 -
-Atlas is an open-source project maintained by [Ariga Technologies Ltd](https://ariga.io),
-a tech company founded by the maintainers of [Ent](https://entgo.io).
-
-### Reaching Out
-
-If you have a question or want to chat with the Atlas community,
-join our [Discord Server](https://discord.com/invite/QhsmBAWzrC) or
-[open an issue](https://github.com/ariga/atlas/issues) on our [GitHub Repo](https://github.com/ariga/atlas).
\ No newline at end of file
diff --git a/doc/md/atlas-schema/external.mdx b/doc/md/atlas-schema/external.mdx
deleted file mode 100644
index ffa973250d1..00000000000
--- a/doc/md/atlas-schema/external.mdx
+++ /dev/null
@@ -1,155 +0,0 @@
----
-id: external-schema
-title: External Integrations
-slug: /atlas-schema/external
----
-
-import Tabs from '@theme/Tabs';
-import TabItem from '@theme/TabItem';
-
-Atlas allows loading the desired state of the database schema from external programs or ORMs, regardless of the
-programing language they are written in. Once the schema is loaded, it can be used by the various Atlas commands
-such as `atlas schema` and `atlas migrate`.
-
-## Loading an External Schema
-
-In order to load an external schema, you need first to create an `atlas.hcl` [config file](projects.mdx), if you don't
-already have one and declare a new data source of type [`external_schema`](projects.mdx#data-source-external_schema) that
-can be used later as the desired state. Let's explain this with an example.
-
-Given the following `atlas.hcl` file:
-
-
-
-Atlas is an open-source project maintained by [Ariga Technologies Ltd](https://ariga.io),
-a tech company founded by the maintainers of [Ent](https://entgo.io).
-
-### Reaching Out
-
-If you have a question or want to chat with the Atlas community,
-join our [Discord Server](https://discord.com/invite/QhsmBAWzrC) or
-[open an issue](https://github.com/ariga/atlas/issues) on our [GitHub Repo](https://github.com/ariga/atlas).
\ No newline at end of file
diff --git a/doc/md/atlas-schema/external.mdx b/doc/md/atlas-schema/external.mdx
deleted file mode 100644
index ffa973250d1..00000000000
--- a/doc/md/atlas-schema/external.mdx
+++ /dev/null
@@ -1,155 +0,0 @@
----
-id: external-schema
-title: External Integrations
-slug: /atlas-schema/external
----
-
-import Tabs from '@theme/Tabs';
-import TabItem from '@theme/TabItem';
-
-Atlas allows loading the desired state of the database schema from external programs or ORMs, regardless of the
-programing language they are written in. Once the schema is loaded, it can be used by the various Atlas commands
-such as `atlas schema` and `atlas migrate`.
-
-## Loading an External Schema
-
-In order to load an external schema, you need first to create an `atlas.hcl` [config file](projects.mdx), if you don't
-already have one and declare a new data source of type [`external_schema`](projects.mdx#data-source-external_schema) that
-can be used later as the desired state. Let's explain this with an example.
-
-Given the following `atlas.hcl` file:
-
-
-
-
-##### Attributes {#data-source-composite-schema-attributes}
-
-- `url` - The [URL](../concepts/url.mdx) of the composite schema.
-
-#### Usage example
-
-By running `atlas migrate diff` with the given configuration, Atlas loads the `inventory` schema from the [SQLAlchemy schema](/guides/orms/sqlalchemy),
-the `graph` schema from [ent/schema](https://entgo.io), and the `auth` and `internal` schemas from HCL and SQL schemas defined in
-Atlas format. Then, the composite schema, which represents these four schemas combined, will be compared against the
-current state of the migration directory. In case of a difference between the two states, a new migration file will be
-created with the necessary SQL statements.
-
-```hcl title="atlas.hcl" {1-14}
-data "composite_schema" "project" {
- schema "inventory" {
- url = data.external_schema.sqlalchemy.url
- }
- schema "graph" {
- url = "ent://ent/schema"
- }
- schema "auth" {
- url = "file://path/to/schema.hcl"
- }
- schema "internal" {
- url = "file://path/to/schema.sql"
- }
-}
-
-env "dev" {
- src = data.composite_schema.project.url
- dev = "docker://postgres/15/dev"
- migration {
- dir = "file://migrations"
- }
-}
-```
-
-#### Data source: `remote_dir`
-
-The `remote_dir` data source reads the state of a migration directory from [Atlas Cloud](https://atlasgo.cloud). For
-instructions on how to connect a migration directory to Atlas Cloud, please refer to the [cloud documentation](../cloud/directory.mdx).
-
-##### Arguments {#data-source-remote_dir-arguments}
-
-- `name` - The slug of the migration directory, as defined in Atlas Cloud.
-- `tag` (optional) - The tag of the migration directory, such as Git commit. If not specified, the latest
-tag (e.g., `master` branch) will be used.
-
-##### Attributes {#data-source-remote_dir-attributes}
-
-- `url` - A [URL](../concepts/url.mdx) to the loaded migration directory.
-
-:::note
-The `remote_dir` data source predates the `atlas://` URL scheme. The example below is equivalent to executing Atlas with
-`--dir "atlas://myapp"`.
-:::
-
-```hcl title="atlas.hcl" {6-10}
-variable "database_url" {
- type = string
- default = getenv("DATABASE_URL")
-}
-
-data "remote_dir" "migrations" {
- // The slug of the migration directory in Atlas Cloud.
- // In this example, the directory is named "myapp".
- name = "myapp"
-}
-
-env {
- // Set environment name dynamically based on --env value.
- name = atlas.env
- url = var.database_url
- migration {
- dir = data.remote_dir.migrations.url
- }
-}
-```
-
-#### Usage example
-
-```shell
-ATLAS_TOKEN="Usage Details
- -##### Mapping to Database Schemas - -The name of the `schema` block represents the database schema to be created in the composed graph. For example, the -following schemas refer to the `public` and `private` schemas within a PostgreSQL database: - -```hcl -data "composite_schema" "project" { - schema "public" { - url = ... - } - schema "private" { - url = ... - } -} -``` - -##### Schema Dependencies - -The order of the `schema` blocks defines the order in which Atlas will load the schemas to compose the entire database -graph. This is useful in the case of dependencies between the schemas. For example, the following schemas refer to the -`inventory` and `auth` schemas, where the `auth` schema depends on the `inventory` schema and therefore should be loaded -after it: - -```hcl -data "composite_schema" "project" { - schema "inventory" { - url = ... - } - schema "auth" { - url = ... - } -} -``` - -##### Schema Composition - -Defining multiple `schema` blocks with the same name enables extending the same database schema from multiple sources. -For example, the following configuration shows how an ORM schema, which relies on database types that cannot be defined -within the ORM itself, can load them separately from another schema source that supports it: - -```hcl -data "composite_schema" "project" { - schema "public" { - url = "file://types.pg.hcl" - } - schema "public" { - url = "ent://ent/schema" - } -} -``` - -##### Labeled vs. Unlabeled Schema Blocks - -Note, if the `schema` block is labeled (e.g., `schema "public"`), the schema will be created if it does not exist, -and the computation for loading the state from the URL will be done within the scope of this schema. - -If the `schema` block is unlabeled (e.g., `schema { ... }`), no schema will be created, and the computation for loading -the state from the URL will be done within the scope of the database. Read more about this in [Schema vs. Database Scope](/concepts/url#scope) -doc. - -
-
-
-:::
-
-#### Data source: `template_dir`
-
-The `template_dir` data source renders a migration directory from a template directory. It does this by parsing the
-entire directory as [Go templates](https://golang.org/pkg/text/template), executing top-level (template) files that
-have the `.sql` file extension, and generating an in-memory migration directory from them.
-
-##### Arguments {#data-source-template_dir-arguments}
-
-- `path` - A path to the template directory.
-- `vars` - A map of variables to pass to the template.
-
-##### Attributes {#data-source-template_dir-attributes}
-
-- `url` - A [URL](../concepts/url.mdx) to the generated migration directory.
-
-Screenshot example
- -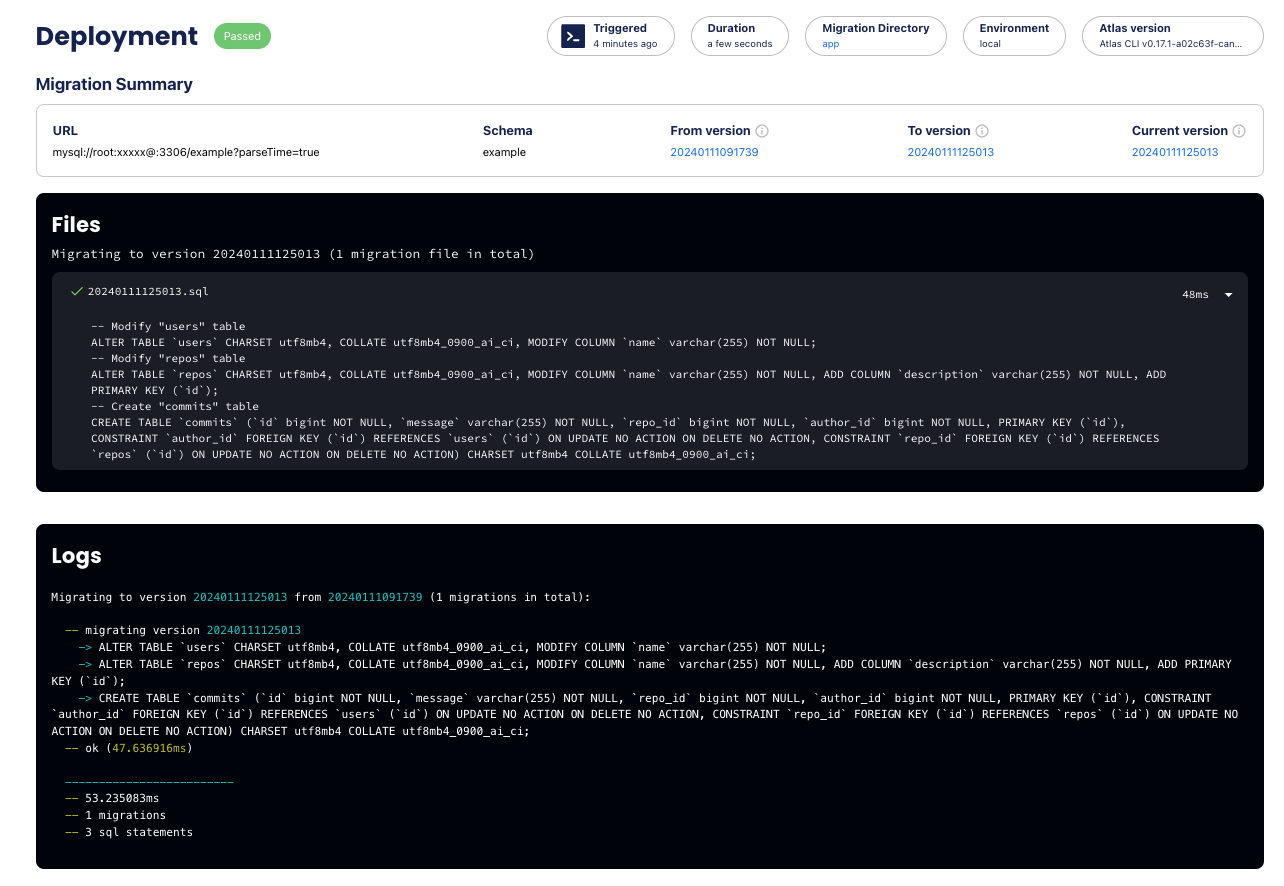 - -
-
-
-Pick a name for your Agent and hit **Create Agent**.
-
-
-Screenshot Example
- -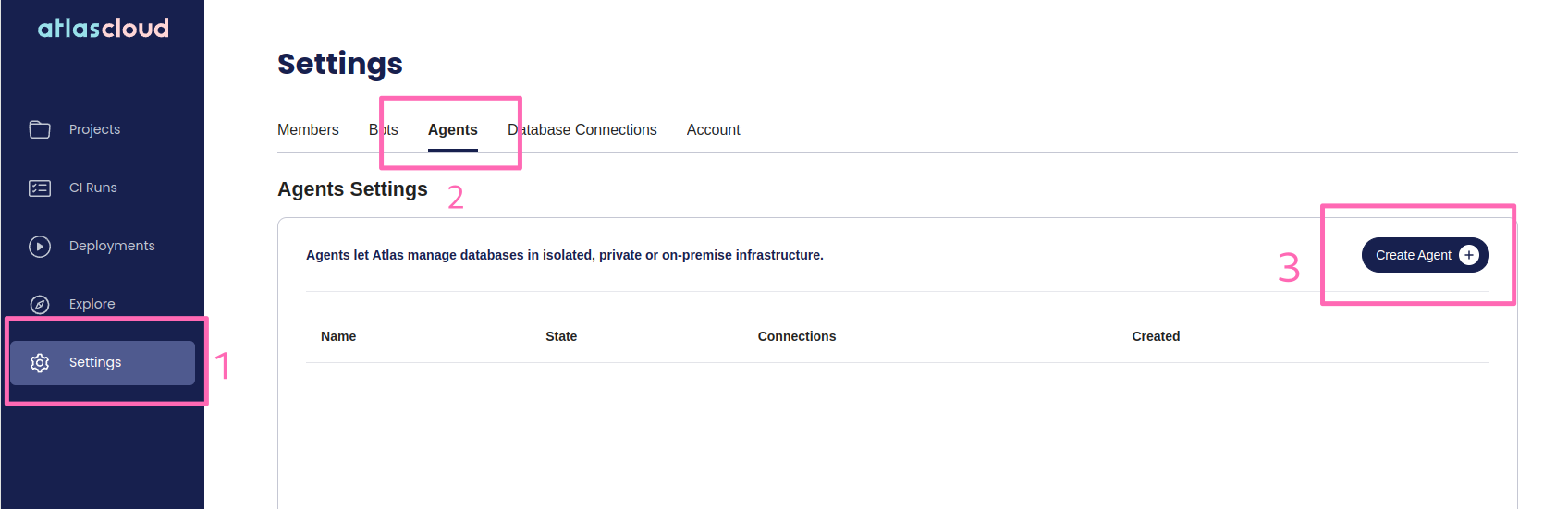 -
-
-
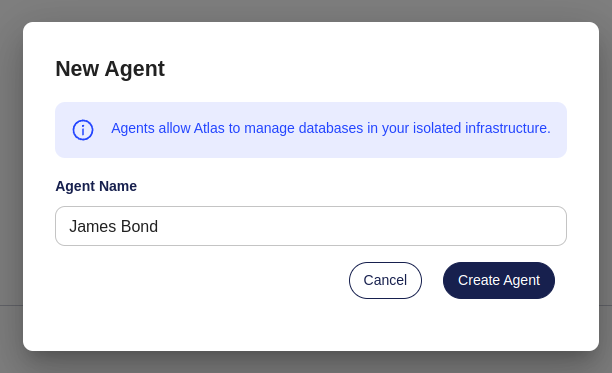
-### Connect the Agent
-
-Now that we have created an Agent in your Atlas Cloud account, we can run an Agent process. This is typically done by
-running it in the same network as our target database. To authenticate against your Atlas Cloud account, a token will
-be created which you will need to provide the Agent with. Store this token in a secure place, as you won't be able to
-see it again. If needed, you can always create a new one later.
-
-Screenshot Example
- - -
-
-
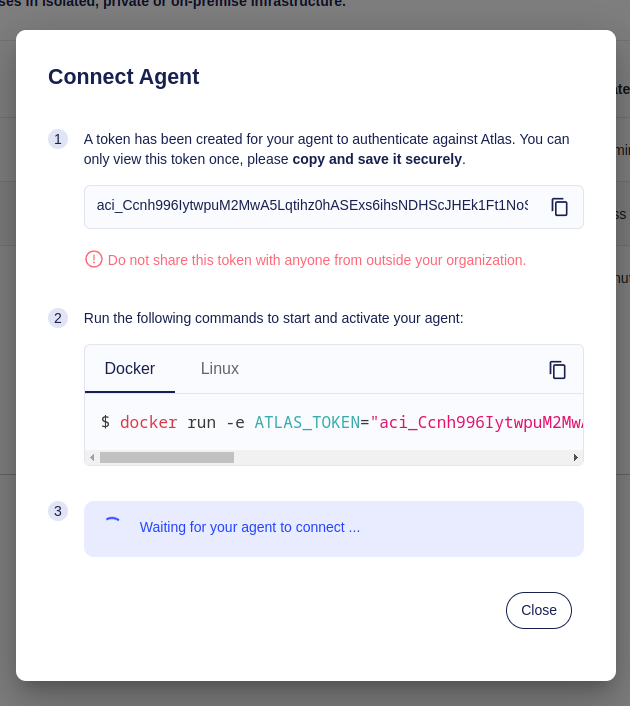
-To start the Agent and let it poll work from Atlas Cloud, simply follow the instructions shown. Currently, Ariga
-provides two builds, a docker image and a linux amd64 binary. All you need to provide the Agent with is a token to
-authenticate against Atlas Cloud.
-
-Screenshot Example
- - -
-
-
-Now the Agent is running and can connect to Atlas. However, in order to connect to your databases, it needs to know
-how to obtain valid credentials and how to use them.
-
-### Database Credentials
-
-Since we want the Agent to connect to our database on behalf of Atlas, it needs to know how to access it.
-For this we can assign an Agent multiple database connections. Either click the **Set up Database Connection** or
-select the **Database Connections** tab and hit **Create Connection**.
-
-:::info
-You can only create a connection with an actively running Agent. If there is no Agent selectable in the dropdown,
-ensure the Agent binary is still running and has access to the cloud.
-:::
-
-Fill out the form with the connection details to your database.
-
-Screenshot Example
- -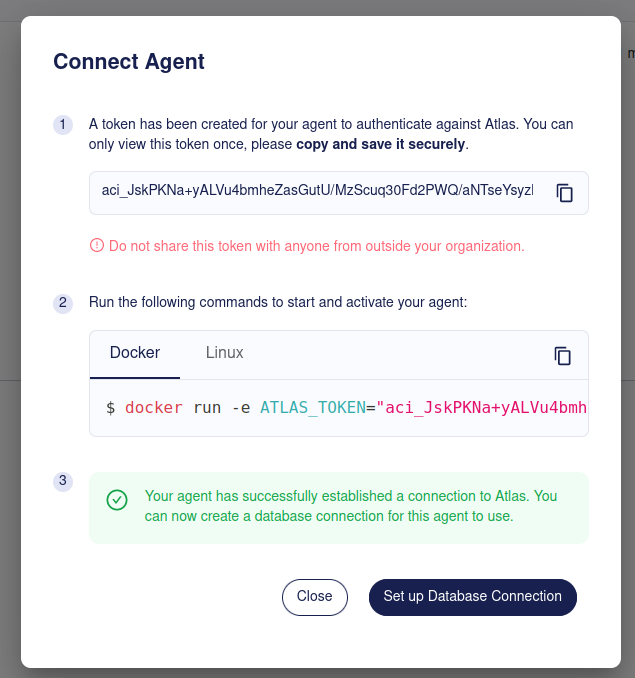 -
-
-
-Screenshot Example
- -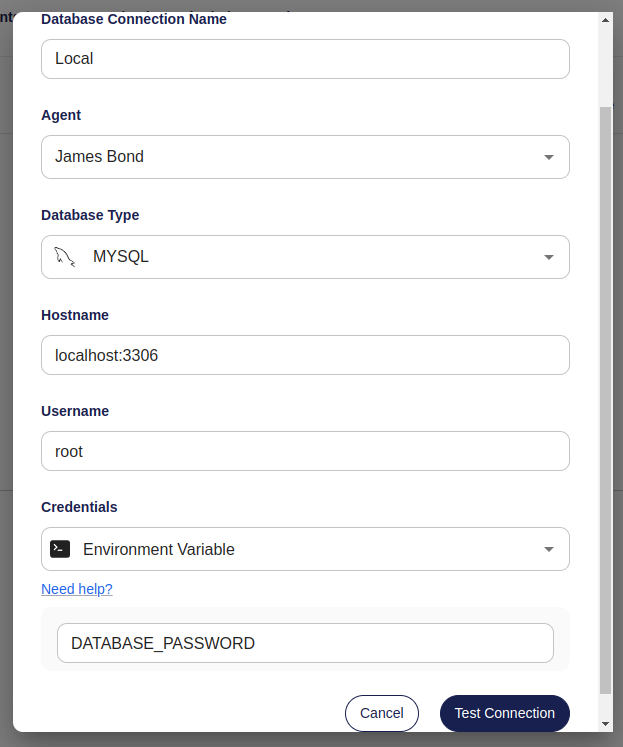 -
-
-
-### Drift Detection
-
-Once Atlas can connect to your database, it can start monitoring your schema and warn you if it detects a drift
-between your migration directory and its deployment. In the migration directory overview, click on
-**Enable Drift Detection**. You'll be asked which database connection the deployments are reachable on.
-
-Screenshot Example
- -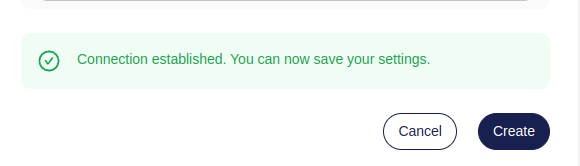 -
-
-
-Once enabled, Atlas will run drift detection jobs twice a day. If there is a drift, Atlas will provide you with detailed
-information about the drift, including an ERD, HCL diff and SQL statements required to fix the drift.
-
-:::caution
-Do not apply the SQL blindly to fix the drift. It is potentially destructive.
-:::
-
-Screenshot Example
- - -
-
-
-### Notifications
-
-You can instruct Atlas to notify you if there is a drift. Atlas supports various channels, such as email, Slack,
-Workplace or by a plain webhook.
-
-Screenshot Example
- -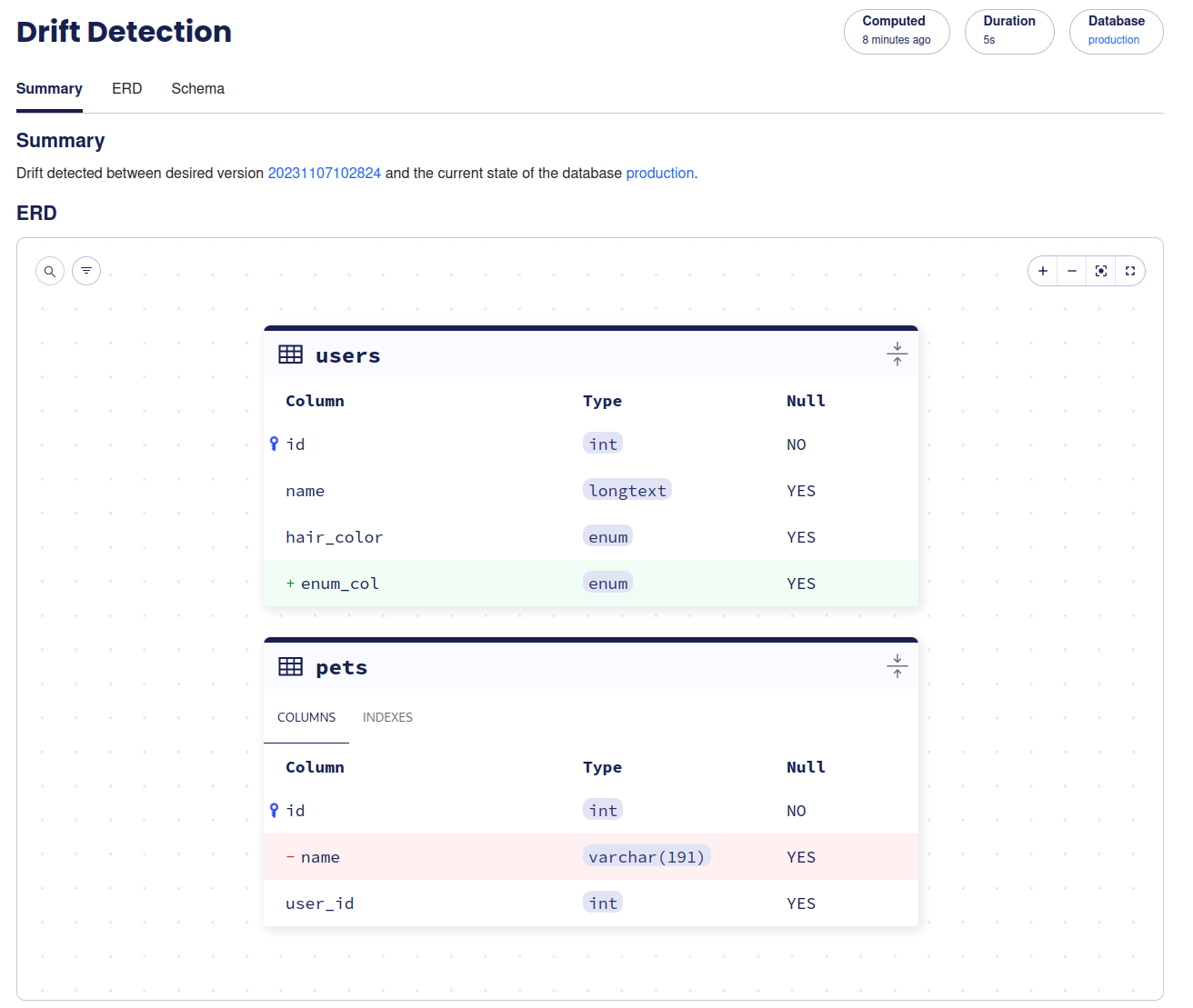 -
-
diff --git a/doc/md/cloud/beta-drivers.mdx b/doc/md/cloud/beta-drivers.mdx
deleted file mode 100644
index b9266e671a4..00000000000
--- a/doc/md/cloud/beta-drivers.mdx
+++ /dev/null
@@ -1,38 +0,0 @@
----
-id: beta-drivers
-title: Get access to beta drivers
----
-
-Atlas Cloud users can get early access to beta drivers by joining the Atlas Cloud Beta Program. To join the program,
-you first need to create an account on Atlas Cloud, enable it in your account settings, and then login to the CLI
-using your Atlas identity.
-
-### Sign up to Atlas Cloud
-
-The first step is to sign up to [Atlas Cloud](https://auth.atlasgo.cloud/signup). If you already have an account, you can skip this step.
-
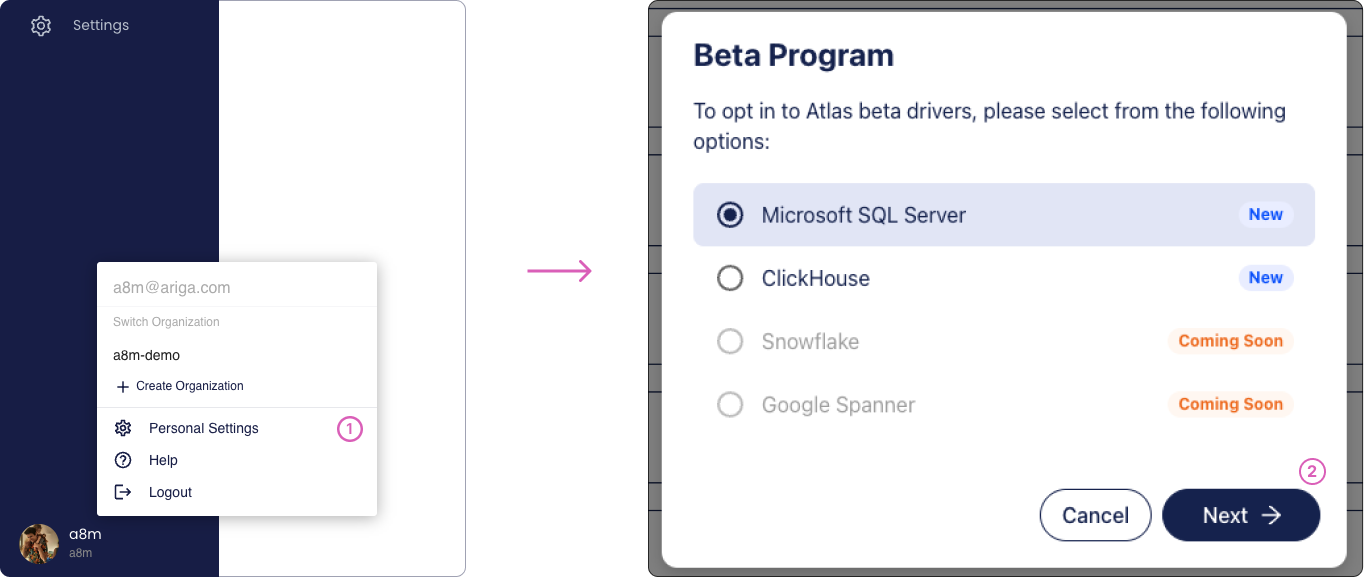
-### Opt-in to the beta program
-
-Go to the account settings by clicking your avatar. Then, select the driver you want to get access to. For example,
-Microsoft SQL Server.
-
-
-
-### Login to the CLI
-
-Then, run `atlas login` to login or update your account permissions:
-
-```text
-$ atlas login a8m
-//highlight-next-line-info
-You are now connected to "a8m" on Atlas Cloud.
-```
-
-### Use the beta driver
-
-```bash
-atlas schema apply \
- --url "sqlserver://sa:P@ssw0rd0995@localhost:1433?database=master" \
- --to "file://schema.hcl"
-```
-
diff --git a/doc/md/cloud/bot.mdx b/doc/md/cloud/bot.mdx
deleted file mode 100644
index dcc6fc1c31a..00000000000
--- a/doc/md/cloud/bot.mdx
+++ /dev/null
@@ -1,32 +0,0 @@
----
-title: Creating Bots
-id: bots
-slug: /cloud/bots
----
-
-Bots are "headless" users that can be used to perform certain actions against the Atlas Cloud API, such as pushing and
-reading schema changes from the Registry, or reporting CI and migration statuses. However, bots **cannot be used for local
-development** or to access the Atlas Cloud UI.
-
-:::info Token Usage For Local Development
-Organizations on the Community (Free) plan cannot use bot tokens for local development, and must use their personal
-tokens instead. Personal tokens are issued by running `atlas login` and are limited to the users who created them.
-:::
-
-### Creating a Bot User
-
-To create a bot user, make sure you are logged in as an administrator to you Atlas Cloud account.
-
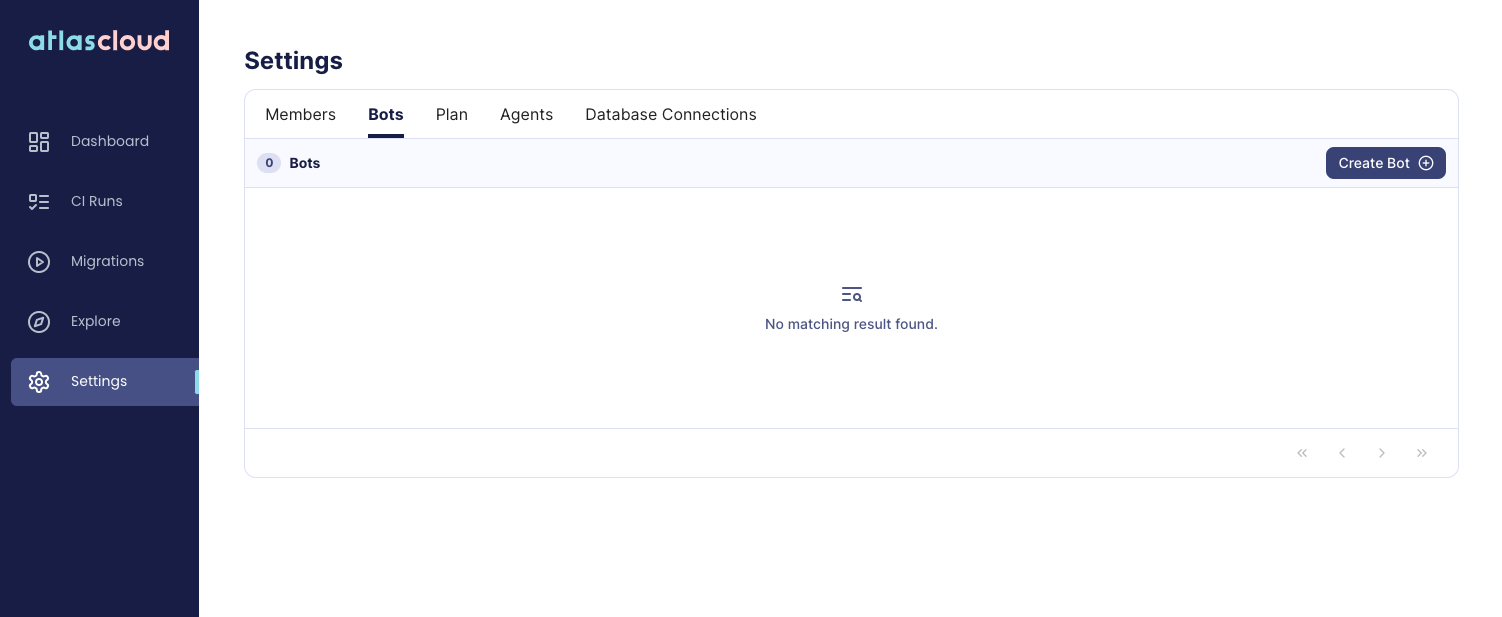
-Follow these steps to create a new bot user:
-1. To get to the bot management screen, click on _**Settings > Bots**_ in the left navigation.
- In this screen, click on the _**Create Bot**_ button.
-
- 
-
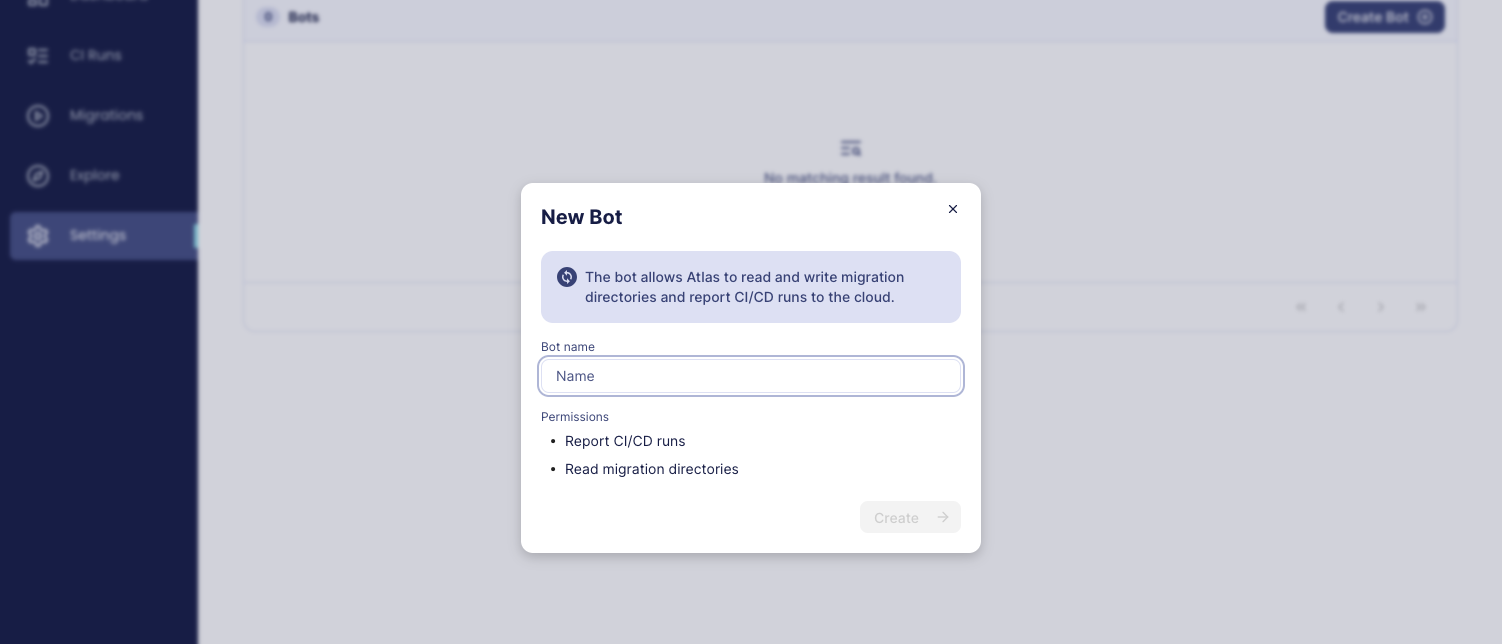
-2. Give your bot a name and click _**Create**_.
-
- 
-
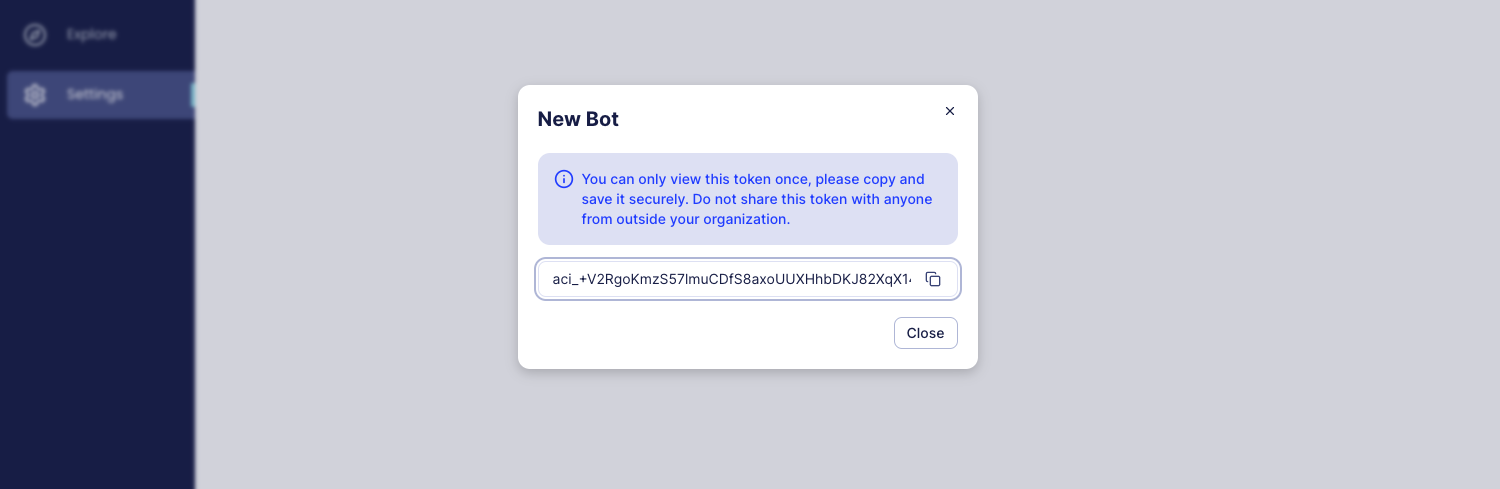
-3. Copy the token and store it in a safe place. You will not be able to see it again.
-
- 
diff --git a/doc/md/cloud/deployment.mdx b/doc/md/cloud/deployment.mdx
deleted file mode 100644
index b08f274cc9f..00000000000
--- a/doc/md/cloud/deployment.mdx
+++ /dev/null
@@ -1,81 +0,0 @@
----
-id: deployment
-title: Deploying migrations from Atlas Cloud
----
-
-import Tabs from '@theme/Tabs';
-import TabItem from '@theme/TabItem';
-
-### Deploying without Atlas Cloud
-
-A common way to deploy migrations using Atlas (or any other migration tool) is similar to this:
-
-* When changes are merged to the `main` branch, a CI/CD pipeline is triggered.
-* The pipeline builds an artifact (usually a Docker image) that includes the migration directory content
- and Atlas itself.
-* The artifact is pushed to a registry.
-* The deployment process is configured to use this newly created image to run the migrations
- against the production database.
-
-This process is a common practice, but it requires setting up a CI/CD pipeline (including storage, permissions,
-and other glue) for each service, adding another layer of complexity.
-
-### Why deploy from Atlas Cloud?
-
-Atlas Cloud streamlines deploying migrations by providing a single place to manage migrations for all your services. After connecting
-your migration directory to Atlas Cloud, it is automatically synced to a central location on every commit to your main branch.
-Once this setup (which takes less than one minute) is complete, you can deploy migrations from Atlas Cloud to any environment
-with a single command (or using popular CD tools such as Kubernetes and Terraform).
-
-## Deploying migrations from Atlas Cloud
-
-To read the migration directory from the [Schema Registry](https://atlasgo.io/cloud/features/registry),
-use the `atlas://` scheme in the migration URL as follows:
-
-```hcl title="atlas.hcl"
-env {
- // Set environment name dynamically based on --env value.
- name = atlas.env
- migration {
- // In this example, the directory is named "myapp".
- dir = "atlas://myapp"
- }
-}
-```
-
-Now you can deploy migrations from Atlas Cloud using the following command:
-
-```shell
-export ATLAS_TOKEN="Screenshot Example
- - -
-
-  -
-
-
-
-
-### Setup CI
-
-After setting up your migration directory, the next step is to add Atlas to your CI pipeline. This ensures that the
-migration files are checked and reviewed before being merged into the main branch. Below are the supported CI platforms
-Atlas currently supports:
-
-- [GitHub Actions](/cloud/setup-ci#github-action-workflow)
-- [GitLab CI](/guides/ci-platforms/gitlab)
-- Using other CI platforms? [Let us know!](https://github.com/ariga/atlas/issues/new)
-
-
-### Setup CD
-
-Atlas Cloud streamlines deploying migrations by providing a single place to manage migrations for all your services.
-After connecting your migration directory to Atlas Cloud, it is automatically synced to a central location on every
-commit to your main branch. Once this setup (which takes less than one minute) is complete, you can deploy migrations
-from Atlas Cloud to any environment with a single command (or using popular CD tools such as Kubernetes and Terraform).
-
-For more information, visit the _Introduction to schema migrations deployments_ in the [guides section](/guides/deploying/intro).
-
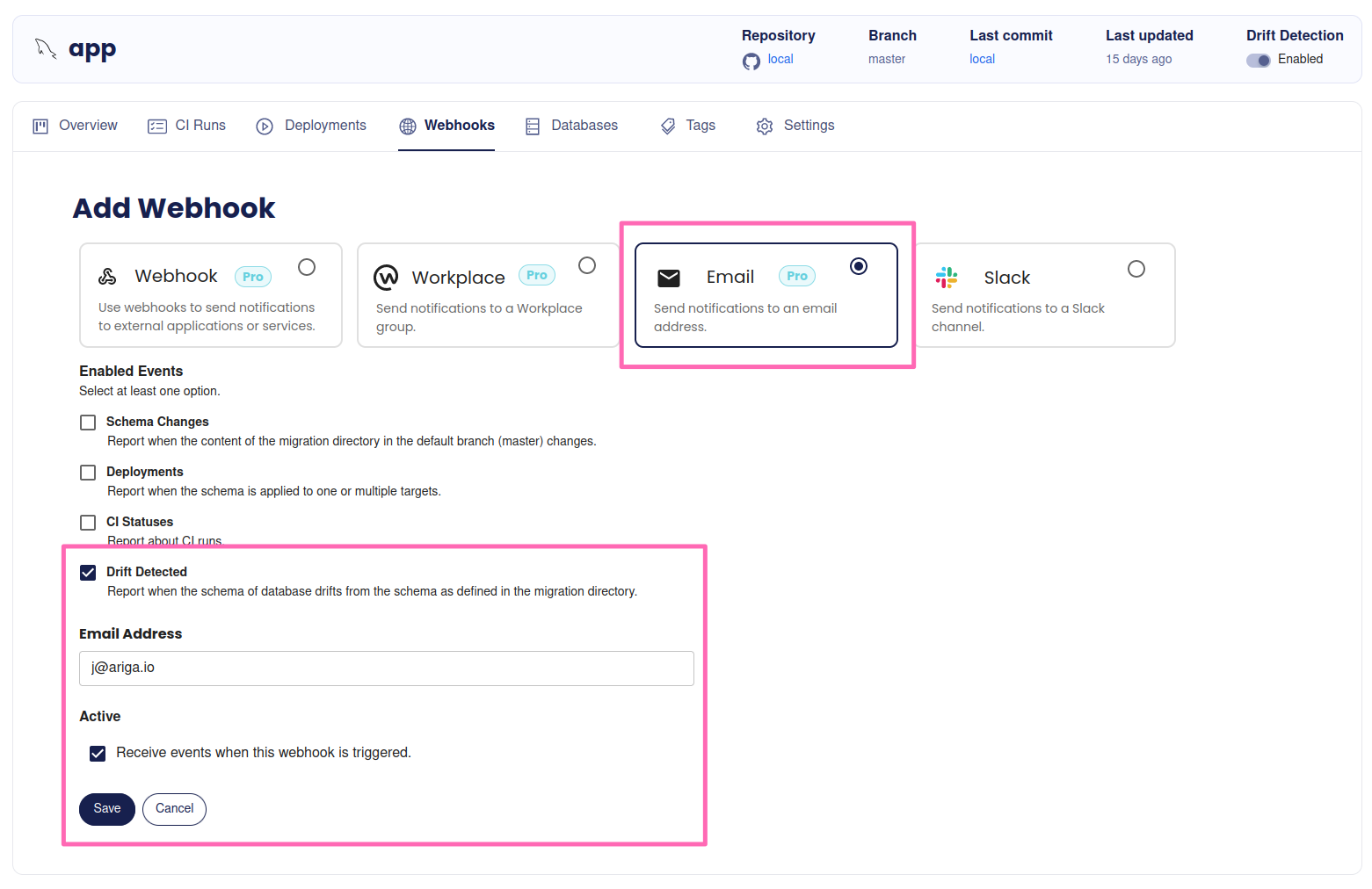
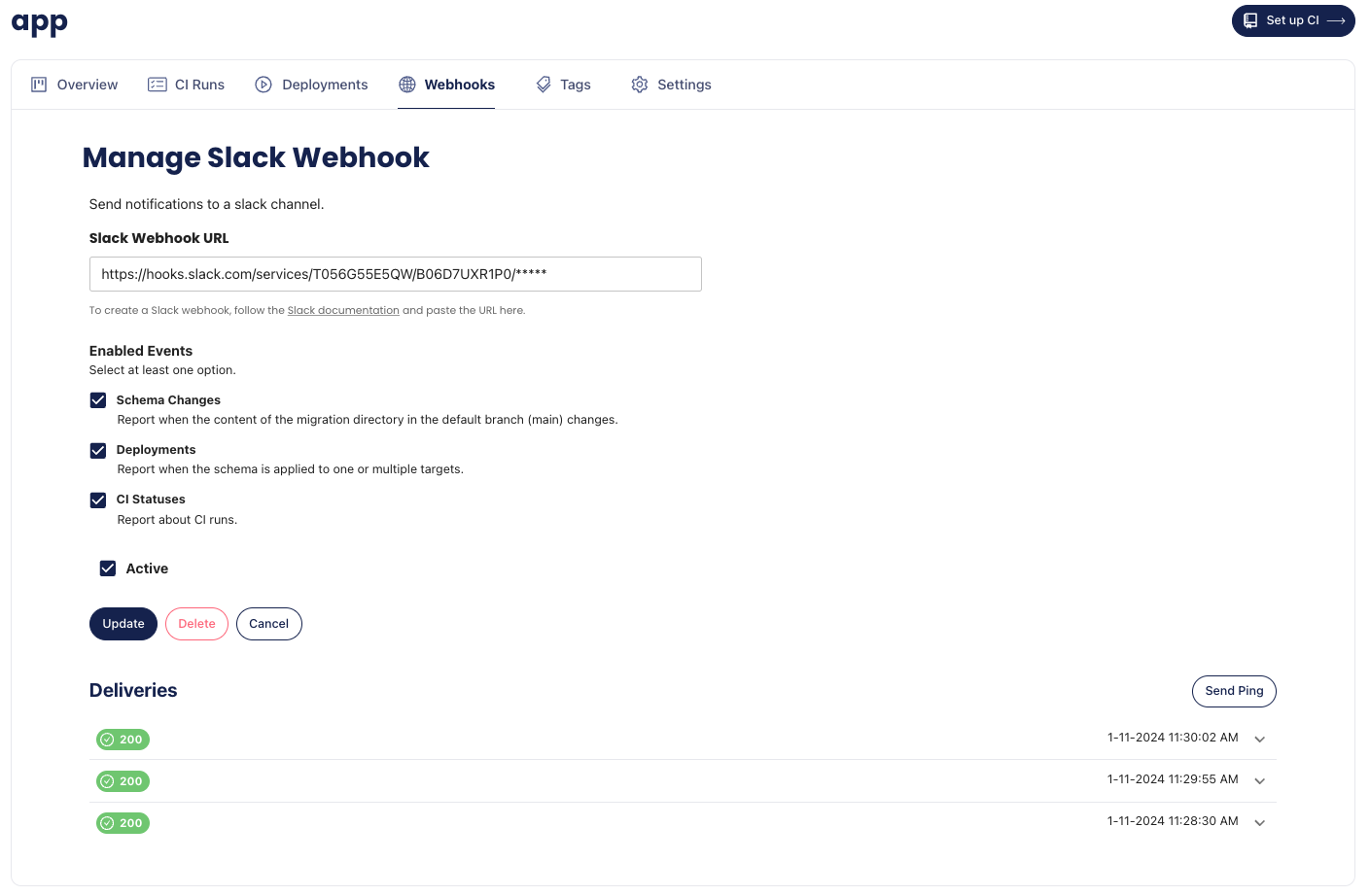
-### Slack Integration
-
-You can use Slack Webhooks to receive updates in your Slack channel about schema changes, CI runs and deployment statuses of your migration directory.
-Make sure you have a Slack incoming webhook configured
-(you can create one [here](https://my.slack.com/services/new/incoming-webhook)).
-
-Select your migration directory, go to "Webhooks" and click on **Add Webhook**.
-
-
- Migration Directory created with atlas migrate push
-
-
-
-Select the Slack integration, Choose the events you want to be notified about and insert your webhook URL.
-Click on **Add Webhook** to confirm.
-
-Once the Webhook is created, you will be redirected to the Webhooks page.
-Select a webhook to edit its configuration and to view its delivery history.
-Screenshot example
- -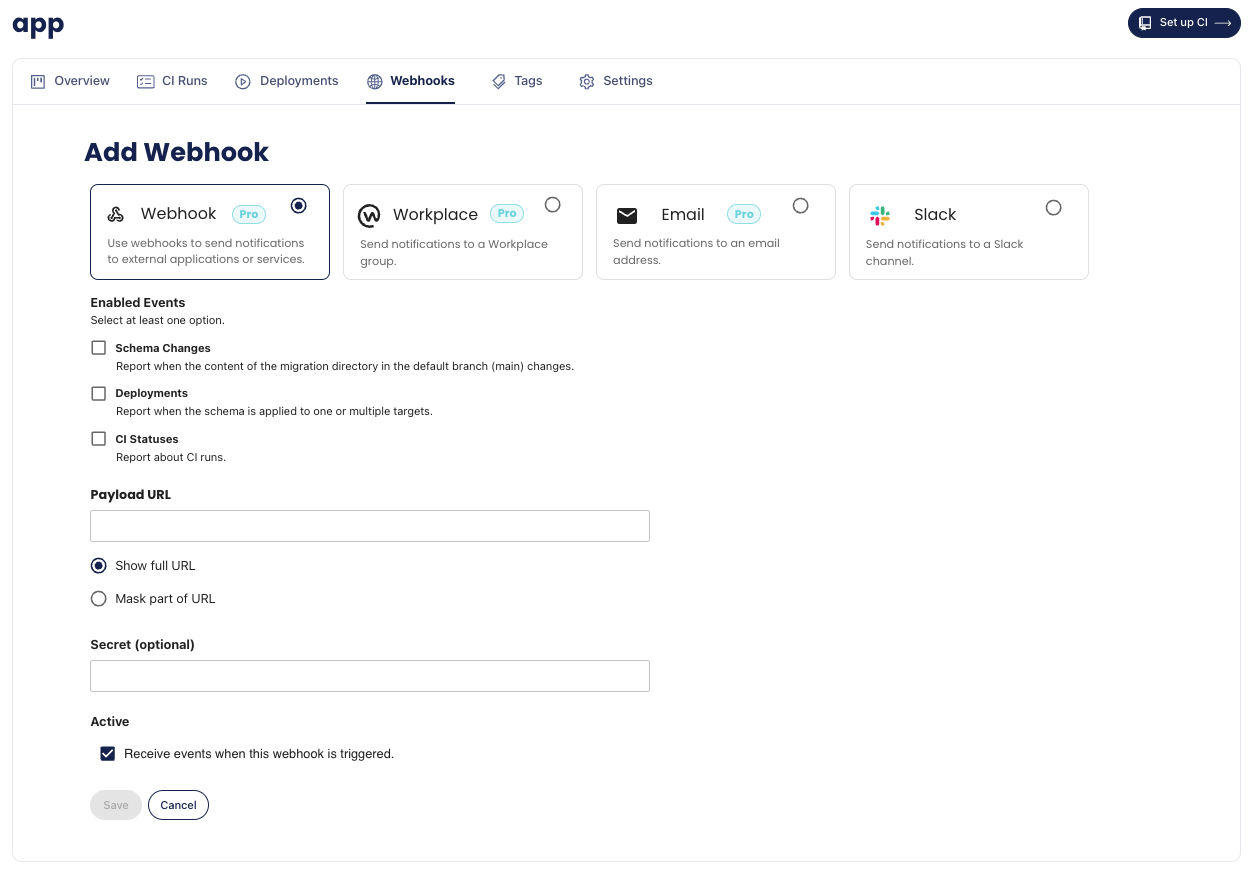 - -
-
-
-You can also test the webhook by clicking on `Send Ping`.
diff --git a/doc/md/cloud/features/pre-migration-checks.mdx b/doc/md/cloud/features/pre-migration-checks.mdx
deleted file mode 100644
index 75f544f3be3..00000000000
--- a/doc/md/cloud/features/pre-migration-checks.mdx
+++ /dev/null
@@ -1,102 +0,0 @@
----
-title: Pre-migration checks
-id: pre-migration-checks
-slug: /cloud/features/pre-migration-checks
----
-
-## Overview
-
-With pre-migration checks, you can provide a list of assertions to make on the target database
-before starting a migration. This can greatly reduce the failure rate of migrations by catching
-issues early.
-
-## Why use pre-migration checks?
-
-Atlas provides a [comprehensive set of safety checks](/lint/analyzers) that can be made against migrations during the
-Continuous Integration (CI) process.
-
-However, some issues can only be classified as "might fail" during the CI process because they depend on the
-actual state of the target database. For example, a migration might fail when you're adding a uniqueness
-constraint to a column that already contains duplicate values. Alternatively, you might decide that you only
-want to delete a column if it doesn't contain data.
-
-## How it works
-
-To add these checks, Atlas supports a text-based file archive to describe "migration plans". Unlike regular migration files,
-which mainly contain a list of DDL statements (with optional directives), Atlas `txtar` files (currently) support two file
-types: migration files and pre-execution check files.
-
-The code below presents a simple example of a pre-migration check. The default checks file is named `checks.sql`,
-and the `migration.sql` file contains the actual DDLs to be executed on the database in case the assertions are passed.
-
-```sql title="20240201131900_drop_users.sql"
--- atlas:txtar
-
-// highlight-next-line
--- checks.sql --
--- The assertion below must be evaluated to true. Hence, the "users" table must not contain any rows.
-SELECT NOT EXISTS(SELECT * FROM users);
-
-// highlight-next-line
--- migration.sql --
--- The statement below will be executed only if the assertion above evaluates to true.
-DROP TABLE users;
-```
-
-If the pre-execution checks pass, the migration will be applied and Atlas will report the results.
-
-```bash
-atlas migrate --dir atlas://app --env prod
-```
-
-
-
-```applylog title="Output"
-Migrating to version 20240201131900 from 20240201131800 (1 migrations in total):
-
-// highlight-start
- -- checks before migrating version 20240201131900
- -> SELECT NOT EXISTS(SELECT * FROM users);
- -- ok (624.004µs)
-// highlight-end
-
- -- migrating version 20240201131900
- -> DROP TABLE users;
- -- ok (5.412737ms)
-
- -------------------------
- -- 22.138088ms
- -- 1 migration
- -- 1 check
- -- 1 sql statement
-```
-
-If the pre-execution checks fail, the migration will not be applied, and Atlas will exit with an error.
-
-```bash
-atlas migrate --dir atlas://app --env prod
-```
-
-
-
-```applylog title="Output"
-Migrating to version 20240201131900 from 20240201131800 (1 migrations in total):
-
- -- checks before migrating version 20240201131900
- -> SELECT NOT EXISTS(SELECT * FROM internal_users);
- -> SELECT NOT EXISTS(SELECT * FROM external_users);
- -- ok (1.322842ms)
-
- -- checks before migrating version 20240201131900
- -> SELECT NOT EXISTS(SELECT * FROM roles);
- -> SELECT NOT EXISTS(SELECT * FROM user_roles);
- 2 of 2 assertions failed: check assertion "SELECT NOT EXISTS(SELECT * FROM user_roles);" returned false
-
- -------------------------
- -- 19.396779ms
- -- 1 migration with errors
- -- 2 checks ok, 2 failures
-Error: 2 of 2 assertions failed: check assertion "SELECT NOT EXISTS(SELECT * FROM user_roles);" returned false
-```
-
-
diff --git a/doc/md/cloud/features/registry.mdx b/doc/md/cloud/features/registry.mdx
deleted file mode 100644
index b3ba6095284..00000000000
--- a/doc/md/cloud/features/registry.mdx
+++ /dev/null
@@ -1,169 +0,0 @@
----
-title: Atlas Registry
-id: registry
-slug: /cloud/features/registry
----
-
-Atlas Registry allows you to store, version, and maintain a single source of truth for your database schemas,
-database migrations, and additional assets related to schema changes. It is like Docker Hub for Atlas schemas and
-migrations.
-
-## Getting Started
-
-### Pushing a Schema
-
-The `atlas schema push` command allows you to push your schema definition to the Atlas Registry. If no repository exists
-in the registry for the schema, a new one is created. Otherwise, a new version is generated.
-
-```bash {4}
-atlas schema push myapp \
- --env local
-
-https://example.atlasgo.cloud/schemas/141733920769
-```
-
-Once pushed, the schema is available to others in your organization and can be referenced in your deployment pipelines.
-
-Screenshot example
- - - -
-  -
-
-
-#### Registry Config for Schemas
-
-The example below demonstrates how to configure the registry for your schema within an `env` block. All commands
-executed in this environment will automatically use the configured repository:
-
-```hcl title="atlas.hcl" {6-13}
-env "local" {
- # URL to the underlying database.
- url = env("DATABASE_URL")
- # URL to the dev-database.
- dev = "sqlite://dev?mode=memory"
- schema {
- # Desired schema state.
- src = "file://schema.sql"
- # Atlas Registry config.
- repo {
- name = "myapp"
- }
- }
-}
-```
-
-### Pushing a Migration Directory
-
-The `atlas migrate push` command allows you to push your migration directory to the Atlas Registry. If no repository
-exists in the registry for the pushed directory, a new one is created. Otherwise, the directory state will be updated.
-
-```bash {4}
-atlas migrate push myapp \
- --env local
-
-https://example.atlasgo.cloud/dirs/4294967370
-```
-
-Once pushed, the migration directory is available to others in your organization and can be referenced in your deployment
-pipelines.
-
-Note that Atlas Registry is schema-aware. In addition to storing and versioning your migrations, it provides ER diagrams,
-SQL diffing, [schema docs](/cloud/features/schema-docs), and other capabilities that make working with your
-schema easier.
-
-
- Schema created with atlas schema push
-
-
-
-#### Registry Config for Migration Directories
-
-The example below demonstrates how to configure the registry for your migration directory within an `env` block.
-All commands executed in this environment will automatically use the configured repository:
-
-```hcl title="atlas.hcl" {8-13}
-env "local" {
- # URL to the underlying database.
- url = env("DATABASE_URL")
- # URL to the dev-database.
- dev = "sqlite://dev?mode=memory"
- # URL to the desired schema state.
- src = "file://schema.sql"
- migration {
- # Atlas Registry config.
- repo {
- name = "myapp"
- }
- }
-}
-```
-
-## Simplifying Deployments
-
-When you push a migration directory to the Schema Registry, you can give it a tag in the same way that you would tag a
-Docker image. This makes any version of your schema effectively _addressable_ which dramatically simplifies deployments.
-
-References to a schema version can then be used in your deployment pipelines with an expression similar to:
-
-```bash
-# Reference by version
-atlas migrate apply \
- --dir "atlas://myapp?version=20231201182011" \
- --url "postgres://postgres:pass@:5432/example?search_path=public&sslmode=disable"
-
-# Reference by tag
-atlas migrate apply \
- --dir "atlas://app?tag=39e7e4e35fce7409bd26d25d8140061695d4ffd5" \
- --url "postgres://postgres:pass@:5432/example?search_path=public&sslmode=disable"
-```
-
-Using the Schema Registry completely eliminates the need to create custom Docker images for migrations or grant your runtime
-environments access to your source code repository.
-
-### Example: Kubernetes Deployment
-
-Let's see how we can use tagged schema versions in a Kubernetes deployment:
-
-```yaml
-apiVersion: db.atlasgo.io/v1alpha1
-kind: AtlasMigration
-metadata:
- name: migration
-spec:
- urlFrom:
- secretKeyRef:
- key: url
- name: postgres-credentials
- cloud:
- project: "atlasdemo" # Atlas Cloud project name
- tokenFrom:
- secretKeyRef:
- name: atlas-credentials
- key: token
- dir:
- // highlight-start
- remote:
- name: "myapp" # Migration directory name in your atlas cloud project
- tag: "39e7e4e35fce7409bd26d25d8140061695d4ffd5" # See below on how to obtain this value for your project.
- // highlight-end
-```
-
-### Example: Terraform
-
-You can also use references to the Schema Registry in your Terraform modules:
-
-```hcl
-resource "atlas_migration" "myapp" {
- url = "postgres://postgres:pass@:5432/example?search_path=public&sslmode=disable"
- // highlight-start
- remote_dir {
- name = "myapp"
- tag = "39e7e4e35fce7409bd26d25d8140061695d4ffd5"
- }
- // highlight-end
-}
-```
-
-## Additional Benefits
-
-* [Schema Docs](schema-docs.mdx) - Get automatically generated documentation for your schemas when you
- push them to the Schema Registry.
\ No newline at end of file
diff --git a/doc/md/cloud/features/schema-docs.mdx b/doc/md/cloud/features/schema-docs.mdx
deleted file mode 100644
index 4a6514f467a..00000000000
--- a/doc/md/cloud/features/schema-docs.mdx
+++ /dev/null
@@ -1,36 +0,0 @@
----
-title: Schema Docs
-id: schema-docs
-slug: /cloud/features/schema-docs
----
-
-
-
- Migration Directory created with atlas migrate push
 -
-### Overview
-
-Atlas Cloud maintains always up-to-date, automatically generated documentation for your database schema.
-
-### Why Schema Docs?
-
-When working in a larger organization, having up-to-date documentation of the database schema
-becomes increasingly important. Whether it's for onboarding new team members, or for streamlining
-collaboration between different functions in the organization, having a single source of truth for the database schema
-in a format that is easy to understand and navigate is crucial.
-
-In addition, as a company matures, it is common to see some databases grow in complexity to a point where it becomes
-difficult to keep track of all the tables, columns, and relationships. After many years of development and changes,
-it is not uncommon to see databases with hundreds of tables and thousands of columns whose authors are no longer with
-the company. In such cases, having a tool that can automatically generate and keep up-to-date the documentation of the database
-can bring clarity and understanding that is necessary for the organization to continue to grow and evolve.
-
-### How it works
-
-Schema Docs are regenerated whenever you push a new version of your schema to Atlas Cloud. It is therefore
-recommended to set up your CI pipeline in such a way that it pushes the schema to Atlas Cloud whenever changes are made to the
-main branch of your project.
-
-[Learn how to connect a directory to Atlas Cloud](/cloud/directories)
-
-Schema Docs available from within the project overview page. You can access it by clicking on the "Docs" tab
-at the top of the page.
diff --git a/doc/md/cloud/features/troubleshooting.mdx b/doc/md/cloud/features/troubleshooting.mdx
deleted file mode 100644
index d545429c828..00000000000
--- a/doc/md/cloud/features/troubleshooting.mdx
+++ /dev/null
@@ -1,46 +0,0 @@
----
-title: Troubleshooting Migrations
-slug: /cloud/features/troubleshooting
----
-
-Troubleshooting and triaging failures during database migrations can be especially difficult. Errors often stem from data
-and schema changes, making it hard to identify the exact problem.
-
-When an error or migration failure occurs, it is crucial to understand what went wrong and assess the current state of
-the database.
-
-## Drill Down Analysis
-
-When reporting migration runs to Atlas Cloud, the detailed logs allow you to quickly drill down and troubleshoot
-any schema migration failures.
-
-The report shows what happened in the migration, what caused the failure, and the current state of the
-database post-deployment.
-
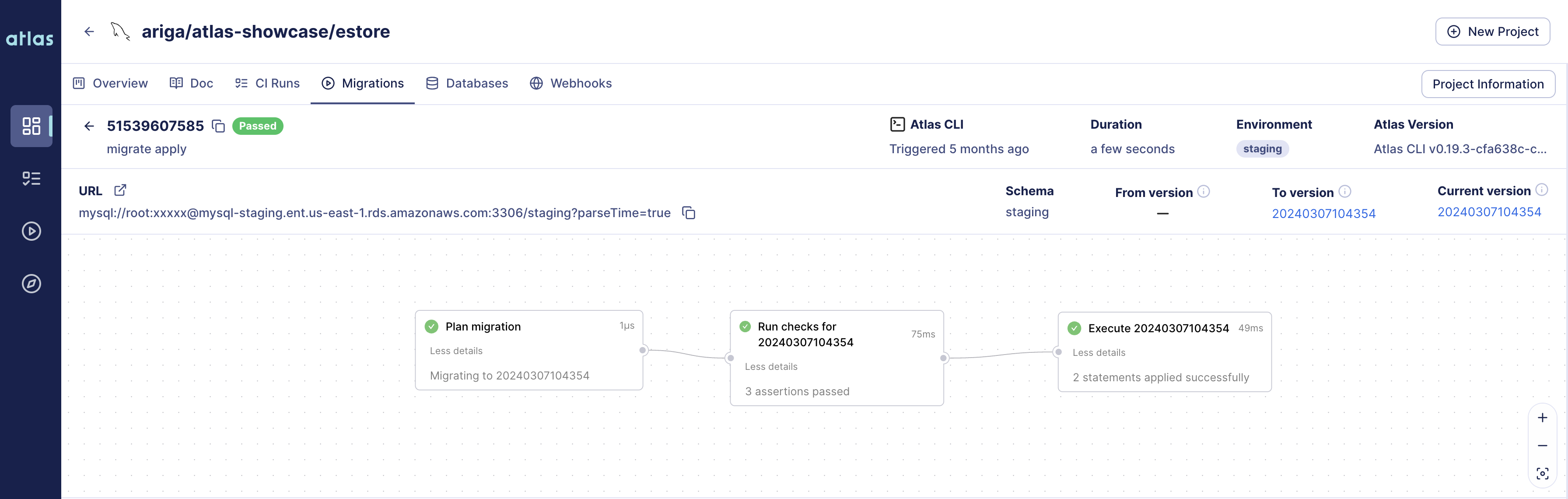
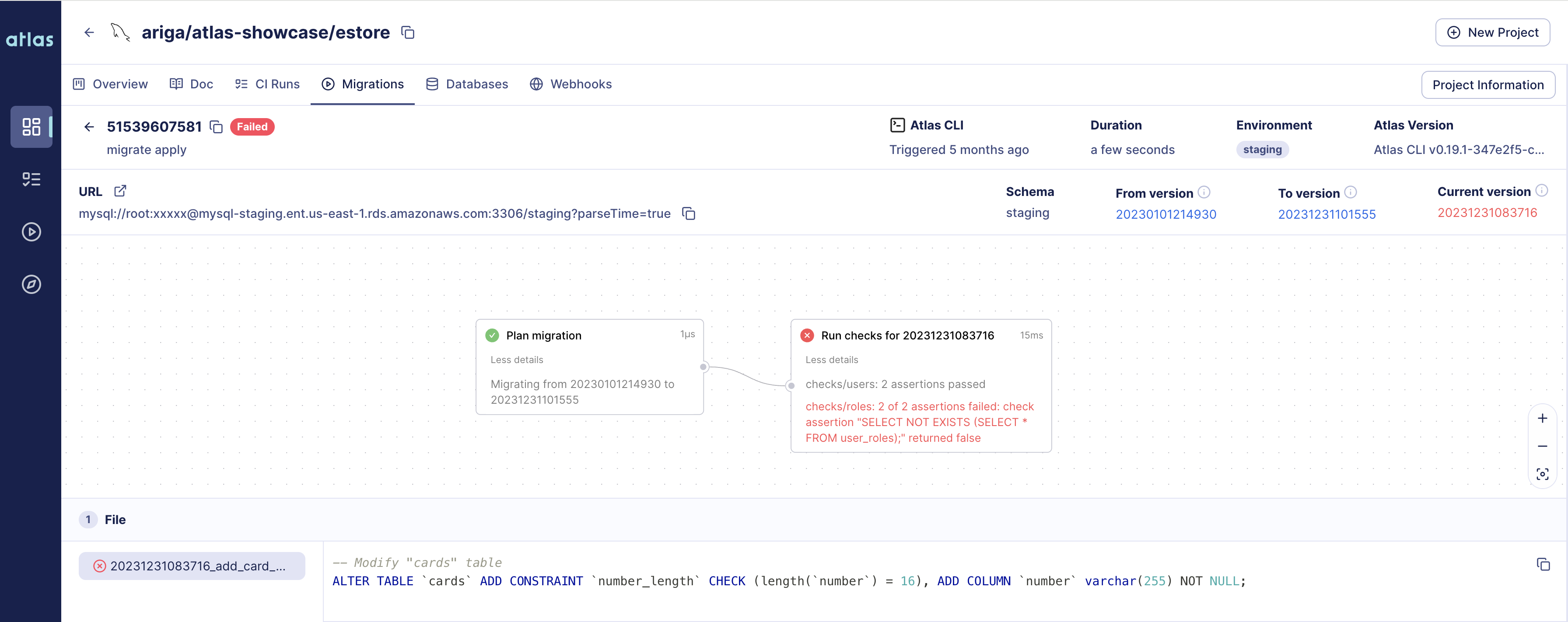
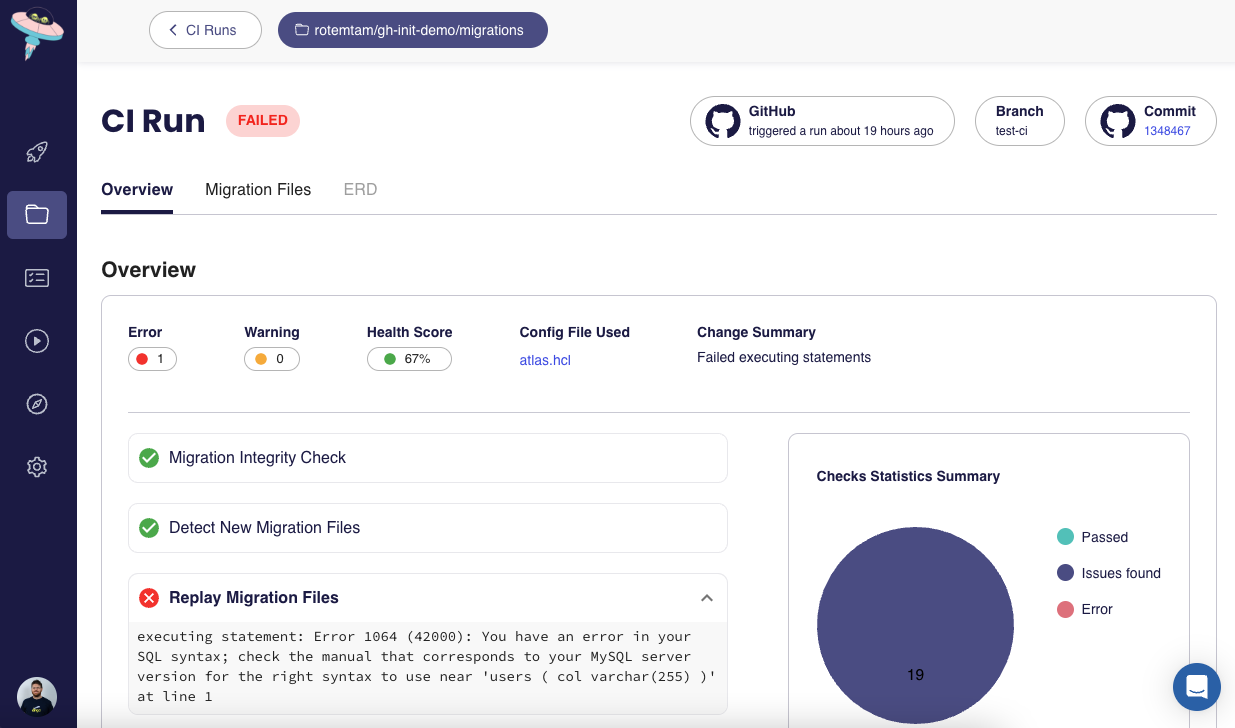
-For example, in the image below we can see a migration that failed due to a constraint, `number_length`, which
-was violated. This caused the migration to fail and only one of the three intended migration files was executed on
-the database.
-
-[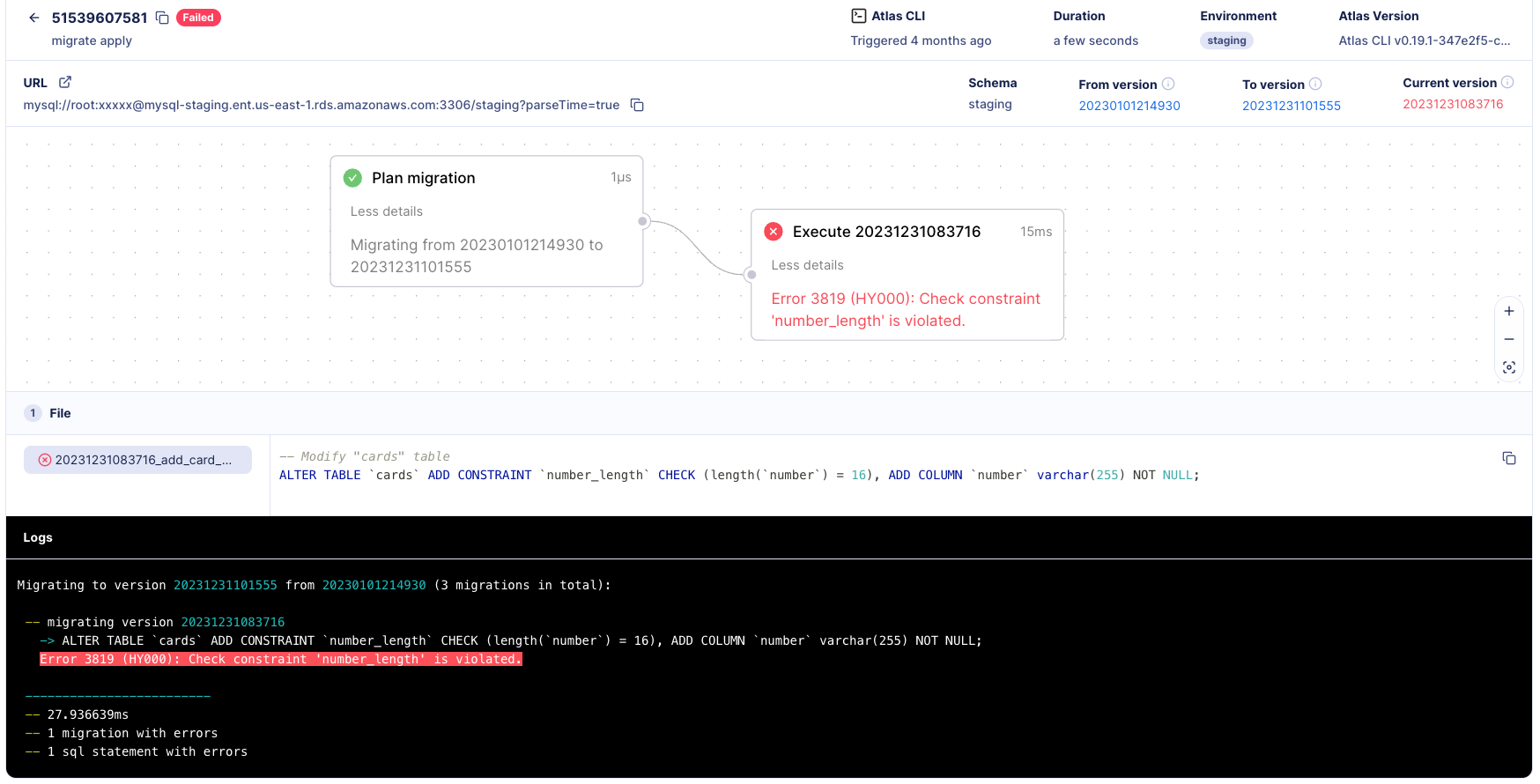](https://gh.atlasgo.cloud/dirs/4294967329/deployments/51539607581)
-
-### Database-per-Tenant Migrations
-
-In a database-per-tenant architecture, the same migration is executed on multiple databases. If a migration fails,
-the root cause of the error often involves tenant-specific data and schema changes, making it even more challenging to
-pinpoint issues.
-
-In this scenario, identifying which databases were affected and which remained unaffected is crucial to assess the impact
-and plan the next steps effectively.
-
-In the image below we can see the deployment intended to run on four different databases. The migration failed once it reached
-the third tenant, stopping the deployment entirely before reaching the last tenant's database.
-
-[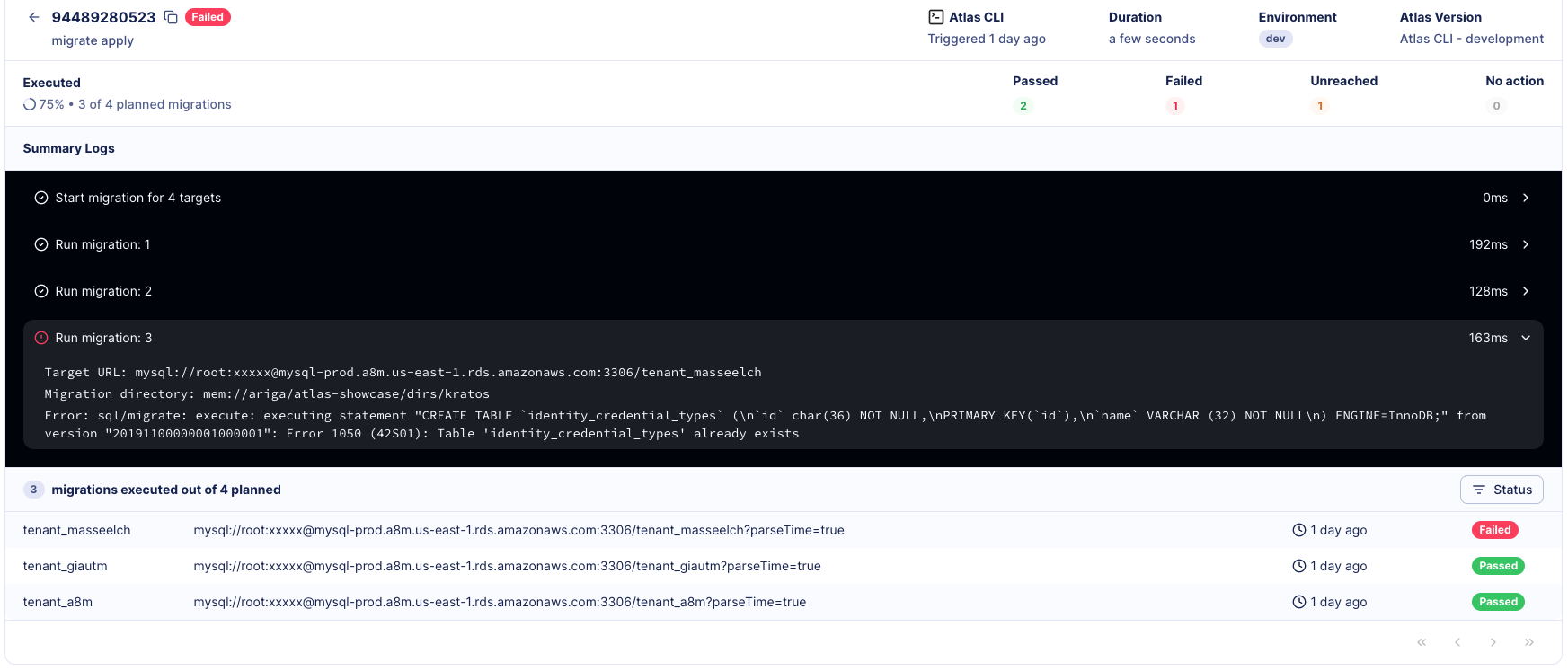](https://gh.atlasgo.cloud/dirs/4294967347/deployments/sets/94489280523)
-
-When examining the specific tenant that failed (as shown in the image below), we can see that the failure was caused by
-an attempt to create a table that already existed in the database.
-
-[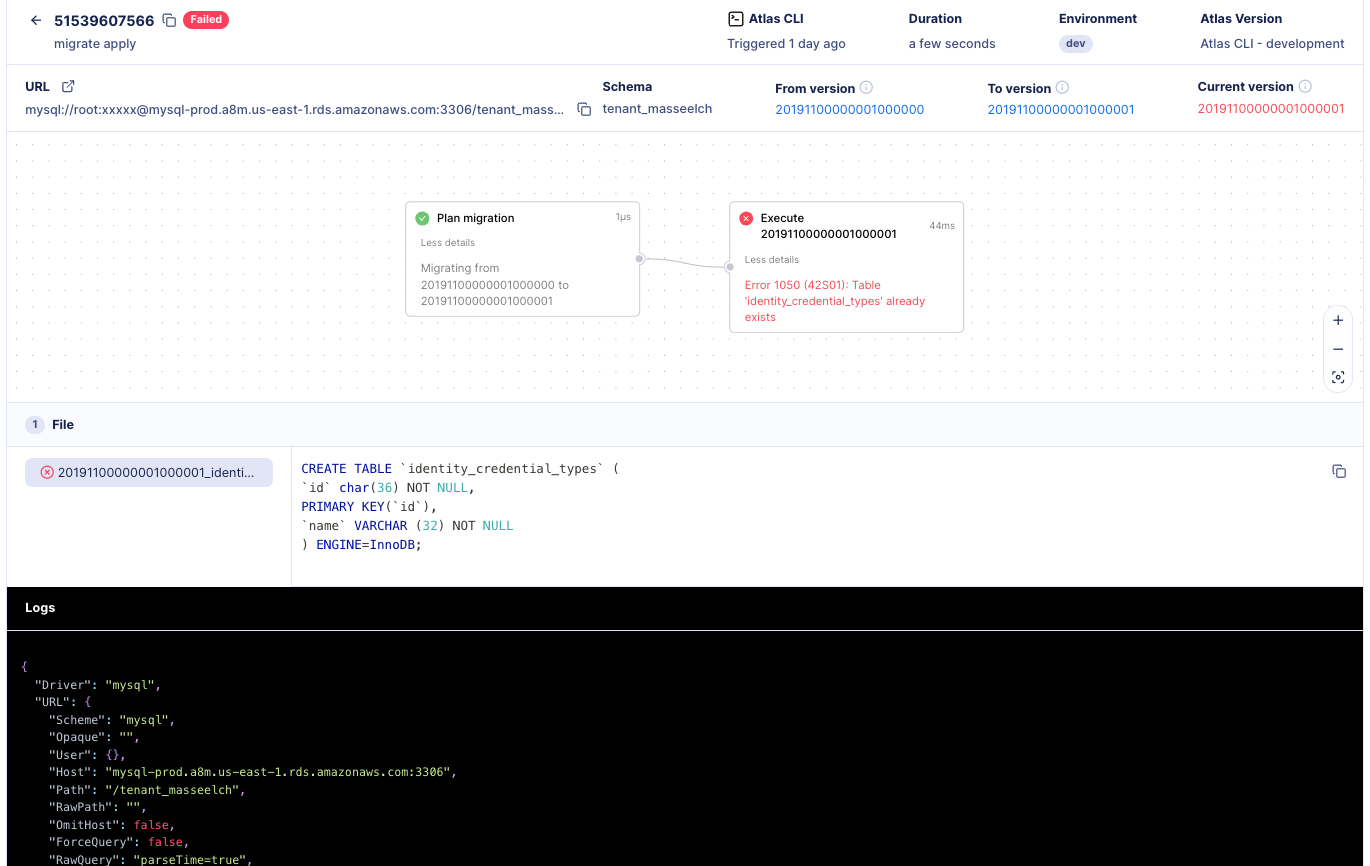](https://gh.atlasgo.cloud/dirs/4294967347/deployments/51539607566)
-
-The detailed deployment reports provide clarity on migration failures, allowing for efficient resolution and minimizing
-downtime.
diff --git a/doc/md/cloud/getting-started.mdx b/doc/md/cloud/getting-started.mdx
deleted file mode 100644
index 2f7ac6b8d54..00000000000
--- a/doc/md/cloud/getting-started.mdx
+++ /dev/null
@@ -1,64 +0,0 @@
----
-id: getting-started
-title: Getting Started with Atlas Cloud
-sidebar_label: Getting Started
----
-
-## What is Atlas Cloud?
-
-[Atlas Cloud](https://atlasgo.cloud) is an online platform that supplements the Atlas CLI
-to allow teams to build robust, end-to-end schema management workflows. We built it to help
-teams make the most out of Atlas with as little friction and effort as possible.
-
-## What can I do with Atlas Cloud?
-
-### For Individuals: Unlock the full power of Atlas CLI
-
-By logging in to Atlas Cloud, get access to enhanced schema management, such as views, triggers, functions and stored procedures.
-You will also get access to various database drivers, private visualizations, and more. For a full list of the CLI features
-that require login access, click [here](/features#feature-availability).
-
-### For Teams: Take database schema management to the next level
-* **[Schema Documentation](/cloud/features/schema-docs)** - Enjoy always up-to-date automatically generated docs for your schema. Atlas Cloud manages a
-single source of truth for the database schema in a format that is easy to understand and navigate.
-
-* **[Automatic Code Review](/cloud/setup-ci)** - If you're not careful, it's easy to accidentally deploy a schema migration
- that breaks your application. Atlas Cloud automatically simulates and reviews your migrations during
-the CI process to ensure that your migrations are safe to deploy. With the Cloud, you can view detailed reports breaking down
-each change and its severity.
-
-* **[Stronger Safety Guarantees](/cloud/features/pre-migration-checks)** - Safeguard deployments with pre-migration checks and interactive migrations.
-
-* **Full Visibility** - Atlas Cloud provides a single pane of glass to view your database schemas, and the status of your migrations across
- all of your environments.
-
-* **[Fast Troubleshooting](/cloud/deployment#visualizing-migration-runs)** - Quickly resolve failed migrations with detailed deployment logs.
-
-* **[Simplify your Pipelines](/cloud/deployment)** - Declutter deployment pipelines by pushing migrations to Atlas Cloud. Atlas Cloud seamlessly
-integrates with modern deployment tools like Kubernetes and Terraform to make it easy to deploy your migrations to production
-as part of your existing CD process.
-
-* **[Send Notifications](/cloud/directories#slack-integration)** - Notify the right people when schema changes are proposed and deployed via Slack and other integrations.
-
-## How do I get started?
-
-1. **Create an account** - in the [signup page](https://auth.atlasgo.cloud/signup) or from the CLI:
-
- ```
- atlas login
- ```
-2. **Connect a migration directory** - To unlock CI, deployments and visibility features you need to connect a migration
- directory to your account. [Follow this guide](/cloud/directories) to learn how.
-3. **Deploy from your connected directory** - Once you've connected a migration directory, you can deploy migrations
- from your Cloud account. [Follow this guide](/cloud/deployment) to learn how.
-
-## Can I see a demo?
-
-Yes, head over to our [live demo account](https://gh.atlasgo.cloud) to see Atlas Cloud in action.
-
-## Can I use Atlas Cloud for free?
-
-We provide a 30 day free trial for new users. After the trial period, a license is required to continue using
-Atlas Cloud.
-
-To learn more see the [pricing page](https://atlasgo.io/pricing).
diff --git a/doc/md/cloud/pricing.mdx b/doc/md/cloud/pricing.mdx
deleted file mode 100644
index 6fde9efd584..00000000000
--- a/doc/md/cloud/pricing.mdx
+++ /dev/null
@@ -1,59 +0,0 @@
----
-title: Pricing
-id: pricing
-slug: /cloud/pricing
----
-
-Atlas Cloud offers two pricing plans:
-
-1. **Pro Plan** - for individuals and small teams that want to unlock the full potential of Atlas. The Pro plan
- provides full access to advanced CLI capabilities, the Cloud UI, and other features. A free, 30-day trial is available
- for new users. After the trial period, a license is required to continue using Atlas Pro.
-
- To learn more about Atlas Pro pricing, visit our [pricing page](https://atlasgo.io/pricing).
-
-2. **Enterprise Plan** - for larger organizations looking to solve schema management at scale. This plan includes a
- dedicated support channel, solution engineering, and other features required for adoption by enterprises.
-
-For a full list of the features in each plan, click [here](https://atlasgo.cloud/pricing).
-
-## What are Seats, Projects and Target Databases?
-
-The three dimensions for billing on the Pro plan are seats, projects, and target databases.
-
-**Seats.** Every developer using Atlas Pro from the CLI or the Cloud UI counts as a seat. The Pro plan comes with 3 free
-seats per company. Additional seats can be purchased as needed. For seat pricing see [here](/pricing).
-
-**Projects.** For teams using Atlas Cloud, resources are grouped into projects. A Project is
-a set of database resources that are versioned and managed together, essentially a *migration directory*.
-Each project gets its own page in the Cloud UI under which you will find CI Runs, Deployments, ERDs, documentation
-and more. See our [live demo](https://gh.atlasgo.cloud/dirs/4294967383) for an example.
-
-The Pro plan comes with 1 free project. Additional projects can be purchased as needed. For project pricing see [here](/pricing).
-
-**Target Databases.** A project may be deployed to multiple target databases, for instance, a development, staging, and
-production database. Atlas Cloud keeps track of each target environment separately, allowing you to deploy to each
-environment independently.
-
-Each target database is essentially a unique URL to which a project is deployed.
-The Pro plan comes with 2 free target databases. Additional target databases can be purchased as needed. For target
-database pricing see [here](/pricing).
-
-## Upgrading your Pricing Plan
-
-### Adding Quota to Pro
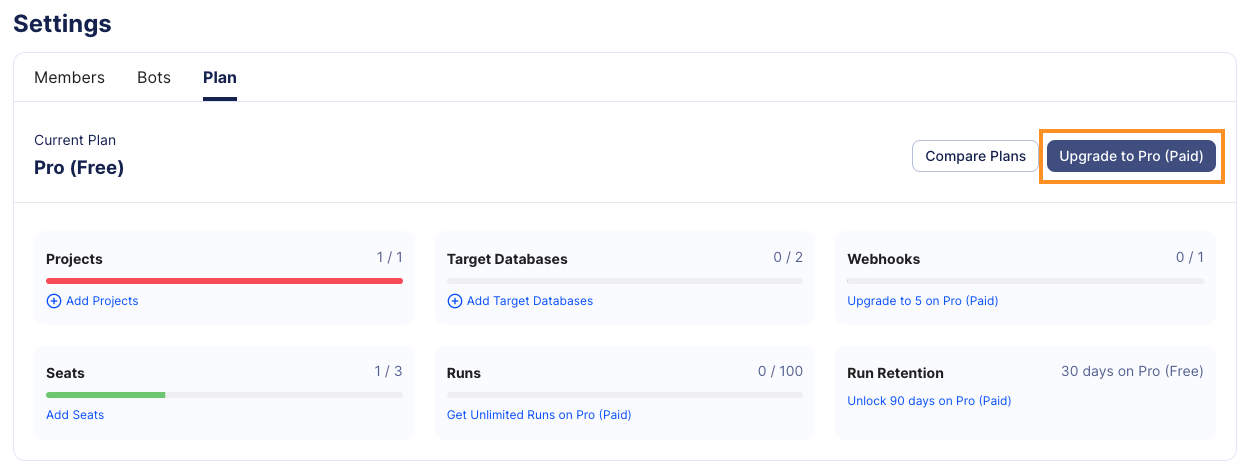
-To purchase extra seats, databases or projects, log in to your [Atlas Cloud](https://auth.atlasgo.cloud/login) account and click on the 'Settings' tab.
-
-
-
-Under the 'Plan' tab, click the 'Upgrade' button. Note, to access the Plan tab you must be an admin of the organization.
-
-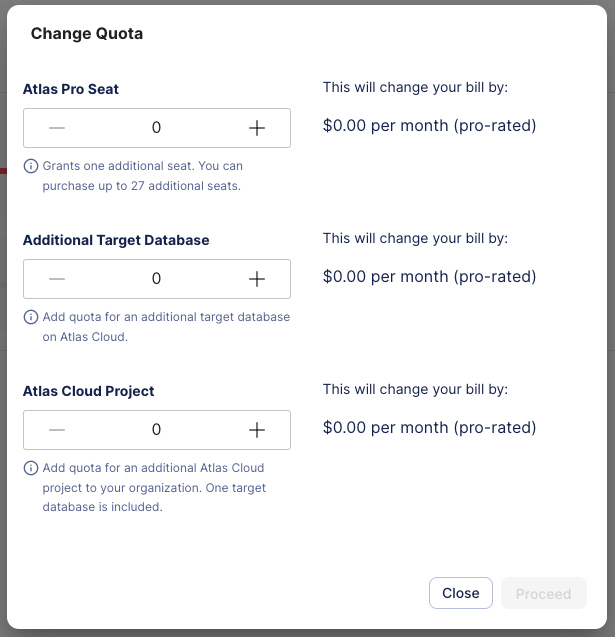
-
-Add the desired resources and proceed to checkout.
-
-That's it!
-
-### Pro to Enterprise
-To upgrade your plan from Pro to Enterprise, send an email to
-
-### Overview
-
-Atlas Cloud maintains always up-to-date, automatically generated documentation for your database schema.
-
-### Why Schema Docs?
-
-When working in a larger organization, having up-to-date documentation of the database schema
-becomes increasingly important. Whether it's for onboarding new team members, or for streamlining
-collaboration between different functions in the organization, having a single source of truth for the database schema
-in a format that is easy to understand and navigate is crucial.
-
-In addition, as a company matures, it is common to see some databases grow in complexity to a point where it becomes
-difficult to keep track of all the tables, columns, and relationships. After many years of development and changes,
-it is not uncommon to see databases with hundreds of tables and thousands of columns whose authors are no longer with
-the company. In such cases, having a tool that can automatically generate and keep up-to-date the documentation of the database
-can bring clarity and understanding that is necessary for the organization to continue to grow and evolve.
-
-### How it works
-
-Schema Docs are regenerated whenever you push a new version of your schema to Atlas Cloud. It is therefore
-recommended to set up your CI pipeline in such a way that it pushes the schema to Atlas Cloud whenever changes are made to the
-main branch of your project.
-
-[Learn how to connect a directory to Atlas Cloud](/cloud/directories)
-
-Schema Docs available from within the project overview page. You can access it by clicking on the "Docs" tab
-at the top of the page.
diff --git a/doc/md/cloud/features/troubleshooting.mdx b/doc/md/cloud/features/troubleshooting.mdx
deleted file mode 100644
index d545429c828..00000000000
--- a/doc/md/cloud/features/troubleshooting.mdx
+++ /dev/null
@@ -1,46 +0,0 @@
----
-title: Troubleshooting Migrations
-slug: /cloud/features/troubleshooting
----
-
-Troubleshooting and triaging failures during database migrations can be especially difficult. Errors often stem from data
-and schema changes, making it hard to identify the exact problem.
-
-When an error or migration failure occurs, it is crucial to understand what went wrong and assess the current state of
-the database.
-
-## Drill Down Analysis
-
-When reporting migration runs to Atlas Cloud, the detailed logs allow you to quickly drill down and troubleshoot
-any schema migration failures.
-
-The report shows what happened in the migration, what caused the failure, and the current state of the
-database post-deployment.
-
-For example, in the image below we can see a migration that failed due to a constraint, `number_length`, which
-was violated. This caused the migration to fail and only one of the three intended migration files was executed on
-the database.
-
-[](https://gh.atlasgo.cloud/dirs/4294967329/deployments/51539607581)
-
-### Database-per-Tenant Migrations
-
-In a database-per-tenant architecture, the same migration is executed on multiple databases. If a migration fails,
-the root cause of the error often involves tenant-specific data and schema changes, making it even more challenging to
-pinpoint issues.
-
-In this scenario, identifying which databases were affected and which remained unaffected is crucial to assess the impact
-and plan the next steps effectively.
-
-In the image below we can see the deployment intended to run on four different databases. The migration failed once it reached
-the third tenant, stopping the deployment entirely before reaching the last tenant's database.
-
-[](https://gh.atlasgo.cloud/dirs/4294967347/deployments/sets/94489280523)
-
-When examining the specific tenant that failed (as shown in the image below), we can see that the failure was caused by
-an attempt to create a table that already existed in the database.
-
-[](https://gh.atlasgo.cloud/dirs/4294967347/deployments/51539607566)
-
-The detailed deployment reports provide clarity on migration failures, allowing for efficient resolution and minimizing
-downtime.
diff --git a/doc/md/cloud/getting-started.mdx b/doc/md/cloud/getting-started.mdx
deleted file mode 100644
index 2f7ac6b8d54..00000000000
--- a/doc/md/cloud/getting-started.mdx
+++ /dev/null
@@ -1,64 +0,0 @@
----
-id: getting-started
-title: Getting Started with Atlas Cloud
-sidebar_label: Getting Started
----
-
-## What is Atlas Cloud?
-
-[Atlas Cloud](https://atlasgo.cloud) is an online platform that supplements the Atlas CLI
-to allow teams to build robust, end-to-end schema management workflows. We built it to help
-teams make the most out of Atlas with as little friction and effort as possible.
-
-## What can I do with Atlas Cloud?
-
-### For Individuals: Unlock the full power of Atlas CLI
-
-By logging in to Atlas Cloud, get access to enhanced schema management, such as views, triggers, functions and stored procedures.
-You will also get access to various database drivers, private visualizations, and more. For a full list of the CLI features
-that require login access, click [here](/features#feature-availability).
-
-### For Teams: Take database schema management to the next level
-* **[Schema Documentation](/cloud/features/schema-docs)** - Enjoy always up-to-date automatically generated docs for your schema. Atlas Cloud manages a
-single source of truth for the database schema in a format that is easy to understand and navigate.
-
-* **[Automatic Code Review](/cloud/setup-ci)** - If you're not careful, it's easy to accidentally deploy a schema migration
- that breaks your application. Atlas Cloud automatically simulates and reviews your migrations during
-the CI process to ensure that your migrations are safe to deploy. With the Cloud, you can view detailed reports breaking down
-each change and its severity.
-
-* **[Stronger Safety Guarantees](/cloud/features/pre-migration-checks)** - Safeguard deployments with pre-migration checks and interactive migrations.
-
-* **Full Visibility** - Atlas Cloud provides a single pane of glass to view your database schemas, and the status of your migrations across
- all of your environments.
-
-* **[Fast Troubleshooting](/cloud/deployment#visualizing-migration-runs)** - Quickly resolve failed migrations with detailed deployment logs.
-
-* **[Simplify your Pipelines](/cloud/deployment)** - Declutter deployment pipelines by pushing migrations to Atlas Cloud. Atlas Cloud seamlessly
-integrates with modern deployment tools like Kubernetes and Terraform to make it easy to deploy your migrations to production
-as part of your existing CD process.
-
-* **[Send Notifications](/cloud/directories#slack-integration)** - Notify the right people when schema changes are proposed and deployed via Slack and other integrations.
-
-## How do I get started?
-
-1. **Create an account** - in the [signup page](https://auth.atlasgo.cloud/signup) or from the CLI:
-
- ```
- atlas login
- ```
-2. **Connect a migration directory** - To unlock CI, deployments and visibility features you need to connect a migration
- directory to your account. [Follow this guide](/cloud/directories) to learn how.
-3. **Deploy from your connected directory** - Once you've connected a migration directory, you can deploy migrations
- from your Cloud account. [Follow this guide](/cloud/deployment) to learn how.
-
-## Can I see a demo?
-
-Yes, head over to our [live demo account](https://gh.atlasgo.cloud) to see Atlas Cloud in action.
-
-## Can I use Atlas Cloud for free?
-
-We provide a 30 day free trial for new users. After the trial period, a license is required to continue using
-Atlas Cloud.
-
-To learn more see the [pricing page](https://atlasgo.io/pricing).
diff --git a/doc/md/cloud/pricing.mdx b/doc/md/cloud/pricing.mdx
deleted file mode 100644
index 6fde9efd584..00000000000
--- a/doc/md/cloud/pricing.mdx
+++ /dev/null
@@ -1,59 +0,0 @@
----
-title: Pricing
-id: pricing
-slug: /cloud/pricing
----
-
-Atlas Cloud offers two pricing plans:
-
-1. **Pro Plan** - for individuals and small teams that want to unlock the full potential of Atlas. The Pro plan
- provides full access to advanced CLI capabilities, the Cloud UI, and other features. A free, 30-day trial is available
- for new users. After the trial period, a license is required to continue using Atlas Pro.
-
- To learn more about Atlas Pro pricing, visit our [pricing page](https://atlasgo.io/pricing).
-
-2. **Enterprise Plan** - for larger organizations looking to solve schema management at scale. This plan includes a
- dedicated support channel, solution engineering, and other features required for adoption by enterprises.
-
-For a full list of the features in each plan, click [here](https://atlasgo.cloud/pricing).
-
-## What are Seats, Projects and Target Databases?
-
-The three dimensions for billing on the Pro plan are seats, projects, and target databases.
-
-**Seats.** Every developer using Atlas Pro from the CLI or the Cloud UI counts as a seat. The Pro plan comes with 3 free
-seats per company. Additional seats can be purchased as needed. For seat pricing see [here](/pricing).
-
-**Projects.** For teams using Atlas Cloud, resources are grouped into projects. A Project is
-a set of database resources that are versioned and managed together, essentially a *migration directory*.
-Each project gets its own page in the Cloud UI under which you will find CI Runs, Deployments, ERDs, documentation
-and more. See our [live demo](https://gh.atlasgo.cloud/dirs/4294967383) for an example.
-
-The Pro plan comes with 1 free project. Additional projects can be purchased as needed. For project pricing see [here](/pricing).
-
-**Target Databases.** A project may be deployed to multiple target databases, for instance, a development, staging, and
-production database. Atlas Cloud keeps track of each target environment separately, allowing you to deploy to each
-environment independently.
-
-Each target database is essentially a unique URL to which a project is deployed.
-The Pro plan comes with 2 free target databases. Additional target databases can be purchased as needed. For target
-database pricing see [here](/pricing).
-
-## Upgrading your Pricing Plan
-
-### Adding Quota to Pro
-To purchase extra seats, databases or projects, log in to your [Atlas Cloud](https://auth.atlasgo.cloud/login) account and click on the 'Settings' tab.
-
-
-
-Under the 'Plan' tab, click the 'Upgrade' button. Note, to access the Plan tab you must be an admin of the organization.
-
-
-
-Add the desired resources and proceed to checkout.
-
-That's it!
-
-### Pro to Enterprise
-To upgrade your plan from Pro to Enterprise, send an email to
-
-
- The PR contains a GitHub Actions workflow similar to this:
-
- Screenshot Example
- -  -
-
-
-
- After reviewing the changes, merge the pull request to enable the GitHub Action.
-
-### Step 4: Test the Action
-
-After merging the pull request, the GitHub Action will run `atlas migrate lint` on every pull request
-and sync the migrations to Atlas Cloud on every push to `master`.
-
-1. To test this setup, create a new branch for making some changes to your database schema:
-
- ```shell
- git checkout -b test-ci
- ```
-
-2. Create a new migration in interactive mode:
-
- ```shell
- atlas migrate new --edit dummy
- ```
-
-3. Type some broken SQL into the migration file and save it:
-
- ```sql
- CREATE users (
- col varchar(255)
- );
- ```
-
- (Notice that we're missing the `TABLE` keyword in the `CREATE TABLE` statement.)
-
-4. Commit the changes and push them to GitHub:
-
- ```shell
- git add migrations
- git commit -m "migrations: add dummy migration"
- git push origin test-ci
- ```
-
- Our changes are pushed to GitHub:
- ```
- remote: Resolving deltas: 100% (3/3), done.
- remote:
- remote: Create a pull request for 'test-ci' on GitHub by visiting:
- remote: https://github.com/rotemtam/gh-init-demo/pull/new/test-ci
- remote:
- To github.com:rotemtam/gh-init-demo.git
- * [new branch] test-ci -> test-ci
- ```
-
-5. Open a pull request for the `test-ci` branch and wait for the GitHub Action to run.
- Code Example
- - ```yaml - name: Atlas - on: - push: - branches: - - master - paths: - - .github/workflows/ci-atlas.yaml - - 'migrations/*' - pull_request: - paths: - - 'migrations/*' - # Permissions to write comments on the pull request. - permissions: - contents: read - pull-requests: write - jobs: - atlas: - services: - # Spin up a mysql:8 container to be used as the dev-database for analysis. - mysql: - image: mysql:8 - env: - MYSQL_DATABASE: dev - MYSQL_ROOT_PASSWORD: pass - ports: - - 3306:3306 - options: >- - --health-cmd "mysqladmin ping -ppass" - --health-interval 10s - --health-start-period 10s - --health-timeout 5s - --health-retries 10 - runs-on: ubuntu-latest - steps: - - uses: actions/checkout@v3 - with: - fetch-depth: 0 - - uses: ariga/setup-atlas@v0 - with: - cloud-token: ${{ secrets.ATLAS_CLOUD_TOKEN_L0QEJQ }} - - uses: ariga/atlas-action/migrate/lint@v1 - with: - dir: 'file://migrations' - dir-name: 'gh-ext-demo' - dev-url: 'mysql://root:pass@localhost:3306/dev' - env: - GITHUB_TOKEN: ${{ github.token }} - - uses: ariga/atlas-action/migrate/push@v1 - if: github.ref == 'refs/heads/master' - with: - dir: 'file://migrations' - dir-name: 'gh-ext-demo' - dev-url: 'mysql://root:pass@localhost:3306/dev' - ``` - -
-
-
-
-
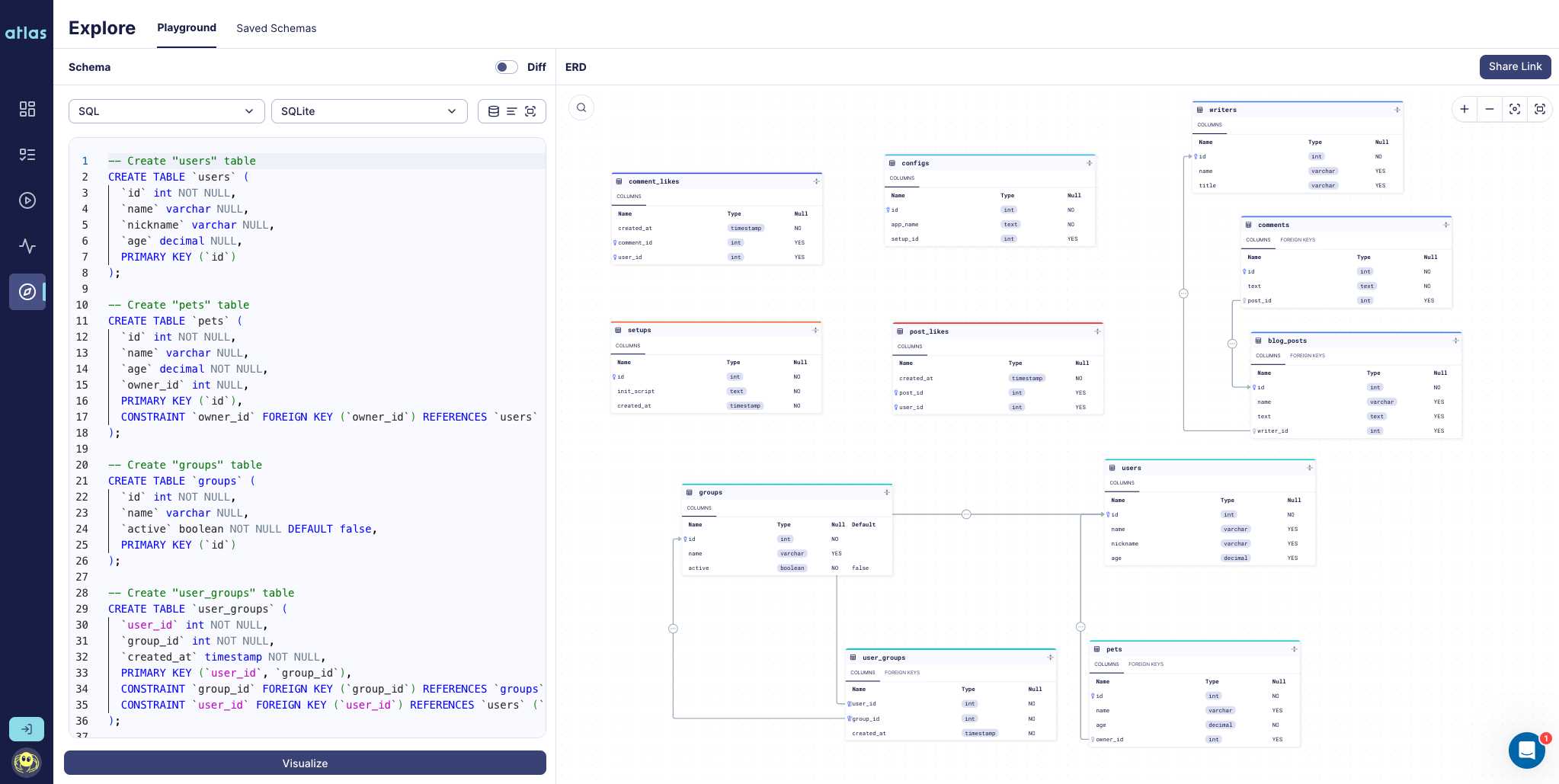
-6. Notice that after a few moments, a comment appears on the pull request with the results of the linting run:
- Screenshot Example
- - 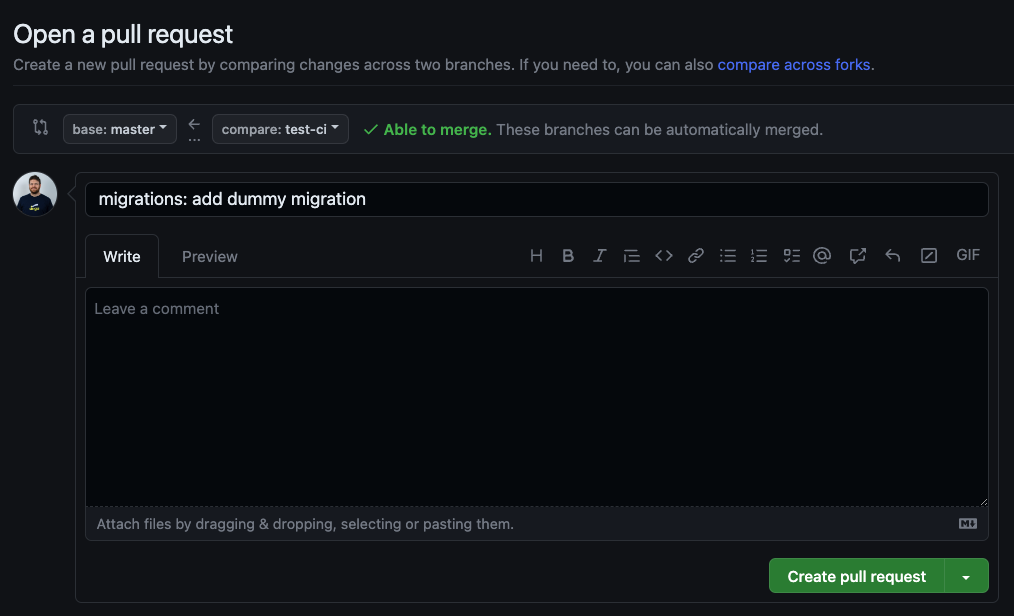 -
-
-
- The linting run failed because of the syntax error we introduced in the migration file.
-
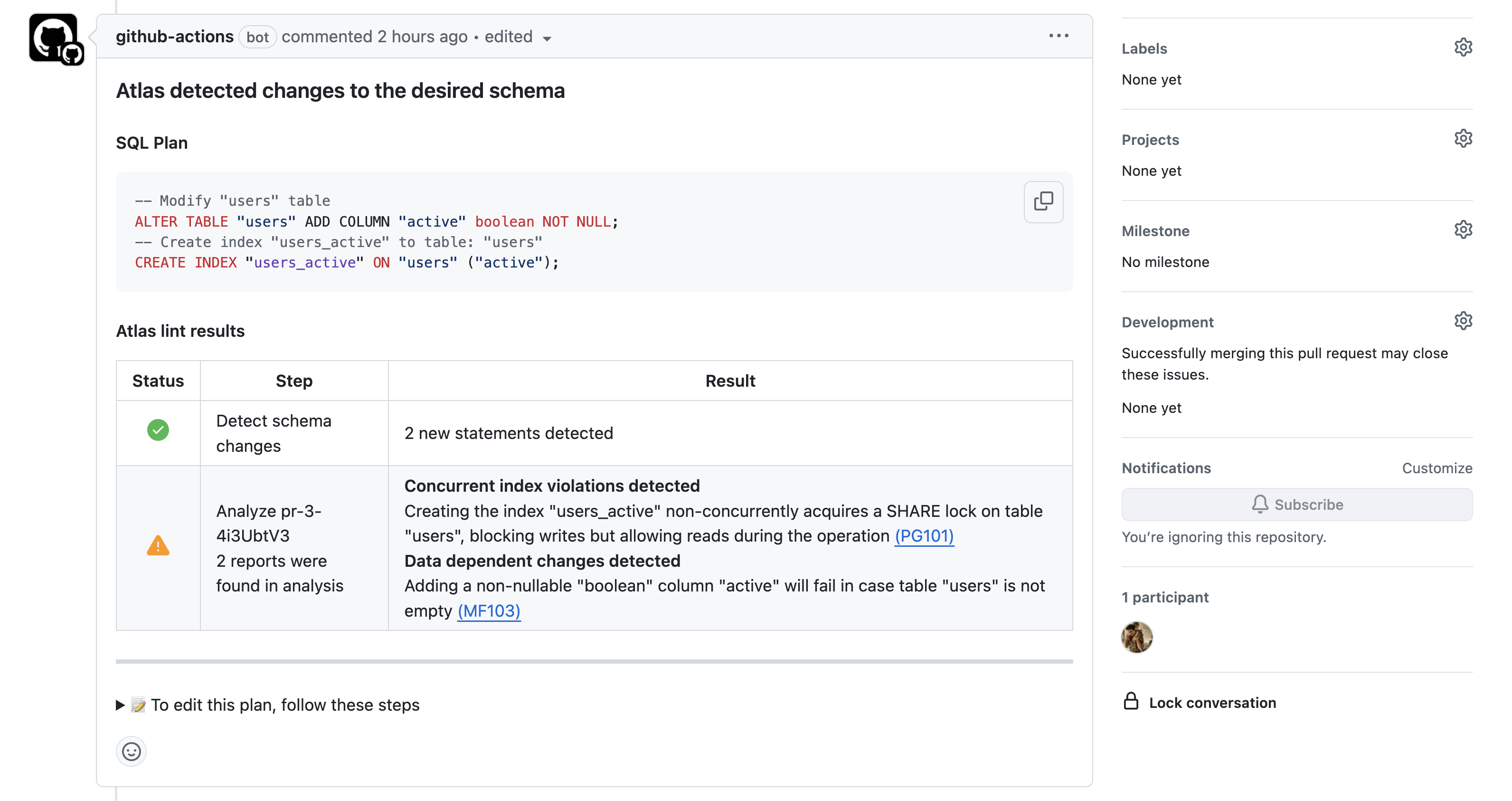
-7. Click on "Full Report" to see the full report on Atlas Cloud:
- Screenshot Example
- - 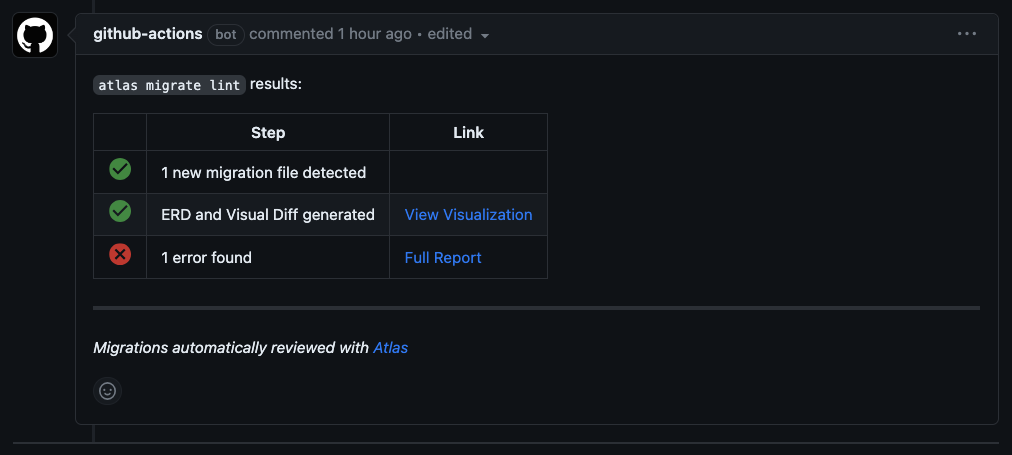 -
-
-
-## Summary
-
-In this guide, we've shown how to configure Atlas Cloud to apply continuous integration
-for our database schema changes. With this setup, whenever a developer proposes a change
-to the database schema, Atlas Cloud will verify the safety of the change using various checks
-and report back the results.
diff --git a/doc/md/community-edition.mdx b/doc/md/community-edition.mdx
deleted file mode 100644
index 030ea83dfa2..00000000000
--- a/doc/md/community-edition.mdx
+++ /dev/null
@@ -1,131 +0,0 @@
----
-title: Community Edition
-id: community-edition
-slug: community-edition
----
-import Tabs from '@theme/Tabs';
-import TabItem from '@theme/TabItem';
-
-## Obtaining Community Binaries
-
-Users that want to use the Community Edition of Atlas which is built directly from the
-[Atlas GitHub repository](https://github.com/ariga/atlas) and licensed under the Apache 2.0 license can do so by following the instructions below.
-
-Screenshot Example
- -  -
-
- );
-}
diff --git a/doc/md/components/login-required.mdx b/doc/md/components/login-required.mdx
deleted file mode 100644
index 0defa6106da..00000000000
--- a/doc/md/components/login-required.mdx
+++ /dev/null
@@ -1,3 +0,0 @@
-
- Atlas Pro
-
\ No newline at end of file
diff --git a/doc/md/components/migrate-push-command.mdx b/doc/md/components/migrate-push-command.mdx
deleted file mode 100644
index cba52829944..00000000000
--- a/doc/md/components/migrate-push-command.mdx
+++ /dev/null
@@ -1,61 +0,0 @@
-import Tabs from '@theme/Tabs';
-import TabItem from '@theme/TabItem';
-
-
-
-
-
-
-
- {name}
-
- {description}
-
-
-
-
- Read guide
-
-
-
-
-  -
-
-
-
-
-
-
-### Edit a Plan
-
-One of the first questions that come to mind when comparing the declarative approach to the versioned approach is:
-_How can I edit a migration plan?_ There are three ways to edit a migration plan:
-
-1. **Edit in-place:**
- - Ensure the `EDITOR` environment variable is set (e.g., `export EDITOR=vim`).
- - Run `atlas schema plan --edit` to open the plan in the default editor. Upon closing, the plan will be pushed
- after approval.
-
-2. **Save, edit, and push:**
- - Run `atlas schema plan --save` to save the plan to a file and edit it manually.
- - Run `atlas schema plan push --file file://
- Schema pushed with atlas schema push
-  -
-
-
-#### Create a Schema Repository in Atlas Registry
-
-For the purpose of the example, let's create a schema repository named `demo` in Atlas Registry with the following
-SQL schema:
-
-
- Plan Generated by atlas schema plan
-  -
-
- 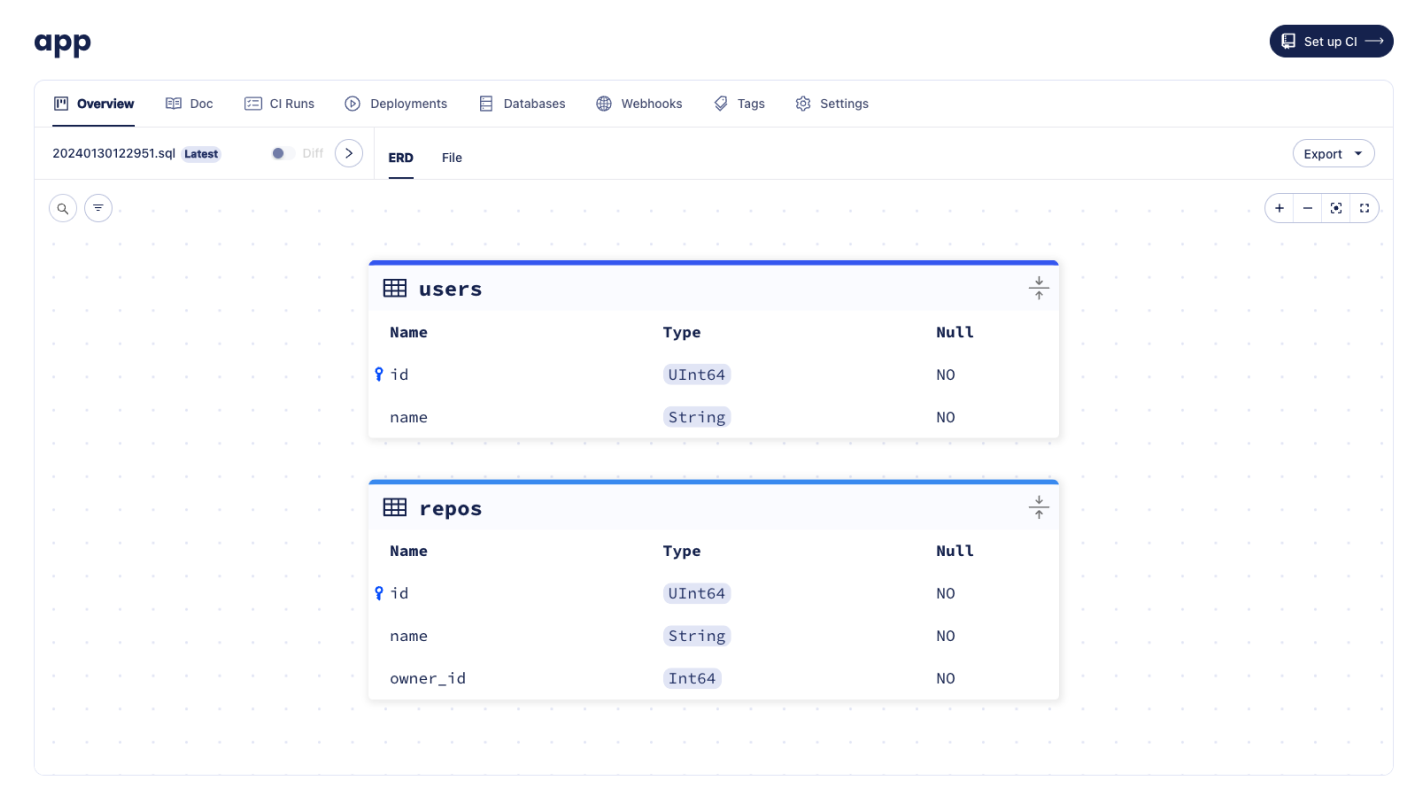 -
-
-
-Let's name our new migration project `app` and run `atlas migrate push`:
-
-```shell
-atlas migrate push app \
- --dev-url "docker://clickhouse/23.11"
-```
-
-Once the migration directory is pushed, Atlas prints a URL to the created directory, similar to the once shown in the
-image above.
-
-### Applying migrations
-
-Once our `app` migration directory has been pushed, we can apply it to a database from any CD platform without
-necessarily having our directory there.
-
-We'll create a simple Atlas configuration file (`atlas.hcl`) to store the settings for our local environment:
-
-```hcl title="atlas.hcl" {1}
-# The "dev" environment represents our local testings.
-env "local" {
- url = "clickhouse://localhost:9000/example"
- migration {
- dir = "atlas://app"
- }
-}
-```
-
-The final step is to apply the migrations to the database. Let's run `atlas migrate apply` with the `--env` flag
-to instruct Atlas to select the environment configuration from the `atlas.hcl` file:
-
-```shell
-atlas migrate apply --env local
-```
-
-Boom! After applying the migration, you should receive a link to the deployment and the database where the migration
-was applied. Here's an example of what it should look like:
-
-
- Migration Directory created with atlas migrate push
- 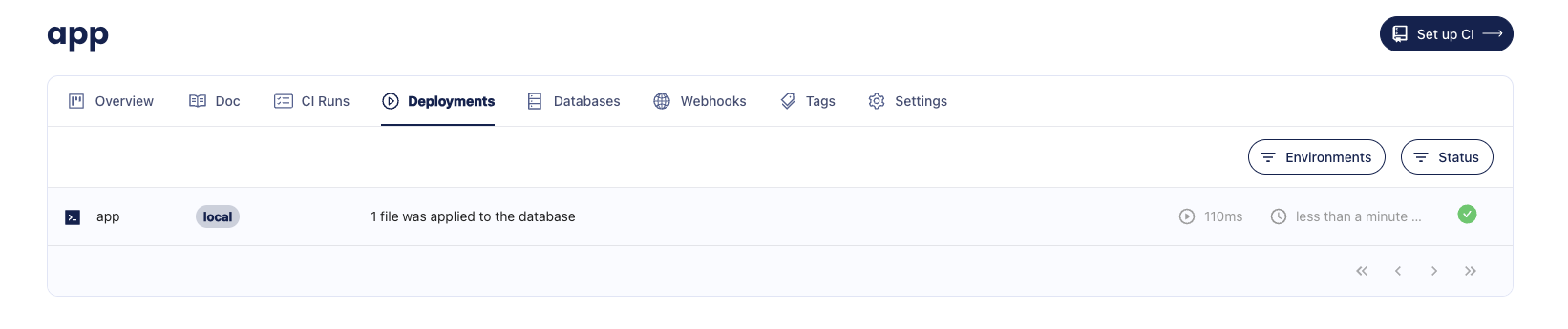 -
-
-
-### Generating another migration
-
-After applying the first migration, it's time to update our schema defined in the schema file and tell Atlas to generate
-another migration. This will bring the migration directory (and the database) in line with the new state defined by the
-desired schema (schema file).
-
-Let's make two changes to our schema:
-
-* Add a new `description` column to our repos table
-* Add a new `commits` table
-
-
- Migration deployment reported created with atlas migrate apply
- 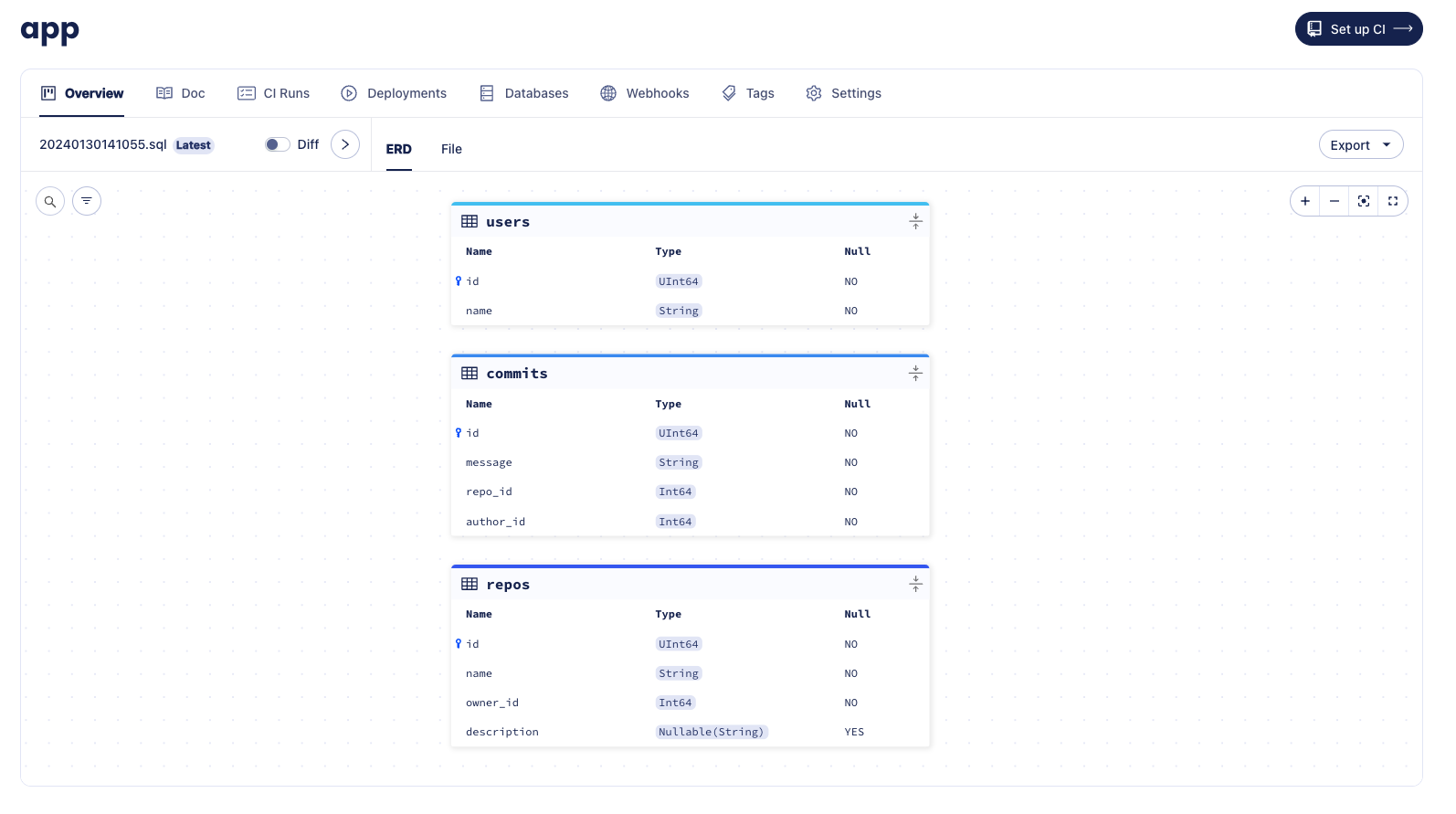 -
-
-
-## Next Steps
-
-In this guide we learned about the declarative and versioned workflows, and how to use Atlas to generate migrations,
-push them to an Atlas workspace and apply them to databases.
-
-Next steps:
-* Read the [full docs](/atlas-schema/hcl) to learn HCL schema syntax or about specific ClickHouse [column types](/atlas-schema/hcl-types#clickhouse)
-* Learn how to [set up CI](/cloud/setup-ci) for your migration directory
-* Deploy schema changes with [Terraform](/integrations/terraform-provider) or [Kubernetes](/integrations/kubernetes/operator)
-* Learn about [modern CI/CD principles](/guides/modern-database-ci-cd) for databases
-
-For more in-depth guides, check out the other pages in [this section](/guides) or visit our [Docs](/getting-started) section.
-
-Have questions? Feedback? Find our team on our [Discord server](https://discord.com/invite/zZ6sWVg6NT).
-
diff --git a/doc/md/guides/database-per-tenant/01-intro.mdx b/doc/md/guides/database-per-tenant/01-intro.mdx
deleted file mode 100644
index 4588b0b28ee..00000000000
--- a/doc/md/guides/database-per-tenant/01-intro.mdx
+++ /dev/null
@@ -1,79 +0,0 @@
----
-title: Database-per-Tenant Architectures with Atlas
-id: intro
-slug: intro
----
-
-## Intro
-
-This guide describes how to utilize Atlas to manage database schemas in "Database per Tenant" architectures,
-a common pattern for deploying multi-tenant applications.
-
-### What is a Database per Tenant Architecture?
-
-In a "Database per Tenant" architecture, each tenant has its own dedicated database (or a schema). Database-per-tenant architectures are commonly
-used in situations where there are considerations around data isolation, security, and scalability. It is worth noting
-it contrary to creating a fully isolated deployment for each tenant, in this architecture compute and other resources
-are shared across tenants.
-
-### Alternative Multi-Tenant Architectures
-
-In addition to a Database per Tenant architecture, there are other common multi-tenant architectures:
-
-1. **Shared Database, Shared Schema**: In this architecture, all tenants share the same database and schema and are
-differentiated by a tenant identifier column in each table.
-2. **Full Isolation**: In this architecture, each tenant has its own isolated deployment, including its own database,
-schema, and compute resources.
-
-### Advantages
-
-Database per Tenant architectures offer several advantages over other multi-tenant architectures:
-
-1. **Data Isolation**: Each tenant has its own dedicated database, providing strong data isolation between tenants.
-By isolating data on the database level, you can ensure that data from one tenant is not accessible to another tenant,
-providing better security and privacy guarantees.
-2. **Data Compliance**: By isolating tenants on the database level, you can ensure that each tenant's data is stored in
-compliance with data regulations and privacy laws relevant to that tenant. For example, you can host the specific
-database in a region that complies with the tenant's data residency requirements or even in your customer's own
-infrastructure.
-3. **Performance**: By isolating tenants on the database level, you can ensure that the performance of one tenant's
-database operations does not impact the performance of other tenants - eliminating the "noisy neighbor" problem.
-Additionally, you can utilize different instance types or configurations for each tenant's database to meet their
-specific performance requirements.
-4. **Simplified Development** (compared to shared database architectures): Codebases for multi-tenant applications are
-notoriously complex. Every action against the database must be made "tenant-aware" to ensure that data is correctly
-isolated. By isolating tenants on the database level, applications become effectively single-tenant, simplifying
-development, reducing the mental overhead of handling multi-tenancy, and reducing the risk of data leakage between tenants.
-5. **Simplified Deployment** (compared to full isolation): In a full isolation architecture, each tenant has its own
-deployment, requiring separate infrastructure, monitoring, and maintenance. By isolating tenants on the database level,
-you can share infrastructure, monitoring, and maintenance across tenants, reducing operational overhead.
-6. **Simplified Maintenance**: Running tenants on different databases simplifies maintenance tasks: Deleting, exporting, and loading tenant data do not require special toolings as most databases offer these functionalities.
-### Challenges
-
-> This architecture decisions is one of my biggest regrets, and we are currently in the process of rebuilding into a single database model.
->
-> *[HN Thread on Database per Tenant Architecture](https://news.ycombinator.com/item?id=23305111)*
-
-Despite their numerous advantages, Database per Tenant architectures present unique challenges, mostly around managing
-database schema migrations:
-
-* **Migration Duration** - As the number of tenants grows, deployment time increases linearly with the number of tenants.
-This is especially problematic when deploying schema migrations that take time, such as data migrations or index rebuilds.
-* **Schema Consistency** - Ensuring that all tenant databases have consistent schema versions can be complex. Any schema
-change needs to be applied across all tenant databases, which can be time-consuming and error-prone.
-* **Detecting Drift** - Migrations can fail due to various reasons, such as network issues, database downtime,
-or data dependent issues (such as constraint violations). Such inconsistencies can cause application downtime for
-users, as new application versions are rolled out and expect database changes to already have been applied.
-Detecting these inconsistencies (schema-drift) across a large fleet of databases can be challenging.
-* **Rollbacks** - Rolling back schema changes across multiple databases can be difficult. In a shared database
-architecture, rolling back a schema change is a single operation. In a database per tenant architecture, rolling back
-a schema change requires rolling back the change on each tenant's database, which needs to be orchestrated somehow.
-
-## Database per Tenant Architectures with Atlas
-
-Atlas was built from the ground up to handle database-per-tenant architectures. In fact, [Atlas Cloud](https://atlasgo.cloud)
-itself is a multi-tenant application that uses a database-per-tenant architecture to manage its own schema.
-
-Atlas supports database-per-tenant architectures both on the CLI and in the Cloud control plane.
-
-In the following sections, we'll describe how to use Atlas to manage database schemas in a database-per-tenant architecture.
diff --git a/doc/md/guides/database-per-tenant/02-db-groups.mdx b/doc/md/guides/database-per-tenant/02-db-groups.mdx
deleted file mode 100644
index 31872f6fd2b..00000000000
--- a/doc/md/guides/database-per-tenant/02-db-groups.mdx
+++ /dev/null
@@ -1,323 +0,0 @@
----
-title: Defining Target Groups
-id: target-groups
-slug: target-groups
----
-In Atlas, a **target group** is a collection of target databases whose schema is managed together. In a database-per-tenant
-architecture, each tenant's database is a target database, and all tenant databases are grouped into a target group.
-However, you can also group databases by other criteria, such as environment (dev, staging, prod), region, or any other
-criteria that makes sense for your application.
-
-For example, you might group all databases in the same region into a target group to ensure that schema changes are
-applied consistently across all databases in that region, or to group free-tier databases separately from
-paid-tier databases.
-
-Target groups can be defined statically or dynamically loaded from an API endpoint or a database query.
-
-Target groups are defined in the project's [`atlas.hcl`](/atlas-schema/projects) file and are later used by the Atlas CLI during the deployment
-process to determine which databases to deploy to.
-
-Let's review some examples of how to define target groups in Atlas.
-
-## `env` blocks and `for_each` meta-arguments
-
-Before we jump into various techniques to define target groups, let's first understand the `for_each` meta-argument for
-environment blocks in Atlas.
-
-Environment blocks (`env` blocks) are used in Atlas project files (`atlas.hcl`) to group configuration settings for
-a specific environment. Normally, an `env` block is used to define the URL of a single target database, like so:
-
-```hcl
-env "dev" {
- url = "postgres://root:pass@localhost:5432/dev"
-}
-```
-
-However, using the `for_each` meta-argument, it is possible to define multiple instances of a specific environment block
-by iterating over a list of values. For example:
-
-```hcl
-locals {
- target_db_urls = [
- "postgres://root:pass@host-1:5432",
- "postgres://root:pass@host-2:5432",
- ]
-}
-
-env "targets" {
- for_each = toset(local.target_db_urls)
- url = each.value
-}
-```
-
-When the `for_each` meta-argument is used, the `env` block is instantiated for each value in the list, and the `each`
-object is used to access the current value. In our case, we will get two instances of the `target` block, one for each
-URL in the `target_db_urls` list.
-
-## Dynamically Computing URLs
-
-A technique commonly used in `atlas.hcl` files is to dynamically compile URLs by combining values from various sources.
-For instance, the database instance URL might be provided as an input variable, with the database name added to it
-dynamically. Here's an example:
-
-```hcl
-variable "db_instance_url" {
- type = string
-}
-
-locals {
- tenants = ["acme_corp", "widget_inc", "wayne_enterprises", "stark_industries"]
-}
-
-env "tenants" {
- for_each = toset(local.tenants)
- url = urlsetpath(var.db_instance_url, each.value)
-}
-```
-
-Let's review the code snippet above:
-* We define a variable `db_instance_url` that will be used as the base URL for the database instances.
- This variable is provided by the user when running the Atlas CLI by providing the `--var` flag.
-* We define a local variable `tenants` that contains a list of tenant names.
-* We define an `env` block named `tenants` that iterates over the `tenants` list. For each tenant, we set the `url`
- attribute to the result of the `urlsetpath` function, which combines the `db_instance_url` with the tenant name.
-
-:::info The `urlsetpath` function
-
-The `urlsetpath` function is a helper function provided by Atlas that allows you to set the "path" part
-of a URL. For example:
-
-```hcl
-urlsetpath("postgres://root:pass@localhost:5432", "mydb")
-# ↳ Evaluates to "postgres://root:pass@localhost:5432/mydb"
-
-urlsetpath("mysql://localhost:3306", "mydb")
-# ↳ Evaluates to "postgres://root:pass@localhost:5432/mydb"
-```
-
-:::
-
-## Loading data from local JSON files
-
-Suppose our list of tenants is stored in a local file named `tenants.json`:
-
-```json title="tenants.json"
-{
- "tenants": [
- "acme_corp",
- "widget_inc",
- "wayne_enterprises",
- "stark_industries"
- ]
-}
-```
-
-We can load this data into our `atlas.hcl` file using the `file` and `jsondecode` functions:
-
-```hcl title="atlas.hcl"
-locals {
- f = file("tenants.json")
- decoded = jsondecode(local.f)
- tenants = local.decoded.tenants
-}
-
-env "tenants" {
- for_each = toset(local.tenants)
- url = urlsetpath("postgres://root:pass@localhost:5432", each.value)
-}
-```
-
-Next, we define an environment block for this target group that consumes the `target_tenants` local variable
-into the `for_each` argument:
-
-```hcl title="atlas.hcl"
-env "tenants" {
- for_each = toset(local.target_tenants)
- url = urlsetpath("postgres://root:pass@localhost:5432", each.value)
-}
-```
-
-Let's review the code snippet above:
-* We define a local variable `f` that reads the contents of the `tenants.json` file.
-* Next, we use the `jsondecode` function to parse the JSON content into a structured object.
-* We extract the `tenants` array from the decoded JSON object and store it in the `tenants` local variable.
-* Finally, we define an `env` block named `tenants` that iterates over the `tenants` list. For each tenant, we set the `url`
- attribute to the result of the `urlsetpath` function, which combines the base URL with the tenant name.
-
-## Loading Data from an API Endpoint
-
-In some cases, you may want to load target groups dynamically from an API endpoint. For example, you might have a
-service `tenant-svc` that provides a list of tenant databases based on some criteria. Let's suppose this service's
-endpoints recieve the target group ID in the path, such as `https://tenant-svc/api/target-group/{id}` and return a
-simple JSON payload:
-
-```json
-{
- "databases": [
- "acme_corp",
- "widget_inc",
- "wayne_enterprises",
- "stark_industries"
- ]
-}
-```
-
-You can use the `runtimevar` data source with the `http` scheme to fetch this data and use it to define
-target groups.
-
-Here's an example of how you might load tenant databases from an API endpoint:
-
-```hcl
-var "group_id" {
- type = string
-}
-
-data "runtimevar" "tenants" {
- url = "http://tenant-svc/api/target-group/${var.group_id}"
-}
-
-locals {
- decoded = jsondecode(data.runtimevar.tenants)
- tenants = local.decoded.databases
-}
-
-env "tenants" {
- for_each = toset(local.tenants)
- url = urlsetpath("postgres://root:pass@localhost:5432", each.value)
-}
-```
-
-Let's unpack this example:
-* We define a variable `group_id` that will be used to fetch the tenant databases from the API endpoint.
-* We use the `runtimevar` data source with the `http` scheme to fetch the tenant databases from the API endpoint.
-* We parse the JSON response using the `jsondecode` function and extract the `databases` array.
-* We define an `env` block named `tenants` that iterates over the `tenants` list. For each tenant, we set the `url`
- attribute to the result of the `urlsetpath` function, which combines the base URL with the tenant name.
-
-By using the `runtimevar` data source with the `http` scheme, you can dynamically load target groups from an API
-endpoint and use them to define target groups in your Atlas project.
-
-## Loading data from a Database Query
-
-In some cases, you may want to load target groups dynamically from a database query. For example, you might have a
-database schema for each tenant in some instance, and would like to retrieve the list from the database's native
-`information_schema` tables.
-
-You can utilize the `sql` data source to fetch this data and use it to define target groups.
-
-```hcl
-var "url" {
- type = string
-}
-
-locals {
- pattern = "tenant_%"
-}
-
-data "sql" "tenants" {
- url = var.url
- query = <
- Migration Directory created with atlas migrate push