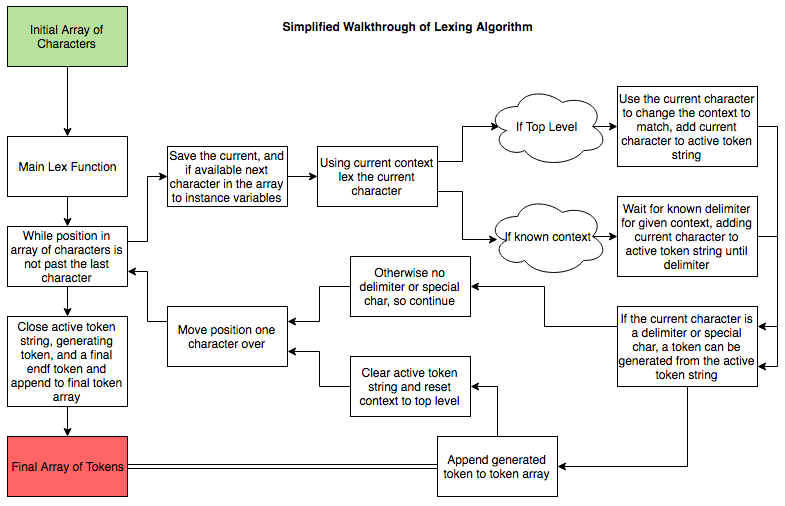
It is time to begin with the actual design and implementation of our toy compiler. If you made it this far, then you know our first step in building a compiler is to create something known as a Lexer. The Lexer will be a component of our compiler. Its job is to take an array of character data and produce an array of tokens.
The Lexer will begin by taking the array of characters and looping through them one at a time. As it does so it will be keeping track of important information such as the line and column number for positioning, the current character, and the current token being parsed. When the Lexer either reaches a character indicating the end of a token, or the current token being parsed equals specific keywords or symbols it knows that it can parse the current token information. When the previous condition is reached, the Lexer adds a new Token to its Token array reflecting the parsed token information, it then restarts the token processing algorithm where it left off.
Our Lexer will also have some additional properties to help it when parsing our language. One thing our Lexer will have is a context property. This allows the Lexer to understand more complicated groupings of characters. For example we want our Lexer to recognize that the following grouping of characters: "Hello World!" is in fact one String token rather than two separate tokens. An easy way to accomplish this is to use the context property to indicate when the Lexer has entered a String section so it knows to continue adding characters until the second quotation symbol is encountered. This context property can also be used to collate comments into a single Token.
The only remaining requirement for our Lexer is for it to inject some whitespace tokens during its work to aid the Parser. In order for the Parser to be able to clearly know when a given expression ends and a new one begins, our Lexer should append a new line token on each new line escape sequence, and to be explicit we will also append an end of file token once Lexing is complete. This way our array of tokens will clearly indicate the linear order of all the semantics of our programming language including the effects of whitespace on expressions.
Here is a high level view of what the lexer is doing to generate the token array from a given array of characters.