𝐑𝐞𝐚𝐥-𝐓𝐢𝐦𝐞 𝐅𝐚𝐜𝐞 𝐦𝐚𝐬𝐤 𝐝𝐞𝐭𝐞𝐜𝐭𝐢𝐨𝐧 𝐮𝐬𝐢𝐧𝐠 𝐝𝐞𝐞𝐩𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠 𝐰𝐢𝐭𝐡 𝐀𝐥𝐞𝐫𝐭 𝐬𝐲𝐬𝐭𝐞𝐦 💻🔔
It detects human faces with 𝐦𝐚𝐬𝐤 𝐨𝐫 𝐧𝐨-𝐦𝐚𝐬𝐤 even in crowd in real time with live count status and notifies user (officer) if danger.

System Modules:
-
Deep Learning Model : I trained a YOLOv2,v3 and v4 on my own dataset and for YOLOv4 achieved 93.95% mAP on Test Set whereas YOLOv3 achieved 90% mAP on Test Set even though my test set contained realistic blur images, small + medium + large faces which represent the real world images of average quality.
-
Alert System: It monitors the mask, no-mask counts and has 3 status :
- Safe : When all people are with mask.
- Warning : When atleast 1 person is without mask.
- Danger : ( + SMS Alert ) When some ratio of people are without mask.
Step 1:
git clone https://github.com/adityap27/face-mask-detector.git
Then, Download weights. https://bit.ly/yolov4_mask_weights and put in yolov4-mask-detector folder
Step 2: Install requirements.
pip install opencv-python
pip install imutils
Step 3: Run yolov4 on webcam
python mask-detector-video.py -y yolov4-mask-detector -u 1
Optional: add -e 1 for Email notifications.
- Images were collected from Google Images, Bing Images and some Kaggle Datasets.
- Chrome Extension used to download images: link
- Images were annoted using Labelimg Tool.
- Dataset is split into 3 sets:
| Set | Number of images | Objects with mask | Objects without mask |
|---|---|---|---|
| Training Set | 700 | 3047 | 868 |
| Validation Set | 100 | 278 | 49 |
| Test Set | 120 | 503 | 156 |
| Total | 920 | 3828 | 1073 |
- Download the Dataset here:
- Install Darknet for Mac or Windows first.
- I have trained Yolov2,Yolov3 and YOLOv4.
- Use following (linux) cmd to train:
./darknet detector train obj.data yolo3.cfg darknet53.conv.74- for windows use darknet.exe instead of ./darknet
YOLOv2 Training details
- Data File = obj.data
- Cfg file = yolov2.cfg
- Pretrained Weights for initialization= yolov2.conv.23
- Main Configs from yolov2.cfg:
- learning_rate=0.001
- batch=64
- subdivisions=16
- steps=1000,4700,5400
- max_batches = 6000
- i.e approx epochs = (6000*64)/700 = 548
- YOLOv2 Training results: 0.674141 avg loss
- Weights of YOLOv2 trained on Face-mask Dataset: yolov2_face_mask.weights
YOLOv3 Training details
- Data File = obj.data
- Cfg file = yolov3.cfg
- Pretrained Weights for initialization= darknet53.conv.74
- Main Configs from yolov3.cfg:
- learning_rate=0.001
- batch=64
- subdivisions=32
- steps=4800,5400
- max_batches = 6000
- i.e approx epochs = (6000*64)/700 = 548
- YOLOv3 Training results: 0.355751 avg loss
- Weights of YOLOv3 trained on Face-mask Dataset: yolov3_face_mask.weights
YOLOv4 Training details
- Data File = obj.data
- Cfg file = yolov4-obj.cfg
- Pretrained Weights for initialization= yolov4.conv.137
- Main Configs from yolov4-obj.cfg:
- learning_rate=0.001
- batch=64
- subdivisions=64
- steps=4800,5400
- max_batches = 6000
- i.e approx epochs = (6000*64)/700 = 548
- YOLOv4 Training results: 1.19 avg loss
- Weights of YOLOv4 trained on Face-mask Dataset: yolov4_face_mask.weights
- Below is the comparison of YOLOv2, YOLOv3 and YOLOv4 on 3 sets.
- Metric is [email protected] i.e Mean Average Precision.
- Frames per Second (FPS) was measured on Google Colab GPU - Tesla P100-PCIE using Darknet command: link
| Model | Training Set | Validation Set | Test Set | FPS |
|---|---|---|---|---|
| YOLOv2 | 83.83% | 74.50% | 78.95% | 45 FPS |
| YOLOv3 | 99.75% | 87.16% | 90.18% | 23 FPS |
| YOLOv4 | 99.65% | 88.38% | 93.95% | 22 FPS |
- Note: For more detailed evaluation of model, click on model name above.
- Conclusion:
- Yolov2 has High bias and High Variance, thus Poor Performance.
- Yolov3 has Low bias and Medium Variance, thus Good Performance.
- Yolov4 has Low bias and Medium Variance, thus Good Performance.
- Model can still generalize well as discussed in section : 4. Suggestions to improve Performance
- You can run model inference or detection on image/video/webcam.
- Two ways:
- Using Darknet itself
- Using Inference script (detection + alert)
- Note: If you are using yolov4 weights and cfg for inference, then make sure you use opencv>=4.4.0 else you will get
Unsupported activation: misherror.
-
Use command:
./darknet detector test obj.data yolov3.cfg yolov3_face_mask.weights input/1.jpg -thresh 0.45OR
-
Use inference script
python mask-detector-image.py -y yolov3-mask-detector -i input/1.jpg -
Output Image:


{kind=link}
{kind=link}
{kind=link}
-
Use command:
./darknet detector demo obj.data yolov3.cfg yolov3_face_mask.weights <video-file> -thresh 0.45OR
-
Use inference script
python mask-detector-video.py -y yolov3-mask-detector -i input/airport.mp4 -u 1 -
Output Video:
-
Use command: (just remove input video file)
./darknet detector demo obj.data yolov3.cfg yolov3_face_mask.weights -thresh 0.45OR
-
Use inference script: (just remove input video file)
python mask-detector-video.py -y yolov3-mask-detector -u 1 -
Output Video:

- All the results(images & videos) shown are output of yolov3, you can use yolov4 for better results.
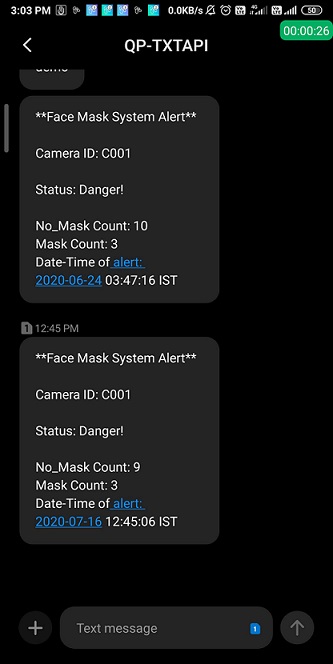
- Update: E-mail notification support is added now as SMS are paid.
- Alert system is present within the inference script code.
- You can modify the SMS alert code in script to customize ratio for sms if you want.
- It monitors the mask, no-mask counts and has 3 status :
- Safe : When all people are with mask.
- Warning : When atleast 1 person is without mask.
- Danger : ( + SMS Alert ) When some ratio of people are without mask.
-
As described earlier that yolov4 is giving 93.95% mAP on Test Set, this can be improved by following tips if you want:
- Use more Training Data.
- Use more Data Augmentation for Training Data.
- Train with larger network-resolution by setting your
.cfg-file(height=640 and width=640) (any value multiple of 32). - For Detection use even larger network-resolution like 864x864.
- Try YOLOv5 or any other Object Detection Algorithms like SSD, Faster-RCNN, RetinaNet, etc. as they are very good as of now (year 2020).