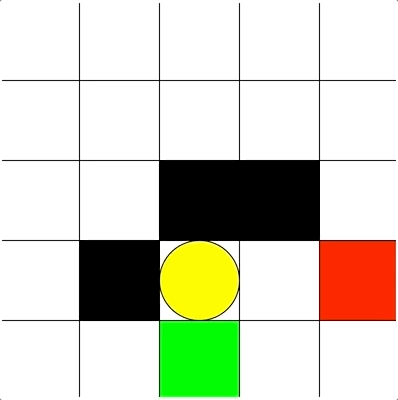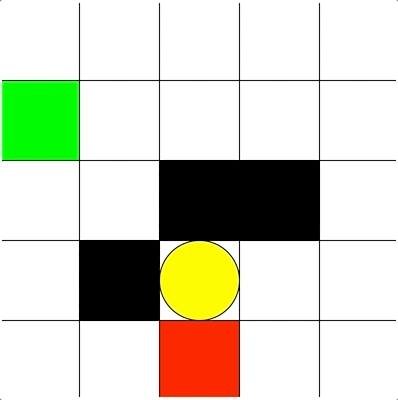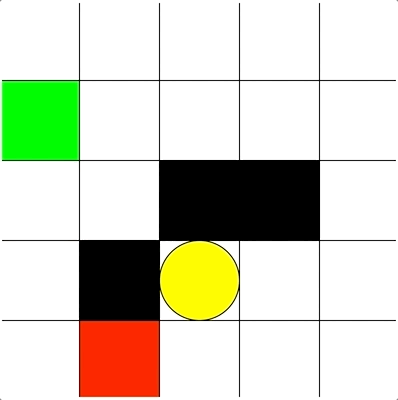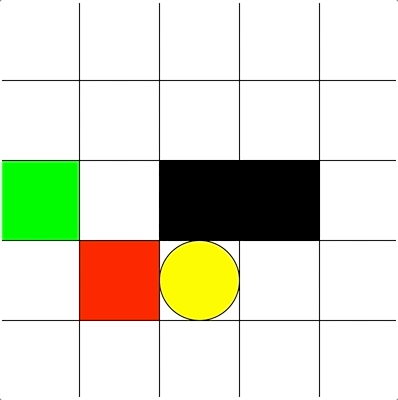
Goal: Reaching the yellow oval while avoiding black blocks and moving enemy (red block)
Implementation of Q-Learning usind TD error for optimally navigating a maze while avoiding a moving enemy.
$ pip install numpy pandas
$ python main.pyProject comes with trained Qtable in pickled file action You may run in the following ways
$ python main.py$ python main.py --test(slow, mostly for debugging)
$ python main.py --test --visQ-values are updated based on the following formula:

newVal = oldVal + learningRate * (reward + discount_val * maxValOfNextState - oldVal)