diff --git a/tools/pika_migrate/README.md b/tools/pika_migrate/README.md
index ccacd1beee..01afc5bcbb 100644
--- a/tools/pika_migrate/README.md
+++ b/tools/pika_migrate/README.md
@@ -1,114 +1,76 @@
-# Pika
-[](https://travis-ci.org/Qihoo360/pika)
-## Introduction[中文](https://github.com/Qihoo360/pika/blob/master/README_CN.md)
+## 适用版本
-Pika is a persistent huge storage service , compatible with the vast majority of redis interfaces ([details](https://github.com/Qihoo360/pika/wiki/pika-支持的redis接口及兼容情况)), including string, hash, list, zset, set and management interfaces. With the huge amount of data stored, redis may suffer for a capacity bottleneck, and pika was born for solving it. Except huge storage capacity, pika also support master-slave mode by slaveof command, including full and partial synchronization. You can also use pika together with twemproxy or codis(*pika has supported data migration in codis,thanks [left2right](https://github.com/left2right) and [fancy-rabbit](https://github.com/fancy-rabbit)*) for distributed Redis solution
+适用 PIKA 3.2.0及以上版本,单机模式且只使用了单 DB。若 PIKA 版本低于3.2.0,需将内核版本升级至 3.2.0。具体信息,请参见 升级 PIKA 内核版本至3.2.0。
+### 开发背景:
+之前Pika项目官方提供的pika\_to\_redis工具仅支持离线将Pika的DB中的数据迁移到Pika、Redis, 且无法增量同步, 该工具实际上就是一个特殊的Pika, 只不过成为从库之后, 内部会将从主库获取到的数据转发给Redis,同时并支持增量同步, 实现热迁功能.
+## 迁移原理
-## UserList
+将 PIKA 中的数据在线迁移到 Redis,并支持全量和增量同步。使用 pika-migrate 工具,将工具虚拟为 PIKA 的从库,然后从主库获取到数据转发给 Redis,同时支持增量同步,实现在线热迁的功能。
+1. pika-migrate 通过 dbsync 请求获取主库全量 DB 数据,以及当前 DB 数据所对应的 binlog 点位。
+2. 获取到主库当前全量 DB 数据之后,扫描 DB,将 DB 中的数据打包转发给 Redis。
+3. 通过之前获取的 binlog 的点位向主库进行增量同步, 在增量同步的过程中,将从主库获取到的 binlog 重组成 Redis 命令,转发给 Redis。
-
-
- |
- |
- |
- |
-
-
- |
- |
- |
- |
-
-
- |
- |
- |
- |
-
-
- |
- |
- |
- |
-
-
- |
- |
- |
- |
-
-
-[More](https://github.com/Qihoo360/pika/blob/master/USERS.md)
+## 注意事项
-## Feature
+PIKA 支持不同数据结构采用同名 Key,但是 Redis 不⽀持,所以在有同 Key 数据的场景下,以第⼀个迁移到 Redis 数据结构为准,其他同名 Key 的数据结构会丢失。
+该工具只支持热迁移单机模式下,并且只采⽤单 DB 版本的 PIKA,如果是集群模式,或者是多 DB 场景,⼯具会报错并且退出。
+为了避免由于主库 binlog 被清理导致该⼯具触发多次全量同步向 Redis 写入脏数据,工具自身做了保护,在第⼆次触发全量同步时会报错退出。
-* huge storage capacity
-* compatible with redis interface, you can migrate to pika easily
-* support master-slave mode (slaveof)
-* various [management](https://github.com/Qihoo360/pika/wiki/pika的一些管理命令方式说明) interfaces
-
-## For developer
-
-### Releases
-The User can download the binary release from [releases](https://github.com/Qihoo360/pika/releases) or compile the source release.
-
-### Dependencies
-
-* snappy - a library for fast data compression
-* glog - google log library
-
-Upgrade your gcc to version at least 4.8 to get C++11 support.
-
-### Supported platforms
-
-* linux - Centos 5&6
-
-* linux - Ubuntu
-
-If it comes to some missing libs, install them according to the prompts and retry it.
-
-### Compile
-
-Upgrade your gcc to version at least 4.8 to get C++11 support.
-
-Get the source code
-
-```
-git clone https://github.com/Qihoo360/pika.git
-```
-
-
-Then compile pika, all submodules will be updated automatically.
-
-```
+## 编译步骤
+```shell
+# 若third目录中子仓库为空,需要进入工具根目录更新submodule
+git submodule update --init --recursive
+# 编译
make
```
-## Usage
+### 编译备注
+1.如果rocksdb编译失败,请先按照[此处](https://github.com/facebook/rocksdb/blob/004237e62790320d8e630456cbeb6f4a1f3579c2/INSTALL.md) 的步骤准备环境
+2.若类似为:
+```shell
+error: implicitly-declared 'constexpr rocksdb::FileDescriptor::FileDescriptor(const rocksdb::FileDescriptor&)' is deprecated [-Werror=deprecated-copy]
```
-./output/bin/pika -c ./conf/pika.conf
-```
-
-## Performance
+可以修改tools/pika_migrate/third/rocksdb目录下的makefile:
WARNING_FLAGS = -Wno-missing-field-initializers
+-Wno-unused-parameter
-More details on [Performance](https://github.com/Qihoo360/pika/wiki/3.2.x-Performance).
+## 迁移步骤
+1. 在 PIKA 主库上执行如下命令,让 PIKA 主库保留10000个 binlog 文件。
-## Documents
-
-1. [Wiki](https://github.com/Qihoo360/pika/wiki)
-
-## Contact Us
+```shell
+config set expire-logs-nums 10000
+```
-Mail: g-infra@360.cn
+```text
+说明:
+pika-port 将全量数据写入到 Redis 这段时间可能耗时很长,而导致主库原先 binlog 点位被清理。需要在 PIKA 主库上保留10000个 binlog ⽂件,确保后续该⼯具请求增量同步的时候,对应的 binlog 文件还存在。
+binlog 文件占用磁盘空间,可以根据实际情况确定保留 binlog 的数量。
+```
-QQ group: 294254078
+2. 修改迁移工具的配置文件 pika.conf 中的如下参数。
+ 
+
+ target-redis-host:指定 Redis 的 IP 地址。
+ target-redis-port:指定 Redis 的端口号。
+ target-redis-pwd:指定 Redis 默认账号的密码。
+ sync-batch-num:指定 pika-migrate 接收到主库的 sync-batch-num 个数据⼀起打包发送给 Redis,提升转发效率。
+ redis-sender-num:指定 redis-sender-num 个线程用于转发数据包。转发命令通过 Key 的哈希值将数据分配到不同的线程发送,无需担心多线程发送导致数据错乱的问题。
+3. 在工具包的路径下执行如下命令,启动 pika-migrate 工具,并查看回显信息。
+```shell
+pika -c pika.conf
+```
-For more information about Pika, Atlas and some other technology please pay attention to our Hulk platform official account
+4. 执行如下命令,将迁移工具伪装成 Slave,向主库请求同步,并观察是否有报错信息。
+```shell
+slaveof ip port force
+```
- +5. 确认主从关系建立成功之后,pika-migrate 同时向目标 Redis 转发数据。执行如下命令,查看主从同步延迟。可在主库写入⼀个特殊的 Key,然后在 Redis 侧查看是否可立即获取到该 Key,判断数据同步完毕。
+```shell
+info Replication
+```
diff --git a/tools/pika_migrate/README_CN.md b/tools/pika_migrate/README_CN.md
deleted file mode 100644
index 211a482c5a..0000000000
--- a/tools/pika_migrate/README_CN.md
+++ /dev/null
@@ -1,348 +0,0 @@
-# Pika
-
-## 简介 [English](https://github.com/Qihoo360/pika/blob/master/README.md)
-Pika是一个可持久化的大容量redis存储服务,兼容string、hash、list、zset、set的绝大部分接口([兼容详情](https://github.com/Qihoo360/pika/wiki/pika-支持的redis接口及兼容情况)),解决redis由于存储数据量巨大而导致内存不够用的容量瓶颈,并且可以像redis一样,通过slaveof命令进行主从备份,支持全同步和部分同步,pika还可以用在twemproxy或者codis中来实现静态数据分片(pika已经可以支持codis的动态迁移slot功能,目前在合并到master分支,欢迎使用,感谢作者[left2right](https://github.com/left2right)和[fancy-rabbit](https://github.com/fancy-rabbit)提交的pr)
-
-## Pika用户
-
-
+5. 确认主从关系建立成功之后,pika-migrate 同时向目标 Redis 转发数据。执行如下命令,查看主从同步延迟。可在主库写入⼀个特殊的 Key,然后在 Redis 侧查看是否可立即获取到该 Key,判断数据同步完毕。
+```shell
+info Replication
+```
diff --git a/tools/pika_migrate/README_CN.md b/tools/pika_migrate/README_CN.md
deleted file mode 100644
index 211a482c5a..0000000000
--- a/tools/pika_migrate/README_CN.md
+++ /dev/null
@@ -1,348 +0,0 @@
-# Pika
-
-## 简介 [English](https://github.com/Qihoo360/pika/blob/master/README.md)
-Pika是一个可持久化的大容量redis存储服务,兼容string、hash、list、zset、set的绝大部分接口([兼容详情](https://github.com/Qihoo360/pika/wiki/pika-支持的redis接口及兼容情况)),解决redis由于存储数据量巨大而导致内存不够用的容量瓶颈,并且可以像redis一样,通过slaveof命令进行主从备份,支持全同步和部分同步,pika还可以用在twemproxy或者codis中来实现静态数据分片(pika已经可以支持codis的动态迁移slot功能,目前在合并到master分支,欢迎使用,感谢作者[left2right](https://github.com/left2right)和[fancy-rabbit](https://github.com/fancy-rabbit)提交的pr)
-
-## Pika用户
-
-
-
- |
- |
- |
- |
-
-
- |
- |
- |
- |
-
-
- |
- |
- |
- |
-
-
- |
- |
- |
- |
-
-
- |
- |
- |
- |
-
-
-
-
-[更多](https://github.com/Qihoo360/pika/blob/master/USERS.md)
-
-## 特点
-* 容量大,支持百G数据量的存储
-* 兼容redis,不用修改代码即可平滑从redis迁移到pika
-* 支持主从(slaveof)
-* 完善的[运维](https://github.com/Qihoo360/pika/wiki/pika的一些管理命令方式说明)命令
-
-
-## 使用
-
-### 二进制包使用
-
-用户可以直接从[releases](https://github.com/Qihoo360/pika/releases)下载最新的二进制版本包直接使用.
-
-### 编译使用
-
-1.在编译机上安装snappy,glog,CentOS系统可以用yum安装,Ubuntu可以用apt-get安装。如是CentOS系统,执行如下命令:
-
-```
- yum install snappy-devel glog-devel
-```
-
-2.安装g++(若没有安装), 在CentOS上执行如下命令:
-
-```
- yum install gcc-c++
-```
-
-3.把gcc版本临时切换到4.8(若已是,则忽略), 在CentOs上执行如下命令:
-
-```
- a. sudo wget http://people.centos.org/tru/devtools-2/devtools-2.repo -O /etc/yum.repos.d/devtools-2.repo
- b. sudo yum install -y devtoolset-2-gcc devtoolset-2-binutils devtoolset-2-gcc-c++
- c. scl enable devtoolset-2 bash
-```
-4.获取源代码
-
-```
- git clone https://github.com/Qihoo360/pika.git && cd pika
-```
-5.切换到最新release版本
-
-```
- a. 执行 git tag 查看最新的release tag,(如 v2.2.5)
- b. 执行 git checkout TAG切换到最新版本,(如 git checkout v2.2.5)
-```
-
-6.编译
-
-```
- make
-```
-
-若编译过程中,提示有依赖的库没有安装,则有提示安装后再重新编译
-
-**注:我们推荐使用TCMalloc来进行内存管理**
-
-## 使用
-```
- ./output/bin/pika -c ./conf/pika.conf
-```
-
-## 清空编译
-
-```
- 如果需要清空编译内容,视不同情况使用一下两种方法其一:
-
- 1. 执行make clean来清空pika的编译内容
- 2. 执行make distclean来清空pika及所有依赖的编译内容(一般用于彻底重新编译)
-```
-
-## 性能 (感谢[deep011](https://github.com/deep011)提供性能测试结果)
-### 注!!!
-本测试结果是在特定环境特定场景下得出的,不能够代表所有环境及场景下的表现,__仅供参考__。
-
-__推荐大家在使用pika前在自己的环境根据自己的使用场景详细测试以评估pika是否满足要求__
-
-### 测试环境
-
-**CPU型号**:Intel(R) Xeon(R) CPU E5-2690 v4 @ 2.60GHz
-
-**CPU线程数**:56
-
-**MEMORY**:256G
-
-**DISK**:3T flash
-
-**NETWORK**:10GBase-T/Full * 2
-
-**OS**:centos 6.6
-
-**Pika版本**:2.2.4
-
-### 压测工具
-
-[**vire-benchmark**](https://deep011.github.io/vire-benchmark)
-
-### 测试一
-
-#### 测试目的
-
-测试在pika不同worker线程数量下,其QPS上限。
-
-#### 测试条件
-
-pika数据容量:800G
-
-value:128字节
-
-CPU未绑定
-
-#### 测试结果
-
-说明:横轴Pika线程数,纵轴QPS,value为128字节。set3/get7代表30%的set和70%的get。
-
-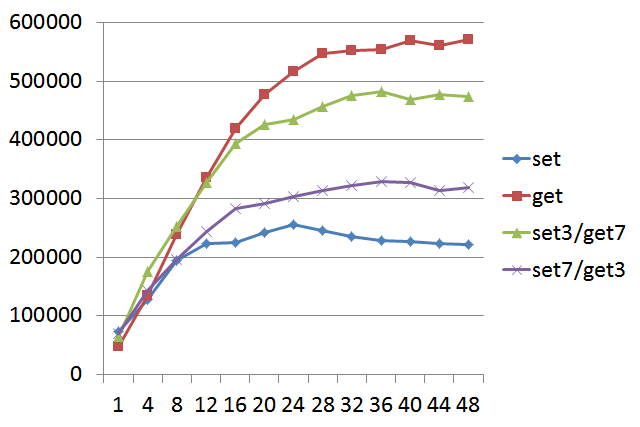 -
-#### 结论
-
-从以上测试图可以看出,pika的worker线程数设置为20-24比较划算。
-
-### 测试二
-
-#### 测试目的
-
-测试在最佳worker线程数(20线程)下,pika的rtt表现。
-
-#### 测试条件
-
-**pika数据容量**:800G
-
-**value**:128字节
-
-#### 测试结果
-
-```c
-====== GET ======
- 10000000 requests completed in 23.10 seconds
- 200 parallel clients
- 3 bytes payload
- keep alive: 1
-99.89% <= 1 milliseconds
-100.00% <= 2 milliseconds
-100.00% <= 3 milliseconds
-100.00% <= 5 milliseconds
-100.00% <= 6 milliseconds
-100.00% <= 7 milliseconds
-100.00% <= 7 milliseconds
-432862.97 requests per second
-```
-
-```c
-====== SET ======
- 10000000 requests completed in 36.15 seconds
- 200 parallel clients
- 3 bytes payload
- keep alive: 1
-91.97% <= 1 milliseconds
-99.98% <= 2 milliseconds
-99.98% <= 3 milliseconds
-99.98% <= 4 milliseconds
-99.98% <= 5 milliseconds
-99.98% <= 6 milliseconds
-99.98% <= 7 milliseconds
-99.98% <= 9 milliseconds
-99.98% <= 10 milliseconds
-99.98% <= 11 milliseconds
-99.98% <= 12 milliseconds
-99.98% <= 13 milliseconds
-99.98% <= 16 milliseconds
-99.98% <= 18 milliseconds
-99.99% <= 19 milliseconds
-99.99% <= 23 milliseconds
-99.99% <= 24 milliseconds
-99.99% <= 25 milliseconds
-99.99% <= 27 milliseconds
-99.99% <= 28 milliseconds
-99.99% <= 34 milliseconds
-99.99% <= 37 milliseconds
-99.99% <= 39 milliseconds
-99.99% <= 40 milliseconds
-99.99% <= 46 milliseconds
-99.99% <= 48 milliseconds
-99.99% <= 49 milliseconds
-99.99% <= 50 milliseconds
-99.99% <= 51 milliseconds
-99.99% <= 52 milliseconds
-99.99% <= 61 milliseconds
-99.99% <= 63 milliseconds
-99.99% <= 72 milliseconds
-99.99% <= 73 milliseconds
-99.99% <= 74 milliseconds
-99.99% <= 76 milliseconds
-99.99% <= 83 milliseconds
-99.99% <= 84 milliseconds
-99.99% <= 88 milliseconds
-99.99% <= 89 milliseconds
-99.99% <= 133 milliseconds
-99.99% <= 134 milliseconds
-99.99% <= 146 milliseconds
-99.99% <= 147 milliseconds
-100.00% <= 203 milliseconds
-100.00% <= 204 milliseconds
-100.00% <= 208 milliseconds
-100.00% <= 217 milliseconds
-100.00% <= 218 milliseconds
-100.00% <= 219 milliseconds
-100.00% <= 220 milliseconds
-100.00% <= 229 milliseconds
-100.00% <= 229 milliseconds
-276617.50 requests per second
-```
-
-#### 结论
-
-get/set 响应时间 99.9%都在2ms以内。
-
-### 测试三
-
-#### 测试目的
-
-在pika最佳的worker线程数下,查看各命令的极限QPS。
-
-#### 测试条件
-
-**pika的worker线程数**:20
-
-**key数量**:10000
-
-**field数量**:100(list除外)
-
-**value**:128字节
-
-**命令执行次数**:1000万(lrange除外)
-
-#### 测试结果
-
-```c
-PING_INLINE: 548606.50 requests per second
-PING_BULK: 544573.31 requests per second
-SET: 231830.31 requests per second
-GET: 512163.91 requests per second
-INCR: 230861.56 requests per second
-MSET (10 keys): 94991.12 requests per second
-LPUSH: 196093.81 requests per second
-RPUSH: 195186.69 requests per second
-LPOP: 131156.14 requests per second
-RPOP: 152292.77 requests per second
-LPUSH (needed to benchmark LRANGE): 196734.20 requests per second
-LRANGE_10 (first 10 elements): 334448.16 requests per second
-LRANGE_100 (first 100 elements): 50705.12 requests per second
-LRANGE_300 (first 300 elements): 16745.16 requests per second
-LRANGE_450 (first 450 elements): 6787.94 requests per second
-LRANGE_600 (first 600 elements): 3170.38 requests per second
-SADD: 160885.52 requests per second
-SPOP: 128920.80 requests per second
-HSET: 180209.41 requests per second
-HINCRBY: 153364.81 requests per second
-HINCRBYFLOAT: 141095.47 requests per second
-HGET: 506791.00 requests per second
-HMSET (10 fields): 27777.31 requests per second
-HMGET (10 fields): 38998.52 requests per second
-HGETALL: 109059.58 requests per second
-ZADD: 120583.62 requests per second
-ZREM: 161689.33 requests per second
-PFADD: 6153.47 requests per second
-PFCOUNT: 28312.57 requests per second
-PFADD (needed to benchmark PFMERGE): 6166.37 requests per second
-PFMERGE: 6007.09 requests per second
-```
-
-#### 结论
-
-整体表现很不错,个别命令表现较弱(LRANGE,PFADD,PFMERGE)。
-
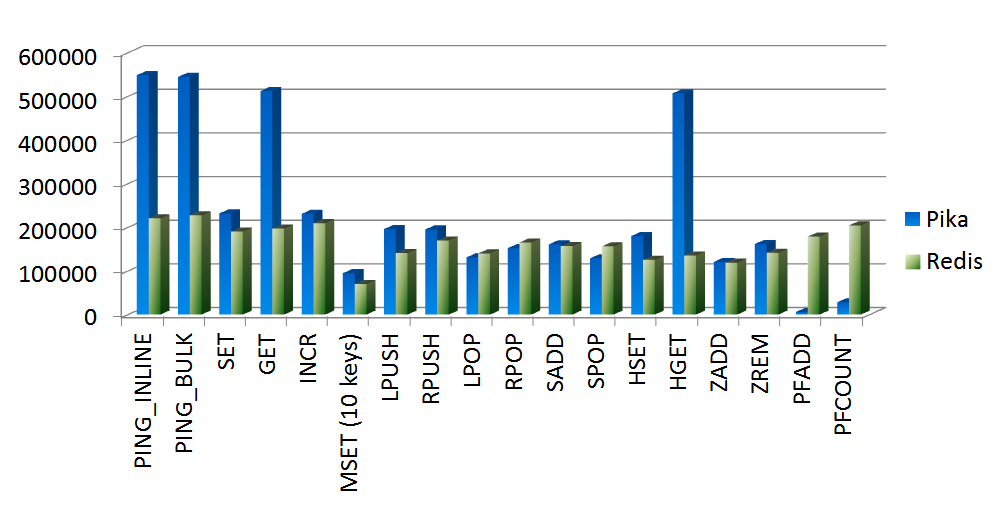
-### 测试四
-
-#### 测试目的
-
-Pika与Redis的极限QPS对比。
-
-#### 测试条件
-
-**pika的worker线程数**:20
-
-**key数量**:10000
-
-**field数量**:100(list除外)
-
-**value**:128字节
-
-**命令执行次数**:1000万(lrange除外)
-
-**Redis版本**:3.2.0
-
-#### 测试结果
-
-
-
-#### 结论
-
-从以上测试图可以看出,pika的worker线程数设置为20-24比较划算。
-
-### 测试二
-
-#### 测试目的
-
-测试在最佳worker线程数(20线程)下,pika的rtt表现。
-
-#### 测试条件
-
-**pika数据容量**:800G
-
-**value**:128字节
-
-#### 测试结果
-
-```c
-====== GET ======
- 10000000 requests completed in 23.10 seconds
- 200 parallel clients
- 3 bytes payload
- keep alive: 1
-99.89% <= 1 milliseconds
-100.00% <= 2 milliseconds
-100.00% <= 3 milliseconds
-100.00% <= 5 milliseconds
-100.00% <= 6 milliseconds
-100.00% <= 7 milliseconds
-100.00% <= 7 milliseconds
-432862.97 requests per second
-```
-
-```c
-====== SET ======
- 10000000 requests completed in 36.15 seconds
- 200 parallel clients
- 3 bytes payload
- keep alive: 1
-91.97% <= 1 milliseconds
-99.98% <= 2 milliseconds
-99.98% <= 3 milliseconds
-99.98% <= 4 milliseconds
-99.98% <= 5 milliseconds
-99.98% <= 6 milliseconds
-99.98% <= 7 milliseconds
-99.98% <= 9 milliseconds
-99.98% <= 10 milliseconds
-99.98% <= 11 milliseconds
-99.98% <= 12 milliseconds
-99.98% <= 13 milliseconds
-99.98% <= 16 milliseconds
-99.98% <= 18 milliseconds
-99.99% <= 19 milliseconds
-99.99% <= 23 milliseconds
-99.99% <= 24 milliseconds
-99.99% <= 25 milliseconds
-99.99% <= 27 milliseconds
-99.99% <= 28 milliseconds
-99.99% <= 34 milliseconds
-99.99% <= 37 milliseconds
-99.99% <= 39 milliseconds
-99.99% <= 40 milliseconds
-99.99% <= 46 milliseconds
-99.99% <= 48 milliseconds
-99.99% <= 49 milliseconds
-99.99% <= 50 milliseconds
-99.99% <= 51 milliseconds
-99.99% <= 52 milliseconds
-99.99% <= 61 milliseconds
-99.99% <= 63 milliseconds
-99.99% <= 72 milliseconds
-99.99% <= 73 milliseconds
-99.99% <= 74 milliseconds
-99.99% <= 76 milliseconds
-99.99% <= 83 milliseconds
-99.99% <= 84 milliseconds
-99.99% <= 88 milliseconds
-99.99% <= 89 milliseconds
-99.99% <= 133 milliseconds
-99.99% <= 134 milliseconds
-99.99% <= 146 milliseconds
-99.99% <= 147 milliseconds
-100.00% <= 203 milliseconds
-100.00% <= 204 milliseconds
-100.00% <= 208 milliseconds
-100.00% <= 217 milliseconds
-100.00% <= 218 milliseconds
-100.00% <= 219 milliseconds
-100.00% <= 220 milliseconds
-100.00% <= 229 milliseconds
-100.00% <= 229 milliseconds
-276617.50 requests per second
-```
-
-#### 结论
-
-get/set 响应时间 99.9%都在2ms以内。
-
-### 测试三
-
-#### 测试目的
-
-在pika最佳的worker线程数下,查看各命令的极限QPS。
-
-#### 测试条件
-
-**pika的worker线程数**:20
-
-**key数量**:10000
-
-**field数量**:100(list除外)
-
-**value**:128字节
-
-**命令执行次数**:1000万(lrange除外)
-
-#### 测试结果
-
-```c
-PING_INLINE: 548606.50 requests per second
-PING_BULK: 544573.31 requests per second
-SET: 231830.31 requests per second
-GET: 512163.91 requests per second
-INCR: 230861.56 requests per second
-MSET (10 keys): 94991.12 requests per second
-LPUSH: 196093.81 requests per second
-RPUSH: 195186.69 requests per second
-LPOP: 131156.14 requests per second
-RPOP: 152292.77 requests per second
-LPUSH (needed to benchmark LRANGE): 196734.20 requests per second
-LRANGE_10 (first 10 elements): 334448.16 requests per second
-LRANGE_100 (first 100 elements): 50705.12 requests per second
-LRANGE_300 (first 300 elements): 16745.16 requests per second
-LRANGE_450 (first 450 elements): 6787.94 requests per second
-LRANGE_600 (first 600 elements): 3170.38 requests per second
-SADD: 160885.52 requests per second
-SPOP: 128920.80 requests per second
-HSET: 180209.41 requests per second
-HINCRBY: 153364.81 requests per second
-HINCRBYFLOAT: 141095.47 requests per second
-HGET: 506791.00 requests per second
-HMSET (10 fields): 27777.31 requests per second
-HMGET (10 fields): 38998.52 requests per second
-HGETALL: 109059.58 requests per second
-ZADD: 120583.62 requests per second
-ZREM: 161689.33 requests per second
-PFADD: 6153.47 requests per second
-PFCOUNT: 28312.57 requests per second
-PFADD (needed to benchmark PFMERGE): 6166.37 requests per second
-PFMERGE: 6007.09 requests per second
-```
-
-#### 结论
-
-整体表现很不错,个别命令表现较弱(LRANGE,PFADD,PFMERGE)。
-
-### 测试四
-
-#### 测试目的
-
-Pika与Redis的极限QPS对比。
-
-#### 测试条件
-
-**pika的worker线程数**:20
-
-**key数量**:10000
-
-**field数量**:100(list除外)
-
-**value**:128字节
-
-**命令执行次数**:1000万(lrange除外)
-
-**Redis版本**:3.2.0
-
-#### 测试结果
-
- -
-## 文档
-1. [Wiki] (https://github.com/Qihoo360/pika/wiki)
-
-## 联系方式
-邮箱:g-infra@360.cn
-
-QQ群:294254078
diff --git a/tools/pika_migrate/USERS.md b/tools/pika_migrate/USERS.md
deleted file mode 100644
index fff9505cb4..0000000000
--- a/tools/pika_migrate/USERS.md
+++ /dev/null
@@ -1,110 +0,0 @@
-## 1. 奇虎360
-
-
-在360, pika已替换几乎全部的Redis大容量实例和所有的SSDB,目前已有1000+实例,每天访问量900亿,存储容量18T,折合内存大致54T
-
-## 2. 新浪微博
-
-
-使用场景:
-1. 上文件存储集群,有文件标识id.
-2. 搜索会有一些用户属性特征pika作为存储物料库之一
-3. 后台发垃圾过滤, 作为反spam
-
-已上线
-
-## 3. Garena
-
-
-使用场景:
-1. 用在Timeline功能,读写比4:1,数据量100G多, QPS 几万
-2. 电商平台推荐功能
-
-## 4. Apus
-
-已上线
-
-## 5. 飞凡电商
-
-
-作为线上Redis海量数据的离线备份
-
-## 6. 美团网
-
-
-
-1. 大数据,推送业务(已上线)
-2. 使用Pika 的引擎nemo 为内部的nosql 提供多数据结构接口(测试中, 准备上线)
-
-## 7. 学而思网校
-
-
-数据持久化存储(已上线)
-
-## 8. 环信
-
-用于存储推送中的离线数据消息
-
-## 9. 迅雷
-
-
-用户存储个性化推荐数据, 目前使用15台机器
-
-已上线
-
-## 10. 高伟达
-
-
-记录移动终端设备访问记录,标记活跃状态
-
-已上线
-
-## 11. 第一弹
-
-
-已上线
-
-## 12. 亿玛科技
-
-
-已上线
-
-## 13. 小米
-
-
-已上线
-
-## 14. 58同城
-
-
-已上线
-
-## 15. 360游戏
-
-
-## 文档
-1. [Wiki] (https://github.com/Qihoo360/pika/wiki)
-
-## 联系方式
-邮箱:g-infra@360.cn
-
-QQ群:294254078
diff --git a/tools/pika_migrate/USERS.md b/tools/pika_migrate/USERS.md
deleted file mode 100644
index fff9505cb4..0000000000
--- a/tools/pika_migrate/USERS.md
+++ /dev/null
@@ -1,110 +0,0 @@
-## 1. 奇虎360
-
-
-在360, pika已替换几乎全部的Redis大容量实例和所有的SSDB,目前已有1000+实例,每天访问量900亿,存储容量18T,折合内存大致54T
-
-## 2. 新浪微博
-
-
-使用场景:
-1. 上文件存储集群,有文件标识id.
-2. 搜索会有一些用户属性特征pika作为存储物料库之一
-3. 后台发垃圾过滤, 作为反spam
-
-已上线
-
-## 3. Garena
-
-
-使用场景:
-1. 用在Timeline功能,读写比4:1,数据量100G多, QPS 几万
-2. 电商平台推荐功能
-
-## 4. Apus
-
-已上线
-
-## 5. 飞凡电商
-
-
-作为线上Redis海量数据的离线备份
-
-## 6. 美团网
-
-
-
-1. 大数据,推送业务(已上线)
-2. 使用Pika 的引擎nemo 为内部的nosql 提供多数据结构接口(测试中, 准备上线)
-
-## 7. 学而思网校
-
-
-数据持久化存储(已上线)
-
-## 8. 环信
-
-用于存储推送中的离线数据消息
-
-## 9. 迅雷
-
-
-用户存储个性化推荐数据, 目前使用15台机器
-
-已上线
-
-## 10. 高伟达
-
-
-记录移动终端设备访问记录,标记活跃状态
-
-已上线
-
-## 11. 第一弹
-
-
-已上线
-
-## 12. 亿玛科技
-
-
-已上线
-
-## 13. 小米
-
-
-已上线
-
-## 14. 58同城
-
-
-已上线
-
-## 15. 360游戏
- -
-360游戏已全面完成SSDB到pika的替换
-
-## 15. 猎豹移动
-
-
-360游戏已全面完成SSDB到pika的替换
-
-## 15. 猎豹移动
- -
-用于大量页面数据、离线用户计算数据的存放
-
-## 16. 铭师堂教育
-
-
-Venus平台已经上线pika+QConf,其他系统在陆续上线中
-
-## 17. 脉脉
-
-
-用于大量页面数据、离线用户计算数据的存放
-
-## 16. 铭师堂教育
-
-
-Venus平台已经上线pika+QConf,其他系统在陆续上线中
-
-## 17. 脉脉
- -
-已上线
-
-## 18. 唯品会
-
-
-已上线
-
-## 19. 路况交通眼
-
-
-已上线,存储路况信息
diff --git a/tools/pika_migrate/img.png b/tools/pika_migrate/img.png
new file mode 100644
index 0000000000..756bfa2948
Binary files /dev/null and b/tools/pika_migrate/img.png differ
diff --git a/tools/pika_migrate/pika-migrate.md b/tools/pika_migrate/pika-migrate.md
deleted file mode 100644
index 8ea696af50..0000000000
--- a/tools/pika_migrate/pika-migrate.md
+++ /dev/null
@@ -1,43 +0,0 @@
-## Pika3.2到Redis迁移工具
-
-### 适用版本:
-Pika 3.2.0及以上, 单机模式且只使用了单db
-
-### 功能
-将Pika中的数据在线迁移到Pika、Redis(支持全量、增量同步)
-
-### 开发背景:
-之前Pika项目官方提供的pika\_to\_redis工具仅支持离线将Pika的DB中的数据迁移到Pika、Redis, 且无法增量同步, 该工具实际上就是一个特殊的Pika, 只不过成为从库之后, 内部会将从主库获取到的数据转发给Redis,同时并支持增量同步, 实现热迁功能.
-
-### 热迁原理
-1. pika-port通过dbsync请求获取主库当前全量db数据, 以及当前db数据所对应的binlog点位
-2. 获取到主库当前全量db数据之后, 扫描db, 将db中的数据转发给Redis
-3. 通过之前获取的binlog的点位向主库进行增量同步, 在增量同步的过程中, 将从主库获取到的binlog重组成Redis命令, 转发给Redis
-
-### 新增配置项
-```cpp
-###################
-## Migrate Settings
-###################
-
-target-redis-host : 127.0.0.1
-target-redis-port : 6379
-target-redis-pwd : abc
-
-sync-batch-num : 100
-redis-sender-num : 10
-```
-
-### 步骤
-1. 考虑到在pika-port在将全量数据写入到Redis这段时间可能耗时很长, 导致主库原先binlog点位已经被清理, 我们首先在主库上执行`config set expire-logs-nums 10000`, 让主库保留10000个Binlog文件(Binlog文件占用磁盘空间, 可以根据实际情况确定保留binlog的数量), 确保后续该工具请求增量同步的时候, 对应的Binlog文件还存在.
-2. 修改该工具配置文件的`target-redis-host, target-redis-port, target-redis-pwd, sync-batch-num, redis-sender-num`配置项(`sync-batch-num`是该工具接收到主库的全量数据之后, 为了提升转发效率, 将`sync-batch-num`个数据一起打包发送给Redis, 此外该工具内部可以指定`redis-sender-num`个线程用于转发命令, 命令通过Key的哈希值被分配到不同的线程中, 所以无需担心多线程发送导致的数据错乱的问题)
-3. 使用`pika -c pika.conf`命令启动该工具, 查看日志是否有报错信息
-4. 向该工具执行`slaveof ip port force`向主库请求同步, 观察是否有报错信息
-5. 在确认主从关系建立成功之后(此时pika-port同时也在向目标Redis转发数据了)通过向主库执行`info Replication`查看主从同步延迟(可在主库写入一个特殊的Key, 然后看在Redis测是否可以立马获取到, 来判断是否数据已经基本同步完毕)
-
-### 注意事项
-1. Pika支持不同数据结构采用同名Key, 但是Redis不支持, 所以在有同Key数据的场景下, 以第一个迁移到Redis数据结构为准, 其他同Key数据结构会丢失
-2. 该工具只支持热迁移单机模式下, 并且只采用单DB版本的Pika, 如果是集群模式, 或者是多DB场景, 工具会报错并且退出.
-3. 为了避免由于主库Binlog被清理导致该工具触发多次全量同步向Redis写入脏数据, 工具自身做了保护, 在第二次触发全量同步时会报错退出.
-
-
-
-已上线
-
-## 18. 唯品会
-
-
-已上线
-
-## 19. 路况交通眼
-
-
-已上线,存储路况信息
diff --git a/tools/pika_migrate/img.png b/tools/pika_migrate/img.png
new file mode 100644
index 0000000000..756bfa2948
Binary files /dev/null and b/tools/pika_migrate/img.png differ
diff --git a/tools/pika_migrate/pika-migrate.md b/tools/pika_migrate/pika-migrate.md
deleted file mode 100644
index 8ea696af50..0000000000
--- a/tools/pika_migrate/pika-migrate.md
+++ /dev/null
@@ -1,43 +0,0 @@
-## Pika3.2到Redis迁移工具
-
-### 适用版本:
-Pika 3.2.0及以上, 单机模式且只使用了单db
-
-### 功能
-将Pika中的数据在线迁移到Pika、Redis(支持全量、增量同步)
-
-### 开发背景:
-之前Pika项目官方提供的pika\_to\_redis工具仅支持离线将Pika的DB中的数据迁移到Pika、Redis, 且无法增量同步, 该工具实际上就是一个特殊的Pika, 只不过成为从库之后, 内部会将从主库获取到的数据转发给Redis,同时并支持增量同步, 实现热迁功能.
-
-### 热迁原理
-1. pika-port通过dbsync请求获取主库当前全量db数据, 以及当前db数据所对应的binlog点位
-2. 获取到主库当前全量db数据之后, 扫描db, 将db中的数据转发给Redis
-3. 通过之前获取的binlog的点位向主库进行增量同步, 在增量同步的过程中, 将从主库获取到的binlog重组成Redis命令, 转发给Redis
-
-### 新增配置项
-```cpp
-###################
-## Migrate Settings
-###################
-
-target-redis-host : 127.0.0.1
-target-redis-port : 6379
-target-redis-pwd : abc
-
-sync-batch-num : 100
-redis-sender-num : 10
-```
-
-### 步骤
-1. 考虑到在pika-port在将全量数据写入到Redis这段时间可能耗时很长, 导致主库原先binlog点位已经被清理, 我们首先在主库上执行`config set expire-logs-nums 10000`, 让主库保留10000个Binlog文件(Binlog文件占用磁盘空间, 可以根据实际情况确定保留binlog的数量), 确保后续该工具请求增量同步的时候, 对应的Binlog文件还存在.
-2. 修改该工具配置文件的`target-redis-host, target-redis-port, target-redis-pwd, sync-batch-num, redis-sender-num`配置项(`sync-batch-num`是该工具接收到主库的全量数据之后, 为了提升转发效率, 将`sync-batch-num`个数据一起打包发送给Redis, 此外该工具内部可以指定`redis-sender-num`个线程用于转发命令, 命令通过Key的哈希值被分配到不同的线程中, 所以无需担心多线程发送导致的数据错乱的问题)
-3. 使用`pika -c pika.conf`命令启动该工具, 查看日志是否有报错信息
-4. 向该工具执行`slaveof ip port force`向主库请求同步, 观察是否有报错信息
-5. 在确认主从关系建立成功之后(此时pika-port同时也在向目标Redis转发数据了)通过向主库执行`info Replication`查看主从同步延迟(可在主库写入一个特殊的Key, 然后看在Redis测是否可以立马获取到, 来判断是否数据已经基本同步完毕)
-
-### 注意事项
-1. Pika支持不同数据结构采用同名Key, 但是Redis不支持, 所以在有同Key数据的场景下, 以第一个迁移到Redis数据结构为准, 其他同Key数据结构会丢失
-2. 该工具只支持热迁移单机模式下, 并且只采用单DB版本的Pika, 如果是集群模式, 或者是多DB场景, 工具会报错并且退出.
-3. 为了避免由于主库Binlog被清理导致该工具触发多次全量同步向Redis写入脏数据, 工具自身做了保护, 在第二次触发全量同步时会报错退出.
-
-