Optimize qubit order for better data locality #26
Comments
|
Hi @totikom, Thank you for your insight! This would be a great initial start to a "circuit optimizer" that can be run prior to executing the actual circuit. If you're interested in implementing your suggestion, you are more than welcome to submit a PR. For the sake of completeness and posterity, I will include some other findings/insights: In my recent tests, I found that the single-threaded performance difference is negligible whether applying Note that applying a gate to the This may be a way to tackle the implementation of your suggestion. Best, |
{kind=link}
{kind=link}
Yes! I've also though about it (I was doing a toy QC simulator for my curriculum two years ago), but I haven't found a data structure, which will "remain local" for all qubits, so I decided that it would be beneficial to reorder circuits. Unfortunately, that course has ended and I was busy working on my Master's, so that project was abandoned. I'll try to implement a naive optimizer for circuits and will make a PR.) |
|
The optimizer can be based on a cost model, which will justify, whenever transformations are beneficial. I'm going to use LLVM VPlan as an example. (Well, it is going to be not so naive optimizer) |
|
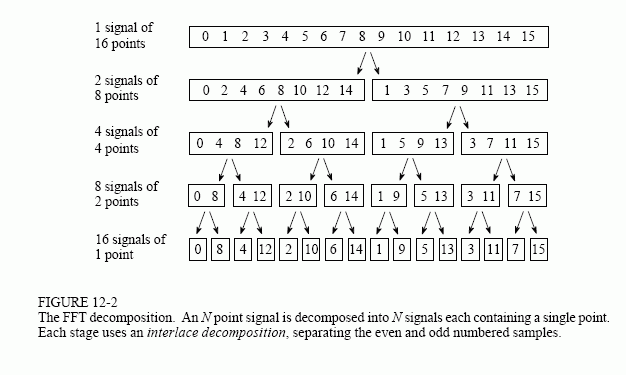
@totikom Thank you! I found a great resource that discusses the same data locality issue, but in the context of FFT. Please see chapter 7 in Construction of a High-Performance FFT. Best, |
(This may be completely unnecessary/inapplicable, so feel free to just close it)
The performance of simulating gates on big states drastically depends on its position (i.e. it is much faster to apply
Hto 0th qubit of the 30-qubit state that to the 29th)So, for "unbalanced" circuits it is very beneficial to move "the most used" qubits to lower indices.
The text was updated successfully, but these errors were encountered: