[arxiv] · [amazon.science blog] · [5min-video] · [talk@RIKEN] · [openreview]
Code repo for ICLR 2022 paper Trans-Encoder: Unsupervised sentence-pair modelling through self- and mutual-distillations
by Fangyu Liu, Yunlong Jiao, Jordan Massiah, Emine Yilmaz, Serhii Havrylov.
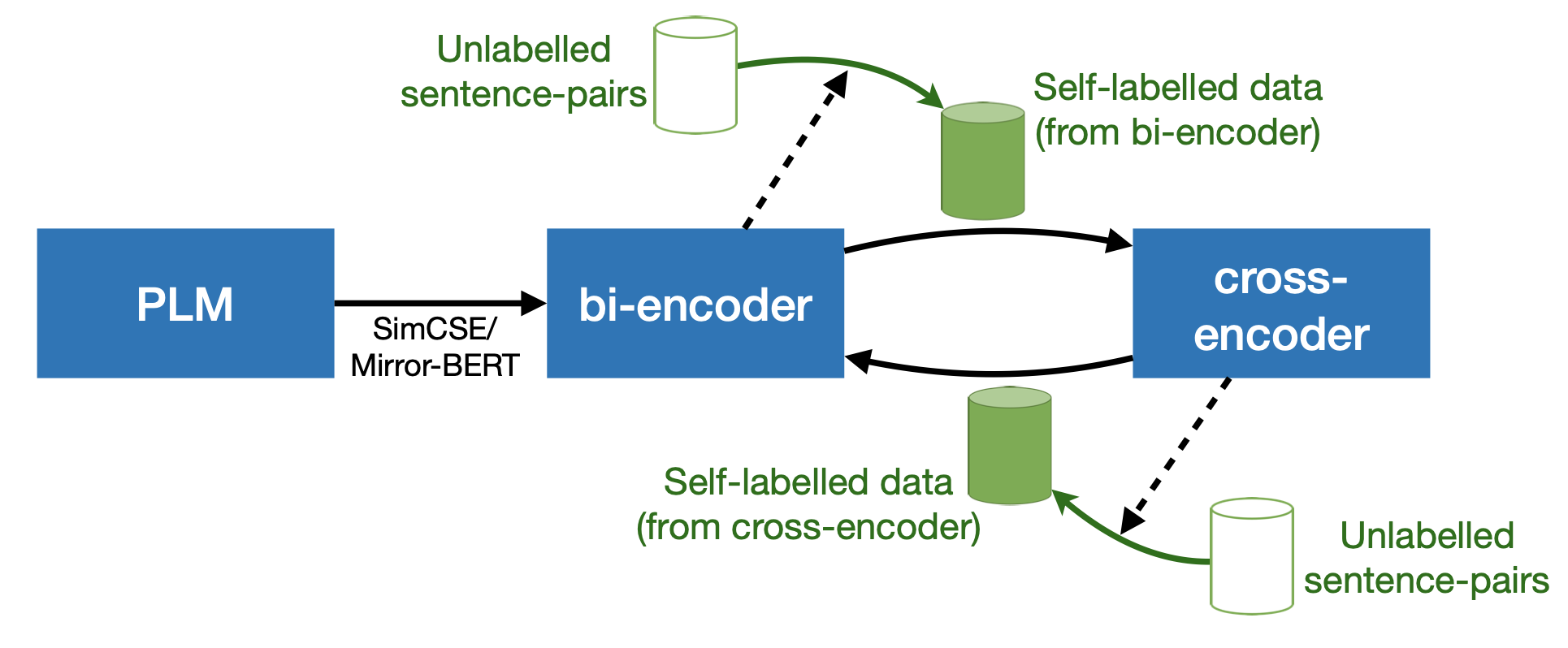
Trans-Encoder is a state-of-the-art unsupervised sentence similarity model. It conducts self-knowledge-distillation on top of pretrained language models by alternating between their bi- and cross-encoder forms.
| base models | large models | ||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
torch==1.8.1
transformers==4.9.0
sentence-transformers==2.0.0
Please view requirements.txt for more details.
All training and evaluation data will be automatically downloaded when running the scripts. See src/data.py for details.
--task options: sts (STS2012-2016 and STS-b), sickr, sts_sickr (STS2012-2016, STS-b, and SICK-R), qqp, qnli, mrpc, snli, custom. See src/data.py for task data details. By default using all STS data (sts_sickr).
>> bash train_self_distill.sh 00 denotes GPU device index.
>> bash train_mutual_distill.sh 0,1Two GPUs needed; by default using SimCSE BERT & RoBERTa base models for ensembling. Add --use_large for switching to large models.
>> CUDA_VISIBLE_DEVICES=0,1 python src/mutual_distill_parallel.py \
--batch_size_bi_encoder 128 \
--batch_size_cross_encoder 64 \
--num_epochs_bi_encoder 10 \
--num_epochs_cross_encoder 1 \
--cycle 3 \
--bi_encoder1_pooling_mode cls \
--bi_encoder2_pooling_mode cls \
--init_with_new_models \
--task custom \
--random_seed 2021 \
--custom_corpus_path CORPUS_PATHCORPUS_PATH should point to your custom corpus in which every line should be a sentence pair in the form of sent1||sent2.
Bi-encoder:
>> python src/eval.py \
--model_name_or_path "cambridgeltl/trans-encoder-bi-simcse-roberta-large" \
--mode bi \
--task sts_sickrCross-encoder:
>> python src/eval.py \
--model_name_or_path "cambridgeltl/trans-encoder-cross-simcse-roberta-large" \
--mode cross \
--task sts_sickrBi-encoder:
>> python src/eval.py \
--model_name_or_path1 "cambridgeltl/trans-encoder-bi-simcse-bert-large" \
--model_name_or_path2 "cambridgeltl/trans-encoder-bi-simcse-roberta-large" \
--mode bi \
--ensemble \
--task sts_sickrCross-encoder:
>> python src/eval.py \
--model_name_or_path1 "cambridgeltl/trans-encoder-cross-simcse-bert-large" \
--model_name_or_path2 "cambridgeltl/trans-encoder-cross-simcse-roberta-large" \
--mode cross \
--ensemble \
--task sts_sickr- Fangyu Liu: Main contributor
See CONTRIBUTING for more information.
This project is licensed under the Apache-2.0 License.