.5 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.5 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.5 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.5 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.5 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.5 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.5 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.6 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.6 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.6 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.6 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.6 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.6 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.6 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.6 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.6 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.6 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.7 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.7 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.7 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.7 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.7 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.7 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.7 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.7 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.7 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.7 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.8 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.8 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.8 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.8 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.8 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.8 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.8 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.8 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.8 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.8 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.9 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.9 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.9 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.9 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.9 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.9 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.9 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.9 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 465.9 MB 1.2 MB/s eta 0:02:58"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████ | 466.0 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.0 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.0 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.0 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.0 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.0 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.0 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.0 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.0 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.0 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.1 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.1 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.1 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.1 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.1 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.1 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.1 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.1 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.1 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.1 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.2 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.3 MB 1.2 MB/s eta 0:02:58\r",
+ "\u001b[K |██████████████████████ | 466.3 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.6 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.6 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.6 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.6 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.6 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.6 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.6 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.6 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.6 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.6 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.7 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.7 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.7 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.7 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.7 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.7 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.7 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.7 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.7 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.7 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.8 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.8 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.8 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.8 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.8 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.8 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.8 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.8 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.8 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.9 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.9 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.9 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.9 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.9 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.9 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.9 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.9 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.9 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 466.9 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.0 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.0 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.0 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.0 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.0 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.0 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.0 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.0 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.0 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.0 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.1 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.1 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.1 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.1 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.1 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.1 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.1 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.1 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.1 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.1 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.2 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.2 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.2 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.2 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.2 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.2 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.2 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.2 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.2 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.3 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.3 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.3 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.3 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.3 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.3 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.3 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.3 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.3 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.3 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.4 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.5 MB 1.2 MB/s eta 0:02:57\r",
+ "\u001b[K |██████████████████████ | 467.5 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.5 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.5 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████ | 467.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.8 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.8 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.8 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.8 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.8 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.8 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.8 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.8 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.8 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.8 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.9 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.9 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.9 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.9 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.9 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.9 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.9 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.9 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.9 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 467.9 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.0 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.0 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.0 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.0 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.0 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.0 MB 1.2 MB/s eta 0:02:56"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████▏ | 468.0 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.0 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.0 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.0 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.1 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.1 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.1 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.1 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.1 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.1 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.1 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.1 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.1 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.2 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.2 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.2 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.2 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.2 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.2 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.2 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.2 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.2 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.2 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.3 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.3 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.3 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.3 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.3 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.3 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.3 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.3 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.3 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.3 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.4 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.4 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.4 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.4 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.4 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.4 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.4 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.4 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.4 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.4 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.5 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.5 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.5 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.5 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.5 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.5 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.5 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.5 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.5 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.6 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.7 MB 1.2 MB/s eta 0:02:56\r",
+ "\u001b[K |██████████████████████▏ | 468.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 468.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.0 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.0 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.0 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.0 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.0 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.0 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.0 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.0 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.0 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.0 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.1 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.1 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.1 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.1 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.1 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.1 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.1 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.1 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.1 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.1 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.2 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.2 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.2 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.2 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.2 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.2 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.2 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.2 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.2 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.2 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.3 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.3 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.3 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.3 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.3 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.3 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.3 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.3 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.3 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.4 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.4 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.4 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.4 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.4 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.4 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.4 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.4 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.4 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.4 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.5 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.5 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.5 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.5 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.5 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.5 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.5 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.5 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.5 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.5 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.6 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.6 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.6 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.6 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.6 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.6 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.6 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.6 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.6 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.6 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K "
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |███ | 63.8 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.8 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.8 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.8 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.8 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.8 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.8 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.8 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.9 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.9 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.9 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.9 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.9 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.9 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.9 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.9 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.9 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 63.9 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.0 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.1 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.2 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.3 MB 1.4 MB/s eta 0:07:26\r",
- "\u001b[K |███ | 64.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.8 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.8 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.8 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.8 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.8 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.8 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.8 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.8 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.8 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.8 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.9 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.9 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.9 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.9 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.9 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.9 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.9 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.9 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 64.9 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.0 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.0 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.0 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.0 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.0 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.0 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.0 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.0 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.0 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.0 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.1 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.1 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.1 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.1 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.1 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.1 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.1 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.1 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.1 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.1 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.2 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.2 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.2 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.2 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.2 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.2 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.2 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.2 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.2 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.2 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.3 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.3 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.3 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.3 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.3 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.3 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.3 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.3 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.3 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.4 MB 1.4 MB/s eta 0:07:25"
+ " |██████████████████████▏ | 469.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.7 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.8 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.9 MB 1.2 MB/s eta 0:02:55\r",
+ "\u001b[K |██████████████████████▏ | 469.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 469.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 469.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 469.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 470.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 470.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 470.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 470.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 470.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 470.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 470.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 470.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 470.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▏ | 470.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.2 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.2 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.2 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.2 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.2 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.2 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.2 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.2 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.2 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.3 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.3 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.3 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.3 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.3 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.3 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.3 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.3 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.3 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.3 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.4 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.4 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.4 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.4 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.4 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.4 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.4 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.4 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.4 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.4 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.5 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.5 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.5 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.5 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.5 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.5 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.5 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.5 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.5 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.5 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.6 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.6 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.6 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.6 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.6 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.6 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.6 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.6 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.6 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.7 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.7 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.7 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.7 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.7 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.7 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.7 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.7 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.7 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.7 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.8 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.8 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.8 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.8 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.8 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.8 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.8 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.8 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.8 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.8 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 470.9 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.0 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.1 MB 1.2 MB/s eta 0:02:54\r",
+ "\u001b[K |██████████████████████▎ | 471.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.1 MB 1.2 MB/s eta 0:02:53"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████▎ | 471.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.4 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.4 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.4 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.4 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.4 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.4 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.4 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.4 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.4 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.4 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.5 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.5 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.5 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.5 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.5 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.5 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.5 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.5 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.5 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.6 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.6 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.6 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.6 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.6 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.6 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.6 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.6 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.6 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.6 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.7 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.7 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.7 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.7 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.7 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.7 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.7 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.7 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.7 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.7 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.8 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.8 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.8 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.8 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.8 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.8 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.8 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.8 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.8 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.8 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.9 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.9 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.9 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.9 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.9 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.9 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.9 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.9 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 471.9 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.0 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.0 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.0 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.0 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.0 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.0 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.0 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.0 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.0 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.0 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.1 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.2 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.3 MB 1.2 MB/s eta 0:02:53\r",
+ "\u001b[K |██████████████████████▎ | 472.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▎ | 472.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▎ | 472.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▎ | 472.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▎ | 472.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▎ | 472.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▎ | 472.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▎ | 472.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▎ | 472.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▎ | 472.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▎ | 472.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▎ | 472.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.5 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.5 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.5 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.5 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.5 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.5 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.5 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.5 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.5 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.5 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.6 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.6 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.6 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.6 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.6 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.6 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.6 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.6 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.6 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.6 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.7 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.7 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.7 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.7 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.7 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.7 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.7 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.7 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.7 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.8 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.8 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.8 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.8 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.8 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.8 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.8 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.8 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.8 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.8 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.9 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.9 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.9 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.9 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.9 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.9 MB 1.2 MB/s eta 0:02:52"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████▍ | 472.9 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.9 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.9 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 472.9 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.0 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.0 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.0 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.0 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.0 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.0 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.0 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.0 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.0 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.0 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.1 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.1 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.1 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.1 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.1 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.1 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.1 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.1 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.1 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.1 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.2 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.2 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.2 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.2 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.2 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.2 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.2 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.2 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.2 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.3 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.4 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.5 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.5 MB 1.2 MB/s eta 0:02:52\r",
+ "\u001b[K |██████████████████████▍ | 473.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.7 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.7 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.7 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.7 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.7 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.7 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.7 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.7 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.7 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.7 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.8 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.8 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.8 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.8 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.8 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.8 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.8 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.8 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.8 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.8 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.9 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.9 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.9 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.9 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.9 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.9 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.9 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.9 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.9 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 473.9 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.0 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.0 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.0 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.0 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.0 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.0 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.0 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.0 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.0 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.1 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.1 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.1 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.1 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.1 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.1 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.1 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.1 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.1 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.1 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.2 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.2 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.2 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.2 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.2 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.2 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.2 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.2 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.2 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.2 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.3 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.3 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.3 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.3 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.3 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.3 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.3 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.3 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.3 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.3 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.4 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.4 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.4 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.4 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.4 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.4 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.4 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.4 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.4 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.4 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.5 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.6 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.7 MB 1.2 MB/s eta 0:02:51\r",
+ "\u001b[K |██████████████████████▍ | 474.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▍ | 474.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▍ | 474.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▍ | 474.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▍ | 474.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▍ | 474.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▍ | 474.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▍ | 474.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▍ | 474.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.9 MB 1.2 MB/s eta 0:02:50"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████▌ | 474.9 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.9 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.9 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.9 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.9 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.9 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.9 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 474.9 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.0 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.0 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.0 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.0 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.0 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.0 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.0 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.0 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.0 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.0 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.1 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.1 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.1 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.1 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.1 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.1 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.1 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.1 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.1 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.1 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.2 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.2 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.2 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.2 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.2 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.2 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.2 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.2 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.2 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.2 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.3 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.3 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.3 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.3 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.3 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.3 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.3 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.3 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.3 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.4 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.4 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.4 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.4 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.4 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.4 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.4 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.4 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.4 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.4 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.5 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.5 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.5 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.5 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.5 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.5 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.5 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.5 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.5 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.5 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.6 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.6 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.6 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.6 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.6 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.6 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.6 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.6 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.6 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.6 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.7 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.8 MB 1.2 MB/s eta 0:02:50\r",
+ "\u001b[K |██████████████████████▌ | 475.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 475.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 475.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 475.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 475.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 475.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 475.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 475.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 475.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 475.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.1 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.1 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.1 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.1 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.1 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.1 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.1 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.1 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.1 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.1 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.2 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.2 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.2 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.2 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.2 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.2 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.2 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.2 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.2 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.3 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.3 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.3 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.3 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.3 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.3 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.3 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.3 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.3 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.3 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.4 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.4 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.4 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.4 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.4 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.4 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.4 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.4 MB 1.2 MB/s eta 0:02:49"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████▌ | 476.4 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.4 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.5 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.5 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.5 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.5 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.5 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.5 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.5 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.5 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.5 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.5 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.6 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.6 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.6 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.6 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.6 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.6 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.6 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.6 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.6 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.7 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.7 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.7 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.7 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.7 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.7 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.7 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.7 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.7 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.7 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.8 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.8 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.8 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.8 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.8 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.8 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.8 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.8 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.8 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.8 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 476.9 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 477.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 477.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 477.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 477.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 477.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 477.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 477.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 477.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 477.0 MB 1.2 MB/s eta 0:02:49\r",
+ "\u001b[K |██████████████████████▌ | 477.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▌ | 477.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▌ | 477.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▌ | 477.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▌ | 477.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▌ | 477.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.3 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.3 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.3 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.3 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.3 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.3 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.3 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.3 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.3 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.3 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.4 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.4 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.4 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.4 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.4 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.4 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.4 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.4 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.4 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.5 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.5 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.5 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.5 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.5 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.5 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.5 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.5 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.5 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.5 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.6 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.6 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.6 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.6 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.6 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.6 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.6 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.6 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.6 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.6 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.7 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.7 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.7 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.7 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.7 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.7 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.7 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.7 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.7 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.7 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.8 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.8 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.8 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.8 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.8 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.8 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.8 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.8 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.8 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.8 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.9 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.9 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.9 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.9 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.9 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.9 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.9 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.9 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 477.9 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.0 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.0 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.0 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.0 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.0 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.0 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.0 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.0 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.0 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.0 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.1 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.2 MB 1.2 MB/s eta 0:02:48\r",
+ "\u001b[K |██████████████████████▋ | 478.2 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.2 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.3 MB 1.2 MB/s eta 0:02:47"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████▋ | 478.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.5 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.5 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.5 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.5 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.5 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.5 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.5 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.5 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.5 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.5 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.6 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.6 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.6 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.6 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.6 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.6 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.6 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.6 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.6 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.6 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.7 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.7 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.7 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.7 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.7 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.7 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.7 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.7 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.7 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.8 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.8 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.8 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.8 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.8 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.8 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.8 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.8 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.8 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.8 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.9 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.9 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.9 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.9 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.9 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.9 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.9 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.9 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.9 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 478.9 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.0 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.0 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.0 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.0 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.0 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.0 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.0 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.0 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.0 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.0 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.1 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.1 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.1 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.1 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.1 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.1 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.1 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.1 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.1 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.2 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.2 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.2 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.2 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.2 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.2 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.2 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.2 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.2 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.2 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.3 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.4 MB 1.2 MB/s eta 0:02:47\r",
+ "\u001b[K |██████████████████████▋ | 479.4 MB 1.2 MB/s eta 0:02:46\r",
+ "\u001b[K |██████████████████████▋ | 479.4 MB 1.2 MB/s eta 0:02:46\r",
+ "\u001b[K |██████████████████████▋ | 479.4 MB 1.2 MB/s eta 0:02:46\r",
+ "\u001b[K |██████████████████████▊ | 479.5 MB 1.2 MB/s eta 0:02:46\r",
+ "\u001b[K |██████████████████████▊ | 479.5 MB 1.2 MB/s eta 0:02:46\r",
+ "\u001b[K |██████████████████████▊ | 479.5 MB 1.2 MB/s eta 0:02:46\r",
+ "\u001b[K |██████████████████████▊ | 479.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 479.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.2 MB 51.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████▊ | 480.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 480.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▊ | 481.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 481.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 482.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.2 MB 51.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████▉ | 483.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |███ | 65.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.4 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.5 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.6 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.7 MB 1.4 MB/s eta 0:07:25\r",
- "\u001b[K |███ | 65.7 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███ | 65.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███ | 65.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███ | 65.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███ | 65.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███ | 65.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███ | 65.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 65.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.2 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.2 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.2 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.2 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.2 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.2 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.2 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.2 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.2 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.2 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.3 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.3 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.3 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.3 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.3 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.3 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.3 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.3 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.3 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.3 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.4 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.4 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.4 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.4 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.4 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.4 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.4 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.4 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.4 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.4 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.5 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.5 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.5 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.5 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.5 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.5 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.5 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.5 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.5 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.5 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.6 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.6 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.6 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.6 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.6 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.6 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.6 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.6 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.6 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.7 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.7 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.7 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.7 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.7 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.7 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.7 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.7 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.7 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.7 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.8 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 66.9 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.0 MB 1.4 MB/s eta 0:07:24"
+ "████████████▉ | 483.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 483.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |██████████████████████▉ | 484.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 484.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.8 MB 51.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████ | 485.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 485.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.5 MB 51.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████ | 486.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 486.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.0 MB 51.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████ | 487.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.5 MB 51.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████ | 487.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 487.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.0 MB 51.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████ | 488.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.1 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.2 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.3 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.4 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.5 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.6 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.7 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████ | 488.8 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 488.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 488.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 488.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 488.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 488.9 MB 51.9 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▏ | 488.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 488.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 488.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 488.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 488.9 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 489.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 489.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 489.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 489.0 MB 51.9 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████▏ | 489.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.2 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.2 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.2 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.2 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.2 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.2 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.2 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.2 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.2 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.2 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.3 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.3 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.3 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.3 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.3 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.3 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.3 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.3 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.3 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.3 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.4 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.4 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.4 MB 1.2 MB/s eta 0:02:37"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▏ | 489.4 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.4 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.4 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.4 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.4 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.4 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.5 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.5 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.5 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.5 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.5 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.5 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.5 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.5 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.5 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.5 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.6 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.6 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.6 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.6 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.6 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.6 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.6 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.6 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.6 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.6 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.7 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.7 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.7 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.7 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.7 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.7 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.7 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.7 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.7 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.7 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.8 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.8 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.8 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.8 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.8 MB 1.2 MB/s eta 0:02:37"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▏ | 489.8 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.8 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.8 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.8 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.9 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.9 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.9 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.9 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.9 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.9 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.9 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.9 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.9 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 489.9 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.0 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.1 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.2 MB 1.2 MB/s eta 0:02:37\r",
+ "\u001b[K |███████████████████████▏ | 490.2 MB 1.2 MB/s eta 0:02:36"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▏ | 490.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.4 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.4 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.4 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.4 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.4 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.4 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.4 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.4 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.4 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.4 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.5 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.5 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.5 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.5 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.5 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.5 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.5 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.5 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.5 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.5 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.6 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.6 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.6 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.6 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.6 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.6 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |███▏ | 67.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.0 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.1 MB 1.4 MB/s eta 0:07:24\r",
- "\u001b[K |███▏ | 67.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.6 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.6 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.6 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.6 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.6 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.6 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.6 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.6 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.6 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.6 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.7 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.7 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.7 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.7 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.7 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.7 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.7 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.7 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.7 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.7 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.8 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.8 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.8 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.8 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.8 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.8 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.8 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.8 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.8 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.9 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.9 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.9 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.9 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.9 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.9 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.9 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.9 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.9 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 67.9 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.0 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.0 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.0 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.0 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.0 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.0 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.0 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.0 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.0 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.0 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▏ | 68.1 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.2 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.3 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.4 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.5 MB 1.4 MB/s eta 0:07:23\r",
- "\u001b[K |███▎ | 68.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.9 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.9 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.9 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.9 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.9 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.9 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.9 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.9 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.9 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 68.9 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.0 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.0 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.0 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.0 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.0 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.0 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.0 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.0 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.0 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.0 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.1 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.1 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.1 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.1 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.1 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.1 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.1 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.1 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.1 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.2 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.2 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.2 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.2 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.2 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.2 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.2 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.2 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.2 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.2 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.3 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.3 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.3 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.3 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.3 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.3 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.3 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.3 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.3 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.3 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.4 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.4 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.4 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.4 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.4 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.4 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.4 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.4 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.4 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.4 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.5 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.6 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.7 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.8 MB 1.4 MB/s eta 0:07:22"
+ " |███████████████████████▏ | 490.6 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.6 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.6 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.6 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.7 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.7 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.7 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.7 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.7 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.7 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.7 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.7 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.7 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.8 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.8 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.8 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.8 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.8 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.8 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.8 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.8 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.8 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.8 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.9 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.9 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.9 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.9 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.9 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.9 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.9 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.9 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.9 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 490.9 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.0 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.0 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.0 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.0 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.0 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.0 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.0 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.0 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.0 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.0 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.1 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |███▎ | 69.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.8 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.9 MB 1.4 MB/s eta 0:07:22\r",
- "\u001b[K |███▎ | 69.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 69.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 69.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 69.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 69.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 69.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 69.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 69.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 69.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.3 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.3 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.3 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.3 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.3 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.3 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.3 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.3 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.3 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.3 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.4 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.4 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.4 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.4 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.4 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.4 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.4 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.4 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.4 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.5 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.5 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.5 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.5 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.5 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▎ | 70.5 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.5 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.5 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.5 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.5 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.6 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.6 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.6 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.6 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.6 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.6 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.6 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.6 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.6 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.6 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.7 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.7 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.7 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.7 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.7 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.7 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.7 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.7 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.7 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.7 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.8 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.8 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.8 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.8 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.8 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.8 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.8 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.8 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.8 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 70.9 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.0 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.1 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.2 MB 1.4 MB/s eta 0:07:21\r",
- "\u001b[K |███▍ | 71.2 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.2 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.7 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.7 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.7 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.7 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.7 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.7 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.7 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.7 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.7 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.8 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.8 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.8 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.8 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.8 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.8 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.8 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.8 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.8 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.8 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.9 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.9 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.9 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.9 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.9 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.9 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.9 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.9 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.9 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 71.9 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.0 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.0 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.0 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.0 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.0 MB 1.4 MB/s eta 0:07:20"
+ " |███████████████████████▏ | 491.1 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.1 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.1 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.1 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.1 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.1 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.1 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.1 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▏ | 491.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.2 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.3 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.4 MB 1.2 MB/s eta 0:02:36\r",
+ "\u001b[K |███████████████████████▎ | 491.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.6 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.6 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.6 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.6 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.6 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.6 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.6 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.6 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.6 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.6 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.7 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.7 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.7 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.7 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.7 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.7 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.7 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.7 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.7 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.7 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.8 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.8 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.8 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.8 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.8 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.8 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.8 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.8 MB 1.2 MB/s eta 0:02:35"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▎ | 491.8 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.8 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.9 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.9 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.9 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.9 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.9 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.9 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.9 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.9 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 491.9 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.0 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.0 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.0 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.0 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.0 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.0 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.0 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.0 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.0 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |██████████████████"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |███▍ | 72.0 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.0 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.0 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.0 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.0 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.1 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.1 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.1 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.1 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.1 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.1 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.1 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.1 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.1 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.2 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.2 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.2 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.2 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.2 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.2 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.2 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.2 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.2 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.2 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.3 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.4 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.5 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.6 MB 1.4 MB/s eta 0:07:20\r",
- "\u001b[K |███▍ | 72.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▍ | 72.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 72.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 72.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 72.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 72.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 72.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 72.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 72.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 72.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 72.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 72.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.1 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.1 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.1 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.1 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.1 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.1 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.1 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.1 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.1 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.1 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.2 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.2 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.2 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.2 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.2 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.2 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.2 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.2 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.2 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.2 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.3 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.3 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.3 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.3 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.3 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.3 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.3 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.3 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.3 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.3 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.4 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.4 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.4 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.4 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.4 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.4 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.4 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.4 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.4 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.5 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.5 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.5 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.5 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.5 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.5 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.5 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.5 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.5 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.5 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.6 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.7 MB 1.4 MB/s eta 0:07:19"
+ "█████▎ | 492.0 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.1 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.1 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.1 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.1 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.1 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.1 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.1 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.1 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.1 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.1 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.2 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.2 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.2 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.2 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.2 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.2 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.2 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.2 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.2 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.2 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.3 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.3 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.3 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.3 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.3 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.3 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.3 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.3 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.3 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.3 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.4 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.5 MB 1.2 MB/s eta 0:02:35"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▎ | 492.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.5 MB 1.2 MB/s eta 0:02:35\r",
+ "\u001b[K |███████████████████████▎ | 492.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.7 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.7 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.7 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.7 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.7 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.7 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.7 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.7 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.7 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.7 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.8 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.8 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.8 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.8 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.8 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.8 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.8 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.8 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.8 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.9 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.9 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.9 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.9 MB 1.2 MB/s eta 0:02:34"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▎ | 492.9 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.9 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.9 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.9 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.9 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 492.9 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.0 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.0 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.0 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.0 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.0 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.0 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.0 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.0 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.0 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.0 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.1 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.1 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.1 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.1 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.1 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.1 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.1 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.1 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.1 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.1 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.2 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.2 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.2 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.2 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.2 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.2 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.2 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.2 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.2 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.3 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.3 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.3 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.3 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.3 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.3 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.3 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.3 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.3 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.3 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.4 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.4 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.4 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.4 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.4 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.4 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.4 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.4 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.4 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.4 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.5 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.5 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.5 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.5 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.5 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.5 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.5 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.5 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.5 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▎ | 493.5 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▍ | 493.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▍ | 493.6 MB 1.2 MB/s eta 0:02:34"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▍ | 493.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▍ | 493.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▍ | 493.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▍ | 493.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▍ | 493.6 MB 1.2 MB/s eta 0:02:34\r",
+ "\u001b[K |███████████████████████▍ | 493.6 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.6 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.6 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.7 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.7 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.7 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.7 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.7 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.7 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.7 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.7 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.7 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.8 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.8 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.8 MB 1.2 MB/s eta 0:02:28\r",
+ "\u001b[K |███████████████████████▍ | 493.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 493.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.0 MB 1.2 MB/s eta 0:02:27"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▍ | 494.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.1 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.1 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.1 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.1 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.1 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.1 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.1 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.1 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.1 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.2 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.2 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.2 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.2 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.2 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.2 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.2 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.2 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.2 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.2 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.3 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.3 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.3 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.3 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.3 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.3 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.3 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.3 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.3 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.3 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.4 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.4 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.4 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.4 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.4 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.4 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.4 MB 1.2 MB/s eta 0:02:27"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▍ | 494.4 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.4 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.4 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.5 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.5 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.5 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.5 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.5 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.5 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.5 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.5 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.5 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.6 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.6 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.6 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.6 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.6 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.6 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.6 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.6 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.6 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.6 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.7 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.7 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.7 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.7 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.7 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.7 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.7 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |███▌ | 73.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.7 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.8 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 73.9 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 74.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 74.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 74.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 74.0 MB 1.4 MB/s eta 0:07:19\r",
- "\u001b[K |███▌ | 74.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.4 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.4 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.4 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.4 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.4 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.4 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.4 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.4 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.4 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.4 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.5 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.5 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.5 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.5 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.5 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.5 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.5 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.5 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.5 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.5 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.6 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.6 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.6 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.6 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.6 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.6 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.6 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.6 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.6 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.6 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.7 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.7 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.7 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.7 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.7 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.7 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.7 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.7 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.7 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.8 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.8 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.8 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.8 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.8 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.8 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.8 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.8 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.8 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.8 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.9 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.9 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.9 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.9 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.9 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.9 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.9 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.9 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.9 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 74.9 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.0 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.1 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▌ | 75.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.2 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.3 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.4 MB 1.4 MB/s eta 0:07:18\r",
- "\u001b[K |███▋ | 75.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.8 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.8 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.8 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.8 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.8 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.8 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.8 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.8 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.8 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.8 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.9 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.9 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.9 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.9 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.9 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.9 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.9 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.9 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 75.9 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.0 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.0 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.0 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.0 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.0 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.0 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.0 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.0 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.0 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.0 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.1 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.1 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.1 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.1 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.1 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.1 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.1 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.1 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.1 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.1 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.2 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.2 MB 1.4 MB/s eta 0:07:17"
+ " |███████████████████████▍ | 494.7 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.7 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.7 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.8 MB 1.2 MB/s eta 0:02:27"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▍ | 494.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.8 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 494.9 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 495.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 495.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 495.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 495.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 495.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 495.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 495.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 495.0 MB 1.2 MB/s eta 0:02:27\r",
+ "\u001b[K |███████████████████████▍ | 495.0 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.0 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.4 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.4 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.4 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.4 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.4 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.4 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.4 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.4 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.4 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.5 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.5 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.5 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.5 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.5 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.5 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.5 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.5 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.5 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.5 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.6 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.6 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.6 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.6 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.6 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.6 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.6 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.6 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.6 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.6 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.7 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.7 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.7 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.7 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.7 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.7 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.7 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.7 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.7 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.7 MB 1.2 MB/s eta 0:02:26"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▍ | 495.8 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.8 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.8 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.8 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.8 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.8 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.8 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.8 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.8 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.9 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.9 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.9 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.9 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.9 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▍ | 495.9 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 495.9 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 495.9 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 495.9 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 495.9 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.0 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.0 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.0 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.0 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.0 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.0 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.0 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.0 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.0 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.0 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.1 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.2 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.3 MB 1.2 MB/s eta 0:02:26\r",
+ "\u001b[K |███████████████████████▌ | 496.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.6 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.6 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.6 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.6 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.6 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.6 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.6 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.6 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.6 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.7 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.7 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.7 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.7 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.7 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.7 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.7 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.7 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.7 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.7 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.8 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.8 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.8 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.8 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.8 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.8 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.8 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.8 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.8 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.8 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.9 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.9 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.9 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.9 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.9 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.9 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.9 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.9 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.9 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 496.9 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.0 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.0 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.0 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.0 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.0 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.0 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.0 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.0 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.0 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.0 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.1 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.1 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.1 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.1 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.1 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.1 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.1 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.1 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.1 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.2 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.2 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.2 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.2 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.2 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.2 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.2 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.2 MB 1.2 MB/s eta 0:02:25"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▌ | 497.2 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.2 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.3 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.4 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.5 MB 1.2 MB/s eta 0:02:25\r",
+ "\u001b[K |███████████████████████▌ | 497.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.8 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.8 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.8 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.8 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.8 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.8 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.8 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.8 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.8 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.8 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.9 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.9 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.9 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.9 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.9 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.9 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.9 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.9 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 497.9 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.0 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.0 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.0 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.0 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.0 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.0 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.0 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.0 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.0 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.0 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.1 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.1 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.1 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.1 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.1 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.1 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.1 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.1 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.1 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.1 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.2 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.2 MB 1.2 MB/s eta 0:02:24"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▌ | 498.2 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.2 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.2 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.2 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.2 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.2 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.2 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▌ | 498.2 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.3 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.3 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.3 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.3 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.3 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.3 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.3 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.3 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.3 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.4 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.4 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.4 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.4 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.4 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.4 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.4 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.4 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.4 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.4 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.5 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.6 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.7 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.8 MB 1.2 MB/s eta 0:02:24\r",
+ "\u001b[K |███████████████████████▋ | 498.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 498.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.1 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.1 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.1 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.1 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.1 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.1 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.1 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.1 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.1 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.1 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.2 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.2 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.2 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.2 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.2 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.2 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.2 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.2 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.2 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.3 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.3 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.3 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.3 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.3 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.3 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.3 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.3 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.3 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.3 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.4 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.4 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.4 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.4 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.4 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.4 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.4 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.4 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.4 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.4 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.5 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.5 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.5 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.5 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.5 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.5 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.5 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.5 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.5 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.5 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.6 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.6 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.6 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.6 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.6 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.6 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.6 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.6 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.6 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.7 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.7 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.7 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.7 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.7 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.7 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.7 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.7 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.7 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.7 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.8 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 499.9 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 500.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 500.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 500.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 500.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 500.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 500.0 MB 1.2 MB/s eta 0:02:23\r",
+ "\u001b[K |███████████████████████▋ | 500.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.3 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.3 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.3 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.3 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.3 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.3 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.3 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.3 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.3 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.3 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.4 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.4 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.4 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.4 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.4 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.4 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.4 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.4 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.4 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.4 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.5 MB 1.2 MB/s eta 0:02:22"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▋ | 500.5 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.5 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.5 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.5 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.5 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.5 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.5 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.5 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.6 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.6 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.6 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.6 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.6 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▋ | 500.6 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.6 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.6 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.6 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.6 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.7 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.7 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.7 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.7 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.7 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.7 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.7 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.7 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.7 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.7 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.8 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.8 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.8 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.8 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.8 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.8 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.8 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.8 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.8 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.8 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.9 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.9 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.9 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.9 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.9 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.9 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.9 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.9 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 500.9 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.0 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.1 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.2 MB 1.2 MB/s eta 0:02:22\r",
+ "\u001b[K |███████████████████████▊ | 501.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.6 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.6 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.6 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.6 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.6 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.6 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.6 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.6 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.6 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.6 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.7 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.7 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.7 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.7 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.7 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.7 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.7 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.7 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.7 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.7 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.8 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.8 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.8 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.8 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.8 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.8 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.8 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.8 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.8 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.9 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.9 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.9 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.9 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.9 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.9 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.9 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.9 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.9 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 501.9 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.0 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.0 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.0 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.0 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.0 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.0 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.0 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.0 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.0 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.0 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.1 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.1 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.1 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.1 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.1 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.1 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.1 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.1 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.1 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.1 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.2 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.2 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.2 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.2 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.2 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.2 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.2 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.2 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.2 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.3 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.4 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.5 MB 1.2 MB/s eta 0:02:21\r",
+ "\u001b[K |███████████████████████▊ | 502.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.7 MB 1.2 MB/s eta 0:02:20"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▊ | 502.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.8 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.8 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.8 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.8 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.8 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.8 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.8 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.8 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.8 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.8 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.9 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.9 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.9 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.9 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.9 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.9 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.9 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.9 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.9 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▊ | 502.9 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.0 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.0 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.0 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.0 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.0 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.0 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.0 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.0 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.0 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.1 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.1 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.1 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.1 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.1 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.1 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.1 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.1 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.1 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.1 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.2 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.2 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.2 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.2 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.2 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.2 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.2 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.2 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.2 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.2 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.3 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.3 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.3 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.3 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.3 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.3 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.3 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.3 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.3 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.3 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.4 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.4 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.4 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.4 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.4 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.4 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.4 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.4 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.4 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.4 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.5 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.6 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.7 MB 1.2 MB/s eta 0:02:20\r",
+ "\u001b[K |███████████████████████▉ | 503.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 503.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.1 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.1 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.1 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.1 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.1 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.1 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.1 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.1 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.1 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.1 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.2 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.2 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.2 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.2 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.2 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.2 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.2 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.2 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.2 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.2 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.3 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.3 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.3 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.3 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.3 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.3 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.3 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.3 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.3 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.4 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.4 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.4 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.4 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.4 MB 1.2 MB/s eta 0:02:19"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████▉ | 504.4 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.4 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.4 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.4 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.4 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.5 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.5 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.5 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.5 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.5 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.5 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.5 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.5 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.5 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.5 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.6 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.6 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.6 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.6 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.6 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.6 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.6 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.6 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.6 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.6 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.7 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.7 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.7 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.7 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.7 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.7 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.7 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.7 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.7 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.8 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 504.9 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 505.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 505.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 505.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 505.0 MB 1.2 MB/s eta 0:02:19\r",
+ "\u001b[K |███████████████████████▉ | 505.0 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.0 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.0 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.0 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.0 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.0 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.1 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.1 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.1 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.1 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.1 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.1 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.1 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.1 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.1 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.1 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.2 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.2 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.2 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.2 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.2 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.2 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.2 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.2 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.2 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.3 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.3 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.3 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.3 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.3 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |███████████████████████▉ | 505.3 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.3 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.3 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.3 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.3 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.4 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.4 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.4 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.4 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.4 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.4 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.4 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.4 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.4 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.4 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.5 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.5 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.5 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.5 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.5 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.5 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.5 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.5 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.5 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.5 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.6 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.6 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.6 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.6 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.6 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.6 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.6 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.6 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.6 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.7 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.7 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.7 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.7 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.7 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.7 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.7 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.7 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.7 MB 1.2 MB/s eta 0:02:18\r",
+ "\u001b[K |████████████████████████ | 505.7 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.9 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.9 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.9 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.9 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.9 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.9 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.9 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.9 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.9 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 505.9 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.0 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.0 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.0 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.0 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.0 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.0 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.0 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.0 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.0 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.1 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.1 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.1 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.1 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.1 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.1 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.1 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.1 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.1 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.1 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.2 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.2 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.2 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.2 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.2 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.2 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.2 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.2 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.2 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.2 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.3 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.3 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.3 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.3 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.3 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.3 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.3 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.3 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.3 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.3 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.4 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.4 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.4 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.4 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.4 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.4 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.4 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.4 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.4 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.4 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.5 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.5 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.5 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.5 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.5 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.5 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.5 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.5 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.5 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.6 MB 56.7 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████ | 506.6 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.6 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.6 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.6 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.6 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.6 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.6 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.6 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.6 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.7 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.7 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.7 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.7 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.7 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.7 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.7 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.7 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.7 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.7 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.8 MB 56.7 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████ | 506.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 506.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 506.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 506.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 506.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 506.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 506.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 506.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 506.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 507.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.1 MB 56.7 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████ | 508.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 508.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 509.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 510.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 510.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 510.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 510.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 510.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████ | 510.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.1 MB 56.7 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████▏ | 510.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 510.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.4 MB 56.7 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████▏ | 511.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 511.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▏ | 512.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |██"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |███▋ | 76.2 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.2 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.2 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.2 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.2 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.2 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.2 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.2 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.3 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.3 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.3 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.3 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.3 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.3 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.3 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.3 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.3 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.3 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.4 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.5 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.6 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.7 MB 1.4 MB/s eta 0:07:17\r",
- "\u001b[K |███▋ | 76.7 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 76.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.2 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.2 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.2 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.2 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.2 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.2 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.2 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.2 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.2 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.3 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.3 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.3 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.3 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.3 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.3 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.3 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.3 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.3 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.3 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.4 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.4 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.4 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.4 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.4 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.4 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.4 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.4 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.4 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.4 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.5 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.5 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.5 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.5 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.5 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.5 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.5 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.5 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.5 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▋ | 77.5 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.6 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.6 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.6 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.6 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.6 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.6 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.6 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.6 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.6 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.6 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.7 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.7 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.7 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.7 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.7 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.7 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.7 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.7 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.7 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.8 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 77.9 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.0 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.1 MB 1.4 MB/s eta 0:07:16\r",
- "\u001b[K |███▊ | 78.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.5 MB 1.4 MB/s eta 0:07:15"
+ "██████████████████████▎ | 512.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 512.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.5 MB 56.7 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████▎ | 513.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 513.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▎ | 514.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.8 MB 56.7 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████▍ | 514.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 514.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 515.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 516.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 517.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 517.0 MB 56.7 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████▍ | 517.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 517.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 517.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 517.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 517.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 517.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 517.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▍ | 517.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 517.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.7 MB 56.7 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████▌ | 518.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 518.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▌ | 519.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.8 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 519.9 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.0 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.1 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.2 MB 56.7 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████▋ | 520.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.2 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.3 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.4 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.5 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.6 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.7 MB 56.7 MB/s eta 0:00:03\r",
+ "\u001b[K |████████████████████████▋ | 520.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 520.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▋ | 521.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 521.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.0 MB 47.4 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████▊ | 522.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 522.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.1 MB 47.4 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████▊ | 523.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 523.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▊ | 524.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████�"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |███▊ | 78.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.6 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.6 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.6 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.6 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.6 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.6 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.6 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.6 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.6 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.6 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.7 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.7 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.7 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.7 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.7 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.7 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.7 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.7 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.7 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.7 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.8 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.8 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.8 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.8 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.8 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.8 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.8 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.8 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.8 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.8 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.9 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.9 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.9 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.9 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.9 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.9 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.9 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.9 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 78.9 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.0 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.0 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.0 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.0 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.0 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.0 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.0 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.0 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.0 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.0 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.1 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.2 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.3 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.4 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.5 MB 1.4 MB/s eta 0:07:15\r",
- "\u001b[K |███▊ | 79.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.7 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.7 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.7 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.7 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.7 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.7 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.7 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.7 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.7 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.7 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.8 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.8 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.8 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.8 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.8 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.8 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.8 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.8 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.8 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.9 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.9 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.9 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.9 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.9 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▊ | 79.9 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 79.9 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 79.9 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 79.9 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 79.9 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.0 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.0 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.0 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.0 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.0 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.0 MB 1.4 MB/s eta 0:07:14"
+ "�███████████▉ | 524.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 524.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 525.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.2 MB 47.4 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████▉ | 526.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |████████████████████████▉ | 526.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 526.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 527.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.1 MB 47.4 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████ | 528.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 528.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 529.9 MB 47.4 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████ | 530.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.4 MB 47.4 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████ | 530.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 530.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████ | 531.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 531.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.8 MB 47.4 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████▏ | 532.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 532.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▏ | 533.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.8 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 533.9 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.0 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.1 MB 47.4 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████▎ | 534.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.1 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.2 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.3 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.4 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.5 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.6 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.7 MB 47.4 MB/s eta 0:00:04\r",
+ "\u001b[K |█████████████████████████▎ | 534.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 534.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▎ | 535.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 535.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 535.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 535.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 535.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 535.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 535.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 535.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 535.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.1 MB 47.4 MB/s eta 0:00:03"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████▍ | 536.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.3 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.4 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.5 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.6 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.7 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.8 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 536.9 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.0 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.1 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.2 MB 47.4 MB/s eta 0:00:03\r",
+ "\u001b[K |█████████████████████████▍ | 537.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 537.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.0 MB 24.1 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████▍ | 538.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▍ | 538.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 538.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.0 MB 24.1 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████▌ | 539.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 539.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.3 MB 24.1 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████▌ | 540.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▌ | 540.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 540.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 541.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.4 MB 24.1 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████▋ | 542.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▋ | 542.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 542.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 542.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 542.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 542.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 543.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.6 MB 24.1 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████▊ | 544.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 544.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▊ | 545.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 545.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.4 MB 24.1 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████▉ | 546.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 546.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████▉ | 547.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 547.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.2 MB 24.1 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████ | 548.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 548.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.2 MB 24.1 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████ | 549.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 549.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.0 MB 24.1 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████ | 550.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 550.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.4 MB 24.1 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████ | 551.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.7 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.8 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 551.9 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.0 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.1 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.2 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████ | 552.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.3 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.4 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.5 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.6 MB 24.1 MB/s eta 0:00:06\r",
+ "\u001b[K |██████████████████████████▏ | 552.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 552.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.2 MB 78.7 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████▏ | 553.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 553.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▏ | 554.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 554.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |███▉ | 80.0 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.0 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.0 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.0 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.1 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.1 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.1 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.1 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.1 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.1 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.1 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.1 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.1 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.1 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.2 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.2 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.2 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.2 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.2 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.2 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.2 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.2 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.2 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.3 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.3 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.3 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.3 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.3 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.3 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.3 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.3 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.3 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.3 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.4 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.4 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.4 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.4 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.4 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.4 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.4 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.4 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.4 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.4 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.5 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.6 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.7 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.7 MB 1.4 MB/s eta 0:07:14\r",
- "\u001b[K |███▉ | 80.7 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.7 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.7 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.7 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.7 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.7 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.7 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.7 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.8 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.8 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.8 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.8 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.8 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.8 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.8 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.8 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.8 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.8 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.9 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.9 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.9 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.9 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.9 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.9 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.9 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.9 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.9 MB 1.3 MB/s eta 0:07:35\r",
- "\u001b[K |███▉ | 80.9 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.3 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.3 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.3 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.3 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.3 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.3 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.3 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.3 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.3 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.3 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.4 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.4 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.4 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.4 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.4 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.4 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.4 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.4 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.4 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.4 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.5 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.5 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.5 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.5 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.5 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.5 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.5 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.5 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.5 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.6 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.6 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.6 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.6 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.6 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.6 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.6 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.6 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.6 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.6 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.7 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.7 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.7 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.7 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.7 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.7 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.7 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.7 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.7 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.7 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.8 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.8 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.8 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.8 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.8 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.8 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.8 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.8 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.8 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.8 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.9 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.9 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.9 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.9 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.9 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.9 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.9 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.9 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 81.9 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.0 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.1 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.2 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |███▉ | 82.3 MB 1.3 MB/s eta 0:07:34\r",
- "\u001b[K |████ | 82.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.6 MB 1.3 MB/s eta 0:07:33"
+ " |██████████████████████████▎ | 555.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 555.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 556.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 557.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 557.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 557.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 557.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 557.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▎ | 557.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.5 MB 78.7 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████▍ | 557.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 557.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 558.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▍ | 559.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.5 MB 78.7 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████▌ | 559.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 559.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 560.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.0 MB 78.7 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████▌ | 561.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▌ | 561.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 561.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.3 MB 78.7 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████▋ | 562.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 562.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |███████�"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |████ | 82.6 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.6 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.6 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.6 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.6 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.6 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.6 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.6 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.6 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.7 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.7 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.7 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.7 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.7 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.7 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.7 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.7 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.7 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.7 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.8 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.8 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.8 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.8 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.8 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.8 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.8 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.8 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.8 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.9 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.9 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.9 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.9 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.9 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.9 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.9 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.9 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.9 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 82.9 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.0 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.0 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.0 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.0 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.0 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.0 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.0 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.0 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.0 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.0 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.1 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.1 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.1 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.1 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.1 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.1 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.1 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.1 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.1 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.1 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.2 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.2 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.2 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.2 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.2 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.2 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.2 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.2 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.2 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.3 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.4 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.5 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.6 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.6 MB 1.3 MB/s eta 0:07:33\r",
- "\u001b[K |████ | 83.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 83.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.0 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.0 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.0 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.0 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.0 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.0 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.0 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.0 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.0 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.0 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.1 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.1 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.1 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.1 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.1 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.1 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.1 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.1 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.1 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.2 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.2 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.2 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.2 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.2 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.2 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.2 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.2 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.2 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.2 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.3 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.3 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.3 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.3 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.3 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.3 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.3 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.3 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.3 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.3 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.4 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.4 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.4 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.4 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.4 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.4 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.4 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.4 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.4 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.4 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.5 MB 1.3 MB/s eta 0:07:32"
+ "��██████████████████▋ | 563.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 563.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 564.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 564.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 564.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 564.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 564.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 564.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 564.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 564.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 564.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 564.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▋ | 564.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 564.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.0 MB 78.7 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████▊ | 565.0 MB 78.7 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████▊ | 565.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |████ | 84.5 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.5 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.5 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.5 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.5 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.5 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.5 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.5 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.6 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.7 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.8 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.9 MB 1.3 MB/s eta 0:07:32\r",
- "\u001b[K |████ | 84.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 84.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 84.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 84.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 84.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 84.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.3 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.3 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.3 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.3 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.3 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.3 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.3 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.3 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.3 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.4 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.4 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.4 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.4 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.4 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.4 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.4 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.4 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.4 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.4 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.5 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.5 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.5 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.5 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.5 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.5 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.5 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.5 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.5 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.5 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.6 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.6 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.6 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.6 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.6 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.6 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.6 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.6 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.6 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.6 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.7 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.7 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.7 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.7 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.7 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.7 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.7 MB 1.3 MB/s eta 0:07:31"
+ "████████▊ | 565.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 565.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▊ | 566.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |███████�"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |████ | 85.7 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.7 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.7 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.8 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.8 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.8 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.8 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.8 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.8 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.8 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.8 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.8 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 85.9 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.0 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.1 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.2 MB 1.3 MB/s eta 0:07:31\r",
- "\u001b[K |████ | 86.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.6 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.6 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.6 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.6 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.6 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.6 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.6 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.6 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.6 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.7 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.7 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.7 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.7 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.7 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.7 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.7 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.7 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.7 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.7 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.8 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.8 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.8 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.8 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.8 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.8 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.8 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.8 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.8 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.8 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.9 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.9 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.9 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.9 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.9 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.9 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.9 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.9 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.9 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 86.9 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████ | 87.0 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.0 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.0 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.0 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.0 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.0 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.0 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.0 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.0 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.1 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.1 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.1 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.1 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.1 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.1 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.1 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.1 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.1 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.1 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.2 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.3 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.4 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.5 MB 1.3 MB/s eta 0:07:30\r",
- "\u001b[K |████▏ | 87.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.6 MB 1.3 MB/s eta 0:07:29"
+ "��██████████████████▉ | 566.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 566.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.1 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.2 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.3 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.4 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.5 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.6 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.7 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.8 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 567.9 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.0 MB 78.7 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.5 MB 67.9 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████▉ | 568.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |██████████████████████████▉ | 568.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 568.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.5 MB 67.9 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████ | 569.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 569.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 570.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.1 MB 67.9 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████ | 571.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 571.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.7 MB 67.9 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████ | 572.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 572.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████ | 573.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 573.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.6 MB 67.9 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████▏ | 574.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 574.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▏ | 575.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 575.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.0 MB 67.9 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████▎ | 576.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 576.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.5 MB 67.9 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████▎ | 577.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 577.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▎ | 578.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.5 MB 67.9 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████▍ | 578.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 578.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.5 MB 67.9 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████▍ | 579.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 579.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▍ | 580.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.8 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 580.9 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.0 MB 67.9 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████▌ | 581.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.0 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.1 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.2 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.3 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.4 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.5 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.6 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.7 MB 67.9 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████▌ | 581.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 581.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.1 MB 8.4 MB/s eta 0:00:12"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████▌ | 582.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▌ | 582.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 582.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 582.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 582.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 582.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 582.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 582.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 582.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 582.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.5 MB 8.4 MB/s eta 0:00:12"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████▋ | 583.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 583.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.1 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.2 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.3 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.4 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.5 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.6 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.7 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.8 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 584.9 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 585.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 585.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 585.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 585.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 585.0 MB 8.4 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████▋ | 585.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▋ | 585.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.5 MB 8.4 MB/s eta 0:00:11"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████▊ | 585.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 585.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 586.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.0 MB 8.4 MB/s eta 0:00:11"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████▊ | 587.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▊ | 587.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 587.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.9 MB 8.4 MB/s eta 0:00:11"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████▉ | 588.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 588.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████▉ | 589.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 589.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 589.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 589.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 589.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.5 MB 8.4 MB/s eta 0:00:11"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████ | 590.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 590.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 591.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |████▏ | 87.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.9 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.9 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.9 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ "
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " | 87.9 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.9 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.9 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.9 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.9 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 87.9 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.0 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.0 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.0 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.0 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.0 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.0 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.0 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.0 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.0 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.0 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.1 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.1 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.1 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.1 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.1 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.1 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.1 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.1 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.1 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.1 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.2 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.2 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.2 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.2 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.2 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.2 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.2 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.2 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.2 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.2 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.3 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.4 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.5 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.6 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.7 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:29\r",
- "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 88.8 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:28"
+ " |████████████████████████████ | 592.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.5 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.6 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.7 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.8 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 592.9 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.0 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.1 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.2 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.3 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.4 MB 8.4 MB/s eta 0:00:11\r",
+ "\u001b[K |████████████████████████████ | 593.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.4 MB 8.4 MB/s eta 0:00:10"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████ | 593.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 593.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████ | 594.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 594.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.1 MB 8.4 MB/s eta 0:00:10"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████▏ | 595.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 595.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 596.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 597.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▏ | 597.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.0 MB 8.4 MB/s eta 0:00:10"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████▎ | 597.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.4 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.5 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.6 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.7 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.8 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 597.9 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.0 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.1 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.2 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.3 MB 8.4 MB/s eta 0:00:10\r",
+ "\u001b[K |████████████████████████████▎ | 598.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.8 MB 12.0 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████▎ | 598.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 598.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▎ | 599.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.9 MB 12.0 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████▍ | 599.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 599.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 600.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.2 MB 12.0 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████▍ | 601.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▍ | 601.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 601.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.2 MB 12.0 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████▌ | 602.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 602.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.9 MB 12.0 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████▌ | 603.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 603.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 604.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 604.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 604.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 604.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 604.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 604.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▌ | 604.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.0 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.1 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.2 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.3 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.4 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.5 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.6 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.7 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.8 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 604.9 MB 12.0 MB/s eta 0:00:07\r",
+ "\u001b[K |████████████████████████████▋ | 605.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.9 MB 12.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████▋ | 605.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 605.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▋ | 606.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 606.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.9 MB 12.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████▊ | 607.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 607.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |███�"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 88.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.2 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.3 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.3 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.3 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.3 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.3 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▏ | 89.3 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.3 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.3 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.3 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.3 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.4 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.5 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.6 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.7 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.8 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 89.9 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.0 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:28\r",
- "\u001b[K |████▎ | 90.1 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.5 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.6 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.7 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.8 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 90.9 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.0 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:27"
+ "��████████████████████████▊ | 608.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▊ | 608.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 608.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 609.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.5 MB 12.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████▉ | 610.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 610.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 611.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 611.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 611.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 611.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 611.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 611.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 611.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 611.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 611.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 611.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |████████████████████████████▉ | 611.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.8 MB 12.0 MB/s eta 0:00:06"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████ | 611.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.8 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 611.9 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.0 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.1 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.2 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.3 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.4 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.5 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.6 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.7 MB 12.0 MB/s eta 0:00:06\r",
+ "\u001b[K |█████████████████████████████ | 612.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 612.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.5 MB 84.4 MB/s eta 0:00:01"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████ | 613.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 613.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.4 MB 84.4 MB/s eta 0:00:01"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████ | 614.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 614.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 615.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.8 MB 84.4 MB/s eta 0:00:01"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████▏ | 615.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 615.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.7 MB 84.4 MB/s eta 0:00:01"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████▏ | 616.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 616.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.8 MB 84.4 MB/s eta 0:00:01"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████▏ | 617.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 617.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 618.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 618.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 619.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.0 MB 84.4 MB/s eta 0:00:01"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████▎ | 620.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▎ | 620.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 620.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.6 MB 84.4 MB/s eta 0:00:01"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████▍ | 621.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.9 MB 8"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "4.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 621.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.2 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.3 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.4 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.5 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.6 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.7 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 622.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 622.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 622.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 622.8 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 622.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 622.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 622.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 622.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 622.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 622.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 622.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 622.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 622.9 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.0 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.1 MB 84.4 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 623.2 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.2 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.2 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.2 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.2 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.2 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.2 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.2 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.2 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.2 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.3 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |████████�"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.1 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.2 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.3 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.4 MB 1.3 MB/s eta 0:07:27\r",
- "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▎ | 91.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.8 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 91.9 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.0 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.1 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.2 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.3 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.4 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.5 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.6 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.7 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:26\r",
- "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 92.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:25"
+ "��████████████████████▌ | 623.3 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.3 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.3 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.3 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.3 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.3 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.3 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.3 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.3 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.4 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.4 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.4 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.4 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.4 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |█████████████████████████████▌ | 623.4 MB 468 kB/s eta 0:01:55\r",
+ "\u001b[K |██████████"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.1 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.2 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.3 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.4 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.5 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.6 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.7 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.8 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 93.9 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 94.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 94.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 94.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 94.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 94.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▍ | 94.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▌ | 94.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▌ | 94.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▌ | 94.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▌ | 94.0 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:25\r",
- "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.5 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.6 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:24"
+ "███████████████████▌ | 623.4 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.4 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.4 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.5 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.5 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.5 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.5 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.5 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.5 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.5 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.5 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.5 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.5 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.6 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.6 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.6 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.6 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.6 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.6 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.6 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.6 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.6 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.6 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.7 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.7 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.7 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.7 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.7 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.7 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.7 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.7 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.7 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.7 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.8 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.8 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.8 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.8 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.8 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.8 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.8 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.8 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.8 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.9 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.9 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.9 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.9 MB 468 kB/s eta 0:01:54\r",
+ "\u001b[K |█████████████████████████████▌ | 623.9 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 623.9 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 623.9 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 623.9 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 623.9 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 623.9 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.0 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.0 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.0 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.0 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.0 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.0 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.0 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.0 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.0 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.0 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.1 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.1 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.1 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.1 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.1 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.1 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.1 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.1 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.1 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.1 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.2 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.2 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.2 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.2 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.2 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.2 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.2 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.2 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.2 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.3 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.3 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.3 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.3 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.3 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.3 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.3 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.3 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.3 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.3 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.4 MB 468 kB/s eta 0:01:53\r",
+ "\u001b[K |█████████████████████████████▌ | 624.4 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.4 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.4 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.4 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.4 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.4 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.4 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.4 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.4 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.5 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.5 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.5 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.5 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.5 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.5 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.5 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.5 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.5 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.5 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.6 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.6 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.6 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.6 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.6 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.6 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.6 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.6 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.6 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.7 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.7 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.7 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.7 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.7 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.7 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.7 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.7 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.7 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.7 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.8 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.8 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.8 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.8 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.8 MB 468 kB/s eta 0:01:52"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████▌ | 624.8 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.8 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.8 MB 468 kB/s eta 0:01:52\r",
+ "\u001b[K |█████████████████████████████▌ | 624.8 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 624.8 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 624.9 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 624.9 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 624.9 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 624.9 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 624.9 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 624.9 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 624.9 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 624.9 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 624.9 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 624.9 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.0 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.0 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.0 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.0 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.0 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.0 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.0 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.0 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.0 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.0 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.1 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.1 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.1 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.1 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.1 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.1 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.1 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.1 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.1 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.2 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▌ | 625.2 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.2 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.2 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.2 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.2 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.2 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.2 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.2 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.2 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.3 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.3 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.3 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.3 MB 468 kB/s eta 0:01:51\r",
+ "\u001b[K |█████████████████████████████▋ | 625.3 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.3 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.3 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.3 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.3 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.3 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.4 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.4 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.4 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.4 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.4 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.4 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.4 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.4 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.4 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.4 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.5 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.5 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.5 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.5 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.5 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.5 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.5 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.5 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.5 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.6 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.6 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.6 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.6 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.6 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.6 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.6 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.6 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.6 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.6 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.7 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.7 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.7 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.7 MB 468 kB/s eta 0:01:50"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████▋ | 625.7 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.7 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.7 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.7 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.7 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.7 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.8 MB 468 kB/s eta 0:01:50\r",
+ "\u001b[K |█████████████████████████████▋ | 625.8 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.8 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.8 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.8 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.8 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.8 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.8 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.8 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.8 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.9 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.9 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.9 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.9 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.9 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.9 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.9 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.9 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 625.9 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.0 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.0 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.0 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.0 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.0 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.0 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.0 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.0 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.0 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.0 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.1 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.1 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.1 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.1 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.1 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.1 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.1 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.1 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.1 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.1 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.2 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.2 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.2 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.2 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.2 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.2 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.2 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.2 MB 468 kB/s eta 0:01:49\r",
+ "\u001b[K |█████████████████████████████▋ | 626.2 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.2 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.3 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.3 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.3 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.3 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.3 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.3 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.3 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.3 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.3 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.4 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.4 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.4 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.4 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.4 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.4 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.4 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.4 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.4 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.4 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.5 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.5 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.5 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.5 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.5 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.5 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.5 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.5 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.5 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.5 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.6 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.6 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.6 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.6 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.6 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.6 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.6 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.6 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.6 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.6 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.7 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.7 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.7 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.7 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.7 MB 468 kB/s eta 0:01:48\r",
+ "\u001b[K |█████████████████████████████▋ | 626.7 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.7 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.7 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.7 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.7 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.8 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.8 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.8 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.8 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.8 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.8 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.8 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.8 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.8 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.9 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.9 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.9 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.9 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.9 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.9 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.9 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.9 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.9 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 626.9 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.0 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.0 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.0 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.0 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.0 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.0 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.0 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.0 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.0 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.0 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.1 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.1 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.1 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.1 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.1 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.1 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.1 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.1 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.1 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.1 MB 468 kB/s eta 0:01:47\r",
+ "\u001b[K |█████████████████████████████▋ | 627.2 MB 468 kB/s eta 0:01:47"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████▋ | 627.2 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.2 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.2 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.2 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.2 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.2 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.2 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.2 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.3 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.3 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.3 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.3 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.3 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.3 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.3 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.3 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.3 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.3 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.4 MB 1.2 MB/s eta 0:00:42\r",
+ "\u001b[K |█████████████████████████████▋ | 627.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▋ | 627.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.6 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.6 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.6 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.6 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.6 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.6 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.6 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.6 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.6 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.7 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.7 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.7 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.7 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.7 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.7 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.7 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.7 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.7 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.7 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.8 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.8 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.8 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.8 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.8 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.8 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.8 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.8 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.8 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.8 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.9 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.9 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.9 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.9 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.9 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.9 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.9 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.9 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.9 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 627.9 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.0 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.0 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.0 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.0 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.0 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.0 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.0 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.0 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.0 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.0 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.1 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.1 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.1 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.1 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.1 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.1 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.1 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.1 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.1 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.2 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.2 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.2 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.2 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.2 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.2 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.2 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.2 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.2 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.2 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.3 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.3 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.3 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.3 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.3 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.3 MB 1.2 MB/s eta 0:00:41"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████▊ | 628.3 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.3 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.3 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.3 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.4 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.5 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.6 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.6 MB 1.2 MB/s eta 0:00:41\r",
+ "\u001b[K |█████████████████████████████▊ | 628.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.8 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.8 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.8 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.8 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.8 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.8 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.8 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.8 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.8 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.8 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.9 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.9 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.9 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.9 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.9 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.9 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.9 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.9 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 628.9 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.0 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.0 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.0 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.0 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.0 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.0 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.0 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.0 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.0 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.0 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.1 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.1 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.1 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.1 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.1 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.1 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.1 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.1 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.1 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.1 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.2 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.2 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.2 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.2 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.2 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.2 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.2 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.2 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.2 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.2 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.3 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.3 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.3 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.3 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.3 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.3 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.3 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.3 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.3 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.4 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.4 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.4 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.4 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.4 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.4 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.4 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.4 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.4 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.4 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.5 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.5 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.5 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.5 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.5 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.5 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.5 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.5 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.5 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.5 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.6 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.7 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.8 MB 1.2 MB/s eta 0:00:40"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████▊ | 629.8 MB 1.2 MB/s eta 0:00:40\r",
+ "\u001b[K |█████████████████████████████▊ | 629.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▊ | 629.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▊ | 629.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▊ | 629.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▊ | 629.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▊ | 629.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▊ | 629.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▊ | 629.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▊ | 629.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 629.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 629.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 629.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 629.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 629.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 629.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 629.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 629.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.1 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.1 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.1 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.1 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.1 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.1 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.1 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.1 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.1 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.1 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.2 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.2 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.2 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.2 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.2 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.2 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.2 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.2 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.2 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.3 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.3 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.3 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.3 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.3 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.3 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.3 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.3 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.3 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.3 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.4 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.4 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.4 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.4 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.4 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.4 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.4 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.4 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.4 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.4 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.5 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.5 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.5 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.5 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.5 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.5 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.5 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.5 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.5 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.5 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.6 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.6 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.6 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.6 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.6 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.6 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.6 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.6 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.6 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.7 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.7 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.7 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.7 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.7 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.7 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.7 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.7 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.7 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.7 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.8 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 630.9 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 631.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 631.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 631.0 MB 1.2 MB/s eta 0:00:39\r",
+ "\u001b[K |█████████████████████████████▉ | 631.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.3 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.3 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.3 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.3 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.3 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.3 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.3 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.3 MB 1.2 MB/s eta 0:00:38"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█████████████████████████████▉ | 631.3 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.3 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.4 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.4 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.4 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.4 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.4 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.4 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.4 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.4 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.4 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.4 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.5 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.5 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.5 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.5 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.5 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.5 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.5 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.5 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.5 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.6 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.6 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.6 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.6 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.6 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.6 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.6 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.6 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.6 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.6 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.7 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.7 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.7 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.7 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.7 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.7 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.7 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.7 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.7 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.7 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.8 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.8 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.8 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.8 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.8 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.8 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.8 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.8 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.8 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.8 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.9 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.9 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.9 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.9 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.9 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.9 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.9 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.9 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 631.9 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.0 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.1 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.2 MB 1.2 MB/s eta 0:00:38\r",
+ "\u001b[K |█████████████████████████████▉ | 632.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |█████████████████████████████▉ | 632.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |█████████████████████████████▉ | 632.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.5 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.5 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.5 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.5 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.5 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.5 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.5 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.5 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.5 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.5 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.6 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.6 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.6 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.6 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.6 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.6 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.6 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.6 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.6 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.6 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.7 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.7 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.7 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.7 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.7 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.7 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.7 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.7 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.7 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.8 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.8 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.8 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.8 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.8 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.8 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.8 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.8 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.8 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.8 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.9 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.9 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.9 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.9 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.9 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.9 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.9 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.9 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.9 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 632.9 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.0 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.0 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.0 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.0 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.0 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.0 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.0 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.0 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.0 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.0 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.1 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.1 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.1 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.1 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.1 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.1 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.1 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.1 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.1 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.1 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.2 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.3 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.4 MB 1.2 MB/s eta 0:00:37\r",
+ "\u001b[K |██████████████████████████████ | 633.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.5 MB 1.2 MB/s eta 0:00:36"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████████ | 633.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.7 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.7 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.7 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.7 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.7 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.7 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.7 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.7 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.7 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.7 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.8 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.8 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.8 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.8 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.8 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.8 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.8 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.8 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.8 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.8 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.9 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.9 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.9 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.9 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.9 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.9 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.9 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.9 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.9 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 633.9 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.0 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.0 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.0 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.0 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.0 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.0 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.0 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.0 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.0 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.1 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.1 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.1 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.1 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.1 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.1 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.1 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.1 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.1 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.1 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.2 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.2 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.2 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.2 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.2 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.2 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.2 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.2 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.2 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.2 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.3 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.3 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.3 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.3 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.3 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.3 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.3 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.3 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.3 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.3 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.4 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.5 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.6 MB 1.2 MB/s eta 0:00:36\r",
+ "\u001b[K |██████████████████████████████ | 634.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.9 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.9 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.9 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.9 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.9 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.9 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.9 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.9 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 634.9 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.0 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.0 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.0 MB 1.2 MB/s eta 0:00:35"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████████ | 635.0 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.0 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.0 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.0 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.0 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.0 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.0 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.1 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.1 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.1 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.1 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.1 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.1 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.1 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.1 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.1 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.1 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.2 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.2 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.2 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.2 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.2 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.2 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.2 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.2 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.2 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.2 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.3 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.3 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.3 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.3 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.3 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.3 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.3 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.3 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.3 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.4 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.4 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.4 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.4 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.4 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.4 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.4 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.4 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.4 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.4 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.5 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.5 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.5 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.5 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.5 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.5 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.5 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.5 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.5 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.5 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.6 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.7 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.8 MB 1.2 MB/s eta 0:00:35\r",
+ "\u001b[K |██████████████████████████████ | 635.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 635.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.1 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.1 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.1 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.1 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.1 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.1 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.1 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.1 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.1 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.1 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.2 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.2 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.2 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.2 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.2 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.2 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.2 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.2 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.2 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.3 MB 1.2 MB/s eta 0:00:34"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████████ | 636.3 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.3 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.3 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.3 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.3 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.3 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.3 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.3 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.3 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.4 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.4 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.4 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.4 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.4 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.4 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.4 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.4 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.4 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.4 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.5 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.5 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.5 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.5 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.5 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.5 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.5 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.5 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.5 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.5 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.6 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.6 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.6 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.6 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.6 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.6 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.6 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.6 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.6 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.7 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.7 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.7 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.7 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.7 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.7 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.7 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.7 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.7 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.7 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.8 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████ | 636.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████▏ | 636.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████▏ | 636.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████▏ | 636.9 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████▏ | 637.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████▏ | 637.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████▏ | 637.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████▏ | 637.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████▏ | 637.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████▏ | 637.0 MB 1.2 MB/s eta 0:00:34\r",
+ "\u001b[K |██████████████████████████████▏ | 637.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.3 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.3 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.3 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.3 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.3 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.3 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.3 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.3 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.3 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.3 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.4 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.4 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.4 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.4 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.4 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.4 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.4 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.4 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.4 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.5 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.5 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.5 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.5 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.5 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.5 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.5 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.5 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.5 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.5 MB 1.2 MB/s eta 0:00:33"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████████▏ | 637.6 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.6 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.6 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.6 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.6 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.6 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.6 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.6 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.6 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.6 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.7 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.7 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.7 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.7 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.7 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.7 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.7 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.7 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.7 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.7 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.8 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.8 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.8 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.8 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.8 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.8 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.8 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.8 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.8 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.8 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.9 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.9 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.9 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.9 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.9 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.9 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.9 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.9 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 637.9 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.0 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.1 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.2 MB 1.2 MB/s eta 0:00:33\r",
+ "\u001b[K |██████████████████████████████▏ | 638.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.5 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.5 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.5 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.5 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.5 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.5 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.5 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.5 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.5 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.5 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.6 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.6 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.6 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.6 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.6 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.6 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.6 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.6 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.6 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.6 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.7 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.7 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.7 MB 1.2 MB/s eta 0:00:32"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████████▏ | 638.7 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.7 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.7 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.7 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.7 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.7 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.8 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.8 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.8 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.8 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.8 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.8 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.8 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.8 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.8 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.8 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.9 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.9 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.9 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.9 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.9 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.9 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.9 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.9 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.9 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 638.9 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.0 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.0 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.0 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.0 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.0 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.0 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.0 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.0 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.0 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.0 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.1 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.1 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.1 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.1 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.1 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.1 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.1 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.1 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.1 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.2 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▏ | 639.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.3 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.4 MB 1.2 MB/s eta 0:00:32\r",
+ "\u001b[K |██████████████████████████████▎ | 639.4 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.4 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.7 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.7 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.7 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.7 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.7 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.7 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.7 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.7 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.7 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.7 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.8 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.8 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.8 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.8 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.8 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.8 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.8 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.8 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.8 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.8 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.9 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.9 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.9 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.9 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.9 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.9 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.9 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.9 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.9 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 639.9 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.0 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.0 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.0 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.0 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.0 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.0 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.0 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.0 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.0 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.1 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.1 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.1 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.1 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.1 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.1 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.1 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.1 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.1 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.1 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.2 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.2 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.2 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.2 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.2 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.2 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.2 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.2 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.2 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.2 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.3 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.3 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.3 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.3 MB 1.2 MB/s eta 0:00:31"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████████▎ | 640.3 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.3 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.3 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.3 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.3 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.3 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.4 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.4 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.4 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.4 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.4 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.4 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.4 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.4 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.4 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.5 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.6 MB 1.2 MB/s eta 0:00:31\r",
+ "\u001b[K |██████████████████████████████▎ | 640.6 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.9 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.9 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.9 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.9 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.9 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.9 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.9 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.9 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 640.9 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.0 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.0 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.0 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.0 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.0 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.0 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.0 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.0 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.0 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.0 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.1 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.1 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.1 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.1 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.1 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.1 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.1 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.1 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.1 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.1 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.2 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.2 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.2 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.2 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.2 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.2 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.2 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.2 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.2 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.2 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.3 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.3 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.3 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.3 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.3 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.3 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.3 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.3 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.3 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.4 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.4 MB 1.2 MB/s eta 0:00:30"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████████▎ | 641.4 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.4 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.4 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.4 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.4 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.4 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.4 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.4 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.5 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.5 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.5 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.5 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.5 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.5 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.5 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.5 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.5 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.5 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.6 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.6 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.6 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.6 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.6 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.6 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▎ | 641.6 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.6 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.6 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.6 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.7 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.8 MB 1.2 MB/s eta 0:00:30\r",
+ "\u001b[K |██████████████████████████████▍ | 641.9 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 641.9 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 641.9 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 641.9 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 641.9 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 641.9 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 641.9 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 641.9 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 641.9 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 641.9 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.0 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.0 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.0 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.0 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.0 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.0 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.0 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.0 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.0 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.0 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.1 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.1 MB 1.2 MB/s eta 0:00:29\r",
+ "\u001b[K |██████████████████████████████▍ | 642.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.3 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.3 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.3 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.3 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.3 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.3 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.3 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.3 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.3 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.3 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.4 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.4 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.4 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.4 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.4 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.4 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.4 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.4 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.4 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.4 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.5 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.5 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.5 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.5 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.5 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.5 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.5 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.5 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.5 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.5 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.6 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.6 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.6 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.6 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.6 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.6 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.6 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.6 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.6 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.7 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.7 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.7 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.7 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.7 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.7 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.7 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.7 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.7 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.7 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.8 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.8 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.8 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.8 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.8 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.8 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.8 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.8 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.8 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.8 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.9 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.9 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.9 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.9 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.9 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.9 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.9 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.9 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.9 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 642.9 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.0 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.0 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.0 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.0 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.0 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.0 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.0 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.0 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.0 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.1 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.2 MB 1.3 MB/s eta 0:00:26\r",
+ "\u001b[K |██████████████████████████████▍ | 643.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643."
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.6 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.6 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.6 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.6 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.6 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.6 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.6 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.6 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.6 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.6 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.7 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.7 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.7 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.7 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.7 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.7 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.7 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.7 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.7 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.7 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.8 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.8 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.8 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.8 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.8 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.8 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.8 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.8 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.8 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.9 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.9 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.9 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.9 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.9 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.9 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.9 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.9 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.9 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 643.9 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 644.0 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▍ | 644.0 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.0 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.0 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.0 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.0 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.0 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.0 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.0 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.0 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.1 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.1 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.1 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.1 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.1 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.1 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.1 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.1 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.1 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.1 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.2 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.3 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.4 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.5 MB 1.3 MB/s eta 0:00:25\r",
+ "\u001b[K |██████████████████████████████▌ | 644.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.6 MB 1.3 MB/s eta 0:00:24"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████████▌ | 644.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 644.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.0 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.0 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.0 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.0 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.0 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.0 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.0 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.0 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.0 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.0 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.1 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.1 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.1 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.1 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.1 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.1 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.1 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.1 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.1 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.2 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.2 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.2 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.2 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.2 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.2 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.2 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.2 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.2 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.2 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.3 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.3 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.3 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.3 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.3 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.3 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.3 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.3 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.3 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.3 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.4 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.4 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.4 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.4 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.4 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.4 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.4 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.4 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.4 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.4 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.5 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.5 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.5 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.5 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.5 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.5 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.5 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.5 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.5 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.6 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.7 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.8 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.9 MB 1.3 MB/s eta 0:00:24\r",
+ "\u001b[K |██████████████████████████████▌ | 645.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 645.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 645.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 645.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 645.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.1 MB 1.3 MB/s eta 0:00:23"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████████▌ | 646.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.3 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.3 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.3 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.3 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.3 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.3 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▌ | 646.3 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.3 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.3 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.3 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.4 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.4 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.4 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.4 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.4 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.4 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.4 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.4 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.4 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.5 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.5 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.5 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.5 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.5 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.5 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.5 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.5 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.5 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.5 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.6 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.6 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.6 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.6 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.6 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.6 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.6 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.6 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.6 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.6 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.7 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.7 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.7 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.7 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.7 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.7 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.7 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.7 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.7 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.7 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.8 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.8 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.8 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.8 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.8 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.8 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.8 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.8 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.8 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 646.9 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.0 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.1 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.2 MB 1.3 MB/s eta 0:00:23\r",
+ "\u001b[K |██████████████████████████████▋ | 647.2 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.7 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.7 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.7 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.7 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.7 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.7 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.7 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.7 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.7 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.8 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.8 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.8 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.8 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.8 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.8 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.8 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.8 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.8 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.8 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.9 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.9 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.9 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.9 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.9 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.9 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.9 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.9 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.9 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 647.9 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.0 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.0 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.0 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.0 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.0 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.0 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.0 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.0 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.0 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.0 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.1 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.1 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.1 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.1 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.1 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.1 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.1 MB 1.3 MB/s eta 0:00:22"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████████▋ | 648.1 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.1 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.2 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.2 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.2 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.2 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.2 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.2 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.2 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.2 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.2 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.2 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.3 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.4 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.5 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.6 MB 1.3 MB/s eta 0:00:22\r",
+ "\u001b[K |██████████████████████████████▋ | 648.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▋ | 648.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▋ | 648.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▋ | 648.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▋ | 648.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▋ | 648.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▋ | 648.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 648.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.0 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.0 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.0 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.0 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.0 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.0 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.0 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.0 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.0 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.1 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.1 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.1 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.1 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.1 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.1 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.1 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.1 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.1 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.1 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.2 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.2 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.2 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.2 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.2 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.2 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.2 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.2 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.2 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.2 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.3 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.3 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |████▌ | 94.7 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.8 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 94.9 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.0 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.1 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.2 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.3 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:24\r",
- "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.8 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 95.9 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.0 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.1 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.2 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.3 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▌ | 96.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.4 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.5 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:23"
+ " |██████████████████████████████▊ | 649.3 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.3 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.3 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.3 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.3 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.3 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.3 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.3 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.4 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.4 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.4 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.4 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.4 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.4 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.4 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.4 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.4 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.5 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.5 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.5 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.5 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.5 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.5 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.5 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.5 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.5 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.5 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.6 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.7 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.8 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.9 MB 1.3 MB/s eta 0:00:21\r",
+ "\u001b[K |██████████████████████████████▊ | 649.9 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.4 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.4 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.4 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.4 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.4 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.4 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.4 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.4 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.4 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.4 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.5 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.5 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.5 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.5 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.5 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.5 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.5 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.5 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.5 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.5 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.6 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.6 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.6 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.6 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.6 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.6 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.6 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.6 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.6 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.6 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.7 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.7 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.7 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.7 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.7 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.7 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.7 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.7 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.7 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.8 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.8 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.8 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.8 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.8 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.8 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.8 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.8 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.8 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.8 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.9 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.9 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.9 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.9 MB 1.3 MB/s eta 0:00:20"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████████▊ | 650.9 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.9 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.9 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.9 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.9 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 650.9 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 651.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 651.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 651.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 651.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 651.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 651.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▊ | 651.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.0 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.1 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.2 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.3 MB 1.3 MB/s eta 0:00:20\r",
+ "\u001b[K |██████████████████████████████▉ | 651.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.7 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.7 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.7 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.7 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.7 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.7 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.7 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.7 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.7 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.7 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.8 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.8 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.8 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.8 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.8 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.8 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.8 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.8 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.8 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.8 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.9 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.9 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.9 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.9 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.9 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.9 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.9 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.9 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 651.9 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.0 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.0 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.0 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.0 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.0 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.0 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.0 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.0 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.0 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.0 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.1 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.1 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.1 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.1 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.1 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.1 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.1 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.1 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.1 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.1 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.2 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.2 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.2 MB 1.3 MB/s eta 0:00:19"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████████▉ | 652.2 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.2 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.2 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.2 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.2 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.2 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.2 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.3 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.4 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.5 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.6 MB 1.3 MB/s eta 0:00:19\r",
+ "\u001b[K |██████████████████████████████▉ | 652.6 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.6 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 652.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.1 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.1 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.1 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.1 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.1 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.1 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.1 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.1 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.1 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.1 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.2 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.2 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.2 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.2 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.2 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.2 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.2 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.2 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.2 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.3 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.3 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.3 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.3 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.3 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.3 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.3 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.3 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.3 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.3 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.4 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |██████████████████████████████▉ | 653.4 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.4 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.4 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.4 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.4 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.4 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.4 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.4 MB 1.3 MB/s eta 0:00:18"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████ | 653.4 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.5 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.5 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.5 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.5 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.5 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.5 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.5 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.5 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.5 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.5 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.6 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.6 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.6 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.6 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.6 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.6 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.6 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.6 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.6 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.6 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.7 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.8 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 653.9 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 654.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 654.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 654.0 MB 1.3 MB/s eta 0:00:18\r",
+ "\u001b[K |███████████████████████████████ | 654.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.4 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.4 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.4 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.4 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.4 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.4 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.4 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.4 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.4 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.4 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.5 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.5 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.5 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.5 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.5 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.5 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.5 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.5 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.5 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.6 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.6 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.6 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.6 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.6 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.6 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.6 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.6 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.6 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.6 MB 1.3 MB/s eta 0:00:17"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████ | 654.7 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.7 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.7 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.7 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.7 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.7 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.7 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.7 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.7 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.7 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.8 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.8 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.8 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.8 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.8 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.8 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.8 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.8 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.8 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.8 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.9 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.9 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.9 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.9 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.9 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.9 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.9 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.9 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 654.9 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.0 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.1 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.2 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.3 MB 1.3 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 655.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.7 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.7 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.7 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.7 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.7 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.7 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.7 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.7 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.7 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.7 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.8 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.8 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.8 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.8 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.8 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.8 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.8 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.8 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.8 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.9 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.9 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.9 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.9 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.9 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.9 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.9 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.9 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.9 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 655.9 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.0 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.0 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.0 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.0 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.0 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.0 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.0 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.0 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.0 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.0 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.1 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.1 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.1 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.1 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.1 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.1 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.1 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.1 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.1 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.1 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.2 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.2 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.2 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.2 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.2 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.2 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.2 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.2 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.2 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.3 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.4 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.5 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.6 MB 1.3 MB/s eta 0:00:16"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████ | 656.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.6 MB 1.3 MB/s eta 0:00:16"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████ | 656.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.6 MB 1.3 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 656.7 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.7 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.7 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.7 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.7 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.7 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.7 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.7 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.7 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.7 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.8 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.8 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.8 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.8 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.8 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.8 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.8 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.8 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.8 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.8 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.9 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.9 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.9 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.9 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.9 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.9 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.9 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.9 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.9 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 656.9 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.0 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.0 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.0 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.0 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.0 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.0 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.0 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.0 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.0 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.0 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.1 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.1 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.1 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.1 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.1 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.1 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.1 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.1 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.1 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.2 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.2 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.2 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.2 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.2 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |████████�"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.6 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:23\r",
- "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 96.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.0 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.1 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.2 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.3 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.4 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.5 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:22"
+ "��██████████████████████ | 657.2 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.2 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.2 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.2 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.2 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.3 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.3 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.3 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.3 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.3 MB 1.2 MB/s eta 0:00:17\r",
+ "\u001b[K |███████████████████████████████ | 657.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.6 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.6 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.6 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.6 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.6 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.6 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.6 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.6 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.6 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.6 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.7 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.7 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.7 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.7 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.7 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.7 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.7 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.7 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.7 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.7 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.8 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.8 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.8 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.8 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.8 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.8 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.8 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.8 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.8 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.8 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.9 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.9 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.9 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.9 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.9 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.9 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.9 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.9 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 657.9 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 658.0 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 658.0 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 658.0 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 658.0 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 658.0 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 658.0 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 658.0 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 658.0 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 658.0 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 658.0 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 658.1 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████ | 658.1 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.1 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.1 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.1 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.1 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.1 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.1 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.1 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.1 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.2 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.2 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.2 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.2 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.2 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.2 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.2 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.2 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.2 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.2 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.3 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.4 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.5 MB 1.2 MB/s eta 0:00:16\r",
+ "\u001b[K |███████████████████████████████▏| 658.5 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.5 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.8 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.8 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.8 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.8 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.8 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.8 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.8 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.8 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.8 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.9 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.9 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.9 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.9 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.9 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.9 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.9 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.9 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.9 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 658.9 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.0 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.0 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.0 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.0 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.0 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.0 MB 1.2 MB/s eta 0:00:15"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████▏| 659.0 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.0 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.0 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.0 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.1 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.1 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.1 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.1 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.1 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.1 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.1 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.1 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.1 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.1 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.2 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.2 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.2 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.2 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.2 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.2 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.2 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.2 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.2 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.3 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.3 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.3 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.3 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.3 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.3 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.3 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.3 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.3 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.3 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.4 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.4 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.4 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.4 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.4 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.4 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.4 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.4 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.4 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.4 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.5 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.5 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.5 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.5 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.5 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.5 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.5 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.5 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.5 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.5 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.6 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.7 MB 1.2 MB/s eta 0:00:15\r",
+ "\u001b[K |███████████████████████████████▏| 659.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 659.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.1 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.1 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.1 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.1 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.1 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.1 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.1 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.1 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.1 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.2 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.2 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.2 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.2 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.2 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.2 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.2 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.2 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.2 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.2 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.3 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.3 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.3 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.3 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.3 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.3 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.3 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.3 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.3 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.3 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.4 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.4 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.4 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.4 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.4 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.4 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▏| 660.4 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.4 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.4 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.4 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.5 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.5 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.5 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.5 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.5 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.5 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.5 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.5 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.5 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.6 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.6 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.6 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.6 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.6 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.6 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.6 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.6 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.6 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.6 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.7 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.7 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.7 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.7 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.7 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.7 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.7 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.7 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.7 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.7 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.8 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 660.9 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 661.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 661.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 661.0 MB 1.2 MB/s eta 0:00:14\r",
+ "\u001b[K |███████████████████████████████▎| 661.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.0 MB 1.2 MB/s eta 0:00:13"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████▎| 661.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.3 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.3 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.3 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.3 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.3 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.3 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.3 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.3 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.3 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.4 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.4 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.4 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.4 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.4 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.4 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.4 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.4 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.4 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.4 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.5 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.5 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.5 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.5 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.5 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.5 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.5 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.5 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.5 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.5 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.6 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.6 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.6 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.6 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.6 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.6 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.6 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.6 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.6 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.6 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.7 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.7 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.7 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.7 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.7 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.7 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.7 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.7 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.7 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.7 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.8 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.8 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.8 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.8 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.8 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.8 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.8 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.8 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.8 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.9 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.9 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.9 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.9 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.9 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.9 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.9 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.9 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.9 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 661.9 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.0 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.1 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.2 MB 1.2 MB/s eta 0:00:13\r",
+ "\u001b[K |███████████████████████████████▎| 662.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.5 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.5 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.5 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.5 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.5 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.5 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.5 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.5 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.5 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.5 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.6 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.6 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.6 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.6 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.6 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.6 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.6 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.6 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.6 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.7 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.7 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.7 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.7 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.7 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.7 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.7 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.7 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.7 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.7 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.8 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.8 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▎| 662.8 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.8 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.8 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.8 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.8 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.8 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.8 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.8 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.9 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.9 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.9 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.9 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.9 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.9 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.9 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.9 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.9 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 662.9 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.0 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.0 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.0 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.0 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.0 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.0 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.0 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.0 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.0 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.1 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.1 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.1 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.1 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.1 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.1 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.1 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.1 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.1 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.1 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.2 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.6 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.7 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.8 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.9 MB 1.3 MB/s eta 0:07:22\r",
- "\u001b[K |████▋ | 97.9 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 97.9 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 97.9 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 97.9 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 97.9 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.0 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.0 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.0 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.0 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.0 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.0 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.0 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.0 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.0 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.0 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.1 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.1 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.1 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.1 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.1 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.1 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.1 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.1 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.1 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.2 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.2 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.2 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.2 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.2 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.2 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.2 MB 1.2 MB/s eta 0:07:47\r",
- "\u001b[K |████▋ | 98.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.5 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.5 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.5 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.5 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.5 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.5 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.5 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.5 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.5 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.5 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.6 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.6 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.6 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.6 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.6 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.6 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.6 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.6 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.6 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.7 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.7 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.7 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.7 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.7 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▋ | 98.7 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.7 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.7 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.7 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.7 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.8 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.8 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.8 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.8 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.8 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.8 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.8 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.8 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.8 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.8 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.9 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.9 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.9 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.9 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.9 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.9 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.9 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.9 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.9 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 98.9 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.0 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.0 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.0 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.0 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.0 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.0 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.0 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.0 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.0 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.1 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.1 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.1 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.1 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.1 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.1 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.1 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.1 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.1 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.1 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.2 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.3 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.4 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.5 MB 1.2 MB/s eta 0:07:46\r",
- "\u001b[K |████▊ | 99.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.6 MB 1.2 MB/s eta 0:07:45"
+ " |███████████████████████████████▍| 663.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.3 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.4 MB 1.2 MB/s eta 0:00:12\r",
+ "\u001b[K |███████████████████████████████▍| 663.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.7 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.7 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.7 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.7 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.7 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.7 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.7 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.7 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.7 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.7 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.8 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.8 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.8 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.8 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.8 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.8 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.8 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.8 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.8 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.8 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.9 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.9 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.9 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.9 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.9 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.9 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.9 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.9 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 663.9 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.0 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.0 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.0 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.0 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.0 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.0 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.0 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.0 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.0 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.0 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.1 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.1 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.1 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.1 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.1 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.1 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.1 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.1 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.1 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.1 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.2 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.2 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.2 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.2 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.2 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.2 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.2 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.2 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.2 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.2 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.3 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.3 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.3 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.3 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.3 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.3 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.3 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.3 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.3 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.4 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.5 MB 1.2 MB/s eta 0:00:11"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████▍| 664.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.5 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.6 MB 1.2 MB/s eta 0:00:11\r",
+ "\u001b[K |███████████████████████████████▍| 664.6 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.9 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.9 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.9 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.9 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.9 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.9 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.9 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.9 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.9 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 664.9 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.0 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.0 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.0 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.0 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.0 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.0 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.0 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.0 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.0 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.0 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.1 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.1 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.1 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.1 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.1 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.1 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▍| 665.1 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.1 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.1 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.1 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.2 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.2 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.2 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.2 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.2 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.2 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.2 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.2 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.2 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.3 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.3 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.3 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.3 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.3 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.3 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.3 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.3 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.3 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.3 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.4 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.4 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.4 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.4 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.4 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.4 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.4 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.4 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.4 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.4 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.5 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.5 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.5 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.5 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.5 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.5 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.5 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.5 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.5 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.5 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.6 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.6 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.6 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.6 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.6 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.6 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.6 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.6 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.6 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.7 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.8 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.9 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.9 MB 1.2 MB/s eta 0:00:10\r",
+ "\u001b[K |███████████████████████████████▌| 665.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 665.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 665.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 665.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 665.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 665.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 665.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 665.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.2 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.2 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.2 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.2 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.2 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.2 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.2 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.2 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.2 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.2 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.3 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.3 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.3 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.3 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.3 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.3 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.3 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.3 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.3 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.3 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.4 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.4 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.4 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.4 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.4 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.4 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.4 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.4 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.4 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.4 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.5 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.5 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.5 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.5 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.5 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.5 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.5 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.5 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.5 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.6 MB 1.2 MB/s eta 0:00:09"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████▌| 666.6 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.6 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.6 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.6 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.6 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.6 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.6 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.6 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.6 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.7 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.7 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.7 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.7 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.7 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.7 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.7 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.7 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.7 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.7 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.8 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.8 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.8 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.8 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.8 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.8 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.8 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.8 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.8 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.8 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 666.9 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.0 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.1 MB 1.2 MB/s eta 0:00:09\r",
+ "\u001b[K |███████████████████████████████▌| 667.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.4 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.4 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.4 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.4 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.4 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.4 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.4 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.4 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.4 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.4 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.5 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.5 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▌| 667.5 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.5 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.5 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.5 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.5 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.5 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.5 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.5 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.6 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.6 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.6 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.6 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.6 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.6 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.6 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.6 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.6 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.6 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.7 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.7 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.7 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.7 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.7 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.7 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.7 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.7 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.7 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.8 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.8 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.8 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.8 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.8 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.8 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.8 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.8 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.8 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.8 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.9 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.9 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.9 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.9 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.9 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.9 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.9 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.9 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.9 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 667.9 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.0 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.0 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.0 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.0 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.0 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.0 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.0 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.0 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.0 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.0 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.1 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.2 MB 1.2 MB/s eta 0:00:08"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████▋| 668.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.2 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.3 MB 1.2 MB/s eta 0:00:08\r",
+ "\u001b[K |███████████████████████████████▋| 668.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.6 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.6 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.6 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.6 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.6 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.6 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.6 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.6 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.6 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.7 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.7 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.7 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.7 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.7 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.7 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.7 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.7 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.7 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.7 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.8 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.8 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.8 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.8 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.8 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.8 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.8 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.8 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.8 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.8 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.9 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.9 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.9 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.9 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.9 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.9 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.9 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.9 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.9 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 668.9 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.0 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.0 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.0 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.0 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.0 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.0 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.0 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.0 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.0 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.1 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.1 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.1 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.1 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.1 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.1 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.1 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.1 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.1 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.1 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.2 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.2 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.2 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.2 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.2 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.2 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.2 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.2 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.2 MB 1.2 MB/s eta 0:00:07"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████▋| 669.2 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.3 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.4 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.5 MB 1.2 MB/s eta 0:00:07\r",
+ "\u001b[K |███████████████████████████████▋| 669.5 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.8 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.8 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.8 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.8 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.8 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.8 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▋| 669.8 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 669.8 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 669.8 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 669.8 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 669.9 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 669.9 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 669.9 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 669.9 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 669.9 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 669.9 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 669.9 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 669.9 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 669.9 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.0 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.0 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.0 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.0 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.0 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.0 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.0 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.0 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.0 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.0 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.1 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.1 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.1 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.1 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.1 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.1 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.1 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.1 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.1 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.1 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.2 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.2 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.2 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.2 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.2 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.2 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.2 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.2 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.2 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.2 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.3 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.3 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.3 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.3 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.3 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.3 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.3 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.3 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.3 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.4 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.4 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.4 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.4 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.4 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.4 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.4 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.4 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.4 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.4 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.5 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.5 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.5 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.5 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.5 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.5 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.5 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.5 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.5 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.5 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.6 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.7 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.8 MB 1.2 MB/s eta 0:00:06\r",
+ "\u001b[K |███████████████████████████████▊| 670.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 670.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.1 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.1 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.1 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.1 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.1 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.1 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.1 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.1 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.1 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.2 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.2 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.2 MB 1.2 MB/s eta 0:00:05"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████▊| 671.2 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.2 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.2 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.2 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.2 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.2 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.2 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.3 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.3 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.3 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.3 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.3 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.3 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.3 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.3 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.3 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.3 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.4 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.4 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.4 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.4 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.4 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.4 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.4 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.4 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.4 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.4 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.5 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.5 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.5 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.5 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.5 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.5 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.5 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.5 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.5 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.5 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.6 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.6 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.6 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.6 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.6 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.6 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.6 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.6 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.6 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.7 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.7 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.7 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.7 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.7 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.7 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.7 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.7 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.7 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.7 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.8 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 671.9 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 672.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 672.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 672.0 MB 1.2 MB/s eta 0:00:05\r",
+ "\u001b[K |███████████████████████████████▊| 672.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.2 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.2 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▊| 672.2 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.2 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.2 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.2 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.2 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.2 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.2 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.2 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.3 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.3 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.3 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.3 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.3 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.3 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.3 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.3 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.3 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.3 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.4 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.4 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.4 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.4 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.4 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.4 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.4 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.4 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.4 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.5 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.5 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.5 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.5 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.5 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.5 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.5 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.5 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.5 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.5 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.6 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.6 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.6 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.6 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.6 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.6 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.6 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.6 MB 1.2 MB/s eta 0:00:04"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████▉| 672.6 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.6 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.7 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.7 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.7 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.7 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.7 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.7 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.7 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.7 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.7 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.7 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.8 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.8 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.8 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.8 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.8 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.8 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.8 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.8 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.8 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.8 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.9 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.9 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.9 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.9 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.9 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.9 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.9 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.9 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 672.9 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.0 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.1 MB 1.2 MB/s eta 0:00:04\r",
+ "\u001b[K |███████████████████████████████▉| 673.1 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.1 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.1 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.4 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.4 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.4 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.4 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.4 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.4 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.4 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.4 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.4 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.4 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.5 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.5 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.5 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.5 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.5 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.5 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.5 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.5 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.5 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.5 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.6 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.6 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.6 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.6 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.6 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.6 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.6 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.6 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.6 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.6 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.7 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.7 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.7 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.7 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.7 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.7 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.7 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.7 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.7 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.8 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.8 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.8 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.8 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.8 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.8 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.8 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.8 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.8 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.8 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.9 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.9 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.9 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.9 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.9 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.9 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.9 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.9 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.9 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 673.9 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.0 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.0 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.0 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.0 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.0 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.0 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.0 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.0 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.0 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.0 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.1 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.1 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.1 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.1 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.1 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.1 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.1 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.1 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.1 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.2 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.3 MB 1.3 MB/s eta 0:00:03\r",
+ "\u001b[K |███████████████████████████████▉| 674.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.4 MB 1.3 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |███████████████████████████████▉| 674.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |███████████████████████████████▉| 674.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.7 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.7 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.7 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.7 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.7 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.7 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.7 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.7 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.7 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.7 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.8 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.8 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.8 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.8 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.8 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.8 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.8 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.8 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.8 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.8 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.9 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.9 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.9 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.9 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.9 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.9 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.9 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.9 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.9 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 674.9 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.0 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.0 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.0 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.0 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.0 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.0 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.0 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.0 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.0 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.1 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.1 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.1 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.1 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.1 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.1 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.1 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.1 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.1 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.1 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.2 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.2 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.2 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.2 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.2 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.2 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.2 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.2 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.2 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.2 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.3 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.4 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.5 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.6 MB 1.3 MB/s eta 0:00:02\r",
+ "\u001b[K |████████████████████████████████| 675.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.9 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.9 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.9 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.9 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.9 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.9 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.9 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.9 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 675.9 MB 1.3 MB/s eta 0:00:01"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████████| 675.9 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.0 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.0 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.0 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.0 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.0 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.0 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.0 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.0 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.0 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.0 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.1 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.1 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.1 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.1 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.1 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.1 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.1 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.1 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.1 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.1 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.2 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.2 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.2 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.2 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.2 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.2 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.2 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.2 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.2 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.2 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.3 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.3 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.3 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.3 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.3 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.3 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.3 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.3 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.3 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.4 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.4 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.4 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.4 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.4 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.4 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.4 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.4 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.4 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.4 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.5 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.5 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.5 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.5 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.5 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.5 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.5 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.5 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.5 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.5 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.6 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.7 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.8 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.9 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.9 MB 1.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 676.9 MB 1.3 MB/s eta 0:00:01"
]
},
{
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
- "\u001b[K |████▊ | 99.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.8 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.8 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.8 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.8 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.8 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.8 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.8 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.8 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.8 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.9 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.9 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.9 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.9 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.9 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.9 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.9 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.9 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.9 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 99.9 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.0 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.0 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.0 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.0 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.0 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.0 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.0 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.0 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.0 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.0 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.1 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.1 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.1 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.1 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.1 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.1 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.1 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.1 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.1 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.1 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.2 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.2 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.2 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.2 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.2 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.2 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.2 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.2 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.2 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.2 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.3 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.3 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.3 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.3 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.3 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.3 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.3 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.3 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.3 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.4 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.4 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.4 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.4 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.4 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.4 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.4 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.4 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.4 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.4 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.5 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.6 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.7 MB 1.2 MB/s eta 0:07:45\r",
- "\u001b[K |████▊ | 100.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 100.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 101.0 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 101.0 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 101.0 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 101.0 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 101.0 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 101.0 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 101.0 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 101.0 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 101.0 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 101.0 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▊ | 101.1 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.1 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.1 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.1 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.1 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.1 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.1 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.1 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.1 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.2 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.2 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.2 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.2 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.2 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.2 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.2 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.2 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.2 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.2 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.3 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.3 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.3 MB 1.2 MB/s eta 0:07:44"
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████████████| 676.9 MB 1.4 kB/s \r\n",
+ "\u001b[?25h"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Requirement already satisfied: numpy in /opt/conda/lib/python3.7/site-packages (from torch==1.1.0) (1.21.1)\r\n"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Installing collected packages: torch\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |████▉ | 101.3 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.3 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.3 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.3 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.3 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.3 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.3 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.4 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.4 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.4 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.4 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.4 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.4 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.4 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.4 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.4 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.4 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.5 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.5 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.5 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.5 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.5 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.5 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.5 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.5 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.5 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.6 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.6 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.6 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.6 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.6 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.6 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.6 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.6 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.6 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.6 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.7 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.8 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.9 MB 1.2 MB/s eta 0:07:44\r",
- "\u001b[K |████▉ | 101.9 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.3 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.3 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.3 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.3 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.3 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.3 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.3 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.3 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.3 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.3 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.4 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.4 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.4 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.4 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.4 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.4 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.4 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.4 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.4 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.5 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.5 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.5 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.5 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.5 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.5 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.5 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.5 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.5 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.5 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.6 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.6 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.6 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.6 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.6 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.6 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.6 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.6 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.6 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.6 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.7 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.7 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.7 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.7 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.7 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.7 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.7 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.7 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.7 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.7 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.8 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.8 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.8 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.8 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.8 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.8 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.8 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.8 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.8 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.9 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.9 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.9 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.9 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.9 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.9 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.9 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.9 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.9 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 102.9 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.0 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.1 MB 1.2 MB/s eta 0:07:43"
+ "Successfully installed torch-1.1.0\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |████▉ | 103.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.1 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.2 MB 1.2 MB/s eta 0:07:43\r",
- "\u001b[K |████▉ | 103.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |████▉ | 103.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.5 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.5 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.5 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.5 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.5 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.5 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.5 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.5 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.5 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.5 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.6 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.6 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.6 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.6 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.6 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.6 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.6 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.6 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.6 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.6 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.7 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.7 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.7 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.7 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.7 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.7 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.7 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.7 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.7 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.8 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.8 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.8 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.8 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.8 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.8 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.8 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.8 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.8 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.8 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.9 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.9 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.9 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.9 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.9 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.9 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.9 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.9 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.9 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 103.9 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.0 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.0 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.0 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.0 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.0 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.0 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.0 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.0 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.0 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.0 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.1 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.1 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.1 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.1 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.1 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.1 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.1 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.1 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.1 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.2 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.3 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.4 MB 1.2 MB/s eta 0:07:42\r",
- "\u001b[K |█████ | 104.4 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.4 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.4 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.7 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.7 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.7 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.7 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.7 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.7 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.7 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.7 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.7 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.7 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.8 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.8 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.8 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.8 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.8 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.8 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.8 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.8 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.8 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.8 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.9 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.9 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.9 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.9 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.9 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.9 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.9 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.9 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.9 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 104.9 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.0 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.0 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.0 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.0 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.0 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.0 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.0 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.0 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.0 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.1 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.1 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.1 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.1 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.1 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.1 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.1 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.1 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.1 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.1 MB 1.2 MB/s eta 0:07:41"
+ "\u001b[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\u001b[0m\r\n",
+ "\u001b[33mWARNING: You are using pip version 21.1.3; however, version 22.2.2 is available.\r\n",
+ "You should consider upgrading via the '/opt/conda/bin/python3 -m pip install --upgrade pip' command.\u001b[0m\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█████ | 105.2 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.2 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.2 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.2 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.2 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.2 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.2 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.2 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.2 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.2 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.3 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.3 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.3 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.3 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.3 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.3 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.3 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.3 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.3 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.3 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.4 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.4 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.4 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.4 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.4 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.4 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.4 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.4 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.4 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.5 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.6 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.7 MB 1.2 MB/s eta 0:07:41\r",
- "\u001b[K |█████ | 105.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 105.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.0 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.0 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.0 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.0 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.0 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.0 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.0 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.0 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.0 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.0 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.1 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.1 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.1 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.1 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.1 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.1 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.1 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.1 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.1 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.1 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.2 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.2 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.2 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.2 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.2 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.2 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.2 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.2 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.2 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.3 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.3 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.3 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.3 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.3 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.3 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.3 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.3 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.3 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.3 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.4 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.4 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.4 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.4 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.4 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.4 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.4 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.4 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.4 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.4 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.5 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.5 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.5 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.5 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.5 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.5 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.5 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.5 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.5 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.5 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.6 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.6 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.6 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.6 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.6 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.6 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.6 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.6 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.6 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.6 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.7 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.8 MB 1.2 MB/s eta 0:07:40"
+ "/opt/conda/lib/python3.7/site-packages/secretstorage/dhcrypto.py:16: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead\r\n",
+ " from cryptography.utils import int_from_bytes\r\n",
+ "/opt/conda/lib/python3.7/site-packages/secretstorage/util.py:25: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead\r\n",
+ " from cryptography.utils import int_from_bytes\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█████ | 106.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.8 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.9 MB 1.2 MB/s eta 0:07:40\r",
- "\u001b[K |█████ | 106.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 106.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 106.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 106.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.2 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.2 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.2 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.2 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.2 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.2 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.2 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.2 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.2 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.2 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.3 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.3 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.3 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.3 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.3 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.3 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.3 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.3 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.3 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.3 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.4 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.4 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.4 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.4 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.4 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.4 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.4 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.4 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.4 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.4 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.5 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.5 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.5 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.5 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.5 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.5 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.5 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.5 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.5 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.6 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.6 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.6 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.6 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.6 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.6 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.6 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.6 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.6 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.6 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.7 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.7 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.7 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.7 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.7 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.7 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.7 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.7 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.7 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.7 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.8 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.8 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.8 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.8 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.8 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.8 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.8 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.8 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.8 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.8 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 107.9 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.0 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████ | 108.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████▏ | 108.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████▏ | 108.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████▏ | 108.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████▏ | 108.1 MB 1.2 MB/s eta 0:07:39\r",
- "\u001b[K |█████▏ | 108.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.5 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.5 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.5 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.5 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.5 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.5 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.5 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.5 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.5 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.5 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.6 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.6 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.6 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.6 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.6 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.6 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.6 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.6 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.6 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.6 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.7 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.7 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.7 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.7 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.7 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.7 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.7 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.7 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.7 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.7 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.8 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.8 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.8 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.8 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.8 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.8 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.8 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.8 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.8 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.9 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.9 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.9 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.9 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.9 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.9 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.9 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.9 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.9 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 108.9 MB 1.2 MB/s eta 0:07:38"
+ "Collecting torchvision==0.2.2\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█████▏ | 109.0 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.0 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.0 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.0 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.0 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.0 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.0 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.0 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.0 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.0 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.1 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.1 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.1 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.1 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.1 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.1 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.1 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.1 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.1 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.1 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.2 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.3 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.4 MB 1.2 MB/s eta 0:07:38\r",
- "\u001b[K |█████▏ | 109.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.7 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.7 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.7 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.7 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.7 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.7 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.7 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.7 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.7 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.8 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.8 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.8 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.8 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.8 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.8 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.8 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.8 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.8 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.8 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.9 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.9 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.9 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.9 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.9 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.9 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.9 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.9 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.9 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 109.9 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.0 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.0 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.0 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.0 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.0 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.0 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.0 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.0 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.0 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.0 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.1 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.1 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.1 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.1 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.1 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.1 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.1 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.1 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.1 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.2 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.2 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.2 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.2 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.2 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.2 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.2 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.2 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.2 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.2 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.3 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.3 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.3 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.3 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.3 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.3 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.3 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.3 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.3 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.3 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.4 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▏ | 110.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.5 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.6 MB 1.2 MB/s eta 0:07:37\r",
- "\u001b[K |█████▎ | 110.6 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.6 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.9 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.9 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.9 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.9 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.9 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.9 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.9 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.9 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 110.9 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.0 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.0 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.0 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.0 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.0 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.0 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.0 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.0 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.0 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.0 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.1 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.1 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.1 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.1 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.1 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.1 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.1 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.1 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.1 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.1 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.2 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.2 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.2 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.2 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.2 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.2 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.2 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.2 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.2 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.2 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.3 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.3 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.3 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.3 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.3 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.3 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.3 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.3 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.3 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.3 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.4 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.4 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.4 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.4 MB 1.2 MB/s eta 0:07:36"
+ " Downloading torchvision-0.2.2-py2.py3-none-any.whl (64 kB)\r\n",
+ "\u001b[?25l\r",
+ "\u001b[K |█████ | 10 kB 5.1 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████▏ | 20 kB 3.1 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████▎ | 30 kB 2.4 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████▍ | 40 kB 2.7 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████▌ | 51 kB 3.0 MB/s eta 0:00:01"
]
},
{
@@ -11471,62293 +69407,3624 @@
"output_type": "stream",
"text": [
"\r",
- "\u001b[K |█████▎ | 111.4 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.4 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.4 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.4 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.4 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.5 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.5 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.5 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.5 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.5 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.5 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.5 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.5 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.5 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.5 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.6 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.6 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.6 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.6 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.6 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.6 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.6 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.6 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.6 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.6 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.7 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.8 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.9 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.9 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.9 MB 1.2 MB/s eta 0:07:36\r",
- "\u001b[K |█████▎ | 111.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 111.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 111.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 111.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 111.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 111.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 111.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.2 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.2 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.2 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.2 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.2 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.2 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.2 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.2 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.2 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.3 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.3 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.3 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.3 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.3 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.3 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.3 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.3 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.3 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.3 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.4 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.4 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.4 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.4 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.4 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.4 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.4 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.4 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.4 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.4 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.5 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.5 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.5 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.5 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.5 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.5 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.5 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.5 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.5 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.5 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.6 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.6 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.6 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.6 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.6 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.6 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.6 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.6 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.6 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.7 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.7 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.7 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.7 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.7 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.7 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.7 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.7 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.7 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.7 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.8 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.8 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.8 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.8 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.8 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▎ | 112.8 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.8 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.8 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.8 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.8 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 112.9 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.0 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.1 MB 1.2 MB/s eta 0:07:35\r",
- "\u001b[K |█████▍ | 113.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.2 MB 1.2 MB/s eta 0:07:34"
+ "\u001b[K |██████████████████████████████▋ | 61 kB 3.2 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 64 kB 2.0 MB/s \r\n",
+ "\u001b[?25h"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█████▍ | 113.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.4 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.4 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.4 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.4 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.4 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.4 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.4 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.4 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.4 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.4 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.5 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.5 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.5 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.5 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.5 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.5 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.5 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.5 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.5 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.6 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.6 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.6 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.6 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.6 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.6 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.6 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.6 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.6 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.6 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.7 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.7 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.7 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.7 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.7 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.7 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.7 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.7 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.7 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.7 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.8 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.8 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.8 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.8 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.8 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.8 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.8 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.8 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.8 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.8 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.9 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.9 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.9 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.9 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.9 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.9 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.9 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.9 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 113.9 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.0 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.0 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.0 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.0 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.0 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.0 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.0 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.0 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.0 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.0 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.1 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.2 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.3 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.4 MB 1.2 MB/s eta 0:07:34\r",
- "\u001b[K |█████▍ | 114.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.7 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.7 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.7 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.7 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.7 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.7 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.7 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.7 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.7 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.7 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.8 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.8 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.8 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.8 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.8 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.8 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.8 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.8 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.8 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.9 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.9 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.9 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.9 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.9 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.9 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.9 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.9 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.9 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 114.9 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.0 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.0 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.0 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.0 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.0 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.0 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.0 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.0 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.0 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.0 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.1 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.1 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.1 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.1 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.1 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.1 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.1 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.1 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.1 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.1 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▍ | 115.2 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.2 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.2 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.2 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.2 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.2 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.2 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.2 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.2 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.3 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.3 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.3 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.3 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.3 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.3 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.3 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.3 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.3 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.3 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.4 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.5 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.6 MB 1.2 MB/s eta 0:07:33\r",
- "\u001b[K |█████▌ | 115.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.9 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.9 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.9 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.9 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.9 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.9 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.9 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.9 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.9 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 115.9 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.0 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.0 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.0 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.0 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.0 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.0 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.0 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.0 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.0 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.0 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.1 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.1 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.1 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.1 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.1 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.1 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.1 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.1 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.1 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.2 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.2 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.2 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.2 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.2 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.2 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.2 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.2 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.2 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.2 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.3 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.3 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.3 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.3 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.3 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.3 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.3 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.3 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.3 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.3 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.4 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.4 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.4 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.4 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.4 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.4 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.4 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.4 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.4 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.4 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.5 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.5 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.5 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.5 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.5 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.5 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.5 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.5 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.5 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.6 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.7 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.8 MB 1.2 MB/s eta 0:07:32\r",
- "\u001b[K |█████▌ | 116.8 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 116.9 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 116.9 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 116.9 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K"
+ "Collecting tqdm==4.19.9\r\n",
+ " Downloading tqdm-4.19.9-py2.py3-none-any.whl (52 kB)\r\n",
+ "\u001b[?25l\r",
+ "\u001b[K |██████▏ | 10 kB 21.1 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████▍ | 20 kB 7.3 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████▋ | 30 kB 10.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████▉ | 40 kB 7.8 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████████ | 51 kB 8.3 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 52 kB 1.7 MB/s \r\n",
+ "\u001b[?25hRequirement already satisfied: numpy in /opt/conda/lib/python3.7/site-packages (from torchvision==0.2.2) (1.21.1)\r\n",
+ "Requirement already satisfied: six in /opt/conda/lib/python3.7/site-packages (from torchvision==0.2.2) (1.14.0)\r\n",
+ "Requirement already satisfied: torch in /opt/conda/lib/python3.7/site-packages (from torchvision==0.2.2) (1.1.0)\r\n",
+ "Requirement already satisfied: pillow>=4.1.1 in /opt/conda/lib/python3.7/site-packages (from torchvision==0.2.2) (8.3.1)\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- " |█████▌ | 116.9 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 116.9 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 116.9 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 116.9 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 116.9 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 116.9 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.0 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.0 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.0 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.0 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.0 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.0 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.0 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.0 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.0 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.0 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.1 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.1 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.1 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.1 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.1 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.1 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.1 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.1 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.1 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.1 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.2 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.2 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.2 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.2 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.2 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.2 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.2 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.2 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.2 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.2 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.3 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.3 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.3 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.3 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.3 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.3 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.3 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.3 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.3 MB 1.2 MB/s eta 0:07:31\r",
- "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.4 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.5 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.5 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.5 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.5 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.5 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▌ | 117.5 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.5 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.5 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.5 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.5 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.6 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.7 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:06:56\r",
- "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 117.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.2 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.3 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.4 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.5 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.6 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:06:55"
+ "Installing collected packages: tqdm, torchvision\r\n",
+ " Attempting uninstall: tqdm\r\n",
+ " Found existing installation: tqdm 4.42.1\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.7 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.8 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 118.9 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.0 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.1 MB 1.3 MB/s eta 0:06:55\r",
- "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.6 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.7 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.8 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▋ | 119.9 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 119.9 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.0 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.1 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.2 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.3 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.4 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:06:54\r",
- "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 120.9 MB 1.3 MB/s eta 0:06:53"
+ " Uninstalling tqdm-4.42.1:\r\n",
+ " Successfully uninstalled tqdm-4.42.1\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.0 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.1 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.2 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.3 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.4 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.5 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.6 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.7 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:06:53\r",
- "\u001b[K |█████▊ | 121.8 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:06:52"
+ "\u001b[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\r\n",
+ "papermill 2.3.4 requires tqdm>=4.32.2, but you have tqdm 4.19.9 which is incompatible.\u001b[0m\r\n",
+ "Successfully installed torchvision-0.2.2 tqdm-4.19.9\r\n",
+ "\u001b[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\u001b[0m\r\n",
+ "\u001b[33mWARNING: You are using pip version 21.1.3; however, version 22.2.2 is available.\r\n",
+ "You should consider upgrading via the '/opt/conda/bin/python3 -m pip install --upgrade pip' command.\u001b[0m\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 121.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▊ | 122.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.3 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.4 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.5 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.6 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.7 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:06:52"
+ "/opt/conda/lib/python3.7/site-packages/secretstorage/dhcrypto.py:16: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead\r\n",
+ " from cryptography.utils import int_from_bytes\r\n",
+ "/opt/conda/lib/python3.7/site-packages/secretstorage/util.py:25: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead\r\n",
+ " from cryptography.utils import int_from_bytes\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.8 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 122.9 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.0 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.1 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:06:52\r",
- "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.6 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.7 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.8 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 123.9 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.0 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.1 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.2 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.3 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.4 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:06:51\r",
- "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |█████▉ | 124.5 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |█████▉ | 124.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 124.9 MB 1.3 MB/s eta 0:06:50"
+ "Collecting pillow==6.2.2\r\n",
+ " Downloading Pillow-6.2.2-cp37-cp37m-manylinux1_x86_64.whl (2.1 MB)\r\n",
+ "\u001b[?25l\r",
+ "\u001b[K |▏ | 10 kB 25.6 MB/s eta 0:00:01\r",
+ "\u001b[K |▎ | 20 kB 17.2 MB/s eta 0:00:01"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |▌ | 30 kB 10.0 MB/s eta 0:00:01\r",
+ "\u001b[K |▋ | 40 kB 7.3 MB/s eta 0:00:01\r",
+ "\u001b[K |▉ | 51 kB 1.0 MB/s eta 0:00:03\r",
+ "\u001b[K |█ | 61 kB 1.2 MB/s eta 0:00:02\r",
+ "\u001b[K |█ | 71 kB 1.4 MB/s eta 0:00:02\r",
+ "\u001b[K |█▎ | 81 kB 1.6 MB/s eta 0:00:02\r",
+ "\u001b[K |█▍ | 92 kB 1.8 MB/s eta 0:00:02"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |█▋ | 102 kB 2.0 MB/s eta 0:00:02\r",
+ "\u001b[K |█▊ | 112 kB 2.0 MB/s eta 0:00:02\r",
+ "\u001b[K |█▉ | 122 kB 2.0 MB/s eta 0:00:02\r",
+ "\u001b[K |██ | 133 kB 2.0 MB/s eta 0:00:02\r",
+ "\u001b[K |██▏ | 143 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██▍ | 153 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██▌ | 163 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██▋ | 174 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██▉ | 184 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███ | 194 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███▏ | 204 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███▎ | 215 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███▍ | 225 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███▋ | 235 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███▊ | 245 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████ | 256 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████ | 266 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████▏ | 276 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████▍ | 286 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████▌ | 296 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████▊ | 307 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████▉ | 317 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████ | 327 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████▏ | 337 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████▎ | 348 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████▌ | 358 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████▋ | 368 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████▊ | 378 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████ | 389 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████ | 399 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████▎ | 409 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████▍ | 419 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████▋ | 430 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████▊ | 440 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████▉ | 450 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████ | 460 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████▏ | 471 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████▍ | 481 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████▌ | 491 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████▋ | 501 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████▉ | 512 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████ | 522 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████▏ | 532 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████▎ | 542 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████▍ | 552 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████▋ | 563 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████▊ | 573 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████ | 583 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████ | 593 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████▏ | 604 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████▍ | 614 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████▌ | 624 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████▊ | 634 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████▉ | 645 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████ | 655 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████▏ | 665 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████▎ | 675 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████▌ | 686 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████▋ | 696 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████▊ | 706 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████ | 716 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████ | 727 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████▎ | 737 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████▍ | 747 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████▌ | 757 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████▊ | 768 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████▉ | 778 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████ | 788 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████▏ | 798 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████▎ | 808 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████▌ | 819 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████▋ | 829 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████▉ | 839 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████ | 849 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████▏ | 860 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████▎ | 870 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████▍ | 880 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████▋ | 890 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████▊ | 901 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████ | 911 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████ | 921 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████▏ | 931 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████▍ | 942 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████▌ | 952 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████▊ | 962 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████▉ | 972 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████ | 983 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████▏ | 993 kB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████▎ | 1.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████▌ | 1.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████▋ | 1.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████▊ | 1.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████ | 1.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████ | 1.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████▎ | 1.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████▍ | 1.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████▌ | 1.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████▊ | 1.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████▉ | 1.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████ | 1.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████▏ | 1.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████▎ | 1.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████▌ | 1.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████▋ | 1.2 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████▉ | 1.2 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████ | 1.2 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████ | 1.2 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████▎ | 1.2 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████▍ | 1.2 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████▋ | 1.2 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████▊ | 1.2 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████ | 1.2 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████ | 1.2 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████▏ | 1.3 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████▍ | 1.3 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████▌ | 1.3 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████▊ | 1.3 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████▉ | 1.3 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████ | 1.3 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████▏ | 1.3 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████▎ | 1.3 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████▌ | 1.3 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████▋ | 1.4 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████▊ | 1.4 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████ | 1.4 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████ | 1.4 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████▎ | 1.4 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████▍ | 1.4 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████▌ | 1.4 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████▊ | 1.4 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████▉ | 1.4 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████ | 1.4 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████▏ | 1.5 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████▎ | 1.5 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████▌ | 1.5 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████▋ | 1.5 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████▉ | 1.5 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████ | 1.5 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████ | 1.5 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████▎ | 1.5 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████▍ | 1.5 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████▋ | 1.5 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████▊ | 1.6 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████▉ | 1.6 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████ | 1.6 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████▏ | 1.6 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████▍ | 1.6 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████▌ | 1.6 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████▋ | 1.6 MB 2.0 MB/s eta 0:00:01"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |████████████████████████▉ | 1.6 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████ | 1.6 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████▏ | 1.6 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████▎ | 1.7 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████▌ | 1.7 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████▋ | 1.7 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████▊ | 1.7 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████████ | 1.7 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████████ | 1.7 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████████▎ | 1.7 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████████▍ | 1.7 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████████▌ | 1.7 MB 2.0 MB/s eta 0:00:01"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "\r",
+ "\u001b[K |██████████████████████████▊ | 1.8 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████████▉ | 1.8 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████ | 1.8 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████▏ | 1.8 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████▎ | 1.8 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████▌ | 1.8 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████▋ | 1.8 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████▉ | 1.8 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████ | 1.8 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████ | 1.8 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████▎ | 1.9 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████▍ | 1.9 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████▋ | 1.9 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████▊ | 1.9 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████▉ | 1.9 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████ | 1.9 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▏ | 1.9 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▍ | 1.9 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▌ | 1.9 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▋ | 1.9 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |█████████████████████████████▉ | 2.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████████████ | 2.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████████████▏ | 2.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████████████▎ | 2.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████████████▍ | 2.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████████████▋ | 2.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |██████████████████████████████▊ | 2.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████████ | 2.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████████ | 2.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████████▎| 2.0 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████████▍| 2.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████████▌| 2.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████████▊| 2.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |███████████████████████████████▉| 2.1 MB 2.0 MB/s eta 0:00:01\r",
+ "\u001b[K |████████████████████████████████| 2.1 MB 2.0 MB/s \r\n",
+ "\u001b[?25h"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Installing collected packages: pillow\r\n",
+ " Attempting uninstall: pillow\r\n",
+ " Found existing installation: Pillow 8.3.1\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.0 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.1 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.2 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.3 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.4 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.5 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.6 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.7 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.8 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:06:50\r",
- "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 125.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.3 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.3 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.3 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.3 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.3 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.3 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.3 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.3 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.3 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.4 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.4 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.4 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.4 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.4 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.4 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.4 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.4 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.4 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.4 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.7 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.7 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.7 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.7 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.7 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.7 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.7 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.7 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.7 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.8 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.8 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.8 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.8 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.8 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.8 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.8 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.8 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.8 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.8 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.9 MB 1.3 MB/s eta 0:06:49"
+ " Uninstalling Pillow-8.3.1:\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██████ | 126.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 126.9 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.0 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.1 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.2 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████ | 127.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 127.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████ | 128.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 128.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.0 MB 1.3 MB/s eta 0:06:47"
+ " Successfully uninstalled Pillow-8.3.1\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██████ | 129.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████ | 129.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.8 MB 1.3 MB/s eta 0:06:47"
+ "Successfully installed pillow-6.2.2\r\n",
+ "\u001b[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\u001b[0m\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██████▏ | 129.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▏ | 129.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 129.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 129.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 130.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▏ | 131.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▏ | 131.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 131.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.0 MB 1.3 MB/s eta 0:06:45"
+ "\u001b[33mWARNING: You are using pip version 21.1.3; however, version 22.2.2 is available.\r\n",
+ "You should consider upgrading via the '/opt/conda/bin/python3 -m pip install --upgrade pip' command.\u001b[0m\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██████▎ | 132.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▎ | 132.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 132.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 133.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▎ | 134.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▍ | 134.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.2 MB 1.3 MB/s eta 0:06:43"
+ "/opt/conda/lib/python3.7/site-packages/secretstorage/dhcrypto.py:16: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead\r\n",
+ " from cryptography.utils import int_from_bytes\r\n",
+ "/opt/conda/lib/python3.7/site-packages/secretstorage/util.py:25: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead\r\n",
+ " from cryptography.utils import int_from_bytes\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██████▍ | 134.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 134.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▍ | 135.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 135.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.0 MB 1.3 MB/s eta 0:06:42"
+ "Requirement already satisfied: sagemaker in /opt/conda/lib/python3.7/site-packages (2.103.0)\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██████▍ | 136.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▍ | 136.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▌ | 136.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.5 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.6 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.7 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.7 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.7 MB 1.3 MB/s eta 0:06:49\r",
- "\u001b[K |██████▌ | 136.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 136.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.1 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.2 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.3 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.4 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.5 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.6 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.7 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.8 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 137.9 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 138.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 138.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 138.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 138.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 138.0 MB 1.3 MB/s eta 0:06:48\r",
- "\u001b[K |██████▌ | 138.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.3 MB 1.3 MB/s eta 0:06:4"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "7\r",
- "\u001b[K |██████▌ | 138.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.4 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.5 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.6 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▌ | 138.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.7 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.8 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 138.9 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.0 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.1 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.2 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.3 MB 1.3 MB/s eta 0:06:47\r",
- "\u001b[K |██████▋ | 139.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.7 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.8 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 139.9 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.0 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.1 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.2 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.3 MB 1.3 MB/s eta 0:06:46"
+ "Requirement already satisfied: smdebug-rulesconfig==1.0.1 in /opt/conda/lib/python3.7/site-packages (from sagemaker) (1.0.1)\r\n",
+ "Requirement already satisfied: google-pasta in /opt/conda/lib/python3.7/site-packages (from sagemaker) (0.2.0)\r\n",
+ "Requirement already satisfied: pandas in /opt/conda/lib/python3.7/site-packages (from sagemaker) (1.0.1)\r\n",
+ "Requirement already satisfied: pathos in /opt/conda/lib/python3.7/site-packages (from sagemaker) (0.2.8)\r\n",
+ "Requirement already satisfied: boto3<2.0,>=1.20.21 in /opt/conda/lib/python3.7/site-packages (from sagemaker) (1.20.47)\r\n",
+ "Requirement already satisfied: protobuf<4.0,>=3.1 in /opt/conda/lib/python3.7/site-packages (from sagemaker) (3.17.3)\r\n",
+ "Requirement already satisfied: attrs<22,>=20.3.0 in /opt/conda/lib/python3.7/site-packages (from sagemaker) (21.4.0)\r\n",
+ "Requirement already satisfied: numpy<2.0,>=1.9.0 in /opt/conda/lib/python3.7/site-packages (from sagemaker) (1.21.1)\r\n",
+ "Requirement already satisfied: protobuf3-to-dict<1.0,>=0.1.5 in /opt/conda/lib/python3.7/site-packages (from sagemaker) (0.1.5)\r\n",
+ "Requirement already satisfied: packaging>=20.0 in /opt/conda/lib/python3.7/site-packages (from sagemaker) (20.1)\r\n",
+ "Requirement already satisfied: importlib-metadata<5.0,>=1.4.0 in /opt/conda/lib/python3.7/site-packages (from sagemaker) (1.5.0)\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██████▋ | 140.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.3 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.4 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.5 MB 1.3 MB/s eta 0:06:46"
+ "Requirement already satisfied: jmespath<1.0.0,>=0.7.1 in /opt/conda/lib/python3.7/site-packages (from boto3<2.0,>=1.20.21->sagemaker) (0.10.0)\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██████▋ | 140.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.5 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.6 MB 1.3 MB/s eta 0:06:46\r",
- "\u001b[K |██████▋ | 140.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 140.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 141.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 141.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 141.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 141.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 141.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▋ | 141.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.1 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.2 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.3 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.4 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.5 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.6 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.7 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.8 MB 1.3 MB/s eta 0:06:45"
+ "Requirement already satisfied: s3transfer<0.6.0,>=0.5.0 in /opt/conda/lib/python3.7/site-packages (from boto3<2.0,>=1.20.21->sagemaker) (0.5.0)\r\n",
+ "Requirement already satisfied: botocore<1.24.0,>=1.23.47 in /opt/conda/lib/python3.7/site-packages (from boto3<2.0,>=1.20.21->sagemaker) (1.23.47)\r\n",
+ "Requirement already satisfied: urllib3<1.27,>=1.25.4 in /opt/conda/lib/python3.7/site-packages (from botocore<1.24.0,>=1.23.47->boto3<2.0,>=1.20.21->sagemaker) (1.26.6)\r\n",
+ "Requirement already satisfied: python-dateutil<3.0.0,>=2.1 in /opt/conda/lib/python3.7/site-packages (from botocore<1.24.0,>=1.23.47->boto3<2.0,>=1.20.21->sagemaker) (2.8.1)\r\n",
+ "Requirement already satisfied: zipp>=0.5 in /opt/conda/lib/python3.7/site-packages (from importlib-metadata<5.0,>=1.4.0->sagemaker) (2.2.0)\r\n",
+ "Requirement already satisfied: six in /opt/conda/lib/python3.7/site-packages (from packaging>=20.0->sagemaker) (1.14.0)\r\n",
+ "Requirement already satisfied: pyparsing>=2.0.2 in /opt/conda/lib/python3.7/site-packages (from packaging>=20.0->sagemaker) (2.4.6)\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██████▊ | 141.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.8 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 141.9 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 142.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 142.0 MB 1.3 MB/s eta 0:06:45\r",
- "\u001b[K |██████▊ | 142.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.4 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.5 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.6 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.7 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.8 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 142.9 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.0 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.1 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.2 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.3 MB 1.3 MB/s eta 0:06:44\r",
- "\u001b[K |██████▊ | 143.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▊ | 143.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▊ | 143.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▊ | 143.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▊ | 143.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▊ | 143.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▊ | 143.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.7 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.8 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.9 MB 1.3 MB/s eta 0:06:43"
+ "Requirement already satisfied: pytz>=2017.2 in /opt/conda/lib/python3.7/site-packages (from pandas->sagemaker) (2019.3)\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |██████▉ | 143.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 143.9 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.0 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.1 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.2 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.3 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.4 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.5 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.6 MB 1.3 MB/s eta 0:06:43\r",
- "\u001b[K |██████▉ | 144.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 144.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.0 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.1 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.2 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.3 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.4 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.5 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.6 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |██████▉ | 145.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.7 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.8 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 145.9 MB 1.3 MB/s eta 0:06:42\r",
- "\u001b[K |███████ | 146.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.3 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.3 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.3 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.3 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.3 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.3 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.3 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.3 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.3 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.4 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.4 MB 1.3 MB/s eta 0:06:41"
+ "Requirement already satisfied: pox>=0.3.0 in /opt/conda/lib/python3.7/site-packages (from pathos->sagemaker) (0.3.0)\r\n",
+ "Requirement already satisfied: ppft>=1.6.6.4 in /opt/conda/lib/python3.7/site-packages (from pathos->sagemaker) (1.6.6.4)\r\n",
+ "Requirement already satisfied: multiprocess>=0.70.12 in /opt/conda/lib/python3.7/site-packages (from pathos->sagemaker) (0.70.12.2)\r\n",
+ "Requirement already satisfied: dill>=0.3.4 in /opt/conda/lib/python3.7/site-packages (from pathos->sagemaker) (0.3.4)\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |███████ | 146.4 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.4 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.4 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.4 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.4 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.4 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.4 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.4 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.5 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.5 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.5 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.5 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.5 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.5 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.5 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.5 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.5 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.5 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.6 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.6 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.6 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.6 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.6 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.6 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.6 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.6 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.6 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.6 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.7 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.7 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.7 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.7 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.7 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.7 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.7 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.7 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.7 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.7 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.8 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.8 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.8 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.8 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.8 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.8 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.8 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.8 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.8 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.9 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.9 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.9 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.9 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.9 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.9 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.9 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.9 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.9 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 146.9 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.0 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.1 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.2 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.3 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.3 MB 1.3 MB/s eta 0:06:41\r",
- "\u001b[K |███████ | 147.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.7 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.7 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.7 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.7 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.7 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.7 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.7 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.7 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.7 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.7 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.8 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.8 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.8 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.8 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.8 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.8 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.8 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.8 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.8 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.8 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.9 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.9 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.9 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.9 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.9 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.9 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.9 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.9 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.9 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 147.9 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.0 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.0 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.0 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.0 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.0 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.0 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.0 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.0 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.0 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.0 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.1 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.1 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.1 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.1 MB 1.3 MB/s eta 0:06:40"
+ "\u001b[33mWARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\u001b[0m\r\n",
+ "\u001b[33mWARNING: You are using pip version 21.1.3; however, version 22.2.2 is available.\r\n",
+ "You should consider upgrading via the '/opt/conda/bin/python3 -m pip install --upgrade pip' command.\u001b[0m\r\n"
]
+ }
+ ],
+ "source": [
+ "# PyTorch version needs to be the same in both the notebook instance and the training job container\n",
+ "# https://github.com/pytorch/pytorch/issues/25214\n",
+ "!{sys.executable} -m pip install torch==1.1.0\n",
+ "!{sys.executable} -m pip install torchvision==0.2.2\n",
+ "!{sys.executable} -m pip install pillow==6.2.2\n",
+ "!{sys.executable} -m pip install --upgrade sagemaker"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b2c708fd",
+ "metadata": {
+ "papermill": {
+ "duration": 0.808621,
+ "end_time": "2022-08-10T21:53:54.461296",
+ "exception": false,
+ "start_time": "2022-08-10T21:53:53.652675",
+ "status": "completed"
+ },
+ "tags": []
+ },
+ "source": [
+ "## Setup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "0baec74a",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-08-10T21:53:56.154823Z",
+ "iopub.status.busy": "2022-08-10T21:53:56.153550Z",
+ "iopub.status.idle": "2022-08-10T21:54:02.166569Z",
+ "shell.execute_reply": "2022-08-10T21:54:02.166960Z"
+ },
+ "papermill": {
+ "duration": 6.893331,
+ "end_time": "2022-08-10T21:54:02.167120",
+ "exception": false,
+ "start_time": "2022-08-10T21:53:55.273789",
+ "status": "completed"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import time\n",
+ "\n",
+ "import boto3\n",
+ "import numpy as np\n",
+ "import pandas as pd\n",
+ "from IPython.display import set_matplotlib_formats\n",
+ "from matplotlib import pyplot as plt\n",
+ "from torchvision import datasets, transforms\n",
+ "\n",
+ "import sagemaker\n",
+ "from sagemaker import get_execution_role\n",
+ "from sagemaker.session import Session\n",
+ "from sagemaker.analytics import ExperimentAnalytics\n",
+ "\n",
+ "from smexperiments.experiment import Experiment\n",
+ "from smexperiments.trial import Trial\n",
+ "from smexperiments.trial_component import TrialComponent\n",
+ "from smexperiments.tracker import Tracker\n",
+ "\n",
+ "set_matplotlib_formats(\"retina\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "id": "bdb38697",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-08-10T21:54:03.850322Z",
+ "iopub.status.busy": "2022-08-10T21:54:03.848805Z",
+ "iopub.status.idle": "2022-08-10T21:54:04.863241Z",
+ "shell.execute_reply": "2022-08-10T21:54:04.862811Z"
+ },
+ "papermill": {
+ "duration": 1.907829,
+ "end_time": "2022-08-10T21:54:04.863387",
+ "exception": false,
+ "start_time": "2022-08-10T21:54:02.955558",
+ "status": "completed"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "sm_sess = sagemaker.Session()\n",
+ "sess = sm_sess.boto_session\n",
+ "sm = sm_sess.sagemaker_client\n",
+ "role = get_execution_role()\n",
+ "region = sess.region_name"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "97f67a29",
+ "metadata": {
+ "papermill": {
+ "duration": 0.796698,
+ "end_time": "2022-08-10T21:54:06.154129",
+ "exception": false,
+ "start_time": "2022-08-10T21:54:05.357431",
+ "status": "completed"
+ },
+ "tags": []
+ },
+ "source": [
+ "## Download the dataset\n",
+ "We download the MNIST handwritten digits dataset, and then apply a transformation on each image."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "a5afddda",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-08-10T21:54:07.865760Z",
+ "iopub.status.busy": "2022-08-10T21:54:07.864203Z",
+ "iopub.status.idle": "2022-08-10T21:54:11.677292Z",
+ "shell.execute_reply": "2022-08-10T21:54:11.676312Z"
+ },
+ "papermill": {
+ "duration": 4.705622,
+ "end_time": "2022-08-10T21:54:11.677415",
+ "exception": false,
+ "start_time": "2022-08-10T21:54:06.971793",
+ "status": "completed"
},
+ "tags": []
+ },
+ "outputs": [
{
- "name": "stdout",
+ "name": "stderr",
"output_type": "stream",
"text": [
"\r",
- "\u001b[K |███████ | 148.1 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.1 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.1 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.1 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.1 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.2 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.2 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.2 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.2 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.2 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.2 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.2 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.2 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.2 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.2 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.3 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.4 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.5 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.6 MB 1.3 MB/s eta 0:06:40\r",
- "\u001b[K |███████ | 148.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 148.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.0 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.0 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.0 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.0 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.0 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.0 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.0 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.0 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.0 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.0 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.1 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.1 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.1 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.1 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.1 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.1 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.1 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.1 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.1 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.1 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.2 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.2 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.2 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.2 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.2 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.2 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.2 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.2 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.2 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.2 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.3 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.3 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.3 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.3 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.3 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.3 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.3 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.3 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.3 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.4 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.4 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.4 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.4 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.4 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.4 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.4 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.4 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.4 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.4 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.5 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.5 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.5 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.5 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.5 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.5 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.5 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.5 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.5 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.5 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.6 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.7 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.8 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.9 MB 1.3 MB/s eta 0:06:39\r",
- "\u001b[K |███████ | 149.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 149.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 149.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.1 MB 1.3 MB/s eta 0:06:38"
+ "0.00B [00:00, ?B/s]"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |███████ | 150.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.3 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.3 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.3 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.3 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.3 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.3 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.3 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.3 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.3 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.3 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.4 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.4 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.4 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.4 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.4 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████ | 150.4 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.4 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.4 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.4 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.4 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.5 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.5 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.5 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.5 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.5 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.5 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.5 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.5 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.5 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.5 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.6 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.6 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.6 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.6 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.6 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.6 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.6 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.6 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.6 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.7 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.7 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.7 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.7 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.7 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.7 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.7 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.7 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.7 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.7 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.8 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.8 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.8 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.8 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.8 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.8 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.8 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.8 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.8 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.8 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 150.9 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.0 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.1 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.2 MB 1.3 MB/s eta 0:06:38\r",
- "\u001b[K |███████▏ | 151.2 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.6 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.6 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.6 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.6 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.6 MB 1.3 MB/s eta 0:06:37"
+ "Using S3 location: s3://sagemaker-us-west-2-000000000000/DEMO-mnist/\n",
+ "Downloading https://sagemaker-sample-files.s3.amazonaws.com/datasets/image/MNIST/train-images-idx3-ubyte.gz to mnist/MNIST/raw/train-images-idx3-ubyte.gz\n"
]
},
{
- "name": "stdout",
+ "name": "stderr",
"output_type": "stream",
"text": [
"\r",
- "\u001b[K |███████▏ | 151.6 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.6 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.6 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.6 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.6 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.7 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.7 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.7 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.7 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.7 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.7 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.7 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.7 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.7 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.7 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.8 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.8 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.8 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.8 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.8 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.8 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.8 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.8 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.8 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.8 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.9 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.9 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.9 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.9 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.9 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.9 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.9 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.9 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 151.9 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.0 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.0 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.0 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.0 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.0 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.0 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.0 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.0 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.0 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.0 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.1 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.1 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.1 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.1 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.1 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.1 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.1 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.1 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.1 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.1 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.2 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.2 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.2 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.2 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.2 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.2 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.2 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.2 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.2 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.2 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.3 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.4 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.5 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.6 MB 1.3 MB/s eta 0:06:37\r",
- "\u001b[K |███████▏ | 152.6 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.6 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.6 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.6 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.6 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.6 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.6 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.6 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.6 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.7 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.7 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.7 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.7 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.7 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.7 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.7 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.7 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.7 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.8 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▏ | 152.8 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.8 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.8 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.8 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.8 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.8 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.8 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.8 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.8 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.9 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.9 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.9 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.9 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.9 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.9 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.9 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.9 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.9 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 152.9 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.0 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.0 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.0 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.0 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.0 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.0 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.0 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.0 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.0 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.0 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.1 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.1 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.1 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.1 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.1 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.1 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.1 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.1 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.1 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.1 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.2 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.2 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.2 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.2 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.2 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.2 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.2 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.2 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.2 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.3 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.3 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.3 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.3 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.3 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.3 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.3 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.3 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.3 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.3 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.4 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.4 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.4 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.4 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.4 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.4 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.4 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.4 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.4 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.4 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.5 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.5 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.5 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.5 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.5 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.5 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.5 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.5 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.5 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.5 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.6 MB 1.3 MB/s eta 0:06:36\r",
- "\u001b[K |███████▎ | 153.6 MB 1.3 MB/s eta 0:06:36"
+ " 0%| | 0.00/9.91M [00:00"
+ ]
+ },
+ "execution_count": 8,
+ "metadata": {},
+ "output_type": "execute_result"
},
{
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " |█████████▎ | 196.9 MB 254 kB/s eta 0:31:29\r",
- "\u001b[K |█████████▎ | 196.9 MB 254 kB/s eta 0:31:29\r",
- "\u001b[K |█████████▎ | 196.9 MB 254 kB/s eta 0:31:29\r",
- "\u001b[K |█████████▎ | 197.0 MB 254 kB/s eta 0:31:29"
- ]
+ "data": {
+ "image/png": "iVBORw0KGgoAAAANSUhEUgAAAfcAAAHwCAYAAAC7cCafAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAAWJQAAFiUBSVIk8AAAADh0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uMy4xLjMsIGh0dHA6Ly9tYXRwbG90bGliLm9yZy+AADFEAAAb7klEQVR4nO3de7BsVX0n8O+Pi4LcEhBGJZYPHhGoIlECGhRG5GEYTaJihJR/RKmUppKMMwSjU2YSSTBmanRqKhglg6moodSqIRmsmGSCj1FAUIxGMkqYgGjgSowir/B+KJc1f/S+yfXknHvv6e579jmrP5+qrnV67716/9hu77dX9+61q7UWAKAfe4xdAAAwX8IdADoj3AGgM8IdADoj3AGgM8IdADoj3AGgM8IdADoj3AGgM8IdADoj3AGgM8IdADqz59gF7A5VdXOSfZNsGbkUAJjWwUnuba0dstqOXYZ7kn33yKYDNueJB4xdCABM44Hcl8eydaq+vYb7ls154gHH1UvGrgMApvLF9uncl7u3TNN31O/cq+rpVfXBqvp2VT1SVVuq6t1V9aQx6wKAjWy0kXtVHZbk6iRPSfJnSW5I8uNJfiXJS6vqhNbanWPVBwAb1Zgj9/+RSbCf3Vo7vbX2a621U5Kcn+SIJP9lxNoAYMMaJdyr6tAkp2VyNfvvL1n9W0keSPLaqtq8xqUBwIY31sfypwztp1prj22/orV2X1V9PpPwf0GSz6z0IlV1zQqrjpxLlQCwAY31sfwRQ3vjCuu/PrSHr0EtANCVsUbu+w3tPSus37Z8/x29SGvt2OWWDyP6Y6YrDQA2tvU6/WwNbRu1CgDYgMYK920j8/1WWL/vku0AgF00Vrh/bWhX+k792UO70nfyAMAKxgr3y4f2tKr6gRqq6olJTkjyUJK/WuvCAGCjGyXcW2t/n+RTmdzx5o1LVr89yeYkH2qtPbDGpQHAhjfmjWP+fSbTz76nqk5Ncn2S45KcnMnH8b8xYm0AsGGNdrX8MHp/XpKLMgn1Nyc5LMl7krzQvPIAMJ1Rb/naWvuHJD8/Zg0A0Jv1+jt3AGBKwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAze45dAAC77oEzjpu677v+24Uz7fsdP/u6qfu2L183075ZndFG7lW1paraCo9bx6oLADa6sUfu9yR59zLL71/rQgCgF2OH+92ttfNGrgEAuuKCOgDozNgj972q6ueSPDPJA0muTXJla23ruGUBwMY1drgflOTDS5bdXFU/31r77M46V9U1K6w6cubKAGCDGvNj+T9KcmomAb85yY8m+YMkByf5eFU9d7zSAGDjGm3k3lp7+5JF1yX5paq6P8mbk5yX5FU7eY1jl1s+jOiPmUOZALDhrMcL6t43tCeOWgUAbFDrMdxvG9rNo1YBABvUegz3Fw7tTaNWAQAb1CjhXlVHVdUByyx/VpILhqcfWduqAKAPY11Qd2aSX6uqy5PcnOS+JIcl+akkeye5NMl/H6k2ANjQxgr3y5MckeTHMvkYfnOSu5N8LpPfvX+4tdZGqg0ANrRRwn2YoGank9Sweg+98sdn63/gpqn7HvDBL8y0b2Dnbnve9N+mvmPLy+dYCevZerygDgCYgXAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDozCj3c2f3+faJs71f2+ewu6fv/MGZdg2LYY9NM3Vvz3xo6r6nPuWGmfb9mTp+pv6sHSN3AOiMcAeAzgh3AOiMcAeAzgh3AOiMcAeAzgh3AOiMcAeAzgh3AOiMcAeAzgh3AOiMcAeAzgh3AOiMcAeAzrjla2fe/tP/a6b+77r+tDlVAixn02HPmqn/DS+e/t7KR3/p52ba99P++m9n6s/aMXIHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM64n3tnHlePjl0CsAN7vv/B0fb90N/vO9q+WVtG7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ1xy9d16LF/e/TUfV+09+fmWAkwbwdvvnO0fT/j01tH2zdry8gdADozl3CvqjOq6r1VdVVV3VtVrao+spM+x1fVpVV1V1U9WFXXVtU5VbVpHjUBwKKa18fyb0vy3CT3J/lWkiN3tHFVvTLJR5M8nOSPk9yV5OVJzk9yQpIz51QXACyceX0s/6YkhyfZN8kv72jDqto3yR8m2ZrkpNba61tr/ynJ0Um+kOSMqnrNnOoCgIUzl3BvrV3eWvt6a63twuZnJHlykotba1/e7jUezuQTgGQnbxAAgJWNcUHdKUP7iWXWXZnkwSTHV9Vea1cSAPRjjJ/CHTG0Ny5d0Vp7tKpuTnJUkkOTXL+jF6qqa1ZYtcPv/AGgZ2OM3Pcb2ntWWL9t+f5rUAsAdGc9TmJTQ7vT7+9ba8cu+wKTEf0x8ywKADaKMUbu20bm+62wft8l2wEAqzBGuH9taA9fuqKq9kxySJJHk9y0lkUBQC/GCPfLhvaly6w7Mck+Sa5urT2ydiUBQD/GCPdLktyR5DVV9bxtC6tq7yS/Mzy9cIS6AKALc7mgrqpOT3L68PSgoX1hVV00/H1Ha+0tSdJau7eqfiGTkL+iqi7OZPrZV2TyM7lLMpmSFgCYwryulj86yVlLlh06PJLkm0nesm1Fa+1jVfXiJL+R5NVJ9k7yjSS/muQ9uzjTHQCwjLmEe2vtvCTnrbLP55P85Dz235tv/vQTpu77lE37zLESYDl7HvzMqfueccCfz7GS1XnCzf80U393g9843M8dADoj3AGgM8IdADoj3AGgM8IdADoj3AGgM8IdADoj3AGgM8IdADoj3AGgM8IdADoj3AGgM8IdADoj3AGgM/O6nztztOcP3zfavh++Yf/R9g0bxT+8e/PUfU/Y67GZ9v2Be58+fee7751p32wcRu4A0BnhDgCdEe4A0BnhDgCdEe4A0BnhDgCdEe4A0BnhDgCdEe4A0BnhDgCdEe4A0BnhDgCdEe4A0BnhDgCdEe4A0Bn3c+cHPOXLs91rGnbVpn9z4Ez9v/vqw6fue8DPfmumfX/28A/M0HvvmfZ94e+fPnXfp3z36pn2zcZh5A4AnRHuANAZ4Q4AnRHuANAZ4Q4AnRHuANAZ4Q4AnRHuANAZ4Q4AnRHuANAZ4Q4AnRHuANAZ4Q4AnRHuANAZt3zlBzx0wPTv9zbPsY619tiLfmzqvm1TzbTvf3jJXlP3/d7Tvj/Tvvd4/Nap+37qRe+dad+Pm+2w5dat0x+3c2961Uz7vuux6W+NvM8e0x/zJHnqF++bum+bac9sJEbuANAZ4Q4AnRHuANAZ4Q4AnRHuANAZ4Q4AnRHuANAZ4Q4AnRHuANAZ4Q4AnRHuANAZ4Q4AnRHuANAZ4Q4AnRHuANAZ93Nfhx55+HFT931sxjs2/9Gvnz913z//D0fPtO8xvfXA90/dd4/MdmPyh9r3pu777a2z3Rv8gttPmrrvSz59zkz73v//Pn6m/j/0qe9O3be++a2Z9n379U+Yuu9TN31/pn23v/7bmfqzGIzcAaAzcwn3qjqjqt5bVVdV1b1V1arqIytse/CwfqXHxfOoCQAW1bw+ln9bkucmuT/Jt5IcuQt9vprkY8ssv25ONQHAQppXuL8pk1D/RpIXJ7l8F/p8pbV23pz2DwAM5hLurbV/DvOq2S4uAgBmM+bV8k+rql9McmCSO5N8obV27WpeoKquWWHVrnwtAABdGjPcf2J4/LOquiLJWa21W0apCAA6MEa4P5jkHZlcTHfTsOw5Sc5LcnKSz1TV0a21B3b2Qq21Y5dbPozoj5lLtQCwwaz579xba7e11n6ztfY3rbW7h8eVSU5L8sUkP5zkDWtdFwD0Yt1MYtNaezTJtmnCThyzFgDYyNZNuA9uH9rNo1YBABvYegv3FwztTTvcCgBY0ZqHe1UdV1X/6o4RVXVKJpPhJMmyU9cCADs3l6vlq+r0JKcPTw8a2hdW1UXD33e01t4y/P2uJEcNP3vbdmum5yQ5Zfj73Nba1fOoCwAW0bx+Cnd0krOWLDt0eCTJN5NsC/cPJ3lVkucneVmSxyX5bpI/SXJBa+2qOdUEAAupWpvt/t/rUVVd88Tsf8xx9ZKxS1lzN//XF87U/xnP/8c5VbI4bv/402fqf+D/m/7+3o//xF/PtO9F9Y9vPX6m/l89+4Kp+158/5Nn2veHjnjGTP3ZOL7YPp37cvffrDSny46stwvqAIAZCXcA6IxwB4DOCHcA6IxwB4DOCHcA6IxwB4DOCHcA6IxwB4DOCHcA6IxwB4DOCHcA6IxwB4DOCHcA6My87ufOOnHIf/7C2CUsnB/KLWOXwCrtc+Lto+37bZe/eqb+h+dLc6qEnhm5A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0Bn3M8dYA0968/a2CWwAIzcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOiPcAaAzwh0AOrPn2AUAbDSbavpx0T8d/riZ9n3Qx2fqzoKYeeReVQdW1Ruq6k+r6htV9VBV3VNVn6uq11ct//+Cqjq+qi6tqruq6sGquraqzqmqTbPWBACLbB4j9zOTXJjkO0kuT3JLkqcm+Zkk70/ysqo6s7XWtnWoqlcm+WiSh5P8cZK7krw8yflJThheEwCYwjzC/cYkr0jyl621x7YtrKpfT/KlJK/OJOg/OizfN8kfJtma5KTW2peH5ecmuSzJGVX1mtbaxXOoDQAWzswfy7fWLmut/cX2wT4svzXJ+4anJ2236owkT05y8bZgH7Z/OMnbhqe/PGtdALCodvfV8t8f2ke3W3bK0H5ime2vTPJgkuOraq/dWRgA9Gq3XS1fVXsmed3wdPsgP2Job1zap7X2aFXdnOSoJIcmuX4n+7hmhVVHrq5aAOjH7hy5vzPJjyS5tLX2ye2W7ze096zQb9vy/XdXYQDQs90ycq+qs5O8OckNSV672u5D23a4VZLW2rEr7P+aJMescr8A0IW5j9yr6o1Jfi/J3yU5ubV215JNto3M98vy9l2yHQCwCnMN96o6J8kFSa7LJNhvXWazrw3t4cv03zPJIZlcgHfTPGsDgEUxt3CvqrdmMgnNVzIJ9ttW2PSyoX3pMutOTLJPkqtba4/MqzYAWCRzCfdhApp3JrkmyamttTt2sPklSe5I8pqqet52r7F3kt8Znl44j7oAYBHNfEFdVZ2V5LczmXHuqiRnV9XSzba01i5KktbavVX1C5mE/BVVdXEm08++IpOfyV2SyZS0AMAU5nG1/CFDuynJOSts89kkF2170lr7WFW9OMlvZDI97d5JvpHkV5O8Z/t56AGA1Zk53Ftr5yU5b4p+n0/yk7PuH2Ctbf3B2bZXZ3fPCwpxmgFAd4Q7AHRGuANAZ4Q7AHRGuANAZ4Q7AHRGuANAZ4Q7AHRGuANAZ4Q7AHRGuANAZ4Q7AHRGuANAZ4Q7AHRGuANAZ2a+nzsAu+7B5z84dgksACN3AOiMcAeAzgh3AOiMcAeAzgh3AOiMcAeAzgh3AOiMcAeAzgh3AOiMcAeAzgh3AOiMcAeAzgh3AOiMcAeAzrjlK8AqbSrjItY3ZygAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdMb93IGF88innzxT/61HPzanSmD3MHIHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojHAHgM4IdwDojFu+AgvnoPOvnqn/T55/zNR9D81XZto37AojdwDozMzhXlUHVtUbqupPq+obVfVQVd1TVZ+rqtdX1R5Ltj+4qtoOHhfPWhMALLJ5fCx/ZpILk3wnyeVJbkny1CQ/k+T9SV5WVWe21tqSfl9N8rFlXu+6OdQEAAtrHuF+Y5JXJPnL1tpj2xZW1a8n+VKSV2cS9B9d0u8rrbXz5rB/AGA7M38s31q7rLX2F9sH+7D81iTvG56eNOt+AIBds7uvlv/+0D66zLqnVdUvJjkwyZ1JvtBau3Y31wMA3dtt4V5VeyZ53fD0E8ts8hPDY/s+VyQ5q7V2yy7u45oVVh25i2UCQHd250/h3pnkR5Jc2lr75HbLH0zyjiTHJnnS8HhxJhfjnZTkM1W1eTfWBQBd2y0j96o6O8mbk9yQ5LXbr2ut3ZbkN5d0ubKqTkvyuSTHJXlDkt/b2X5aa8eusP9rkkw/ywQAbGBzH7lX1RszCea/S3Jya+2uXenXWns0k5/OJcmJ864LABbFXMO9qs5JckEmv1U/ebhifjVuH1ofywPAlOYW7lX11iTnJ/lKJsF+2xQv84KhvWledQHAoplLuFfVuZlcQHdNklNba3fsYNvjqurxyyw/JcmbhqcfmUddALCIZr6grqrOSvLbSbYmuSrJ2VW1dLMtrbWLhr/fleSo4Wdv3xqWPSfJKcPf57bWZrtlEwAssHlcLX/I0G5Kcs4K23w2yUXD3x9O8qokz0/ysiSPS/LdJH+S5ILW2lVzqAkAFtbM4T7MD3/eKrb/QJIPzLpfAGB57ucOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ0R7gDQGeEOAJ2p1trYNcxdVd25RzYdsDlPHLsUAJjKA7kvj2XrXa21A1fbd8/dUdA6cO9j2Zr7cveWFdYfObQ3rFE9PXDMpuO4TcdxWz3HbDrr+bgdnOTeaTp2OXLfmaq6Jklaa8eOXctG4ZhNx3GbjuO2eo7ZdHo9br5zB4DOCHcA6IxwB4DOCHcA6IxwB4DOLOTV8gDQMyN3AOiMcAeAzgh3AOiMcAeAzgh3AOiMcAeAzgh3AOjMQoV7VT29qj5YVd+uqkeqaktVvbuqnjR2bevVcIzaCo9bx65vLFV1RlW9t6quqqp7h+PxkZ30Ob6qLq2qu6rqwaq6tqrOqapNa1X32FZz3Krq4B2ce62qLl7r+sdQVQdW1Ruq6k+r6htV9VBV3VNVn6uq11fVsv+OL/r5ttrj1tv51uv93P+VqjosydVJnpLkzzK5d++PJ/mVJC+tqhNaa3eOWOJ6dk+Sdy+z/P61LmQdeVuS52ZyDL6Vf7kn9LKq6pVJPprk4SR/nOSuJC9Pcn6SE5KcuTuLXUdWddwGX03ysWWWXzfHutazM5NcmOQ7SS5PckuSpyb5mSTvT/KyqjqzbTcjmfMtyRTHbdDH+dZaW4hHkk8maUn+45Llvzssf9/YNa7HR5ItSbaMXcd6eyQ5Ocmzk1SSk4Zz6CMrbLtvktuSPJLkedst3zuTN5wtyWvG/m9ah8ft4GH9RWPXPfIxOyWTYN5jyfKDMgmsluTV2y13vk133Lo63xbiY/mqOjTJaZkE1e8vWf1bSR5I8tqq2rzGpbFBtdYub619vQ3/KuzEGUmenOTi1tqXt3uNhzMZySbJL++GMtedVR43krTWLmut/UVr7bEly29N8r7h6UnbrXK+Zarj1pVF+Vj+lKH91DL/Q99XVZ/PJPxfkOQza13cBrBXVf1ckmdm8kbo2iRXtta2jlvWhrHt/PvEMuuuTPJgkuOraq/W2iNrV9aG8bSq+sUkBya5M8kXWmvXjlzTevH9oX10u2XOt51b7rht08X5tijhfsTQ3rjC+q9nEu6HR7gv56AkH16y7Oaq+vnW2mfHKGiDWfH8a609WlU3JzkqyaFJrl/LwjaInxge/6yqrkhyVmvtllEqWgeqas8krxuebh/kzrcd2MFx26aL820hPpZPst/Q3rPC+m3L91+DWjaaP0pyaiYBvznJjyb5g0y+n/p4VT13vNI2DOffdB5M8o4kxyZ50vB4cSYXR52U5DML/lXaO5P8SJJLW2uf3G65823HVjpuXZ1vixLuO1ND63vAJVprbx++u/pua+3B1tp1rbVfyuRCxCckOW/cCrvg/FtGa+221tpvttb+prV29/C4MpNP2b6Y5IeTvGHcKsdRVWcneXMmv/p57Wq7D+3CnW87Om69nW+LEu7b3qnut8L6fZdsx85tuyDlxFGr2Bicf3PUWns0k58yJQt4/lXVG5P8XpK/S3Jya+2uJZs435axC8dtWRv1fFuUcP/a0B6+wvpnD+1K38nzr902tBvmY6oRrXj+Dd//HZLJhT03rWVRG9ztQ7tQ519VnZPkgkx+c33ycOX3Us63JXbxuO3IhjvfFiXcLx/a05aZleiJmUzq8FCSv1rrwjawFw7twvwDMYPLhvaly6w7Mck+Sa5e4CuXp/GCoV2Y86+q3prJJDRfySSgblthU+fbdlZx3HZkw51vCxHurbW/T/KpTC4Ce+OS1W/P5N3Yh1prD6xxaetaVR1VVQcss/xZmbwLTpIdTrlKkuSSJHckeU1VPW/bwqraO8nvDE8vHKOw9ayqjquqxy+z/JQkbxqeLsT5V1XnZnIh2DVJTm2t3bGDzZ1vg9Uct97Ot1qUuSSWmX72+iTHZTJj1o1Jjm+mn/0BVXVekl/L5JOPm5Pcl+SwJD+VyWxXlyZ5VWvte2PVOJaqOj3J6cPTg5L8u0ze1V81LLujtfaWJdtfksl0oBdnMh3oKzL52dIlSX52ESZ2Wc1xG35+dFSSKzKZqjZJnpN/+R33ua21bWHVrao6K8lFSbYmeW+W/658S2vtou36LPz5ttrj1t35NvYUeWv5SPKMTH7a9Z0k30vyzUwusDhg7NrW4yOTn4H8z0yuLL07k4kfbk/yfzL5nWiNXeOIx+a8TK42XumxZZk+J2TyhuifMvka6G8zGRFsGvu/Zz0etySvT/K/M5lZ8v5MplO9JZO50l809n/LOjpmLckVzrfZjltv59vCjNwBYFEsxHfuALBIhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0BnhDsAdEa4A0Bn/j8XT2auSn8BKgAAAABJRU5ErkJggg==\n",
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {
+ "image/png": {
+ "height": 248,
+ "width": 251
+ },
+ "needs_background": "light"
+ },
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "plt.imshow(train_set.data[2].numpy())"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2095111d",
+ "metadata": {
+ "papermill": {
+ "duration": 0.812931,
+ "end_time": "2022-08-10T21:54:15.860198",
+ "exception": false,
+ "start_time": "2022-08-10T21:54:15.047267",
+ "status": "completed"
},
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
- "\u001b[K |█████████▎ | 197.0 MB 254 kB/s eta 0:31:29\r",
- "\u001b[K |█████████▎ | 197.0 MB 254 kB/s eta 0:31:29\r",
- "\u001b[K |█████████▎ | 197.0 MB 254 kB/s eta 0:31:29\r",
- "\u001b[K |█████████▎ | 197.0 MB 254 kB/s eta 0:31:29\r",
- "\u001b[K |█████████▎ | 197.0 MB 254 kB/s eta 0:31:29\r",
- "\u001b[K |█████████▎ | 197.0 MB 254 kB/s eta 0:31:29\r",
- "\u001b[K |█████████▎ | 197.0 MB 254 kB/s eta 0:31:29\r",
- "\u001b[K |█████████▎ | 197.0 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.0 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.1 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.1 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.1 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.1 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.1 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.1 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.1 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.1 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.1 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.2 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.2 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.2 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.2 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.2 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.2 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.2 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.2 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.2 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.2 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.3 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.3 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.3 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.3 MB 254 kB/s eta 0:31:28\r",
- "\u001b[K |█████████▎ | 197.3 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▎ | 197.3 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▎ | 197.3 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▎ | 197.3 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▎ | 197.3 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▎ | 197.3 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▎ | 197.4 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▎ | 197.4 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▎ | 197.4 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▎ | 197.4 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▎ | 197.4 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▎ | 197.4 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▎ | 197.4 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▍ | 197.4 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▍ | 197.4 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▍ | 197.4 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▍ | 197.5 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▍ | 197.5 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▍ | 197.5 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▍ | 197.5 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▍ | 197.5 MB 254 kB/s eta 0:31:27"
- ]
+ "tags": []
+ },
+ "source": [
+ "After transforming the images in the dataset, we upload it to S3."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 9,
+ "id": "f5381859",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-08-10T21:54:17.753667Z",
+ "iopub.status.busy": "2022-08-10T21:54:17.753138Z",
+ "iopub.status.idle": "2022-08-10T21:54:22.428840Z",
+ "shell.execute_reply": "2022-08-10T21:54:22.428411Z"
},
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
- "\u001b[K |█████████▍ | 197.5 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▍ | 197.5 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▍ | 197.5 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▍ | 197.5 MB 254 kB/s eta 0:31:27\r",
- "\u001b[K |█████████▍ | 197.6 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.6 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.6 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.6 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.6 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.6 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.6 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.6 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.6 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.6 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.7 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.7 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.7 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.7 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.7 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.7 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.7 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.7 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.7 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.7 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.8 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.8 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.8 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.8 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.8 MB 254 kB/s eta 0:31:26\r",
- "\u001b[K |█████████▍ | 197.8 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.8 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.8 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.8 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.8 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.9 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.9 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.9 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.9 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.9 MB 254 kB/s eta 0:31:25"
- ]
+ "papermill": {
+ "duration": 5.752617,
+ "end_time": "2022-08-10T21:54:22.428962",
+ "exception": false,
+ "start_time": "2022-08-10T21:54:16.676345",
+ "status": "completed"
},
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
- "\u001b[K |█████████▍ | 197.9 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.9 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.9 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.9 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 197.9 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 198.0 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 198.0 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 198.0 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 198.0 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 198.0 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 198.0 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 198.0 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 198.0 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 198.0 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 198.1 MB 254 kB/s eta 0:31:25\r",
- "\u001b[K |█████████▍ | 198.1 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.1 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.1 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.1 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.1 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.1 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.1 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.1 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.1 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.2 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.2 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.2 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.2 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.2 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.2 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.2 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.2 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.2 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.2 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.3 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.3 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.3 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.3 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.3 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.3 MB 254 kB/s eta 0:31:24\r",
- "\u001b[K |█████████▍ | 198.3 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.3 MB 254 kB/s eta 0:31:23"
- ]
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "inputs = sagemaker.Session().upload_data(path=\"mnist\", bucket=bucket, key_prefix=prefix)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dab5d975",
+ "metadata": {
+ "papermill": {
+ "duration": 0.80147,
+ "end_time": "2022-08-10T21:54:23.761502",
+ "exception": false,
+ "start_time": "2022-08-10T21:54:22.960032",
+ "status": "completed"
},
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
- "\u001b[K |█████████▍ | 198.3 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.3 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.4 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.4 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.4 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.4 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.4 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.4 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.4 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.4 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.4 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.5 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.5 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.5 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.5 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.5 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.5 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.5 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.5 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.5 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.5 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.6 MB 254 kB/s eta 0:31:23\r",
- "\u001b[K |█████████▍ | 198.6 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.6 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.6 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.6 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.6 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.6 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.6 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.6 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.6 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.7 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.7 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.7 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.7 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.7 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.7 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.7 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.7 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.7 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.7 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.8 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.8 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.8 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.8 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.8 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.8 MB 254 kB/s eta 0:31:22\r",
- "\u001b[K |█████████▍ | 198.8 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ "
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " | 198.8 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 198.8 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 198.9 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 198.9 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 198.9 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 198.9 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 198.9 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 198.9 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 198.9 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 198.9 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 198.9 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 198.9 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.0 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.0 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.0 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.0 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.0 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.0 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.0 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.0 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.0 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.0 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.1 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.1 MB 254 kB/s eta 0:31:21\r",
- "\u001b[K |█████████▍ | 199.1 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.1 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.1 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.1 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.1 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.1 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.1 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.1 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.2 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.2 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.2 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.2 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.2 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.2 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.2 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.2 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.2 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.2 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.3 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.3 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.3 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.3 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.3 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.3 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.3 MB 254 kB/s eta 0:31:20\r",
- "\u001b[K |█████████▍ | 199.3 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.3 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.4 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.4 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.4 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.4 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.4 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.4 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.4 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.4 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.4 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.4 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.5 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.5 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.5 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.5 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.5 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.5 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.5 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.5 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.5 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.5 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.6 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.6 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.6 MB 254 kB/s eta 0:31:19\r",
- "\u001b[K |█████████▍ | 199.6 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.6 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.6 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.6 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.6 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.6 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.6 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.7 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.7 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.7 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.7 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.7 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.7 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.7 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.7 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.7 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.8 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▍ | 199.8 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▌ | 199.8 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▌ | 199.8 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▌ | 199.8 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▌ | 199.8 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▌ | 199.8 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▌ | 199.8 MB 254 kB/s eta 0:31:18\r",
- "\u001b[K |█████████▌ | 199.8 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 199.8 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 199.9 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 199.9 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 199.9 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 199.9 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 199.9 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 199.9 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 199.9 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 199.9 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 199.9 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 199.9 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.0 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.0 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.0 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.0 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.0 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.0 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.0 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.0 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.0 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.0 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.1 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.1 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.1 MB 254 kB/s eta 0:31:17\r",
- "\u001b[K |█████████▌ | 200.1 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.1 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.1 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.1 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.1 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.1 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.2 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.2 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.2 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.2 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.2 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.2 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.2 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.2 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.2 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.2 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.3 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.3 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.3 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.3 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.3 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.3 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.3 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.3 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.3 MB 254 kB/s eta 0:31:16\r",
- "\u001b[K |█████████▌ | 200.3 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.4 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.4 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.4 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.4 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.4 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.4 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.4 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.4 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.4 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.4 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.5 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.5 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.5 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.5 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.5 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.5 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.5 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.5 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.5 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.6 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.6 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.6 MB 254 kB/s eta 0:31:15"
- ]
+ "tags": []
+ },
+ "source": [
+ "Now let's track the parameters from the data pre-processing step."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 10,
+ "id": "37e97fda",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-08-10T21:54:25.551990Z",
+ "iopub.status.busy": "2022-08-10T21:54:25.551343Z",
+ "iopub.status.idle": "2022-08-10T21:54:25.687202Z",
+ "shell.execute_reply": "2022-08-10T21:54:25.687595Z"
},
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
- "\u001b[K |█████████▌ | 200.6 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.6 MB 254 kB/s eta 0:31:15\r",
- "\u001b[K |█████████▌ | 200.6 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.6 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.6 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.6 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.6 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.7 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.7 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.7 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.7 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.7 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.7 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.7 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.7 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.7 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.7 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.8 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.8 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.8 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.8 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.8 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.8 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.8 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.8 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.8 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.8 MB 254 kB/s eta 0:31:14\r",
- "\u001b[K |█████████▌ | 200.9 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 200.9 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 200.9 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 200.9 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 200.9 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 200.9 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 200.9 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 200.9 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 200.9 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 200.9 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 201.0 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 201.0 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 201.0 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 201.0 MB 254 kB/s eta 0:31:13\r",
- "\u001b[K |█████████▌ | 201.0 MB 254 kB/s eta 0:31:13"
- ]
+ "papermill": {
+ "duration": 1.110399,
+ "end_time": "2022-08-10T21:54:25.687738",
+ "exception": false,
+ "start_time": "2022-08-10T21:54:24.577339",
+ "status": "completed"
},
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\r",
- "\u001b[K |█████████▌ | 201.0 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.0 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.0 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.0 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.1 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.1 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.1 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.1 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.1 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.1 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.1 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.1 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.1 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.1 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.2 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.2 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.2 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.2 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.2 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.2 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.2 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.2 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.2 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.2 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.3 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.3 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.3 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.3 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.3 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.3 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.3 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.3 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.3 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.3 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.4 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.4 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.4 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.4 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.4 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.4 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.4 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.4 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.4 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.5 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.5 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.5 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.5 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.5 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.5 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.5 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.5 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.5 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.5 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.6 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.6 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.6 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.6 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.6 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.6 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.6 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.6 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.6 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.6 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.7 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.7 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.7 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.7 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.7 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.7 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.7 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.7 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.7 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.7 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.8 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.8 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.8 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.8 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.8 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.8 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.8 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.8 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.8 MB 1.2 MB/s eta 0:06:42\r",
- "\u001b[K |█████████▌ | 201.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 201.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ "
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " | 201.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 201.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 201.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 201.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 201.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 201.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 201.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 201.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.1 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.1 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.1 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.1 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.1 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.1 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▌ | 202.1 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.1 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.1 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.1 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.2 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.2 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.2 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.2 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.2 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.2 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.2 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.2 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.2 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.3 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.3 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.3 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.3 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.3 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.3 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.3 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.3 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.3 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.3 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.4 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.4 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.4 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.4 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.4 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.4 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.4 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.4 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.4 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.4 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.5 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.5 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.5 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.5 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.5 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.5 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.5 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.5 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.5 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.5 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.6 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.6 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.6 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.6 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.6 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.6 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.6 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.6 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.6 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.6 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.7 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.7 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.7 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.7 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.7 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.7 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.7 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.7 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.7 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.8 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.8 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.8 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.8 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.8 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.8 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.8 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.8 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.8 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.8 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 202.9 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 203.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 203.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 203.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 203.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 203.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 203.0 MB 1.2 MB/s eta 0:06:41"
- ]
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "with Tracker.create(display_name=\"Preprocessing\", sagemaker_boto_client=sm) as tracker:\n",
+ " tracker.log_parameters(\n",
+ " {\n",
+ " \"normalization_mean\": 0.1307,\n",
+ " \"normalization_std\": 0.3081,\n",
+ " }\n",
+ " )\n",
+ " # We can log the S3 uri to the dataset we just uploaded\n",
+ " tracker.log_input(name=\"mnist-dataset\", media_type=\"s3/uri\", value=inputs)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "04ef9e20",
+ "metadata": {
+ "papermill": {
+ "duration": 0.806991,
+ "end_time": "2022-08-10T21:54:27.281808",
+ "exception": false,
+ "start_time": "2022-08-10T21:54:26.474817",
+ "status": "completed"
+ },
+ "tags": []
+ },
+ "source": [
+ "## Step 1: Set up the Experiment\n",
+ "\n",
+ "Create an experiment to track all the model training iterations. Experiments are a great way to organize your data science work. You can create experiments to organize all your model development work for: [1] a business use case you are addressing (e.g. create experiment named “customer churn prediction”), or [2] a data science team that owns the experiment (e.g. create experiment named “marketing analytics experiment”), or [3] a specific data science and ML project. Think of it as a “folder” for organizing your “files”."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dc161575",
+ "metadata": {
+ "papermill": {
+ "duration": 0.72498,
+ "end_time": "2022-08-10T21:54:28.880347",
+ "exception": false,
+ "start_time": "2022-08-10T21:54:28.155367",
+ "status": "completed"
+ },
+ "tags": []
+ },
+ "source": [
+ "### Create an Experiment"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "afc5f217",
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-08-10T21:54:30.661535Z",
+ "iopub.status.busy": "2022-08-10T21:54:30.660928Z",
+ "iopub.status.idle": "2022-08-10T21:54:30.689011Z",
+ "shell.execute_reply": "2022-08-10T21:54:30.688579Z"
+ },
+ "papermill": {
+ "duration": 0.938327,
+ "end_time": "2022-08-10T21:54:30.689125",
+ "exception": false,
+ "start_time": "2022-08-10T21:54:29.750798",
+ "status": "completed"
},
+ "tags": []
+ },
+ "outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
- "\r",
- "\u001b[K |█████████▋ | 203.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 203.0 MB 1.2 MB/s eta 0:06:41\r",
- "\u001b[K |█████████▋ | 203.0 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.0 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.1 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.1 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.1 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.1 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.1 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.1 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.1 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.1 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.1 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.2 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.2 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.2 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.2 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.2 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.2 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.2 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.2 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.2 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.2 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.3 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.3 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.3 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.3 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.3 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.3 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.3 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.3 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.3 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.3 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.4 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.4 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.4 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.4 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.4 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.4 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.4 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.4 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.4 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.4 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.5 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.5 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.5 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.5 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.5 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.5 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.5 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.5 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.5 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.6 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.6 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.6 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.6 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.6 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.6 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.6 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.6 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.6 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.6 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.7 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.7 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.7 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.7 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.7 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.7 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.7 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.7 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.7 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.7 MB 1.2 MB/s eta 0:06:40\r",
- "\u001b[K |█████████▋ | 203.8 MB 1.2 MB/s eta 0:06:40"
+ "Experiment(sagemaker_boto_client= +
+#### ! Important: The example provided can be tested also by using Amazon SageMaker Notebook Instances
+
+### Prerequisites
+
+1. Required NVIDIA NGC Account. Follow the instruction https://docs.nvidia.com/ngc/ngc-catalog-user-guide/index.html#registering-activating-ngc-account
+
+## Step 1: Clone this repository
+
+## Step 2: Build Studio image
+
+In this example, we provide a [Dokerfile](./studio-image/image_tensorrt/Dockerfile) example to build a custom image for SageMaker Studio.
+
+To build the image, push it and make it available in your Amazon SageMaker Studio environment, edit [sagemaker-studio-config](./studio-image/studio-domain-config.json) by replacing `$DOMAIN_ID` with your Studio domain ID.
+
+We also provide automation scripts in order to [build and push](./studio-image/build_image.sh) your docker image to an ECR repository
+and [create](./studio-image/create_studio_image.sh) or [update](./studio-image/update_studio_image.sh) an Amazon SageMaker Image. Please follow the instructions in the [README](./studio-image/README.md) for additional info on the usage of this script.
+
+## Step 3: Compile model, create an Amazon SageMaker Real-Time Endpoint with NVIDIA Triton Inference Server
+
+Clone this repository into your Amazon SageMaker Studio environment and execute the cells in the [notebook](./examples/triton_sentence_embeddings.ipynb)
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/bert-trt/config.pbtxt b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/bert-trt/config.pbtxt
new file mode 100644
index 0000000000..3bf605dfc4
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/bert-trt/config.pbtxt
@@ -0,0 +1,32 @@
+name: "bert-trt"
+platform: "tensorrt_plan"
+max_batch_size: 16
+input [
+ {
+ name: "token_ids"
+ data_type: TYPE_INT32
+ dims: [128]
+ },
+ {
+ name: "attn_mask"
+ data_type: TYPE_INT32
+ dims: [128]
+ }
+]
+output [
+ {
+ name: "output"
+ data_type: TYPE_FP32
+ dims: [128, 384]
+ },
+ {
+ name: "854"
+ data_type: TYPE_FP32
+ dims: [384]
+ }
+]
+instance_group [
+ {
+ kind: KIND_GPU
+ }
+ ]
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/ensemble/1/README.md b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/ensemble/1/README.md
new file mode 100644
index 0000000000..a8e639ff9d
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/ensemble/1/README.md
@@ -0,0 +1 @@
+Do not delete me!
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/ensemble/config.pbtxt b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/ensemble/config.pbtxt
new file mode 100644
index 0000000000..aa36dd1ded
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/ensemble/config.pbtxt
@@ -0,0 +1,70 @@
+name: "ensemble"
+platform: "ensemble"
+max_batch_size: 16
+input [
+ {
+ name: "INPUT0"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ }
+]
+output [
+ {
+ name: "finaloutput"
+ data_type: TYPE_FP32
+ dims: [384]
+ }
+]
+ensemble_scheduling {
+ step [
+ {
+ model_name: "preprocess"
+ model_version: -1
+ input_map {
+ key: "INPUT0"
+ value: "INPUT0"
+ }
+ output_map {
+ key: "OUTPUT0"
+ value: "token_ids"
+ }
+ output_map {
+ key: "OUTPUT1"
+ value: "attn_mask"
+ }
+ },
+ {
+ model_name: "bert-trt"
+ model_version: -1
+ input_map {
+ key: "token_ids"
+ value: "token_ids"
+ }
+ input_map {
+ key: "attn_mask"
+ value: "attn_mask"
+ }
+ output_map {
+ key: "output"
+ value: "output"
+ }
+ },
+ {
+ model_name: "postprocess"
+ model_version: -1
+ input_map {
+ key: "TOKEN_EMBEDS_POST"
+ value: "output"
+ }
+ input_map {
+ key: "ATTENTION_POST"
+ value: "attn_mask"
+ }
+ output_map {
+ key: "SENT_EMBED"
+ value: "finaloutput"
+ }
+
+ }
+ ]
+}
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/1/model.py b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/1/model.py
new file mode 100644
index 0000000000..5373e90dbb
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/1/model.py
@@ -0,0 +1,78 @@
+import json
+import logging
+import numpy as np
+import subprocess
+import sys
+import os
+
+import triton_python_backend_utils as pb_utils
+
+logging.basicConfig(level=logging.INFO)
+logger = logging.getLogger(__name__)
+
+class TritonPythonModel:
+ """This model loops through different dtypes to make sure that
+ serialize_byte_tensor works correctly in the Python backend.
+ """
+
+ def __mean_pooling(self, token_embeddings, attention_mask):
+ logger.info("token_embeddings: {}".format(token_embeddings))
+ logger.info("attention_mask: {}".format(attention_mask))
+
+ input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
+ return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
+
+ def initialize(self, args):
+ self.model_dir = args['model_repository']
+ subprocess.check_call([sys.executable, "-m", "pip", "install", '-r', f'{self.model_dir}/requirements.txt'])
+ global torch
+ import torch
+
+ self.device_id = args['model_instance_device_id']
+ self.model_config = model_config = json.loads(args['model_config'])
+ self.device = torch.device(f'cuda:{self.device_id}') if torch.cuda.is_available() else torch.device('cpu')
+
+ output0_config = pb_utils.get_output_config_by_name(
+ model_config, "SENT_EMBED")
+
+ self.output0_dtype = pb_utils.triton_string_to_numpy(
+ output0_config["data_type"])
+
+ def execute(self, requests):
+
+ responses = []
+
+ for request in requests:
+ tok_embeds = pb_utils.get_input_tensor_by_name(request, "TOKEN_EMBEDS_POST")
+ attn_mask = pb_utils.get_input_tensor_by_name(request, "ATTENTION_POST")
+
+ tok_embeds = tok_embeds.as_numpy()
+
+ logger.info("tok_embeds: {}".format(tok_embeds))
+ logger.info("tok_embeds shape: {}".format(tok_embeds.shape))
+
+ tok_embeds = torch.tensor(tok_embeds,device=self.device)
+
+ logger.info("tok_embeds_tensor: {}".format(tok_embeds))
+
+ attn_mask = attn_mask.as_numpy()
+
+ logger.info("attn_mask: {}".format(attn_mask))
+ logger.info("attn_mask shape: {}".format(attn_mask.shape))
+
+ attn_mask = torch.tensor(attn_mask,device=self.device)
+
+ logger.info("attn_mask_tensor: {}".format(attn_mask))
+
+ sentence_embeddings = self.__mean_pooling(tok_embeds, attn_mask)
+ sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
+
+ out_0 = np.array(sentence_embeddings.cpu(),dtype=self.output0_dtype)
+ logger.info("out_0: {}".format(out_0))
+
+ out_tensor_0 = pb_utils.Tensor("SENT_EMBED", out_0)
+ logger.info("out_tensor_0: {}".format(out_tensor_0))
+
+ responses.append(pb_utils.InferenceResponse([out_tensor_0]))
+
+ return responses
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/config.pbtxt b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/config.pbtxt
new file mode 100644
index 0000000000..de573d924d
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/config.pbtxt
@@ -0,0 +1,26 @@
+name: "postprocess"
+backend: "python"
+max_batch_size: 16
+
+input [
+ {
+ name: "TOKEN_EMBEDS_POST"
+ data_type: TYPE_FP32
+ dims: [128, 384]
+
+ },
+ {
+ name: "ATTENTION_POST"
+ data_type: TYPE_INT32
+ dims: [128]
+ }
+]
+output [
+ {
+ name: "SENT_EMBED"
+ data_type: TYPE_FP32
+ dims: [ 384 ]
+ }
+]
+
+instance_group [{ kind: KIND_GPU }]
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/requirements.txt b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/requirements.txt
new file mode 100644
index 0000000000..08ed5eeb4b
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/requirements.txt
@@ -0,0 +1 @@
+torch
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/1/model.py b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/1/model.py
new file mode 100644
index 0000000000..47b1f1befc
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/1/model.py
@@ -0,0 +1,74 @@
+import json
+import logging
+import numpy as np
+import subprocess
+import sys
+
+import triton_python_backend_utils as pb_utils
+
+logging.basicConfig(level=logging.INFO)
+logger = logging.getLogger(__name__)
+
+class TritonPythonModel:
+ """This model loops through different dtypes to make sure that
+ serialize_byte_tensor works correctly in the Python backend.
+ """
+
+ def initialize(self, args):
+ self.model_dir = args['model_repository']
+ subprocess.check_call([sys.executable, "-m", "pip", "install", '-r', f'{self.model_dir}/requirements.txt'])
+ global transformers
+ import transformers
+
+ self.tokenizer = transformers.AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
+ self.model_config = model_config = json.loads(args['model_config'])
+
+ output0_config = pb_utils.get_output_config_by_name(
+ model_config, "OUTPUT0")
+ output1_config = pb_utils.get_output_config_by_name(
+ model_config, "OUTPUT1")
+
+ self.output0_dtype = pb_utils.triton_string_to_numpy(
+ output0_config['data_type'])
+ self.output1_dtype = pb_utils.triton_string_to_numpy(
+ output0_config['data_type'])
+
+ def execute(self, requests):
+
+ file = open("logs.txt", "w")
+
+ responses = []
+ for request in requests:
+ logger.info("Request: {}".format(request))
+
+ in_0 = pb_utils.get_input_tensor_by_name(request, "INPUT0")
+ in_0 = in_0.as_numpy()
+
+ logger.info("in_0: {}".format(in_0))
+
+ tok_batch = []
+
+ for i in range(in_0.shape[0]):
+ decoded_object = in_0[i,0].decode()
+
+ logger.info("decoded_object: {}".format(decoded_object))
+
+ tok_batch.append(decoded_object)
+
+ logger.info("tok_batch: {}".format(tok_batch))
+
+ tok_sent = self.tokenizer(tok_batch,
+ padding='max_length',
+ max_length=128,
+ )
+
+
+ logger.info("Tokens: {}".format(tok_sent))
+
+ out_0 = np.array(tok_sent['input_ids'],dtype=self.output0_dtype)
+ out_1 = np.array(tok_sent['attention_mask'],dtype=self.output1_dtype)
+ out_tensor_0 = pb_utils.Tensor("OUTPUT0", out_0)
+ out_tensor_1 = pb_utils.Tensor("OUTPUT1", out_1)
+
+ responses.append(pb_utils.InferenceResponse([out_tensor_0,out_tensor_1]))
+ return responses
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/config.pbtxt b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/config.pbtxt
new file mode 100644
index 0000000000..c3f70b03dd
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/config.pbtxt
@@ -0,0 +1,28 @@
+name: "preprocess"
+backend: "python"
+max_batch_size: 16
+
+input [
+ {
+ name: "INPUT0"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+
+ }
+]
+output [
+ {
+ name: "OUTPUT0"
+ data_type: TYPE_INT32
+ dims: [ 128 ]
+ },
+
+ {
+ name: "OUTPUT1"
+ data_type: TYPE_INT32
+ dims: [ 128 ]
+ }
+
+]
+
+instance_group [{ kind: KIND_CPU }]
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/requirements.txt b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/requirements.txt
new file mode 100644
index 0000000000..747b7aa97a
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/requirements.txt
@@ -0,0 +1 @@
+transformers
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/triton_sentence_embeddings.ipynb b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/triton_sentence_embeddings.ipynb
new file mode 100644
index 0000000000..5fef5c4405
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/triton_sentence_embeddings.ipynb
@@ -0,0 +1,1015 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "ce5723a5",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "# Prerequisites\n",
+ "\n",
+ "Install the necessary Python modules to use and interact with [NVIDIA Triton Inference Server](https://github.com/triton-inference-server/server/)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f5995424",
+ "metadata": {
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "! pip install torch==1.10.0 sagemaker transformers==4.9.1 tritonclient[all]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4d9d12fa",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "# Part 1 - Setup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3aef44c4",
+ "metadata": {
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import argparse\n",
+ "import boto3\n",
+ "import copy\n",
+ "import datetime\n",
+ "import json\n",
+ "import numpy as np\n",
+ "import os\n",
+ "import pandas as pd\n",
+ "import pprint\n",
+ "import re\n",
+ "import sagemaker\n",
+ "import sys\n",
+ "import time\n",
+ "from time import gmtime, strftime\n",
+ "import tritonclient.http as http_client"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fe9a1636",
+ "metadata": {
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "session = boto3.Session()\n",
+ "role = sagemaker.get_execution_role()\n",
+ "\n",
+ "sm_client = session.client(\"sagemaker\")\n",
+ "sagemaker_session = sagemaker.Session(boto_session=session)\n",
+ "sm_runtime_client = boto3.client(\"sagemaker-runtime\")\n",
+ "\n",
+ "region = boto3.Session().region_name"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a4996fe6",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "account_id_map = {\n",
+ " \"us-east-1\": \"785573368785\",\n",
+ " \"us-east-2\": \"007439368137\",\n",
+ " \"us-west-1\": \"710691900526\",\n",
+ " \"us-west-2\": \"301217895009\",\n",
+ " \"eu-west-1\": \"802834080501\",\n",
+ " \"eu-west-2\": \"205493899709\",\n",
+ " \"eu-west-3\": \"254080097072\",\n",
+ " \"eu-north-1\": \"601324751636\",\n",
+ " \"eu-south-1\": \"966458181534\",\n",
+ " \"eu-central-1\": \"746233611703\",\n",
+ " \"ap-east-1\": \"110948597952\",\n",
+ " \"ap-south-1\": \"763008648453\",\n",
+ " \"ap-northeast-1\": \"941853720454\",\n",
+ " \"ap-northeast-2\": \"151534178276\",\n",
+ " \"ap-southeast-1\": \"324986816169\",\n",
+ " \"ap-southeast-2\": \"355873309152\",\n",
+ " \"cn-northwest-1\": \"474822919863\",\n",
+ " \"cn-north-1\": \"472730292857\",\n",
+ " \"sa-east-1\": \"756306329178\",\n",
+ " \"ca-central-1\": \"464438896020\",\n",
+ " \"me-south-1\": \"836785723513\",\n",
+ " \"af-south-1\": \"774647643957\",\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d31659f5",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "***"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "14a0ba73",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "# Part 2 - Generate TensorRT Model\n",
+ "\n",
+ "In the following cells, we are using [HuggingFace Auto Classes](https://huggingface.co/docs/transformers/model_doc/auto) to load a pre-trained model from the [HuggingFace Model Hub](https://huggingface.co/models). We then convert the model to the ONNX format, and compile it using NVIDIA TensorRT - namely its command-line wrapper tool, `trtexec` -, using the scripts provided in the official AWS Sample for [SageMaker Triton](https://github.com/aws/amazon-sagemaker-examples/tree/main/sagemaker-triton).\n",
+ "\n",
+ "NVIDIA TensorRT is an SDK that facilitates high-performance machine learning inference. You can use it to create `engines` from models that have already been trained, \n",
+ "optimizing for a selected GPU architecture. Triton natively supports the TensorRT runtime, which enables you to easily deploy a TensorRT engine and pair it with the rich features that Triton provides.\n",
+ "\n",
+ "### Parameters:\n",
+ "\n",
+ "* `model_name`: Model identifier from the Hugging Face model hub library"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5e3f1883",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "model_id = \"sentence-transformers/all-MiniLM-L6-v2\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "436d115f",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "## Option 1 - TensorRT Model with Amazon SageMaker Studio"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "629bfade-8f14-44b6-9be7-88a2fdb84ba9",
+ "metadata": {},
+ "source": [
+ "> **WARNING**: The next cell will only work if you have first created a custom Studio image, described in Step 2 of this repository's README. Change the `RUNNING_IN_STUDIO` to `True` if this is the case."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6df2bf7d-a595-46b1-8d1a-43ab946bc858",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "RUNNING_IN_STUDIO = False"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7c0eb376",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "if RUNNING_IN_STUDIO:\n",
+ " !/bin/bash ./workspace/generate_model_trt.sh $model_id && rm -rf ensemble_hf/bert-trt/1 && mkdir -p ensemble_hf/bert-trt/1 && cp ./model.plan ensemble_hf/bert-trt/1/model.plan && rm -rf ./model.plan ./conversion_bs16_dy.txt ./model.onnx"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b34cf8a7",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "## Option 2 - TensorRT Model with SageMaker Notebook Instances \n",
+ "\n",
+ "To make sure we use TensorRT version and dependencies that are compatible with the ones in our Triton container, we compile the model using the corresponding version of NVIDIA's PyTorch container image.\n",
+ "\n",
+ "If you take a look at the python files within the `workspace` folder, you will see that we are first convert the model into ONNX format, specifying dynamic axis indexes so that inputs with a different batch size and sequence length can be passed to the model. TensorRT will treat other input dimensions as fixed, and optimize for those.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4f1e86f3",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "! docker run --gpus=all --rm -it -v `pwd`/workspace:/workspace nvcr.io/nvidia/pytorch:21.08-py3 /bin/bash generate_model_trt.sh $model_id"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dd0bf459",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "! rm -rf ensemble_hf/bert-trt && mkdir -p ensemble_hf/bert-trt/1 && cp workspace/model.plan ensemble_hf/bert-trt/1/model.plan && rm -rf workspace/model.onnx workspace/core*"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fe095659",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "Explore the output logs of the compilation process; at the very end, we get a section headlined \"=== Performance summary ===\" which gives us a series of metrics on the obtained engine's performance (latency, throughput, etc...). "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8455c0ca",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "# Part 3 - Run Local Triton Inference Server"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ed0cd1c9-c8ab-4f75-a368-a719dd165c04",
+ "metadata": {},
+ "source": [
+ "> **WARNING**: The cells under part 3 will only work if run within a SageMaker Notebook Instance!\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9c22df98",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "\n",
+ "\n",
+ "The following cells run the Triton Inference Server container in the background and load all the models within the folder `/ensemble_hf`. The docker won't fail if one or more of the model fails because of `--exit-on-error=false`, which is useful for iterative code and model repository building. Remove `-d` to see the logs."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "35cac085",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "!sudo docker system prune -f"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d6965857",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "!docker run --gpus=all -d --shm-size=4G --rm -p8000:8000 -p8001:8001 -p8002:8002 -v$(pwd)/ensemble_hf:/model_repository nvcr.io/nvidia/tritonserver:21.08-py3 tritonserver --model-repository=/model_repository --exit-on-error=false --strict-model-config=false\n",
+ "time.sleep(20)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b9950b9c",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "CONTAINER_ID=!docker container ls -q\n",
+ "FIRST_CONTAINER_ID = CONTAINER_ID[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3f903432-6e87-449c-84ea-4c3ed2fa445b",
+ "metadata": {},
+ "source": [
+ "Uncomment the next cell and run it to view the container logs and understand Triton model loading."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9ca9f7dc",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# !docker logs $FIRST_CONTAINER_ID -f"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f5946837",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "## Test TensorRT model by invoking the local Triton Server"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7b5775f1",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Start a local Triton client\n",
+ "try:\n",
+ " triton_client = http_client.InferenceServerClient(url=\"localhost:8000\", verbose=True)\n",
+ "except Exception as e:\n",
+ " print(\"context creation failed: \" + str(e))\n",
+ " sys.exit()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "36b46556",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Create inputs to send to Triton\n",
+ "model_name = \"ensemble\"\n",
+ "\n",
+ "text_inputs = [\"Sentence 1\", \"Sentence 2\"]\n",
+ "\n",
+ "# Text is passed to Trtion as BYTES\n",
+ "inputs = []\n",
+ "inputs.append(http_client.InferInput(\"INPUT0\", [len(text_inputs), 1], \"BYTES\"))\n",
+ "\n",
+ "# We need to structure batch inputs as such\n",
+ "batch_request = [[text_inputs[i]] for i in range(len(text_inputs))]\n",
+ "input0_real = np.array(batch_request, dtype=np.object_)\n",
+ "\n",
+ "inputs[0].set_data_from_numpy(input0_real, binary_data=False)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b47da0cb",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "outputs = []\n",
+ "\n",
+ "outputs.append(http_client.InferRequestedOutput(\"finaloutput\"))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2588e261",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "results = triton_client.infer(model_name=model_name, inputs=inputs, outputs=outputs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a405f8ee",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "outputs_data = results.as_numpy(\"finaloutput\")\n",
+ "\n",
+ "for idx, output in enumerate(outputs_data):\n",
+ " print(text_inputs[idx])\n",
+ " print(output)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1d88a95c",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Use this to stop the container that was started in detached mode\n",
+ "!docker kill $FIRST_CONTAINER_ID"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dc75efff",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "***"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ef0e365f",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "# Part 4 - Deploy Triton to SageMaker Real-Time Endpoint"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "706db9cb",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "## Deploy with SageMaker Triton container"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bdceed91-9fbc-4ea3-ab9e-0e2599ba7281",
+ "metadata": {},
+ "source": [
+ "First we get the URI for the Sagemaker Triton container image that matches the one we used for TensorRT model compilation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e0dd85b6",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "if region not in account_id_map.keys():\n",
+ " raise (\"UNSUPPORTED REGION\")\n",
+ "\n",
+ "base = \"amazonaws.com.cn\" if region.startswith(\"cn-\") else \"amazonaws.com\"\n",
+ "\n",
+ "triton_image_uri = \"{account_id}.dkr.ecr.{region}.{base}/sagemaker-tritonserver:21.08-py3\".format(\n",
+ " account_id=account_id_map[region], region=region, base=base\n",
+ ")\n",
+ "\n",
+ "triton_image_uri"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "081d1204",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "print(sagemaker_session.default_bucket())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0adf2f45",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "ensemble_prefix = \"mme_gpu_tests/ensemble-singlemodel\"\n",
+ "!tar -C ensemble_hf/ -czf ensemble-sentencetrans.tar.gz .\n",
+ "model_uri_tf = sagemaker_session.upload_data(\n",
+ " path=\"ensemble-sentencetrans.tar.gz\", key_prefix=ensemble_prefix\n",
+ ")\n",
+ "\n",
+ "print(\"S3 model uri: {}\".format(model_uri_tf))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "da4eb8ef",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Important to define what which one of the models loaded by Triton is the default to be served by SM\n",
+ "# That is, SAGEMAKER_TRITON_DEFAULT_MODEL_NAME\n",
+ "container_model = {\n",
+ " \"Image\": triton_image_uri,\n",
+ " \"ModelDataUrl\": model_uri_tf,\n",
+ " \"Mode\": \"SingleModel\",\n",
+ " \"Environment\": {\"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME\": \"ensemble\"},\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "16b0ce98-b921-476d-8921-5e3ffb5cc7d4",
+ "metadata": {},
+ "source": [
+ "Register the model with Sagemaker."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e15ae6ac",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "sm_model_name = \"triton-sentence-ensemble\" + time.strftime(\"%Y-%m-%d-%H-%M-%S\", time.gmtime())\n",
+ "\n",
+ "create_model_response = sm_client.create_model(\n",
+ " ModelName=sm_model_name, ExecutionRoleArn=role, PrimaryContainer=container_model\n",
+ ")\n",
+ "\n",
+ "print(\"Model Arn: \" + create_model_response[\"ModelArn\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "695e71ab-c842-4001-8674-0d5c67ffd79f",
+ "metadata": {},
+ "source": [
+ "Create an endpoint configuration."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c6096778",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "endpoint_config_name = \"triton-sentence-ensemble\" + time.strftime(\n",
+ " \"%Y-%m-%d-%H-%M-%S\", time.gmtime()\n",
+ ")\n",
+ "\n",
+ "create_endpoint_config_response = sm_client.create_endpoint_config(\n",
+ " EndpointConfigName=endpoint_config_name,\n",
+ " ProductionVariants=[\n",
+ " {\n",
+ " \"InstanceType\": \"ml.g4dn.xlarge\",\n",
+ " \"InitialVariantWeight\": 1,\n",
+ " \"InitialInstanceCount\": 1,\n",
+ " \"ModelName\": sm_model_name,\n",
+ " \"VariantName\": \"AllTraffic\",\n",
+ " }\n",
+ " ],\n",
+ ")\n",
+ "\n",
+ "print(\"Endpoint Config Arn: \" + create_endpoint_config_response[\"EndpointConfigArn\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c4893f46-dd98-4e60-9490-36026f128446",
+ "metadata": {},
+ "source": [
+ "Deploy the endpoint."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e9932ae0",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "endpoint_name = \"triton-sentence-ensemble\" + time.strftime(\"%Y-%m-%d-%H-%M-%S\", time.gmtime())\n",
+ "\n",
+ "create_endpoint_response = sm_client.create_endpoint(\n",
+ " EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name\n",
+ ")\n",
+ "\n",
+ "print(\"Endpoint Arn: \" + create_endpoint_response[\"EndpointArn\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a3ec6a48-5fc5-4495-9b1d-10f94ef95277",
+ "metadata": {},
+ "source": [
+ "Wait for the endpoint to be up and running."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f257b3e7",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "resp = sm_client.describe_endpoint(EndpointName=endpoint_name)\n",
+ "status = resp[\"EndpointStatus\"]\n",
+ "print(\"Status: \" + status)\n",
+ "\n",
+ "while status == \"Creating\":\n",
+ " time.sleep(60)\n",
+ " resp = sm_client.describe_endpoint(EndpointName=endpoint_name)\n",
+ " status = resp[\"EndpointStatus\"]\n",
+ " print(\"Status: \" + status)\n",
+ "\n",
+ "print(\"Arn: \" + resp[\"EndpointArn\"])\n",
+ "print(\"Status: \" + status)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7aee2ad4",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "***"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "59448028",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "## Test the SageMaker Triton Endpoint"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d55e6ea4",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "text_inputs = [\"Sentence 1\", \"Sentence 2\"]\n",
+ "\n",
+ "inputs = []\n",
+ "inputs.append(http_client.InferInput(\"INPUT0\", [len(text_inputs), 1], \"BYTES\"))\n",
+ "\n",
+ "batch_request = [[text_inputs[i]] for i in range(len(text_inputs))]\n",
+ "\n",
+ "input0_real = np.array(batch_request, dtype=np.object_)\n",
+ "\n",
+ "inputs[0].set_data_from_numpy(input0_real, binary_data=False)\n",
+ "\n",
+ "len(input0_real)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "71acf686",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "outputs = []\n",
+ "\n",
+ "outputs.append(http_client.InferRequestedOutput(\"finaloutput\"))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8cc9a386",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "request_body, header_length = http_client.InferenceServerClient.generate_request_body(\n",
+ " inputs, outputs=outputs\n",
+ ")\n",
+ "\n",
+ "print(request_body)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2782361a",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "response = sm_runtime_client.invoke_endpoint(\n",
+ " EndpointName=endpoint_name,\n",
+ " ContentType=\"application/vnd.sagemaker-triton.binary+json;json-header-size={}\".format(\n",
+ " header_length\n",
+ " ),\n",
+ " Body=request_body,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "65724cd1",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "## json.loads fails\n",
+ "# a = json.loads(response[\"Body\"].read().decode(\"utf8\"))\n",
+ "\n",
+ "header_length_prefix = \"application/vnd.sagemaker-triton.binary+json;json-header-size=\"\n",
+ "header_length_str = response[\"ContentType\"][len(header_length_prefix) :]\n",
+ "\n",
+ "# Read response body\n",
+ "result = http_client.InferenceServerClient.parse_response_body(\n",
+ " response[\"Body\"].read(), header_length=int(header_length_str)\n",
+ ")\n",
+ "\n",
+ "outputs_data = result.as_numpy(\"finaloutput\")\n",
+ "\n",
+ "for idx, output in enumerate(outputs_data):\n",
+ " print(text_inputs[idx])\n",
+ " print(output)"
+ ]
+ }
+ ],
+ "metadata": {
+ "instance_type": "ml.g4dn.xlarge",
+ "kernelspec": {
+ "display_name": "conda_pytorch_p38",
+ "language": "python",
+ "name": "conda_pytorch_p38"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.12"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/workspace/generate_model_trt.sh b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/workspace/generate_model_trt.sh
new file mode 100755
index 0000000000..8c68d40c60
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/workspace/generate_model_trt.sh
@@ -0,0 +1,14 @@
+#!/bin/bash
+MODEL_NAME=$1
+python -m pip install transformers==4.9.1
+python onnx_exporter.py --model $MODEL_NAME
+
+trtexec \
+ --onnx=model.onnx \
+ --saveEngine=model.plan \
+ --minShapes=token_ids:1x128,attn_mask:1x128 \
+ --optShapes=token_ids:16x128,attn_mask:16x128 \
+ --maxShapes=token_ids:32x128,attn_mask:32x128 \
+ --verbose \
+ --workspace=14000 \
+| tee conversion.txt
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/workspace/onnx_exporter.py b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/workspace/onnx_exporter.py
new file mode 100644
index 0000000000..b7e0907e52
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/workspace/onnx_exporter.py
@@ -0,0 +1,30 @@
+import torch
+from transformers import AutoModel
+import argparse
+import os
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--save", default="model.onnx")
+ parser.add_argument("--model", required=True)
+
+ args = parser.parse_args()
+
+ model = AutoModel.from_pretrained(args.model, torchscript=True)
+
+ bs = 1
+ seq_len = 128
+ dummy_inputs = (torch.randint(1000, (bs, seq_len),dtype=torch.int), torch.zeros(bs, seq_len, dtype=torch.int))
+
+ torch.onnx.export(
+ model,
+ dummy_inputs,
+ args.save,
+ export_params=True,
+ opset_version=10,
+ input_names=["token_ids", "attn_mask"],
+ output_names=["output"],
+ dynamic_axes={"token_ids": [0, 1], "attn_mask": [0, 1], "output": [0]},
+ )
+
+ print("Saved {}".format(args.save))
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/images/triton-ensemble.png b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/images/triton-ensemble.png
new file mode 100644
index 0000000000..32f5c1a6aa
Binary files /dev/null and b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/images/triton-ensemble.png differ
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/studio-image/README.md b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/studio-image/README.md
new file mode 100644
index 0000000000..76083a1c26
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/studio-image/README.md
@@ -0,0 +1,67 @@
+## build_image.sh
+
+This script allows you to create a custom docker image and push on ECR
+
+Parameters:
+* IMAGE_NAME: *Mandatory* - Name of the image you want to build
+* REGISTRY_NAME: *Mandatory* - Name of the ECR repository you want to use for pushing the image
+* IMAGE_TAG: *Mandatory* - Tag to apply to the ECR image
+* DOCKER_FILE: *Mandatory* - Dockerfile to build
+* PLATFORM: *Optional* - Target architecture chip where the image is executed
+```
+./build_image.sh
+
+#### ! Important: The example provided can be tested also by using Amazon SageMaker Notebook Instances
+
+### Prerequisites
+
+1. Required NVIDIA NGC Account. Follow the instruction https://docs.nvidia.com/ngc/ngc-catalog-user-guide/index.html#registering-activating-ngc-account
+
+## Step 1: Clone this repository
+
+## Step 2: Build Studio image
+
+In this example, we provide a [Dokerfile](./studio-image/image_tensorrt/Dockerfile) example to build a custom image for SageMaker Studio.
+
+To build the image, push it and make it available in your Amazon SageMaker Studio environment, edit [sagemaker-studio-config](./studio-image/studio-domain-config.json) by replacing `$DOMAIN_ID` with your Studio domain ID.
+
+We also provide automation scripts in order to [build and push](./studio-image/build_image.sh) your docker image to an ECR repository
+and [create](./studio-image/create_studio_image.sh) or [update](./studio-image/update_studio_image.sh) an Amazon SageMaker Image. Please follow the instructions in the [README](./studio-image/README.md) for additional info on the usage of this script.
+
+## Step 3: Compile model, create an Amazon SageMaker Real-Time Endpoint with NVIDIA Triton Inference Server
+
+Clone this repository into your Amazon SageMaker Studio environment and execute the cells in the [notebook](./examples/triton_sentence_embeddings.ipynb)
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/bert-trt/config.pbtxt b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/bert-trt/config.pbtxt
new file mode 100644
index 0000000000..3bf605dfc4
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/bert-trt/config.pbtxt
@@ -0,0 +1,32 @@
+name: "bert-trt"
+platform: "tensorrt_plan"
+max_batch_size: 16
+input [
+ {
+ name: "token_ids"
+ data_type: TYPE_INT32
+ dims: [128]
+ },
+ {
+ name: "attn_mask"
+ data_type: TYPE_INT32
+ dims: [128]
+ }
+]
+output [
+ {
+ name: "output"
+ data_type: TYPE_FP32
+ dims: [128, 384]
+ },
+ {
+ name: "854"
+ data_type: TYPE_FP32
+ dims: [384]
+ }
+]
+instance_group [
+ {
+ kind: KIND_GPU
+ }
+ ]
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/ensemble/1/README.md b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/ensemble/1/README.md
new file mode 100644
index 0000000000..a8e639ff9d
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/ensemble/1/README.md
@@ -0,0 +1 @@
+Do not delete me!
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/ensemble/config.pbtxt b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/ensemble/config.pbtxt
new file mode 100644
index 0000000000..aa36dd1ded
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/ensemble/config.pbtxt
@@ -0,0 +1,70 @@
+name: "ensemble"
+platform: "ensemble"
+max_batch_size: 16
+input [
+ {
+ name: "INPUT0"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ }
+]
+output [
+ {
+ name: "finaloutput"
+ data_type: TYPE_FP32
+ dims: [384]
+ }
+]
+ensemble_scheduling {
+ step [
+ {
+ model_name: "preprocess"
+ model_version: -1
+ input_map {
+ key: "INPUT0"
+ value: "INPUT0"
+ }
+ output_map {
+ key: "OUTPUT0"
+ value: "token_ids"
+ }
+ output_map {
+ key: "OUTPUT1"
+ value: "attn_mask"
+ }
+ },
+ {
+ model_name: "bert-trt"
+ model_version: -1
+ input_map {
+ key: "token_ids"
+ value: "token_ids"
+ }
+ input_map {
+ key: "attn_mask"
+ value: "attn_mask"
+ }
+ output_map {
+ key: "output"
+ value: "output"
+ }
+ },
+ {
+ model_name: "postprocess"
+ model_version: -1
+ input_map {
+ key: "TOKEN_EMBEDS_POST"
+ value: "output"
+ }
+ input_map {
+ key: "ATTENTION_POST"
+ value: "attn_mask"
+ }
+ output_map {
+ key: "SENT_EMBED"
+ value: "finaloutput"
+ }
+
+ }
+ ]
+}
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/1/model.py b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/1/model.py
new file mode 100644
index 0000000000..5373e90dbb
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/1/model.py
@@ -0,0 +1,78 @@
+import json
+import logging
+import numpy as np
+import subprocess
+import sys
+import os
+
+import triton_python_backend_utils as pb_utils
+
+logging.basicConfig(level=logging.INFO)
+logger = logging.getLogger(__name__)
+
+class TritonPythonModel:
+ """This model loops through different dtypes to make sure that
+ serialize_byte_tensor works correctly in the Python backend.
+ """
+
+ def __mean_pooling(self, token_embeddings, attention_mask):
+ logger.info("token_embeddings: {}".format(token_embeddings))
+ logger.info("attention_mask: {}".format(attention_mask))
+
+ input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
+ return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
+
+ def initialize(self, args):
+ self.model_dir = args['model_repository']
+ subprocess.check_call([sys.executable, "-m", "pip", "install", '-r', f'{self.model_dir}/requirements.txt'])
+ global torch
+ import torch
+
+ self.device_id = args['model_instance_device_id']
+ self.model_config = model_config = json.loads(args['model_config'])
+ self.device = torch.device(f'cuda:{self.device_id}') if torch.cuda.is_available() else torch.device('cpu')
+
+ output0_config = pb_utils.get_output_config_by_name(
+ model_config, "SENT_EMBED")
+
+ self.output0_dtype = pb_utils.triton_string_to_numpy(
+ output0_config["data_type"])
+
+ def execute(self, requests):
+
+ responses = []
+
+ for request in requests:
+ tok_embeds = pb_utils.get_input_tensor_by_name(request, "TOKEN_EMBEDS_POST")
+ attn_mask = pb_utils.get_input_tensor_by_name(request, "ATTENTION_POST")
+
+ tok_embeds = tok_embeds.as_numpy()
+
+ logger.info("tok_embeds: {}".format(tok_embeds))
+ logger.info("tok_embeds shape: {}".format(tok_embeds.shape))
+
+ tok_embeds = torch.tensor(tok_embeds,device=self.device)
+
+ logger.info("tok_embeds_tensor: {}".format(tok_embeds))
+
+ attn_mask = attn_mask.as_numpy()
+
+ logger.info("attn_mask: {}".format(attn_mask))
+ logger.info("attn_mask shape: {}".format(attn_mask.shape))
+
+ attn_mask = torch.tensor(attn_mask,device=self.device)
+
+ logger.info("attn_mask_tensor: {}".format(attn_mask))
+
+ sentence_embeddings = self.__mean_pooling(tok_embeds, attn_mask)
+ sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
+
+ out_0 = np.array(sentence_embeddings.cpu(),dtype=self.output0_dtype)
+ logger.info("out_0: {}".format(out_0))
+
+ out_tensor_0 = pb_utils.Tensor("SENT_EMBED", out_0)
+ logger.info("out_tensor_0: {}".format(out_tensor_0))
+
+ responses.append(pb_utils.InferenceResponse([out_tensor_0]))
+
+ return responses
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/config.pbtxt b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/config.pbtxt
new file mode 100644
index 0000000000..de573d924d
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/config.pbtxt
@@ -0,0 +1,26 @@
+name: "postprocess"
+backend: "python"
+max_batch_size: 16
+
+input [
+ {
+ name: "TOKEN_EMBEDS_POST"
+ data_type: TYPE_FP32
+ dims: [128, 384]
+
+ },
+ {
+ name: "ATTENTION_POST"
+ data_type: TYPE_INT32
+ dims: [128]
+ }
+]
+output [
+ {
+ name: "SENT_EMBED"
+ data_type: TYPE_FP32
+ dims: [ 384 ]
+ }
+]
+
+instance_group [{ kind: KIND_GPU }]
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/requirements.txt b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/requirements.txt
new file mode 100644
index 0000000000..08ed5eeb4b
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/postprocess/requirements.txt
@@ -0,0 +1 @@
+torch
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/1/model.py b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/1/model.py
new file mode 100644
index 0000000000..47b1f1befc
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/1/model.py
@@ -0,0 +1,74 @@
+import json
+import logging
+import numpy as np
+import subprocess
+import sys
+
+import triton_python_backend_utils as pb_utils
+
+logging.basicConfig(level=logging.INFO)
+logger = logging.getLogger(__name__)
+
+class TritonPythonModel:
+ """This model loops through different dtypes to make sure that
+ serialize_byte_tensor works correctly in the Python backend.
+ """
+
+ def initialize(self, args):
+ self.model_dir = args['model_repository']
+ subprocess.check_call([sys.executable, "-m", "pip", "install", '-r', f'{self.model_dir}/requirements.txt'])
+ global transformers
+ import transformers
+
+ self.tokenizer = transformers.AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
+ self.model_config = model_config = json.loads(args['model_config'])
+
+ output0_config = pb_utils.get_output_config_by_name(
+ model_config, "OUTPUT0")
+ output1_config = pb_utils.get_output_config_by_name(
+ model_config, "OUTPUT1")
+
+ self.output0_dtype = pb_utils.triton_string_to_numpy(
+ output0_config['data_type'])
+ self.output1_dtype = pb_utils.triton_string_to_numpy(
+ output0_config['data_type'])
+
+ def execute(self, requests):
+
+ file = open("logs.txt", "w")
+
+ responses = []
+ for request in requests:
+ logger.info("Request: {}".format(request))
+
+ in_0 = pb_utils.get_input_tensor_by_name(request, "INPUT0")
+ in_0 = in_0.as_numpy()
+
+ logger.info("in_0: {}".format(in_0))
+
+ tok_batch = []
+
+ for i in range(in_0.shape[0]):
+ decoded_object = in_0[i,0].decode()
+
+ logger.info("decoded_object: {}".format(decoded_object))
+
+ tok_batch.append(decoded_object)
+
+ logger.info("tok_batch: {}".format(tok_batch))
+
+ tok_sent = self.tokenizer(tok_batch,
+ padding='max_length',
+ max_length=128,
+ )
+
+
+ logger.info("Tokens: {}".format(tok_sent))
+
+ out_0 = np.array(tok_sent['input_ids'],dtype=self.output0_dtype)
+ out_1 = np.array(tok_sent['attention_mask'],dtype=self.output1_dtype)
+ out_tensor_0 = pb_utils.Tensor("OUTPUT0", out_0)
+ out_tensor_1 = pb_utils.Tensor("OUTPUT1", out_1)
+
+ responses.append(pb_utils.InferenceResponse([out_tensor_0,out_tensor_1]))
+ return responses
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/config.pbtxt b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/config.pbtxt
new file mode 100644
index 0000000000..c3f70b03dd
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/config.pbtxt
@@ -0,0 +1,28 @@
+name: "preprocess"
+backend: "python"
+max_batch_size: 16
+
+input [
+ {
+ name: "INPUT0"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+
+ }
+]
+output [
+ {
+ name: "OUTPUT0"
+ data_type: TYPE_INT32
+ dims: [ 128 ]
+ },
+
+ {
+ name: "OUTPUT1"
+ data_type: TYPE_INT32
+ dims: [ 128 ]
+ }
+
+]
+
+instance_group [{ kind: KIND_CPU }]
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/requirements.txt b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/requirements.txt
new file mode 100644
index 0000000000..747b7aa97a
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/ensemble_hf/preprocess/requirements.txt
@@ -0,0 +1 @@
+transformers
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/triton_sentence_embeddings.ipynb b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/triton_sentence_embeddings.ipynb
new file mode 100644
index 0000000000..5fef5c4405
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/triton_sentence_embeddings.ipynb
@@ -0,0 +1,1015 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "ce5723a5",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "# Prerequisites\n",
+ "\n",
+ "Install the necessary Python modules to use and interact with [NVIDIA Triton Inference Server](https://github.com/triton-inference-server/server/)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f5995424",
+ "metadata": {
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "! pip install torch==1.10.0 sagemaker transformers==4.9.1 tritonclient[all]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4d9d12fa",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "# Part 1 - Setup"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "3aef44c4",
+ "metadata": {
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import argparse\n",
+ "import boto3\n",
+ "import copy\n",
+ "import datetime\n",
+ "import json\n",
+ "import numpy as np\n",
+ "import os\n",
+ "import pandas as pd\n",
+ "import pprint\n",
+ "import re\n",
+ "import sagemaker\n",
+ "import sys\n",
+ "import time\n",
+ "from time import gmtime, strftime\n",
+ "import tritonclient.http as http_client"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fe9a1636",
+ "metadata": {
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "session = boto3.Session()\n",
+ "role = sagemaker.get_execution_role()\n",
+ "\n",
+ "sm_client = session.client(\"sagemaker\")\n",
+ "sagemaker_session = sagemaker.Session(boto_session=session)\n",
+ "sm_runtime_client = boto3.client(\"sagemaker-runtime\")\n",
+ "\n",
+ "region = boto3.Session().region_name"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a4996fe6",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "account_id_map = {\n",
+ " \"us-east-1\": \"785573368785\",\n",
+ " \"us-east-2\": \"007439368137\",\n",
+ " \"us-west-1\": \"710691900526\",\n",
+ " \"us-west-2\": \"301217895009\",\n",
+ " \"eu-west-1\": \"802834080501\",\n",
+ " \"eu-west-2\": \"205493899709\",\n",
+ " \"eu-west-3\": \"254080097072\",\n",
+ " \"eu-north-1\": \"601324751636\",\n",
+ " \"eu-south-1\": \"966458181534\",\n",
+ " \"eu-central-1\": \"746233611703\",\n",
+ " \"ap-east-1\": \"110948597952\",\n",
+ " \"ap-south-1\": \"763008648453\",\n",
+ " \"ap-northeast-1\": \"941853720454\",\n",
+ " \"ap-northeast-2\": \"151534178276\",\n",
+ " \"ap-southeast-1\": \"324986816169\",\n",
+ " \"ap-southeast-2\": \"355873309152\",\n",
+ " \"cn-northwest-1\": \"474822919863\",\n",
+ " \"cn-north-1\": \"472730292857\",\n",
+ " \"sa-east-1\": \"756306329178\",\n",
+ " \"ca-central-1\": \"464438896020\",\n",
+ " \"me-south-1\": \"836785723513\",\n",
+ " \"af-south-1\": \"774647643957\",\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d31659f5",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "***"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "14a0ba73",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "# Part 2 - Generate TensorRT Model\n",
+ "\n",
+ "In the following cells, we are using [HuggingFace Auto Classes](https://huggingface.co/docs/transformers/model_doc/auto) to load a pre-trained model from the [HuggingFace Model Hub](https://huggingface.co/models). We then convert the model to the ONNX format, and compile it using NVIDIA TensorRT - namely its command-line wrapper tool, `trtexec` -, using the scripts provided in the official AWS Sample for [SageMaker Triton](https://github.com/aws/amazon-sagemaker-examples/tree/main/sagemaker-triton).\n",
+ "\n",
+ "NVIDIA TensorRT is an SDK that facilitates high-performance machine learning inference. You can use it to create `engines` from models that have already been trained, \n",
+ "optimizing for a selected GPU architecture. Triton natively supports the TensorRT runtime, which enables you to easily deploy a TensorRT engine and pair it with the rich features that Triton provides.\n",
+ "\n",
+ "### Parameters:\n",
+ "\n",
+ "* `model_name`: Model identifier from the Hugging Face model hub library"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5e3f1883",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "model_id = \"sentence-transformers/all-MiniLM-L6-v2\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "436d115f",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "## Option 1 - TensorRT Model with Amazon SageMaker Studio"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "629bfade-8f14-44b6-9be7-88a2fdb84ba9",
+ "metadata": {},
+ "source": [
+ "> **WARNING**: The next cell will only work if you have first created a custom Studio image, described in Step 2 of this repository's README. Change the `RUNNING_IN_STUDIO` to `True` if this is the case."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6df2bf7d-a595-46b1-8d1a-43ab946bc858",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "RUNNING_IN_STUDIO = False"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7c0eb376",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "if RUNNING_IN_STUDIO:\n",
+ " !/bin/bash ./workspace/generate_model_trt.sh $model_id && rm -rf ensemble_hf/bert-trt/1 && mkdir -p ensemble_hf/bert-trt/1 && cp ./model.plan ensemble_hf/bert-trt/1/model.plan && rm -rf ./model.plan ./conversion_bs16_dy.txt ./model.onnx"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b34cf8a7",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "## Option 2 - TensorRT Model with SageMaker Notebook Instances \n",
+ "\n",
+ "To make sure we use TensorRT version and dependencies that are compatible with the ones in our Triton container, we compile the model using the corresponding version of NVIDIA's PyTorch container image.\n",
+ "\n",
+ "If you take a look at the python files within the `workspace` folder, you will see that we are first convert the model into ONNX format, specifying dynamic axis indexes so that inputs with a different batch size and sequence length can be passed to the model. TensorRT will treat other input dimensions as fixed, and optimize for those.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4f1e86f3",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "! docker run --gpus=all --rm -it -v `pwd`/workspace:/workspace nvcr.io/nvidia/pytorch:21.08-py3 /bin/bash generate_model_trt.sh $model_id"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "dd0bf459",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "! rm -rf ensemble_hf/bert-trt && mkdir -p ensemble_hf/bert-trt/1 && cp workspace/model.plan ensemble_hf/bert-trt/1/model.plan && rm -rf workspace/model.onnx workspace/core*"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fe095659",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "Explore the output logs of the compilation process; at the very end, we get a section headlined \"=== Performance summary ===\" which gives us a series of metrics on the obtained engine's performance (latency, throughput, etc...). "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8455c0ca",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "# Part 3 - Run Local Triton Inference Server"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ed0cd1c9-c8ab-4f75-a368-a719dd165c04",
+ "metadata": {},
+ "source": [
+ "> **WARNING**: The cells under part 3 will only work if run within a SageMaker Notebook Instance!\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9c22df98",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "\n",
+ "\n",
+ "The following cells run the Triton Inference Server container in the background and load all the models within the folder `/ensemble_hf`. The docker won't fail if one or more of the model fails because of `--exit-on-error=false`, which is useful for iterative code and model repository building. Remove `-d` to see the logs."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "35cac085",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "!sudo docker system prune -f"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d6965857",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "!docker run --gpus=all -d --shm-size=4G --rm -p8000:8000 -p8001:8001 -p8002:8002 -v$(pwd)/ensemble_hf:/model_repository nvcr.io/nvidia/tritonserver:21.08-py3 tritonserver --model-repository=/model_repository --exit-on-error=false --strict-model-config=false\n",
+ "time.sleep(20)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b9950b9c",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "CONTAINER_ID=!docker container ls -q\n",
+ "FIRST_CONTAINER_ID = CONTAINER_ID[0]"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3f903432-6e87-449c-84ea-4c3ed2fa445b",
+ "metadata": {},
+ "source": [
+ "Uncomment the next cell and run it to view the container logs and understand Triton model loading."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9ca9f7dc",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# !docker logs $FIRST_CONTAINER_ID -f"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f5946837",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "## Test TensorRT model by invoking the local Triton Server"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7b5775f1",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Start a local Triton client\n",
+ "try:\n",
+ " triton_client = http_client.InferenceServerClient(url=\"localhost:8000\", verbose=True)\n",
+ "except Exception as e:\n",
+ " print(\"context creation failed: \" + str(e))\n",
+ " sys.exit()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "36b46556",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Create inputs to send to Triton\n",
+ "model_name = \"ensemble\"\n",
+ "\n",
+ "text_inputs = [\"Sentence 1\", \"Sentence 2\"]\n",
+ "\n",
+ "# Text is passed to Trtion as BYTES\n",
+ "inputs = []\n",
+ "inputs.append(http_client.InferInput(\"INPUT0\", [len(text_inputs), 1], \"BYTES\"))\n",
+ "\n",
+ "# We need to structure batch inputs as such\n",
+ "batch_request = [[text_inputs[i]] for i in range(len(text_inputs))]\n",
+ "input0_real = np.array(batch_request, dtype=np.object_)\n",
+ "\n",
+ "inputs[0].set_data_from_numpy(input0_real, binary_data=False)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b47da0cb",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "outputs = []\n",
+ "\n",
+ "outputs.append(http_client.InferRequestedOutput(\"finaloutput\"))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2588e261",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "results = triton_client.infer(model_name=model_name, inputs=inputs, outputs=outputs)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "a405f8ee",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "outputs_data = results.as_numpy(\"finaloutput\")\n",
+ "\n",
+ "for idx, output in enumerate(outputs_data):\n",
+ " print(text_inputs[idx])\n",
+ " print(output)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1d88a95c",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Use this to stop the container that was started in detached mode\n",
+ "!docker kill $FIRST_CONTAINER_ID"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "dc75efff",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "***"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ef0e365f",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "# Part 4 - Deploy Triton to SageMaker Real-Time Endpoint"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "706db9cb",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "## Deploy with SageMaker Triton container"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bdceed91-9fbc-4ea3-ab9e-0e2599ba7281",
+ "metadata": {},
+ "source": [
+ "First we get the URI for the Sagemaker Triton container image that matches the one we used for TensorRT model compilation."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e0dd85b6",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "if region not in account_id_map.keys():\n",
+ " raise (\"UNSUPPORTED REGION\")\n",
+ "\n",
+ "base = \"amazonaws.com.cn\" if region.startswith(\"cn-\") else \"amazonaws.com\"\n",
+ "\n",
+ "triton_image_uri = \"{account_id}.dkr.ecr.{region}.{base}/sagemaker-tritonserver:21.08-py3\".format(\n",
+ " account_id=account_id_map[region], region=region, base=base\n",
+ ")\n",
+ "\n",
+ "triton_image_uri"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "081d1204",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "print(sagemaker_session.default_bucket())"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0adf2f45",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "ensemble_prefix = \"mme_gpu_tests/ensemble-singlemodel\"\n",
+ "!tar -C ensemble_hf/ -czf ensemble-sentencetrans.tar.gz .\n",
+ "model_uri_tf = sagemaker_session.upload_data(\n",
+ " path=\"ensemble-sentencetrans.tar.gz\", key_prefix=ensemble_prefix\n",
+ ")\n",
+ "\n",
+ "print(\"S3 model uri: {}\".format(model_uri_tf))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "da4eb8ef",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "# Important to define what which one of the models loaded by Triton is the default to be served by SM\n",
+ "# That is, SAGEMAKER_TRITON_DEFAULT_MODEL_NAME\n",
+ "container_model = {\n",
+ " \"Image\": triton_image_uri,\n",
+ " \"ModelDataUrl\": model_uri_tf,\n",
+ " \"Mode\": \"SingleModel\",\n",
+ " \"Environment\": {\"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME\": \"ensemble\"},\n",
+ "}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "16b0ce98-b921-476d-8921-5e3ffb5cc7d4",
+ "metadata": {},
+ "source": [
+ "Register the model with Sagemaker."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e15ae6ac",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "sm_model_name = \"triton-sentence-ensemble\" + time.strftime(\"%Y-%m-%d-%H-%M-%S\", time.gmtime())\n",
+ "\n",
+ "create_model_response = sm_client.create_model(\n",
+ " ModelName=sm_model_name, ExecutionRoleArn=role, PrimaryContainer=container_model\n",
+ ")\n",
+ "\n",
+ "print(\"Model Arn: \" + create_model_response[\"ModelArn\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "695e71ab-c842-4001-8674-0d5c67ffd79f",
+ "metadata": {},
+ "source": [
+ "Create an endpoint configuration."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c6096778",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "endpoint_config_name = \"triton-sentence-ensemble\" + time.strftime(\n",
+ " \"%Y-%m-%d-%H-%M-%S\", time.gmtime()\n",
+ ")\n",
+ "\n",
+ "create_endpoint_config_response = sm_client.create_endpoint_config(\n",
+ " EndpointConfigName=endpoint_config_name,\n",
+ " ProductionVariants=[\n",
+ " {\n",
+ " \"InstanceType\": \"ml.g4dn.xlarge\",\n",
+ " \"InitialVariantWeight\": 1,\n",
+ " \"InitialInstanceCount\": 1,\n",
+ " \"ModelName\": sm_model_name,\n",
+ " \"VariantName\": \"AllTraffic\",\n",
+ " }\n",
+ " ],\n",
+ ")\n",
+ "\n",
+ "print(\"Endpoint Config Arn: \" + create_endpoint_config_response[\"EndpointConfigArn\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c4893f46-dd98-4e60-9490-36026f128446",
+ "metadata": {},
+ "source": [
+ "Deploy the endpoint."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e9932ae0",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "endpoint_name = \"triton-sentence-ensemble\" + time.strftime(\"%Y-%m-%d-%H-%M-%S\", time.gmtime())\n",
+ "\n",
+ "create_endpoint_response = sm_client.create_endpoint(\n",
+ " EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name\n",
+ ")\n",
+ "\n",
+ "print(\"Endpoint Arn: \" + create_endpoint_response[\"EndpointArn\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a3ec6a48-5fc5-4495-9b1d-10f94ef95277",
+ "metadata": {},
+ "source": [
+ "Wait for the endpoint to be up and running."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f257b3e7",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "resp = sm_client.describe_endpoint(EndpointName=endpoint_name)\n",
+ "status = resp[\"EndpointStatus\"]\n",
+ "print(\"Status: \" + status)\n",
+ "\n",
+ "while status == \"Creating\":\n",
+ " time.sleep(60)\n",
+ " resp = sm_client.describe_endpoint(EndpointName=endpoint_name)\n",
+ " status = resp[\"EndpointStatus\"]\n",
+ " print(\"Status: \" + status)\n",
+ "\n",
+ "print(\"Arn: \" + resp[\"EndpointArn\"])\n",
+ "print(\"Status: \" + status)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7aee2ad4",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "***"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "59448028",
+ "metadata": {
+ "pycharm": {
+ "name": "#%% md\n"
+ }
+ },
+ "source": [
+ "## Test the SageMaker Triton Endpoint"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "d55e6ea4",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "text_inputs = [\"Sentence 1\", \"Sentence 2\"]\n",
+ "\n",
+ "inputs = []\n",
+ "inputs.append(http_client.InferInput(\"INPUT0\", [len(text_inputs), 1], \"BYTES\"))\n",
+ "\n",
+ "batch_request = [[text_inputs[i]] for i in range(len(text_inputs))]\n",
+ "\n",
+ "input0_real = np.array(batch_request, dtype=np.object_)\n",
+ "\n",
+ "inputs[0].set_data_from_numpy(input0_real, binary_data=False)\n",
+ "\n",
+ "len(input0_real)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "71acf686",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "outputs = []\n",
+ "\n",
+ "outputs.append(http_client.InferRequestedOutput(\"finaloutput\"))"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8cc9a386",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "request_body, header_length = http_client.InferenceServerClient.generate_request_body(\n",
+ " inputs, outputs=outputs\n",
+ ")\n",
+ "\n",
+ "print(request_body)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "2782361a",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "response = sm_runtime_client.invoke_endpoint(\n",
+ " EndpointName=endpoint_name,\n",
+ " ContentType=\"application/vnd.sagemaker-triton.binary+json;json-header-size={}\".format(\n",
+ " header_length\n",
+ " ),\n",
+ " Body=request_body,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "65724cd1",
+ "metadata": {
+ "collapsed": false,
+ "jupyter": {
+ "outputs_hidden": false
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "## json.loads fails\n",
+ "# a = json.loads(response[\"Body\"].read().decode(\"utf8\"))\n",
+ "\n",
+ "header_length_prefix = \"application/vnd.sagemaker-triton.binary+json;json-header-size=\"\n",
+ "header_length_str = response[\"ContentType\"][len(header_length_prefix) :]\n",
+ "\n",
+ "# Read response body\n",
+ "result = http_client.InferenceServerClient.parse_response_body(\n",
+ " response[\"Body\"].read(), header_length=int(header_length_str)\n",
+ ")\n",
+ "\n",
+ "outputs_data = result.as_numpy(\"finaloutput\")\n",
+ "\n",
+ "for idx, output in enumerate(outputs_data):\n",
+ " print(text_inputs[idx])\n",
+ " print(output)"
+ ]
+ }
+ ],
+ "metadata": {
+ "instance_type": "ml.g4dn.xlarge",
+ "kernelspec": {
+ "display_name": "conda_pytorch_p38",
+ "language": "python",
+ "name": "conda_pytorch_p38"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.12"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/workspace/generate_model_trt.sh b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/workspace/generate_model_trt.sh
new file mode 100755
index 0000000000..8c68d40c60
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/workspace/generate_model_trt.sh
@@ -0,0 +1,14 @@
+#!/bin/bash
+MODEL_NAME=$1
+python -m pip install transformers==4.9.1
+python onnx_exporter.py --model $MODEL_NAME
+
+trtexec \
+ --onnx=model.onnx \
+ --saveEngine=model.plan \
+ --minShapes=token_ids:1x128,attn_mask:1x128 \
+ --optShapes=token_ids:16x128,attn_mask:16x128 \
+ --maxShapes=token_ids:32x128,attn_mask:32x128 \
+ --verbose \
+ --workspace=14000 \
+| tee conversion.txt
\ No newline at end of file
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/workspace/onnx_exporter.py b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/workspace/onnx_exporter.py
new file mode 100644
index 0000000000..b7e0907e52
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/examples/workspace/onnx_exporter.py
@@ -0,0 +1,30 @@
+import torch
+from transformers import AutoModel
+import argparse
+import os
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--save", default="model.onnx")
+ parser.add_argument("--model", required=True)
+
+ args = parser.parse_args()
+
+ model = AutoModel.from_pretrained(args.model, torchscript=True)
+
+ bs = 1
+ seq_len = 128
+ dummy_inputs = (torch.randint(1000, (bs, seq_len),dtype=torch.int), torch.zeros(bs, seq_len, dtype=torch.int))
+
+ torch.onnx.export(
+ model,
+ dummy_inputs,
+ args.save,
+ export_params=True,
+ opset_version=10,
+ input_names=["token_ids", "attn_mask"],
+ output_names=["output"],
+ dynamic_axes={"token_ids": [0, 1], "attn_mask": [0, 1], "output": [0]},
+ )
+
+ print("Saved {}".format(args.save))
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/images/triton-ensemble.png b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/images/triton-ensemble.png
new file mode 100644
index 0000000000..32f5c1a6aa
Binary files /dev/null and b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/images/triton-ensemble.png differ
diff --git a/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/studio-image/README.md b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/studio-image/README.md
new file mode 100644
index 0000000000..76083a1c26
--- /dev/null
+++ b/inference/nlp/realtime/huggingface/sentence-transformers-triton-ensemble/studio-image/README.md
@@ -0,0 +1,67 @@
+## build_image.sh
+
+This script allows you to create a custom docker image and push on ECR
+
+Parameters:
+* IMAGE_NAME: *Mandatory* - Name of the image you want to build
+* REGISTRY_NAME: *Mandatory* - Name of the ECR repository you want to use for pushing the image
+* IMAGE_TAG: *Mandatory* - Tag to apply to the ECR image
+* DOCKER_FILE: *Mandatory* - Dockerfile to build
+* PLATFORM: *Optional* - Target architecture chip where the image is executed
+```
+./build_image.sh  +
+## 3. Architecture Overview
+
+The following illustration is the architecture for the end-to-end training and deployment process
+
+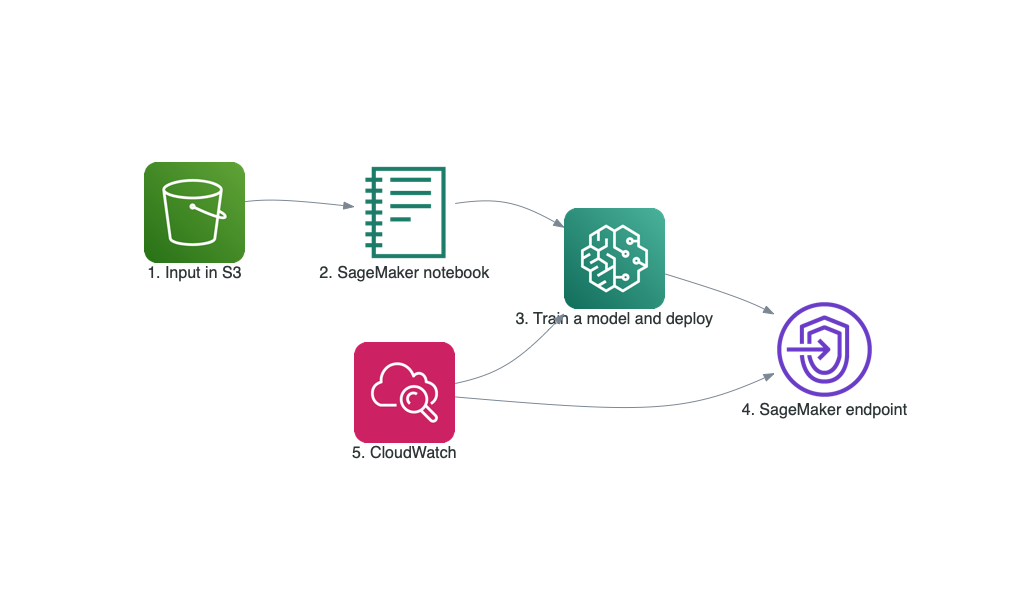
+
+1. The input data located in an [Amazon S3](https://aws.amazon.com/s3/) bucket
+2. The provided [SageMaker notebook](source/deep_demand_forecast.ipynb) that gets the input data and launches the later stages below
+3. **Training Classifier and Detector models** and evaluating its results using Amazon SageMaker. If desired, one can deploy the trained models and create SageMaker endpoints
+4. **SageMaker endpoint** created from the previous step is an [HTTPS endpoint](https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-hosting.html) and is capable of producing predictions
+5. Monitoring the training and deployed model via [Amazon CloudWatch](https://aws.amazon.com/cloudwatch/)
+
+## 4. Cleaning up
+
+If you run the notebook end-to-end, the Cleaning up section in the notebook will delete all the checkpoints and models automatically for you. If you choose to only train some of the four models in the notebook, please make sure to run corresponding code in the Cleaning up section to delete all the artifacts.
+
+**Caution:** You need to manually delete any extra resources that you may have created in this notebook. For examples extra Amazon S3 bucketis.
+
+## 5. Customization
+
+For using your own data, make sure it is labeled and is a *relatively* balanced dataset. Also make sure the image annotations follow the required format.
+
+
+
+### Useful Links
+
+* [Amazon SageMaker Getting Started](https://aws.amazon.com/sagemaker/getting-started/)
+* [Amazon SageMaker Developer Guide](https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html)
+* [Amazon SageMaker Python SDK Documentation](https://sagemaker.readthedocs.io/en/stable/)
+* [AWS CloudFormation User Guide](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/Welcome.html)
+
+### References
+
+* K. Song and Y. Yan, “A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects,” Applied Surface Science, vol. 285, pp. 858-864, Nov. 2013.
+
+* Yu He, Kechen Song, Qinggang Meng, Yunhui Yan, “An End-to-end Steel Surface Defect Detection Approach via Fusing Multiple Hierarchical Features,” IEEE Transactions on Instrumentation and Measuremente, 2020,69(4),1493-1504.
+
+* Hongwen Dong, Kechen Song, Yu He, Jing Xu, Yunhui Yan, Qinggang Meng, “PGA-Net: Pyramid Feature Fusion and Global Context Attention Network for Automated Surface Defect Detection,” IEEE Transactions on Industrial Informatics, 2020.
diff --git a/introduction_to_applying_machine_learning/visual_object_detection/numerical.png b/introduction_to_applying_machine_learning/visual_object_detection/numerical.png
new file mode 100644
index 0000000000..427d7583d3
Binary files /dev/null and b/introduction_to_applying_machine_learning/visual_object_detection/numerical.png differ
diff --git a/introduction_to_applying_machine_learning/visual_object_detection/patches_116.jpeg b/introduction_to_applying_machine_learning/visual_object_detection/patches_116.jpeg
new file mode 100644
index 0000000000..fc2443f9df
Binary files /dev/null and b/introduction_to_applying_machine_learning/visual_object_detection/patches_116.jpeg differ
diff --git a/introduction_to_applying_machine_learning/visual_object_detection/src/im2rec.py b/introduction_to_applying_machine_learning/visual_object_detection/src/im2rec.py
new file mode 100644
index 0000000000..16693351fc
--- /dev/null
+++ b/introduction_to_applying_machine_learning/visual_object_detection/src/im2rec.py
@@ -0,0 +1,409 @@
+#!/usr/bin/env python3
+# -*- coding: utf-8 -*-
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+from __future__ import print_function
+
+import argparse
+import os
+import random
+import sys
+import time
+import traceback
+
+import cv2
+import mxnet as mx
+
+
+curr_path = os.path.abspath(os.path.dirname(__file__))
+sys.path.append(os.path.join(curr_path, "../python"))
+
+
+
+def list_image(root, recursive, exts):
+ """Traverses the root of directory that contains images and generates image list iterator.
+
+ Args:
+ root (str): the directory to explore
+ recursive (bool): whether subdirectories should be explored recursively
+ exts (collection[str]): the file extensions to look for
+
+ Returns:
+ image iterator that contains all the image under the specified path
+ """
+
+ i = 0
+ if recursive:
+ cat = {}
+ for path, dirs, files in os.walk(root, followlinks=True):
+ dirs.sort()
+ files.sort()
+ for fname in files:
+ fpath = os.path.join(path, fname)
+ suffix = os.path.splitext(fname)[1].lower()
+ if os.path.isfile(fpath) and (suffix in exts):
+ if path not in cat:
+ cat[path] = len(cat)
+ yield (i, os.path.relpath(fpath, root), cat[path])
+ i += 1
+ for k, v in sorted(cat.items(), key=lambda x: x[1]):
+ print(os.path.relpath(k, root), v)
+ else:
+ for fname in sorted(os.listdir(root)):
+ fpath = os.path.join(root, fname)
+ suffix = os.path.splitext(fname)[1].lower()
+ if os.path.isfile(fpath) and (suffix in exts):
+ yield (i, os.path.relpath(fpath, root), 0)
+ i += 1
+
+
+def write_list(path_out, image_list):
+ r"""Helper function to write image list into the file.
+
+ The format is as below, integer_image_index \t float_label_index \t path_to_image
+ Note that the blank between number and tab is only used for readability.
+
+ Args:
+ path_out (str): the path of the file to write to
+ image_list (list): objects in the images
+ """
+ with open(path_out, "w") as fout:
+ for i, item in enumerate(image_list):
+ line = "%d\t" % item[0]
+ for j in item[2:]:
+ line += "%f\t" % j
+ line += "%s\n" % item[1]
+ fout.write(line)
+
+
+def make_list(args):
+ """Generates .lst file.
+
+ Args:
+ args: object that contains all the arguments
+ """
+ image_list = list_image(args.root, args.recursive, args.exts)
+ image_list = list(image_list)
+ if args.shuffle is True:
+ random.seed(100)
+ random.shuffle(image_list)
+ N = len(image_list)
+ chunk_size = (N + args.chunks - 1) // args.chunks
+ for i in range(args.chunks):
+ chunk = image_list[i * chunk_size : (i + 1) * chunk_size]
+ if args.chunks > 1:
+ str_chunk = "_%d" % i
+ else:
+ str_chunk = ""
+ sep = int(chunk_size * args.train_ratio)
+ sep_test = int(chunk_size * args.test_ratio)
+ if args.train_ratio == 1.0:
+ write_list(args.prefix + str_chunk + ".lst", chunk)
+ else:
+ if args.test_ratio:
+ write_list(args.prefix + str_chunk + "_test.lst", chunk[:sep_test])
+ if args.train_ratio + args.test_ratio < 1.0:
+ write_list(args.prefix + str_chunk + "_val.lst", chunk[sep_test + sep :])
+ write_list(args.prefix + str_chunk + "_train.lst", chunk[sep_test : sep_test + sep])
+
+
+def read_list(path_in):
+ """Reads the .lst file and generates corresponding iterator.
+
+ Args:
+ path_in (str)
+
+ Returns:
+ item iterator that contains information in .lst file
+ """
+ with open(path_in) as fin:
+ while True:
+ line = fin.readline()
+ if not line:
+ break
+ line = [i.strip() for i in line.strip().split("\t")]
+ line_len = len(line)
+ # check the data format of .lst file
+ if line_len < 3:
+ print("lst should have at least has three parts, but only has %s parts for %s" % (line_len, line))
+ continue
+ try:
+ item = [int(line[0])] + [line[-1]] + [float(i) for i in line[1:-1]]
+ except Exception as e:
+ print("Parsing lst met error for %s, detail: %s" % (line, e))
+ continue
+ yield item
+
+
+def image_encode(args, i, item, q_out):
+ """Reads, preprocesses, packs the image and put it back in output queue.
+
+ Args"
+ args (object): image
+ i (int): image index
+ item (list): labels
+ q_out (queue): collection to store the image to
+ """
+ fullpath = os.path.join(args.root, item[1])
+
+ if len(item) > 3 and args.pack_label:
+ header = mx.recordio.IRHeader(0, item[2:], item[0], 0)
+ else:
+ header = mx.recordio.IRHeader(0, item[2], item[0], 0)
+
+ if args.pass_through:
+ try:
+ with open(fullpath, "rb") as fin:
+ img = fin.read()
+ s = mx.recordio.pack(header, img)
+ q_out.put((i, s, item))
+ except Exception as e:
+ traceback.print_exc()
+ print("pack_img error:", item[1], e)
+ q_out.put((i, None, item))
+ return
+
+ try:
+ img = cv2.imread(fullpath, args.color)
+ except Exception:
+ traceback.print_exc()
+ print("imread error trying to load file: %s " % fullpath)
+ q_out.put((i, None, item))
+ return
+ if img is None:
+ print("imread read blank (None) image for file: %s" % fullpath)
+ q_out.put((i, None, item))
+ return
+ if args.center_crop:
+ if img.shape[0] > img.shape[1]:
+ margin = (img.shape[0] - img.shape[1]) // 2
+ img = img[margin : margin + img.shape[1], :]
+ else:
+ margin = (img.shape[1] - img.shape[0]) // 2
+ img = img[:, margin : margin + img.shape[0]]
+ if args.resize:
+ if img.shape[0] > img.shape[1]:
+ newsize = (args.resize, img.shape[0] * args.resize // img.shape[1])
+ else:
+ newsize = (img.shape[1] * args.resize // img.shape[0], args.resize)
+ img = cv2.resize(img, newsize)
+
+ try:
+ s = mx.recordio.pack_img(header, img, quality=args.quality, img_fmt=args.encoding)
+ q_out.put((i, s, item))
+ except Exception as e:
+ traceback.print_exc()
+ print("pack_img error on file: %s" % fullpath, e)
+ q_out.put((i, None, item))
+ return
+
+
+def read_worker(args, q_in, q_out):
+ """Function that will be spawned to fetch the image from the input queue and put it back to output queue.
+
+ Args:
+ args (object): image
+ q_in (queue): input queue
+ q_out (queue): output queue
+ """
+ while True:
+ deq = q_in.get()
+ if deq is None:
+ break
+ i, item = deq
+ image_encode(args, i, item, q_out)
+
+
+def write_worker(q_out, fname, working_dir):
+ """Function that will be spawned to fetch processed image from the output queue and write to the .rec file.
+
+ Args:
+ q_out (queue): output queue
+ fname (str): name of the files
+ working_dir (str): name of directory to write to
+ """
+ pre_time = time.time()
+ count = 0
+ fname = os.path.basename(fname)
+ fname_rec = os.path.splitext(fname)[0] + ".rec"
+ fname_idx = os.path.splitext(fname)[0] + ".idx"
+ record = mx.recordio.MXIndexedRecordIO(
+ os.path.join(working_dir, fname_idx), os.path.join(working_dir, fname_rec), "w"
+ )
+ buf = {}
+ more = True
+ while more:
+ deq = q_out.get()
+ if deq is not None:
+ i, s, item = deq
+ buf[i] = (s, item)
+ else:
+ more = False
+ while count in buf:
+ s, item = buf[count]
+ del buf[count]
+ if s is not None:
+ record.write_idx(item[0], s)
+
+ if count % 1000 == 0:
+ cur_time = time.time()
+ print("time:", cur_time - pre_time, " count:", count)
+ pre_time = cur_time
+ count += 1
+
+
+def parse_args():
+ """Defines all arguments.
+
+ Returns:
+ args object that contains all the params
+ """
+ parser = argparse.ArgumentParser(
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter,
+ description="Create an image list or \
+ make a record database by reading from an image list",
+ )
+ parser.add_argument("prefix", help="prefix of input/output lst and rec files.")
+ parser.add_argument("root", help="path to folder containing images.")
+
+ cgroup = parser.add_argument_group("Options for creating image lists")
+ cgroup.add_argument(
+ "--list",
+ action="store_true",
+ help="If this is set im2rec will create image list(s) by traversing root folder\
+ and output to
+
+## 3. Architecture Overview
+
+The following illustration is the architecture for the end-to-end training and deployment process
+
+
+
+1. The input data located in an [Amazon S3](https://aws.amazon.com/s3/) bucket
+2. The provided [SageMaker notebook](source/deep_demand_forecast.ipynb) that gets the input data and launches the later stages below
+3. **Training Classifier and Detector models** and evaluating its results using Amazon SageMaker. If desired, one can deploy the trained models and create SageMaker endpoints
+4. **SageMaker endpoint** created from the previous step is an [HTTPS endpoint](https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-hosting.html) and is capable of producing predictions
+5. Monitoring the training and deployed model via [Amazon CloudWatch](https://aws.amazon.com/cloudwatch/)
+
+## 4. Cleaning up
+
+If you run the notebook end-to-end, the Cleaning up section in the notebook will delete all the checkpoints and models automatically for you. If you choose to only train some of the four models in the notebook, please make sure to run corresponding code in the Cleaning up section to delete all the artifacts.
+
+**Caution:** You need to manually delete any extra resources that you may have created in this notebook. For examples extra Amazon S3 bucketis.
+
+## 5. Customization
+
+For using your own data, make sure it is labeled and is a *relatively* balanced dataset. Also make sure the image annotations follow the required format.
+
+
+
+### Useful Links
+
+* [Amazon SageMaker Getting Started](https://aws.amazon.com/sagemaker/getting-started/)
+* [Amazon SageMaker Developer Guide](https://docs.aws.amazon.com/sagemaker/latest/dg/whatis.html)
+* [Amazon SageMaker Python SDK Documentation](https://sagemaker.readthedocs.io/en/stable/)
+* [AWS CloudFormation User Guide](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/Welcome.html)
+
+### References
+
+* K. Song and Y. Yan, “A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects,” Applied Surface Science, vol. 285, pp. 858-864, Nov. 2013.
+
+* Yu He, Kechen Song, Qinggang Meng, Yunhui Yan, “An End-to-end Steel Surface Defect Detection Approach via Fusing Multiple Hierarchical Features,” IEEE Transactions on Instrumentation and Measuremente, 2020,69(4),1493-1504.
+
+* Hongwen Dong, Kechen Song, Yu He, Jing Xu, Yunhui Yan, Qinggang Meng, “PGA-Net: Pyramid Feature Fusion and Global Context Attention Network for Automated Surface Defect Detection,” IEEE Transactions on Industrial Informatics, 2020.
diff --git a/introduction_to_applying_machine_learning/visual_object_detection/numerical.png b/introduction_to_applying_machine_learning/visual_object_detection/numerical.png
new file mode 100644
index 0000000000..427d7583d3
Binary files /dev/null and b/introduction_to_applying_machine_learning/visual_object_detection/numerical.png differ
diff --git a/introduction_to_applying_machine_learning/visual_object_detection/patches_116.jpeg b/introduction_to_applying_machine_learning/visual_object_detection/patches_116.jpeg
new file mode 100644
index 0000000000..fc2443f9df
Binary files /dev/null and b/introduction_to_applying_machine_learning/visual_object_detection/patches_116.jpeg differ
diff --git a/introduction_to_applying_machine_learning/visual_object_detection/src/im2rec.py b/introduction_to_applying_machine_learning/visual_object_detection/src/im2rec.py
new file mode 100644
index 0000000000..16693351fc
--- /dev/null
+++ b/introduction_to_applying_machine_learning/visual_object_detection/src/im2rec.py
@@ -0,0 +1,409 @@
+#!/usr/bin/env python3
+# -*- coding: utf-8 -*-
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+from __future__ import print_function
+
+import argparse
+import os
+import random
+import sys
+import time
+import traceback
+
+import cv2
+import mxnet as mx
+
+
+curr_path = os.path.abspath(os.path.dirname(__file__))
+sys.path.append(os.path.join(curr_path, "../python"))
+
+
+
+def list_image(root, recursive, exts):
+ """Traverses the root of directory that contains images and generates image list iterator.
+
+ Args:
+ root (str): the directory to explore
+ recursive (bool): whether subdirectories should be explored recursively
+ exts (collection[str]): the file extensions to look for
+
+ Returns:
+ image iterator that contains all the image under the specified path
+ """
+
+ i = 0
+ if recursive:
+ cat = {}
+ for path, dirs, files in os.walk(root, followlinks=True):
+ dirs.sort()
+ files.sort()
+ for fname in files:
+ fpath = os.path.join(path, fname)
+ suffix = os.path.splitext(fname)[1].lower()
+ if os.path.isfile(fpath) and (suffix in exts):
+ if path not in cat:
+ cat[path] = len(cat)
+ yield (i, os.path.relpath(fpath, root), cat[path])
+ i += 1
+ for k, v in sorted(cat.items(), key=lambda x: x[1]):
+ print(os.path.relpath(k, root), v)
+ else:
+ for fname in sorted(os.listdir(root)):
+ fpath = os.path.join(root, fname)
+ suffix = os.path.splitext(fname)[1].lower()
+ if os.path.isfile(fpath) and (suffix in exts):
+ yield (i, os.path.relpath(fpath, root), 0)
+ i += 1
+
+
+def write_list(path_out, image_list):
+ r"""Helper function to write image list into the file.
+
+ The format is as below, integer_image_index \t float_label_index \t path_to_image
+ Note that the blank between number and tab is only used for readability.
+
+ Args:
+ path_out (str): the path of the file to write to
+ image_list (list): objects in the images
+ """
+ with open(path_out, "w") as fout:
+ for i, item in enumerate(image_list):
+ line = "%d\t" % item[0]
+ for j in item[2:]:
+ line += "%f\t" % j
+ line += "%s\n" % item[1]
+ fout.write(line)
+
+
+def make_list(args):
+ """Generates .lst file.
+
+ Args:
+ args: object that contains all the arguments
+ """
+ image_list = list_image(args.root, args.recursive, args.exts)
+ image_list = list(image_list)
+ if args.shuffle is True:
+ random.seed(100)
+ random.shuffle(image_list)
+ N = len(image_list)
+ chunk_size = (N + args.chunks - 1) // args.chunks
+ for i in range(args.chunks):
+ chunk = image_list[i * chunk_size : (i + 1) * chunk_size]
+ if args.chunks > 1:
+ str_chunk = "_%d" % i
+ else:
+ str_chunk = ""
+ sep = int(chunk_size * args.train_ratio)
+ sep_test = int(chunk_size * args.test_ratio)
+ if args.train_ratio == 1.0:
+ write_list(args.prefix + str_chunk + ".lst", chunk)
+ else:
+ if args.test_ratio:
+ write_list(args.prefix + str_chunk + "_test.lst", chunk[:sep_test])
+ if args.train_ratio + args.test_ratio < 1.0:
+ write_list(args.prefix + str_chunk + "_val.lst", chunk[sep_test + sep :])
+ write_list(args.prefix + str_chunk + "_train.lst", chunk[sep_test : sep_test + sep])
+
+
+def read_list(path_in):
+ """Reads the .lst file and generates corresponding iterator.
+
+ Args:
+ path_in (str)
+
+ Returns:
+ item iterator that contains information in .lst file
+ """
+ with open(path_in) as fin:
+ while True:
+ line = fin.readline()
+ if not line:
+ break
+ line = [i.strip() for i in line.strip().split("\t")]
+ line_len = len(line)
+ # check the data format of .lst file
+ if line_len < 3:
+ print("lst should have at least has three parts, but only has %s parts for %s" % (line_len, line))
+ continue
+ try:
+ item = [int(line[0])] + [line[-1]] + [float(i) for i in line[1:-1]]
+ except Exception as e:
+ print("Parsing lst met error for %s, detail: %s" % (line, e))
+ continue
+ yield item
+
+
+def image_encode(args, i, item, q_out):
+ """Reads, preprocesses, packs the image and put it back in output queue.
+
+ Args"
+ args (object): image
+ i (int): image index
+ item (list): labels
+ q_out (queue): collection to store the image to
+ """
+ fullpath = os.path.join(args.root, item[1])
+
+ if len(item) > 3 and args.pack_label:
+ header = mx.recordio.IRHeader(0, item[2:], item[0], 0)
+ else:
+ header = mx.recordio.IRHeader(0, item[2], item[0], 0)
+
+ if args.pass_through:
+ try:
+ with open(fullpath, "rb") as fin:
+ img = fin.read()
+ s = mx.recordio.pack(header, img)
+ q_out.put((i, s, item))
+ except Exception as e:
+ traceback.print_exc()
+ print("pack_img error:", item[1], e)
+ q_out.put((i, None, item))
+ return
+
+ try:
+ img = cv2.imread(fullpath, args.color)
+ except Exception:
+ traceback.print_exc()
+ print("imread error trying to load file: %s " % fullpath)
+ q_out.put((i, None, item))
+ return
+ if img is None:
+ print("imread read blank (None) image for file: %s" % fullpath)
+ q_out.put((i, None, item))
+ return
+ if args.center_crop:
+ if img.shape[0] > img.shape[1]:
+ margin = (img.shape[0] - img.shape[1]) // 2
+ img = img[margin : margin + img.shape[1], :]
+ else:
+ margin = (img.shape[1] - img.shape[0]) // 2
+ img = img[:, margin : margin + img.shape[0]]
+ if args.resize:
+ if img.shape[0] > img.shape[1]:
+ newsize = (args.resize, img.shape[0] * args.resize // img.shape[1])
+ else:
+ newsize = (img.shape[1] * args.resize // img.shape[0], args.resize)
+ img = cv2.resize(img, newsize)
+
+ try:
+ s = mx.recordio.pack_img(header, img, quality=args.quality, img_fmt=args.encoding)
+ q_out.put((i, s, item))
+ except Exception as e:
+ traceback.print_exc()
+ print("pack_img error on file: %s" % fullpath, e)
+ q_out.put((i, None, item))
+ return
+
+
+def read_worker(args, q_in, q_out):
+ """Function that will be spawned to fetch the image from the input queue and put it back to output queue.
+
+ Args:
+ args (object): image
+ q_in (queue): input queue
+ q_out (queue): output queue
+ """
+ while True:
+ deq = q_in.get()
+ if deq is None:
+ break
+ i, item = deq
+ image_encode(args, i, item, q_out)
+
+
+def write_worker(q_out, fname, working_dir):
+ """Function that will be spawned to fetch processed image from the output queue and write to the .rec file.
+
+ Args:
+ q_out (queue): output queue
+ fname (str): name of the files
+ working_dir (str): name of directory to write to
+ """
+ pre_time = time.time()
+ count = 0
+ fname = os.path.basename(fname)
+ fname_rec = os.path.splitext(fname)[0] + ".rec"
+ fname_idx = os.path.splitext(fname)[0] + ".idx"
+ record = mx.recordio.MXIndexedRecordIO(
+ os.path.join(working_dir, fname_idx), os.path.join(working_dir, fname_rec), "w"
+ )
+ buf = {}
+ more = True
+ while more:
+ deq = q_out.get()
+ if deq is not None:
+ i, s, item = deq
+ buf[i] = (s, item)
+ else:
+ more = False
+ while count in buf:
+ s, item = buf[count]
+ del buf[count]
+ if s is not None:
+ record.write_idx(item[0], s)
+
+ if count % 1000 == 0:
+ cur_time = time.time()
+ print("time:", cur_time - pre_time, " count:", count)
+ pre_time = cur_time
+ count += 1
+
+
+def parse_args():
+ """Defines all arguments.
+
+ Returns:
+ args object that contains all the params
+ """
+ parser = argparse.ArgumentParser(
+ formatter_class=argparse.ArgumentDefaultsHelpFormatter,
+ description="Create an image list or \
+ make a record database by reading from an image list",
+ )
+ parser.add_argument("prefix", help="prefix of input/output lst and rec files.")
+ parser.add_argument("root", help="path to folder containing images.")
+
+ cgroup = parser.add_argument_group("Options for creating image lists")
+ cgroup.add_argument(
+ "--list",
+ action="store_true",
+ help="If this is set im2rec will create image list(s) by traversing root folder\
+ and output to  \n",
+ "\n",
+ "If you predict all test images using all endpoints, you end up with this table. The pycocotools package reports more metric values. We wil focus on row 1 - the mAP averaged over all IoU thresholds, all recall thresholds, all region sizes (small, medium, large), and all numbers of predicted bbox (1, 10, and 100), and all object categories. It's the [standard practice](https://cocodataset.org/#detection-eval) to use this metric for evaluating object detection algorithms."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "papermill": {
+ "duration": 2.403376,
+ "end_time": "2022-08-05T14:36:28.020761",
+ "exception": false,
+ "start_time": "2022-08-05T14:36:25.617385",
+ "status": "completed"
+ },
+ "pycharm": {
+ "name": "#%% md\n"
+ },
+ "tags": []
+ },
+ "source": [
+ "### 7. Clean Up the Endpoints\n",
+ "\n",
+ "When you are done with the endpoint, you should clean it up.\n",
+ "\n",
+ "All of the training jobs, models and endpoints we created can be viewed through the SageMaker console of your AWS account."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 27,
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-08-05T14:36:32.833309Z",
+ "iopub.status.busy": "2022-08-05T14:36:32.832838Z",
+ "iopub.status.idle": "2022-08-05T14:36:39.752304Z",
+ "shell.execute_reply": "2022-08-05T14:36:39.751877Z"
+ },
+ "papermill": {
+ "duration": 9.328678,
+ "end_time": "2022-08-05T14:36:39.752413",
+ "exception": false,
+ "start_time": "2022-08-05T14:36:30.423735",
+ "status": "completed"
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Delete the SageMaker endpoint\n",
+ "od_type1_predictor.delete_model()\n",
+ "od_type1_predictor.delete_endpoint()\n",
+ "\n",
+ "od_type1_hpo_predictor.delete_model()\n",
+ "od_type1_hpo_predictor.delete_endpoint()\n",
+ "\n",
+ "od_type2_predictor.delete_model()\n",
+ "od_type2_predictor.delete_endpoint()\n",
+ "\n",
+ "od_type2_hpo_predictor.delete_model()\n",
+ "od_type2_hpo_predictor.delete_endpoint()\n",
+ "\n",
+ "# You should go to the Sagemaker console and manually delete the DDN model endpoint"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "papermill": {
+ "duration": 2.415178,
+ "end_time": "2022-08-05T14:36:44.577598",
+ "exception": false,
+ "start_time": "2022-08-05T14:36:42.162420",
+ "status": "completed"
+ },
+ "pycharm": {
+ "name": "#%% md\n"
+ },
+ "tags": []
+ },
+ "source": [
+ "## 8. Conclusion\n",
+ "\n",
+ "Both visual and numerical comparison confirm that the Type 2 (latest) OD model or Type 2 (latest) OD + HPO performs the best. \n",
+ "\n",
+ "1. Training models from scratch can be very time-consuming and less effective. In this example, the target dataset is very small, consisting of only 1,800 images in 6 categories, and the training data is only 64% of this small dataset.\n",
+ "2. The built-in Sagemaker OD models were pre-trained on large-scale dataset, e.g., the ImageNet dataset includes 14,197,122 images for 21,841 categories, and the PASCAL VOC dataset includes 11,530 images for 20 categories. The pre-trained models have learned rich and diverse low level features, and can efficiently transfer knowledge to finetuned models and focus on learning high-level semantic features for the target dataset.\n",
+ "3. HPO is extremely effective, especially for models with large hyperparameter search spaces. Since we finetuned on three hyperparameters (learning rate, momentum, and weight decay) for the Type 1 (legacy) OD models and only one hyperparameter (adam learning rate) for the Type 2 (latest) OD model, there is relatively larger room for improvement for the Type 1 (legacy) OD model and we do observe larger performance enhancement. Of course, we need to trade off model performance with budget (compute resource and training time) when running HPO.\n",
+ "4. In terms of training time, for the steel surface dataset, training the Type 1 (legacy) OD model took 34 min, Type 2 (latest) OD model took 1 hour, and the model trained from scratch took 8+ hours. It indicates finetuning a pre-trained model is much more efficient.\n",
+ "5. In summary, finetuning a pretrained model is both more efficient and more performant, we suggest taking advantage of the pre-trained Sagemaker built-in models and finetune on your target datasets.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "papermill": {
+ "duration": 2.382722,
+ "end_time": "2022-08-05T14:36:49.342790",
+ "exception": false,
+ "start_time": "2022-08-05T14:36:46.960068",
+ "status": "completed"
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "instance_type": "ml.g4dn.xlarge",
+ "kernelspec": {
+ "display_name": "Python 3 (PyTorch 1.8 Python 3.6 CPU Optimized)",
+ "language": "python",
+ "name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:us-west-2:236514542706:image/1.8.1-cpu-py36"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.6.13"
+ },
+ "papermill": {
+ "default_parameters": {},
+ "duration": 23169.556233,
+ "end_time": "2022-08-05T14:36:52.361701",
+ "environment_variables": {},
+ "exception": null,
+ "input_path": "4_finetune-processed.ipynb",
+ "output_path": "4_finetune-processed-output.ipynb",
+ "parameters": {},
+ "start_time": "2022-08-05T08:10:42.805468",
+ "version": "2.3.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/licenses/2-CLAUSE-BSD b/licenses/2-CLAUSE-BSD
new file mode 100644
index 0000000000..b79ea4a15c
--- /dev/null
+++ b/licenses/2-CLAUSE-BSD
@@ -0,0 +1,28 @@
+2-Clause BSD License
+=====================
+
+Copyright (c) 2007-2020 by the Sphinx team (see AUTHORS file).
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without
+modification, are permitted provided that the following conditions are
+met:
+
+* Redistributions of source code must retain the above copyright
+ notice, this list of conditions and the following disclaimer.
+
+* Redistributions in binary form must reproduce the above copyright
+ notice, this list of conditions and the following disclaimer in the
+ documentation and/or other materials provided with the distribution.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
+"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
+LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
+A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
+HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
+SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
+LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
+DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
+THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
+(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
\ No newline at end of file
diff --git a/ml-lifecycle/index.rst b/ml-lifecycle/index.rst
new file mode 100644
index 0000000000..8f7e17178a
--- /dev/null
+++ b/ml-lifecycle/index.rst
@@ -0,0 +1,7 @@
+Feature Store
+---------------------------
+
+.. toctree::
+ :maxdepth: 1
+
+ feature_store/FS_demo
diff --git a/model-governance/index.rst b/model-governance/index.rst
new file mode 100644
index 0000000000..838392f015
--- /dev/null
+++ b/model-governance/index.rst
@@ -0,0 +1,7 @@
+Model Governance
+---------------------
+
+.. toctree::
+ :maxdepth: 0
+
+ model_governance_graph
diff --git a/multi-model-endpoints/mme-on-gpu/cv/images/mme-gpu.jpg b/multi-model-endpoints/mme-on-gpu/cv/images/mme-gpu.jpg
new file mode 100644
index 0000000000..3567646283
Binary files /dev/null and b/multi-model-endpoints/mme-on-gpu/cv/images/mme-gpu.jpg differ
diff --git a/multi-model-endpoints/mme-on-gpu/cv/images/pyt-model-repo.png b/multi-model-endpoints/mme-on-gpu/cv/images/pyt-model-repo.png
new file mode 100644
index 0000000000..a54d1a4a6d
Binary files /dev/null and b/multi-model-endpoints/mme-on-gpu/cv/images/pyt-model-repo.png differ
diff --git a/multi-model-endpoints/mme-on-gpu/cv/images/trt-model-repo.png b/multi-model-endpoints/mme-on-gpu/cv/images/trt-model-repo.png
new file mode 100644
index 0000000000..26d0a79332
Binary files /dev/null and b/multi-model-endpoints/mme-on-gpu/cv/images/trt-model-repo.png differ
diff --git a/multi-model-endpoints/mme-on-gpu/cv/resnet50_mme_with_gpu.ipynb b/multi-model-endpoints/mme-on-gpu/cv/resnet50_mme_with_gpu.ipynb
new file mode 100644
index 0000000000..25530ac9a5
--- /dev/null
+++ b/multi-model-endpoints/mme-on-gpu/cv/resnet50_mme_with_gpu.ipynb
@@ -0,0 +1,903 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "9df84fc4",
+ "metadata": {},
+ "source": [
+ "# Run mulitple deep learning models on GPUs with Amazon SageMaker Multi-model endpoints (MME)\n",
+ "\n",
+ "[Amazon SageMaker](https://aws.amazon.com/sagemaker/) multi-model endpoints(MME) provide a scalable and cost-effective way to deploy large number of deep learning models. Previously, customers had limited options to deploy 100s of deep learning models that need accelerated compute with GPUs. Now customers can deploy 1000s of deep learning models behind one SageMaker endpoint. Now, MME will run multiple models on a GPU core, share GPU instances behind an endpoint across multiple models and dynamically load/unload models based on the incoming traffic. With this, customers can significantly save cost and achieve best price performance.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "If you predict all test images using all endpoints, you end up with this table. The pycocotools package reports more metric values. We wil focus on row 1 - the mAP averaged over all IoU thresholds, all recall thresholds, all region sizes (small, medium, large), and all numbers of predicted bbox (1, 10, and 100), and all object categories. It's the [standard practice](https://cocodataset.org/#detection-eval) to use this metric for evaluating object detection algorithms."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "papermill": {
+ "duration": 2.403376,
+ "end_time": "2022-08-05T14:36:28.020761",
+ "exception": false,
+ "start_time": "2022-08-05T14:36:25.617385",
+ "status": "completed"
+ },
+ "pycharm": {
+ "name": "#%% md\n"
+ },
+ "tags": []
+ },
+ "source": [
+ "### 7. Clean Up the Endpoints\n",
+ "\n",
+ "When you are done with the endpoint, you should clean it up.\n",
+ "\n",
+ "All of the training jobs, models and endpoints we created can be viewed through the SageMaker console of your AWS account."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 27,
+ "metadata": {
+ "execution": {
+ "iopub.execute_input": "2022-08-05T14:36:32.833309Z",
+ "iopub.status.busy": "2022-08-05T14:36:32.832838Z",
+ "iopub.status.idle": "2022-08-05T14:36:39.752304Z",
+ "shell.execute_reply": "2022-08-05T14:36:39.751877Z"
+ },
+ "papermill": {
+ "duration": 9.328678,
+ "end_time": "2022-08-05T14:36:39.752413",
+ "exception": false,
+ "start_time": "2022-08-05T14:36:30.423735",
+ "status": "completed"
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "# Delete the SageMaker endpoint\n",
+ "od_type1_predictor.delete_model()\n",
+ "od_type1_predictor.delete_endpoint()\n",
+ "\n",
+ "od_type1_hpo_predictor.delete_model()\n",
+ "od_type1_hpo_predictor.delete_endpoint()\n",
+ "\n",
+ "od_type2_predictor.delete_model()\n",
+ "od_type2_predictor.delete_endpoint()\n",
+ "\n",
+ "od_type2_hpo_predictor.delete_model()\n",
+ "od_type2_hpo_predictor.delete_endpoint()\n",
+ "\n",
+ "# You should go to the Sagemaker console and manually delete the DDN model endpoint"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "papermill": {
+ "duration": 2.415178,
+ "end_time": "2022-08-05T14:36:44.577598",
+ "exception": false,
+ "start_time": "2022-08-05T14:36:42.162420",
+ "status": "completed"
+ },
+ "pycharm": {
+ "name": "#%% md\n"
+ },
+ "tags": []
+ },
+ "source": [
+ "## 8. Conclusion\n",
+ "\n",
+ "Both visual and numerical comparison confirm that the Type 2 (latest) OD model or Type 2 (latest) OD + HPO performs the best. \n",
+ "\n",
+ "1. Training models from scratch can be very time-consuming and less effective. In this example, the target dataset is very small, consisting of only 1,800 images in 6 categories, and the training data is only 64% of this small dataset.\n",
+ "2. The built-in Sagemaker OD models were pre-trained on large-scale dataset, e.g., the ImageNet dataset includes 14,197,122 images for 21,841 categories, and the PASCAL VOC dataset includes 11,530 images for 20 categories. The pre-trained models have learned rich and diverse low level features, and can efficiently transfer knowledge to finetuned models and focus on learning high-level semantic features for the target dataset.\n",
+ "3. HPO is extremely effective, especially for models with large hyperparameter search spaces. Since we finetuned on three hyperparameters (learning rate, momentum, and weight decay) for the Type 1 (legacy) OD models and only one hyperparameter (adam learning rate) for the Type 2 (latest) OD model, there is relatively larger room for improvement for the Type 1 (legacy) OD model and we do observe larger performance enhancement. Of course, we need to trade off model performance with budget (compute resource and training time) when running HPO.\n",
+ "4. In terms of training time, for the steel surface dataset, training the Type 1 (legacy) OD model took 34 min, Type 2 (latest) OD model took 1 hour, and the model trained from scratch took 8+ hours. It indicates finetuning a pre-trained model is much more efficient.\n",
+ "5. In summary, finetuning a pretrained model is both more efficient and more performant, we suggest taking advantage of the pre-trained Sagemaker built-in models and finetune on your target datasets.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "papermill": {
+ "duration": 2.382722,
+ "end_time": "2022-08-05T14:36:49.342790",
+ "exception": false,
+ "start_time": "2022-08-05T14:36:46.960068",
+ "status": "completed"
+ },
+ "pycharm": {
+ "name": "#%%\n"
+ },
+ "tags": []
+ },
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "instance_type": "ml.g4dn.xlarge",
+ "kernelspec": {
+ "display_name": "Python 3 (PyTorch 1.8 Python 3.6 CPU Optimized)",
+ "language": "python",
+ "name": "python3__SAGEMAKER_INTERNAL__arn:aws:sagemaker:us-west-2:236514542706:image/1.8.1-cpu-py36"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.6.13"
+ },
+ "papermill": {
+ "default_parameters": {},
+ "duration": 23169.556233,
+ "end_time": "2022-08-05T14:36:52.361701",
+ "environment_variables": {},
+ "exception": null,
+ "input_path": "4_finetune-processed.ipynb",
+ "output_path": "4_finetune-processed-output.ipynb",
+ "parameters": {},
+ "start_time": "2022-08-05T08:10:42.805468",
+ "version": "2.3.4"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/licenses/2-CLAUSE-BSD b/licenses/2-CLAUSE-BSD
new file mode 100644
index 0000000000..b79ea4a15c
--- /dev/null
+++ b/licenses/2-CLAUSE-BSD
@@ -0,0 +1,28 @@
+2-Clause BSD License
+=====================
+
+Copyright (c) 2007-2020 by the Sphinx team (see AUTHORS file).
+All rights reserved.
+
+Redistribution and use in source and binary forms, with or without
+modification, are permitted provided that the following conditions are
+met:
+
+* Redistributions of source code must retain the above copyright
+ notice, this list of conditions and the following disclaimer.
+
+* Redistributions in binary form must reproduce the above copyright
+ notice, this list of conditions and the following disclaimer in the
+ documentation and/or other materials provided with the distribution.
+
+THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
+"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
+LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
+A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
+HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
+SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
+LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
+DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
+THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
+(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
+OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
\ No newline at end of file
diff --git a/ml-lifecycle/index.rst b/ml-lifecycle/index.rst
new file mode 100644
index 0000000000..8f7e17178a
--- /dev/null
+++ b/ml-lifecycle/index.rst
@@ -0,0 +1,7 @@
+Feature Store
+---------------------------
+
+.. toctree::
+ :maxdepth: 1
+
+ feature_store/FS_demo
diff --git a/model-governance/index.rst b/model-governance/index.rst
new file mode 100644
index 0000000000..838392f015
--- /dev/null
+++ b/model-governance/index.rst
@@ -0,0 +1,7 @@
+Model Governance
+---------------------
+
+.. toctree::
+ :maxdepth: 0
+
+ model_governance_graph
diff --git a/multi-model-endpoints/mme-on-gpu/cv/images/mme-gpu.jpg b/multi-model-endpoints/mme-on-gpu/cv/images/mme-gpu.jpg
new file mode 100644
index 0000000000..3567646283
Binary files /dev/null and b/multi-model-endpoints/mme-on-gpu/cv/images/mme-gpu.jpg differ
diff --git a/multi-model-endpoints/mme-on-gpu/cv/images/pyt-model-repo.png b/multi-model-endpoints/mme-on-gpu/cv/images/pyt-model-repo.png
new file mode 100644
index 0000000000..a54d1a4a6d
Binary files /dev/null and b/multi-model-endpoints/mme-on-gpu/cv/images/pyt-model-repo.png differ
diff --git a/multi-model-endpoints/mme-on-gpu/cv/images/trt-model-repo.png b/multi-model-endpoints/mme-on-gpu/cv/images/trt-model-repo.png
new file mode 100644
index 0000000000..26d0a79332
Binary files /dev/null and b/multi-model-endpoints/mme-on-gpu/cv/images/trt-model-repo.png differ
diff --git a/multi-model-endpoints/mme-on-gpu/cv/resnet50_mme_with_gpu.ipynb b/multi-model-endpoints/mme-on-gpu/cv/resnet50_mme_with_gpu.ipynb
new file mode 100644
index 0000000000..25530ac9a5
--- /dev/null
+++ b/multi-model-endpoints/mme-on-gpu/cv/resnet50_mme_with_gpu.ipynb
@@ -0,0 +1,903 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "9df84fc4",
+ "metadata": {},
+ "source": [
+ "# Run mulitple deep learning models on GPUs with Amazon SageMaker Multi-model endpoints (MME)\n",
+ "\n",
+ "[Amazon SageMaker](https://aws.amazon.com/sagemaker/) multi-model endpoints(MME) provide a scalable and cost-effective way to deploy large number of deep learning models. Previously, customers had limited options to deploy 100s of deep learning models that need accelerated compute with GPUs. Now customers can deploy 1000s of deep learning models behind one SageMaker endpoint. Now, MME will run multiple models on a GPU core, share GPU instances behind an endpoint across multiple models and dynamically load/unload models based on the incoming traffic. With this, customers can significantly save cost and achieve best price performance.\n",
+ "\n",
+ " \n",
+ "\n",
+ "In this notebook we will walk through using [RAPIDS](https://rapids.ai/about.html) for GPU-accelerated data preprocessing and training of XGBoost model for a Fraud Detection use-case. This is the first notebook in a two notebook series. In the [second notebook](2_triton_xgb_fil_ensemble.ipynb) we will show how to deploy the trained XGBoost model in Triton on SageMaker. The RAPIDS suite of open source software libraries and APIs gives you the ability to execute end-to-end data science and analytics pipelines entirely on GPUs. \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a15d9b9e",
+ "metadata": {},
+ "source": [
+ "**Note:** Since the primary goal of this example is to get a trained XGBoost model to illustrate deployment of Tree-based ML models on Triton in SageMaker we don't perform any in-depth feature engineering or hyperparameter optimization. RAPIDS on SageMaker however is excellent for running cost-effective HPO in minimal amount of time as shown in the blog post [RAPIDS and Amazon SageMaker: Scale up and scale out to tackle ML challenges](https://aws.amazon.com/blogs/machine-learning/rapids-and-amazon-sagemaker-scale-up-and-scale-out-to-tackle-ml-challenges/). \n",
+ "\n",
+ "## To Run This Notebook Please Select RAPIDS 2106 Kernel from the Kernel Dropdown menu"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bdf4884f",
+ "metadata": {},
+ "source": [
+ "This notebook was tested with the `rapids-2106` kernel on an Amazon SageMaker notebook instance of type `g4dn`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0f87fb40",
+ "metadata": {},
+ "source": [
+ "## Get Data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b379efd7",
+ "metadata": {},
+ "source": [
+ "For this example, we use the Tabformer [synthetic credit card transactions dataset](https://arxiv.org/abs/1910.03033) from IBM available on [Kaggle](https://www.kaggle.com/datasets/ealtman2019/credit-card-transactions). The origin of this dataset along with its licensing terms can be found at: [Kaggle link](https://www.kaggle.com/datasets/ealtman2019/credit-card-transactions).\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d82b7ea5",
+ "metadata": {},
+ "source": [
+ "### Download Dataset"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4588fb76",
+ "metadata": {},
+ "source": [
+ "First we download the dataset from our Amazon S3 bucket."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4f4f19b0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!python -m pip install --upgrade pip --quiet\n",
+ "!pip install -U awscli --quiet"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "58a250bc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!aws s3 cp s3://sagemaker-sample-files/datasets/tabular/synthetic_credit_card_transactions/credit_card_transactions-ibm_v2.csv ./"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f00abe8b",
+ "metadata": {},
+ "source": [
+ "## Check on our GPU"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "96e7edd8",
+ "metadata": {},
+ "source": [
+ "Next, let's check the GPU resources we have by using the terminal command `nvidia-smi`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7c3aeafc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!nvidia-smi\n",
+ "!nvidia-smi -L"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8f5e8810",
+ "metadata": {},
+ "source": [
+ "Awesome, we have powerful NVIDIA GPU at our disposal. Let's get started with using it for Data Preprocessing."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0fb68f21",
+ "metadata": {},
+ "source": [
+ "## Data Preprocessing"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9894de9e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import cudf\n",
+ "import cuml\n",
+ "import numpy as np\n",
+ "import pickle\n",
+ "import os"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ef59ddd2",
+ "metadata": {},
+ "source": [
+ "We read in the data and begin our data preprocessing."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7adb6815",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data_path = \"./\"\n",
+ "data_csv = \"credit_card_transactions-ibm_v2.csv\"\n",
+ "full_data = cudf.read_csv(os.path.join(data_path, data_csv))\n",
+ "full_data.head()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4ffea2c4",
+ "metadata": {},
+ "source": [
+ "Each row here is a credit card transaction with attributes like time and amount of transaction along with merchant attributes like Name, City, State, Zipcode and Merchant Category Code (MCC) and finally whether the transaction was fraudulent or legitimate (`Is Fraud?`). \n",
+ "\n",
+ "**Note:** `Merchant Name` is hashed so that's why we see integers instead of strings.\n",
+ "\n",
+ "The full dataset has about 24 million rows but in this example we use random subset of about ~5 million transactions."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aaa12ce5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "SEED = 42\n",
+ "data = full_data.sample(frac=0.2, random_state=SEED)\n",
+ "data = data.reset_index(drop=True)\n",
+ "print(data.shape)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aff03966",
+ "metadata": {},
+ "source": [
+ "We convert some categorical features to dtype objects."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "937f07a6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data[\"Zip\"] = data[\"Zip\"].astype(\"object\")\n",
+ "data[\"MCC\"] = data[\"MCC\"].astype(\"object\")\n",
+ "data[\"Merchant Name\"] = data[\"Merchant Name\"].astype(\"object\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e60bbfcd",
+ "metadata": {},
+ "source": [
+ "### Encode labels\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1a5b1c65",
+ "metadata": {},
+ "source": [
+ "Next we perform encoding on our binary labels `Is Fraud?` which indicate whether a transaction is fraudulent or not. After encoding, `1` will denote fraud and `0` will denote legitimate transaction."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "89dd9c48",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "y = data[\"Is Fraud?\"]\n",
+ "data.drop(columns=[\"Is Fraud?\"], inplace=True)\n",
+ "y = (y == \"Yes\").astype(int)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "91889ae3",
+ "metadata": {},
+ "source": [
+ "### Save subset for inference"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8fdac51b",
+ "metadata": {},
+ "source": [
+ "We will also save a small subset of the data to submit Triton inference requests for later on in the [second notebook](2_triton_xgb_fil_ensemble.ipynb)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "588dcba3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data_infer = data.iloc[625:630]\n",
+ "data_infer.to_csv(\"data_infer.csv\", index=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "89151f4b",
+ "metadata": {},
+ "source": [
+ "### Handle Missing Values"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d57baac4",
+ "metadata": {},
+ "source": [
+ "Next let's handle the missing values in our data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "626f87dc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data.isna().sum() / len(data) * 100"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "66b2518f",
+ "metadata": {},
+ "source": [
+ "We have some missing values in `Merchant State` and `Zip` columns. Turns out these correspond to ONLINE transactions so we will set those missing values to `ONLINE`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "48e9d1b1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data.loc[data[\"Merchant City\"] == \"ONLINE\", \"Merchant State\"] = \"ONLINE\"\n",
+ "data.loc[data[\"Merchant City\"] == \"ONLINE\", \"Zip\"] = \"ONLINE\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa13e333",
+ "metadata": {},
+ "source": [
+ "We also have some foreign transactions where `Merchant City` and `Merchant State` is a foreign city and country and the Zipcode is missing. For those transactions we will set the Zipcode to `FOREIGN`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "926ac124",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "us_states_plus_online = [\n",
+ " \"AK\",\n",
+ " \"AL\",\n",
+ " \"AR\",\n",
+ " \"AZ\",\n",
+ " \"CA\",\n",
+ " \"CO\",\n",
+ " \"CT\",\n",
+ " \"DC\",\n",
+ " \"DE\",\n",
+ " \"FL\",\n",
+ " \"GA\",\n",
+ " \"HI\",\n",
+ " \"IA\",\n",
+ " \"ID\",\n",
+ " \"IL\",\n",
+ " \"IN\",\n",
+ " \"KS\",\n",
+ " \"KY\",\n",
+ " \"LA\",\n",
+ " \"MA\",\n",
+ " \"MD\",\n",
+ " \"ME\",\n",
+ " \"MI\",\n",
+ " \"MN\",\n",
+ " \"MO\",\n",
+ " \"MS\",\n",
+ " \"MT\",\n",
+ " \"NC\",\n",
+ " \"ND\",\n",
+ " \"NE\",\n",
+ " \"NH\",\n",
+ " \"NJ\",\n",
+ " \"NM\",\n",
+ " \"NV\",\n",
+ " \"NY\",\n",
+ " \"OH\",\n",
+ " \"OK\",\n",
+ " \"OR\",\n",
+ " \"PA\",\n",
+ " \"RI\",\n",
+ " \"SC\",\n",
+ " \"SD\",\n",
+ " \"TN\",\n",
+ " \"TX\",\n",
+ " \"UT\",\n",
+ " \"VA\",\n",
+ " \"VT\",\n",
+ " \"WA\",\n",
+ " \"WI\",\n",
+ " \"WV\",\n",
+ " \"WY\",\n",
+ " \"ONLINE\",\n",
+ "]\n",
+ "\n",
+ "# set zip of all transactions that are not in US States or Online to Foreign\n",
+ "data.loc[~data[\"Merchant State\"].isin(us_states_plus_online), \"Zip\"] = \"FOREIGN\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ff624ef",
+ "metadata": {},
+ "source": [
+ "The `Errors?` column indicates whether or not the transaction had any errors like an Incorrect Pin associated with it. We make this a boolean indicator feature."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "068800f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data[\"Errors?\"] = data[\"Errors?\"].notna()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0ae0b332",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data.isna().sum() / len(data) * 100"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5162efe1",
+ "metadata": {},
+ "source": [
+ "So now we have handled all the missing values in our data."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e80a3fb2",
+ "metadata": {},
+ "source": [
+ "### Handle Amount and Time"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9f8ea1d0",
+ "metadata": {},
+ "source": [
+ "Next, for the `Amount` column we remove the dollar symbol prefix and for `Time` column we extract out the Hour and Minute."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8350762d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data[\"Amount\"] = data[\"Amount\"].str.slice(1)\n",
+ "data[\"Hour\"] = data[\"Time\"].str.slice(stop=2)\n",
+ "data[\"Minute\"] = data[\"Time\"].str.slice(start=3)\n",
+ "data.drop(columns=[\"Time\"], inplace=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a2934011",
+ "metadata": {},
+ "source": [
+ "### Train-Test Split"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "25acf723",
+ "metadata": {},
+ "source": [
+ "Before doing any further preprocessing let's perform the train-test split. Here we use 70-30 train-test split."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1aa71566",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from cuml.model_selection import train_test_split\n",
+ "\n",
+ "X_train, X_test, y_train, y_test = train_test_split(\n",
+ " data, y, test_size=0.3, random_state=SEED, stratify=y\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5c957d39",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Free up some room on the GPU by explicitly deleting dataframes\n",
+ "import gc\n",
+ "\n",
+ "del data\n",
+ "del y\n",
+ "gc.collect()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8dfa111b",
+ "metadata": {},
+ "source": [
+ "### Encoding Categorical Columns"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "08c0cb62",
+ "metadata": {},
+ "source": [
+ "Next, we handle categorical columns in our dataset by performing [label encoding](https://docs.rapids.ai/api/cuml/stable/api.html?highlight=label%20encoder#feature-and-label-encoding-single-gpu) on them which convert categorical values into numerical values. For some of these columns we have some unseen values which are present in test data but not train data. We handle those values by setting them to `UNKNOWN` before doing the label encoding so that at test time we have an encoding for these unseen values.\n",
+ "\n",
+ "We also serialize the encodings for all categorical columns so that we can later use them for doing data preprocessing at inference time in the [second notebook](2_triton_xgb_fil_ensemble.ipynb)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "27bcaf30",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from cuml.preprocessing import LabelEncoder\n",
+ "\n",
+ "categorial_columns = [\"Zip\", \"MCC\", \"Merchant Name\", \"Use Chip\", \"Merchant City\", \"Merchant State\"]\n",
+ "encoders = {}\n",
+ "\n",
+ "# handle unknown values present in test data but not in training data\n",
+ "for col in categorial_columns:\n",
+ " # convert cudf series to numpy array with .values_host\n",
+ " unique_values = X_train[col].unique().values_host\n",
+ " X_test.loc[~X_test[col].isin(unique_values), col] = \"UNKNOWN\"\n",
+ " unique_values = np.append(unique_values, [\"UNKNOWN\"])\n",
+ " # convert numpy array to cudf series\n",
+ " unique_values = cudf.Series(unique_values)\n",
+ " le = LabelEncoder().fit(unique_values)\n",
+ " X_train[col] = le.transform(X_train[col])\n",
+ " X_test[col] = le.transform(X_test[col])\n",
+ " encoders[col] = le.classes_.values_host\n",
+ "\n",
+ "with open(\"label_encoders.pkl\", \"wb\") as f:\n",
+ " pickle.dump(encoders, f)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "97eb4855",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# convert all dtypes to fp32 for xgboost training\n",
+ "X_train = X_train.astype(\"float32\")\n",
+ "X_test = X_test.astype(\"float32\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "28e78093",
+ "metadata": {},
+ "source": [
+ "Let's look at our preprocessed data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "46c42639",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "X_train.head()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fbf7bb71",
+ "metadata": {},
+ "source": [
+ "## Train XGBoost"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8df4e196",
+ "metadata": {},
+ "source": [
+ "Now we train the XGBoost fraud detection model on our GPU. This will take about 2-3 minutes on `g4dn.xlarge` instance."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e6be5d5e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import xgboost as xgb\n",
+ "import time\n",
+ "\n",
+ "dtrain = xgb.DMatrix(X_train, y_train)\n",
+ "\n",
+ "dtest = xgb.DMatrix(X_test, y_test)\n",
+ "\n",
+ "max_depth = 8\n",
+ "num_trees = 2000\n",
+ "xgb_params = {\n",
+ " \"max_depth\": max_depth,\n",
+ " \"tree_method\": \"gpu_hist\",\n",
+ " \"objective\": \"binary:logistic\",\n",
+ " \"eval_metric\": \"aucpr\",\n",
+ " \"predictor\": \"gpu_predictor\",\n",
+ "}\n",
+ "model = xgb.train(params=xgb_params, dtrain=dtrain, num_boost_round=num_trees)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e26dbd34",
+ "metadata": {},
+ "source": [
+ "We quickly evaluate our trained model's predictions on the test set using F1-score."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0121077c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from sklearn.metrics import f1_score\n",
+ "\n",
+ "y_score = model.predict(dtest)\n",
+ "threshold = 0.5\n",
+ "y_pred = (y_score >= 0.5).astype(int)\n",
+ "y_true = y_test.values_host\n",
+ "f1 = f1_score(y_true, y_pred)\n",
+ "print(f\"Test F1-Score: {f1: 0.4f}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2672cf3a",
+ "metadata": {},
+ "source": [
+ "We can do further Hyperparameter tuning/Feature Engineering to improve the model accuracy but since the primary goal of this example is to walkthrough deployment of decision tree-based ML models like XGBoost on Triton in SageMaker we save our trained model and move on to the [second notebook](2_triton_xgb_fil_ensemble.ipynb)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b0962df8",
+ "metadata": {},
+ "source": [
+ "### Save Trained Model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c5f2f476",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_path = \"./xgboost.json\"\n",
+ "model.save_model(model_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3236c5c1",
+ "metadata": {},
+ "source": [
+ "## Next Step"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fdb0297e",
+ "metadata": {},
+ "source": [
+ "Please open the [second notebook](2_triton_xgb_fil_ensemble.ipynb) to learn how to deploy this XGBoost model and other similar decision tree-based ML models on Triton in SageMaker."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3.9.13 64-bit",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.13"
+ },
+ "vscode": {
+ "interpreter": {
+ "hash": "b0fa6594d8f4cbf19f97940f81e996739fb7646882a419484c72d19e05852a7e"
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/sagemaker-triton/fil_ensemble/2_triton_xgb_fil_ensemble.ipynb b/sagemaker-triton/fil_ensemble/2_triton_xgb_fil_ensemble.ipynb
new file mode 100644
index 0000000000..890d449a3a
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/2_triton_xgb_fil_ensemble.ipynb
@@ -0,0 +1,910 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "7e386477",
+ "metadata": {},
+ "source": [
+ "# Pre-processing and XGBoost model inference pipeline with NVIDIA Triton Inference Server on Amazon SageMaker"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ea6713c",
+ "metadata": {},
+ "source": [
+ "NOTE: This is the SECOND NOTEBOOOK included in a TWO PART SERIES. The [FIRST NOTEBOOK](1_prep_rapids_train_xgb.ipynb) creates artifacts which are dependencies for this notebook. \n",
+ "\n",
+ "With the 22.05 version release of [NVIDIA Triton](https://github.com/triton-inference-server/server/) container image on SageMaker you can now use Triton's Forest Inference Library (FIL) backend to easily serve tree based ML models like XGBoost for high-performance CPU and GPU inference in SageMaker. Using Triton's FIL backend allows you to benefit from performance optimizations like dynamic batching and concurrent execution which help maximize the utilization of GPU and CPU, further lowering the cost of inference. The multi-framework support provided by NVIDIA Triton allows you to seamlessly deploy tree-based ML models alongside deep learning models for fast, unified inference pipelines.\n",
+ "\n",
+ "Machine Learning applications are complex and can often require data pre-processing. In this notebook, we will not only deep dive into how to deploy a tree-based ML model like XGBoost using the FIL Backend in Triton on SageMaker endpoint but also cover how to implement python-based data pre-processing inference pipeline for your model using the ensemble feature in Triton. This will allow us to send in the raw data from client side and have both data pre-processing and model inference happen in Triton SageMaker endpoint for the optimal inference performance.\n",
+ "\n",
+ "## To Run This Notebook Please Select conda_python3 Kernel from the Kernel Dropdown menu\n",
+ "\n",
+ "**Note:** This notebook was tested with the `conda_python3` kernel on an Amazon SageMaker notebook instance of type `g4dn`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8f9fc77d",
+ "metadata": {},
+ "source": [
+ "## Forest Inference Library (FIL)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f9686e34",
+ "metadata": {},
+ "source": [
+ "RAPIDS Forest Inference Library (FIL) is a library to provide high-performance inference for tree-based models. Here are some important FIL features:\n",
+ "\n",
+ "* Supports XGBoost, LightGBM, cuML RandomForest, and Scikit Learn Random Forest\n",
+ "* No conversion needed for XGBoost and LightGBM. SKLearn or cuML pickle models need to be converted to Treelite's binary checkpoint format \n",
+ "* SKLearn Random Forest is supported for single-output regression and multi-class classification\n",
+ "* Both CPU and GPU are supported\n",
+ "\n",
+ "Below we show benchmark highlighting FIL's throughput performance against CPU XGBoost.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "In this notebook we will walk through using [RAPIDS](https://rapids.ai/about.html) for GPU-accelerated data preprocessing and training of XGBoost model for a Fraud Detection use-case. This is the first notebook in a two notebook series. In the [second notebook](2_triton_xgb_fil_ensemble.ipynb) we will show how to deploy the trained XGBoost model in Triton on SageMaker. The RAPIDS suite of open source software libraries and APIs gives you the ability to execute end-to-end data science and analytics pipelines entirely on GPUs. \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a15d9b9e",
+ "metadata": {},
+ "source": [
+ "**Note:** Since the primary goal of this example is to get a trained XGBoost model to illustrate deployment of Tree-based ML models on Triton in SageMaker we don't perform any in-depth feature engineering or hyperparameter optimization. RAPIDS on SageMaker however is excellent for running cost-effective HPO in minimal amount of time as shown in the blog post [RAPIDS and Amazon SageMaker: Scale up and scale out to tackle ML challenges](https://aws.amazon.com/blogs/machine-learning/rapids-and-amazon-sagemaker-scale-up-and-scale-out-to-tackle-ml-challenges/). \n",
+ "\n",
+ "## To Run This Notebook Please Select RAPIDS 2106 Kernel from the Kernel Dropdown menu"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bdf4884f",
+ "metadata": {},
+ "source": [
+ "This notebook was tested with the `rapids-2106` kernel on an Amazon SageMaker notebook instance of type `g4dn`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0f87fb40",
+ "metadata": {},
+ "source": [
+ "## Get Data"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b379efd7",
+ "metadata": {},
+ "source": [
+ "For this example, we use the Tabformer [synthetic credit card transactions dataset](https://arxiv.org/abs/1910.03033) from IBM available on [Kaggle](https://www.kaggle.com/datasets/ealtman2019/credit-card-transactions). The origin of this dataset along with its licensing terms can be found at: [Kaggle link](https://www.kaggle.com/datasets/ealtman2019/credit-card-transactions).\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d82b7ea5",
+ "metadata": {},
+ "source": [
+ "### Download Dataset"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4588fb76",
+ "metadata": {},
+ "source": [
+ "First we download the dataset from our Amazon S3 bucket."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "4f4f19b0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!python -m pip install --upgrade pip --quiet\n",
+ "!pip install -U awscli --quiet"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "58a250bc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!aws s3 cp s3://sagemaker-sample-files/datasets/tabular/synthetic_credit_card_transactions/credit_card_transactions-ibm_v2.csv ./"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f00abe8b",
+ "metadata": {},
+ "source": [
+ "## Check on our GPU"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "96e7edd8",
+ "metadata": {},
+ "source": [
+ "Next, let's check the GPU resources we have by using the terminal command `nvidia-smi`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7c3aeafc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!nvidia-smi\n",
+ "!nvidia-smi -L"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8f5e8810",
+ "metadata": {},
+ "source": [
+ "Awesome, we have powerful NVIDIA GPU at our disposal. Let's get started with using it for Data Preprocessing."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0fb68f21",
+ "metadata": {},
+ "source": [
+ "## Data Preprocessing"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "9894de9e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import cudf\n",
+ "import cuml\n",
+ "import numpy as np\n",
+ "import pickle\n",
+ "import os"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ef59ddd2",
+ "metadata": {},
+ "source": [
+ "We read in the data and begin our data preprocessing."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7adb6815",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data_path = \"./\"\n",
+ "data_csv = \"credit_card_transactions-ibm_v2.csv\"\n",
+ "full_data = cudf.read_csv(os.path.join(data_path, data_csv))\n",
+ "full_data.head()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4ffea2c4",
+ "metadata": {},
+ "source": [
+ "Each row here is a credit card transaction with attributes like time and amount of transaction along with merchant attributes like Name, City, State, Zipcode and Merchant Category Code (MCC) and finally whether the transaction was fraudulent or legitimate (`Is Fraud?`). \n",
+ "\n",
+ "**Note:** `Merchant Name` is hashed so that's why we see integers instead of strings.\n",
+ "\n",
+ "The full dataset has about 24 million rows but in this example we use random subset of about ~5 million transactions."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aaa12ce5",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "SEED = 42\n",
+ "data = full_data.sample(frac=0.2, random_state=SEED)\n",
+ "data = data.reset_index(drop=True)\n",
+ "print(data.shape)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aff03966",
+ "metadata": {},
+ "source": [
+ "We convert some categorical features to dtype objects."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "937f07a6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data[\"Zip\"] = data[\"Zip\"].astype(\"object\")\n",
+ "data[\"MCC\"] = data[\"MCC\"].astype(\"object\")\n",
+ "data[\"Merchant Name\"] = data[\"Merchant Name\"].astype(\"object\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e60bbfcd",
+ "metadata": {},
+ "source": [
+ "### Encode labels\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1a5b1c65",
+ "metadata": {},
+ "source": [
+ "Next we perform encoding on our binary labels `Is Fraud?` which indicate whether a transaction is fraudulent or not. After encoding, `1` will denote fraud and `0` will denote legitimate transaction."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "89dd9c48",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "y = data[\"Is Fraud?\"]\n",
+ "data.drop(columns=[\"Is Fraud?\"], inplace=True)\n",
+ "y = (y == \"Yes\").astype(int)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "91889ae3",
+ "metadata": {},
+ "source": [
+ "### Save subset for inference"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8fdac51b",
+ "metadata": {},
+ "source": [
+ "We will also save a small subset of the data to submit Triton inference requests for later on in the [second notebook](2_triton_xgb_fil_ensemble.ipynb)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "588dcba3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data_infer = data.iloc[625:630]\n",
+ "data_infer.to_csv(\"data_infer.csv\", index=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "89151f4b",
+ "metadata": {},
+ "source": [
+ "### Handle Missing Values"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d57baac4",
+ "metadata": {},
+ "source": [
+ "Next let's handle the missing values in our data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "626f87dc",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data.isna().sum() / len(data) * 100"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "66b2518f",
+ "metadata": {},
+ "source": [
+ "We have some missing values in `Merchant State` and `Zip` columns. Turns out these correspond to ONLINE transactions so we will set those missing values to `ONLINE`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "48e9d1b1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data.loc[data[\"Merchant City\"] == \"ONLINE\", \"Merchant State\"] = \"ONLINE\"\n",
+ "data.loc[data[\"Merchant City\"] == \"ONLINE\", \"Zip\"] = \"ONLINE\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "aa13e333",
+ "metadata": {},
+ "source": [
+ "We also have some foreign transactions where `Merchant City` and `Merchant State` is a foreign city and country and the Zipcode is missing. For those transactions we will set the Zipcode to `FOREIGN`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "926ac124",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "us_states_plus_online = [\n",
+ " \"AK\",\n",
+ " \"AL\",\n",
+ " \"AR\",\n",
+ " \"AZ\",\n",
+ " \"CA\",\n",
+ " \"CO\",\n",
+ " \"CT\",\n",
+ " \"DC\",\n",
+ " \"DE\",\n",
+ " \"FL\",\n",
+ " \"GA\",\n",
+ " \"HI\",\n",
+ " \"IA\",\n",
+ " \"ID\",\n",
+ " \"IL\",\n",
+ " \"IN\",\n",
+ " \"KS\",\n",
+ " \"KY\",\n",
+ " \"LA\",\n",
+ " \"MA\",\n",
+ " \"MD\",\n",
+ " \"ME\",\n",
+ " \"MI\",\n",
+ " \"MN\",\n",
+ " \"MO\",\n",
+ " \"MS\",\n",
+ " \"MT\",\n",
+ " \"NC\",\n",
+ " \"ND\",\n",
+ " \"NE\",\n",
+ " \"NH\",\n",
+ " \"NJ\",\n",
+ " \"NM\",\n",
+ " \"NV\",\n",
+ " \"NY\",\n",
+ " \"OH\",\n",
+ " \"OK\",\n",
+ " \"OR\",\n",
+ " \"PA\",\n",
+ " \"RI\",\n",
+ " \"SC\",\n",
+ " \"SD\",\n",
+ " \"TN\",\n",
+ " \"TX\",\n",
+ " \"UT\",\n",
+ " \"VA\",\n",
+ " \"VT\",\n",
+ " \"WA\",\n",
+ " \"WI\",\n",
+ " \"WV\",\n",
+ " \"WY\",\n",
+ " \"ONLINE\",\n",
+ "]\n",
+ "\n",
+ "# set zip of all transactions that are not in US States or Online to Foreign\n",
+ "data.loc[~data[\"Merchant State\"].isin(us_states_plus_online), \"Zip\"] = \"FOREIGN\""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ff624ef",
+ "metadata": {},
+ "source": [
+ "The `Errors?` column indicates whether or not the transaction had any errors like an Incorrect Pin associated with it. We make this a boolean indicator feature."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "068800f0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data[\"Errors?\"] = data[\"Errors?\"].notna()"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0ae0b332",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data.isna().sum() / len(data) * 100"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5162efe1",
+ "metadata": {},
+ "source": [
+ "So now we have handled all the missing values in our data."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e80a3fb2",
+ "metadata": {},
+ "source": [
+ "### Handle Amount and Time"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9f8ea1d0",
+ "metadata": {},
+ "source": [
+ "Next, for the `Amount` column we remove the dollar symbol prefix and for `Time` column we extract out the Hour and Minute."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8350762d",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data[\"Amount\"] = data[\"Amount\"].str.slice(1)\n",
+ "data[\"Hour\"] = data[\"Time\"].str.slice(stop=2)\n",
+ "data[\"Minute\"] = data[\"Time\"].str.slice(start=3)\n",
+ "data.drop(columns=[\"Time\"], inplace=True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a2934011",
+ "metadata": {},
+ "source": [
+ "### Train-Test Split"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "25acf723",
+ "metadata": {},
+ "source": [
+ "Before doing any further preprocessing let's perform the train-test split. Here we use 70-30 train-test split."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1aa71566",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from cuml.model_selection import train_test_split\n",
+ "\n",
+ "X_train, X_test, y_train, y_test = train_test_split(\n",
+ " data, y, test_size=0.3, random_state=SEED, stratify=y\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "5c957d39",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Free up some room on the GPU by explicitly deleting dataframes\n",
+ "import gc\n",
+ "\n",
+ "del data\n",
+ "del y\n",
+ "gc.collect()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8dfa111b",
+ "metadata": {},
+ "source": [
+ "### Encoding Categorical Columns"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "08c0cb62",
+ "metadata": {},
+ "source": [
+ "Next, we handle categorical columns in our dataset by performing [label encoding](https://docs.rapids.ai/api/cuml/stable/api.html?highlight=label%20encoder#feature-and-label-encoding-single-gpu) on them which convert categorical values into numerical values. For some of these columns we have some unseen values which are present in test data but not train data. We handle those values by setting them to `UNKNOWN` before doing the label encoding so that at test time we have an encoding for these unseen values.\n",
+ "\n",
+ "We also serialize the encodings for all categorical columns so that we can later use them for doing data preprocessing at inference time in the [second notebook](2_triton_xgb_fil_ensemble.ipynb)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "27bcaf30",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from cuml.preprocessing import LabelEncoder\n",
+ "\n",
+ "categorial_columns = [\"Zip\", \"MCC\", \"Merchant Name\", \"Use Chip\", \"Merchant City\", \"Merchant State\"]\n",
+ "encoders = {}\n",
+ "\n",
+ "# handle unknown values present in test data but not in training data\n",
+ "for col in categorial_columns:\n",
+ " # convert cudf series to numpy array with .values_host\n",
+ " unique_values = X_train[col].unique().values_host\n",
+ " X_test.loc[~X_test[col].isin(unique_values), col] = \"UNKNOWN\"\n",
+ " unique_values = np.append(unique_values, [\"UNKNOWN\"])\n",
+ " # convert numpy array to cudf series\n",
+ " unique_values = cudf.Series(unique_values)\n",
+ " le = LabelEncoder().fit(unique_values)\n",
+ " X_train[col] = le.transform(X_train[col])\n",
+ " X_test[col] = le.transform(X_test[col])\n",
+ " encoders[col] = le.classes_.values_host\n",
+ "\n",
+ "with open(\"label_encoders.pkl\", \"wb\") as f:\n",
+ " pickle.dump(encoders, f)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "97eb4855",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# convert all dtypes to fp32 for xgboost training\n",
+ "X_train = X_train.astype(\"float32\")\n",
+ "X_test = X_test.astype(\"float32\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "28e78093",
+ "metadata": {},
+ "source": [
+ "Let's look at our preprocessed data."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "46c42639",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "X_train.head()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fbf7bb71",
+ "metadata": {},
+ "source": [
+ "## Train XGBoost"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8df4e196",
+ "metadata": {},
+ "source": [
+ "Now we train the XGBoost fraud detection model on our GPU. This will take about 2-3 minutes on `g4dn.xlarge` instance."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e6be5d5e",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import xgboost as xgb\n",
+ "import time\n",
+ "\n",
+ "dtrain = xgb.DMatrix(X_train, y_train)\n",
+ "\n",
+ "dtest = xgb.DMatrix(X_test, y_test)\n",
+ "\n",
+ "max_depth = 8\n",
+ "num_trees = 2000\n",
+ "xgb_params = {\n",
+ " \"max_depth\": max_depth,\n",
+ " \"tree_method\": \"gpu_hist\",\n",
+ " \"objective\": \"binary:logistic\",\n",
+ " \"eval_metric\": \"aucpr\",\n",
+ " \"predictor\": \"gpu_predictor\",\n",
+ "}\n",
+ "model = xgb.train(params=xgb_params, dtrain=dtrain, num_boost_round=num_trees)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e26dbd34",
+ "metadata": {},
+ "source": [
+ "We quickly evaluate our trained model's predictions on the test set using F1-score."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0121077c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from sklearn.metrics import f1_score\n",
+ "\n",
+ "y_score = model.predict(dtest)\n",
+ "threshold = 0.5\n",
+ "y_pred = (y_score >= 0.5).astype(int)\n",
+ "y_true = y_test.values_host\n",
+ "f1 = f1_score(y_true, y_pred)\n",
+ "print(f\"Test F1-Score: {f1: 0.4f}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2672cf3a",
+ "metadata": {},
+ "source": [
+ "We can do further Hyperparameter tuning/Feature Engineering to improve the model accuracy but since the primary goal of this example is to walkthrough deployment of decision tree-based ML models like XGBoost on Triton in SageMaker we save our trained model and move on to the [second notebook](2_triton_xgb_fil_ensemble.ipynb)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b0962df8",
+ "metadata": {},
+ "source": [
+ "### Save Trained Model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c5f2f476",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_path = \"./xgboost.json\"\n",
+ "model.save_model(model_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3236c5c1",
+ "metadata": {},
+ "source": [
+ "## Next Step"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fdb0297e",
+ "metadata": {},
+ "source": [
+ "Please open the [second notebook](2_triton_xgb_fil_ensemble.ipynb) to learn how to deploy this XGBoost model and other similar decision tree-based ML models on Triton in SageMaker."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3.9.13 64-bit",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.13"
+ },
+ "vscode": {
+ "interpreter": {
+ "hash": "b0fa6594d8f4cbf19f97940f81e996739fb7646882a419484c72d19e05852a7e"
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/sagemaker-triton/fil_ensemble/2_triton_xgb_fil_ensemble.ipynb b/sagemaker-triton/fil_ensemble/2_triton_xgb_fil_ensemble.ipynb
new file mode 100644
index 0000000000..890d449a3a
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/2_triton_xgb_fil_ensemble.ipynb
@@ -0,0 +1,910 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "id": "7e386477",
+ "metadata": {},
+ "source": [
+ "# Pre-processing and XGBoost model inference pipeline with NVIDIA Triton Inference Server on Amazon SageMaker"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9ea6713c",
+ "metadata": {},
+ "source": [
+ "NOTE: This is the SECOND NOTEBOOOK included in a TWO PART SERIES. The [FIRST NOTEBOOK](1_prep_rapids_train_xgb.ipynb) creates artifacts which are dependencies for this notebook. \n",
+ "\n",
+ "With the 22.05 version release of [NVIDIA Triton](https://github.com/triton-inference-server/server/) container image on SageMaker you can now use Triton's Forest Inference Library (FIL) backend to easily serve tree based ML models like XGBoost for high-performance CPU and GPU inference in SageMaker. Using Triton's FIL backend allows you to benefit from performance optimizations like dynamic batching and concurrent execution which help maximize the utilization of GPU and CPU, further lowering the cost of inference. The multi-framework support provided by NVIDIA Triton allows you to seamlessly deploy tree-based ML models alongside deep learning models for fast, unified inference pipelines.\n",
+ "\n",
+ "Machine Learning applications are complex and can often require data pre-processing. In this notebook, we will not only deep dive into how to deploy a tree-based ML model like XGBoost using the FIL Backend in Triton on SageMaker endpoint but also cover how to implement python-based data pre-processing inference pipeline for your model using the ensemble feature in Triton. This will allow us to send in the raw data from client side and have both data pre-processing and model inference happen in Triton SageMaker endpoint for the optimal inference performance.\n",
+ "\n",
+ "## To Run This Notebook Please Select conda_python3 Kernel from the Kernel Dropdown menu\n",
+ "\n",
+ "**Note:** This notebook was tested with the `conda_python3` kernel on an Amazon SageMaker notebook instance of type `g4dn`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "8f9fc77d",
+ "metadata": {},
+ "source": [
+ "## Forest Inference Library (FIL)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f9686e34",
+ "metadata": {},
+ "source": [
+ "RAPIDS Forest Inference Library (FIL) is a library to provide high-performance inference for tree-based models. Here are some important FIL features:\n",
+ "\n",
+ "* Supports XGBoost, LightGBM, cuML RandomForest, and Scikit Learn Random Forest\n",
+ "* No conversion needed for XGBoost and LightGBM. SKLearn or cuML pickle models need to be converted to Treelite's binary checkpoint format \n",
+ "* SKLearn Random Forest is supported for single-output regression and multi-class classification\n",
+ "* Both CPU and GPU are supported\n",
+ "\n",
+ "Below we show benchmark highlighting FIL's throughput performance against CPU XGBoost.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7df7b53e",
+ "metadata": {},
+ "source": [
+ "## Triton FIL Backend\n",
+ "FIL is available as a backend in Triton with features to allow for serving XGBoost, LightGBM and RandomForest models both on CPU and GPU with high performance. Here are some important features of the FIL Backend:\n",
+ "\n",
+ "* **Shapley Value Support (GPU)**: GPU Shapley Values are supported for Model Explainability\n",
+ "* **Categorical Feature Support**: Models trained on categorical features fully supported.\n",
+ "* **CPU Optimizations**: Optimized CPU mode offers faster execution than native XGBoost.\n",
+ "\n",
+ "To learn more about FIL Backend's features please see the [FAQ Notebook](https://github.com/triton-inference-server/fil_backend/blob/fea-faq_nb/notebooks/faq/FAQs.ipynb) and [Triton FIL Backend GitHub.](https://github.com/triton-inference-server/fil_backend/tree/main)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3907aeb3",
+ "metadata": {},
+ "source": [
+ "## Triton Model Ensemble Feature\n",
+ "Triton Inference Server greatly simplifies the deployment of AI models at scale in production. Triton Server comes with a convenient solution that simplifies building pre-processing and post-processing pipelines. Triton Server platform provides the ensemble scheduler, which is responsible for pipelining models participating in the inference process while ensuring efficiency and optimizing throughput. Using ensemble models can avoid the overhead of transferring intermediate tensors and minimize the number of requests that must be sent to Triton.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7df7b53e",
+ "metadata": {},
+ "source": [
+ "## Triton FIL Backend\n",
+ "FIL is available as a backend in Triton with features to allow for serving XGBoost, LightGBM and RandomForest models both on CPU and GPU with high performance. Here are some important features of the FIL Backend:\n",
+ "\n",
+ "* **Shapley Value Support (GPU)**: GPU Shapley Values are supported for Model Explainability\n",
+ "* **Categorical Feature Support**: Models trained on categorical features fully supported.\n",
+ "* **CPU Optimizations**: Optimized CPU mode offers faster execution than native XGBoost.\n",
+ "\n",
+ "To learn more about FIL Backend's features please see the [FAQ Notebook](https://github.com/triton-inference-server/fil_backend/blob/fea-faq_nb/notebooks/faq/FAQs.ipynb) and [Triton FIL Backend GitHub.](https://github.com/triton-inference-server/fil_backend/tree/main)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3907aeb3",
+ "metadata": {},
+ "source": [
+ "## Triton Model Ensemble Feature\n",
+ "Triton Inference Server greatly simplifies the deployment of AI models at scale in production. Triton Server comes with a convenient solution that simplifies building pre-processing and post-processing pipelines. Triton Server platform provides the ensemble scheduler, which is responsible for pipelining models participating in the inference process while ensuring efficiency and optimizing throughput. Using ensemble models can avoid the overhead of transferring intermediate tensors and minimize the number of requests that must be sent to Triton.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3ade5d7a",
+ "metadata": {},
+ "source": [
+ "In this notebook we will be show how to use the ensemble feature for building a pipeline of data preprocessing with XGBoost model inference and you can extrapolate from it to add custom postprocessing to the pipeline."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d32d93c",
+ "metadata": {},
+ "source": [
+ "## Set up Environment"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "da60ff17",
+ "metadata": {},
+ "source": [
+ "We begin by setting up the required environment. We will install the dependencies required to package our model pipeline and run inferences using Triton server. Also define the IAM role that will give SageMaker access to the model artifacts and the NVIDIA Triton ECR image."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "36a83ed3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install nvidia-pyindex\n",
+ "!pip install tritonclient[http]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "81049583",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import boto3\n",
+ "import json\n",
+ "import sagemaker\n",
+ "import time\n",
+ "import os\n",
+ "from sagemaker import get_execution_role\n",
+ "import pandas as pd\n",
+ "import numpy as np\n",
+ "\n",
+ "sess = boto3.Session()\n",
+ "sm = sess.client(\"sagemaker\")\n",
+ "sagemaker_session = sagemaker.Session(boto_session=sess)\n",
+ "role = get_execution_role()\n",
+ "client = boto3.client(\"sagemaker-runtime\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e96f98b1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "account_id_map = {\n",
+ " \"us-east-1\": \"785573368785\",\n",
+ " \"us-east-2\": \"007439368137\",\n",
+ " \"us-west-1\": \"710691900526\",\n",
+ " \"us-west-2\": \"301217895009\",\n",
+ " \"eu-west-1\": \"802834080501\",\n",
+ " \"eu-west-2\": \"205493899709\",\n",
+ " \"eu-west-3\": \"254080097072\",\n",
+ " \"eu-north-1\": \"601324751636\",\n",
+ " \"eu-south-1\": \"966458181534\",\n",
+ " \"eu-central-1\": \"746233611703\",\n",
+ " \"ap-east-1\": \"110948597952\",\n",
+ " \"ap-south-1\": \"763008648453\",\n",
+ " \"ap-northeast-1\": \"941853720454\",\n",
+ " \"ap-northeast-2\": \"151534178276\",\n",
+ " \"ap-southeast-1\": \"324986816169\",\n",
+ " \"ap-southeast-2\": \"355873309152\",\n",
+ " \"cn-northwest-1\": \"474822919863\",\n",
+ " \"cn-north-1\": \"472730292857\",\n",
+ " \"sa-east-1\": \"756306329178\",\n",
+ " \"ca-central-1\": \"464438896020\",\n",
+ " \"me-south-1\": \"836785723513\",\n",
+ " \"af-south-1\": \"774647643957\",\n",
+ "}\n",
+ "\n",
+ "region = boto3.Session().region_name\n",
+ "if region not in account_id_map.keys():\n",
+ " raise (\"UNSUPPORTED REGION\")\n",
+ "\n",
+ "base = \"amazonaws.com.cn\" if region.startswith(\"cn-\") else \"amazonaws.com\"\n",
+ "triton_image_uri = \"{account_id}.dkr.ecr.{region}.{base}/sagemaker-tritonserver:22.05-py3\".format(\n",
+ " account_id=account_id_map[region], region=region, base=base\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e796fbd9",
+ "metadata": {},
+ "source": [
+ "## Set up pre-processing with Triton Python Backend"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1b30cc9c",
+ "metadata": {},
+ "source": [
+ "We will be using Triton's [Python Backend](https://github.com/triton-inference-server/python_backend) to perform the same tabular data preprocessing that we did in [first notebook](1_prep_rapids_train_xgb.ipynb) but now during inference time for raw data requests coming into the server. The Python backend enables pre-process, post-processing and any other custom logic to be implemented in Python and served with Triton."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9f95bf6b",
+ "metadata": {},
+ "source": [
+ "Using Triton on SageMaker requires us to first set up a model repository folder containing the models we want to serve. We have already set up model for python data preprocessing called `preprocessing` in the `model_repository`.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3ade5d7a",
+ "metadata": {},
+ "source": [
+ "In this notebook we will be show how to use the ensemble feature for building a pipeline of data preprocessing with XGBoost model inference and you can extrapolate from it to add custom postprocessing to the pipeline."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3d32d93c",
+ "metadata": {},
+ "source": [
+ "## Set up Environment"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "da60ff17",
+ "metadata": {},
+ "source": [
+ "We begin by setting up the required environment. We will install the dependencies required to package our model pipeline and run inferences using Triton server. Also define the IAM role that will give SageMaker access to the model artifacts and the NVIDIA Triton ECR image."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "36a83ed3",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install nvidia-pyindex\n",
+ "!pip install tritonclient[http]"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "81049583",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import boto3\n",
+ "import json\n",
+ "import sagemaker\n",
+ "import time\n",
+ "import os\n",
+ "from sagemaker import get_execution_role\n",
+ "import pandas as pd\n",
+ "import numpy as np\n",
+ "\n",
+ "sess = boto3.Session()\n",
+ "sm = sess.client(\"sagemaker\")\n",
+ "sagemaker_session = sagemaker.Session(boto_session=sess)\n",
+ "role = get_execution_role()\n",
+ "client = boto3.client(\"sagemaker-runtime\")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "e96f98b1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "account_id_map = {\n",
+ " \"us-east-1\": \"785573368785\",\n",
+ " \"us-east-2\": \"007439368137\",\n",
+ " \"us-west-1\": \"710691900526\",\n",
+ " \"us-west-2\": \"301217895009\",\n",
+ " \"eu-west-1\": \"802834080501\",\n",
+ " \"eu-west-2\": \"205493899709\",\n",
+ " \"eu-west-3\": \"254080097072\",\n",
+ " \"eu-north-1\": \"601324751636\",\n",
+ " \"eu-south-1\": \"966458181534\",\n",
+ " \"eu-central-1\": \"746233611703\",\n",
+ " \"ap-east-1\": \"110948597952\",\n",
+ " \"ap-south-1\": \"763008648453\",\n",
+ " \"ap-northeast-1\": \"941853720454\",\n",
+ " \"ap-northeast-2\": \"151534178276\",\n",
+ " \"ap-southeast-1\": \"324986816169\",\n",
+ " \"ap-southeast-2\": \"355873309152\",\n",
+ " \"cn-northwest-1\": \"474822919863\",\n",
+ " \"cn-north-1\": \"472730292857\",\n",
+ " \"sa-east-1\": \"756306329178\",\n",
+ " \"ca-central-1\": \"464438896020\",\n",
+ " \"me-south-1\": \"836785723513\",\n",
+ " \"af-south-1\": \"774647643957\",\n",
+ "}\n",
+ "\n",
+ "region = boto3.Session().region_name\n",
+ "if region not in account_id_map.keys():\n",
+ " raise (\"UNSUPPORTED REGION\")\n",
+ "\n",
+ "base = \"amazonaws.com.cn\" if region.startswith(\"cn-\") else \"amazonaws.com\"\n",
+ "triton_image_uri = \"{account_id}.dkr.ecr.{region}.{base}/sagemaker-tritonserver:22.05-py3\".format(\n",
+ " account_id=account_id_map[region], region=region, base=base\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e796fbd9",
+ "metadata": {},
+ "source": [
+ "## Set up pre-processing with Triton Python Backend"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1b30cc9c",
+ "metadata": {},
+ "source": [
+ "We will be using Triton's [Python Backend](https://github.com/triton-inference-server/python_backend) to perform the same tabular data preprocessing that we did in [first notebook](1_prep_rapids_train_xgb.ipynb) but now during inference time for raw data requests coming into the server. The Python backend enables pre-process, post-processing and any other custom logic to be implemented in Python and served with Triton."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9f95bf6b",
+ "metadata": {},
+ "source": [
+ "Using Triton on SageMaker requires us to first set up a model repository folder containing the models we want to serve. We have already set up model for python data preprocessing called `preprocessing` in the `model_repository`.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f40198e8",
+ "metadata": {},
+ "source": [
+ "Now Triton has specific requirements for model repository layout. Within the top-level model repository directory each model has its own sub-directory containing the information for the corresponding model. Each model directory in Triton must have at least one numeric sub-directory representing a version of the model. Here that is `1` representing version 1 of our python preprocessing model. Each model is executed by a specific backend so within each version sub-directory there must be the model artifact required by that backend. Here, we are using the Python backend and it requires the python file you are serving to be called `model.py` and the file needs to implement [certain functions](https://github.com/triton-inference-server/python_backend#usage). If we were using a PyTorch backend a `model.pt` file would be required and so on. For more details on naming conventions for model files please see the [model files doc](https://github.com/triton-inference-server/server/blob/185253ce225a0b012e73cade5c9a948ef9e75abd/docs/model_repository.md#model-files).\n",
+ "\n",
+ "\n",
+ "[Our model.py](model_repository/preprocessing/1/model.py) python file we are using here implements all the tabular data preprocessing logic to convert raw data into features that can be fed into our XGBoost model.\n",
+ "\n",
+ "Every Triton model must also provide a `config.pbtxt` file describing the model configuration. To learn more about the config settings please see [model configuration](https://github.com/triton-inference-server/server/blob/main/docs/model_configuration.md) doc. [Our config.pbtxt](model_repository/preprocessing/config.pbtxt) specifies the backend as `python` and specifies all the input columns for raw data along with preprocessed output that consists of 15 features. We also specify we want to run this python preprocessing model on the CPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1b42213e",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Create Conda Env for Preprocessing Dependencies"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3be5e211",
+ "metadata": {},
+ "source": [
+ "The Python backend in Triton requires us to use conda environment for any additional dependencies. In this case we are using the Python backend to do preprocessing of the raw data before feeding it into the XGBoost model being run in FIL Backend. Even though we originally used RAPIDS cuDF and cuML to do the data preprocessing here we use Pandas and Scikit-learn as preprocessing dependencies for inference time. We do this for three reasons. \n",
+ "* Firstly, to show how to create conda environment for your dependencies and how to package it in [format expected](https://github.com/triton-inference-server/python_backend#2-packaging-the-conda-environment) by Triton's Python backend. \n",
+ "* Secondly, by showing the preprocessing model running in Python backend on the CPU while the XGBoost runs on the GPU in FIL Backend we illustrate how each model in Triton's ensemble pipeline can run on different framework backend as well as different hardware configurations\n",
+ "* Thirdly, it highlights how the RAPIDS libraries (cuDF, cuML) are compatible with their CPU counterparts (Pandas, Scikit-learn). For example this way we get to show how LabelEncoders created in cuML can be used in Scikit-learn and vice-versa"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "eedfc6dc",
+ "metadata": {},
+ "source": [
+ "We follow the instructions from the [Triton documentation](https://github.com/triton-inference-server/python_backend#2-packaging-the-conda-environment) for packaging preprocessing dependencies (scikit-learn and pandas) to be used in the python backend as conda env tar file. The bash script [create_prep_env.sh](./create_prep_env.sh) creates the conda environment tar file and then we move it into the preprocessing model directory."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aefd7687",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!bash create_prep_env.sh\n",
+ "!cp preprocessing_env.tar.gz model_repository/preprocessing/"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc8232dc",
+ "metadata": {},
+ "source": [
+ "After creating the tar file from the conda environment and placing it in model folder, you need to tell Python backend to use that environment for your model. We do this by including the lines below in the model `config.pbtxt` file:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "606f2be2",
+ "metadata": {},
+ "source": [
+ "```\n",
+ "parameters: {\n",
+ " key: \"EXECUTION_ENV_PATH\",\n",
+ " value: {string_value: \"$$TRITON_MODEL_DIRECTORY/preprocessing_env.tar.gz\"}\n",
+ "}\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "338d5bcf",
+ "metadata": {},
+ "source": [
+ "Here, `$$TRITON_MODEL_DIRECTORY` helps provide environment path relative to the model folder in model repository and is resolved to `$pwd/model_repository/preprocessing`. Finally `preprocessing_env.tar.gz` is the name we gave to our conda env file. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7e429da7",
+ "metadata": {},
+ "source": [
+ "### Set up Label Encoders"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc987681",
+ "metadata": {},
+ "source": [
+ "We also move the label encoders we had serialized earlier into `preprocessing` model folder so that we can use them to encode raw data categorical features at inference time."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "40c9c454",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!cp label_encoders.pkl model_repository/preprocessing/1/"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "07b7307a",
+ "metadata": {},
+ "source": [
+ "## Set up Tree-based ML Model for FIL Backend"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e86978d1",
+ "metadata": {},
+ "source": [
+ "Next, we set up the model directory for tree-based ML model like XGBoost which will be using FIL Backend.\n",
+ "\n",
+ "The expected layout for model directory is similar to the one we showed above:\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f40198e8",
+ "metadata": {},
+ "source": [
+ "Now Triton has specific requirements for model repository layout. Within the top-level model repository directory each model has its own sub-directory containing the information for the corresponding model. Each model directory in Triton must have at least one numeric sub-directory representing a version of the model. Here that is `1` representing version 1 of our python preprocessing model. Each model is executed by a specific backend so within each version sub-directory there must be the model artifact required by that backend. Here, we are using the Python backend and it requires the python file you are serving to be called `model.py` and the file needs to implement [certain functions](https://github.com/triton-inference-server/python_backend#usage). If we were using a PyTorch backend a `model.pt` file would be required and so on. For more details on naming conventions for model files please see the [model files doc](https://github.com/triton-inference-server/server/blob/185253ce225a0b012e73cade5c9a948ef9e75abd/docs/model_repository.md#model-files).\n",
+ "\n",
+ "\n",
+ "[Our model.py](model_repository/preprocessing/1/model.py) python file we are using here implements all the tabular data preprocessing logic to convert raw data into features that can be fed into our XGBoost model.\n",
+ "\n",
+ "Every Triton model must also provide a `config.pbtxt` file describing the model configuration. To learn more about the config settings please see [model configuration](https://github.com/triton-inference-server/server/blob/main/docs/model_configuration.md) doc. [Our config.pbtxt](model_repository/preprocessing/config.pbtxt) specifies the backend as `python` and specifies all the input columns for raw data along with preprocessed output that consists of 15 features. We also specify we want to run this python preprocessing model on the CPU."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1b42213e",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "### Create Conda Env for Preprocessing Dependencies"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3be5e211",
+ "metadata": {},
+ "source": [
+ "The Python backend in Triton requires us to use conda environment for any additional dependencies. In this case we are using the Python backend to do preprocessing of the raw data before feeding it into the XGBoost model being run in FIL Backend. Even though we originally used RAPIDS cuDF and cuML to do the data preprocessing here we use Pandas and Scikit-learn as preprocessing dependencies for inference time. We do this for three reasons. \n",
+ "* Firstly, to show how to create conda environment for your dependencies and how to package it in [format expected](https://github.com/triton-inference-server/python_backend#2-packaging-the-conda-environment) by Triton's Python backend. \n",
+ "* Secondly, by showing the preprocessing model running in Python backend on the CPU while the XGBoost runs on the GPU in FIL Backend we illustrate how each model in Triton's ensemble pipeline can run on different framework backend as well as different hardware configurations\n",
+ "* Thirdly, it highlights how the RAPIDS libraries (cuDF, cuML) are compatible with their CPU counterparts (Pandas, Scikit-learn). For example this way we get to show how LabelEncoders created in cuML can be used in Scikit-learn and vice-versa"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "eedfc6dc",
+ "metadata": {},
+ "source": [
+ "We follow the instructions from the [Triton documentation](https://github.com/triton-inference-server/python_backend#2-packaging-the-conda-environment) for packaging preprocessing dependencies (scikit-learn and pandas) to be used in the python backend as conda env tar file. The bash script [create_prep_env.sh](./create_prep_env.sh) creates the conda environment tar file and then we move it into the preprocessing model directory."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "aefd7687",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!bash create_prep_env.sh\n",
+ "!cp preprocessing_env.tar.gz model_repository/preprocessing/"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc8232dc",
+ "metadata": {},
+ "source": [
+ "After creating the tar file from the conda environment and placing it in model folder, you need to tell Python backend to use that environment for your model. We do this by including the lines below in the model `config.pbtxt` file:"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "606f2be2",
+ "metadata": {},
+ "source": [
+ "```\n",
+ "parameters: {\n",
+ " key: \"EXECUTION_ENV_PATH\",\n",
+ " value: {string_value: \"$$TRITON_MODEL_DIRECTORY/preprocessing_env.tar.gz\"}\n",
+ "}\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "338d5bcf",
+ "metadata": {},
+ "source": [
+ "Here, `$$TRITON_MODEL_DIRECTORY` helps provide environment path relative to the model folder in model repository and is resolved to `$pwd/model_repository/preprocessing`. Finally `preprocessing_env.tar.gz` is the name we gave to our conda env file. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7e429da7",
+ "metadata": {},
+ "source": [
+ "### Set up Label Encoders"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "bc987681",
+ "metadata": {},
+ "source": [
+ "We also move the label encoders we had serialized earlier into `preprocessing` model folder so that we can use them to encode raw data categorical features at inference time."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "40c9c454",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!cp label_encoders.pkl model_repository/preprocessing/1/"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "07b7307a",
+ "metadata": {},
+ "source": [
+ "## Set up Tree-based ML Model for FIL Backend"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e86978d1",
+ "metadata": {},
+ "source": [
+ "Next, we set up the model directory for tree-based ML model like XGBoost which will be using FIL Backend.\n",
+ "\n",
+ "The expected layout for model directory is similar to the one we showed above:\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "facb89d4",
+ "metadata": {},
+ "source": [
+ "Here, `fil` is the name of the model. We can give it a different name like xgboost if we want to. `1` is the version sub-directory which contains the model artifact, in this case it's the `xgboost.json` model that we saved at the end of [first notebook](1_prep_rapids_train_xgb.ipynb). Let's create this expected layout."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af0a4ac2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# move saved xgboost model into fil model directory\n",
+ "!mkdir -p model_repository/fil/1\n",
+ "!cp xgboost.json model_repository/fil/1/"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3413e6eb",
+ "metadata": {},
+ "source": [
+ "And then finally we need to have configuration file `config.pbtxt` describing the model configuration for tree-based ML model so that FIL Backend in Triton can understand how to serve it."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "754f8c5d",
+ "metadata": {},
+ "source": [
+ "### Create Config File for FIL Backend Model"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e4c957cd",
+ "metadata": {},
+ "source": [
+ "You can read about all generic Triton configuration options [here](https://github.com/triton-inference-server/server/blob/master/docs/model_configuration.md) and about configuration options specific to the FIL backend [here](https://github.com/triton-inference-server/fil_backend#configuration), but we will focus on just a few of the most common and relevant options in this example. Below are general descriptions of these options:\n",
+ "\n",
+ "* **max_batch_size:** The maximum batch size that can be passed to this model. In general, the only limit on the size of batches passed to a FIL backend is the memory available with which to process them. \n",
+ "* **input:** Options in this section tell Triton the number of features to expect for each input sample.\n",
+ "* **output:** Options in this section tell Triton how many output values there will be for each sample. If the \"predict_proba\" option (described further on) is set to true, then a probability value will be returned for each class. Otherwise, a single value will be returned indicating the class predicted for the given sample.\n",
+ "* **instance_group:** This determines how many instances of this model will be created and whether they will use the GPU or CPU.\n",
+ "* **model_type:** A string indicating what format the model is in (\"xgboost_json\" in this example, but \"xgboost\", \"lightgbm\", and \"tl_checkpoint\" are valid formats as well).\n",
+ "* **predict_proba:** If set to true, probability values will be returned for each class rather than just a class prediction.\n",
+ "* **output_class:** True for classification models, false for regression models.\n",
+ "* **threshold:** A score threshold for determining classification. When output_class is set to true, this must be provided, although it will not be used if predict_proba is also set to true.\n",
+ "* **storage_type:** In general, using \"AUTO\" for this setting should meet most usecases. If \"AUTO\" storage is selected, FIL will load the model using either a sparse or dense representation based on the approximate size of the model. In some cases, you may want to explicitly set this to \"SPARSE\" in order to reduce the memory footprint of large models.\n",
+ "\n",
+ "Here we have 15 input features and 2 classes (FRAUD, NOT FRAUD) that we are doing classification for in our XGBoost Model. Based on this information, let's set up FIL Backend configuration file for our tree-based model for serving on GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af7e054c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "USE_GPU = True\n",
+ "FIL_MODEL_DIR = \"./model_repository/fil\"\n",
+ "\n",
+ "# Maximum size in bytes for input and output arrays. If you are\n",
+ "# using Triton 21.11 or higher, all memory allocations will make\n",
+ "# use of Triton's memory pool, which has a default size of\n",
+ "# 67_108_864 bytes\n",
+ "MAX_MEMORY_BYTES = 60_000_000\n",
+ "NUM_FEATURES = 15\n",
+ "NUM_CLASSES = 2\n",
+ "bytes_per_sample = (NUM_FEATURES + NUM_CLASSES) * 4\n",
+ "max_batch_size = MAX_MEMORY_BYTES // bytes_per_sample\n",
+ "\n",
+ "IS_CLASSIFIER = True\n",
+ "model_format = \"xgboost_json\"\n",
+ "\n",
+ "# Select deployment hardware (GPU or CPU)\n",
+ "if USE_GPU:\n",
+ " instance_kind = \"KIND_GPU\"\n",
+ "else:\n",
+ " instance_kind = \"KIND_CPU\"\n",
+ "\n",
+ "# whether the model is doing classification or regression\n",
+ "if IS_CLASSIFIER:\n",
+ " classifier_string = \"true\"\n",
+ "else:\n",
+ " classifier_string = \"false\"\n",
+ "\n",
+ "# whether to predict probabilites or not\n",
+ "predict_proba = False\n",
+ "\n",
+ "if predict_proba:\n",
+ " predict_proba_string = \"true\"\n",
+ "else:\n",
+ " predict_proba_string = \"false\"\n",
+ "\n",
+ "config_text = f\"\"\"backend: \"fil\"\n",
+ "max_batch_size: {max_batch_size}\n",
+ "input [ \n",
+ " {{ \n",
+ " name: \"input__0\"\n",
+ " data_type: TYPE_FP32\n",
+ " dims: [ {NUM_FEATURES} ] \n",
+ " }} \n",
+ "]\n",
+ "output [\n",
+ " {{\n",
+ " name: \"output__0\"\n",
+ " data_type: TYPE_FP32\n",
+ " dims: [ 1 ]\n",
+ " }}\n",
+ "]\n",
+ "instance_group [{{ kind: {instance_kind} }}]\n",
+ "parameters [\n",
+ " {{\n",
+ " key: \"model_type\"\n",
+ " value: {{ string_value: \"{model_format}\" }}\n",
+ " }},\n",
+ " {{\n",
+ " key: \"predict_proba\"\n",
+ " value: {{ string_value: \"{predict_proba_string}\" }}\n",
+ " }},\n",
+ " {{\n",
+ " key: \"output_class\"\n",
+ " value: {{ string_value: \"{classifier_string}\" }}\n",
+ " }},\n",
+ " {{\n",
+ " key: \"threshold\"\n",
+ " value: {{ string_value: \"0.5\" }}\n",
+ " }},\n",
+ " {{\n",
+ " key: \"storage_type\"\n",
+ " value: {{ string_value: \"AUTO\" }}\n",
+ " }}\n",
+ "]\n",
+ "\n",
+ "dynamic_batching {{}}\"\"\"\n",
+ "\n",
+ "config_path = os.path.join(FIL_MODEL_DIR, \"config.pbtxt\")\n",
+ "with open(config_path, \"w\") as file_:\n",
+ " file_.write(config_text)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9beceae2",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Set up Inference Pipeline of Data Preprocessing Python Backend and FIL Backend using Ensemble"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1855b520",
+ "metadata": {},
+ "source": [
+ "Now we are ready to set up the inference pipeline for data preprocessing and tree-based model inference using an [ensemble model](https://github.com/triton-inference-server/server/blob/main/docs/architecture.md#ensemble-models). An ensemble model represents a pipeline of one or more models and the connection of input and output tensors between those models. Here we use the ensemble model to build a pipeline of Data Preprocessing in Python backend followed by XGBoost in FIL Backend. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "34c04454",
+ "metadata": {},
+ "source": [
+ "The expected layout for `ensemble` model directory is similar to the ones we showed above:\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "facb89d4",
+ "metadata": {},
+ "source": [
+ "Here, `fil` is the name of the model. We can give it a different name like xgboost if we want to. `1` is the version sub-directory which contains the model artifact, in this case it's the `xgboost.json` model that we saved at the end of [first notebook](1_prep_rapids_train_xgb.ipynb). Let's create this expected layout."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af0a4ac2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# move saved xgboost model into fil model directory\n",
+ "!mkdir -p model_repository/fil/1\n",
+ "!cp xgboost.json model_repository/fil/1/"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3413e6eb",
+ "metadata": {},
+ "source": [
+ "And then finally we need to have configuration file `config.pbtxt` describing the model configuration for tree-based ML model so that FIL Backend in Triton can understand how to serve it."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "754f8c5d",
+ "metadata": {},
+ "source": [
+ "### Create Config File for FIL Backend Model"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e4c957cd",
+ "metadata": {},
+ "source": [
+ "You can read about all generic Triton configuration options [here](https://github.com/triton-inference-server/server/blob/master/docs/model_configuration.md) and about configuration options specific to the FIL backend [here](https://github.com/triton-inference-server/fil_backend#configuration), but we will focus on just a few of the most common and relevant options in this example. Below are general descriptions of these options:\n",
+ "\n",
+ "* **max_batch_size:** The maximum batch size that can be passed to this model. In general, the only limit on the size of batches passed to a FIL backend is the memory available with which to process them. \n",
+ "* **input:** Options in this section tell Triton the number of features to expect for each input sample.\n",
+ "* **output:** Options in this section tell Triton how many output values there will be for each sample. If the \"predict_proba\" option (described further on) is set to true, then a probability value will be returned for each class. Otherwise, a single value will be returned indicating the class predicted for the given sample.\n",
+ "* **instance_group:** This determines how many instances of this model will be created and whether they will use the GPU or CPU.\n",
+ "* **model_type:** A string indicating what format the model is in (\"xgboost_json\" in this example, but \"xgboost\", \"lightgbm\", and \"tl_checkpoint\" are valid formats as well).\n",
+ "* **predict_proba:** If set to true, probability values will be returned for each class rather than just a class prediction.\n",
+ "* **output_class:** True for classification models, false for regression models.\n",
+ "* **threshold:** A score threshold for determining classification. When output_class is set to true, this must be provided, although it will not be used if predict_proba is also set to true.\n",
+ "* **storage_type:** In general, using \"AUTO\" for this setting should meet most usecases. If \"AUTO\" storage is selected, FIL will load the model using either a sparse or dense representation based on the approximate size of the model. In some cases, you may want to explicitly set this to \"SPARSE\" in order to reduce the memory footprint of large models.\n",
+ "\n",
+ "Here we have 15 input features and 2 classes (FRAUD, NOT FRAUD) that we are doing classification for in our XGBoost Model. Based on this information, let's set up FIL Backend configuration file for our tree-based model for serving on GPU."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "af7e054c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "USE_GPU = True\n",
+ "FIL_MODEL_DIR = \"./model_repository/fil\"\n",
+ "\n",
+ "# Maximum size in bytes for input and output arrays. If you are\n",
+ "# using Triton 21.11 or higher, all memory allocations will make\n",
+ "# use of Triton's memory pool, which has a default size of\n",
+ "# 67_108_864 bytes\n",
+ "MAX_MEMORY_BYTES = 60_000_000\n",
+ "NUM_FEATURES = 15\n",
+ "NUM_CLASSES = 2\n",
+ "bytes_per_sample = (NUM_FEATURES + NUM_CLASSES) * 4\n",
+ "max_batch_size = MAX_MEMORY_BYTES // bytes_per_sample\n",
+ "\n",
+ "IS_CLASSIFIER = True\n",
+ "model_format = \"xgboost_json\"\n",
+ "\n",
+ "# Select deployment hardware (GPU or CPU)\n",
+ "if USE_GPU:\n",
+ " instance_kind = \"KIND_GPU\"\n",
+ "else:\n",
+ " instance_kind = \"KIND_CPU\"\n",
+ "\n",
+ "# whether the model is doing classification or regression\n",
+ "if IS_CLASSIFIER:\n",
+ " classifier_string = \"true\"\n",
+ "else:\n",
+ " classifier_string = \"false\"\n",
+ "\n",
+ "# whether to predict probabilites or not\n",
+ "predict_proba = False\n",
+ "\n",
+ "if predict_proba:\n",
+ " predict_proba_string = \"true\"\n",
+ "else:\n",
+ " predict_proba_string = \"false\"\n",
+ "\n",
+ "config_text = f\"\"\"backend: \"fil\"\n",
+ "max_batch_size: {max_batch_size}\n",
+ "input [ \n",
+ " {{ \n",
+ " name: \"input__0\"\n",
+ " data_type: TYPE_FP32\n",
+ " dims: [ {NUM_FEATURES} ] \n",
+ " }} \n",
+ "]\n",
+ "output [\n",
+ " {{\n",
+ " name: \"output__0\"\n",
+ " data_type: TYPE_FP32\n",
+ " dims: [ 1 ]\n",
+ " }}\n",
+ "]\n",
+ "instance_group [{{ kind: {instance_kind} }}]\n",
+ "parameters [\n",
+ " {{\n",
+ " key: \"model_type\"\n",
+ " value: {{ string_value: \"{model_format}\" }}\n",
+ " }},\n",
+ " {{\n",
+ " key: \"predict_proba\"\n",
+ " value: {{ string_value: \"{predict_proba_string}\" }}\n",
+ " }},\n",
+ " {{\n",
+ " key: \"output_class\"\n",
+ " value: {{ string_value: \"{classifier_string}\" }}\n",
+ " }},\n",
+ " {{\n",
+ " key: \"threshold\"\n",
+ " value: {{ string_value: \"0.5\" }}\n",
+ " }},\n",
+ " {{\n",
+ " key: \"storage_type\"\n",
+ " value: {{ string_value: \"AUTO\" }}\n",
+ " }}\n",
+ "]\n",
+ "\n",
+ "dynamic_batching {{}}\"\"\"\n",
+ "\n",
+ "config_path = os.path.join(FIL_MODEL_DIR, \"config.pbtxt\")\n",
+ "with open(config_path, \"w\") as file_:\n",
+ " file_.write(config_text)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9beceae2",
+ "metadata": {
+ "tags": []
+ },
+ "source": [
+ "## Set up Inference Pipeline of Data Preprocessing Python Backend and FIL Backend using Ensemble"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1855b520",
+ "metadata": {},
+ "source": [
+ "Now we are ready to set up the inference pipeline for data preprocessing and tree-based model inference using an [ensemble model](https://github.com/triton-inference-server/server/blob/main/docs/architecture.md#ensemble-models). An ensemble model represents a pipeline of one or more models and the connection of input and output tensors between those models. Here we use the ensemble model to build a pipeline of Data Preprocessing in Python backend followed by XGBoost in FIL Backend. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "34c04454",
+ "metadata": {},
+ "source": [
+ "The expected layout for `ensemble` model directory is similar to the ones we showed above:\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6274e1ed",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# create model version directory for ensemble model\n",
+ "!mkdir -p model_repository/ensemble/1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5061b0c4",
+ "metadata": {},
+ "source": [
+ "We created the ensemble model's [config.pbtxt](model_repository/ensemble/config.pbtxt) following the guidance on [ensemble doc](https://github.com/triton-inference-server/server/blob/main/docs/architecture.md#ensemble-models). Importantly, we need to set up the ensemble scheduler in config.pbtxt which specifies the dataflow between models within the ensemble. The ensemble scheduler collects the output tensors in each step, provides them as input tensors for other steps according to the specification."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "125319fc",
+ "metadata": {},
+ "source": [
+ "## Package model repository and upload to S3"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d770f25d",
+ "metadata": {},
+ "source": [
+ "Finally, we end up with the following model repository directory structure, containing a Python preprocessing model and its dependencies along with XGBoost FIL model, and the model ensemble.\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "6274e1ed",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# create model version directory for ensemble model\n",
+ "!mkdir -p model_repository/ensemble/1"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5061b0c4",
+ "metadata": {},
+ "source": [
+ "We created the ensemble model's [config.pbtxt](model_repository/ensemble/config.pbtxt) following the guidance on [ensemble doc](https://github.com/triton-inference-server/server/blob/main/docs/architecture.md#ensemble-models). Importantly, we need to set up the ensemble scheduler in config.pbtxt which specifies the dataflow between models within the ensemble. The ensemble scheduler collects the output tensors in each step, provides them as input tensors for other steps according to the specification."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "125319fc",
+ "metadata": {},
+ "source": [
+ "## Package model repository and upload to S3"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "d770f25d",
+ "metadata": {},
+ "source": [
+ "Finally, we end up with the following model repository directory structure, containing a Python preprocessing model and its dependencies along with XGBoost FIL model, and the model ensemble.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c286c251",
+ "metadata": {},
+ "source": [
+ "We will package this up as `model.tar.gz` for uploading it to S3."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b3b29ea0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!tar --exclude='.ipynb_checkpoints' -czvf model.tar.gz -C model_repository ."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7eacc699",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_uri = sagemaker_session.upload_data(path=\"model.tar.gz\", key_prefix=\"triton-fil-ensemble\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71c2ff3c",
+ "metadata": {},
+ "source": [
+ "## Create SageMaker Endpoint"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "294a69cb",
+ "metadata": {},
+ "source": [
+ "We start off by creating a SageMaker model from the model repository we uploaded to S3 in the previous step.\n",
+ "\n",
+ "In this step we also provide an additional Environment Variable `SAGEMAKER_TRITON_DEFAULT_MODEL_NAME` which specifies the name of the model to be loaded by Triton. **The value of this key should match the folder name in the model package uploaded to S3.** This variable is optional in case of a single model. In case of ensemble models, this **key has to be specified** for Triton to startup in SageMaker.\n",
+ "\n",
+ "Additionally, customers can set `SAGEMAKER_TRITON_BUFFER_MANAGER_THREAD_COUNT` and `SAGEMAKER_TRITON_THREAD_COUNT` for optimizing the thread counts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fb3c04ff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sm_model_name = \"triton-fil-ensemble-\" + time.strftime(\"%Y-%m-%d-%H-%M-%S\", time.gmtime())\n",
+ "\n",
+ "container = {\n",
+ " \"Image\": triton_image_uri,\n",
+ " \"ModelDataUrl\": model_uri,\n",
+ " \"Environment\": {\"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME\": \"ensemble\"},\n",
+ "}\n",
+ "\n",
+ "create_model_response = sm.create_model(\n",
+ " ModelName=sm_model_name, ExecutionRoleArn=role, PrimaryContainer=container\n",
+ ")\n",
+ "\n",
+ "print(\"Model Arn: \" + create_model_response[\"ModelArn\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3ee9ac31",
+ "metadata": {},
+ "source": [
+ "Using the model above, we create an endpoint configuration where we can specify the type and number of instances we want in the endpoint."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0be165b2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "endpoint_config_name = \"triton-fil-ensemble-\" + time.strftime(\"%Y-%m-%d-%H-%M-%S\", time.gmtime())\n",
+ "\n",
+ "create_endpoint_config_response = sm.create_endpoint_config(\n",
+ " EndpointConfigName=endpoint_config_name,\n",
+ " ProductionVariants=[\n",
+ " {\n",
+ " \"InstanceType\": \"ml.g4dn.4xlarge\",\n",
+ " \"InitialVariantWeight\": 1,\n",
+ " \"InitialInstanceCount\": 1,\n",
+ " \"ModelName\": sm_model_name,\n",
+ " \"VariantName\": \"AllTraffic\",\n",
+ " }\n",
+ " ],\n",
+ ")\n",
+ "\n",
+ "print(\"Endpoint Config Arn: \" + create_endpoint_config_response[\"EndpointConfigArn\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5e132d08",
+ "metadata": {},
+ "source": [
+ "Using the above endpoint configuration we create a new SageMaker endpoint and wait for the deployment to finish. The status will change to InService once the deployment is successful."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c8e48705",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "endpoint_name = \"triton-fil-ensemble-\" + time.strftime(\"%Y-%m-%d-%H-%M-%S\", time.gmtime())\n",
+ "\n",
+ "create_endpoint_response = sm.create_endpoint(\n",
+ " EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name\n",
+ ")\n",
+ "\n",
+ "print(\"Endpoint Arn: \" + create_endpoint_response[\"EndpointArn\"])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "635fd26f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "waiter = sm.get_waiter(\"endpoint_in_service\")\n",
+ "print(\"Waiting for endpoint to create...\")\n",
+ "waiter.wait(EndpointName=endpoint_name)\n",
+ "resp = sm.describe_endpoint(EndpointName=endpoint_name)\n",
+ "print(f\"Endpoint Status: {resp['EndpointStatus']}\")\n",
+ "\n",
+ "print(\"Arn: \" + resp[\"EndpointArn\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2d9c2761",
+ "metadata": {},
+ "source": [
+ "## Run Inference"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9c4be74a",
+ "metadata": {},
+ "source": [
+ "Once we have the endpoint running we can use some sample raw data to do an inference using json as the payload format. For the inference request format, Triton uses the KFServing community standard [inference protocols.](https://github.com/triton-inference-server/server/blob/main/docs/protocol/README.md)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "96fb73bf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data_infer = pd.read_csv(\"data_infer.csv\")\n",
+ "data_infer"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0749cedb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "STR_COLUMNS = [\n",
+ " \"Time\",\n",
+ " \"Amount\",\n",
+ " \"Zip\",\n",
+ " \"MCC\",\n",
+ " \"Merchant Name\",\n",
+ " \"Use Chip\",\n",
+ " \"Merchant City\",\n",
+ " \"Merchant State\",\n",
+ " \"Errors?\",\n",
+ "]\n",
+ "\n",
+ "batch_size = len(data_infer)\n",
+ "\n",
+ "payload = {}\n",
+ "payload[\"inputs\"] = []\n",
+ "data_dict = {}\n",
+ "for col_name in data_infer.columns:\n",
+ " data_dict[col_name] = {}\n",
+ " data_dict[col_name][\"name\"] = col_name\n",
+ " if col_name in STR_COLUMNS:\n",
+ " data_dict[col_name][\"data\"] = data_infer[col_name].astype(str).tolist()\n",
+ " data_dict[col_name][\"datatype\"] = \"BYTES\"\n",
+ " else:\n",
+ " data_dict[col_name][\"data\"] = data_infer[col_name].astype(\"float32\").tolist()\n",
+ " data_dict[col_name][\"datatype\"] = \"FP32\"\n",
+ " data_dict[col_name][\"shape\"] = [batch_size, 1]\n",
+ " payload[\"inputs\"].append(data_dict[col_name])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "94ca03cf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "response = client.invoke_endpoint(\n",
+ " EndpointName=endpoint_name, ContentType=\"application/octet-stream\", Body=json.dumps(payload)\n",
+ ")\n",
+ "\n",
+ "response_body = json.loads(response[\"Body\"].read().decode(\"utf8\"))\n",
+ "predictions = response_body[\"outputs\"][0][\"data\"]\n",
+ "\n",
+ "CLASS_LABELS = [\"NOT FRAUD\", \"FRAUD\"]\n",
+ "predictions = [CLASS_LABELS[int(idx)] for idx in predictions]\n",
+ "print(predictions)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a40cfcae",
+ "metadata": {},
+ "source": [
+ "### Binary + Json Payload"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f69eaf44",
+ "metadata": {},
+ "source": [
+ "We can also use binary+json as the payload format to get better performance for the inference call. The specification of this format is provided [here](https://github.com/triton-inference-server/server/blob/main/docs/protocol/extension_binary_data.md).\n",
+ "\n",
+ "**Note:** With the `binary+json` format, we have to specify the length of the request metadata in the header to allow Triton to correctly parse the binary payload. This is done using a custom Content-Type header `application/vnd.sagemaker-triton.binary+json;json-header-size={}`.\n",
+ "\n",
+ "Please note, this is different from using `Inference-Header-Content-Length` header on a stand-alone Triton server since custom headers are not allowed in SageMaker.\n",
+ "\n",
+ "The [tritonclient](https://github.com/triton-inference-server/client) package provides utility methods to generate the payload without having to know the details of the specification. We'll use the following methods to convert our inference request into a binary format which provides lower latencies for inference."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f38ef326",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import tritonclient.http as httpclient\n",
+ "\n",
+ "\n",
+ "def get_sample_data_binary(data, output_name):\n",
+ " inputs = []\n",
+ " outputs = []\n",
+ " batch_size = len(data)\n",
+ " for col_name in data.columns:\n",
+ " if col_name in STR_COLUMNS:\n",
+ " np_data = np.expand_dims(data[col_name], axis=1).astype(\"object\")\n",
+ " infer_input = httpclient.InferInput(col_name, [batch_size, 1], \"BYTES\")\n",
+ " else:\n",
+ " np_data = np.expand_dims(data[col_name], axis=1).astype(\"float32\")\n",
+ " infer_input = httpclient.InferInput(col_name, [batch_size, 1], \"FP32\")\n",
+ " infer_input.set_data_from_numpy(np_data, binary_data=True)\n",
+ " inputs.append(infer_input)\n",
+ " outputs.append(httpclient.InferRequestedOutput(output_name, binary_data=True))\n",
+ " request_body, header_length = httpclient.InferenceServerClient.generate_request_body(\n",
+ " inputs, outputs=outputs\n",
+ " )\n",
+ " return request_body, header_length"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1547f43c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "output_name = \"predictions\"\n",
+ "request_body, header_length = get_sample_data_binary(data_infer, output_name)\n",
+ "\n",
+ "response = client.invoke_endpoint(\n",
+ " EndpointName=endpoint_name,\n",
+ " ContentType=\"application/vnd.sagemaker-triton.binary+json;json-header-size={}\".format(\n",
+ " header_length\n",
+ " ),\n",
+ " Body=request_body,\n",
+ ")\n",
+ "\n",
+ "# Parse json header size length from the response\n",
+ "header_length_prefix = \"application/vnd.sagemaker-triton.binary+json;json-header-size=\"\n",
+ "header_length_str = response[\"ContentType\"][len(header_length_prefix) :]\n",
+ "\n",
+ "# Read response body\n",
+ "result = httpclient.InferenceServerClient.parse_response_body(\n",
+ " response[\"Body\"].read(), header_length=int(header_length_str)\n",
+ ")\n",
+ "predictions = result.as_numpy(output_name)\n",
+ "CLASS_LABELS = [\"NOT FRAUD\", \"FRAUD\"]\n",
+ "predictions = [CLASS_LABELS[int(idx)] for idx in predictions]\n",
+ "print(predictions)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7154ecdd",
+ "metadata": {},
+ "source": [
+ "## Terminate endpoint and clean up artifacts"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "03f60fd4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sm.delete_endpoint(EndpointName=endpoint_name)\n",
+ "sm.delete_endpoint_config(EndpointConfigName=endpoint_config_name)\n",
+ "sm.delete_model(ModelName=sm_model_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2b870fa3",
+ "metadata": {},
+ "source": [
+ "## Conclusion\n",
+ "\n",
+ "In this SageMaker example leveraging Triton Inference Server we walked through training an XGBoost model using RAPIDS for GPU acceleration during training. After creating the artifacts we leveraged Triton to create an ensemble to do Python preprocessing and used the XGBoost model to show how fraud can be detected using Triton and its corresponding Python and FIL backends. This example can further be used as a guide to create your own ensembles leveraging the other backends that Triton provides solving a wide variety of use cases that you may have that require scale and performance while using hardware for acceleration. "
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3.9.13 64-bit",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.13"
+ },
+ "vscode": {
+ "interpreter": {
+ "hash": "b0fa6594d8f4cbf19f97940f81e996739fb7646882a419484c72d19e05852a7e"
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/sagemaker-triton/fil_ensemble/README.md b/sagemaker-triton/fil_ensemble/README.md
new file mode 100644
index 0000000000..b5f26328e8
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/README.md
@@ -0,0 +1,19 @@
+# XGBoost model inference pipeline with NVIDIA Triton Inference Server on Amazon SageMaker
+
+In this example we show an end-to-end GPU-accelerated fraud detection example making use of tree-based models like XGBoost. In the first notebook [Data Preprocessing using RAPIDS and Training XGBoost for Fraud Detection](1_prep_rapids_train_xgb.ipynb) we demonstrate GPU-accelerated tabular data preprocessing using RAPIDS and training of XGBoost model for fraud detection on the GPU in SageMaker. Then in the second notebook [Pre-processing and XGBoost model inference pipeline with NVIDIA Triton Inference Server on Amazon SageMaker](2_triton_xgb_fil_ensemble.ipynb) we walk through the process of deploying data preprocessing and XGBoost model inference pipeline for high throughput, low-latency inference on Triton in SageMaker.
+
+## Steps to run the notebooks
+1. Launch SageMaker **notebook instance** with `g4dn.xlarge` instance. This example can also be run on a SageMaker **studio notebook instace** but the steps that follow will focus on the **notebook instance**.
+ - In **Additional Configuration** select `Create a new lifecycle configuration`. Specify `rapids-2106` as the name in Configuration Setting and copy paste the [on_start.sh](on_start.sh) script as the lifecycle configuration start notebook script. This will create the RAPIDS kernel for us to use inside SageMaker notebook.
+ * For those using AWS on Windows machine, because of the incompatibility between Windows and Unix formatted text, especially in end of line characters you will run into this [error](https://stackoverflow.com/questions/63361229/how-do-you-write-lifecycle-configurations-for-sagemaker-on-windows) if you copy paste [on_start.sh](on_start.sh) script. To prevent that use Notepad++ (or other text editor) to change end of line characters (CRLF to LF) in the [on_start.sh](on_start.sh) script.
+ 1. Click on Search > Replace (or Ctrl + H)
+ 2. Find what: \r\n.
+ 3. Replace with: \n.
+ 4. Search Mode: select Extended.
+ 5. Replace All. And then copy paste this into the AWS Lifecycle Configuration Start Notebook UI
+ - **IMPORTANT:** In Additional Configuration for **Volume Size in GB** specify at least **50 GB**.
+ - For git repositories select the option `Clone a public git repository to this notebook instance only` and specify the Git repository URL https://github.com/aws/amazon-sagemaker-examples/tree/main/sagemaker-triton/fil_ensemble
+
+2. Once JupyterLab is ready, launch the [1_prep_rapids_train_xgb.ipynb](1_prep_rapids_train_xgb.ipynb) notebook with `rapids-2106` conda kernel and run through this notebook to do GPU-accelerated data preprocessing and XGBoost training on credit card transactions dataset for fraud detection use-case. **Make sure to use the `rapids-2106` kernel for this notebook.**
+
+3. Launch the [2_triton_xgb_fil_ensemble.ipynb](2_triton_xgb_fil_ensemble.ipynb) notebook using `conda_python3` kernel (we don't use RAPIDS in this notebook). **Make sure to use the `conda_python3` kernel for this notebook.** Please note that this notebook requires that the [first notebook](1_prep_rapids_train_xgb.ipynb) be run to create the required dependencies. Run through this notebook to learn how to deploy the ensemble data preprocessing + XGBoost model inference pipeline using the Triton's Python and FIL Backends on Triton SageMaker `g4dn.xlarge` endpoint.
diff --git a/sagemaker-triton/fil_ensemble/create_prep_env.sh b/sagemaker-triton/fil_ensemble/create_prep_env.sh
new file mode 100644
index 0000000000..e17353d49a
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/create_prep_env.sh
@@ -0,0 +1,9 @@
+#!/bin/bash
+
+conda create -y -n preprocessing_env python=3.8
+source ~/anaconda3/etc/profile.d/conda.sh
+conda activate preprocessing_env
+export PYTHONNOUSERSITE=True
+conda install -y -c conda-forge pandas scikit-learn
+pip install conda-pack
+conda-pack
diff --git a/sagemaker-triton/fil_ensemble/images/ensemble_model.png b/sagemaker-triton/fil_ensemble/images/ensemble_model.png
new file mode 100644
index 0000000000..43788e10b5
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/ensemble_model.png differ
diff --git a/sagemaker-triton/fil_ensemble/images/fil_benchmark.png b/sagemaker-triton/fil_ensemble/images/fil_benchmark.png
new file mode 100644
index 0000000000..60713e74e1
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/fil_benchmark.png differ
diff --git a/sagemaker-triton/fil_ensemble/images/fil_model.png b/sagemaker-triton/fil_ensemble/images/fil_model.png
new file mode 100644
index 0000000000..db595b8250
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/fil_model.png differ
diff --git a/sagemaker-triton/fil_ensemble/images/model_repo.png b/sagemaker-triton/fil_ensemble/images/model_repo.png
new file mode 100644
index 0000000000..00f98ff4fc
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/model_repo.png differ
diff --git a/sagemaker-triton/fil_ensemble/images/preprocessing_model.png b/sagemaker-triton/fil_ensemble/images/preprocessing_model.png
new file mode 100644
index 0000000000..2b0946be36
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/preprocessing_model.png differ
diff --git a/sagemaker-triton/fil_ensemble/images/rapids.png b/sagemaker-triton/fil_ensemble/images/rapids.png
new file mode 100644
index 0000000000..b91131b3c4
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/rapids.png differ
diff --git a/sagemaker-triton/fil_ensemble/images/triton-ensemble.png b/sagemaker-triton/fil_ensemble/images/triton-ensemble.png
new file mode 100644
index 0000000000..32f5c1a6aa
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/triton-ensemble.png differ
diff --git a/sagemaker-triton/fil_ensemble/model_repository/ensemble/config.pbtxt b/sagemaker-triton/fil_ensemble/model_repository/ensemble/config.pbtxt
new file mode 100644
index 0000000000..397db68b6c
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/model_repository/ensemble/config.pbtxt
@@ -0,0 +1,162 @@
+name: "ensemble"
+platform: "ensemble"
+max_batch_size: 882352
+input [
+ {
+ name: "User"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Card"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Year"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Month"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Day"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Time"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Amount"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Use Chip"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Merchant Name"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Merchant City"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Merchant State"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Zip"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "MCC"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Errors?"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ }
+]
+output [
+ {
+ name: "predictions"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ }
+]
+ensemble_scheduling {
+ step [
+ {
+ model_name: "preprocessing"
+ model_version: 1
+ input_map {
+ key: "User"
+ value: "User"
+ }
+ input_map {
+ key: "Card"
+ value: "Card"
+ }
+ input_map {
+ key: "Year"
+ value: "Year"
+ }
+ input_map {
+ key: "Month"
+ value: "Month"
+ }
+ input_map {
+ key: "Day"
+ value: "Day"
+ }
+ input_map {
+ key: "Time"
+ value: "Time"
+ }
+ input_map {
+ key: "Amount"
+ value: "Amount"
+ }
+ input_map {
+ key: "Use Chip"
+ value: "Use Chip"
+ }
+ input_map {
+ key: "Merchant Name"
+ value: "Merchant Name"
+ }
+ input_map {
+ key: "Merchant City"
+ value: "Merchant City"
+ }
+ input_map {
+ key: "Merchant State"
+ value: "Merchant State"
+ }
+ input_map {
+ key: "Zip"
+ value: "Zip"
+ }
+ input_map {
+ key: "MCC"
+ value: "MCC"
+ }
+ input_map {
+ key: "Errors?"
+ value: "Errors?"
+ }
+ output_map {
+ key: "OUTPUT"
+ value: "preprocessed_data"
+ }
+ },
+ {
+ model_name: "fil"
+ model_version: 1
+ input_map {
+ key: "input__0"
+ value: "preprocessed_data"
+ }
+ output_map {
+ key: "output__0"
+ value: "predictions"
+ }
+ }
+ ]
+}
\ No newline at end of file
diff --git a/sagemaker-triton/fil_ensemble/model_repository/fil/config.pbtxt b/sagemaker-triton/fil_ensemble/model_repository/fil/config.pbtxt
new file mode 100644
index 0000000000..c831b6b4c0
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/model_repository/fil/config.pbtxt
@@ -0,0 +1,41 @@
+backend: "fil"
+max_batch_size: 882352
+input [
+ {
+ name: "input__0"
+ data_type: TYPE_FP32
+ dims: [ 15 ]
+ }
+]
+output [
+ {
+ name: "output__0"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ }
+]
+instance_group [{ kind: KIND_GPU }]
+parameters [
+ {
+ key: "model_type"
+ value: { string_value: "xgboost_json" }
+ },
+ {
+ key: "predict_proba"
+ value: { string_value: "false" }
+ },
+ {
+ key: "output_class"
+ value: { string_value: "true" }
+ },
+ {
+ key: "threshold"
+ value: { string_value: "0.5" }
+ },
+ {
+ key: "storage_type"
+ value: { string_value: "AUTO" }
+ }
+]
+
+dynamic_batching {}
\ No newline at end of file
diff --git a/sagemaker-triton/fil_ensemble/model_repository/preprocessing/1/model.py b/sagemaker-triton/fil_ensemble/model_repository/preprocessing/1/model.py
new file mode 100644
index 0000000000..2b573394b6
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/model_repository/preprocessing/1/model.py
@@ -0,0 +1,209 @@
+import pandas as pd
+import os
+import sklearn
+import triton_python_backend_utils as pb_utils
+from sklearn.preprocessing import LabelEncoder
+import numpy as np
+import json
+import pickle
+from pathlib import Path
+
+COLUMNS = [
+ "User",
+ "Card",
+ "Year",
+ "Month",
+ "Day",
+ "Time",
+ "Amount",
+ "Use Chip",
+ "Merchant Name",
+ "Merchant City",
+ "Merchant State",
+ "Zip",
+ "MCC",
+ "Errors?",
+]
+
+STR_COLUMNS = [
+ "Time",
+ "Amount",
+ "Zip",
+ "MCC",
+ "Merchant Name",
+ "Use Chip",
+ "Merchant City",
+ "Merchant State",
+ "Errors?",
+]
+
+ENCODE_COLUMNS = ["Zip", "MCC", "Merchant Name", "Use Chip", "Merchant City", "Merchant State"]
+
+us_states_plus_online = [
+ "AK",
+ "AL",
+ "AR",
+ "AZ",
+ "CA",
+ "CO",
+ "CT",
+ "DC",
+ "DE",
+ "FL",
+ "GA",
+ "HI",
+ "IA",
+ "ID",
+ "IL",
+ "IN",
+ "KS",
+ "KY",
+ "LA",
+ "MA",
+ "MD",
+ "ME",
+ "MI",
+ "MN",
+ "MO",
+ "MS",
+ "MT",
+ "NC",
+ "ND",
+ "NE",
+ "NH",
+ "NJ",
+ "NM",
+ "NV",
+ "NY",
+ "OH",
+ "OK",
+ "OR",
+ "PA",
+ "RI",
+ "SC",
+ "SD",
+ "TN",
+ "TX",
+ "UT",
+ "VA",
+ "VT",
+ "WA",
+ "WI",
+ "WV",
+ "WY",
+ "ONLINE",
+]
+
+LABEL_ENCODERS_FILE = "label_encoders.pkl"
+
+
+class TritonPythonModel:
+ """Your Python model must use the same class name. Every Python model
+ that is created must have "TritonPythonModel" as the class name.
+ """
+
+ def initialize(self, args):
+ """`initialize` is called only once when the model is being loaded.
+ Implementing `initialize` function is optional. This function allows
+ the model to intialize any state associated with this model.
+ Parameters
+ ----------
+ args : dict
+ Both keys and values are strings. The dictionary keys and values are:
+ * model_config: A JSON string containing the model configuration
+ * model_instance_kind: A string containing model instance kind
+ * model_instance_device_id: A string containing model instance device ID
+ * model_repository: Model repository path
+ * model_version: Model version
+ * model_name: Model name
+ """
+ # Parse model config
+
+ self.model_config = json.loads(args["model_config"])
+
+ output_config = pb_utils.get_output_config_by_name(self.model_config, "OUTPUT")
+
+ # Convert Triton types to numpy types
+ self.output_dtype = pb_utils.triton_string_to_numpy(output_config["data_type"])
+
+ cur_folder = Path(__file__).parent
+ with open(str(cur_folder / LABEL_ENCODERS_FILE), "rb") as f:
+ self.encoders = pickle.load(f)
+
+ def execute(self, requests):
+ """`execute` must be implemented in every Python model. `execute`
+ function receives a list of pb_utils.InferenceRequest as the only
+ argument. This function is called when an inference is requested
+ for this model. Depending on the batching configuration (e.g. Dynamic
+ Batching) used, `requests` may contain multiple requests. Every
+ Python model, must create one pb_utils.InferenceResponse for every
+ pb_utils.InferenceRequest in `requests`. If there is an error, you can
+ set the error argument when creating a pb_utils.InferenceResponse.
+ Parameters
+ ----------
+ requests : list
+ A list of pb_utils.InferenceRequest
+ Returns
+ -------
+ list
+ A list of pb_utils.InferenceResponse. The length of this list must
+ be the same as `requests`
+ """
+
+ responses = []
+
+ # Every Python backend must iterate over everyone of the requests
+ # and create a pb_utils.InferenceResponse for each of them.
+
+ for request in requests:
+ # Get input tensors
+ data_dict = {}
+ for col in COLUMNS:
+ data_dict[col] = (
+ pb_utils.get_input_tensor_by_name(request, col).as_numpy().squeeze(1)
+ )
+ if col in STR_COLUMNS:
+ data_dict[col] = data_dict[col].astype(str)
+ data = pd.DataFrame(data_dict)
+ data.loc[data["Merchant City"] == "ONLINE", "Merchant State"] = "ONLINE"
+ data.loc[data["Merchant City"] == "ONLINE", "Zip"] = "ONLINE"
+ data["Errors?"] = (data["Errors?"] != "nan").astype("float32")
+
+ data.loc[~data["Merchant State"].isin(us_states_plus_online), "Zip"] = "FOREIGN"
+ data["Amount"] = data["Amount"].str.slice(1)
+ data["Hour"] = data["Time"].str.slice(stop=2)
+ data["Minute"] = data["Time"].str.slice(start=3)
+ data.drop(columns=["Time"], inplace=True)
+
+ for col in ENCODE_COLUMNS:
+ le = LabelEncoder()
+ le.classes_ = self.encoders[col]
+ data[col] = le.transform(data[col])
+
+ # Create output tensors. You need pb_utils.Tensor
+ # objects to create pb_utils.InferenceResponse.
+
+ # FIL XGboost expects fp32 input
+ data_np = data.values.astype(self.output_dtype)
+ data_tensor = pb_utils.Tensor("OUTPUT", data_np)
+
+ # Create InferenceResponse. You can set an error here in case
+ # there was a problem with handling this inference request.
+ # Below is an example of how you can set errors in inference
+ # response:
+ #
+ # pb_utils.InferenceResponse(
+ # output_tensors=..., TritonError("An error occured"))
+ inference_response = pb_utils.InferenceResponse(output_tensors=[data_tensor])
+ responses.append(inference_response)
+
+ # You should return a list of pb_utils.InferenceResponse. Length
+ # of this list must match the length of `requests` list.
+ return responses
+
+ def finalize(self):
+ """`finalize` is called only once when the model is being unloaded.
+ Implementing `finalize` function is optional. This function allows
+ the model to perform any necessary clean ups before exit.
+ """
+ print("Cleaning up...")
diff --git a/sagemaker-triton/fil_ensemble/model_repository/preprocessing/config.pbtxt b/sagemaker-triton/fil_ensemble/model_repository/preprocessing/config.pbtxt
new file mode 100644
index 0000000000..b81ad52965
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/model_repository/preprocessing/config.pbtxt
@@ -0,0 +1,94 @@
+name: "preprocessing"
+backend: "python"
+max_batch_size: 882352
+input [
+ {
+ name: "User"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Card"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Year"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Month"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Day"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Time"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Amount"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Use Chip"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Merchant Name"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Merchant City"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Merchant State"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Zip"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "MCC"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Errors?"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ }
+
+]
+output [
+ {
+ name: "OUTPUT"
+ data_type: TYPE_FP32
+ dims: [ 15 ]
+ }
+]
+
+instance_group [
+ {
+ count: 1
+ kind: KIND_CPU
+ }
+]
+parameters: {
+ key: "EXECUTION_ENV_PATH",
+ value: {string_value: "$$TRITON_MODEL_DIRECTORY/preprocessing_env.tar.gz"}
+}
diff --git a/sagemaker-triton/fil_ensemble/on_start.sh b/sagemaker-triton/fil_ensemble/on_start.sh
new file mode 100644
index 0000000000..26d35a3ac5
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/on_start.sh
@@ -0,0 +1,19 @@
+#!/bin/bash
+
+set -e
+
+sudo -u ec2-user -i <<'EOF'
+
+mkdir -p rapids_kernel
+cd rapids_kernel
+wget -q https://rapidsai-data.s3.us-east-2.amazonaws.com/conda-pack/rapidsai/rapids21.06_cuda11.0_py3.8.tar.gz
+echo "wget completed"
+tar -xzf *.gz
+echo "unzip completed"
+source /home/ec2-user/rapids_kernel/bin/activate
+conda-unpack
+echo "unpack completed"
+python -m ipykernel install --user --name rapids-2106
+echo "kernel install completed"
+
+EOF
diff --git a/sagemaker_batch_transform/index.rst b/sagemaker_batch_transform/index.rst
index cd6b035981..2a75b11501 100644
--- a/sagemaker_batch_transform/index.rst
+++ b/sagemaker_batch_transform/index.rst
@@ -5,7 +5,7 @@ Get started with Batch Transform
:maxdepth: 1
introduction_to_batch_transform/batch_transform_pca_dbscan_movie_clusters
-
+ batch_transform_associate_predictions_with_input/Batch Transform - breast cancer prediction with lowel level SDK
..
file name change required
batch_transform_associate_predictions_with_input/Batch Transform - breast cancer prediction with high level SDK
@@ -61,4 +61,5 @@ TensorFlow
.. toctree::
:maxdepth: 1
- tensorflow_cifar-10_with_inference_script/tensorflow-serving-cifar10-python-sdk
+ tensorflow_cifar-10_with_inference_script/tensorflow-serving-cifar10-python-sdk
+ custom_tensorflow_inference_script_csv_and_tfrecord/custom_tensorflow_inference_script_csv_and_tfrecord
diff --git a/sagemaker_batch_transform/introduction_to_batch_transform/Dockerfile b/sagemaker_batch_transform/introduction_to_batch_transform/Dockerfile
index c72b3e416f..9509a739c4 100644
--- a/sagemaker_batch_transform/introduction_to_batch_transform/Dockerfile
+++ b/sagemaker_batch_transform/introduction_to_batch_transform/Dockerfile
@@ -6,9 +6,33 @@ RUN apt-get -y update && apt-get install -y --no-install-recommends \
wget \
r-base \
r-base-dev \
- ca-certificates
+ ca-certificates
-RUN R -e "install.packages(c('dbscan', 'plumber'), repos='https://cloud.r-project.org')"
+RUN R -e "install.packages(c('Rcpp', 'BH', 'R6', 'jsonlite', 'crayon'), repos='https://cloud.r-project.org')"
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/stringi/stringi_1.2.4.tar.gz
+RUN R CMD INSTALL stringi_1.2.4.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/rlang/rlang_0.2.2.tar.gz
+RUN R CMD INSTALL rlang_0.2.2.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/magrittr/magrittr_1.5.tar.gz
+RUN R CMD INSTALL magrittr_1.5.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/later/later_0.7.5.tar.gz
+RUN R CMD INSTALL later_0.7.5.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/promises/promises_1.0.1.tar.gz
+RUN R CMD INSTALL promises_1.0.1.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/httpuv/httpuv_1.4.4.2.tar.gz
+RUN R CMD INSTALL httpuv_1.4.4.2.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/dbscan/dbscan_1.1-2.tar.gz
+RUN R CMD INSTALL dbscan_1.1-2.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/plumber/plumber_0.4.6.tar.gz
+RUN R CMD INSTALL plumber_0.4.6.tar.gz
COPY dbscan.R /opt/ml/dbscan.R
COPY plumber.R /opt/ml/plumber.R
diff --git a/sagemaker_batch_transform/introduction_to_batch_transform/batch_transform_pca_dbscan_movie_clusters.ipynb b/sagemaker_batch_transform/introduction_to_batch_transform/batch_transform_pca_dbscan_movie_clusters.ipynb
index dab8931db9..420935fe05 100644
--- a/sagemaker_batch_transform/introduction_to_batch_transform/batch_transform_pca_dbscan_movie_clusters.ipynb
+++ b/sagemaker_batch_transform/introduction_to_batch_transform/batch_transform_pca_dbscan_movie_clusters.ipynb
@@ -261,7 +261,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Now, we'll setup to split our dataset into train and test. Dimensionality reduction and clustering don't always require a holdout set to test accuracy, but it will allow us to illustrate how batch prediction might be used when new data arrives. In this case, our test dataset will be a simple 10% sample of items."
+ "Now, we'll setup to split our dataset into train and test. Dimensionality reduction and clustering don't always require a holdout set to test accuracy, but it will allow us to illustrate how batch prediction might be used when new data arrives. In this case, our test dataset will be a simple 0.5% sample of items."
]
},
{
@@ -270,7 +270,7 @@
"metadata": {},
"outputs": [],
"source": [
- "test_products = products.sample(frac=0.1)\n",
+ "test_products = products.sample(frac=0.005)\n",
"train_products = products[~(products.index.isin(test_products.index))]"
]
},
diff --git a/sagemaker_batch_transform/introduction_to_batch_transform/dbscan.R b/sagemaker_batch_transform/introduction_to_batch_transform/dbscan.R
index c19cf3f5fe..7dba606c3f 100644
--- a/sagemaker_batch_transform/introduction_to_batch_transform/dbscan.R
+++ b/sagemaker_batch_transform/introduction_to_batch_transform/dbscan.R
@@ -69,7 +69,7 @@ parse_file <- function(file) {
# Second helper function for apply
parse_json <- function(line) {
if (validate(line)) {
- return(do.call(rbind, fromJSON(line)[['projections']][[1]]))}}
+ return(do.call(rbind, fromJSON(line)))}}
# Setup scoring function
diff --git a/sagemaker_batch_transform/introduction_to_batch_transform/plumber.R b/sagemaker_batch_transform/introduction_to_batch_transform/plumber.R
index 1a884f083c..6857c2e474 100644
--- a/sagemaker_batch_transform/introduction_to_batch_transform/plumber.R
+++ b/sagemaker_batch_transform/introduction_to_batch_transform/plumber.R
@@ -47,4 +47,4 @@ parse_file <- function(file) {
# Second helper function for apply
parse_json <- function(line) {
if (validate(line)) {
- return(do.call(rbind, fromJSON(line)[['projections']][[1]]))}}
+ return(do.call(rbind, fromJSON(line)))}}
diff --git a/sagemaker_batch_transform/tensorflow_open-images_tfrecord/tensorflow-serving-tfrecord.cli.ipynb b/sagemaker_batch_transform/tensorflow_open-images_tfrecord/tensorflow-serving-tfrecord.cli.ipynb
index 48f7427362..678a38c58c 100644
--- a/sagemaker_batch_transform/tensorflow_open-images_tfrecord/tensorflow-serving-tfrecord.cli.ipynb
+++ b/sagemaker_batch_transform/tensorflow_open-images_tfrecord/tensorflow-serving-tfrecord.cli.ipynb
@@ -270,7 +270,7 @@
"SPLIT_TYPE=\"TFRecord\"\n",
"BATCH_STRATEGY=\"SingleRecord\"\n",
"\n",
- "# Join outputs by newline characters. This will make JSONLines output, since each output is JSON.\n",
+ "# Join outputs by newline characters. This will make JSON Lines output, since each output is JSON.\n",
"ASSEMBLE_WITH=\"Line\"\n",
"\n",
"# The Data Source tells Batch to get all objects under the S3 prefix.\n",
diff --git a/sagemaker_batch_transform/working_with_tfrecords/working-with-tfrecords.ipynb b/sagemaker_batch_transform/working_with_tfrecords/working-with-tfrecords.ipynb
index ec20e480c9..ebe06ddfbe 100644
--- a/sagemaker_batch_transform/working_with_tfrecords/working-with-tfrecords.ipynb
+++ b/sagemaker_batch_transform/working_with_tfrecords/working-with-tfrecords.ipynb
@@ -50,7 +50,7 @@
"import sagemaker\n",
"import tensorflow as tf\n",
"\n",
- "bucket = \"
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c286c251",
+ "metadata": {},
+ "source": [
+ "We will package this up as `model.tar.gz` for uploading it to S3."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "b3b29ea0",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!tar --exclude='.ipynb_checkpoints' -czvf model.tar.gz -C model_repository ."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "7eacc699",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "model_uri = sagemaker_session.upload_data(path=\"model.tar.gz\", key_prefix=\"triton-fil-ensemble\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "71c2ff3c",
+ "metadata": {},
+ "source": [
+ "## Create SageMaker Endpoint"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "294a69cb",
+ "metadata": {},
+ "source": [
+ "We start off by creating a SageMaker model from the model repository we uploaded to S3 in the previous step.\n",
+ "\n",
+ "In this step we also provide an additional Environment Variable `SAGEMAKER_TRITON_DEFAULT_MODEL_NAME` which specifies the name of the model to be loaded by Triton. **The value of this key should match the folder name in the model package uploaded to S3.** This variable is optional in case of a single model. In case of ensemble models, this **key has to be specified** for Triton to startup in SageMaker.\n",
+ "\n",
+ "Additionally, customers can set `SAGEMAKER_TRITON_BUFFER_MANAGER_THREAD_COUNT` and `SAGEMAKER_TRITON_THREAD_COUNT` for optimizing the thread counts."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "fb3c04ff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sm_model_name = \"triton-fil-ensemble-\" + time.strftime(\"%Y-%m-%d-%H-%M-%S\", time.gmtime())\n",
+ "\n",
+ "container = {\n",
+ " \"Image\": triton_image_uri,\n",
+ " \"ModelDataUrl\": model_uri,\n",
+ " \"Environment\": {\"SAGEMAKER_TRITON_DEFAULT_MODEL_NAME\": \"ensemble\"},\n",
+ "}\n",
+ "\n",
+ "create_model_response = sm.create_model(\n",
+ " ModelName=sm_model_name, ExecutionRoleArn=role, PrimaryContainer=container\n",
+ ")\n",
+ "\n",
+ "print(\"Model Arn: \" + create_model_response[\"ModelArn\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3ee9ac31",
+ "metadata": {},
+ "source": [
+ "Using the model above, we create an endpoint configuration where we can specify the type and number of instances we want in the endpoint."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0be165b2",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "endpoint_config_name = \"triton-fil-ensemble-\" + time.strftime(\"%Y-%m-%d-%H-%M-%S\", time.gmtime())\n",
+ "\n",
+ "create_endpoint_config_response = sm.create_endpoint_config(\n",
+ " EndpointConfigName=endpoint_config_name,\n",
+ " ProductionVariants=[\n",
+ " {\n",
+ " \"InstanceType\": \"ml.g4dn.4xlarge\",\n",
+ " \"InitialVariantWeight\": 1,\n",
+ " \"InitialInstanceCount\": 1,\n",
+ " \"ModelName\": sm_model_name,\n",
+ " \"VariantName\": \"AllTraffic\",\n",
+ " }\n",
+ " ],\n",
+ ")\n",
+ "\n",
+ "print(\"Endpoint Config Arn: \" + create_endpoint_config_response[\"EndpointConfigArn\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "5e132d08",
+ "metadata": {},
+ "source": [
+ "Using the above endpoint configuration we create a new SageMaker endpoint and wait for the deployment to finish. The status will change to InService once the deployment is successful."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "c8e48705",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "endpoint_name = \"triton-fil-ensemble-\" + time.strftime(\"%Y-%m-%d-%H-%M-%S\", time.gmtime())\n",
+ "\n",
+ "create_endpoint_response = sm.create_endpoint(\n",
+ " EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name\n",
+ ")\n",
+ "\n",
+ "print(\"Endpoint Arn: \" + create_endpoint_response[\"EndpointArn\"])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "635fd26f",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "waiter = sm.get_waiter(\"endpoint_in_service\")\n",
+ "print(\"Waiting for endpoint to create...\")\n",
+ "waiter.wait(EndpointName=endpoint_name)\n",
+ "resp = sm.describe_endpoint(EndpointName=endpoint_name)\n",
+ "print(f\"Endpoint Status: {resp['EndpointStatus']}\")\n",
+ "\n",
+ "print(\"Arn: \" + resp[\"EndpointArn\"])"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2d9c2761",
+ "metadata": {},
+ "source": [
+ "## Run Inference"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9c4be74a",
+ "metadata": {},
+ "source": [
+ "Once we have the endpoint running we can use some sample raw data to do an inference using json as the payload format. For the inference request format, Triton uses the KFServing community standard [inference protocols.](https://github.com/triton-inference-server/server/blob/main/docs/protocol/README.md)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "96fb73bf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "data_infer = pd.read_csv(\"data_infer.csv\")\n",
+ "data_infer"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "0749cedb",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "STR_COLUMNS = [\n",
+ " \"Time\",\n",
+ " \"Amount\",\n",
+ " \"Zip\",\n",
+ " \"MCC\",\n",
+ " \"Merchant Name\",\n",
+ " \"Use Chip\",\n",
+ " \"Merchant City\",\n",
+ " \"Merchant State\",\n",
+ " \"Errors?\",\n",
+ "]\n",
+ "\n",
+ "batch_size = len(data_infer)\n",
+ "\n",
+ "payload = {}\n",
+ "payload[\"inputs\"] = []\n",
+ "data_dict = {}\n",
+ "for col_name in data_infer.columns:\n",
+ " data_dict[col_name] = {}\n",
+ " data_dict[col_name][\"name\"] = col_name\n",
+ " if col_name in STR_COLUMNS:\n",
+ " data_dict[col_name][\"data\"] = data_infer[col_name].astype(str).tolist()\n",
+ " data_dict[col_name][\"datatype\"] = \"BYTES\"\n",
+ " else:\n",
+ " data_dict[col_name][\"data\"] = data_infer[col_name].astype(\"float32\").tolist()\n",
+ " data_dict[col_name][\"datatype\"] = \"FP32\"\n",
+ " data_dict[col_name][\"shape\"] = [batch_size, 1]\n",
+ " payload[\"inputs\"].append(data_dict[col_name])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "94ca03cf",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "response = client.invoke_endpoint(\n",
+ " EndpointName=endpoint_name, ContentType=\"application/octet-stream\", Body=json.dumps(payload)\n",
+ ")\n",
+ "\n",
+ "response_body = json.loads(response[\"Body\"].read().decode(\"utf8\"))\n",
+ "predictions = response_body[\"outputs\"][0][\"data\"]\n",
+ "\n",
+ "CLASS_LABELS = [\"NOT FRAUD\", \"FRAUD\"]\n",
+ "predictions = [CLASS_LABELS[int(idx)] for idx in predictions]\n",
+ "print(predictions)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a40cfcae",
+ "metadata": {},
+ "source": [
+ "### Binary + Json Payload"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "f69eaf44",
+ "metadata": {},
+ "source": [
+ "We can also use binary+json as the payload format to get better performance for the inference call. The specification of this format is provided [here](https://github.com/triton-inference-server/server/blob/main/docs/protocol/extension_binary_data.md).\n",
+ "\n",
+ "**Note:** With the `binary+json` format, we have to specify the length of the request metadata in the header to allow Triton to correctly parse the binary payload. This is done using a custom Content-Type header `application/vnd.sagemaker-triton.binary+json;json-header-size={}`.\n",
+ "\n",
+ "Please note, this is different from using `Inference-Header-Content-Length` header on a stand-alone Triton server since custom headers are not allowed in SageMaker.\n",
+ "\n",
+ "The [tritonclient](https://github.com/triton-inference-server/client) package provides utility methods to generate the payload without having to know the details of the specification. We'll use the following methods to convert our inference request into a binary format which provides lower latencies for inference."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f38ef326",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import tritonclient.http as httpclient\n",
+ "\n",
+ "\n",
+ "def get_sample_data_binary(data, output_name):\n",
+ " inputs = []\n",
+ " outputs = []\n",
+ " batch_size = len(data)\n",
+ " for col_name in data.columns:\n",
+ " if col_name in STR_COLUMNS:\n",
+ " np_data = np.expand_dims(data[col_name], axis=1).astype(\"object\")\n",
+ " infer_input = httpclient.InferInput(col_name, [batch_size, 1], \"BYTES\")\n",
+ " else:\n",
+ " np_data = np.expand_dims(data[col_name], axis=1).astype(\"float32\")\n",
+ " infer_input = httpclient.InferInput(col_name, [batch_size, 1], \"FP32\")\n",
+ " infer_input.set_data_from_numpy(np_data, binary_data=True)\n",
+ " inputs.append(infer_input)\n",
+ " outputs.append(httpclient.InferRequestedOutput(output_name, binary_data=True))\n",
+ " request_body, header_length = httpclient.InferenceServerClient.generate_request_body(\n",
+ " inputs, outputs=outputs\n",
+ " )\n",
+ " return request_body, header_length"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "1547f43c",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "output_name = \"predictions\"\n",
+ "request_body, header_length = get_sample_data_binary(data_infer, output_name)\n",
+ "\n",
+ "response = client.invoke_endpoint(\n",
+ " EndpointName=endpoint_name,\n",
+ " ContentType=\"application/vnd.sagemaker-triton.binary+json;json-header-size={}\".format(\n",
+ " header_length\n",
+ " ),\n",
+ " Body=request_body,\n",
+ ")\n",
+ "\n",
+ "# Parse json header size length from the response\n",
+ "header_length_prefix = \"application/vnd.sagemaker-triton.binary+json;json-header-size=\"\n",
+ "header_length_str = response[\"ContentType\"][len(header_length_prefix) :]\n",
+ "\n",
+ "# Read response body\n",
+ "result = httpclient.InferenceServerClient.parse_response_body(\n",
+ " response[\"Body\"].read(), header_length=int(header_length_str)\n",
+ ")\n",
+ "predictions = result.as_numpy(output_name)\n",
+ "CLASS_LABELS = [\"NOT FRAUD\", \"FRAUD\"]\n",
+ "predictions = [CLASS_LABELS[int(idx)] for idx in predictions]\n",
+ "print(predictions)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "7154ecdd",
+ "metadata": {},
+ "source": [
+ "## Terminate endpoint and clean up artifacts"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "03f60fd4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "sm.delete_endpoint(EndpointName=endpoint_name)\n",
+ "sm.delete_endpoint_config(EndpointConfigName=endpoint_config_name)\n",
+ "sm.delete_model(ModelName=sm_model_name)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "2b870fa3",
+ "metadata": {},
+ "source": [
+ "## Conclusion\n",
+ "\n",
+ "In this SageMaker example leveraging Triton Inference Server we walked through training an XGBoost model using RAPIDS for GPU acceleration during training. After creating the artifacts we leveraged Triton to create an ensemble to do Python preprocessing and used the XGBoost model to show how fraud can be detected using Triton and its corresponding Python and FIL backends. This example can further be used as a guide to create your own ensembles leveraging the other backends that Triton provides solving a wide variety of use cases that you may have that require scale and performance while using hardware for acceleration. "
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3.9.13 64-bit",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.13"
+ },
+ "vscode": {
+ "interpreter": {
+ "hash": "b0fa6594d8f4cbf19f97940f81e996739fb7646882a419484c72d19e05852a7e"
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/sagemaker-triton/fil_ensemble/README.md b/sagemaker-triton/fil_ensemble/README.md
new file mode 100644
index 0000000000..b5f26328e8
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/README.md
@@ -0,0 +1,19 @@
+# XGBoost model inference pipeline with NVIDIA Triton Inference Server on Amazon SageMaker
+
+In this example we show an end-to-end GPU-accelerated fraud detection example making use of tree-based models like XGBoost. In the first notebook [Data Preprocessing using RAPIDS and Training XGBoost for Fraud Detection](1_prep_rapids_train_xgb.ipynb) we demonstrate GPU-accelerated tabular data preprocessing using RAPIDS and training of XGBoost model for fraud detection on the GPU in SageMaker. Then in the second notebook [Pre-processing and XGBoost model inference pipeline with NVIDIA Triton Inference Server on Amazon SageMaker](2_triton_xgb_fil_ensemble.ipynb) we walk through the process of deploying data preprocessing and XGBoost model inference pipeline for high throughput, low-latency inference on Triton in SageMaker.
+
+## Steps to run the notebooks
+1. Launch SageMaker **notebook instance** with `g4dn.xlarge` instance. This example can also be run on a SageMaker **studio notebook instace** but the steps that follow will focus on the **notebook instance**.
+ - In **Additional Configuration** select `Create a new lifecycle configuration`. Specify `rapids-2106` as the name in Configuration Setting and copy paste the [on_start.sh](on_start.sh) script as the lifecycle configuration start notebook script. This will create the RAPIDS kernel for us to use inside SageMaker notebook.
+ * For those using AWS on Windows machine, because of the incompatibility between Windows and Unix formatted text, especially in end of line characters you will run into this [error](https://stackoverflow.com/questions/63361229/how-do-you-write-lifecycle-configurations-for-sagemaker-on-windows) if you copy paste [on_start.sh](on_start.sh) script. To prevent that use Notepad++ (or other text editor) to change end of line characters (CRLF to LF) in the [on_start.sh](on_start.sh) script.
+ 1. Click on Search > Replace (or Ctrl + H)
+ 2. Find what: \r\n.
+ 3. Replace with: \n.
+ 4. Search Mode: select Extended.
+ 5. Replace All. And then copy paste this into the AWS Lifecycle Configuration Start Notebook UI
+ - **IMPORTANT:** In Additional Configuration for **Volume Size in GB** specify at least **50 GB**.
+ - For git repositories select the option `Clone a public git repository to this notebook instance only` and specify the Git repository URL https://github.com/aws/amazon-sagemaker-examples/tree/main/sagemaker-triton/fil_ensemble
+
+2. Once JupyterLab is ready, launch the [1_prep_rapids_train_xgb.ipynb](1_prep_rapids_train_xgb.ipynb) notebook with `rapids-2106` conda kernel and run through this notebook to do GPU-accelerated data preprocessing and XGBoost training on credit card transactions dataset for fraud detection use-case. **Make sure to use the `rapids-2106` kernel for this notebook.**
+
+3. Launch the [2_triton_xgb_fil_ensemble.ipynb](2_triton_xgb_fil_ensemble.ipynb) notebook using `conda_python3` kernel (we don't use RAPIDS in this notebook). **Make sure to use the `conda_python3` kernel for this notebook.** Please note that this notebook requires that the [first notebook](1_prep_rapids_train_xgb.ipynb) be run to create the required dependencies. Run through this notebook to learn how to deploy the ensemble data preprocessing + XGBoost model inference pipeline using the Triton's Python and FIL Backends on Triton SageMaker `g4dn.xlarge` endpoint.
diff --git a/sagemaker-triton/fil_ensemble/create_prep_env.sh b/sagemaker-triton/fil_ensemble/create_prep_env.sh
new file mode 100644
index 0000000000..e17353d49a
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/create_prep_env.sh
@@ -0,0 +1,9 @@
+#!/bin/bash
+
+conda create -y -n preprocessing_env python=3.8
+source ~/anaconda3/etc/profile.d/conda.sh
+conda activate preprocessing_env
+export PYTHONNOUSERSITE=True
+conda install -y -c conda-forge pandas scikit-learn
+pip install conda-pack
+conda-pack
diff --git a/sagemaker-triton/fil_ensemble/images/ensemble_model.png b/sagemaker-triton/fil_ensemble/images/ensemble_model.png
new file mode 100644
index 0000000000..43788e10b5
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/ensemble_model.png differ
diff --git a/sagemaker-triton/fil_ensemble/images/fil_benchmark.png b/sagemaker-triton/fil_ensemble/images/fil_benchmark.png
new file mode 100644
index 0000000000..60713e74e1
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/fil_benchmark.png differ
diff --git a/sagemaker-triton/fil_ensemble/images/fil_model.png b/sagemaker-triton/fil_ensemble/images/fil_model.png
new file mode 100644
index 0000000000..db595b8250
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/fil_model.png differ
diff --git a/sagemaker-triton/fil_ensemble/images/model_repo.png b/sagemaker-triton/fil_ensemble/images/model_repo.png
new file mode 100644
index 0000000000..00f98ff4fc
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/model_repo.png differ
diff --git a/sagemaker-triton/fil_ensemble/images/preprocessing_model.png b/sagemaker-triton/fil_ensemble/images/preprocessing_model.png
new file mode 100644
index 0000000000..2b0946be36
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/preprocessing_model.png differ
diff --git a/sagemaker-triton/fil_ensemble/images/rapids.png b/sagemaker-triton/fil_ensemble/images/rapids.png
new file mode 100644
index 0000000000..b91131b3c4
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/rapids.png differ
diff --git a/sagemaker-triton/fil_ensemble/images/triton-ensemble.png b/sagemaker-triton/fil_ensemble/images/triton-ensemble.png
new file mode 100644
index 0000000000..32f5c1a6aa
Binary files /dev/null and b/sagemaker-triton/fil_ensemble/images/triton-ensemble.png differ
diff --git a/sagemaker-triton/fil_ensemble/model_repository/ensemble/config.pbtxt b/sagemaker-triton/fil_ensemble/model_repository/ensemble/config.pbtxt
new file mode 100644
index 0000000000..397db68b6c
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/model_repository/ensemble/config.pbtxt
@@ -0,0 +1,162 @@
+name: "ensemble"
+platform: "ensemble"
+max_batch_size: 882352
+input [
+ {
+ name: "User"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Card"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Year"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Month"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Day"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Time"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Amount"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Use Chip"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Merchant Name"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Merchant City"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Merchant State"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Zip"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "MCC"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Errors?"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ }
+]
+output [
+ {
+ name: "predictions"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ }
+]
+ensemble_scheduling {
+ step [
+ {
+ model_name: "preprocessing"
+ model_version: 1
+ input_map {
+ key: "User"
+ value: "User"
+ }
+ input_map {
+ key: "Card"
+ value: "Card"
+ }
+ input_map {
+ key: "Year"
+ value: "Year"
+ }
+ input_map {
+ key: "Month"
+ value: "Month"
+ }
+ input_map {
+ key: "Day"
+ value: "Day"
+ }
+ input_map {
+ key: "Time"
+ value: "Time"
+ }
+ input_map {
+ key: "Amount"
+ value: "Amount"
+ }
+ input_map {
+ key: "Use Chip"
+ value: "Use Chip"
+ }
+ input_map {
+ key: "Merchant Name"
+ value: "Merchant Name"
+ }
+ input_map {
+ key: "Merchant City"
+ value: "Merchant City"
+ }
+ input_map {
+ key: "Merchant State"
+ value: "Merchant State"
+ }
+ input_map {
+ key: "Zip"
+ value: "Zip"
+ }
+ input_map {
+ key: "MCC"
+ value: "MCC"
+ }
+ input_map {
+ key: "Errors?"
+ value: "Errors?"
+ }
+ output_map {
+ key: "OUTPUT"
+ value: "preprocessed_data"
+ }
+ },
+ {
+ model_name: "fil"
+ model_version: 1
+ input_map {
+ key: "input__0"
+ value: "preprocessed_data"
+ }
+ output_map {
+ key: "output__0"
+ value: "predictions"
+ }
+ }
+ ]
+}
\ No newline at end of file
diff --git a/sagemaker-triton/fil_ensemble/model_repository/fil/config.pbtxt b/sagemaker-triton/fil_ensemble/model_repository/fil/config.pbtxt
new file mode 100644
index 0000000000..c831b6b4c0
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/model_repository/fil/config.pbtxt
@@ -0,0 +1,41 @@
+backend: "fil"
+max_batch_size: 882352
+input [
+ {
+ name: "input__0"
+ data_type: TYPE_FP32
+ dims: [ 15 ]
+ }
+]
+output [
+ {
+ name: "output__0"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ }
+]
+instance_group [{ kind: KIND_GPU }]
+parameters [
+ {
+ key: "model_type"
+ value: { string_value: "xgboost_json" }
+ },
+ {
+ key: "predict_proba"
+ value: { string_value: "false" }
+ },
+ {
+ key: "output_class"
+ value: { string_value: "true" }
+ },
+ {
+ key: "threshold"
+ value: { string_value: "0.5" }
+ },
+ {
+ key: "storage_type"
+ value: { string_value: "AUTO" }
+ }
+]
+
+dynamic_batching {}
\ No newline at end of file
diff --git a/sagemaker-triton/fil_ensemble/model_repository/preprocessing/1/model.py b/sagemaker-triton/fil_ensemble/model_repository/preprocessing/1/model.py
new file mode 100644
index 0000000000..2b573394b6
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/model_repository/preprocessing/1/model.py
@@ -0,0 +1,209 @@
+import pandas as pd
+import os
+import sklearn
+import triton_python_backend_utils as pb_utils
+from sklearn.preprocessing import LabelEncoder
+import numpy as np
+import json
+import pickle
+from pathlib import Path
+
+COLUMNS = [
+ "User",
+ "Card",
+ "Year",
+ "Month",
+ "Day",
+ "Time",
+ "Amount",
+ "Use Chip",
+ "Merchant Name",
+ "Merchant City",
+ "Merchant State",
+ "Zip",
+ "MCC",
+ "Errors?",
+]
+
+STR_COLUMNS = [
+ "Time",
+ "Amount",
+ "Zip",
+ "MCC",
+ "Merchant Name",
+ "Use Chip",
+ "Merchant City",
+ "Merchant State",
+ "Errors?",
+]
+
+ENCODE_COLUMNS = ["Zip", "MCC", "Merchant Name", "Use Chip", "Merchant City", "Merchant State"]
+
+us_states_plus_online = [
+ "AK",
+ "AL",
+ "AR",
+ "AZ",
+ "CA",
+ "CO",
+ "CT",
+ "DC",
+ "DE",
+ "FL",
+ "GA",
+ "HI",
+ "IA",
+ "ID",
+ "IL",
+ "IN",
+ "KS",
+ "KY",
+ "LA",
+ "MA",
+ "MD",
+ "ME",
+ "MI",
+ "MN",
+ "MO",
+ "MS",
+ "MT",
+ "NC",
+ "ND",
+ "NE",
+ "NH",
+ "NJ",
+ "NM",
+ "NV",
+ "NY",
+ "OH",
+ "OK",
+ "OR",
+ "PA",
+ "RI",
+ "SC",
+ "SD",
+ "TN",
+ "TX",
+ "UT",
+ "VA",
+ "VT",
+ "WA",
+ "WI",
+ "WV",
+ "WY",
+ "ONLINE",
+]
+
+LABEL_ENCODERS_FILE = "label_encoders.pkl"
+
+
+class TritonPythonModel:
+ """Your Python model must use the same class name. Every Python model
+ that is created must have "TritonPythonModel" as the class name.
+ """
+
+ def initialize(self, args):
+ """`initialize` is called only once when the model is being loaded.
+ Implementing `initialize` function is optional. This function allows
+ the model to intialize any state associated with this model.
+ Parameters
+ ----------
+ args : dict
+ Both keys and values are strings. The dictionary keys and values are:
+ * model_config: A JSON string containing the model configuration
+ * model_instance_kind: A string containing model instance kind
+ * model_instance_device_id: A string containing model instance device ID
+ * model_repository: Model repository path
+ * model_version: Model version
+ * model_name: Model name
+ """
+ # Parse model config
+
+ self.model_config = json.loads(args["model_config"])
+
+ output_config = pb_utils.get_output_config_by_name(self.model_config, "OUTPUT")
+
+ # Convert Triton types to numpy types
+ self.output_dtype = pb_utils.triton_string_to_numpy(output_config["data_type"])
+
+ cur_folder = Path(__file__).parent
+ with open(str(cur_folder / LABEL_ENCODERS_FILE), "rb") as f:
+ self.encoders = pickle.load(f)
+
+ def execute(self, requests):
+ """`execute` must be implemented in every Python model. `execute`
+ function receives a list of pb_utils.InferenceRequest as the only
+ argument. This function is called when an inference is requested
+ for this model. Depending on the batching configuration (e.g. Dynamic
+ Batching) used, `requests` may contain multiple requests. Every
+ Python model, must create one pb_utils.InferenceResponse for every
+ pb_utils.InferenceRequest in `requests`. If there is an error, you can
+ set the error argument when creating a pb_utils.InferenceResponse.
+ Parameters
+ ----------
+ requests : list
+ A list of pb_utils.InferenceRequest
+ Returns
+ -------
+ list
+ A list of pb_utils.InferenceResponse. The length of this list must
+ be the same as `requests`
+ """
+
+ responses = []
+
+ # Every Python backend must iterate over everyone of the requests
+ # and create a pb_utils.InferenceResponse for each of them.
+
+ for request in requests:
+ # Get input tensors
+ data_dict = {}
+ for col in COLUMNS:
+ data_dict[col] = (
+ pb_utils.get_input_tensor_by_name(request, col).as_numpy().squeeze(1)
+ )
+ if col in STR_COLUMNS:
+ data_dict[col] = data_dict[col].astype(str)
+ data = pd.DataFrame(data_dict)
+ data.loc[data["Merchant City"] == "ONLINE", "Merchant State"] = "ONLINE"
+ data.loc[data["Merchant City"] == "ONLINE", "Zip"] = "ONLINE"
+ data["Errors?"] = (data["Errors?"] != "nan").astype("float32")
+
+ data.loc[~data["Merchant State"].isin(us_states_plus_online), "Zip"] = "FOREIGN"
+ data["Amount"] = data["Amount"].str.slice(1)
+ data["Hour"] = data["Time"].str.slice(stop=2)
+ data["Minute"] = data["Time"].str.slice(start=3)
+ data.drop(columns=["Time"], inplace=True)
+
+ for col in ENCODE_COLUMNS:
+ le = LabelEncoder()
+ le.classes_ = self.encoders[col]
+ data[col] = le.transform(data[col])
+
+ # Create output tensors. You need pb_utils.Tensor
+ # objects to create pb_utils.InferenceResponse.
+
+ # FIL XGboost expects fp32 input
+ data_np = data.values.astype(self.output_dtype)
+ data_tensor = pb_utils.Tensor("OUTPUT", data_np)
+
+ # Create InferenceResponse. You can set an error here in case
+ # there was a problem with handling this inference request.
+ # Below is an example of how you can set errors in inference
+ # response:
+ #
+ # pb_utils.InferenceResponse(
+ # output_tensors=..., TritonError("An error occured"))
+ inference_response = pb_utils.InferenceResponse(output_tensors=[data_tensor])
+ responses.append(inference_response)
+
+ # You should return a list of pb_utils.InferenceResponse. Length
+ # of this list must match the length of `requests` list.
+ return responses
+
+ def finalize(self):
+ """`finalize` is called only once when the model is being unloaded.
+ Implementing `finalize` function is optional. This function allows
+ the model to perform any necessary clean ups before exit.
+ """
+ print("Cleaning up...")
diff --git a/sagemaker-triton/fil_ensemble/model_repository/preprocessing/config.pbtxt b/sagemaker-triton/fil_ensemble/model_repository/preprocessing/config.pbtxt
new file mode 100644
index 0000000000..b81ad52965
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/model_repository/preprocessing/config.pbtxt
@@ -0,0 +1,94 @@
+name: "preprocessing"
+backend: "python"
+max_batch_size: 882352
+input [
+ {
+ name: "User"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Card"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Year"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Month"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Day"
+ data_type: TYPE_FP32
+ dims: [ 1 ]
+ },
+ {
+ name: "Time"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Amount"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Use Chip"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Merchant Name"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Merchant City"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Merchant State"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Zip"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "MCC"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ },
+ {
+ name: "Errors?"
+ data_type: TYPE_STRING
+ dims: [ 1 ]
+ }
+
+]
+output [
+ {
+ name: "OUTPUT"
+ data_type: TYPE_FP32
+ dims: [ 15 ]
+ }
+]
+
+instance_group [
+ {
+ count: 1
+ kind: KIND_CPU
+ }
+]
+parameters: {
+ key: "EXECUTION_ENV_PATH",
+ value: {string_value: "$$TRITON_MODEL_DIRECTORY/preprocessing_env.tar.gz"}
+}
diff --git a/sagemaker-triton/fil_ensemble/on_start.sh b/sagemaker-triton/fil_ensemble/on_start.sh
new file mode 100644
index 0000000000..26d35a3ac5
--- /dev/null
+++ b/sagemaker-triton/fil_ensemble/on_start.sh
@@ -0,0 +1,19 @@
+#!/bin/bash
+
+set -e
+
+sudo -u ec2-user -i <<'EOF'
+
+mkdir -p rapids_kernel
+cd rapids_kernel
+wget -q https://rapidsai-data.s3.us-east-2.amazonaws.com/conda-pack/rapidsai/rapids21.06_cuda11.0_py3.8.tar.gz
+echo "wget completed"
+tar -xzf *.gz
+echo "unzip completed"
+source /home/ec2-user/rapids_kernel/bin/activate
+conda-unpack
+echo "unpack completed"
+python -m ipykernel install --user --name rapids-2106
+echo "kernel install completed"
+
+EOF
diff --git a/sagemaker_batch_transform/index.rst b/sagemaker_batch_transform/index.rst
index cd6b035981..2a75b11501 100644
--- a/sagemaker_batch_transform/index.rst
+++ b/sagemaker_batch_transform/index.rst
@@ -5,7 +5,7 @@ Get started with Batch Transform
:maxdepth: 1
introduction_to_batch_transform/batch_transform_pca_dbscan_movie_clusters
-
+ batch_transform_associate_predictions_with_input/Batch Transform - breast cancer prediction with lowel level SDK
..
file name change required
batch_transform_associate_predictions_with_input/Batch Transform - breast cancer prediction with high level SDK
@@ -61,4 +61,5 @@ TensorFlow
.. toctree::
:maxdepth: 1
- tensorflow_cifar-10_with_inference_script/tensorflow-serving-cifar10-python-sdk
+ tensorflow_cifar-10_with_inference_script/tensorflow-serving-cifar10-python-sdk
+ custom_tensorflow_inference_script_csv_and_tfrecord/custom_tensorflow_inference_script_csv_and_tfrecord
diff --git a/sagemaker_batch_transform/introduction_to_batch_transform/Dockerfile b/sagemaker_batch_transform/introduction_to_batch_transform/Dockerfile
index c72b3e416f..9509a739c4 100644
--- a/sagemaker_batch_transform/introduction_to_batch_transform/Dockerfile
+++ b/sagemaker_batch_transform/introduction_to_batch_transform/Dockerfile
@@ -6,9 +6,33 @@ RUN apt-get -y update && apt-get install -y --no-install-recommends \
wget \
r-base \
r-base-dev \
- ca-certificates
+ ca-certificates
-RUN R -e "install.packages(c('dbscan', 'plumber'), repos='https://cloud.r-project.org')"
+RUN R -e "install.packages(c('Rcpp', 'BH', 'R6', 'jsonlite', 'crayon'), repos='https://cloud.r-project.org')"
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/stringi/stringi_1.2.4.tar.gz
+RUN R CMD INSTALL stringi_1.2.4.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/rlang/rlang_0.2.2.tar.gz
+RUN R CMD INSTALL rlang_0.2.2.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/magrittr/magrittr_1.5.tar.gz
+RUN R CMD INSTALL magrittr_1.5.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/later/later_0.7.5.tar.gz
+RUN R CMD INSTALL later_0.7.5.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/promises/promises_1.0.1.tar.gz
+RUN R CMD INSTALL promises_1.0.1.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/httpuv/httpuv_1.4.4.2.tar.gz
+RUN R CMD INSTALL httpuv_1.4.4.2.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/dbscan/dbscan_1.1-2.tar.gz
+RUN R CMD INSTALL dbscan_1.1-2.tar.gz
+
+RUN wget http://cran.r-project.org/src/contrib/Archive/plumber/plumber_0.4.6.tar.gz
+RUN R CMD INSTALL plumber_0.4.6.tar.gz
COPY dbscan.R /opt/ml/dbscan.R
COPY plumber.R /opt/ml/plumber.R
diff --git a/sagemaker_batch_transform/introduction_to_batch_transform/batch_transform_pca_dbscan_movie_clusters.ipynb b/sagemaker_batch_transform/introduction_to_batch_transform/batch_transform_pca_dbscan_movie_clusters.ipynb
index dab8931db9..420935fe05 100644
--- a/sagemaker_batch_transform/introduction_to_batch_transform/batch_transform_pca_dbscan_movie_clusters.ipynb
+++ b/sagemaker_batch_transform/introduction_to_batch_transform/batch_transform_pca_dbscan_movie_clusters.ipynb
@@ -261,7 +261,7 @@
"cell_type": "markdown",
"metadata": {},
"source": [
- "Now, we'll setup to split our dataset into train and test. Dimensionality reduction and clustering don't always require a holdout set to test accuracy, but it will allow us to illustrate how batch prediction might be used when new data arrives. In this case, our test dataset will be a simple 10% sample of items."
+ "Now, we'll setup to split our dataset into train and test. Dimensionality reduction and clustering don't always require a holdout set to test accuracy, but it will allow us to illustrate how batch prediction might be used when new data arrives. In this case, our test dataset will be a simple 0.5% sample of items."
]
},
{
@@ -270,7 +270,7 @@
"metadata": {},
"outputs": [],
"source": [
- "test_products = products.sample(frac=0.1)\n",
+ "test_products = products.sample(frac=0.005)\n",
"train_products = products[~(products.index.isin(test_products.index))]"
]
},
diff --git a/sagemaker_batch_transform/introduction_to_batch_transform/dbscan.R b/sagemaker_batch_transform/introduction_to_batch_transform/dbscan.R
index c19cf3f5fe..7dba606c3f 100644
--- a/sagemaker_batch_transform/introduction_to_batch_transform/dbscan.R
+++ b/sagemaker_batch_transform/introduction_to_batch_transform/dbscan.R
@@ -69,7 +69,7 @@ parse_file <- function(file) {
# Second helper function for apply
parse_json <- function(line) {
if (validate(line)) {
- return(do.call(rbind, fromJSON(line)[['projections']][[1]]))}}
+ return(do.call(rbind, fromJSON(line)))}}
# Setup scoring function
diff --git a/sagemaker_batch_transform/introduction_to_batch_transform/plumber.R b/sagemaker_batch_transform/introduction_to_batch_transform/plumber.R
index 1a884f083c..6857c2e474 100644
--- a/sagemaker_batch_transform/introduction_to_batch_transform/plumber.R
+++ b/sagemaker_batch_transform/introduction_to_batch_transform/plumber.R
@@ -47,4 +47,4 @@ parse_file <- function(file) {
# Second helper function for apply
parse_json <- function(line) {
if (validate(line)) {
- return(do.call(rbind, fromJSON(line)[['projections']][[1]]))}}
+ return(do.call(rbind, fromJSON(line)))}}
diff --git a/sagemaker_batch_transform/tensorflow_open-images_tfrecord/tensorflow-serving-tfrecord.cli.ipynb b/sagemaker_batch_transform/tensorflow_open-images_tfrecord/tensorflow-serving-tfrecord.cli.ipynb
index 48f7427362..678a38c58c 100644
--- a/sagemaker_batch_transform/tensorflow_open-images_tfrecord/tensorflow-serving-tfrecord.cli.ipynb
+++ b/sagemaker_batch_transform/tensorflow_open-images_tfrecord/tensorflow-serving-tfrecord.cli.ipynb
@@ -270,7 +270,7 @@
"SPLIT_TYPE=\"TFRecord\"\n",
"BATCH_STRATEGY=\"SingleRecord\"\n",
"\n",
- "# Join outputs by newline characters. This will make JSONLines output, since each output is JSON.\n",
+ "# Join outputs by newline characters. This will make JSON Lines output, since each output is JSON.\n",
"ASSEMBLE_WITH=\"Line\"\n",
"\n",
"# The Data Source tells Batch to get all objects under the S3 prefix.\n",
diff --git a/sagemaker_batch_transform/working_with_tfrecords/working-with-tfrecords.ipynb b/sagemaker_batch_transform/working_with_tfrecords/working-with-tfrecords.ipynb
index ec20e480c9..ebe06ddfbe 100644
--- a/sagemaker_batch_transform/working_with_tfrecords/working-with-tfrecords.ipynb
+++ b/sagemaker_batch_transform/working_with_tfrecords/working-with-tfrecords.ipynb
@@ -50,7 +50,7 @@
"import sagemaker\n",
"import tensorflow as tf\n",
"\n",
- "bucket = \" \n",
+ "\n",
+ "Heterogeneous Training Job - Where we add ml.c5.9xlarge instance for extra CPU cores, to allow increased GPU usage of ml.p3.2xlarge instance, and improve cost-efficiency. Both the jobs runs the training code, train data set, pre-processing, and other relevant parameters.\n",
+ "
\n",
+ "\n",
+ "Heterogeneous Training Job - Where we add ml.c5.9xlarge instance for extra CPU cores, to allow increased GPU usage of ml.p3.2xlarge instance, and improve cost-efficiency. Both the jobs runs the training code, train data set, pre-processing, and other relevant parameters.\n",
+ " \n",
+ "\n",
+ "In homogeneous cluster training job, the data pre-processing and Deep Neural Network (DNN) training code runs on the same instance. However, in heterogeneous cluster training job, the data pre-processing code runs on the CPU nodes (here by referred as **data_group or data group**), whereas the Deep Neural Network (DNN) training code runs on the GPU nodes (here referred as **dnn_group or dnn group**). The inter-node communication between the data and dnn groups is handled by generic implementation of [gRPC client-server interface](https://grpc.io/docs/languages/python/basics/). \n",
+ "\n",
+ "The script (`launcher.py`) has the logic to detect (using SageMaker environment variables) whether the node it is running on belongs to data_group or dnn_group. If it is data_group, it spawns a separate process by executing `train_data.py`. This script runs grpc-server service for extracting processed training batches using [Protocol Buffers](https://developers.google.com/protocol-buffers/docs/overview). The gRPC server running on the data_group listens on a specific port (ex. 6000). In the code (`train_data.py`) documentation, we have chosen an implementation that keeps the data loading logic intact where data batches are entered into a shared queue. The `get_samples` function of the `DataFeedService` pulls batches from the same queue and sends them to the client in the form of a continuous data stream. While fetching the data, the main entrypoint script `launcher.py` listens on port 16000 for a shutdown request coming from gRPC client i.e. data group. The `train_data.py` waits for shutdown action from the parent process. \n",
+ "\n",
+ "If the node belongs to dnn_group, the main training script (`launcher.py`) spawns a separate set of processes by executing `train_dnn.py`. The script runs gRPC client code and DNN component of the training job. It consumes the processed training data from the gRPC server. We have defined an iterable PyTorch dataset, RemoteDataset, that opens a connection to the gRPC server, and reads from a stream of data batches. Once the model is trained with all the batches of training data, the gRPC client exits, and the parent process`launcher.py` sends a shutdown request on port 16000. This indicates the gRPC server to shutdown, and signals ends of the training job. \n",
+ "\n",
+ "Here is how the workflow looks like:\n",
+ "\n",
+ "
\n",
+ "\n",
+ "In homogeneous cluster training job, the data pre-processing and Deep Neural Network (DNN) training code runs on the same instance. However, in heterogeneous cluster training job, the data pre-processing code runs on the CPU nodes (here by referred as **data_group or data group**), whereas the Deep Neural Network (DNN) training code runs on the GPU nodes (here referred as **dnn_group or dnn group**). The inter-node communication between the data and dnn groups is handled by generic implementation of [gRPC client-server interface](https://grpc.io/docs/languages/python/basics/). \n",
+ "\n",
+ "The script (`launcher.py`) has the logic to detect (using SageMaker environment variables) whether the node it is running on belongs to data_group or dnn_group. If it is data_group, it spawns a separate process by executing `train_data.py`. This script runs grpc-server service for extracting processed training batches using [Protocol Buffers](https://developers.google.com/protocol-buffers/docs/overview). The gRPC server running on the data_group listens on a specific port (ex. 6000). In the code (`train_data.py`) documentation, we have chosen an implementation that keeps the data loading logic intact where data batches are entered into a shared queue. The `get_samples` function of the `DataFeedService` pulls batches from the same queue and sends them to the client in the form of a continuous data stream. While fetching the data, the main entrypoint script `launcher.py` listens on port 16000 for a shutdown request coming from gRPC client i.e. data group. The `train_data.py` waits for shutdown action from the parent process. \n",
+ "\n",
+ "If the node belongs to dnn_group, the main training script (`launcher.py`) spawns a separate set of processes by executing `train_dnn.py`. The script runs gRPC client code and DNN component of the training job. It consumes the processed training data from the gRPC server. We have defined an iterable PyTorch dataset, RemoteDataset, that opens a connection to the gRPC server, and reads from a stream of data batches. Once the model is trained with all the batches of training data, the gRPC client exits, and the parent process`launcher.py` sends a shutdown request on port 16000. This indicates the gRPC server to shutdown, and signals ends of the training job. \n",
+ "\n",
+ "Here is how the workflow looks like:\n",
+ "\n",
+ " \n",
+ "\n",
+ "This example notebook runs a training job on 2 instances, 1 in each node group. The data_group uses ml.c5.9xlarge whereas dnn_group uses ml.p3.2xlarge.\n",
+ "\n",
+ "This notebook refers following files and folders:\n",
+ "\n",
+ "- Folders: \n",
+ " - `code`: this has the training (data pre-processing and dnn) scripts, and grpc client-server start and shutdown scripts\n",
+ " - `images`: contains images referred in notebook\n",
+ "- Files: \n",
+ " - `launcher.py`: entry point training script. This script is executed on all the nodes irrespective of which group it belongs to. This is a parent process that makes a decision on where to spawn a data pre-processing or dnn component of the training job. The script runs on all the nodes as entry point. It also handles the shutdown logic for gRPC server. \n",
+ " - `train_data.py`, `dataset_feed_pb2.py`, `dataset_feed_pb2_grpc.py`: these scripts run on the data_group nodes and responsible for setting up grpc-server, start and shutdown.\n",
+ " - `train_dnn.py`: this script runs dnn code on the training data set. It fetches preprocessed data from the data_group node as a stream using gRPC client-server communication. It also sends a shutdown request after all the iterations on the preprocessed training data set. \n",
+ " - `requirement.txt`: defines package required for gRPC \n",
+ " - `train.py`: this script is the entry point script for SageMaker homogeneous cluster training. This script is picked up when you choose IS_HETERO = False. This uses a local dataset and runs both data pre-processing and a dnn component on the same node. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1f98cde9",
+ "metadata": {},
+ "source": [
+ "### security groups update if running in private VPC\n",
+ "This section is relevant if you plan to [run in a private VPC](https://docs.aws.amazon.com/sagemaker/latest/dg/train-vpc.html) (passing `subnets` and `security_group_ids` parameters when defining an Estimator). \n",
+ "SageMaker documentation recommends you [add](https://docs.aws.amazon.com/sagemaker/latest/dg/train-vpc.html#train-vpc-vpc) a rule for your security group that allows inbound connections between members of the same security group, for all TCP communication. This will also cover for the gRPC related traffic between instances:\n",
+ "- the data_group instances will listen on port 6000 for connections from all nodes. This stream is not encrypted. You can change the code to encrypted the connection if needed.\n",
+ "- the data_group intances listen on port 16000 for a shutdown signal from all nodes."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fd1e5aca",
+ "metadata": {},
+ "source": [
+ "### A. Setting up SageMaker Studio notebook\n",
+ "\n",
+ "#### Step 1 - Upgrade SageMaker SDK and dependent packages \n",
+ "Heterogeneous Clusters for Amazon SageMaker model training was [announced](https://aws.amazon.com/about-aws/whats-new/2022/07/announcing-heterogeneous-clusters-amazon-sagemaker-model-training) on 07/08/2022. As a first step, ensure you have updated SageMaker SDK, PyTorch, and Boto3 client that enables this feature."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 51,
+ "id": "54ff1687",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "python3 -m pip install --upgrade boto3 botocore awscli sagemaker"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0d20b2f3",
+ "metadata": {},
+ "source": [
+ "#### Step 2 - Restart the notebook kernel "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "229e1b18",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#import IPython\n",
+ "#IPython.Application.instance().kernel.do_shutdown(True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a9592cda",
+ "metadata": {},
+ "source": [
+ "#### Step 3 - Validate SageMaker Python SDK and PyTorch versions\n",
+ "Ensure the output of the cell below reflects:\n",
+ "\n",
+ "- SageMaker Python SDK version 2.98.0 or above, \n",
+ "- boto3 1.24 or above \n",
+ "- botocore 1.27 or above \n",
+ "- PyTorch 1.10 or above "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 52,
+ "id": "0b0e3202",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Name: sagemaker\n",
+ "Version: 2.109.0\n",
+ "---\n",
+ "Name: torch\n",
+ "Version: 1.10.2+cpu\n",
+ "---\n",
+ "Name: boto3\n",
+ "Version: 1.24.72\n",
+ "---\n",
+ "Name: botocore\n",
+ "Version: 1.27.72\n"
+ ]
+ }
+ ],
+ "source": [
+ "!pip show sagemaker torch boto3 botocore |egrep 'Name|Version|---'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9176d868",
+ "metadata": {},
+ "source": [
+ "--------------\n",
+ "### B. Setting up the Training environment\n",
+ "\n",
+ "#### Step 1 - Import SageMaker components and set up the IAM role and Amazon S3 bucket"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 53,
+ "id": "594fce53",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "arn:aws:iam::776941257690:role/service-role/AmazonSageMakerServiceCatalogProductsUseRole\n",
+ "s3://sagemaker-us-east-1-776941257690/DEMO-MNIST\n"
+ ]
+ }
+ ],
+ "source": [
+ "import os\n",
+ "import json\n",
+ "import datetime\n",
+ "import os\n",
+ "\n",
+ "import sagemaker\n",
+ "from sagemaker.pytorch import PyTorch\n",
+ "from sagemaker import get_execution_role\n",
+ "from sagemaker.instance_group import InstanceGroup\n",
+ "\n",
+ "\n",
+ "sess = sagemaker.Session()\n",
+ "\n",
+ "role = get_execution_role()\n",
+ "\n",
+ "output_path = \"s3://\" + sess.default_bucket() + \"/DEMO-MNIST\"\n",
+ "print(role)\n",
+ "print(output_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "165bca04",
+ "metadata": {},
+ "source": [
+ "#### Step 2 - Configure environment variables \n",
+ "This step defines whether you want to run training job in heterogeneous cluster mode or not. Also, defines instance groups, multiple nodes in group, and hyperparameter values. For baselining, run a homogeneous cluster training job by setting `IS_HETERO = False`. This will let both the data pre-processing and DNN code run on the same node i.e. `ml.p3.2xlarge`. \n",
+ "\n",
+ "\n",
+ "Test configuration (if running training on p3.2xl or g5.2xl as dnn_group instance type, and c5.2xl as data_group instance type: (training duration: 7-8 mins) \n",
+ "`num-data-workers: 4` \n",
+ "`grpc-workers: 4` \n",
+ "`num-dnn-workers: 4` \n",
+ "`pin-memory\": True` \n",
+ "`iterations : 100` \n",
+ "\n",
+ "Performance configuration (if running training on p3.2xl as dnn_group instance type, and c5.9xl as data_group instance type OR training in homogeneous cluster mode i.e. g5.8xl): (training duration - 30 mins) \n",
+ "`num-data-workers: 32` \n",
+ "`grpc-workers: 2` \n",
+ "`num-dnn-workers: 2` \n",
+ "`pin-memory\": True` \n",
+ "`iterations : 4800`\n",
+ "\n",
+ "Performance configuration (if running training on p3.2xl in homogeneous cluster mode): \n",
+ "`num-data-workers: 8` \n",
+ "`grpc-workers: 2` \n",
+ "`num-dnn-workers: 2` \n",
+ "`pin-memory\": True` \n",
+ "`iterations : 2400`\n",
+ "\n",
+ "Note: This PyTorch example has not been tested with multiple instances in an instance group. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 54,
+ "id": "0d65707b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "IS_CLOUD_JOB = True\n",
+ "IS_HETERO = True # if set to false, uses homogeneous cluster\n",
+ "PT_DATA_MODE = \"service\" if IS_HETERO else \"local\" # local | service\n",
+ "IS_DNN_DISTRIBUTION = False # Distributed Training with DNN nodes not tested, set it to False\n",
+ "\n",
+ "data_group = InstanceGroup(\n",
+ " \"data_group\", \"ml.c5.9xlarge\", 1\n",
+ ") # 36 vCPU #change the instance type if IS_HETERO=True\n",
+ "dnn_group = InstanceGroup(\n",
+ " \"dnn_group\", \"ml.p3.2xlarge\", 1\n",
+ ") # 8 vCPU #change the instance type if IS_HETERO=True\n",
+ "\n",
+ "kwargs = dict()\n",
+ "kwargs[\"hyperparameters\"] = {\n",
+ " \"batch-size\": 8192,\n",
+ " \"num-data-workers\": 4, # This number drives the avg. step time. More workers help parallel pre-processing of data. Recommendation: Total no. of cpu 'n' = 'num-data-wokers'+'grpc-workers'+ 2 (reserved)\n",
+ " \"grpc-workers\": 4, # No. of workers serving pre-processed data to DNN group (gRPC client). see above formula.\n",
+ " \"num-dnn-workers\": 4, # Modify this no. to be less than the cpu core of your training instances in dnn group\n",
+ " \"pin-memory\": True, # Pin to GPU memory\n",
+ " \"iterations\": 100, # No. of iterations in an epoch (must be multiple of 10).\n",
+ "}\n",
+ "\n",
+ "if IS_HETERO:\n",
+ " kwargs[\"instance_groups\"] = [data_group, dnn_group]\n",
+ " entry_point = \"launcher.py\"\n",
+ "else:\n",
+ " kwargs[\"instance_type\"] = (\n",
+ " \"ml.p3.2xlarge\" if IS_CLOUD_JOB else \"local\"\n",
+ " ) # change the instance type if IS_HETERO=False\n",
+ " kwargs[\"instance_count\"] = 1\n",
+ " entry_point = \"train.py\"\n",
+ "\n",
+ "if IS_DNN_DISTRIBUTION:\n",
+ " processes_per_host_dict = {\n",
+ " \"ml.g5.xlarge\": 1,\n",
+ " \"ml.g5.12xlarge\": 4,\n",
+ " \"ml.p3.8xlarge\": 4,\n",
+ " \"ml.p4d.24xlarge\": 8,\n",
+ " }\n",
+ " kwargs[\"distribution\"] = {\n",
+ " \"mpi\": {\n",
+ " \"enabled\": True,\n",
+ " \"processes_per_host\": processes_per_host_dict[dnn_instance_type],\n",
+ " \"custom_mpi_options\": \"--NCCL_DEBUG INFO\",\n",
+ " },\n",
+ " }\n",
+ " if IS_HETERO:\n",
+ " kwargs[\"distribution\"][\"instance_groups\"] = [dnn_group]\n",
+ "\n",
+ " print(f\"distribution={kwargs['distribution']}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4ff19e24",
+ "metadata": {},
+ "source": [
+ "#### Step 3: Set up the Estimator\n",
+ "In order to use SageMaker to fit our algorithm, we'll create `Estimator` that defines how to use the container to train. This includes the configuration we need to invoke SageMaker training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 55,
+ "id": "94f4c8ce",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "estimator = PyTorch(\n",
+ " framework_version=\"1.11.0\", # 1.10.0 or later\n",
+ " py_version=\"py38\", # Python v3.8\n",
+ " role=role,\n",
+ " entry_point=entry_point,\n",
+ " source_dir=\"code\",\n",
+ " volume_size=10,\n",
+ " max_run=4800,\n",
+ " disable_profiler=True,\n",
+ " debugger_hook_config=False,\n",
+ " **kwargs,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a81dcab6",
+ "metadata": {},
+ "source": [
+ "#### Step 4: Download the MNIST Data and Upload it to S3 bucket\n",
+ "\n",
+ "This is an optional step for now. The training job downloads the data on its run directly from MNIST website to the data_group node (grpc server). "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 56,
+ "id": "d0534973",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import boto3\n",
+ "from botocore.exceptions import ClientError\n",
+ "\n",
+ "# Download training and testing data from a public S3 bucket\n",
+ "\n",
+ "\n",
+ "def download_from_s3(data_dir=\"./data\", train=True):\n",
+ " \"\"\"Download MNIST dataset and convert it to numpy array\n",
+ "\n",
+ " Args:\n",
+ " data_dir (str): directory to save the data\n",
+ " train (bool): download training set\n",
+ "\n",
+ " Returns:\n",
+ " None\n",
+ " \"\"\"\n",
+ "\n",
+ " if not os.path.exists(data_dir):\n",
+ " os.makedirs(data_dir)\n",
+ "\n",
+ " if train:\n",
+ " images_file = \"train-images-idx3-ubyte.gz\"\n",
+ " labels_file = \"train-labels-idx1-ubyte.gz\"\n",
+ " else:\n",
+ " images_file = \"t10k-images-idx3-ubyte.gz\"\n",
+ " labels_file = \"t10k-labels-idx1-ubyte.gz\"\n",
+ "\n",
+ " # download objects\n",
+ " s3 = boto3.client(\"s3\")\n",
+ " bucket = f\"sagemaker-sample-files\"\n",
+ " for obj in [images_file, labels_file]:\n",
+ " key = os.path.join(\"datasets/image/MNIST\", obj)\n",
+ " dest = os.path.join(data_dir, obj)\n",
+ " if not os.path.exists(dest):\n",
+ " s3.download_file(bucket, key, dest)\n",
+ " return\n",
+ "\n",
+ "\n",
+ "download_from_s3(\"./data\", True)\n",
+ "download_from_s3(\"./data\", False)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 57,
+ "id": "2d699654",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Upload to the default bucket\n",
+ "\n",
+ "prefix = \"DEMO-MNIST\"\n",
+ "bucket = sess.default_bucket()\n",
+ "loc = sess.upload_data(path=\"./data\", bucket=bucket, key_prefix=prefix)\n",
+ "\n",
+ "channels = {\"training\": loc, \"testing\": loc}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "48352f04",
+ "metadata": {},
+ "source": [
+ "## C. Submit the training job\n",
+ "\n",
+ "The job runs for the predefined iterations. DNN instance group sends a shutdown request to data group after done with the training. You can see the following entries in the CloudWatch logs of dnn instance. A job with 4800 iterations finishes in 29 mins in a Heterogeneous cluster composed of 1x ml.c5.9xlarge as data node and 1x ml.p3.2xlarge as DNN node.\n",
+ "\n",
+ "Note: The console output of billing seconds can be ignored. See the AWS console > SageMaker > Training Job for the exact billing seconds.\n",
+ "\n",
+ "Log excerpt from algo-1 (DNN instance)\n",
+ "```\n",
+ "4780: avg step time: 0.19709917231025106\n",
+ "INFO:__main__:4780: avg step time: 0.19709917231025106\n",
+ "4790: avg step time: 0.19694106239373696\n",
+ "INFO:__main__:4790: avg step time: 0.19694106239373696\n",
+ "4800: avg step time: 0.196784295383125\n",
+ "Saving the model\n",
+ "INFO:__main__:4800: avg step time: 0.196784295383125\n",
+ "INFO:__main__:Saving the model\n",
+ "Training job completed!\n",
+ "INFO:__main__:Training job completed!\n",
+ "Process train_dnn.py closed with returncode=0\n",
+ "Shutting downdata service dispatcher via: [algo-2:16000]\n",
+ "shutdown request sent to algo-2:16000\n",
+ "2022-08-16 01:15:05,555 sagemaker-training-toolkit INFO Waiting for the process to finish and give a return code.\n",
+ "2022-08-16 01:15:05,555 sagemaker-training-toolkit INFO Done waiting for a return code. Received 0 from exiting process.\n",
+ "2022-08-16 01:15:05,556 sagemaker-training-toolkit INFO Reporting training SUCCESS\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "31cb6cae",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "2022-09-15 00:55:22 Starting - Starting the training job...\n",
+ "2022-09-15 00:55:50 Starting - Preparing the instances for training.........\n",
+ "2022-09-15 00:57:10 Downloading - Downloading input data.."
+ ]
+ }
+ ],
+ "source": [
+ "estimator.fit(\n",
+ " inputs=channels,\n",
+ " job_name=\"pt-hetero\"\n",
+ " + \"-\"\n",
+ " + \"H-\"\n",
+ " + str(IS_HETERO)[0]\n",
+ " + \"-\"\n",
+ " + datetime.datetime.utcnow().strftime(\"%Y%m%dT%H%M%SZ\"),\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3ea2e092",
+ "metadata": {},
+ "source": [
+ "## D. Monitoring Instance Metrics for GPU and CPU utilization\n",
+ "\n",
+ "Click on **View instance metrics** from the **Training jobs** node in **Amazon SageMaker Console**. In the run above, all 30 vCPU of Data node (algo-1) is approx. 100% utilized, and the GPU utilization is at 100% at frequent intervals in the DNN node (algo-2). To rescale the CloudWatch Metrics to 100% on CPU utilization for algo-1 and algo-2, use CloudWatch \"Add Math\" feature and average it out by no. of cores on those instance types.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "This example notebook runs a training job on 2 instances, 1 in each node group. The data_group uses ml.c5.9xlarge whereas dnn_group uses ml.p3.2xlarge.\n",
+ "\n",
+ "This notebook refers following files and folders:\n",
+ "\n",
+ "- Folders: \n",
+ " - `code`: this has the training (data pre-processing and dnn) scripts, and grpc client-server start and shutdown scripts\n",
+ " - `images`: contains images referred in notebook\n",
+ "- Files: \n",
+ " - `launcher.py`: entry point training script. This script is executed on all the nodes irrespective of which group it belongs to. This is a parent process that makes a decision on where to spawn a data pre-processing or dnn component of the training job. The script runs on all the nodes as entry point. It also handles the shutdown logic for gRPC server. \n",
+ " - `train_data.py`, `dataset_feed_pb2.py`, `dataset_feed_pb2_grpc.py`: these scripts run on the data_group nodes and responsible for setting up grpc-server, start and shutdown.\n",
+ " - `train_dnn.py`: this script runs dnn code on the training data set. It fetches preprocessed data from the data_group node as a stream using gRPC client-server communication. It also sends a shutdown request after all the iterations on the preprocessed training data set. \n",
+ " - `requirement.txt`: defines package required for gRPC \n",
+ " - `train.py`: this script is the entry point script for SageMaker homogeneous cluster training. This script is picked up when you choose IS_HETERO = False. This uses a local dataset and runs both data pre-processing and a dnn component on the same node. "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "1f98cde9",
+ "metadata": {},
+ "source": [
+ "### security groups update if running in private VPC\n",
+ "This section is relevant if you plan to [run in a private VPC](https://docs.aws.amazon.com/sagemaker/latest/dg/train-vpc.html) (passing `subnets` and `security_group_ids` parameters when defining an Estimator). \n",
+ "SageMaker documentation recommends you [add](https://docs.aws.amazon.com/sagemaker/latest/dg/train-vpc.html#train-vpc-vpc) a rule for your security group that allows inbound connections between members of the same security group, for all TCP communication. This will also cover for the gRPC related traffic between instances:\n",
+ "- the data_group instances will listen on port 6000 for connections from all nodes. This stream is not encrypted. You can change the code to encrypted the connection if needed.\n",
+ "- the data_group intances listen on port 16000 for a shutdown signal from all nodes."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "fd1e5aca",
+ "metadata": {},
+ "source": [
+ "### A. Setting up SageMaker Studio notebook\n",
+ "\n",
+ "#### Step 1 - Upgrade SageMaker SDK and dependent packages \n",
+ "Heterogeneous Clusters for Amazon SageMaker model training was [announced](https://aws.amazon.com/about-aws/whats-new/2022/07/announcing-heterogeneous-clusters-amazon-sagemaker-model-training) on 07/08/2022. As a first step, ensure you have updated SageMaker SDK, PyTorch, and Boto3 client that enables this feature."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 51,
+ "id": "54ff1687",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "%%bash\n",
+ "python3 -m pip install --upgrade boto3 botocore awscli sagemaker"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "0d20b2f3",
+ "metadata": {},
+ "source": [
+ "#### Step 2 - Restart the notebook kernel "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "229e1b18",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#import IPython\n",
+ "#IPython.Application.instance().kernel.do_shutdown(True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a9592cda",
+ "metadata": {},
+ "source": [
+ "#### Step 3 - Validate SageMaker Python SDK and PyTorch versions\n",
+ "Ensure the output of the cell below reflects:\n",
+ "\n",
+ "- SageMaker Python SDK version 2.98.0 or above, \n",
+ "- boto3 1.24 or above \n",
+ "- botocore 1.27 or above \n",
+ "- PyTorch 1.10 or above "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 52,
+ "id": "0b0e3202",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Name: sagemaker\n",
+ "Version: 2.109.0\n",
+ "---\n",
+ "Name: torch\n",
+ "Version: 1.10.2+cpu\n",
+ "---\n",
+ "Name: boto3\n",
+ "Version: 1.24.72\n",
+ "---\n",
+ "Name: botocore\n",
+ "Version: 1.27.72\n"
+ ]
+ }
+ ],
+ "source": [
+ "!pip show sagemaker torch boto3 botocore |egrep 'Name|Version|---'"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "9176d868",
+ "metadata": {},
+ "source": [
+ "--------------\n",
+ "### B. Setting up the Training environment\n",
+ "\n",
+ "#### Step 1 - Import SageMaker components and set up the IAM role and Amazon S3 bucket"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 53,
+ "id": "594fce53",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "arn:aws:iam::776941257690:role/service-role/AmazonSageMakerServiceCatalogProductsUseRole\n",
+ "s3://sagemaker-us-east-1-776941257690/DEMO-MNIST\n"
+ ]
+ }
+ ],
+ "source": [
+ "import os\n",
+ "import json\n",
+ "import datetime\n",
+ "import os\n",
+ "\n",
+ "import sagemaker\n",
+ "from sagemaker.pytorch import PyTorch\n",
+ "from sagemaker import get_execution_role\n",
+ "from sagemaker.instance_group import InstanceGroup\n",
+ "\n",
+ "\n",
+ "sess = sagemaker.Session()\n",
+ "\n",
+ "role = get_execution_role()\n",
+ "\n",
+ "output_path = \"s3://\" + sess.default_bucket() + \"/DEMO-MNIST\"\n",
+ "print(role)\n",
+ "print(output_path)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "165bca04",
+ "metadata": {},
+ "source": [
+ "#### Step 2 - Configure environment variables \n",
+ "This step defines whether you want to run training job in heterogeneous cluster mode or not. Also, defines instance groups, multiple nodes in group, and hyperparameter values. For baselining, run a homogeneous cluster training job by setting `IS_HETERO = False`. This will let both the data pre-processing and DNN code run on the same node i.e. `ml.p3.2xlarge`. \n",
+ "\n",
+ "\n",
+ "Test configuration (if running training on p3.2xl or g5.2xl as dnn_group instance type, and c5.2xl as data_group instance type: (training duration: 7-8 mins) \n",
+ "`num-data-workers: 4` \n",
+ "`grpc-workers: 4` \n",
+ "`num-dnn-workers: 4` \n",
+ "`pin-memory\": True` \n",
+ "`iterations : 100` \n",
+ "\n",
+ "Performance configuration (if running training on p3.2xl as dnn_group instance type, and c5.9xl as data_group instance type OR training in homogeneous cluster mode i.e. g5.8xl): (training duration - 30 mins) \n",
+ "`num-data-workers: 32` \n",
+ "`grpc-workers: 2` \n",
+ "`num-dnn-workers: 2` \n",
+ "`pin-memory\": True` \n",
+ "`iterations : 4800`\n",
+ "\n",
+ "Performance configuration (if running training on p3.2xl in homogeneous cluster mode): \n",
+ "`num-data-workers: 8` \n",
+ "`grpc-workers: 2` \n",
+ "`num-dnn-workers: 2` \n",
+ "`pin-memory\": True` \n",
+ "`iterations : 2400`\n",
+ "\n",
+ "Note: This PyTorch example has not been tested with multiple instances in an instance group. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 54,
+ "id": "0d65707b",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "IS_CLOUD_JOB = True\n",
+ "IS_HETERO = True # if set to false, uses homogeneous cluster\n",
+ "PT_DATA_MODE = \"service\" if IS_HETERO else \"local\" # local | service\n",
+ "IS_DNN_DISTRIBUTION = False # Distributed Training with DNN nodes not tested, set it to False\n",
+ "\n",
+ "data_group = InstanceGroup(\n",
+ " \"data_group\", \"ml.c5.9xlarge\", 1\n",
+ ") # 36 vCPU #change the instance type if IS_HETERO=True\n",
+ "dnn_group = InstanceGroup(\n",
+ " \"dnn_group\", \"ml.p3.2xlarge\", 1\n",
+ ") # 8 vCPU #change the instance type if IS_HETERO=True\n",
+ "\n",
+ "kwargs = dict()\n",
+ "kwargs[\"hyperparameters\"] = {\n",
+ " \"batch-size\": 8192,\n",
+ " \"num-data-workers\": 4, # This number drives the avg. step time. More workers help parallel pre-processing of data. Recommendation: Total no. of cpu 'n' = 'num-data-wokers'+'grpc-workers'+ 2 (reserved)\n",
+ " \"grpc-workers\": 4, # No. of workers serving pre-processed data to DNN group (gRPC client). see above formula.\n",
+ " \"num-dnn-workers\": 4, # Modify this no. to be less than the cpu core of your training instances in dnn group\n",
+ " \"pin-memory\": True, # Pin to GPU memory\n",
+ " \"iterations\": 100, # No. of iterations in an epoch (must be multiple of 10).\n",
+ "}\n",
+ "\n",
+ "if IS_HETERO:\n",
+ " kwargs[\"instance_groups\"] = [data_group, dnn_group]\n",
+ " entry_point = \"launcher.py\"\n",
+ "else:\n",
+ " kwargs[\"instance_type\"] = (\n",
+ " \"ml.p3.2xlarge\" if IS_CLOUD_JOB else \"local\"\n",
+ " ) # change the instance type if IS_HETERO=False\n",
+ " kwargs[\"instance_count\"] = 1\n",
+ " entry_point = \"train.py\"\n",
+ "\n",
+ "if IS_DNN_DISTRIBUTION:\n",
+ " processes_per_host_dict = {\n",
+ " \"ml.g5.xlarge\": 1,\n",
+ " \"ml.g5.12xlarge\": 4,\n",
+ " \"ml.p3.8xlarge\": 4,\n",
+ " \"ml.p4d.24xlarge\": 8,\n",
+ " }\n",
+ " kwargs[\"distribution\"] = {\n",
+ " \"mpi\": {\n",
+ " \"enabled\": True,\n",
+ " \"processes_per_host\": processes_per_host_dict[dnn_instance_type],\n",
+ " \"custom_mpi_options\": \"--NCCL_DEBUG INFO\",\n",
+ " },\n",
+ " }\n",
+ " if IS_HETERO:\n",
+ " kwargs[\"distribution\"][\"instance_groups\"] = [dnn_group]\n",
+ "\n",
+ " print(f\"distribution={kwargs['distribution']}\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "4ff19e24",
+ "metadata": {},
+ "source": [
+ "#### Step 3: Set up the Estimator\n",
+ "In order to use SageMaker to fit our algorithm, we'll create `Estimator` that defines how to use the container to train. This includes the configuration we need to invoke SageMaker training."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 55,
+ "id": "94f4c8ce",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "estimator = PyTorch(\n",
+ " framework_version=\"1.11.0\", # 1.10.0 or later\n",
+ " py_version=\"py38\", # Python v3.8\n",
+ " role=role,\n",
+ " entry_point=entry_point,\n",
+ " source_dir=\"code\",\n",
+ " volume_size=10,\n",
+ " max_run=4800,\n",
+ " disable_profiler=True,\n",
+ " debugger_hook_config=False,\n",
+ " **kwargs,\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "a81dcab6",
+ "metadata": {},
+ "source": [
+ "#### Step 4: Download the MNIST Data and Upload it to S3 bucket\n",
+ "\n",
+ "This is an optional step for now. The training job downloads the data on its run directly from MNIST website to the data_group node (grpc server). "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 56,
+ "id": "d0534973",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import logging\n",
+ "import boto3\n",
+ "from botocore.exceptions import ClientError\n",
+ "\n",
+ "# Download training and testing data from a public S3 bucket\n",
+ "\n",
+ "\n",
+ "def download_from_s3(data_dir=\"./data\", train=True):\n",
+ " \"\"\"Download MNIST dataset and convert it to numpy array\n",
+ "\n",
+ " Args:\n",
+ " data_dir (str): directory to save the data\n",
+ " train (bool): download training set\n",
+ "\n",
+ " Returns:\n",
+ " None\n",
+ " \"\"\"\n",
+ "\n",
+ " if not os.path.exists(data_dir):\n",
+ " os.makedirs(data_dir)\n",
+ "\n",
+ " if train:\n",
+ " images_file = \"train-images-idx3-ubyte.gz\"\n",
+ " labels_file = \"train-labels-idx1-ubyte.gz\"\n",
+ " else:\n",
+ " images_file = \"t10k-images-idx3-ubyte.gz\"\n",
+ " labels_file = \"t10k-labels-idx1-ubyte.gz\"\n",
+ "\n",
+ " # download objects\n",
+ " s3 = boto3.client(\"s3\")\n",
+ " bucket = f\"sagemaker-sample-files\"\n",
+ " for obj in [images_file, labels_file]:\n",
+ " key = os.path.join(\"datasets/image/MNIST\", obj)\n",
+ " dest = os.path.join(data_dir, obj)\n",
+ " if not os.path.exists(dest):\n",
+ " s3.download_file(bucket, key, dest)\n",
+ " return\n",
+ "\n",
+ "\n",
+ "download_from_s3(\"./data\", True)\n",
+ "download_from_s3(\"./data\", False)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 57,
+ "id": "2d699654",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Upload to the default bucket\n",
+ "\n",
+ "prefix = \"DEMO-MNIST\"\n",
+ "bucket = sess.default_bucket()\n",
+ "loc = sess.upload_data(path=\"./data\", bucket=bucket, key_prefix=prefix)\n",
+ "\n",
+ "channels = {\"training\": loc, \"testing\": loc}"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "48352f04",
+ "metadata": {},
+ "source": [
+ "## C. Submit the training job\n",
+ "\n",
+ "The job runs for the predefined iterations. DNN instance group sends a shutdown request to data group after done with the training. You can see the following entries in the CloudWatch logs of dnn instance. A job with 4800 iterations finishes in 29 mins in a Heterogeneous cluster composed of 1x ml.c5.9xlarge as data node and 1x ml.p3.2xlarge as DNN node.\n",
+ "\n",
+ "Note: The console output of billing seconds can be ignored. See the AWS console > SageMaker > Training Job for the exact billing seconds.\n",
+ "\n",
+ "Log excerpt from algo-1 (DNN instance)\n",
+ "```\n",
+ "4780: avg step time: 0.19709917231025106\n",
+ "INFO:__main__:4780: avg step time: 0.19709917231025106\n",
+ "4790: avg step time: 0.19694106239373696\n",
+ "INFO:__main__:4790: avg step time: 0.19694106239373696\n",
+ "4800: avg step time: 0.196784295383125\n",
+ "Saving the model\n",
+ "INFO:__main__:4800: avg step time: 0.196784295383125\n",
+ "INFO:__main__:Saving the model\n",
+ "Training job completed!\n",
+ "INFO:__main__:Training job completed!\n",
+ "Process train_dnn.py closed with returncode=0\n",
+ "Shutting downdata service dispatcher via: [algo-2:16000]\n",
+ "shutdown request sent to algo-2:16000\n",
+ "2022-08-16 01:15:05,555 sagemaker-training-toolkit INFO Waiting for the process to finish and give a return code.\n",
+ "2022-08-16 01:15:05,555 sagemaker-training-toolkit INFO Done waiting for a return code. Received 0 from exiting process.\n",
+ "2022-08-16 01:15:05,556 sagemaker-training-toolkit INFO Reporting training SUCCESS\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "31cb6cae",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "2022-09-15 00:55:22 Starting - Starting the training job...\n",
+ "2022-09-15 00:55:50 Starting - Preparing the instances for training.........\n",
+ "2022-09-15 00:57:10 Downloading - Downloading input data.."
+ ]
+ }
+ ],
+ "source": [
+ "estimator.fit(\n",
+ " inputs=channels,\n",
+ " job_name=\"pt-hetero\"\n",
+ " + \"-\"\n",
+ " + \"H-\"\n",
+ " + str(IS_HETERO)[0]\n",
+ " + \"-\"\n",
+ " + datetime.datetime.utcnow().strftime(\"%Y%m%dT%H%M%SZ\"),\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3ea2e092",
+ "metadata": {},
+ "source": [
+ "## D. Monitoring Instance Metrics for GPU and CPU utilization\n",
+ "\n",
+ "Click on **View instance metrics** from the **Training jobs** node in **Amazon SageMaker Console**. In the run above, all 30 vCPU of Data node (algo-1) is approx. 100% utilized, and the GPU utilization is at 100% at frequent intervals in the DNN node (algo-2). To rescale the CloudWatch Metrics to 100% on CPU utilization for algo-1 and algo-2, use CloudWatch \"Add Math\" feature and average it out by no. of cores on those instance types.\n",
+ "\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "430fb45e",
+ "metadata": {},
+ "source": [
+ "## E. Comparing time-to-train and cost-to-train\n",
+ "\n",
+ "Let's continue with the above example i.e. train a heavy data pre-processing (CPU intensive) model (MNIST) requiring only 1 GPU. We start with ml.p3.2xlarge (1xV100 GPU, 8x vCPU) in homogeneous cluster mode to get the baseline performance numbers. Due to the no. of CPU cores, we could not go beyond 8 data loader/workers for data pre-processing. The avg. step cost was `7.6 cents` and avg. step time is `1.19 seconds`. \n",
+ "\n",
+ "Our objective is to reduce the cost and speed up the model training time. The first choice here is to scale up the instance type in the same family. If we leverage the next instance type (4 GPU) in the P3 family, the GPUs would have gone underutilized. In this case, we needed more vCPU to GPU ratio. Assuming we haven't had any instance type in another instance family or the model is incompatible with the CPU/GPU architectures of other instance families, we are constrained to use ml.p3.2xlarge. The only way then to have more vCPUs to GPU ratio is to use SageMaker feature, Heterogeneous Cluster, which enables customers to offload data pre-processing logic to CPU only instance types example ml.c5. In the next test, we offloaded CPU intensive work i.e. data preprocessing to ml.c5.9xlarge (36 vCPU) and continued using ml.p3.2xlarge for DNN. The avg. step cost was `1.9 cents` and avg. step time is `0.18 seconds`. \n",
+ "\n",
+ "In summary, we reduced the training cost by 4.75 times, and the avg. step reduced by 6.5 times. This was possible because with higher cpu count, we could use 32 data loader workers (compared to 8 with p3.2xl) to preprocess the data, and kept GPU close to 100% utilized at frequent intervals. Note: These numbers are just taken as a sample, you have to do benchmarking with your own model and dataset to come up with the exact price-performance benefits. \n",
+ "\n",
+ "## F. Conclusion\n",
+ "In this notebook, we demonstrated how to leverage heterogeneous cluster feature of SageMaker Training to achieve better price performance. To get started you can copy this example project, and only change the `train_dnn.py` script.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3.9.7 ('.venv': venv)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.7"
+ },
+ "vscode": {
+ "interpreter": {
+ "hash": "77c0de85c2cb739aa5100af7b92fb9d2075368f0e653f4148499a56c989df5f7"
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/training/heterogeneous-clusters/pt.grpc.sagemaker/images/heterogeneous-cluster-diagram.png b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/heterogeneous-cluster-diagram.png
new file mode 100644
index 0000000000..c84c185d31
Binary files /dev/null and b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/heterogeneous-cluster-diagram.png differ
diff --git a/training/heterogeneous-clusters/pt.grpc.sagemaker/images/heterogeneous-instance-metrics.png b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/heterogeneous-instance-metrics.png
new file mode 100644
index 0000000000..d812e2f46b
Binary files /dev/null and b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/heterogeneous-instance-metrics.png differ
diff --git a/training/heterogeneous-clusters/pt.grpc.sagemaker/images/homogeneous-cluster-diagram.png b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/homogeneous-cluster-diagram.png
new file mode 100644
index 0000000000..ae3119d4b6
Binary files /dev/null and b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/homogeneous-cluster-diagram.png differ
diff --git a/training/heterogeneous-clusters/pt.grpc.sagemaker/images/pytorch-heterogeneous-workflow.png b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/pytorch-heterogeneous-workflow.png
new file mode 100644
index 0000000000..c40b09aeed
Binary files /dev/null and b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/pytorch-heterogeneous-workflow.png differ
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/cloudwatch-metric-definitions/heterogenenous-workload.json b/training/heterogeneous-clusters/tf.data.service.sagemaker/cloudwatch-metric-definitions/heterogenenous-workload.json
new file mode 100644
index 0000000000..5b3736fc35
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/cloudwatch-metric-definitions/heterogenenous-workload.json
@@ -0,0 +1,30 @@
+{
+ "metrics": [
+ [ { "expression": "100*(m1/9600)", "label": "DNN1 CPU/100%", "id": "e1" } ],
+ [ { "expression": "100*(m2/800)", "label": "DNN1 GPU/100%", "id": "e2" } ],
+ [ { "expression": "100*(m3/7200)", "label": "DATA1 CPU/100%", "id": "e3" } ],
+ [ { "expression": "100*(m4/7200)", "label": "DATA2 CPU/100%", "id": "e4" } ],
+ [ "/aws/sagemaker/TrainingJobs", "CPUUtilization", "Host", "hetero-tf-data-service-Dnode2-wrkrs-1-20220922T214326Z/algo-1", { "id": "m1", "yAxis": "left", "visible": false } ],
+ [ ".", "GPUUtilization", ".", ".", { "id": "m2", "visible": false } ],
+ [ ".", "CPUUtilization", ".", "hetero-tf-data-service-Dnode2-wrkrs-1-20220922T214326Z/algo-2", { "id": "m3", "visible": false } ],
+ [ "...", "hetero-tf-data-service-Dnode2-wrkrs-1-20220922T214326Z/algo-3", { "id": "m4", "visible": false } ]
+ ],
+ "sparkline": true,
+ "view": "timeSeries",
+ "stacked": false,
+ "region": "us-east-1",
+ "stat": "Average",
+ "period": 60,
+ "setPeriodToTimeRange": true,
+ "yAxis": {
+ "left": {
+ "min": 0,
+ "max": 100,
+ "label": "% Utilization",
+ "showUnits": false
+ }
+ },
+ "legend": {
+ "position": "bottom"
+ }
+}
\ No newline at end of file
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/cloudwatch-metric-definitions/homogenous-workload copy.json b/training/heterogeneous-clusters/tf.data.service.sagemaker/cloudwatch-metric-definitions/homogenous-workload copy.json
new file mode 100644
index 0000000000..c514eced5a
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/cloudwatch-metric-definitions/homogenous-workload copy.json
@@ -0,0 +1,26 @@
+{
+ "sparkline": true,
+ "metrics": [
+ [ { "expression": "100*(m1/9600)", "label": "CPU/100%", "id": "e1" } ],
+ [ { "expression": "100*(m2/800)", "label": "GPU/100%", "id": "e2" } ],
+ [ "/aws/sagemaker/TrainingJobs", "CPUUtilization", "Host", "hetero-tf-data-local-Dnode1-wrkrs-1-20220921T213920Z/algo-1", { "id": "m1", "visible": false } ],
+ [ ".", "GPUUtilization", ".", ".", { "id": "m2", "visible": false } ]
+ ],
+ "view": "timeSeries",
+ "stacked": false,
+ "region": "us-east-1",
+ "stat": "Average",
+ "period": 60,
+ "setPeriodToTimeRange": true,
+ "yAxis": {
+ "left": {
+ "min": 0,
+ "max": 100,
+ "label": "% Utilization",
+ "showUnits": false
+ }
+ },
+ "legend": {
+ "position": "bottom"
+ }
+}
\ No newline at end of file
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/code/launcher.py b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/launcher.py
new file mode 100644
index 0000000000..d67b27af7d
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/launcher.py
@@ -0,0 +1,123 @@
+import sys
+import os
+import time
+from typing import Optional
+import subprocess
+
+# instance group names
+DATA_GROUP = 'data_group'
+DNN_GROUP = 'dnn_group'
+
+
+def start_child_process_async(name : str, additional_args=[]) -> int:
+ #TODO: Find a way to stream stdout and stderr to the parent process
+ params = ["python", f"./{name}"] + sys.argv[1:] + additional_args
+ print(f'Opening process async: {params}')
+ p = subprocess.Popen(params)
+ print(f'Process {name} started')
+ return p.pid
+
+
+def start_child_process(name : str, additional_args=[]) -> int:
+ params = ["python", f"./{name}"] + sys.argv[1:] + additional_args
+ print(f'Opening process: {params}')
+ p = subprocess.run(params)
+ print(f'Process {name} closed with returncode={p.returncode}')
+ return p.returncode
+
+
+def start_data_group(dispatcher_host : str) -> int:
+ return start_child_process('train_data.py', ["--dispatcher_host", dispatcher_host])
+
+
+def not_mpi_or_rank_0() -> bool:
+ return 'OMPI_COMM_WORLD_LOCAL_RANK' not in os.environ or os.environ['OMPI_COMM_WORLD_LOCAL_RANK'] == '0'
+
+
+def start_dnn_group(dispatcher_host : Optional[str]) -> int:
+ if dispatcher_host is not None:
+ args = ["--dispatcher_host", dispatcher_host]
+ # Start a tf.data.service worker processes for each host in the DNN group
+ # to take advantage of its CPU resources.
+ # Start once per instance, not per MPI process
+ if not_mpi_or_rank_0():
+ start_child_process_async('train_data.py', args)
+ else:
+ args = []
+ return start_child_process('train_dnn.py', args)
+
+
+def get_group_first_host(instance_groups, target_group_name):
+ return instance_groups[target_group_name]['hosts'][0]
+
+
+def is_not_mpi_or_world_rank_0() -> bool:
+ return 'OMPI_COMM_WORLD_RANK' in os.environ and os.environ['OMPI_COMM_WORLD_RANK'] != '0'
+
+
+def shutdown_tf_data_service_with_retries(hosts : list):
+ # only world rank 0 process should shutdown the dispatcher
+ if is_not_mpi_or_world_rank_0():
+ return
+
+ completed_hosts = []
+ for host in hosts:
+ for i in range(0,12):
+ try:
+ if i>0:
+ sleeptime = 10
+ print(f'Will attempt {i} time to shutdown in {sleeptime} seconds')
+ time.sleep(sleeptime)
+
+ if host not in completed_hosts:
+ _shutdown_data_service(host)
+ completed_hosts.append(host)
+ break
+ except Exception as e:
+ print(f'Failed to shutdown dispatcher in {host} due to: {e}')
+
+
+def _shutdown_data_service(dispatcher_host : str):
+ SHUTDOWN_PORT = 16000
+ print(f'Shutting down tf.data.service dispatcher via: [{dispatcher_host}:{SHUTDOWN_PORT}]')
+ import socket
+ with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
+ s.connect((dispatcher_host, SHUTDOWN_PORT))
+ print(f'Shutdown request sent to {dispatcher_host}:{SHUTDOWN_PORT}')
+
+
+def split_to_instance_group_train_script() -> int:
+ from sagemaker_training import environment
+ env = environment.Environment()
+
+ print(f'env.is_hetero={env.is_hetero}')
+ print(f'current_host={env.current_host}')
+
+ if env.is_hetero:
+ dispatcher_host = get_group_first_host(env.instance_groups_dict, DATA_GROUP)
+ first_host_in_dnn_group = get_group_first_host(env.instance_groups_dict, DNN_GROUP)
+ print(f'current_instance_type={env.current_instance_type}')
+ print(f'current_group_name={env.current_instance_group}')
+ print(f'dispatcher_host={dispatcher_host}')
+ if env.current_instance_group == DATA_GROUP:
+ return start_data_group(dispatcher_host)
+ elif env.current_instance_group == DNN_GROUP:
+ returncode = start_dnn_group(dispatcher_host)
+ # first host in DNN group will take care of shutting down the dispatcher
+ if env.current_host == first_host_in_dnn_group:
+ hosts = env.instance_groups_dict[DATA_GROUP]['hosts'] + env.instance_groups_dict[DNN_GROUP]['hosts']
+ shutdown_tf_data_service_with_retries(hosts)
+ return returncode
+ else:
+ raise Exception(f'Unknown instance group: {env.current_instance_group}')
+
+ else: # not heterogenous
+ return start_dnn_group(dispatcher_host=None)
+
+if __name__ == "__main__":
+ try:
+ returncode = split_to_instance_group_train_script()
+ exit(returncode)
+ except Exception as e:
+ print(f'Failed due to {e}. exiting with returncode=1')
+ sys.exit(1)
\ No newline at end of file
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/code/requirements.txt b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/requirements.txt
new file mode 100644
index 0000000000..10aac59994
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/requirements.txt
@@ -0,0 +1,2 @@
+protobuf==3.20.2
+tensorflow-addons==0.17.0
\ No newline at end of file
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/code/train_data.py b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/train_data.py
new file mode 100644
index 0000000000..62248d1e68
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/train_data.py
@@ -0,0 +1,68 @@
+from tensorflow.data.experimental.service import DispatchServer, WorkerServer, DispatcherConfig, WorkerConfig
+
+def wait_for_shutdown_signal(dispatcher, workers):
+ SHUTDOWN_PORT = 16000
+ import socket
+ s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
+ s.bind(('', SHUTDOWN_PORT))
+ s.listen(1)
+ print('Awaiting shutdown signal on port {}'.format(SHUTDOWN_PORT))
+ conn, addr = s.accept()
+ print('Received shutdown signal from: ', addr)
+ try:
+ conn.close()
+ s.close()
+ except Exception as e:
+ print(e)
+
+ if dispatcher is not None: # dispatcher runs only on the 1st data instance
+ print('Stopping dispatcher.')
+ dispatcher._stop()
+ print('Joining dispatcher')
+ dispatcher.join()
+
+ for i,worker in enumerate(workers, start=0):
+ print(f'Stopping worker {i}')
+ worker._stop()
+ print(f'Joining worker {i}')
+ worker.join()
+
+def create_worker(workerIndex : int, dispatcher_host : str, current_host : str) -> WorkerServer:
+ port = 6001 + workerIndex
+ w_config = WorkerConfig(port=port,
+ dispatcher_address=f'{dispatcher_host}:6000',
+ worker_address=f'{current_host}:{port}')
+ print(f'Starting tf.data.service WorkerServer {w_config}')
+ worker = WorkerServer(w_config)
+ return worker
+
+def start_dispatcher_and_worker(dispatcher_host : str, current_host : str, num_of_data_workers : int):
+ assert(dispatcher_host is not None)
+
+ if current_host == dispatcher_host:
+ print(f'starting Dispatcher (dispatcher_host={dispatcher_host})')
+ d_config = DispatcherConfig(port=6000)
+ dispatcher = DispatchServer(d_config)
+ else:
+ dispatcher = None
+
+ workers = [ create_worker(i, dispatcher_host, current_host) for i in range(num_of_data_workers) ]
+ print(f'Finished starting dispatcher and {num_of_data_workers} workers')
+
+ wait_for_shutdown_signal(dispatcher, workers)
+
+
+"This function read mode command line argument"
+def read_args():
+ import argparse, os
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--dispatcher_host", type=str)
+ parser.add_argument("--current_host", type=str, default=os.environ["SM_CURRENT_HOST"])
+ parser.add_argument("--num_of_data_workers", type=int)
+ args, unknown = parser.parse_known_args()
+ return args
+
+
+if __name__ == "__main__":
+ args = read_args()
+ start_dispatcher_and_worker(args.dispatcher_host, args.current_host, args.num_of_data_workers)
\ No newline at end of file
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/code/train_dnn.py b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/train_dnn.py
new file mode 100644
index 0000000000..cd938b46c7
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/train_dnn.py
@@ -0,0 +1,153 @@
+from tensorflow.keras.layers.experimental import preprocessing
+from tensorflow.keras.applications.resnet50 import ResNet50
+import tensorflow_addons as tfa
+import tensorflow as tf
+import os
+import horovod.tensorflow.keras as hvd
+
+
+# dilation filter
+def dilate(image, label):
+ dilateFilter = tf.zeros([3, 3, 3], tf.uint8)
+ image = tf.expand_dims(image, 0)
+ image = tf.nn.dilation2d(
+ image, dilateFilter, strides=[1, 1, 1, 1],
+ dilations=[1, 1, 1, 1],
+ padding='SAME',
+ data_format='NHWC')
+ image = tf.squeeze(image)
+ return image, label
+# blur filter
+
+
+def blur(image, label):
+ image = tfa.image.gaussian_filter2d(image=image,
+ filter_shape=(11, 11), sigma=0.8)
+ return image, label
+
+# rescale filter
+def rescale(image, label):
+ image = preprocessing.Rescaling(1.0 / 255)(image)
+ return image, label
+
+
+# augmentation filters
+def augment(image, label):
+ data_augmentation = tf.keras.Sequential(
+ [preprocessing.RandomFlip("horizontal"),
+ preprocessing.RandomRotation(0.1),
+ preprocessing.RandomZoom(0.1)])
+ image = data_augmentation(image)
+ return image, label
+
+
+# This function generates a dataset consisting 32x32x3 random images
+# And a corresponding random label representing 10 different classes.
+# As this dataset is randomly generated, you should not expect the model
+# to converge in a meaningful way, it doesn't matter as our intent is
+# only to measure data pipeline and DNN optimization throughput
+def generate_artificial_dataset():
+ import numpy as np
+ x_train = np.random.randint(0, 255, size=(32000, 32, 32, 3), dtype=np.uint8)
+ y_train = np.random.randint(0, 10, size=(32000,1))
+ train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
+ return train_dataset
+
+
+def get_dataset(batch_size : int, use_tf_data_service : bool, dispatcher_host : str):
+ autotune = tf.data.experimental.AUTOTUNE
+ options = tf.data.Options()
+ options.experimental_deterministic = False
+
+ ds = generate_artificial_dataset().shuffle(10000).repeat()
+
+ ds = ds.map(dilate, num_parallel_calls=autotune)
+ ds = ds.map(blur, num_parallel_calls=autotune)
+ ds = ds.map(rescale,num_parallel_calls=autotune)
+ ds = ds.map(augment, num_parallel_calls=autotune)
+ ds = ds.batch(batch_size)
+
+ if use_tf_data_service:
+ ds = ds.apply(tf.data.experimental.service.distribute(
+ processing_mode="parallel_epochs",
+ service=f'grpc://{dispatcher_host}:6000',),
+ )
+
+ #ds = ds.take(1).cache().repeat()
+ ds = ds.prefetch(autotune)
+ return ds
+
+"This function read mode command line argument"
+def read_args():
+ import argparse
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--tf_data_mode', type=str, default='local',
+ help="'service' distributed dataset using tf.data.service. 'local' use standard tf.data")
+ parser.add_argument('--steps_per_epoch', type=int, default=1)
+ parser.add_argument('--batch_size', type=int)
+ parser.add_argument('--epochs', type=int, default=1)
+ parser.add_argument("--n_gpus", type=str,
+ default=os.environ.get("SM_NUM_GPUS"))
+ parser.add_argument("--dispatcher_host", type=str)
+ parser.add_argument("--num_of_data_workers", type=int, default=1)
+ parser.add_argument("--output_data_dir", type=str,
+ default=os.environ.get("SM_OUTPUT_DATA_DIR"))
+ parser.add_argument("--model_dir", type=str,
+ default=os.environ.get("SM_MODEL_DIR"))
+ parser.add_argument("--checkpoint-path",type=str,default="/opt/ml/checkpoints",help="Path where checkpoints are saved.")
+ args = parser.parse_args()
+ return args
+
+if __name__ == "__main__":
+ args = read_args()
+ hvd.init()
+ # Horovod: pin GPU to be used to process local rank (one GPU per process)
+ gpus = tf.config.experimental.list_physical_devices('GPU')
+ print(str(gpus))
+ for gpu in gpus:
+ tf.config.experimental.set_memory_growth(gpu, True)
+ if gpus:
+ print(f'hvd.local_rank() {hvd.local_rank()}')
+ tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')
+
+ model = ResNet50(weights=None,
+ input_shape=(32, 32, 3),
+ classes=10)
+
+ model.compile(loss=tf.losses.SparseCategoricalCrossentropy(),
+ optimizer=tf.optimizers.Adam())
+ # Horovod: adjust learning rate based on number of GPUs.
+ scaled_lr = 0.001 * hvd.size()
+ opt = tf.optimizers.Adam(scaled_lr)
+ opt = hvd.DistributedOptimizer(
+ opt, backward_passes_per_step=1, average_aggregated_gradients=True)
+
+ model.compile(loss=tf.losses.SparseCategoricalCrossentropy(),
+ optimizer=opt,
+ experimental_run_tf_function=False)
+
+ callbacks = [
+ hvd.callbacks.BroadcastGlobalVariablesCallback(0),
+ hvd.callbacks.MetricAverageCallback(),
+ hvd.callbacks.LearningRateWarmupCallback(initial_lr=scaled_lr, warmup_epochs=3, verbose=1),
+ ]
+ # Horovod: save checkpoints only on worker 0 to prevent other workers from corrupting them.
+ if hvd.rank() == 0:
+ path = os.path.join(args.checkpoint_path, './checkpoint-{epoch}.h5')
+ callbacks.append(tf.keras.callbacks.ModelCheckpoint(path))
+
+ # Horovod: write logs on worker 0.
+ verbose = 1 if hvd.rank() == 0 else 0
+
+ assert(args.tf_data_mode == 'local' or args.tf_data_mode == 'service')
+ print(f'Running in {args.tf_data_mode} tf_data_mode.')
+ dataset = get_dataset(batch_size = args.batch_size, use_tf_data_service=(args.tf_data_mode == 'service'), dispatcher_host = args.dispatcher_host)
+
+ model.fit( dataset,
+ steps_per_epoch=args.steps_per_epoch,
+ callbacks=callbacks,
+ epochs=args.epochs,
+ verbose=2,)
+
+ if hvd.rank() == 0:
+ model.save(os.path.join(args.model_dir, '000000001'), 'my_model.h5')
\ No newline at end of file
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/hetero-tensorflow-restnet50.ipynb b/training/heterogeneous-clusters/tf.data.service.sagemaker/hetero-tensorflow-restnet50.ipynb
new file mode 100644
index 0000000000..61cdc56cf5
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/hetero-tensorflow-restnet50.ipynb
@@ -0,0 +1,1136 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# TensorFlow's tf.data.service with Amazon SageMaker Training Heterogeneous Clusters\n",
+ "\n",
+ "---\n",
+ "### Introduction\n",
+ "\n",
+ "Heterogeneous clusters enable launching training jobs that use multiple instance types in a single job. This capability can improve your training cost and speed by running different parts of the model training on the most suitable instance type. This use case typically happens in computer vision (CV) deep learning (DL) training, where training is bottleneck on CPU resources needed for data augmentation, leaving the expensive GPU underutilized. Heterogeneous clusters enable you to add more CPU resources to fully utilize GPUs to increase training speed and cost-efficiency. For more details, you can find the documentation of this feature [here](https://docs.aws.amazon.com/sagemaker/latest/dg/train-heterogeneous-cluster.html).\n",
+ "\n",
+ "This notebook demonstrates how to use Heterogeneous Clusters with TensorFlow's [tf.data.service](https://www.TensorFlow.org/api_docs/python/tf/data/experimental/service). It includes training a CPU intensive DL CV workload. Comparing cost and performance between homogeneous and heterogeneous training configurations. \n",
+ "\n",
+ "💡To get started quickly with heterogeneous clusters, we suggest you'll reuse the provided code as a quick way to migrate your workload from a local tf.data pipeline to a distributed tf.data.service pipeline. You'll need to change [code/train_dnn.py](./code/train_dnn.py), while keeping [code/train_data.py](./code/train_data.py) and [code/launcher.py](code/launcher.py) intact. This is explained below in the [Workload Details] section.\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This notebook covers:\n",
+ "- A guide to switching from a homogeneous job (single instance type) to a heterogeneous job (multiple instance types)\n",
+ "- Explaining to use Heterogeneous clusters with TensorFlow's tf.data.service\n",
+ "- Set up Amazon SageMaker Studio Notebook \n",
+ "- Run homogeneous cluster training job \n",
+ "- Run heterogeneous cluster training job \n",
+ "- Compare time and cost to train between homogeneous and heterogeneous clusters\n",
+ "- Conclusion\n",
+ "\n",
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### A guide to switching from a homogeneous to a heterogeneous job\n",
+ "\n",
+ "This notebook runs and compares these two workloads:\n",
+ "\n",
+ "Homogeneous Training Job - The image shows a ml.p4d.24xlarge instance GPUs is under-utilized due to a CPU bottleneck. \n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "430fb45e",
+ "metadata": {},
+ "source": [
+ "## E. Comparing time-to-train and cost-to-train\n",
+ "\n",
+ "Let's continue with the above example i.e. train a heavy data pre-processing (CPU intensive) model (MNIST) requiring only 1 GPU. We start with ml.p3.2xlarge (1xV100 GPU, 8x vCPU) in homogeneous cluster mode to get the baseline performance numbers. Due to the no. of CPU cores, we could not go beyond 8 data loader/workers for data pre-processing. The avg. step cost was `7.6 cents` and avg. step time is `1.19 seconds`. \n",
+ "\n",
+ "Our objective is to reduce the cost and speed up the model training time. The first choice here is to scale up the instance type in the same family. If we leverage the next instance type (4 GPU) in the P3 family, the GPUs would have gone underutilized. In this case, we needed more vCPU to GPU ratio. Assuming we haven't had any instance type in another instance family or the model is incompatible with the CPU/GPU architectures of other instance families, we are constrained to use ml.p3.2xlarge. The only way then to have more vCPUs to GPU ratio is to use SageMaker feature, Heterogeneous Cluster, which enables customers to offload data pre-processing logic to CPU only instance types example ml.c5. In the next test, we offloaded CPU intensive work i.e. data preprocessing to ml.c5.9xlarge (36 vCPU) and continued using ml.p3.2xlarge for DNN. The avg. step cost was `1.9 cents` and avg. step time is `0.18 seconds`. \n",
+ "\n",
+ "In summary, we reduced the training cost by 4.75 times, and the avg. step reduced by 6.5 times. This was possible because with higher cpu count, we could use 32 data loader workers (compared to 8 with p3.2xl) to preprocess the data, and kept GPU close to 100% utilized at frequent intervals. Note: These numbers are just taken as a sample, you have to do benchmarking with your own model and dataset to come up with the exact price-performance benefits. \n",
+ "\n",
+ "## F. Conclusion\n",
+ "In this notebook, we demonstrated how to leverage heterogeneous cluster feature of SageMaker Training to achieve better price performance. To get started you can copy this example project, and only change the `train_dnn.py` script.\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": []
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3.9.7 ('.venv': venv)",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.9.7"
+ },
+ "vscode": {
+ "interpreter": {
+ "hash": "77c0de85c2cb739aa5100af7b92fb9d2075368f0e653f4148499a56c989df5f7"
+ }
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/training/heterogeneous-clusters/pt.grpc.sagemaker/images/heterogeneous-cluster-diagram.png b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/heterogeneous-cluster-diagram.png
new file mode 100644
index 0000000000..c84c185d31
Binary files /dev/null and b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/heterogeneous-cluster-diagram.png differ
diff --git a/training/heterogeneous-clusters/pt.grpc.sagemaker/images/heterogeneous-instance-metrics.png b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/heterogeneous-instance-metrics.png
new file mode 100644
index 0000000000..d812e2f46b
Binary files /dev/null and b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/heterogeneous-instance-metrics.png differ
diff --git a/training/heterogeneous-clusters/pt.grpc.sagemaker/images/homogeneous-cluster-diagram.png b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/homogeneous-cluster-diagram.png
new file mode 100644
index 0000000000..ae3119d4b6
Binary files /dev/null and b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/homogeneous-cluster-diagram.png differ
diff --git a/training/heterogeneous-clusters/pt.grpc.sagemaker/images/pytorch-heterogeneous-workflow.png b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/pytorch-heterogeneous-workflow.png
new file mode 100644
index 0000000000..c40b09aeed
Binary files /dev/null and b/training/heterogeneous-clusters/pt.grpc.sagemaker/images/pytorch-heterogeneous-workflow.png differ
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/cloudwatch-metric-definitions/heterogenenous-workload.json b/training/heterogeneous-clusters/tf.data.service.sagemaker/cloudwatch-metric-definitions/heterogenenous-workload.json
new file mode 100644
index 0000000000..5b3736fc35
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/cloudwatch-metric-definitions/heterogenenous-workload.json
@@ -0,0 +1,30 @@
+{
+ "metrics": [
+ [ { "expression": "100*(m1/9600)", "label": "DNN1 CPU/100%", "id": "e1" } ],
+ [ { "expression": "100*(m2/800)", "label": "DNN1 GPU/100%", "id": "e2" } ],
+ [ { "expression": "100*(m3/7200)", "label": "DATA1 CPU/100%", "id": "e3" } ],
+ [ { "expression": "100*(m4/7200)", "label": "DATA2 CPU/100%", "id": "e4" } ],
+ [ "/aws/sagemaker/TrainingJobs", "CPUUtilization", "Host", "hetero-tf-data-service-Dnode2-wrkrs-1-20220922T214326Z/algo-1", { "id": "m1", "yAxis": "left", "visible": false } ],
+ [ ".", "GPUUtilization", ".", ".", { "id": "m2", "visible": false } ],
+ [ ".", "CPUUtilization", ".", "hetero-tf-data-service-Dnode2-wrkrs-1-20220922T214326Z/algo-2", { "id": "m3", "visible": false } ],
+ [ "...", "hetero-tf-data-service-Dnode2-wrkrs-1-20220922T214326Z/algo-3", { "id": "m4", "visible": false } ]
+ ],
+ "sparkline": true,
+ "view": "timeSeries",
+ "stacked": false,
+ "region": "us-east-1",
+ "stat": "Average",
+ "period": 60,
+ "setPeriodToTimeRange": true,
+ "yAxis": {
+ "left": {
+ "min": 0,
+ "max": 100,
+ "label": "% Utilization",
+ "showUnits": false
+ }
+ },
+ "legend": {
+ "position": "bottom"
+ }
+}
\ No newline at end of file
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/cloudwatch-metric-definitions/homogenous-workload copy.json b/training/heterogeneous-clusters/tf.data.service.sagemaker/cloudwatch-metric-definitions/homogenous-workload copy.json
new file mode 100644
index 0000000000..c514eced5a
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/cloudwatch-metric-definitions/homogenous-workload copy.json
@@ -0,0 +1,26 @@
+{
+ "sparkline": true,
+ "metrics": [
+ [ { "expression": "100*(m1/9600)", "label": "CPU/100%", "id": "e1" } ],
+ [ { "expression": "100*(m2/800)", "label": "GPU/100%", "id": "e2" } ],
+ [ "/aws/sagemaker/TrainingJobs", "CPUUtilization", "Host", "hetero-tf-data-local-Dnode1-wrkrs-1-20220921T213920Z/algo-1", { "id": "m1", "visible": false } ],
+ [ ".", "GPUUtilization", ".", ".", { "id": "m2", "visible": false } ]
+ ],
+ "view": "timeSeries",
+ "stacked": false,
+ "region": "us-east-1",
+ "stat": "Average",
+ "period": 60,
+ "setPeriodToTimeRange": true,
+ "yAxis": {
+ "left": {
+ "min": 0,
+ "max": 100,
+ "label": "% Utilization",
+ "showUnits": false
+ }
+ },
+ "legend": {
+ "position": "bottom"
+ }
+}
\ No newline at end of file
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/code/launcher.py b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/launcher.py
new file mode 100644
index 0000000000..d67b27af7d
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/launcher.py
@@ -0,0 +1,123 @@
+import sys
+import os
+import time
+from typing import Optional
+import subprocess
+
+# instance group names
+DATA_GROUP = 'data_group'
+DNN_GROUP = 'dnn_group'
+
+
+def start_child_process_async(name : str, additional_args=[]) -> int:
+ #TODO: Find a way to stream stdout and stderr to the parent process
+ params = ["python", f"./{name}"] + sys.argv[1:] + additional_args
+ print(f'Opening process async: {params}')
+ p = subprocess.Popen(params)
+ print(f'Process {name} started')
+ return p.pid
+
+
+def start_child_process(name : str, additional_args=[]) -> int:
+ params = ["python", f"./{name}"] + sys.argv[1:] + additional_args
+ print(f'Opening process: {params}')
+ p = subprocess.run(params)
+ print(f'Process {name} closed with returncode={p.returncode}')
+ return p.returncode
+
+
+def start_data_group(dispatcher_host : str) -> int:
+ return start_child_process('train_data.py', ["--dispatcher_host", dispatcher_host])
+
+
+def not_mpi_or_rank_0() -> bool:
+ return 'OMPI_COMM_WORLD_LOCAL_RANK' not in os.environ or os.environ['OMPI_COMM_WORLD_LOCAL_RANK'] == '0'
+
+
+def start_dnn_group(dispatcher_host : Optional[str]) -> int:
+ if dispatcher_host is not None:
+ args = ["--dispatcher_host", dispatcher_host]
+ # Start a tf.data.service worker processes for each host in the DNN group
+ # to take advantage of its CPU resources.
+ # Start once per instance, not per MPI process
+ if not_mpi_or_rank_0():
+ start_child_process_async('train_data.py', args)
+ else:
+ args = []
+ return start_child_process('train_dnn.py', args)
+
+
+def get_group_first_host(instance_groups, target_group_name):
+ return instance_groups[target_group_name]['hosts'][0]
+
+
+def is_not_mpi_or_world_rank_0() -> bool:
+ return 'OMPI_COMM_WORLD_RANK' in os.environ and os.environ['OMPI_COMM_WORLD_RANK'] != '0'
+
+
+def shutdown_tf_data_service_with_retries(hosts : list):
+ # only world rank 0 process should shutdown the dispatcher
+ if is_not_mpi_or_world_rank_0():
+ return
+
+ completed_hosts = []
+ for host in hosts:
+ for i in range(0,12):
+ try:
+ if i>0:
+ sleeptime = 10
+ print(f'Will attempt {i} time to shutdown in {sleeptime} seconds')
+ time.sleep(sleeptime)
+
+ if host not in completed_hosts:
+ _shutdown_data_service(host)
+ completed_hosts.append(host)
+ break
+ except Exception as e:
+ print(f'Failed to shutdown dispatcher in {host} due to: {e}')
+
+
+def _shutdown_data_service(dispatcher_host : str):
+ SHUTDOWN_PORT = 16000
+ print(f'Shutting down tf.data.service dispatcher via: [{dispatcher_host}:{SHUTDOWN_PORT}]')
+ import socket
+ with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
+ s.connect((dispatcher_host, SHUTDOWN_PORT))
+ print(f'Shutdown request sent to {dispatcher_host}:{SHUTDOWN_PORT}')
+
+
+def split_to_instance_group_train_script() -> int:
+ from sagemaker_training import environment
+ env = environment.Environment()
+
+ print(f'env.is_hetero={env.is_hetero}')
+ print(f'current_host={env.current_host}')
+
+ if env.is_hetero:
+ dispatcher_host = get_group_first_host(env.instance_groups_dict, DATA_GROUP)
+ first_host_in_dnn_group = get_group_first_host(env.instance_groups_dict, DNN_GROUP)
+ print(f'current_instance_type={env.current_instance_type}')
+ print(f'current_group_name={env.current_instance_group}')
+ print(f'dispatcher_host={dispatcher_host}')
+ if env.current_instance_group == DATA_GROUP:
+ return start_data_group(dispatcher_host)
+ elif env.current_instance_group == DNN_GROUP:
+ returncode = start_dnn_group(dispatcher_host)
+ # first host in DNN group will take care of shutting down the dispatcher
+ if env.current_host == first_host_in_dnn_group:
+ hosts = env.instance_groups_dict[DATA_GROUP]['hosts'] + env.instance_groups_dict[DNN_GROUP]['hosts']
+ shutdown_tf_data_service_with_retries(hosts)
+ return returncode
+ else:
+ raise Exception(f'Unknown instance group: {env.current_instance_group}')
+
+ else: # not heterogenous
+ return start_dnn_group(dispatcher_host=None)
+
+if __name__ == "__main__":
+ try:
+ returncode = split_to_instance_group_train_script()
+ exit(returncode)
+ except Exception as e:
+ print(f'Failed due to {e}. exiting with returncode=1')
+ sys.exit(1)
\ No newline at end of file
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/code/requirements.txt b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/requirements.txt
new file mode 100644
index 0000000000..10aac59994
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/requirements.txt
@@ -0,0 +1,2 @@
+protobuf==3.20.2
+tensorflow-addons==0.17.0
\ No newline at end of file
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/code/train_data.py b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/train_data.py
new file mode 100644
index 0000000000..62248d1e68
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/train_data.py
@@ -0,0 +1,68 @@
+from tensorflow.data.experimental.service import DispatchServer, WorkerServer, DispatcherConfig, WorkerConfig
+
+def wait_for_shutdown_signal(dispatcher, workers):
+ SHUTDOWN_PORT = 16000
+ import socket
+ s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
+ s.bind(('', SHUTDOWN_PORT))
+ s.listen(1)
+ print('Awaiting shutdown signal on port {}'.format(SHUTDOWN_PORT))
+ conn, addr = s.accept()
+ print('Received shutdown signal from: ', addr)
+ try:
+ conn.close()
+ s.close()
+ except Exception as e:
+ print(e)
+
+ if dispatcher is not None: # dispatcher runs only on the 1st data instance
+ print('Stopping dispatcher.')
+ dispatcher._stop()
+ print('Joining dispatcher')
+ dispatcher.join()
+
+ for i,worker in enumerate(workers, start=0):
+ print(f'Stopping worker {i}')
+ worker._stop()
+ print(f'Joining worker {i}')
+ worker.join()
+
+def create_worker(workerIndex : int, dispatcher_host : str, current_host : str) -> WorkerServer:
+ port = 6001 + workerIndex
+ w_config = WorkerConfig(port=port,
+ dispatcher_address=f'{dispatcher_host}:6000',
+ worker_address=f'{current_host}:{port}')
+ print(f'Starting tf.data.service WorkerServer {w_config}')
+ worker = WorkerServer(w_config)
+ return worker
+
+def start_dispatcher_and_worker(dispatcher_host : str, current_host : str, num_of_data_workers : int):
+ assert(dispatcher_host is not None)
+
+ if current_host == dispatcher_host:
+ print(f'starting Dispatcher (dispatcher_host={dispatcher_host})')
+ d_config = DispatcherConfig(port=6000)
+ dispatcher = DispatchServer(d_config)
+ else:
+ dispatcher = None
+
+ workers = [ create_worker(i, dispatcher_host, current_host) for i in range(num_of_data_workers) ]
+ print(f'Finished starting dispatcher and {num_of_data_workers} workers')
+
+ wait_for_shutdown_signal(dispatcher, workers)
+
+
+"This function read mode command line argument"
+def read_args():
+ import argparse, os
+ parser = argparse.ArgumentParser()
+ parser.add_argument("--dispatcher_host", type=str)
+ parser.add_argument("--current_host", type=str, default=os.environ["SM_CURRENT_HOST"])
+ parser.add_argument("--num_of_data_workers", type=int)
+ args, unknown = parser.parse_known_args()
+ return args
+
+
+if __name__ == "__main__":
+ args = read_args()
+ start_dispatcher_and_worker(args.dispatcher_host, args.current_host, args.num_of_data_workers)
\ No newline at end of file
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/code/train_dnn.py b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/train_dnn.py
new file mode 100644
index 0000000000..cd938b46c7
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/code/train_dnn.py
@@ -0,0 +1,153 @@
+from tensorflow.keras.layers.experimental import preprocessing
+from tensorflow.keras.applications.resnet50 import ResNet50
+import tensorflow_addons as tfa
+import tensorflow as tf
+import os
+import horovod.tensorflow.keras as hvd
+
+
+# dilation filter
+def dilate(image, label):
+ dilateFilter = tf.zeros([3, 3, 3], tf.uint8)
+ image = tf.expand_dims(image, 0)
+ image = tf.nn.dilation2d(
+ image, dilateFilter, strides=[1, 1, 1, 1],
+ dilations=[1, 1, 1, 1],
+ padding='SAME',
+ data_format='NHWC')
+ image = tf.squeeze(image)
+ return image, label
+# blur filter
+
+
+def blur(image, label):
+ image = tfa.image.gaussian_filter2d(image=image,
+ filter_shape=(11, 11), sigma=0.8)
+ return image, label
+
+# rescale filter
+def rescale(image, label):
+ image = preprocessing.Rescaling(1.0 / 255)(image)
+ return image, label
+
+
+# augmentation filters
+def augment(image, label):
+ data_augmentation = tf.keras.Sequential(
+ [preprocessing.RandomFlip("horizontal"),
+ preprocessing.RandomRotation(0.1),
+ preprocessing.RandomZoom(0.1)])
+ image = data_augmentation(image)
+ return image, label
+
+
+# This function generates a dataset consisting 32x32x3 random images
+# And a corresponding random label representing 10 different classes.
+# As this dataset is randomly generated, you should not expect the model
+# to converge in a meaningful way, it doesn't matter as our intent is
+# only to measure data pipeline and DNN optimization throughput
+def generate_artificial_dataset():
+ import numpy as np
+ x_train = np.random.randint(0, 255, size=(32000, 32, 32, 3), dtype=np.uint8)
+ y_train = np.random.randint(0, 10, size=(32000,1))
+ train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
+ return train_dataset
+
+
+def get_dataset(batch_size : int, use_tf_data_service : bool, dispatcher_host : str):
+ autotune = tf.data.experimental.AUTOTUNE
+ options = tf.data.Options()
+ options.experimental_deterministic = False
+
+ ds = generate_artificial_dataset().shuffle(10000).repeat()
+
+ ds = ds.map(dilate, num_parallel_calls=autotune)
+ ds = ds.map(blur, num_parallel_calls=autotune)
+ ds = ds.map(rescale,num_parallel_calls=autotune)
+ ds = ds.map(augment, num_parallel_calls=autotune)
+ ds = ds.batch(batch_size)
+
+ if use_tf_data_service:
+ ds = ds.apply(tf.data.experimental.service.distribute(
+ processing_mode="parallel_epochs",
+ service=f'grpc://{dispatcher_host}:6000',),
+ )
+
+ #ds = ds.take(1).cache().repeat()
+ ds = ds.prefetch(autotune)
+ return ds
+
+"This function read mode command line argument"
+def read_args():
+ import argparse
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--tf_data_mode', type=str, default='local',
+ help="'service' distributed dataset using tf.data.service. 'local' use standard tf.data")
+ parser.add_argument('--steps_per_epoch', type=int, default=1)
+ parser.add_argument('--batch_size', type=int)
+ parser.add_argument('--epochs', type=int, default=1)
+ parser.add_argument("--n_gpus", type=str,
+ default=os.environ.get("SM_NUM_GPUS"))
+ parser.add_argument("--dispatcher_host", type=str)
+ parser.add_argument("--num_of_data_workers", type=int, default=1)
+ parser.add_argument("--output_data_dir", type=str,
+ default=os.environ.get("SM_OUTPUT_DATA_DIR"))
+ parser.add_argument("--model_dir", type=str,
+ default=os.environ.get("SM_MODEL_DIR"))
+ parser.add_argument("--checkpoint-path",type=str,default="/opt/ml/checkpoints",help="Path where checkpoints are saved.")
+ args = parser.parse_args()
+ return args
+
+if __name__ == "__main__":
+ args = read_args()
+ hvd.init()
+ # Horovod: pin GPU to be used to process local rank (one GPU per process)
+ gpus = tf.config.experimental.list_physical_devices('GPU')
+ print(str(gpus))
+ for gpu in gpus:
+ tf.config.experimental.set_memory_growth(gpu, True)
+ if gpus:
+ print(f'hvd.local_rank() {hvd.local_rank()}')
+ tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')
+
+ model = ResNet50(weights=None,
+ input_shape=(32, 32, 3),
+ classes=10)
+
+ model.compile(loss=tf.losses.SparseCategoricalCrossentropy(),
+ optimizer=tf.optimizers.Adam())
+ # Horovod: adjust learning rate based on number of GPUs.
+ scaled_lr = 0.001 * hvd.size()
+ opt = tf.optimizers.Adam(scaled_lr)
+ opt = hvd.DistributedOptimizer(
+ opt, backward_passes_per_step=1, average_aggregated_gradients=True)
+
+ model.compile(loss=tf.losses.SparseCategoricalCrossentropy(),
+ optimizer=opt,
+ experimental_run_tf_function=False)
+
+ callbacks = [
+ hvd.callbacks.BroadcastGlobalVariablesCallback(0),
+ hvd.callbacks.MetricAverageCallback(),
+ hvd.callbacks.LearningRateWarmupCallback(initial_lr=scaled_lr, warmup_epochs=3, verbose=1),
+ ]
+ # Horovod: save checkpoints only on worker 0 to prevent other workers from corrupting them.
+ if hvd.rank() == 0:
+ path = os.path.join(args.checkpoint_path, './checkpoint-{epoch}.h5')
+ callbacks.append(tf.keras.callbacks.ModelCheckpoint(path))
+
+ # Horovod: write logs on worker 0.
+ verbose = 1 if hvd.rank() == 0 else 0
+
+ assert(args.tf_data_mode == 'local' or args.tf_data_mode == 'service')
+ print(f'Running in {args.tf_data_mode} tf_data_mode.')
+ dataset = get_dataset(batch_size = args.batch_size, use_tf_data_service=(args.tf_data_mode == 'service'), dispatcher_host = args.dispatcher_host)
+
+ model.fit( dataset,
+ steps_per_epoch=args.steps_per_epoch,
+ callbacks=callbacks,
+ epochs=args.epochs,
+ verbose=2,)
+
+ if hvd.rank() == 0:
+ model.save(os.path.join(args.model_dir, '000000001'), 'my_model.h5')
\ No newline at end of file
diff --git a/training/heterogeneous-clusters/tf.data.service.sagemaker/hetero-tensorflow-restnet50.ipynb b/training/heterogeneous-clusters/tf.data.service.sagemaker/hetero-tensorflow-restnet50.ipynb
new file mode 100644
index 0000000000..61cdc56cf5
--- /dev/null
+++ b/training/heterogeneous-clusters/tf.data.service.sagemaker/hetero-tensorflow-restnet50.ipynb
@@ -0,0 +1,1136 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# TensorFlow's tf.data.service with Amazon SageMaker Training Heterogeneous Clusters\n",
+ "\n",
+ "---\n",
+ "### Introduction\n",
+ "\n",
+ "Heterogeneous clusters enable launching training jobs that use multiple instance types in a single job. This capability can improve your training cost and speed by running different parts of the model training on the most suitable instance type. This use case typically happens in computer vision (CV) deep learning (DL) training, where training is bottleneck on CPU resources needed for data augmentation, leaving the expensive GPU underutilized. Heterogeneous clusters enable you to add more CPU resources to fully utilize GPUs to increase training speed and cost-efficiency. For more details, you can find the documentation of this feature [here](https://docs.aws.amazon.com/sagemaker/latest/dg/train-heterogeneous-cluster.html).\n",
+ "\n",
+ "This notebook demonstrates how to use Heterogeneous Clusters with TensorFlow's [tf.data.service](https://www.TensorFlow.org/api_docs/python/tf/data/experimental/service). It includes training a CPU intensive DL CV workload. Comparing cost and performance between homogeneous and heterogeneous training configurations. \n",
+ "\n",
+ "💡To get started quickly with heterogeneous clusters, we suggest you'll reuse the provided code as a quick way to migrate your workload from a local tf.data pipeline to a distributed tf.data.service pipeline. You'll need to change [code/train_dnn.py](./code/train_dnn.py), while keeping [code/train_data.py](./code/train_data.py) and [code/launcher.py](code/launcher.py) intact. This is explained below in the [Workload Details] section.\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "This notebook covers:\n",
+ "- A guide to switching from a homogeneous job (single instance type) to a heterogeneous job (multiple instance types)\n",
+ "- Explaining to use Heterogeneous clusters with TensorFlow's tf.data.service\n",
+ "- Set up Amazon SageMaker Studio Notebook \n",
+ "- Run homogeneous cluster training job \n",
+ "- Run heterogeneous cluster training job \n",
+ "- Compare time and cost to train between homogeneous and heterogeneous clusters\n",
+ "- Conclusion\n",
+ "\n",
+ "---"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### A guide to switching from a homogeneous to a heterogeneous job\n",
+ "\n",
+ "This notebook runs and compares these two workloads:\n",
+ "\n",
+ "Homogeneous Training Job - The image shows a ml.p4d.24xlarge instance GPUs is under-utilized due to a CPU bottleneck. \n",
+ " \n",
+ " \n",
+ "Heterogeneous Training Job - The image shows two ml.c5.18xlarge instances with extra CPU cores, to reduce the CPU bottleneck and increase GPU usage, to improve training speed cost-efficiency. \n",
+ "
\n",
+ " \n",
+ "Heterogeneous Training Job - The image shows two ml.c5.18xlarge instances with extra CPU cores, to reduce the CPU bottleneck and increase GPU usage, to improve training speed cost-efficiency. \n",
+ "  \n",
+ "\n",
+ "In each workload: Training data is an artificially generated dataset consisting of 32x32x3 images with random pixel values, and a corresponding random label representing 10 different classes. As this dataset is randomly generated, you should not expect the model to converge in a meaningful way. This shouldn't matter as our intent is only to measure data pipeline and neural network optimization throughput expressed in epoch/step time. \n",
+ "The model we used is [Resnet50](https://www.TensorFlow.org/api_docs/python/tf/keras/applications/ResNet50). The workloads uses an 8 GPUs instance, ml.p4d.24xlarge, and uses Horovod for data parallelization. \n",
+ "\n",
+ "The heterogeneous job will include two instance groups:\n",
+ "- **data_group** - A group of CPU instances that will run data pre-processing code.\n",
+ "- **dnn_group** - A group of GPU instances that will run Deep Neural Network training code.\n",
+ "\n",
+ "In this example, the inter-node communication between CPU and GPU instance groups is implemented using [TensorFlow data service feature](https://www.TensorFlow.org/api_docs/python/tf/data/experimental/service). This feature allows offloading a configurable amount of preprocessing work to worker machines. Note that SageMaker's Heterogeneous cluster does not provide out-of-the-box support for inter-instance_group communication, and it is up to the user to implement (we provide reference implementation here).\n",
+ "\n",
+ "This notebook refers following files and folders:\n",
+ "- [code/train_dnn.py](./code/train_dnn.py) - this is standard TF training script, it has a single reference to tf.data.service when setting up the tf.data pipeline. This script will be executed on GPU instances belonging to the dnn_group.\n",
+ "- [code/train_data.py](./code/train_data.py) - this script starts tf.data.service services like a tf.data.service Dispatcher and tf.data.service Worker processes. You shouldn't edit this script when adjusting to your workload.\n",
+ "- [code/launcher.py](./code/launcher.py) - Entry point training script. This is the script that SageMaker Training will start on all instances (all instances groups must share the same entry point script in heterogeneous clusters). `launcher.py` is responsible for detecting the instance group the instance belong to, and start `train_dnn.py` and `train_data.py` accordingly. It is also responsible for shutting down tf.data.services the training script completes (`train_dnn.py`) so all instances exit allowing the SageMaker training job to complete. \n",
+ "In every instance `luncher.py` will use `train_data.py` to start a tf.data.service worker server (As all instance types have CPUs that could be used for preprocessing). `luncher.py` will start a single tf.data.service dispatcher server (on the first instance of the `data_group`). \n",
+ "`luncher.py` will start the `train_dnn.py` script in all GPU instances (`dnn_group` instances).\n",
+ "\n",
+ "#### Learn more about tf.data.service processes\n",
+ "`tf.data.service Dispatcher` - The dispatcher server acts as the control plain for tf.data.service; Being responsible for registering worker servers and assigning preprocessing tasks to them. Each training job has a single Dispatcher running in the first instance of the `data_group` and listens on port 6000.\n",
+ "`tf.data.service Workers` - Worker servers carry out the data processing. Each instance could have one or more workers (listen on port 6001/6002/...).\n",
+ "\n",
+ "##### Defining what part of your pipeline runs in which instance group\n",
+ " When you apply `tf.data.experimental.service.distribute()` on your dataset, all preprocessing operations defined up to the apply will run on the tf.data.service workers, and all dataset operations defined afterwords will run on the local process. All instances will need access to a dataset you'll make available through a SageMaker training data channel. You do have the option of limiting which instance group will see which training data channel.\n",
+ "\n",
+ "The below figure shows sequence of events of setting up and running in a tf.data.service based heterogeneous cluster training job.\n",
+ "\n",
+ "
\n",
+ "\n",
+ "In each workload: Training data is an artificially generated dataset consisting of 32x32x3 images with random pixel values, and a corresponding random label representing 10 different classes. As this dataset is randomly generated, you should not expect the model to converge in a meaningful way. This shouldn't matter as our intent is only to measure data pipeline and neural network optimization throughput expressed in epoch/step time. \n",
+ "The model we used is [Resnet50](https://www.TensorFlow.org/api_docs/python/tf/keras/applications/ResNet50). The workloads uses an 8 GPUs instance, ml.p4d.24xlarge, and uses Horovod for data parallelization. \n",
+ "\n",
+ "The heterogeneous job will include two instance groups:\n",
+ "- **data_group** - A group of CPU instances that will run data pre-processing code.\n",
+ "- **dnn_group** - A group of GPU instances that will run Deep Neural Network training code.\n",
+ "\n",
+ "In this example, the inter-node communication between CPU and GPU instance groups is implemented using [TensorFlow data service feature](https://www.TensorFlow.org/api_docs/python/tf/data/experimental/service). This feature allows offloading a configurable amount of preprocessing work to worker machines. Note that SageMaker's Heterogeneous cluster does not provide out-of-the-box support for inter-instance_group communication, and it is up to the user to implement (we provide reference implementation here).\n",
+ "\n",
+ "This notebook refers following files and folders:\n",
+ "- [code/train_dnn.py](./code/train_dnn.py) - this is standard TF training script, it has a single reference to tf.data.service when setting up the tf.data pipeline. This script will be executed on GPU instances belonging to the dnn_group.\n",
+ "- [code/train_data.py](./code/train_data.py) - this script starts tf.data.service services like a tf.data.service Dispatcher and tf.data.service Worker processes. You shouldn't edit this script when adjusting to your workload.\n",
+ "- [code/launcher.py](./code/launcher.py) - Entry point training script. This is the script that SageMaker Training will start on all instances (all instances groups must share the same entry point script in heterogeneous clusters). `launcher.py` is responsible for detecting the instance group the instance belong to, and start `train_dnn.py` and `train_data.py` accordingly. It is also responsible for shutting down tf.data.services the training script completes (`train_dnn.py`) so all instances exit allowing the SageMaker training job to complete. \n",
+ "In every instance `luncher.py` will use `train_data.py` to start a tf.data.service worker server (As all instance types have CPUs that could be used for preprocessing). `luncher.py` will start a single tf.data.service dispatcher server (on the first instance of the `data_group`). \n",
+ "`luncher.py` will start the `train_dnn.py` script in all GPU instances (`dnn_group` instances).\n",
+ "\n",
+ "#### Learn more about tf.data.service processes\n",
+ "`tf.data.service Dispatcher` - The dispatcher server acts as the control plain for tf.data.service; Being responsible for registering worker servers and assigning preprocessing tasks to them. Each training job has a single Dispatcher running in the first instance of the `data_group` and listens on port 6000.\n",
+ "`tf.data.service Workers` - Worker servers carry out the data processing. Each instance could have one or more workers (listen on port 6001/6002/...).\n",
+ "\n",
+ "##### Defining what part of your pipeline runs in which instance group\n",
+ " When you apply `tf.data.experimental.service.distribute()` on your dataset, all preprocessing operations defined up to the apply will run on the tf.data.service workers, and all dataset operations defined afterwords will run on the local process. All instances will need access to a dataset you'll make available through a SageMaker training data channel. You do have the option of limiting which instance group will see which training data channel.\n",
+ "\n",
+ "The below figure shows sequence of events of setting up and running in a tf.data.service based heterogeneous cluster training job.\n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### security groups update if running in private VPC\n",
+ "This section is relevant if you plan to [run in a private VPC](https://docs.aws.amazon.com/sagemaker/latest/dg/train-vpc.html) (passing `subnets` and `security_group_ids` parameters when defining an Estimator). \n",
+ "SageMaker documentation recommends you [add](https://docs.aws.amazon.com/sagemaker/latest/dg/train-vpc.html#train-vpc-vpc) a rule for your security group that allows inbound connections between members of the same security group, for all TCP communication. This will also cover for the tf.data.service related traffic between instances:\n",
+ "- tf.data.service Dispatcher node will listen for incoming connections on port 6000 (configurable) from all nodes.\n",
+ "- tf.data.service Workers will listen on ports 6001-6006 from all nodes.\n",
+ "- Each node listens on port 16000 for a tf.data.service shutdown signal from all nodes."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### A. Set up SageMaker Studio notebook\n",
+ "#### Before you start\n",
+ "Ensure you have selected Python 3 (_TensorFlow 2.6 Python 3.8 CPU Optimized_) image for your SageMaker Studio Notebook instance, and running on _ml.t3.medium_ instance type.\n",
+ "\n",
+ "#### Step 1 - Upgrade SageMaker SDK and dependent packages \n",
+ "Heterogeneous Clusters for Amazon SageMaker model training was [announced](https://aws.amazon.com/about-aws/whats-new/2022/07/announcing-heterogeneous-clusters-amazon-sagemaker-model-training) on 07/08/2022. This feature release requires you to have updated SageMaker SDK, Boto3 client."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Requirement already satisfied: boto3 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (1.24.72)\n",
+ "Collecting boto3\n",
+ " Downloading boto3-1.24.80-py3-none-any.whl (132 kB)\n",
+ " ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 132.5/132.5 kB 925.9 kB/s eta 0:00:00\n",
+ "Requirement already satisfied: botocore in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (1.27.72)\n",
+ "Collecting botocore\n",
+ " Downloading botocore-1.27.80-py3-none-any.whl (9.1 MB)\n",
+ " ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 9.1/9.1 MB 16.4 MB/s eta 0:00:00\n",
+ "Requirement already satisfied: awscli in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (1.25.73)\n",
+ "Collecting awscli\n",
+ " Downloading awscli-1.25.81-py3-none-any.whl (3.9 MB)\n",
+ " ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.9/3.9 MB 38.4 MB/s eta 0:00:00\n",
+ "Requirement already satisfied: sagemaker in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (2.109.0)\n",
+ "Requirement already satisfied: s3transfer<0.7.0,>=0.6.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from boto3) (0.6.0)\n",
+ "Requirement already satisfied: jmespath<2.0.0,>=0.7.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/jmespath-1.0.0-py3.9.egg (from boto3) (1.0.0)\n",
+ "Requirement already satisfied: urllib3<1.27,>=1.25.4 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/urllib3-1.26.9-py3.9.egg (from botocore) (1.26.9)\n",
+ "Requirement already satisfied: python-dateutil<3.0.0,>=2.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/python_dateutil-2.8.2-py3.9.egg (from botocore) (2.8.2)\n",
+ "Requirement already satisfied: PyYAML<5.5,>=3.10 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from awscli) (5.4.1)\n",
+ "Requirement already satisfied: docutils<0.17,>=0.10 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from awscli) (0.16)\n",
+ "Requirement already satisfied: colorama<0.4.5,>=0.2.5 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from awscli) (0.4.4)\n",
+ "Requirement already satisfied: rsa<4.8,>=3.1.2 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from awscli) (4.7.2)\n",
+ "Requirement already satisfied: importlib-metadata<5.0,>=1.4.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/importlib_metadata-4.11.3-py3.9.egg (from sagemaker) (4.11.3)\n",
+ "Requirement already satisfied: pathos in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pathos-0.2.8-py3.9.egg (from sagemaker) (0.2.8)\n",
+ "Requirement already satisfied: protobuf3-to-dict<1.0,>=0.1.5 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/protobuf3_to_dict-0.1.5-py3.9.egg (from sagemaker) (0.1.5)\n",
+ "Requirement already satisfied: pandas in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pandas-1.4.2-py3.9-macosx-10.9-x86_64.egg (from sagemaker) (1.4.2)\n",
+ "Requirement already satisfied: numpy<2.0,>=1.9.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from sagemaker) (1.22.4)\n",
+ "Requirement already satisfied: attrs<22,>=20.3.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/attrs-20.3.0-py3.9.egg (from sagemaker) (20.3.0)\n",
+ "Requirement already satisfied: smdebug-rulesconfig==1.0.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/smdebug_rulesconfig-1.0.1-py3.9.egg (from sagemaker) (1.0.1)\n",
+ "Requirement already satisfied: google-pasta in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/google_pasta-0.2.0-py3.9.egg (from sagemaker) (0.2.0)\n",
+ "Requirement already satisfied: protobuf<4.0,>=3.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from sagemaker) (3.20.1)\n",
+ "Requirement already satisfied: packaging>=20.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/packaging-21.3-py3.9.egg (from sagemaker) (21.3)\n",
+ "Requirement already satisfied: zipp>=0.5 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/zipp-3.7.0-py3.9.egg (from importlib-metadata<5.0,>=1.4.0->sagemaker) (3.7.0)\n",
+ "Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pyparsing-3.0.7-py3.9.egg (from packaging>=20.0->sagemaker) (3.0.7)\n",
+ "Requirement already satisfied: six in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from protobuf3-to-dict<1.0,>=0.1.5->sagemaker) (1.15.0)\n",
+ "Requirement already satisfied: pyasn1>=0.1.3 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from rsa<4.8,>=3.1.2->awscli) (0.4.8)\n",
+ "Requirement already satisfied: pytz>=2020.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pytz-2022.1-py3.9.egg (from pandas->sagemaker) (2022.1)\n",
+ "Requirement already satisfied: dill>=0.3.4 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/dill-0.3.4-py3.9.egg (from pathos->sagemaker) (0.3.4)\n",
+ "Requirement already satisfied: multiprocess>=0.70.12 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/multiprocess-0.70.12.2-py3.9.egg (from pathos->sagemaker) (0.70.12.2)\n",
+ "Requirement already satisfied: pox>=0.3.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pox-0.3.0-py3.9.egg (from pathos->sagemaker) (0.3.0)\n",
+ "Requirement already satisfied: ppft>=1.6.6.4 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/ppft-1.6.6.4-py3.9.egg (from pathos->sagemaker) (1.6.6.4)\n",
+ "Installing collected packages: botocore, boto3, awscli\n",
+ " Attempting uninstall: botocore\n",
+ " Found existing installation: botocore 1.27.72\n",
+ " Uninstalling botocore-1.27.72:\n",
+ " Successfully uninstalled botocore-1.27.72\n",
+ " Attempting uninstall: boto3\n",
+ " Found existing installation: boto3 1.24.72\n",
+ " Uninstalling boto3-1.24.72:\n",
+ " Successfully uninstalled boto3-1.24.72\n",
+ " Attempting uninstall: awscli\n",
+ " Found existing installation: awscli 1.25.73\n",
+ " Uninstalling awscli-1.25.73:\n",
+ " Successfully uninstalled awscli-1.25.73\n"
+ ]
+ },
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\n",
+ "sagemaker-training 4.2.2 requires protobuf<3.20,>=3.9.2, but you have protobuf 3.20.1 which is incompatible.\n"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Successfully installed awscli-1.25.81 boto3-1.24.80 botocore-1.27.80\n"
+ ]
+ }
+ ],
+ "source": [
+ "%%bash\n",
+ "python3 -m pip install --upgrade boto3 botocore awscli sagemaker"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Step 2 - Restart the notebook kernel "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#import IPython\n",
+ "#IPython.Application.instance().kernel.do_shutdown(True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Step 3 - Validate SageMaker Python SDK and TensorFlow versions\n",
+ "Ensure the output of the cell below reflects:\n",
+ "\n",
+ "- SageMaker Python SDK version 2.98.0 or above, \n",
+ "- boto3 1.24 or above \n",
+ "- botocore 1.27 or above \n",
+ "- TensorFlow 2.6 or above "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Name: sagemaker\n",
+ "Version: 2.109.0\n",
+ "---\n",
+ "Name: boto3\n",
+ "Version: 1.24.80\n",
+ "---\n",
+ "Name: botocore\n",
+ "Version: 1.27.80\n",
+ "---\n",
+ "Name: tensorflow\n",
+ "Version: 2.8.0\n",
+ "---\n",
+ "Name: protobuf\n",
+ "Version: 3.20.1\n"
+ ]
+ }
+ ],
+ "source": [
+ "!pip show sagemaker boto3 botocore tensorflow protobuf |egrep 'Name|Version|---'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import json\n",
+ "import datetime\n",
+ "\n",
+ "import sagemaker\n",
+ "from sagemaker import get_execution_role\n",
+ "from sagemaker.instance_group import InstanceGroup\n",
+ "\n",
+ "sess = sagemaker.Session()\n",
+ "role = get_execution_role()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### C. Run a homogeneous training job\n",
+ "#### Step 1: Set up the training environment\n",
+ "In this step, we define and submit a homogeneous training job. It uses a single instance type (p4d.24xlarge) with 8 GPUs. The analysis of the job will shows that it is CPU bound and therefore its GPUs are underutilized."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import datetime\n",
+ "from sagemaker.tensorflow import TensorFlow\n",
+ "from sagemaker.instance_group import InstanceGroup\n",
+ "import os\n",
+ "\n",
+ "hyperparameters = {\n",
+ " \"epochs\": 10,\n",
+ " \"steps_per_epoch\": 500,\n",
+ " \"batch_size\": 1024,\n",
+ " \"tf_data_mode\": \"local\", # We won't be using tf.data.service ('service') for this homogeneous job\n",
+ " \"num_of_data_workers\": 0, # We won't be using tf.data.service ('service') for this homogeneous job\n",
+ "}\n",
+ "\n",
+ "estimator = TensorFlow(\n",
+ " entry_point=\"launcher.py\",\n",
+ " source_dir=\"code\",\n",
+ " framework_version=\"2.9.1\",\n",
+ " py_version=\"py39\",\n",
+ " role=role,\n",
+ " volume_size=10,\n",
+ " max_run=1800, # 30 minutes\n",
+ " disable_profiler=True,\n",
+ " instance_type=\"ml.p4d.24xlarge\",\n",
+ " instance_count=1,\n",
+ " hyperparameters=hyperparameters,\n",
+ " distribution={\n",
+ " \"mpi\": {\n",
+ " \"enabled\": True,\n",
+ " \"processes_per_host\": 8, # 8 GPUs per host\n",
+ " \"custom_mpi_options\": \"--NCCL_DEBUG WARN\",\n",
+ " },\n",
+ " },\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Step 2: Submit the training job\n",
+ "\n",
+ "Note: For the logs, click on **View logs** from the **Training Jobs** node in **Amazon SageMaker Console**. \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 17,
+ "metadata": {
+ "collapsed": true,
+ "jupyter": {
+ "outputs_hidden": true
+ }
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "2022-09-24 11:28:23 Starting - Starting the training job......\n",
+ "2022-09-24 11:29:08 Starting - Preparing the instances for training........................\n",
+ "2022-09-24 11:33:34 Downloading - Downloading input data\n",
+ "2022-09-24 11:33:34 Training - Downloading the training image..................\n",
+ "2022-09-24 11:37:00 Training - Training image download completed. Training in progress..2022-09-24 11:37:05.792579: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.\n",
+ "2022-09-24 11:37:05.801314: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.\n",
+ "2022-09-24 11:37:06.269740: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.\n",
+ "2022-09-24 11:37:13,412 sagemaker-training-toolkit INFO Imported framework sagemaker_tensorflow_container.training\n",
+ "2022-09-24 11:37:14,075 sagemaker-training-toolkit INFO Installing dependencies from requirements.txt:\n",
+ "/usr/local/bin/python3.9 -m pip install -r requirements.txt\n",
+ "Collecting protobuf==3.20.1\n",
+ "Downloading protobuf-3.20.1-cp39-cp39-manylinux_2_5_x86_64.manylinux1_x86_64.whl (1.0 MB)\n",
+ "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.0/1.0 MB 39.6 MB/s eta 0:00:00\n",
+ "Collecting tensorflow-addons==0.17.0\n",
+ "Downloading tensorflow_addons-0.17.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.1 MB)\n",
+ "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 51.6 MB/s eta 0:00:00\n",
+ "Requirement already satisfied: packaging in /usr/local/lib/python3.9/site-packages (from tensorflow-addons==0.17.0->-r requirements.txt (line 2)) (21.3)\n",
+ "Requirement already satisfied: typeguard>=2.7 in /usr/local/lib/python3.9/site-packages (from tensorflow-addons==0.17.0->-r requirements.txt (line 2)) (2.13.3)\n",
+ "Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /usr/local/lib/python3.9/site-packages (from packaging->tensorflow-addons==0.17.0->-r requirements.txt (line 2)) (3.0.9)\n",
+ "Installing collected packages: protobuf, tensorflow-addons\n",
+ "Attempting uninstall: protobuf\n",
+ "Found existing installation: protobuf 3.19.4\n",
+ "Uninstalling protobuf-3.19.4:\n",
+ "Successfully uninstalled protobuf-3.19.4\n",
+ "Attempting uninstall: tensorflow-addons\n",
+ "Found existing installation: tensorflow-addons 0.17.1\n",
+ "Uninstalling tensorflow-addons-0.17.1:\n",
+ "Successfully uninstalled tensorflow-addons-0.17.1\n",
+ "ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\n",
+ "tf-models-official 2.9.1 requires tensorflow~=2.9.0, which is not installed.\n",
+ "tensorflow-gpu 2.9.1 requires protobuf<3.20,>=3.9.2, but you have protobuf 3.20.1 which is incompatible.\n",
+ "tensorboard 2.9.1 requires protobuf<3.20,>=3.9.2, but you have protobuf 3.20.1 which is incompatible.\n",
+ "sagemaker-training 4.1.4.dev0 requires protobuf<3.20,>=3.9.2, but you have protobuf 3.20.1 which is incompatible.\n",
+ "Successfully installed protobuf-3.20.1 tensorflow-addons-0.17.0\n",
+ "WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\n",
+ "[notice] A new release of pip available: 22.1.2 -> 22.2.2\n",
+ "[notice] To update, run: pip install --upgrade pip\n",
+ "2022-09-24 11:37:24,079 sagemaker-training-toolkit INFO Waiting for the process to finish and give a return code.\n",
+ "2022-09-24 11:37:24,079 sagemaker-training-toolkit INFO Done waiting for a return code. Received 0 from exiting process.\n",
+ "2022-09-24 11:37:24,258 sagemaker-training-toolkit INFO Starting MPI run as worker node.\n",
+ "2022-09-24 11:37:24,258 sagemaker-training-toolkit INFO Creating SSH daemon.\n",
+ "2022-09-24 11:37:24,274 sagemaker-training-toolkit INFO Waiting for MPI workers to establish their SSH connections\n",
+ "2022-09-24 11:37:24,274 sagemaker-training-toolkit INFO Env Hosts: ['algo-1'] Hosts: ['algo-1:8'] process_per_hosts: 8 num_processes: 8\n",
+ "2022-09-24 11:37:24,276 sagemaker-training-toolkit INFO Network interface name: eth0\n",
+ "2022-09-24 11:37:24,368 sagemaker-training-toolkit INFO Invoking user script\n",
+ "Training Env:\n",
+ "{\n",
+ " \"additional_framework_parameters\": {\n",
+ " \"sagemaker_mpi_custom_mpi_options\": \"--NCCL_DEBUG WARN\",\n",
+ " \"sagemaker_mpi_enabled\": true,\n",
+ " \"sagemaker_mpi_num_of_processes_per_host\": 8\n",
+ " },\n",
+ " \"channel_input_dirs\": {},\n",
+ " \"current_host\": \"algo-1\",\n",
+ " \"current_instance_group\": \"homogeneousCluster\",\n",
+ " \"current_instance_group_hosts\": [\n",
+ " \"algo-1\"\n",
+ " ],\n",
+ " \"current_instance_type\": \"ml.p4d.24xlarge\",\n",
+ " \"distribution_hosts\": [\n",
+ " \"algo-1\"\n",
+ " ],\n",
+ " \"distribution_instance_groups\": [\n",
+ " \"homogeneousCluster\"\n",
+ " ],\n",
+ " \"framework_module\": \"sagemaker_tensorflow_container.training:main\",\n",
+ " \"hosts\": [\n",
+ " \"algo-1\"\n",
+ " ],\n",
+ " \"hyperparameters\": {\n",
+ " \"batch_size\": 1024,\n",
+ " \"epochs\": 10,\n",
+ " \"model_dir\": \"/opt/ml/model\",\n",
+ " \"num_of_data_workers\": 0,\n",
+ " \"steps_per_epoch\": 500,\n",
+ " \"tf_data_mode\": \"local\"\n",
+ " },\n",
+ " \"input_config_dir\": \"/opt/ml/input/config\",\n",
+ " \"input_data_config\": {},\n",
+ " \"input_dir\": \"/opt/ml/input\",\n",
+ " \"instance_groups\": [\n",
+ " \"homogeneousCluster\"\n",
+ " ],\n",
+ " \"instance_groups_dict\": {\n",
+ " \"homogeneousCluster\": {\n",
+ " \"instance_group_name\": \"homogeneousCluster\",\n",
+ " \"instance_type\": \"ml.p4d.24xlarge\",\n",
+ " \"hosts\": [\n",
+ " \"algo-1\"\n",
+ " ]\n",
+ " }\n",
+ " },\n",
+ " \"is_hetero\": false,\n",
+ " \"is_master\": true,\n",
+ " \"job_name\": \"homogeneous-20220924T112821Z-1\",\n",
+ " \"log_level\": 20,\n",
+ " \"master_hostname\": \"algo-1\",\n",
+ " \"model_dir\": \"/opt/ml/model\",\n",
+ " \"module_dir\": \"s3://sagemaker-us-east-1-331113010199/homogeneous-20220924T112821Z-1/source/sourcedir.tar.gz\",\n",
+ " \"module_name\": \"launcher\",\n",
+ " \"network_interface_name\": \"eth0\",\n",
+ " \"num_cpus\": 96,\n",
+ " \"num_gpus\": 8,\n",
+ " \"output_data_dir\": \"/opt/ml/output/data\",\n",
+ " \"output_dir\": \"/opt/ml/output\",\n",
+ " \"output_intermediate_dir\": \"/opt/ml/output/intermediate\",\n",
+ " \"resource_config\": {\n",
+ " \"current_host\": \"algo-1\",\n",
+ " \"current_instance_type\": \"ml.p4d.24xlarge\",\n",
+ " \"current_group_name\": \"homogeneousCluster\",\n",
+ " \"hosts\": [\n",
+ " \"algo-1\"\n",
+ " ],\n",
+ " \"instance_groups\": [\n",
+ " {\n",
+ " \"instance_group_name\": \"homogeneousCluster\",\n",
+ " \"instance_type\": \"ml.p4d.24xlarge\",\n",
+ " \"hosts\": [\n",
+ " \"algo-1\"\n",
+ " ]\n",
+ " }\n",
+ " ],\n",
+ " \"network_interface_name\": \"eth0\"\n",
+ " },\n",
+ " \"user_entry_point\": \"launcher.py\"\n",
+ "}\n",
+ "Environment variables:\n",
+ "SM_HOSTS=[\"algo-1\"]\n",
+ "SM_NETWORK_INTERFACE_NAME=eth0\n",
+ "SM_HPS={\"batch_size\":1024,\"epochs\":10,\"model_dir\":\"/opt/ml/model\",\"num_of_data_workers\":0,\"steps_per_epoch\":500,\"tf_data_mode\":\"local\"}\n",
+ "SM_USER_ENTRY_POINT=launcher.py\n",
+ "SM_FRAMEWORK_PARAMS={\"sagemaker_mpi_custom_mpi_options\":\"--NCCL_DEBUG WARN\",\"sagemaker_mpi_enabled\":true,\"sagemaker_mpi_num_of_processes_per_host\":8}\n",
+ "SM_RESOURCE_CONFIG={\"current_group_name\":\"homogeneousCluster\",\"current_host\":\"algo-1\",\"current_instance_type\":\"ml.p4d.24xlarge\",\"hosts\":[\"algo-1\"],\"instance_groups\":[{\"hosts\":[\"algo-1\"],\"instance_group_name\":\"homogeneousCluster\",\"instance_type\":\"ml.p4d.24xlarge\"}],\"network_interface_name\":\"eth0\"}\n",
+ "SM_INPUT_DATA_CONFIG={}\n",
+ "SM_OUTPUT_DATA_DIR=/opt/ml/output/data\n",
+ "SM_CHANNELS=[]\n",
+ "SM_CURRENT_HOST=algo-1\n",
+ "SM_CURRENT_INSTANCE_TYPE=ml.p4d.24xlarge\n",
+ "SM_CURRENT_INSTANCE_GROUP=homogeneousCluster\n",
+ "SM_CURRENT_INSTANCE_GROUP_HOSTS=[\"algo-1\"]\n",
+ "SM_INSTANCE_GROUPS=[\"homogeneousCluster\"]\n",
+ "SM_INSTANCE_GROUPS_DICT={\"homogeneousCluster\":{\"hosts\":[\"algo-1\"],\"instance_group_name\":\"homogeneousCluster\",\"instance_type\":\"ml.p4d.24xlarge\"}}\n",
+ "SM_DISTRIBUTION_INSTANCE_GROUPS=[\"homogeneousCluster\"]\n",
+ "SM_IS_HETERO=false\n",
+ "SM_MODULE_NAME=launcher\n",
+ "SM_LOG_LEVEL=20\n",
+ "SM_FRAMEWORK_MODULE=sagemaker_tensorflow_container.training:main\n",
+ "SM_INPUT_DIR=/opt/ml/input\n",
+ "SM_INPUT_CONFIG_DIR=/opt/ml/input/config\n",
+ "SM_OUTPUT_DIR=/opt/ml/output\n",
+ "SM_NUM_CPUS=96\n",
+ "SM_NUM_GPUS=8\n",
+ "SM_MODEL_DIR=/opt/ml/model\n",
+ "SM_MODULE_DIR=s3://sagemaker-us-east-1-331113010199/homogeneous-20220924T112821Z-1/source/sourcedir.tar.gz\n",
+ "SM_TRAINING_ENV={\"additional_framework_parameters\":{\"sagemaker_mpi_custom_mpi_options\":\"--NCCL_DEBUG WARN\",\"sagemaker_mpi_enabled\":true,\"sagemaker_mpi_num_of_processes_per_host\":8},\"channel_input_dirs\":{},\"current_host\":\"algo-1\",\"current_instance_group\":\"homogeneousCluster\",\"current_instance_group_hosts\":[\"algo-1\"],\"current_instance_type\":\"ml.p4d.24xlarge\",\"distribution_hosts\":[\"algo-1\"],\"distribution_instance_groups\":[\"homogeneousCluster\"],\"framework_module\":\"sagemaker_tensorflow_container.training:main\",\"hosts\":[\"algo-1\"],\"hyperparameters\":{\"batch_size\":1024,\"epochs\":10,\"model_dir\":\"/opt/ml/model\",\"num_of_data_workers\":0,\"steps_per_epoch\":500,\"tf_data_mode\":\"local\"},\"input_config_dir\":\"/opt/ml/input/config\",\"input_data_config\":{},\"input_dir\":\"/opt/ml/input\",\"instance_groups\":[\"homogeneousCluster\"],\"instance_groups_dict\":{\"homogeneousCluster\":{\"hosts\":[\"algo-1\"],\"instance_group_name\":\"homogeneousCluster\",\"instance_type\":\"ml.p4d.24xlarge\"}},\"is_hetero\":false,\"is_master\":true,\"job_name\":\"homogeneous-20220924T112821Z-1\",\"log_level\":20,\"master_hostname\":\"algo-1\",\"model_dir\":\"/opt/ml/model\",\"module_dir\":\"s3://sagemaker-us-east-1-331113010199/homogeneous-20220924T112821Z-1/source/sourcedir.tar.gz\",\"module_name\":\"launcher\",\"network_interface_name\":\"eth0\",\"num_cpus\":96,\"num_gpus\":8,\"output_data_dir\":\"/opt/ml/output/data\",\"output_dir\":\"/opt/ml/output\",\"output_intermediate_dir\":\"/opt/ml/output/intermediate\",\"resource_config\":{\"current_group_name\":\"homogeneousCluster\",\"current_host\":\"algo-1\",\"current_instance_type\":\"ml.p4d.24xlarge\",\"hosts\":[\"algo-1\"],\"instance_groups\":[{\"hosts\":[\"algo-1\"],\"instance_group_name\":\"homogeneousCluster\",\"instance_type\":\"ml.p4d.24xlarge\"}],\"network_interface_name\":\"eth0\"},\"user_entry_point\":\"launcher.py\"}\n",
+ "SM_USER_ARGS=[\"--batch_size\",\"1024\",\"--epochs\",\"10\",\"--model_dir\",\"/opt/ml/model\",\"--num_of_data_workers\",\"0\",\"--steps_per_epoch\",\"500\",\"--tf_data_mode\",\"local\"]\n",
+ "SM_OUTPUT_INTERMEDIATE_DIR=/opt/ml/output/intermediate\n",
+ "SM_HP_BATCH_SIZE=1024\n",
+ "SM_HP_EPOCHS=10\n",
+ "SM_HP_MODEL_DIR=/opt/ml/model\n",
+ "SM_HP_NUM_OF_DATA_WORKERS=0\n",
+ "SM_HP_STEPS_PER_EPOCH=500\n",
+ "SM_HP_TF_DATA_MODE=local\n",
+ "PYTHONPATH=/opt/ml/code:/usr/local/bin:/usr/local/lib/python39.zip:/usr/local/lib/python3.9:/usr/local/lib/python3.9/lib-dynload:/usr/local/lib/python3.9/site-packages:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg:/usr/local/lib/python3.9/site-packages/pyinstrument-3.4.2-py3.9.egg:/usr/local/lib/python3.9/site-packages/pyinstrument_cext-0.2.4-py3.9-linux-x86_64.egg\n",
+ "Invoking script with the following command:\n",
+ "mpirun --host algo-1:8 -np 8 --allow-run-as-root --display-map --tag-output -mca btl_tcp_if_include eth0 -mca oob_tcp_if_include eth0 -mca plm_rsh_no_tree_spawn 1 -bind-to none -map-by slot -mca pml ob1 -mca btl ^openib -mca orte_abort_on_non_zero_status 1 -mca btl_vader_single_copy_mechanism none -x NCCL_MIN_NRINGS=4 -x NCCL_SOCKET_IFNAME=eth0 -x NCCL_DEBUG=WARN -x LD_LIBRARY_PATH -x PATH -x LD_PRELOAD=/usr/local/lib/python3.9/site-packages/gethostname.cpython-39-x86_64-linux-gnu.so -x SM_HOSTS -x SM_NETWORK_INTERFACE_NAME -x SM_HPS -x SM_USER_ENTRY_POINT -x SM_FRAMEWORK_PARAMS -x SM_RESOURCE_CONFIG -x SM_INPUT_DATA_CONFIG -x SM_OUTPUT_DATA_DIR -x SM_CHANNELS -x SM_CURRENT_HOST -x SM_CURRENT_INSTANCE_TYPE -x SM_CURRENT_INSTANCE_GROUP -x SM_CURRENT_INSTANCE_GROUP_HOSTS -x SM_INSTANCE_GROUPS -x SM_INSTANCE_GROUPS_DICT -x SM_DISTRIBUTION_INSTANCE_GROUPS -x SM_IS_HETERO -x SM_MODULE_NAME -x SM_LOG_LEVEL -x SM_FRAMEWORK_MODULE -x SM_INPUT_DIR -x SM_INPUT_CONFIG_DIR -x SM_OUTPUT_DIR -x SM_NUM_CPUS -x SM_NUM_GPUS -x SM_MODEL_DIR -x SM_MODULE_DIR -x SM_TRAINING_ENV -x SM_USER_ARGS -x SM_OUTPUT_INTERMEDIATE_DIR -x SM_HP_BATCH_SIZE -x SM_HP_EPOCHS -x SM_HP_MODEL_DIR -x SM_HP_NUM_OF_DATA_WORKERS -x SM_HP_STEPS_PER_EPOCH -x SM_HP_TF_DATA_MODE -x PYTHONPATH /usr/local/bin/python3.9 -m mpi4py launcher.py --batch_size 1024 --epochs 10 --model_dir /opt/ml/model --num_of_data_workers 0 --steps_per_epoch 500 --tf_data_mode local\n",
+ "Data for JOB [7555,1] offset 0 Total slots allocated 8\n",
+ " ======================== JOB MAP ========================\n",
+ " Data for node: ip-10-0-215-180#011Num slots: 8#011Max slots: 0#011Num procs: 8\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 0 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 1 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 2 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 3 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 4 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 5 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 6 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 7 Bound: N/A\n",
+ " =============================================================\n",
+ "[1,mpirank:1,algo-1]
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### security groups update if running in private VPC\n",
+ "This section is relevant if you plan to [run in a private VPC](https://docs.aws.amazon.com/sagemaker/latest/dg/train-vpc.html) (passing `subnets` and `security_group_ids` parameters when defining an Estimator). \n",
+ "SageMaker documentation recommends you [add](https://docs.aws.amazon.com/sagemaker/latest/dg/train-vpc.html#train-vpc-vpc) a rule for your security group that allows inbound connections between members of the same security group, for all TCP communication. This will also cover for the tf.data.service related traffic between instances:\n",
+ "- tf.data.service Dispatcher node will listen for incoming connections on port 6000 (configurable) from all nodes.\n",
+ "- tf.data.service Workers will listen on ports 6001-6006 from all nodes.\n",
+ "- Each node listens on port 16000 for a tf.data.service shutdown signal from all nodes."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### A. Set up SageMaker Studio notebook\n",
+ "#### Before you start\n",
+ "Ensure you have selected Python 3 (_TensorFlow 2.6 Python 3.8 CPU Optimized_) image for your SageMaker Studio Notebook instance, and running on _ml.t3.medium_ instance type.\n",
+ "\n",
+ "#### Step 1 - Upgrade SageMaker SDK and dependent packages \n",
+ "Heterogeneous Clusters for Amazon SageMaker model training was [announced](https://aws.amazon.com/about-aws/whats-new/2022/07/announcing-heterogeneous-clusters-amazon-sagemaker-model-training) on 07/08/2022. This feature release requires you to have updated SageMaker SDK, Boto3 client."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Requirement already satisfied: boto3 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (1.24.72)\n",
+ "Collecting boto3\n",
+ " Downloading boto3-1.24.80-py3-none-any.whl (132 kB)\n",
+ " ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 132.5/132.5 kB 925.9 kB/s eta 0:00:00\n",
+ "Requirement already satisfied: botocore in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (1.27.72)\n",
+ "Collecting botocore\n",
+ " Downloading botocore-1.27.80-py3-none-any.whl (9.1 MB)\n",
+ " ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 9.1/9.1 MB 16.4 MB/s eta 0:00:00\n",
+ "Requirement already satisfied: awscli in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (1.25.73)\n",
+ "Collecting awscli\n",
+ " Downloading awscli-1.25.81-py3-none-any.whl (3.9 MB)\n",
+ " ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 3.9/3.9 MB 38.4 MB/s eta 0:00:00\n",
+ "Requirement already satisfied: sagemaker in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (2.109.0)\n",
+ "Requirement already satisfied: s3transfer<0.7.0,>=0.6.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from boto3) (0.6.0)\n",
+ "Requirement already satisfied: jmespath<2.0.0,>=0.7.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/jmespath-1.0.0-py3.9.egg (from boto3) (1.0.0)\n",
+ "Requirement already satisfied: urllib3<1.27,>=1.25.4 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/urllib3-1.26.9-py3.9.egg (from botocore) (1.26.9)\n",
+ "Requirement already satisfied: python-dateutil<3.0.0,>=2.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/python_dateutil-2.8.2-py3.9.egg (from botocore) (2.8.2)\n",
+ "Requirement already satisfied: PyYAML<5.5,>=3.10 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from awscli) (5.4.1)\n",
+ "Requirement already satisfied: docutils<0.17,>=0.10 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from awscli) (0.16)\n",
+ "Requirement already satisfied: colorama<0.4.5,>=0.2.5 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from awscli) (0.4.4)\n",
+ "Requirement already satisfied: rsa<4.8,>=3.1.2 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from awscli) (4.7.2)\n",
+ "Requirement already satisfied: importlib-metadata<5.0,>=1.4.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/importlib_metadata-4.11.3-py3.9.egg (from sagemaker) (4.11.3)\n",
+ "Requirement already satisfied: pathos in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pathos-0.2.8-py3.9.egg (from sagemaker) (0.2.8)\n",
+ "Requirement already satisfied: protobuf3-to-dict<1.0,>=0.1.5 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/protobuf3_to_dict-0.1.5-py3.9.egg (from sagemaker) (0.1.5)\n",
+ "Requirement already satisfied: pandas in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pandas-1.4.2-py3.9-macosx-10.9-x86_64.egg (from sagemaker) (1.4.2)\n",
+ "Requirement already satisfied: numpy<2.0,>=1.9.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from sagemaker) (1.22.4)\n",
+ "Requirement already satisfied: attrs<22,>=20.3.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/attrs-20.3.0-py3.9.egg (from sagemaker) (20.3.0)\n",
+ "Requirement already satisfied: smdebug-rulesconfig==1.0.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/smdebug_rulesconfig-1.0.1-py3.9.egg (from sagemaker) (1.0.1)\n",
+ "Requirement already satisfied: google-pasta in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/google_pasta-0.2.0-py3.9.egg (from sagemaker) (0.2.0)\n",
+ "Requirement already satisfied: protobuf<4.0,>=3.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from sagemaker) (3.20.1)\n",
+ "Requirement already satisfied: packaging>=20.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/packaging-21.3-py3.9.egg (from sagemaker) (21.3)\n",
+ "Requirement already satisfied: zipp>=0.5 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/zipp-3.7.0-py3.9.egg (from importlib-metadata<5.0,>=1.4.0->sagemaker) (3.7.0)\n",
+ "Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pyparsing-3.0.7-py3.9.egg (from packaging>=20.0->sagemaker) (3.0.7)\n",
+ "Requirement already satisfied: six in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from protobuf3-to-dict<1.0,>=0.1.5->sagemaker) (1.15.0)\n",
+ "Requirement already satisfied: pyasn1>=0.1.3 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages (from rsa<4.8,>=3.1.2->awscli) (0.4.8)\n",
+ "Requirement already satisfied: pytz>=2020.1 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pytz-2022.1-py3.9.egg (from pandas->sagemaker) (2022.1)\n",
+ "Requirement already satisfied: dill>=0.3.4 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/dill-0.3.4-py3.9.egg (from pathos->sagemaker) (0.3.4)\n",
+ "Requirement already satisfied: multiprocess>=0.70.12 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/multiprocess-0.70.12.2-py3.9.egg (from pathos->sagemaker) (0.70.12.2)\n",
+ "Requirement already satisfied: pox>=0.3.0 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/pox-0.3.0-py3.9.egg (from pathos->sagemaker) (0.3.0)\n",
+ "Requirement already satisfied: ppft>=1.6.6.4 in /Users/gili/dev/hetro-training/.venv/lib/python3.9/site-packages/ppft-1.6.6.4-py3.9.egg (from pathos->sagemaker) (1.6.6.4)\n",
+ "Installing collected packages: botocore, boto3, awscli\n",
+ " Attempting uninstall: botocore\n",
+ " Found existing installation: botocore 1.27.72\n",
+ " Uninstalling botocore-1.27.72:\n",
+ " Successfully uninstalled botocore-1.27.72\n",
+ " Attempting uninstall: boto3\n",
+ " Found existing installation: boto3 1.24.72\n",
+ " Uninstalling boto3-1.24.72:\n",
+ " Successfully uninstalled boto3-1.24.72\n",
+ " Attempting uninstall: awscli\n",
+ " Found existing installation: awscli 1.25.73\n",
+ " Uninstalling awscli-1.25.73:\n",
+ " Successfully uninstalled awscli-1.25.73\n"
+ ]
+ },
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\n",
+ "sagemaker-training 4.2.2 requires protobuf<3.20,>=3.9.2, but you have protobuf 3.20.1 which is incompatible.\n"
+ ]
+ },
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Successfully installed awscli-1.25.81 boto3-1.24.80 botocore-1.27.80\n"
+ ]
+ }
+ ],
+ "source": [
+ "%%bash\n",
+ "python3 -m pip install --upgrade boto3 botocore awscli sagemaker"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Step 2 - Restart the notebook kernel "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "#import IPython\n",
+ "#IPython.Application.instance().kernel.do_shutdown(True)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Step 3 - Validate SageMaker Python SDK and TensorFlow versions\n",
+ "Ensure the output of the cell below reflects:\n",
+ "\n",
+ "- SageMaker Python SDK version 2.98.0 or above, \n",
+ "- boto3 1.24 or above \n",
+ "- botocore 1.27 or above \n",
+ "- TensorFlow 2.6 or above "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Name: sagemaker\n",
+ "Version: 2.109.0\n",
+ "---\n",
+ "Name: boto3\n",
+ "Version: 1.24.80\n",
+ "---\n",
+ "Name: botocore\n",
+ "Version: 1.27.80\n",
+ "---\n",
+ "Name: tensorflow\n",
+ "Version: 2.8.0\n",
+ "---\n",
+ "Name: protobuf\n",
+ "Version: 3.20.1\n"
+ ]
+ }
+ ],
+ "source": [
+ "!pip show sagemaker boto3 botocore tensorflow protobuf |egrep 'Name|Version|---'"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import json\n",
+ "import datetime\n",
+ "\n",
+ "import sagemaker\n",
+ "from sagemaker import get_execution_role\n",
+ "from sagemaker.instance_group import InstanceGroup\n",
+ "\n",
+ "sess = sagemaker.Session()\n",
+ "role = get_execution_role()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "### C. Run a homogeneous training job\n",
+ "#### Step 1: Set up the training environment\n",
+ "In this step, we define and submit a homogeneous training job. It uses a single instance type (p4d.24xlarge) with 8 GPUs. The analysis of the job will shows that it is CPU bound and therefore its GPUs are underutilized."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 6,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import datetime\n",
+ "from sagemaker.tensorflow import TensorFlow\n",
+ "from sagemaker.instance_group import InstanceGroup\n",
+ "import os\n",
+ "\n",
+ "hyperparameters = {\n",
+ " \"epochs\": 10,\n",
+ " \"steps_per_epoch\": 500,\n",
+ " \"batch_size\": 1024,\n",
+ " \"tf_data_mode\": \"local\", # We won't be using tf.data.service ('service') for this homogeneous job\n",
+ " \"num_of_data_workers\": 0, # We won't be using tf.data.service ('service') for this homogeneous job\n",
+ "}\n",
+ "\n",
+ "estimator = TensorFlow(\n",
+ " entry_point=\"launcher.py\",\n",
+ " source_dir=\"code\",\n",
+ " framework_version=\"2.9.1\",\n",
+ " py_version=\"py39\",\n",
+ " role=role,\n",
+ " volume_size=10,\n",
+ " max_run=1800, # 30 minutes\n",
+ " disable_profiler=True,\n",
+ " instance_type=\"ml.p4d.24xlarge\",\n",
+ " instance_count=1,\n",
+ " hyperparameters=hyperparameters,\n",
+ " distribution={\n",
+ " \"mpi\": {\n",
+ " \"enabled\": True,\n",
+ " \"processes_per_host\": 8, # 8 GPUs per host\n",
+ " \"custom_mpi_options\": \"--NCCL_DEBUG WARN\",\n",
+ " },\n",
+ " },\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "#### Step 2: Submit the training job\n",
+ "\n",
+ "Note: For the logs, click on **View logs** from the **Training Jobs** node in **Amazon SageMaker Console**. \n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 17,
+ "metadata": {
+ "collapsed": true,
+ "jupyter": {
+ "outputs_hidden": true
+ }
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "2022-09-24 11:28:23 Starting - Starting the training job......\n",
+ "2022-09-24 11:29:08 Starting - Preparing the instances for training........................\n",
+ "2022-09-24 11:33:34 Downloading - Downloading input data\n",
+ "2022-09-24 11:33:34 Training - Downloading the training image..................\n",
+ "2022-09-24 11:37:00 Training - Training image download completed. Training in progress..2022-09-24 11:37:05.792579: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.\n",
+ "2022-09-24 11:37:05.801314: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:105] SageMaker Profiler is not enabled. The timeline writer thread will not be started, future recorded events will be dropped.\n",
+ "2022-09-24 11:37:06.269740: W tensorflow/core/profiler/internal/smprofiler_timeline.cc:460] Initializing the SageMaker Profiler.\n",
+ "2022-09-24 11:37:13,412 sagemaker-training-toolkit INFO Imported framework sagemaker_tensorflow_container.training\n",
+ "2022-09-24 11:37:14,075 sagemaker-training-toolkit INFO Installing dependencies from requirements.txt:\n",
+ "/usr/local/bin/python3.9 -m pip install -r requirements.txt\n",
+ "Collecting protobuf==3.20.1\n",
+ "Downloading protobuf-3.20.1-cp39-cp39-manylinux_2_5_x86_64.manylinux1_x86_64.whl (1.0 MB)\n",
+ "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.0/1.0 MB 39.6 MB/s eta 0:00:00\n",
+ "Collecting tensorflow-addons==0.17.0\n",
+ "Downloading tensorflow_addons-0.17.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.1 MB)\n",
+ "━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.1/1.1 MB 51.6 MB/s eta 0:00:00\n",
+ "Requirement already satisfied: packaging in /usr/local/lib/python3.9/site-packages (from tensorflow-addons==0.17.0->-r requirements.txt (line 2)) (21.3)\n",
+ "Requirement already satisfied: typeguard>=2.7 in /usr/local/lib/python3.9/site-packages (from tensorflow-addons==0.17.0->-r requirements.txt (line 2)) (2.13.3)\n",
+ "Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /usr/local/lib/python3.9/site-packages (from packaging->tensorflow-addons==0.17.0->-r requirements.txt (line 2)) (3.0.9)\n",
+ "Installing collected packages: protobuf, tensorflow-addons\n",
+ "Attempting uninstall: protobuf\n",
+ "Found existing installation: protobuf 3.19.4\n",
+ "Uninstalling protobuf-3.19.4:\n",
+ "Successfully uninstalled protobuf-3.19.4\n",
+ "Attempting uninstall: tensorflow-addons\n",
+ "Found existing installation: tensorflow-addons 0.17.1\n",
+ "Uninstalling tensorflow-addons-0.17.1:\n",
+ "Successfully uninstalled tensorflow-addons-0.17.1\n",
+ "ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.\n",
+ "tf-models-official 2.9.1 requires tensorflow~=2.9.0, which is not installed.\n",
+ "tensorflow-gpu 2.9.1 requires protobuf<3.20,>=3.9.2, but you have protobuf 3.20.1 which is incompatible.\n",
+ "tensorboard 2.9.1 requires protobuf<3.20,>=3.9.2, but you have protobuf 3.20.1 which is incompatible.\n",
+ "sagemaker-training 4.1.4.dev0 requires protobuf<3.20,>=3.9.2, but you have protobuf 3.20.1 which is incompatible.\n",
+ "Successfully installed protobuf-3.20.1 tensorflow-addons-0.17.0\n",
+ "WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv\n",
+ "[notice] A new release of pip available: 22.1.2 -> 22.2.2\n",
+ "[notice] To update, run: pip install --upgrade pip\n",
+ "2022-09-24 11:37:24,079 sagemaker-training-toolkit INFO Waiting for the process to finish and give a return code.\n",
+ "2022-09-24 11:37:24,079 sagemaker-training-toolkit INFO Done waiting for a return code. Received 0 from exiting process.\n",
+ "2022-09-24 11:37:24,258 sagemaker-training-toolkit INFO Starting MPI run as worker node.\n",
+ "2022-09-24 11:37:24,258 sagemaker-training-toolkit INFO Creating SSH daemon.\n",
+ "2022-09-24 11:37:24,274 sagemaker-training-toolkit INFO Waiting for MPI workers to establish their SSH connections\n",
+ "2022-09-24 11:37:24,274 sagemaker-training-toolkit INFO Env Hosts: ['algo-1'] Hosts: ['algo-1:8'] process_per_hosts: 8 num_processes: 8\n",
+ "2022-09-24 11:37:24,276 sagemaker-training-toolkit INFO Network interface name: eth0\n",
+ "2022-09-24 11:37:24,368 sagemaker-training-toolkit INFO Invoking user script\n",
+ "Training Env:\n",
+ "{\n",
+ " \"additional_framework_parameters\": {\n",
+ " \"sagemaker_mpi_custom_mpi_options\": \"--NCCL_DEBUG WARN\",\n",
+ " \"sagemaker_mpi_enabled\": true,\n",
+ " \"sagemaker_mpi_num_of_processes_per_host\": 8\n",
+ " },\n",
+ " \"channel_input_dirs\": {},\n",
+ " \"current_host\": \"algo-1\",\n",
+ " \"current_instance_group\": \"homogeneousCluster\",\n",
+ " \"current_instance_group_hosts\": [\n",
+ " \"algo-1\"\n",
+ " ],\n",
+ " \"current_instance_type\": \"ml.p4d.24xlarge\",\n",
+ " \"distribution_hosts\": [\n",
+ " \"algo-1\"\n",
+ " ],\n",
+ " \"distribution_instance_groups\": [\n",
+ " \"homogeneousCluster\"\n",
+ " ],\n",
+ " \"framework_module\": \"sagemaker_tensorflow_container.training:main\",\n",
+ " \"hosts\": [\n",
+ " \"algo-1\"\n",
+ " ],\n",
+ " \"hyperparameters\": {\n",
+ " \"batch_size\": 1024,\n",
+ " \"epochs\": 10,\n",
+ " \"model_dir\": \"/opt/ml/model\",\n",
+ " \"num_of_data_workers\": 0,\n",
+ " \"steps_per_epoch\": 500,\n",
+ " \"tf_data_mode\": \"local\"\n",
+ " },\n",
+ " \"input_config_dir\": \"/opt/ml/input/config\",\n",
+ " \"input_data_config\": {},\n",
+ " \"input_dir\": \"/opt/ml/input\",\n",
+ " \"instance_groups\": [\n",
+ " \"homogeneousCluster\"\n",
+ " ],\n",
+ " \"instance_groups_dict\": {\n",
+ " \"homogeneousCluster\": {\n",
+ " \"instance_group_name\": \"homogeneousCluster\",\n",
+ " \"instance_type\": \"ml.p4d.24xlarge\",\n",
+ " \"hosts\": [\n",
+ " \"algo-1\"\n",
+ " ]\n",
+ " }\n",
+ " },\n",
+ " \"is_hetero\": false,\n",
+ " \"is_master\": true,\n",
+ " \"job_name\": \"homogeneous-20220924T112821Z-1\",\n",
+ " \"log_level\": 20,\n",
+ " \"master_hostname\": \"algo-1\",\n",
+ " \"model_dir\": \"/opt/ml/model\",\n",
+ " \"module_dir\": \"s3://sagemaker-us-east-1-331113010199/homogeneous-20220924T112821Z-1/source/sourcedir.tar.gz\",\n",
+ " \"module_name\": \"launcher\",\n",
+ " \"network_interface_name\": \"eth0\",\n",
+ " \"num_cpus\": 96,\n",
+ " \"num_gpus\": 8,\n",
+ " \"output_data_dir\": \"/opt/ml/output/data\",\n",
+ " \"output_dir\": \"/opt/ml/output\",\n",
+ " \"output_intermediate_dir\": \"/opt/ml/output/intermediate\",\n",
+ " \"resource_config\": {\n",
+ " \"current_host\": \"algo-1\",\n",
+ " \"current_instance_type\": \"ml.p4d.24xlarge\",\n",
+ " \"current_group_name\": \"homogeneousCluster\",\n",
+ " \"hosts\": [\n",
+ " \"algo-1\"\n",
+ " ],\n",
+ " \"instance_groups\": [\n",
+ " {\n",
+ " \"instance_group_name\": \"homogeneousCluster\",\n",
+ " \"instance_type\": \"ml.p4d.24xlarge\",\n",
+ " \"hosts\": [\n",
+ " \"algo-1\"\n",
+ " ]\n",
+ " }\n",
+ " ],\n",
+ " \"network_interface_name\": \"eth0\"\n",
+ " },\n",
+ " \"user_entry_point\": \"launcher.py\"\n",
+ "}\n",
+ "Environment variables:\n",
+ "SM_HOSTS=[\"algo-1\"]\n",
+ "SM_NETWORK_INTERFACE_NAME=eth0\n",
+ "SM_HPS={\"batch_size\":1024,\"epochs\":10,\"model_dir\":\"/opt/ml/model\",\"num_of_data_workers\":0,\"steps_per_epoch\":500,\"tf_data_mode\":\"local\"}\n",
+ "SM_USER_ENTRY_POINT=launcher.py\n",
+ "SM_FRAMEWORK_PARAMS={\"sagemaker_mpi_custom_mpi_options\":\"--NCCL_DEBUG WARN\",\"sagemaker_mpi_enabled\":true,\"sagemaker_mpi_num_of_processes_per_host\":8}\n",
+ "SM_RESOURCE_CONFIG={\"current_group_name\":\"homogeneousCluster\",\"current_host\":\"algo-1\",\"current_instance_type\":\"ml.p4d.24xlarge\",\"hosts\":[\"algo-1\"],\"instance_groups\":[{\"hosts\":[\"algo-1\"],\"instance_group_name\":\"homogeneousCluster\",\"instance_type\":\"ml.p4d.24xlarge\"}],\"network_interface_name\":\"eth0\"}\n",
+ "SM_INPUT_DATA_CONFIG={}\n",
+ "SM_OUTPUT_DATA_DIR=/opt/ml/output/data\n",
+ "SM_CHANNELS=[]\n",
+ "SM_CURRENT_HOST=algo-1\n",
+ "SM_CURRENT_INSTANCE_TYPE=ml.p4d.24xlarge\n",
+ "SM_CURRENT_INSTANCE_GROUP=homogeneousCluster\n",
+ "SM_CURRENT_INSTANCE_GROUP_HOSTS=[\"algo-1\"]\n",
+ "SM_INSTANCE_GROUPS=[\"homogeneousCluster\"]\n",
+ "SM_INSTANCE_GROUPS_DICT={\"homogeneousCluster\":{\"hosts\":[\"algo-1\"],\"instance_group_name\":\"homogeneousCluster\",\"instance_type\":\"ml.p4d.24xlarge\"}}\n",
+ "SM_DISTRIBUTION_INSTANCE_GROUPS=[\"homogeneousCluster\"]\n",
+ "SM_IS_HETERO=false\n",
+ "SM_MODULE_NAME=launcher\n",
+ "SM_LOG_LEVEL=20\n",
+ "SM_FRAMEWORK_MODULE=sagemaker_tensorflow_container.training:main\n",
+ "SM_INPUT_DIR=/opt/ml/input\n",
+ "SM_INPUT_CONFIG_DIR=/opt/ml/input/config\n",
+ "SM_OUTPUT_DIR=/opt/ml/output\n",
+ "SM_NUM_CPUS=96\n",
+ "SM_NUM_GPUS=8\n",
+ "SM_MODEL_DIR=/opt/ml/model\n",
+ "SM_MODULE_DIR=s3://sagemaker-us-east-1-331113010199/homogeneous-20220924T112821Z-1/source/sourcedir.tar.gz\n",
+ "SM_TRAINING_ENV={\"additional_framework_parameters\":{\"sagemaker_mpi_custom_mpi_options\":\"--NCCL_DEBUG WARN\",\"sagemaker_mpi_enabled\":true,\"sagemaker_mpi_num_of_processes_per_host\":8},\"channel_input_dirs\":{},\"current_host\":\"algo-1\",\"current_instance_group\":\"homogeneousCluster\",\"current_instance_group_hosts\":[\"algo-1\"],\"current_instance_type\":\"ml.p4d.24xlarge\",\"distribution_hosts\":[\"algo-1\"],\"distribution_instance_groups\":[\"homogeneousCluster\"],\"framework_module\":\"sagemaker_tensorflow_container.training:main\",\"hosts\":[\"algo-1\"],\"hyperparameters\":{\"batch_size\":1024,\"epochs\":10,\"model_dir\":\"/opt/ml/model\",\"num_of_data_workers\":0,\"steps_per_epoch\":500,\"tf_data_mode\":\"local\"},\"input_config_dir\":\"/opt/ml/input/config\",\"input_data_config\":{},\"input_dir\":\"/opt/ml/input\",\"instance_groups\":[\"homogeneousCluster\"],\"instance_groups_dict\":{\"homogeneousCluster\":{\"hosts\":[\"algo-1\"],\"instance_group_name\":\"homogeneousCluster\",\"instance_type\":\"ml.p4d.24xlarge\"}},\"is_hetero\":false,\"is_master\":true,\"job_name\":\"homogeneous-20220924T112821Z-1\",\"log_level\":20,\"master_hostname\":\"algo-1\",\"model_dir\":\"/opt/ml/model\",\"module_dir\":\"s3://sagemaker-us-east-1-331113010199/homogeneous-20220924T112821Z-1/source/sourcedir.tar.gz\",\"module_name\":\"launcher\",\"network_interface_name\":\"eth0\",\"num_cpus\":96,\"num_gpus\":8,\"output_data_dir\":\"/opt/ml/output/data\",\"output_dir\":\"/opt/ml/output\",\"output_intermediate_dir\":\"/opt/ml/output/intermediate\",\"resource_config\":{\"current_group_name\":\"homogeneousCluster\",\"current_host\":\"algo-1\",\"current_instance_type\":\"ml.p4d.24xlarge\",\"hosts\":[\"algo-1\"],\"instance_groups\":[{\"hosts\":[\"algo-1\"],\"instance_group_name\":\"homogeneousCluster\",\"instance_type\":\"ml.p4d.24xlarge\"}],\"network_interface_name\":\"eth0\"},\"user_entry_point\":\"launcher.py\"}\n",
+ "SM_USER_ARGS=[\"--batch_size\",\"1024\",\"--epochs\",\"10\",\"--model_dir\",\"/opt/ml/model\",\"--num_of_data_workers\",\"0\",\"--steps_per_epoch\",\"500\",\"--tf_data_mode\",\"local\"]\n",
+ "SM_OUTPUT_INTERMEDIATE_DIR=/opt/ml/output/intermediate\n",
+ "SM_HP_BATCH_SIZE=1024\n",
+ "SM_HP_EPOCHS=10\n",
+ "SM_HP_MODEL_DIR=/opt/ml/model\n",
+ "SM_HP_NUM_OF_DATA_WORKERS=0\n",
+ "SM_HP_STEPS_PER_EPOCH=500\n",
+ "SM_HP_TF_DATA_MODE=local\n",
+ "PYTHONPATH=/opt/ml/code:/usr/local/bin:/usr/local/lib/python39.zip:/usr/local/lib/python3.9:/usr/local/lib/python3.9/lib-dynload:/usr/local/lib/python3.9/site-packages:/usr/local/lib/python3.9/site-packages/smdebug-1.0.17b20220701-py3.9.egg:/usr/local/lib/python3.9/site-packages/pyinstrument-3.4.2-py3.9.egg:/usr/local/lib/python3.9/site-packages/pyinstrument_cext-0.2.4-py3.9-linux-x86_64.egg\n",
+ "Invoking script with the following command:\n",
+ "mpirun --host algo-1:8 -np 8 --allow-run-as-root --display-map --tag-output -mca btl_tcp_if_include eth0 -mca oob_tcp_if_include eth0 -mca plm_rsh_no_tree_spawn 1 -bind-to none -map-by slot -mca pml ob1 -mca btl ^openib -mca orte_abort_on_non_zero_status 1 -mca btl_vader_single_copy_mechanism none -x NCCL_MIN_NRINGS=4 -x NCCL_SOCKET_IFNAME=eth0 -x NCCL_DEBUG=WARN -x LD_LIBRARY_PATH -x PATH -x LD_PRELOAD=/usr/local/lib/python3.9/site-packages/gethostname.cpython-39-x86_64-linux-gnu.so -x SM_HOSTS -x SM_NETWORK_INTERFACE_NAME -x SM_HPS -x SM_USER_ENTRY_POINT -x SM_FRAMEWORK_PARAMS -x SM_RESOURCE_CONFIG -x SM_INPUT_DATA_CONFIG -x SM_OUTPUT_DATA_DIR -x SM_CHANNELS -x SM_CURRENT_HOST -x SM_CURRENT_INSTANCE_TYPE -x SM_CURRENT_INSTANCE_GROUP -x SM_CURRENT_INSTANCE_GROUP_HOSTS -x SM_INSTANCE_GROUPS -x SM_INSTANCE_GROUPS_DICT -x SM_DISTRIBUTION_INSTANCE_GROUPS -x SM_IS_HETERO -x SM_MODULE_NAME -x SM_LOG_LEVEL -x SM_FRAMEWORK_MODULE -x SM_INPUT_DIR -x SM_INPUT_CONFIG_DIR -x SM_OUTPUT_DIR -x SM_NUM_CPUS -x SM_NUM_GPUS -x SM_MODEL_DIR -x SM_MODULE_DIR -x SM_TRAINING_ENV -x SM_USER_ARGS -x SM_OUTPUT_INTERMEDIATE_DIR -x SM_HP_BATCH_SIZE -x SM_HP_EPOCHS -x SM_HP_MODEL_DIR -x SM_HP_NUM_OF_DATA_WORKERS -x SM_HP_STEPS_PER_EPOCH -x SM_HP_TF_DATA_MODE -x PYTHONPATH /usr/local/bin/python3.9 -m mpi4py launcher.py --batch_size 1024 --epochs 10 --model_dir /opt/ml/model --num_of_data_workers 0 --steps_per_epoch 500 --tf_data_mode local\n",
+ "Data for JOB [7555,1] offset 0 Total slots allocated 8\n",
+ " ======================== JOB MAP ========================\n",
+ " Data for node: ip-10-0-215-180#011Num slots: 8#011Max slots: 0#011Num procs: 8\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 0 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 1 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 2 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 3 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 4 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 5 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 6 Bound: N/A\n",
+ " #011Process OMPI jobid: [7555,1] App: 0 Process rank: 7 Bound: N/A\n",
+ " =============================================================\n",
+ "[1,mpirank:1,algo-1]