- 在用户和计算机硬件之间的中介
- OS是个软件 ——一个虚拟化计算机的程序

OS的作用:
- 物理机层面(CPU Memory Devices):分配资源
- 虚拟机层面(Application):控制程序
No OS->Simple Batch Systems->Batch System->Multiprogramming systems->Time sharing system->Modern System
优点:loosely-coupled 松耦合
- 资源共享
- 提高计算速度
- 更可靠
- 交互性强
多处理器 紧耦合
- 所有处理器共享时钟、总线、内存
两类
- 对称并行 Symmetric multiprocessing
- 每个CPU没有差别
- 非对称并行 Asymmetric multiprocessing
- 每个CPU有特定功能
优点
- 提高吞吐量
- 提高可靠性
- 规模经济
- 和并行系统不同
- 由多个独立系统组成
- 和分布式系统不同
- 共享存储
硬实时:保证所有任务都在deadline之前完成 软实时:尽最大努力
未来 更关注人机交互 安全
User:使用系统的角色,不一定是人 Application programs Operating system Hardware
- 打开电源
- CPU通过系统时钟初始化
- 在BIOS中找到启动程序的CPU的第一条指令
- 执行开机自检(POST),检查所有硬件设备
Bootstrap program 启动程序 很重要,在开机或重启的时候加载 -一般写在ROM或EPROM中,称为固件 firmware
OS等待人去交互
多个任务如何共享一个CPU?
- 中断 interrupt
- IO设备可以和CPU同时执行
- I/O在设备和控制器缓存(controller's buffer)之间转移数据
- CPU在控制器和主存之间转移数据
- I/O设备访问
- Memory Mapped I/O(CPU就像访问内存一样访问I/O)
- Programmed I/O(每个控制寄存器都分配一个I/O端口号,CPU使用特定的I/O指令去读写寄存器)
CPU不断读状态寄存器直到有任务 -效率不高
谁有需要谁就主动通知CPU -硬件触发通过总线 软件触发通过系统调用
大部分OS都是中断的
- 程序执行 Program execution
- I/O操作 I/O operations
- 文件系统的操作 File-system manipulation
- Communications 在进程间传递消息
- 错误检测 Error detection
额外的功能
- 资源分配 Resource allocation
- 账号管理 Accounting
- 保护 Protection
- Process Management
- Main Memory Management
- File Management
- I/O System Management
- Secondary Management
- Networking
- Protection System
- Command-Interpreter System
一个进程是一个正在执行的程序
进程管理负责
- 进程的管理和删除
- 进程的暂停和恢复
- 提供机制为
- 进程同步
- 进程交流
主存管理负责
- 追踪哪部分内存正在被使用,被谁使用
- 决定当内存空间可用时哪个进程被加载
- 在需要时分配和收回内存空间
一个文件是由它的创建者定义的一系列相关信息的集合
文件管理负责
- 文件的创建和删除
- 文件夹的创建和删除
- 支持基本的管理文件和文件夹
- 映射文件到辅助存储器
- 备份文件到稳定的存储介质
I/O系统包含
- 缓存系统
- 通用设备驱动接口
- 特定硬件设备的驱动
大部分计算机系统使用磁盘
磁盘管理负责
- 空闲空间管理
- 存储分配
- 磁盘调度
Process——a program in execution 一个执行过程中的程序
- Program(executable):磁盘上的passive实体
- Process:active entity被激活的实体,包含
- 程序计数器
- 栈
- 堆
- 文本
- 数据
一个程序包含
- Code
- Data
- DLLs 动态链接库
- mapped files
Running a program 运行一个程序
- OS创建一个进程,并为它分配内存
Process vs Program
- 两个进程可能和同一个程序相关联
- 两条单独执行的顺序
- 文本部分相同,数据、堆、栈都不同
一个进程执行时,它会改变状态
基本状态
- running:指令正在执行
- waiting:进程等待某个事件发生
- ready:进程等待分配给CPU
扩展状态
- new:进程被创建
- terminated:进程结束执行
dot语言画进程状态图如下
digraph states{
new->ready[label=admitted]
ready->running[label="scheduler dispatch"]
running->terminated[label=exit]
{rank=same;new terminated}
{rank=same;ready running}
running->ready[label="interrupt"]
running->waiting[label="I/O or event wait"]
waiting->ready[label="I/O or event completion"]
}
为什么waiting之后不能直接running?
如果有两条队列都能进入running状态,调度很麻烦。同时只有一条队列进入running队列也对所有进程公平。
四种典型事件
- 系统初始化
- 用户请求创建
- 系统调用相应接口
- Unix:fork()
- Windows:CreateProcess()
- 开启一个批处理任务
父进程可以创建子进程,子进程可以继续创建子进程,形成进程树
- 父子进程共享全部资源
- 子进程分享父进程资源的子集
- 父子进程不共享资源
- 父子进程同时执行
- 父进程等子进程结束再执行
- 子进程复制了父进程的地址空间
- 子进程有专门的程序加载地址空间
- 正常退出(自愿)
- Error exit(自愿)
- Fatal error(强制) 致命错误
- 被其他进程杀死
Exit 正常退出 Abort放弃
和每个进程相关联的信息,包含:
- Process state 进程状态
- Program counter 程序计数器
- CPU register 寄存器:为了能让CPU离开进程后回来还能执行
- CPU scheduling information CPU调度信息
- Memory-management information 内存管理信息
Account information(本课程不学习)I/O status information(本课程不学习)
进程被组织成不同的队列
- Ready一条 Ready queue
- New一条 Job queue
- Waiting一条或多条 不同的设备可以放到不同的队列 Device queues
进程被需要触发的事件驱动,从一条队列转移到另一条队列
- Long-term scheduling(or job scheduling) 长程调度 从job queue中选一个到ready queue中 内存可用时,从磁盘中移出一个到内存 不太频繁,速度慢
- Short-term scheduling(or CPU scheduling) 短程调度 从ready queue中选一个到running 更加频繁,速度必须快
- Interrupt handling 中断处理 从waiting到ready
- Medium-term scheduling CPU和内存资源管理的混合 swapping:一个进程需要长期等待时,把它先移动到磁盘,把其他进程移入内存
当CPU从一个进程切换到另一个进程时,系统要保存旧进程的状态,加载新进程的状态。这个过程叫 上下文切换 context switch
在进程之间切换越快越好,而创建进程和进程通信工作量很大,所以产生了线程 线程有
- 独立的 PC, Register, Stack pointer
- 共享的 Code, Data, File
进程是资源的拥有者
线程用来调度任务

digraph hyper_threading{
table [ shape = "plaintext", label = <
<table border="1" cellspacing="0">
<tr>
<td port="r1">Register</td>
<td port="r2">Register</td>
</tr>
<tr>
<td colspan="2">ALU</td>
</tr>
<tr>
<td colspan="2" port="cache">Cache</td>
</tr>
</table>
>]
mm [label="Main memory", shape="plaintext"]
lp1 [label="Logical processor", shape="plaintext"]
lp2 [label="Logical processor", shape="plaintext"]
table:cache->mm->table:cache
lp1->table:r1
lp2->table:r2
}
digraph multicore{
table [ shape = "plaintext", label = <
<table border="1" cellspacing="0">
<tr>
<td port="r1">Register</td>
<td port="r2">Register</td>
</tr>
<tr>
<td>ALU</td>
<td>ALU</td>
</tr>
<tr>
<td port="c1">Cache</td>
<td port="c2">Cache</td>
</tr>
</table>
>]
mm1 [label="Main memory", shape="plaintext"]
mm2 [label="Main memory", shape="plaintext"]
pp1 [label="Physical processor", shape="plaintext"]
pp2 [label="Physical processor", shape="plaintext"]
table:c1->mm1->table:c1
table:c2->mm2->table:c2
pp1->table:r1
pp2->table:r2
}
- 用户线程 用户层级 所有线程在user space中完成
- 内核线程 OS直接执行
- IPC(Interprocess communication) 协作的进程需要IPC
进程通信可以通过
- shared memory 共享内存
- pipe 管道
- message passing 消息传递
- 建立一个communicate link(physical/logical)
- 通过send/receive交换
- 进程必须互相知道对方名字
- send(P,message)
- receive(Q,message)
- 自动建立了link 两个进程间只有一条,一条链路只有两个进程
- 发送时指明了名字,接收只有id
- send(P,message)
- receive(id,message) 例如:共享打印机
直接通信的缺点:必须知道对方的名字,局限了模块化
- 消息从中介取,往中介发 mailbox or ports
- send(A,message)
- receive(A,message)
每个mailbox都有独立id
一条链路连接多个进程
- Blocking send :直到上一个消息被接收时才会发下一个消息
- Non-blocking send :随时发
- Blocking receive :一个消息来的时候receiver才工作
- Non-blocking receive :随时取
Non-blocking和blocking receive是最常见的
link的消息队列容量
- Zero capacity 队列长度=0
- Bounded capacity 队列长度=n
- Unbounded capacity 队列长度=$\infty$
对于共享数据的并行访问可能导致数据的不一致
多个进程同时访问操作文件,最终结果取决于最后执行的指令
为了避免竞争条件,并行的进程必须是 mutual exclusion 互斥的
互斥
- 如果一个进程正在使用一个共享文件或变量,其他进程不能做同样的事
每个进程拥有的操作共享数据的代码称为 critical section 临界区。要保证当一个进程执行时它的临界区代码时,其他进程不能执行临界区代码
解决方案: 在执行之前加点条件,判断能否执行,执行完毕后解锁
do{
entry section //执行前判断
crical section
exit section //执行完毕后解锁
reminder section
}解决临界区问题需要满足
- Mutual Exclusion 互斥
- Progress 前进原则 如果没有临界区代码在执行,有一个进程想进入临界区是,应当允许
- Bounded wait 有限等待 想进入临界区的在有限时间内总能进入
有两列相向而行的火车需要在某个地点占用同一段铁轨,如何保证两车进入不会相撞,且两车都能正常运行
int turn;
turn=i //Pi可以进入Pi
do {
while(turn!=i);
/* critical section */
turn=j;
/* remainder section */
} while(1);满足互斥,但不满足前进原则(只有一辆车运行的情况下)
boolean flag[2];
flag[i]=true;Pi
do {
flag[i]=true;
while(flag[j]); //空循环等待j
/* critical sectioon */
flag[i]=false;
/* remainder */
} while(1);如果两个同时刻到,那么都进不去,不满足Bounded waiting
do {
flag[i]=true;
turn=j; //先把机会让给另外一个
while(flag[j] && turn==j); //如果另外一个也到了,就空循环等待
/* critical section */
flag[i]=false;
/* remainder section */
} while(1);三个要求都满足
- Synchronization hardware
- Semaphores
- Critical Regions
- Monitors
很多系统提供了硬件对于临界区代码的支持
- 单处理器可以禁止中断,使当前运行代码不会被抢占
- 在多处理器上上述方案效率太低
现代计算机提供了特别的 原子的(atomic) 硬件指令
- 检查和修改字的内容
- 或交换两个字的内容
方法:
boolean TestAndSet(boolean *target) {
boolean rv=*target;
*target=true;
return rv;
}初始化:
boolean lock=false;执行时:
do{
while(TestAndSet(&lock));
//critical section
lock=false;
//remainder section
}操作两个数据,与指令TestAndSet一样原子执行
void Swap(boolean *a,boolean *b) {
boolean temp=*a;
*a=*b;
*b=temp;
}初始化:
boolean lock=false;执行时:
do {
key=true;
while(key==true)
Swap(&lock, &key);
//critical section
lock=false;
//remainder
} Dijkstra提出 信号量 一个整形变量,只能通过两个标准原子操作:
- wait()
- signal()
wait(s):
while(s<=0)
; //no-operation
s--;signal(s):
s++在wait()和signal()操作中,对信号量的修改必须是原子的,即当一个进程修改信号量值时,不能有其他进程同时修改同一信号的值
初始化:
int mutex=1;Critical section of n processes
do {
wait(mutex);
//critical section
signal(mutex);
//remainder section
} while(1);- 计数信号量的值域不受限制,用来表示可用资源的数量
- 二进制信号量的值只能为0或1
主要缺点是 忙等待(busy waiting)
当一个进程位于其临界区内时,其他想进入临界区的进程必须连续循环等待,浪费了CPU时钟。也称为自旋锁。
为了克服忙等待,可以使用阻塞并放入等待队列的操作。通过wakeup()来重新执行
定义一个新结构
typedef struct {
int value;
struct process *List;
} semaphore;- Block operation: block()
- Wakeup operation: wakeup()
新的信号量操作定义
wait(semaphore *S){
S.value--;
if(S.value<0) {
block(); //add this process to S.List
}
}
signal(semaphore *S) {
S.value++;
if(S.value<=0) {
wakeup(P); //remove a process P from S.List
}
}Bounded-Buffer Problem 可用计数信号量来解决
- Deadlock: 两个或多个进程无限地等待一个事件
- Starvation: 无限期阻塞
一种高层同步结构
另一种高层同步结构
比信号量更高的抽象。或者说并没有这种实体存在于系统或编程语言中,更多的是一种机制,一种解决方法,但是编程语言和操作系统都提供了实现管程的重要部件条件变量
管程就是管理一组共享变量的程序。主要有一下几部分组成
mutex // 一个互斥锁,任何线程访问都必须先获得mutex
condition //一个或者多个,每个条件变量都包含一个等待队列
balabala //共享变量及其访问方法- 采用面向对象方法,简化线程同步
- 同一时刻仅有一个线程在管程中工作
- 可临时放弃管程的访问权,叫醒一个在等待队列中的线程,这是其他方法都没有的(原子锁和信号量一旦进入临界区就必须执行完临界区代码才能退出),而实现这一点采用的就是条件变量
- Hansan管程
- Hoare管程
管程类型提供了一组由程序员定义的、在管程内互斥的操作
monitor monitor-name {
shared variable declarations
procedure body P1() { }
procedure body Pn() { }
{initialization code}
}同一时刻管程内只有一个进程在活动,因此不需显式地编写同步代码
为了让进程在管程内等待,必须声明一些condition类型的变量,即条件变量
条件变量两种操作
- x.wait() 进程挂起
- x.signal() 被挂起的进程重新活动

这里的wait和P操作是不一样的,最大的不同就是他一定会将自己阻塞同时释放锁。而signal如果没有等待线程相当于一个空操作。而且numWaiting 不可能为负数
一些经典的同步问题
- 写者、读者互斥访问文件资源。
- 多个读者可以同时访问文件资源。
- 只允许一个写者访问文件资源。
- 没有读者会因为有一个写者在等待而去等待其他读者的完成
- 写者执行写操作前,应该让所有读者和写者退出
- 除非有一个写者在访问临界区,其他情况下,读者不应该等待
如果一个写者等待访问对象,那么不会有新读者开始读操作
初始化变量
BINARY_SEMAPHORE wrt=1;
BINARY_SEMAPHORE mutex=1;
int readcount=0;Reader:
do {
wait(mutex); //Allow 1 reader in entry
readcount=readcount+1;
if(readcount==1)
wait(wrt); //1st reader locks writer
signal(mutex);
//reading operation
wait(mutex);
readcount=readcount-1;
if(readcount==0)
signal(wrt); //last reader frees writer
signal(mutex);
}Writer:
do {
wait(wrt);
//writing operation
signal(wrt);
}初始化变量
BINARY_SEMAPHORE read=1; //使有写者进行操作时读者等待
BINARY_SEMAPHORE file=1; //使文件操作互斥
BINARY_SEMAPHORE mutex1=1; //使改变readcount的方法互斥
BINARY_SEMAPHORE mutex2=1; //使改变writecount的方法互斥
int readcount=0;
int writecount=0;Reader:
do {
wait(read); //等待直至读者队列没有阻塞,即全部写者都退出,同时自身进入后再次上锁,使后来的读者等待,因为接下来要进行一系列互斥的操作
wait(mutex1);
readcount++;
if(readcount==1) //第一个读者进入
wait(file); //后来的写者无法操作文件,但对后来的读者的文件操作不造成影响
signal(mutex1);
signal(read); //释放
//read operation
wait(mutex1);
readcount--;
if(readcount==0)
signal(file);
signal(mutex1);
}Writer:
do {
wait(mutex2);
writecount++;
if(writecount==1) //第一个写者进入
wait(read); //阻塞读者队列
signal(mutex2);
wait(file);
//write operation
signal(file);
wait(mutex2);
writecount--;
if(writecount==0) //最后一个写者退出
signal(read); //释放读者队列
signal(mutex2);
}5个哲学家围着桌子吃饭,筷子只有5枝,分别在每个哲学家的左手边和右手边。哲学家必须得到两只筷子才能吃饭,要使每个哲学家都能吃到饭,该如何调度
只有左右两只筷子都可用时,才允许一个哲学家拿起它们
void philosopher(int i) { //主方法
while(true) {
thinking();
dp.pickup(i);
eating();
dp.putdown(i);
}
}
monitor dp {
enum{thinking,hungry,eating} state[5];
condition self[5];
void pickup(int i) {
state[i]=hungry; //设置本人为饥饿状态
test[i]; //测试左右两个人是否在吃
if(state[i]!=eating) //如果需要等待
self[i].wait(); //进入等待,在pickup方法处阻塞
}
void putdown(int i) {
state[i]=thinking;
test((i+4)%5);
test((i+1)%5); //本人放下筷子后,状态发生了变化,测试左右两个是否等待吃,如有,则给他们开始吃的机会(但也不一定能马上开始吃)
}
void test(int i) {
if((state[(i+4)%5]!=eating) && (state[i]==hungry) && (state[(i+1)%5]!=eating)) { //如果左右两个人并没有在吃,而且自己处于饥饿状态
state[i]=eating; //设置状态为eating
self[i].signal(); //释放pickup方法,在philosopher方法中下一步将执行eating操作
}
}
initializationCode() {
for(int i=0;i<5;i++)
state[i]=thinking;
}
}一个生产者,一个消费者,库存有限,如何能持续生产
对于生产者,如果缓存是满的就去睡觉。消费者从缓存中取走数据后就叫醒生产者,让它再次将缓存填满。若消费者发现缓存是空的,就去睡觉了。下一轮中生产者将数据写入后就叫醒消费者。
不完善的解决方案会造成“死锁”,即两个进程都在“睡觉”等着对方来“唤醒”。
初始化变量:
semaphore mutex=1; //临界区互斥信号量
semaphore empty=n; //空闲库存空间
semaphore full=0; //库存初始化为空生产者进程:
producer ()
{
while(1)
{
produce an item in nextp; //生产数据
P(empty); //获取空闲库存单元
P(mutex); //进入临界区.
add nextp to buffer; //将数据放入缓冲区
V(mutex); //离开临界区,释放互斥信号量
V(full); //库存数加1
}
}消费者进程:
consumer ()
{
while(1)
{
P(full); //获取库存数单元
P(mutex); // 进入临界区
remove an item from buffer; //从库存中取出数据
V (mutex); //离开临界区,释放互斥信号量
V (empty) ; //空闲库存数加1
consume the item; //消费数据
}
}何时调度
- 非抢占式 nonpreemptive
- 从running到waiting
- Terminates
- 抢占式
- 从waiting到ready
- 从running到ready
- 切换上下文
- 转换为use mode
- 跳转到用户程序中的适当位置来重启程序
- Max CPU utilization —— 让CPU越忙越好
- Max Throughput 单位时间内能完成的进程个数越多越好
- Min Turnround time 周转时间越短越好
- Min Waiting time 等待时间
- Min Response time 响应时间指从请求提交到第一个相应产生,并非输出产生
不同种类OS有不同的目标
批处理系统的调度算法
主要有4种
- First-Come, First-Served (FCFS)
- Shortest Job First (SJF)
- Shortest Remaining Time First (SRTF)
- Three-Level Scheduling
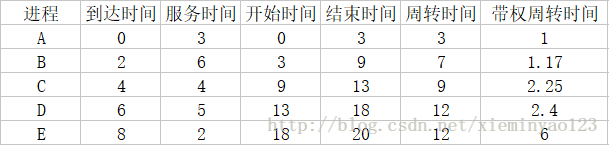
主要的时间概念
- 周转周期=结束时间-到达时间
- 带权周转时间=周转时间/服务时间
例子
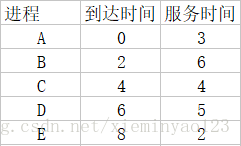
FCFS最简单,是非抢占式的
进程按照请求CPU的顺序排序
上述例子解决图

表格
如果运行时间事先已知,可以每次挑选最短的任务以避免convoy effect(护航效应,即小进程等待大进程释放)
也是非抢占式的。
例子图


可以证明SJF是最优的 避免了护航效应(convoy effect)
难以得知下次CPU请求的长度,只能预测。一般通过数学期望
SRTF是抢占式的,有时也被称为抢占式的SJF
- 当前剩余运行时间最短的进程被挑出来
- 如果新到达进程的CPU Burst time比当前执行进程的要短,则抢占
例子图

- A先运行至2,B到达等待。
- A运行到3结束,B开始运行。
- B开始运行,运行到4时,C进程到达,且C只需要4,此时B还需要5。所以先运行C,B继续等待。
- C运行时间点到达6时,D到达,D需要5,进入等待,排在B后。
- C运行结束,此时时间点是8,E到达,运行时间只要2,小于等待的BD,直接运行。
- C运行结束,B开始运行。
- B运行结束,D开始运行。
表格形式:

高级调度,就是按某种算法在外存中处于后备队列的作业中挑选一个(或多个)作业,给它分配内存等必要资源,并建立相应的进程(建立PCB),以使它(们)获得竞争处理机的权利。
中级调度,就是决定将哪个挂起状态的进程从外存重新调回内存。
低级调度的主要任务是按照某种规则从就绪队列中选取一个进程,将CPU分配给它。
重点讨论 Scheduling algorithms for Interactive Systems
算法
- Priority Scheduling
- Round-Robin Scheduling
策略
- Multilevel Queues Scheduling
- Multilevel Feedback Queues Scheduling
可以是抢占式的,也可以是非抢占式的
优先级最高的进程被选出来运行
- 最大的问题:无限等待 starvation 优先级低的可能永远无法运行 解决方法:老化 每执行一个周期就把当前进程优先级降一下
先给定时间片(time quantum)的大小
- Case 1: CPU burst <= one time quantum 执行完就退出执行其他任务
- Case 2: CPU burst > one time quantum 执行不完将该任务放到队尾
RR比SJF的平均周转时间长,但有更好的response time
假设ready queue的时间片为q
q太大——FCFS
q太小——频繁切换,增加了开销
进程分组,不同组队列不同优先级,不同队列中算法不同
进程可以根据反馈情况在不同组队列间切换位置
几种评估模型
- Deterministic modeling
- Queuing models
- Simulations
- Implementation
在确定的场景中去评价
比如 确定输入值,评价平均等待时间
优点:
快、简单
可以给出具体数值
通常用来举例
缺点: 要有明确输入
知道到达速率和服务速率就可以比较其他指标
例
n: 平均队列长度 w: 平均等待时间 λ: 平均到达新进程速率
n=w*λ
优点:对于比较调度算法很有用
缺点:难以理解
真实去跑
Useful but expensive
R1,R2,...,Rm表示不同的资源类型
每个Ri有Wi个实例
每个进程使用资源时,先request,再use,再release
- 同一时间一种资源只能由一个进程使用(互斥使用)
- 同一时间一个进程可能需要访问多种资源
- 有一些资源不能被抢占
这就导致了一些进程的阻塞
- Mutual exclusion 互斥访问
- Hold and wait 占有和等待
- No preemption 非抢占
- Circular wait 循环等待
- 一组节点 V
- P 进程集合
- R 资源类型集合
- 一组边 E
- 请求边 request edge P到R
- 分配边 assignment edge R到P

无环一定没有死锁,有环不一定有死锁
如果有环,且环上有资源只有一个实例,则必有死锁;有多个实例,可能有死锁
- 忽略
- 预防
- 避免
- 探测并恢复
The Ostrich algorithm 鸵鸟算法
- 打破互斥 不是所有的资源都行
- 打破Hold and wait
- 在运行前把所有所需资源拿来(不容易)
- 请求资源时把占有的资源都释放(很好)
- 打破非抢占 不可能
- 打破循环等待 和hold and wait类似 有序的 资源访问
判断请求在未来是否出现死锁 动态检验
指一个进程序列{P1,…,Pn}是安全的,即对于每一个进程Pi(1≤i≤n),它以后尚需要的资源量不超过系统当前剩余资源量与所有进程Pj (j < i )当前占有资源量之和
系统给进程按一定顺序分配资源,不会有死锁
System is in safe state if there exists a safe sequence of all processes
- 如果一个系统在安全状态,不会有死锁
- 如果一个系统在不安全状态,可能有死锁
- Resource allocation graph 每个资源一个实例
- Banker's algorithm 每个资源多个实例
一种新的边 claim edge -----> 代表 未来可能需要的资源
claim edge 变成 assignment edge后,图中不能有环
- 每个新进程必须声明它所需每种资源的最大实例数
- 进程请求时,系统必须确认是否分配资源会让系统不安全
- 当一个进程得到所有所需资源后,它必须在有限时间内归还
例子:
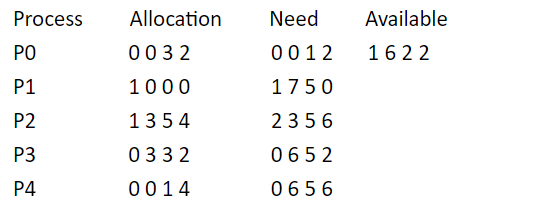
- 该状态是否安全?
- 若进程P2提出请求Request(1,2,2,2)后,系统能否将资源分配给它?
答:
- 利用安全性算法对上面的状态进行分析(见下表),找到了一个安全序列{P0,P3,P4,P1,P2},故系统是安全的。
- P2发出请求向量Request(1,2,2,2),系统按银行家算法进行检查:
- Request2(1,2,2,2)<=Need2(2,3,5,6)
- Request2(1,2,2,2)<=Available(1,6,2,2)
- 系统先假定可为P2分配资源,并修改Available,Allocation2和Need2向量: Available=(0,4,0,0) Allocation2=(2,5,7,6) Need2=(1,1,3,4) 此时再进行安全性检查,发现 Available=(0,4,0,0) 不能满足任何一个进程,所以判定系统进入不安全状态,即不能分配给P2相应的Request(1,2,2,2)。
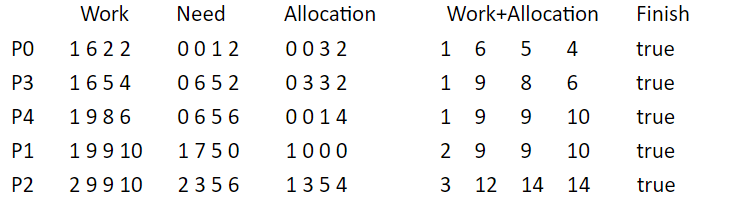
- Detection algorithm
- Recovery scheme
只有进程,每条边代表一个进程Pi等待另一个进程Pj释放一个Pi所需的资源
等待图有环就代表有死锁
digraph wait {
node [shape=circle]
Pi->Pj [label=x]
Pj->Pk [label=y]
Pk->Pi [label=z]
{rank=same; Pj,Pk}
}算法使用了一些随时间变化的数据结构,和银行家算法类型
- Availabel: 长度为m的向量,表示各种进程的可用实例
- Allocation:
$n \times m$ 矩阵,表示当前各进程的资源分配情况 - Request:
$n \times m$ 矩阵,表示当各进程的资源请求情况
和银行家算法类似
- 死锁发生频率是多少
- 死锁发生时,有多少进程会受影响
- 终止所有死锁进程
- 一次只终止一个进程,知道取消死锁循环为止
从进程中抢占资源给其他进程使用
三个问题
- 选择被抢的对象:占用资源最少的进程
- 回滚:回到安全状态
- 饥饿:一个进程可能一直被抢
将三种基本方法组合起来使用
- Prevention
- Avoidance
- Detection
Von Numann theory
有工作内存的计算机
数字计算机要以二进制计数
根据在程序中预先写好的指令顺序执行
- Input
- Store
- Calculate
- Control
- Output
- 从内存取指令,存到寄存器
- 解析指令,从内存取数据,放到寄存器
- 执行特定指令,把结果存到内存
- Main memory 主存
- Secondary storage 辅存
- Static linking 在磁盘中链接好
- Load-time dynamic linking 装入内存时链接
- Run-time dynamic linking 需要运行时链接
- Absolute loading 每次相同位置
- Relocation loading 每次不同位置
- Dynamic run-time loading 放进去以后还能挪
- Logical address 逻辑地址 CPU生成 也叫Virtual address
- Physical address 物理地址 实际在内存中的地址
Memory management unit(MMU)
用来将逻辑地址映射为物理地址的硬件
OS中用来管理内存的步伐叫 memory manager
职责:
- Keep track of the using of memory
- 分配和取消分配内存给进程
- 当内存不够用时,管理内存和硬盘的swapping
graph mmc {
node [shape="box"]
a [label="Memory management\ntechniques"];
b [label="Contiguous \n allocation"]
c [label="Non-continguous \n allocation"]
d [label="Single \n partition \n allocation"]
e [label="Multiple \n partition \n allocation"]
f [label="Paging"]
g [label="Segmentation"]
h [label="Fixed partition"]
i [label="Variable partition"]
a--{b c}
b--{d e}
e--{h i}
c--{f g}
}每个进程都完整地、连续地放到内存空间
- 内存分为两个区,一个给OS,一个给用户进程
- Single user, single task 单用户,单任务的情况下使用
- OS由Base regisrer, Limit register保护
把内存分成多个分区,每个分区大小可定可变
每个分区包含恰好一个进程
分区大小固定
分区内部剩余内存空置会造成浪费
Hole:空闲区域
当进程到达时,从一个足够大的hole中分内存给它
三种分配策略
- First-fit:分配按地址顺序的第一个可用的hole
- Best-fit:放到最小的足够大的hole
- Worst-fit:放到最大的hole
First-fit通常比Best-fit好
First-fit和Best-fit通常比Worst-fit好
不同进程间还未分配出去的小内存空间,单个碎片无法分配给任何一个进程
可以把它们压到一起,这种技术叫做Compaction 紧缩技术
外部碎片存在于可变分区、段式虚拟存储系统(分段存储 Segmentation) 中,主要是可变分区
已经被分配出去的大于请求所需的内存空间部分
在固定分区中表现为分区内进程未使用的内存空间
无法重新利用,只能被浪费
内部碎片存在于固定分区、页式虚拟存储系统(分页存储 Paging) 中,主要是固定分区
使用非连续分配
非连续分配
- 把物理内存分为大小相等的块,称为Frame(帧)
- 把逻辑内存分为大小相等的块,称为Page(页) 页的大小和帧相同
- 追踪所有空闲帧,必要时可以找到n个空闲帧加载进程
- 建立 Page table(页表) 记录Page和Frame的映射 页表的数据列只有一列
CPU产生的地址被分为
- Page number(p)
- Page offset(d)
- 清楚划分物理地址和逻辑地址
- 动态重定位
- 没有外部碎片,但会有一些内部碎片(最后一页)
- Page大小通常在4KB-8KB
页表保存在主存中
- Page-table base register(PTBR)指向页表起始
- Page-table length register(PRLR)指明页表大小
每次数据访问需要两次访问内存
- 一次为页表
- 一次为数据
- 使用TLB,一种支持并行搜索的高速硬件 先在TLB里面查,如果页号在里面,就取出相应的帧号,如果不在再去内存的页表找

hit ratio 命中率 EAT(effective access time)
有效无效位
页是否在进程的地址空间内
- Hierarchical page tables
- Hashed page tables
- Inverted page tables
页表太大,不想连续存放 可以分为二级页表 相当于二维数组
系统里只有一张页表 只有真正使用的才被记录
分为大小不同的段,用来存一组相对完整的逻辑信息
逻辑地址包含 <段号,偏移>
- Segment-table base register(STBR) 指向段表起始位置
- Segment-table length register(STLR) 指明段数量
将二维逻辑地址转为一维物理地址
- Base: 段起始空间
- Limit: 段长度
分享代码或数据


将用户逻辑内存从物理内存分离
- 只有部分程序需要在内存中执行
- 因此逻辑内存空间可以比内存空间大很多
- 允许地址空间被多个进程共享
通过需求分页来实现
当需要的时候才把页放入内存
1:页在内存 0:页不在内存
初始都为0
现在页表的数据列变为了两列
地址不在内存,操作系统接管,在磁盘空间查找,找到后放回内存,回到页表修改
如果主存没有空闲帧,则使用Page replacement 页置换
- Copy-on-Write
- Memory-Mapped Files
COW允许父进程和子进程共享同样的资源
- 当共享的页需要修改时,则复制一份
可以像内存访问一样读取文件
- 在磁盘上找到需要的页的位置
- 在内存上找到空闲帧
- 如果没有,放一个牺牲帧到磁盘
- 将页放入空闲帧,更新页表
使用modify(dirty) bit标识帧在取出磁盘后是否被修改
页错误率
平均访问时间
EAT=(1-p)*memory access
+p(page fault interrupt
+swap page out
+swap page in
+restart the process) - Page frame number
- Present/absent bit
- Protection bit
- Modified bit
- Referenced bit
- Caching disabled bit
会有空余部分,因为页表是按字节分配的
目标:更低的页错误率
评估方法:通过一个特定的页置换顺序(reference string)来评估
先进先出
假设最小物理块数为3块。页面引用序列如下:
7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1

注意最开始还未填满时也算作页错误
替换未来最长时间内不会被用到的页
理论上可以达到最低的页错误率 实际上无法做到,只是一个理论参考,因为不知道未来的情况
假定系统为某进程分配了三个物理块, 并考虑有以下的页面号引用串: 7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1 进程运行时,先将7,0,1三个页面装入内存。以后,当进程要访问页面2时,将会产生缺页中断。此时OS根据最佳置换算法,将选择页面7予以淘汰。

过去一段时间内未访问过的页面,在最近的将来可能也不会被访问
因此替换过去最长时间内没被用到的页
两种实现方法
- Counter计数器实现
- Stack栈结构实现
可利用一个特殊的栈来保存当前使用的各个页面的页面号。每当进程访问某页面时,便将该页面的页面号从栈中移出,将它再压入栈顶。即栈顶始终是最新被访问页面的编号,而栈底则是最近最久未使用页面的页面号

对应,每个页面进入后的栈(栈的深度与物理块数量一致)

使用reference bit
被引用过设为1,没被引用过设为0
每次置换reference bit为0的
为每页设置一位访问位,再将内存中的所有页面都通过链接指针链接成一个循环队列。当某页被访问时,其访问位被置1。在选择页面淘汰时,只需检查页的访问位,如果是0,就选择该页换出;若为1,则重新将它置为0,暂时不换出,而给该页第二次驻留内存的机会,再按照FIFO算法检查下一个页面。当检查到队列中的最后一个页面时,若其访问位仍为1,则再返回到队首去检查第一个页面。由于该算法是循环地检查各页面的使用情况,故称为Clock算法。

由访问位A和修改位M可以组合成下面四种类型的页面:
- (A=0, M=0):表示该页最近既未被访问,又未被修改,是最佳淘汰页
- (A=0, M=1):表示该页最近未被访问,但已被修改,并不是很好的淘汰页
- (A=1, M=0):最近已被访问,但未被修改,该页有可能再被访问
- (A=1, M=1):最近已被访问且被修改,该页可能再被访问
有一个时钟顺序,如果轮到要置换的页的reference bit为1,则
- 设reference bit为0
- 把该页留在内存
- 查找下一个reference bit为0的进行替换
注:各种资料对于Clock算法、二次机会法、NRU算法分类不统一,以Clock算法也称NRU算法为准
用一个计数器记录页的使用次数
- LFU(Least Frequently Used) 替换使用次数最小的
- MFU(Most Frequently Used) 替换使用次数最多的
内存没有足够帧
进程忙于交换页
此时CPU利用率极其低下
能从TLB访问到的内存总数 TLB Reach=(TLB Size)*(Page Size)
理想情况下,每个进程的工作集都存在TLB
- Fixed allocation 固定分配
- Priority allocation 优先级分配
- 同等分配 100个帧分给5个进程,每个20页
- 按比例分配 根据进程大小分配
如果Pi产生页错误
- 从自己拥有的帧里选一个替换帧 local replacement
- 从其他低优先级的进程中得到一个替换帧 global replacement
页表里条目数量就看页数(不知道为什么突然加了这么一句)
- 存大量数据
- 进程停止后数据能保存
- 多个进程可以并发访问
在用户视角中,文件是最小的分配存储
- 名称
- 标识符
- 类型
- 位置
- 大小
- 保护
- 时间、日期和用户标识
- 创建文件
- 写文件
- 读文件
- 文件重定位(文件寻址)
- 删除文件
- 截断文件
6个基本操作可以组合执行其他文件操作
- 字节
- 记录
- 树
- 顺序访问
- 直接访问
- 索引访问,在直接访问之上
- 磁盘被分区 逻辑分区 CDEF
- 文件信息保存在目录 directory directory可以看成符号表,将文件名翻译为目录条目
- Single-Level Directory
- Two-Level Directory
- Tree-Structured Directory
- Acyclic-Graph Directory
- General-Graph Directory
所有User一个目录
文件名要唯一
graph sld{
ROOT [shape=folder];
A,B,C [shape=note];
ROOT -- A,B,C
}- 每个User一个目录
- 当一个User需要特定文件时,只在它的目录搜索
- 不同用户可以有相同名称的文件
- 协作困难
graph tld{
ROOT,UserA,UserB,UserC [shape=folder];
a1,a2,b1,c1,c2,c3 [shape=note,label=""];
ROOT--UserA,UserB,UserC
UserA--a1,a2
UserB--b1
UserC--c1,c2,c3
}最普遍的
- 有一个跟
- 每个文件都有唯一路径名
graph tsd{
ROOT,A,B,C,D,E [shape=folder]
a1,d1,b1 [shape=note,label=""]
ROOT--A,B,C
A--a1
B--D,b1,E
D--d1
}树形目录结构可便于实现文件分类,但不便于实现文件共享,为此在树形目录结构的基础上增加一些指向同一节点的有向边
父目录共享子目录和文件,但共享边不会形成环
digraph agd{
ROOT,A,B,C,D,E [shape=folder]
ROOT->A,B,C
A,B->D
A,C->E
}共享边有环
会产生问题
| 层级 | 操作、实例 |
|---|---|
| App, Programs | 发出文件请求的代码 |
| Logical File System | OS最高层。保护、安全、文件名解析 |
| File-organization Module | 逻辑块 |
| Basic File System | 具体文件块 |
| I/O Control | 驱动、中断 |
| Devices | Disk,tapes |
包含
- boot control block: 启动OS的信息
- partition control block: 分区信息
- directory structure
- FCB(File Control Block): 文件细节
- 线性表
- Hash表
- 缩短时间
- 冲突
- 大小固定
- 文件名存储
- 行内
- 堆内
- Contiguous allocation 连续分配
- Linked allocation 链接分配
- Indexed allocation 索引分配
<起始块位置,文件长度>
- 简单、快速
- 有浪费
- 文件大小不能改变
- 离散的
- 链表结构
- 没有浪费
- 不能直接访问
例子 File-Allocation Table FAT
每个文件都有索引快
- 需要索引表
- 随机访问
- 没有外部碎片,但小文件有内部碎片
为所有空闲块建立一张空闲块标,每个空闲区对应一个空闲表项,内容包括表项序号、该空闲区第一个盘块号、该区的空闲盘块数
例子
| 序号 | 第一个空闲块号 | 空闲块数 |
|---|---|---|
| 1 | 2 | 4 |
| 2 | 9 | 3 |
| 3 | 15 | 5 |
| 4 | ... | ... |
每个块用1 bit表示
- 如果块空闲,bit为1
- 如果块被分配,bit为0
特点
- 简单
- 有效找到第一个空闲块
- 容易得到连续的空闲块 1111
- bit map需要额外的空间
空闲块用链表的形式连接
- 不浪费空间
- 必须遍历list
在第一个空闲块存n个空闲块的地址,在n个空闲块的最后一个再存n个空闲块的地址
- Block devices 块设备 由于信息的存取总是以数据块为单位的,所以存储信息的设备称为块设备,如硬盘,每个都有自己的地址,可寻址
- Character devices 字符设备 用于数据输入输出的设备为字符设备,因为其传输的基本单位是字符,如打印机,不可寻址
I/O设备有机械和电子部分 电子部分叫controller
每个controller有一些寄存器用来和CPU交互
两种方案
- 每个controller register有端口号,CPU使用端口号访问
- 把所有寄存器的值导入内存,CPU访问内存
各种各样
- 屏蔽硬件
- 错误处理
- 缓存
- 抽象
- 封装
- 中断处理
- 设备驱动
- 设备无关的I/O软件
- Scheduling
- Buffering 缓冲 在设备传输时存数据 解决设备速度不一致
- Caching 缓存 快速存储数据备份
- Spooling 保存设备输出
磁道
扇区
访问时间有两部分
- Seek time(主要) 磁头寻道时间
- Rotational latency 磁盘转到合适位置需要的时间
先来先服务
最短寻道时间优先
离磁头当前位置最近的优先
先按一个方向走完,再换另一个方向走
先向一个方向,回来直接到边界,再按同一方向走
先向一个方向,回来到最远的访问点,再按同一方向走
低级格式化,也称物理格式化
- 所有盘面上的扇区编好道
高级格式化,也称逻辑格式化
- 建立起文件系统
冗余磁盘阵列