OpenMMD represents the OpenPose-Based Deep-Learning project that can directly convert real-person videos to the motion of animation models (i.e. Miku, Anmicius). OpenMMD can be referred as OpenPose + MikuMikuDance (MMD). In short, you record a piece of video with human motions, through this project you will see a 3D model acting the same motions as what you do in the video.

3D model example: Anmicius
- OpenPose is the first real-time multi-person system proposed by Carnegie Mellon University used to jointly detect human body key points on single images or videos.
- MMD is a freeware animation program that lets users animate and create 3D animated movies using 3D models like Miku and Anmicius.
- OpenPose and MMD are only the "entrance" and "exit" of the application box. There are three intermediate pre-trained Deep Learning Models in the box to process and convert formatted data. They are stated in the Features section below.
The project implements multiple Deep Learning Models as a sequential chain. The output of the previous model will be fed as the input of the following. Some implementations are the edited version of the original for better performance in the application.
- Functionality:
- 3D Single-person Key Points Detection (OpenPose):
- Proposed by Gines Hidalgo, Zhe Cao, Tomas Simon, Shih-En Wei, Hanbyul Joo, and Yaser Sheikh at CVPR 2017.
- Recoded real-person video input and JSON files collections of motion key points as the output.
- Strong Baseline for 3D Human Pose Estimation:
- Proposed by Julieta Martinez, Rayat Hossain, Javier Romero, James J. Little In ICCV, 2017. An effective baseline for 3d human pose estimation.
- Combining all the key points JSON files to a continuous sequence with strong baselines.
- Unsupervised Adversarial Learning of 3D Human Pose from 2D Joint Locations (Newly added feature. Under testing.):
- Proposed by Yasunori Kudo, Keisuke Ogaki, Yusuke Matsui, Yuri Odagiri at CVPR 2018. The task of 3D human pose estimation from a single image can be divided into two parts: (1) 2D human joint detection from the image and (2) estimating a 3D pose from the 2D joints.
- Implemented by @DwangoMediaVillage to fit to VMD format. Use of GAN will significantly improve the performance during the converting process than what achived by using the baseline methods.
- Video Depth Prediction:
- Proposed by Iro Laina and Christian Rupprecht at the IEEE International Conference on 3D Vision 2016. FCRN: Deeper Depth Prediction with Fully Convolutional Residual Networks.
- Estimation of depth for objects, backgrounds and the moving person in the video (e.g. dancer).
- Human Motion Key Points to VMD Motion Files for MMD Build:
- Proposed by Denis Tome, Chris Russell and Lourdes Agapito at CVPR 2017. Convolutional 3D Pose Estimation from a single image.
- Edited by @miu200521358 to output VMD files so that the formatted result can be directly fed to MMD for generating animated dancing movies.
- 3D Single-person Key Points Detection (OpenPose):
- Input: videos of common formats (AVI, WAV, MOV) or images of common formats (PNG, JPG),
- Output: Animations or Posetures of 3D models (e.g. Miku Dancing)
- OS: Windows (8, 10), MacOS (2017 Released Version)
- Demo Video: Youtube Link made by Jacob Xie.

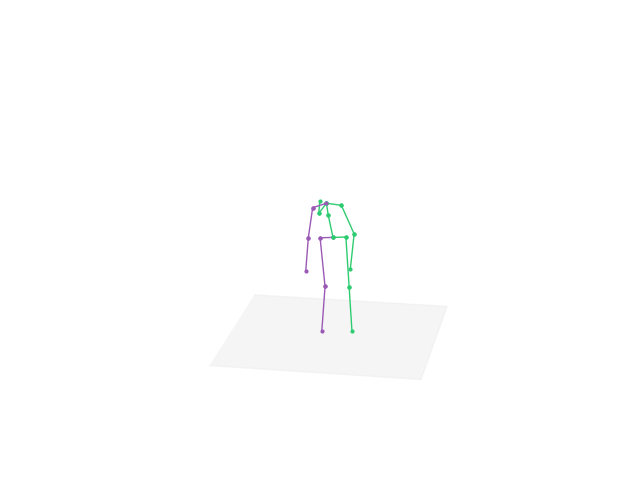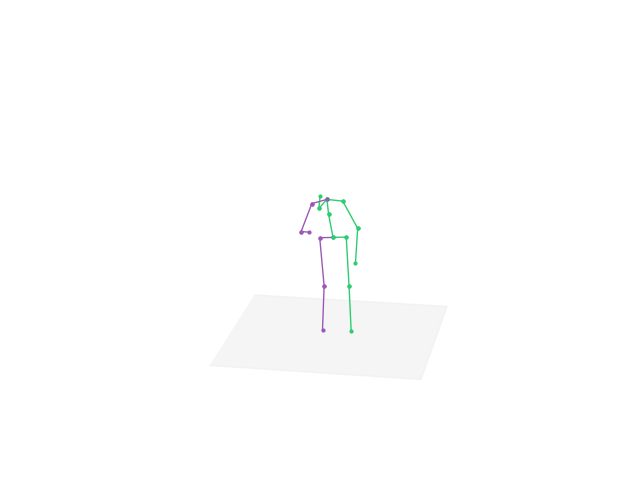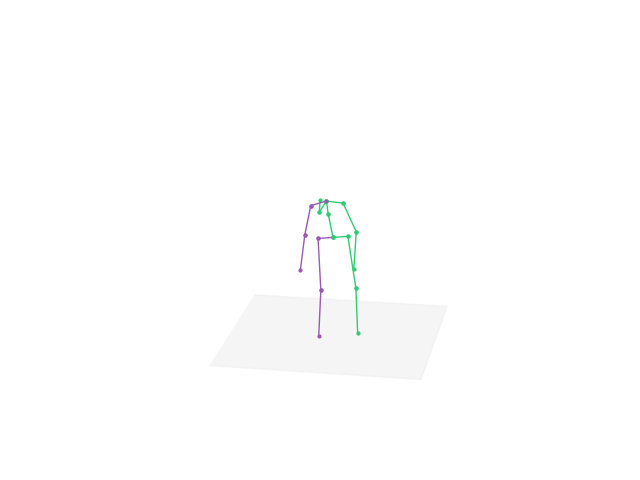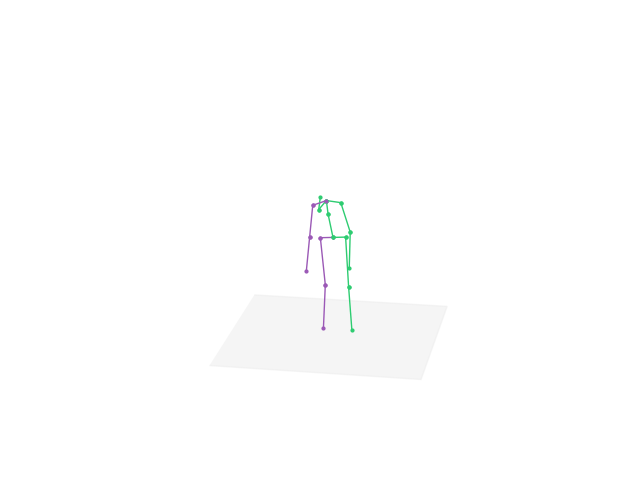

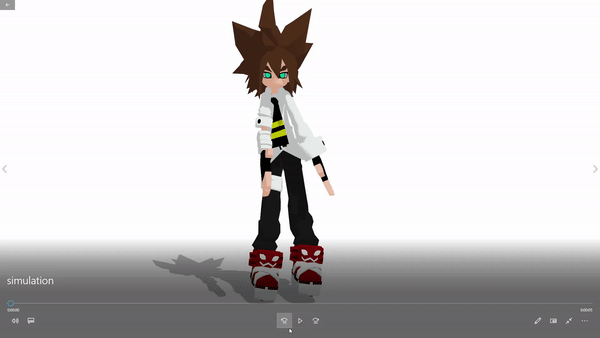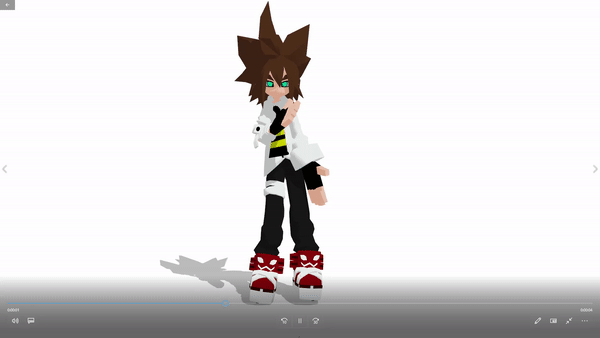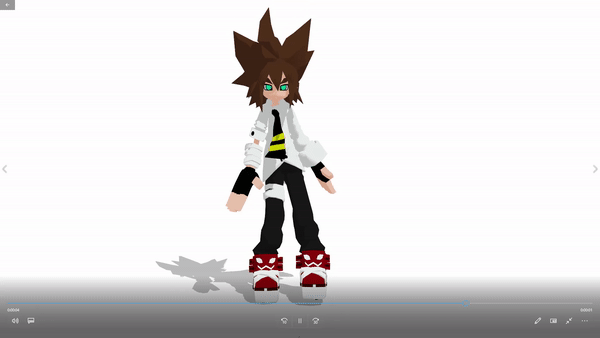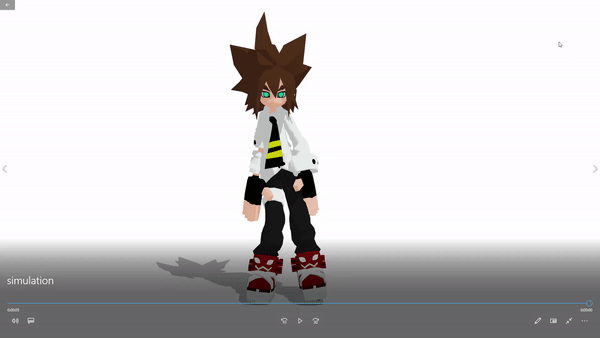
Download the full pack: Note that the full application is about 5GB. That is mainly because the large-size parameters of the pre-trained deep learning models. Download the whole pack contains the pre-trained models with optimized parameters and corresponding compilable codes.
Follow the instruction to begin your first animation:
- Record a piece of video contains human motions. Satisfy all the prerequisite libraries stated below.
- After downloading, firstly activate tensorflow environment in the terminal of anaconda.
- Run OpenposeVideo.bat and follow the pop-out instructions.
- Then proceed to the 3d-pose-baseline-vmd folder and run OpenposeTo3D.bat. Follow the pop-out instructions.
- After that, proceed to the FCRN-DepthPrediction-vmd folder and run VideoToDepth.dat.
- Finally, proceed to the VMD-3d-pose-baseline-multi folder and run 3DToVMD.bat. You will get the vmd file.
- VMD files are 3D animation file used by MikuMikuDance, a program used to create dance animation movies. Open your MikuMikuDance and input the VMD file.
- You will see your Miku begin acting the same motions as that in your recorded video.
Tutorial in Chinese (中文教程): Developers that can understand Chinese are encouraged to read the tutorial written by @mrzjy on Bilibili Articles: Click Here. This tutorial covers how to install and run the OpenMMD. The tutorial also introduces some common issues of OpenMMD.
- OpenCV and relevance
pip install opencv-python
pip install numpy
pip install matplotlib
- Tensorflow and h5py. Please implement them in anaconda.
pip install tensorflow
conda create -n tensorflow pip python=3.6 // Create a workbench
activate tensorflow
pip install --ignore-installed --upgrade tensorflow
conda install h5py
//You will also need to install Keras in anaconda.
- Other libraries includes:
pip install python-dateutil
pip install pytz
pip install pyparsing
pip install six
pip install imageio
I would like to give special thanks for the contribution from Zhang Xinyi. As an expert in Photoshop and Video Processing, He offered great help in recording and processing the sample images and videos. He also offered nice ideas on how to improve video smoothing performance.
I would like to say special thanks to @miu200521358 who provides a series of detailed tutorials on OpenPose and relevant models. That really promotes my implementation progress. His versions of model implementations are also of great help. I learn a lot from his instructions on anaconda and tensorflow.
I would like to give special thanks to @mrzjy from Bilibili who writes a very detailed Chinese tutorial on how to install and run OpenMMD. This tutorial covers detailed steps and possible bugs when using the project. The quality of the tutorial is very high. 哔哩哔哩(゜-゜)つロ干杯!
This project is an open source project. Let me know if:
- you find videos or images conversion does not work well.
- you know how to speed up or improve the performance of 3D converting.
- you have suggestions about future possible functionalities.
- and anything you want to ask...
Just comment on GitHub or make a pull request and I will answer as soon as possible!
If you appreciate the project, please kindly star it. :D Feel free to download and develop your own 3D animations.
Thank you for your time!