Yash Khare*, Viraj Bagal*, Minesh Mathew, Adithi Devi, U Deva Priyakumar, CV Jawahar
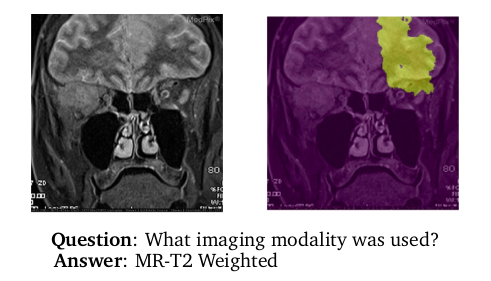
Abstract: Images in the medical domain are fundamentally different from the general domain images. Consequently, it is infeasible to directly employ general domain Visual Question Answering ( VQA ) models for the medical domain. Additionally,medical images annotation is a costly and time-consuming process. To overcome these limitations, we propose a solution inspired by self-supervised pretraining of Transformer-style architectures for NLP , V ision and L anguage tasks. Our method involves learning richer medical image and text semantic representations using Masked Language Modeling (MLM) with image features as the pretext task on a large medical image+caption dataset. The proposed solution achieves new state-of-the-art performance on two VQA datasets for radiology images – VQA - M ed 2019 and VQA - RAD , outperforming even the ensemble models of previous best solutions. Moreover, our solution provides attention maps which help in model interpretability.
python train_vqarad.py --run_name give_name --mixed_precision --use_pretrained --lr set_lr --epochs set_epochs
python train.py --run_name give_name --mixed_precision --lr set_lr --category cat_name --batch_size 16 --num_vis set_visual_feats --hidden_size hidden_dim_size
python eval.py --run_name give_name --mixed_precision --category cat_name --hidden_size hidden_dim_size --use_pretrained
MMBERT General, which is a single model for both the question types in the dataset, outperforms the existing approaches including the ones which have a dedicated model for each question type.
| Method | Dedicated Models | Open Acc. | Closed Acc. | Overall Acc. |
|---|---|---|---|---|
| MEVF + SAN | - | 40.7 | 74.1 | 60.8 |
| MEVF + BAN | - | 43.9 | 75.1 | 62.7 |
| Conditional Reasoning | ✔️ | 60.0 | 79.3 | 71.6 |
| MMBERT General | ❌ | 63.1 | 77.9 | 72.0 |
Our MMBERT Exclusive achieves state-of-the-art results on the overall accuracy and BLEU score, even surpassing CGMVQA E ns. which is an ensemble of 3 dedicated models for each category. Even our MMBERT General performs better than the CGMVQA Ens. on the abnormality and yes/no categories. Additionally, our MMBERT General outperforms single dedicated CGMVQA models in all the categories but modality.
| Method | Dedicated Models | Modality Acc. | Modality Bleu | Plane Acc. | Plane Bleu | Organ Acc. | Organ Bleu | Abnormality Acc. | Abnormality Bleu | Yes/No Acc. | Yes/No Bleu | Overall Acc. | Overall Bleu |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VGG16 + BERT | - | - | - | - | - | - | - | - | - | - | - | 62.4 | 64.4 |
| CGMVQA | ✔️ | 80.5 | 85.6 | 80.8 | 81.3 | 72.8 | 76.9 | 1.7 | 1.7 | 75.0 | 75.0 | 62.4 | 64.4 |
| CGMVQA Ens. | ✔️ | 81.9 | 88.0 | 86.4 | 86.4 | 78.4 | 79.7 | 4.4 | 7.6 | 78.1 | 78.1 | 64.0 | 65.9 |
| MMBERT General | ❌ | 77.7 | 81.8 | 82.4 | 82.9 | 73.6 | 76.6 | 5.2 | 6.7 | 85.9 | 85.9 | 62.4 | 64.2 |
| MMBERT NP | ✔️ | 80.6 | 85.6 | 81.6 | 82.1 | 71.2 | 74.4 | 4.3 | 5.7 | 78.1 | 78.1 | 60.2 | 62.7 |
| MMBERT Exclusive | ✔️ | 83.3 | 86.2 | 86.4 | 86.4 | 76.8 | 80.7 | 14.0 | 16.0 | 87.5 | 87.5 | 67.2 | 69.0 |