Pawn promotion issues in T40 #784
Comments
|
See below I parsed some sample pgns from training for T40, T30, and T50. Is 3.0-3.6% too low? Or it's not too low, but there are not enough examples in training for the net to care? Or the Policy head architecture makes it too hard to learn this? |
|
A different type but probably same underlying problem position in #750 is when promoting to queen is not the best move (in particular queen = stalemate, others winning):
|

|
Another example where Leela Lc0v0.21-RC2 41356 running on GTX 1070 Ti, threw a draw by playing 33.Qa8+??(in the following game) and she has played this move because she didn't even consider that (the obvious!) Queen promotion 35...e1Q wins in the following position: She should have considered the Queen promotion instantly as any other promotion with capture loses the Queen. Lc0v0.21-RC2 41356 analysis from PGN of the game: PGN of the game: |
|
BTW here is my code, instructions not included. :) |
Plies : 24424424 I think 1 in 8047 is not so rare it can't learn? But probably many of these cases are still "not interesting" because e.g. the game is over and it doesn't matter. But it requires more parsing of the position and maybe feeding to Stockfish to find cases where the decision really matters. Or taking these examples and sending them to the current NN to see if it finds those specific examples but doesn't generalize to unseen examples. |
|
5 examples of the promotion bug can be found in the attached PGN. For example, in game 5: E.g.: 4r3/1kp4p/1n1prPp1/p5P1/2PRN3/P2Q4/K2R4/6q1 b - -
In the 4th game of the PGN, as early as move 13 leela goes wrong. After 13.h5 Leela plays 13. b6??? b/c she doesn't even see the promotion idea. SF immediately jumps eval and wins soon after. Leela doesn't realize the blunder - at all - until the queen is actually made! E.g., in the diagram below, SF plays 15. Qxg8+ and is at +5 and - but leela thinks -17 after Nxg8! Game continues Nxg8 h7 Nce7 h8=Q and only now, after the queen is made, does she jump to +14. She doesn't even consider the promotion until after Queen is made.
FEN of the position after 16. h7: |


|
I've modified 41452 by reducing Policy channel 33. The nets are called hack2, hack4, hack8, for channel 33 being reduced 2X, 4X, 8X. I tested the position in the OP: By the time you get to 8X, the capture-promote move is down to 14.9%. I didn't list other moves, but they go up as well. So 8X might cause a too-wide search. Maybe 4X is best. See below channel 33 is abnormally large output. The Policy FC layer uses the huge 359 number at a1 to increase Policy of a2b1q and reduce Policy of a2a1q: Final result: Hacked nets here: Technical implementation note: Instead of dividing gamma for channel 33, I divided all weights in the FC layer that take channel 33 as an input. Just because I had code to modify the FC layer but not the gamma layer. |
|
what do the elo tests say? |
|
I tested all 5 of the promo bug losses in my PGN against the "hack8" version - leela saw all the right moves and didn't make the same mistakes. I.e., the fix worked. I didn't test hack2 or hack4 but jhorthos tested all 3 against base and hack8 scored the highest elo. I will now test 41452-hack8 in my standard 100 game rapid match and compare against the bugged 41452 result. The bugged version lost at least 4 games to the promo bug - so if its fixed without negatively impacting elsewhere, hack8 should score better. Will report back. |
|
Finished the comparison of 41452_hack8 to regular 41452, both against SF_10: RTX 2080 & 6 core i7 6800k Score of lc0_41452_h8 vs SF_10: +35 -15 =50 [0.600] 100 Score of lc0_41452 vs SF_10: +28 -20 =52 [0.540] 100 Some 43 Elo points improvement from hack8. Error margins are still large, but the result is much outside one standard deviation difference. |
|
Final score of the non-hack version: Of these, EIGHT losses were from the promo bug. see attached PGN for all 8 losses. Now re-running the match with the hack8 version |
|
Quoting jio aka ttl from Discord:
|
|
Test complete - final score: Lc0.21.0-rc2.pr784.hack8.41452 - Stockfish_10_x64_bmi2 : 48.5/100 19-22-59 (=====0=110=0=====0=0==0=001=====01==101=0==0==0===111===1111=0==1=1======0=0100=100==0======10====1=) 49% -> 3455 ordo score And improvement of "1.5" points / 100. Not overly significant BUT there were no promo blunders and the score is better, so at the least I don't think the change hurts the net. Others show similar results. |
|
I did some supervised tests starting from 41498 network and training from the latest T40 data to check how this issue could be solved. The base 41498 network had 99.8% policy for capture on the position in the first post with Training 500 steps with the default training parameters resulted in a net with the same 99.8% policy. Training with default parameters, but with gamma regularization from the same net had the same 99.8% policy in the test position at 500 steps. Removing the virtual_batch_size and enabling batch renormalization with The reason I suspect issue with batch norm statistics more than issue with batch norm gammas is that SE-units are after batch normalization and they have ability to zero any of the output channels. In training batch norm uses statistics from the current batch to normalize it, while in testing/play it uses moving averages of the training statistics. Currently the training code calculates the batch norm statistics using ghost batch norm of 64 positions. If one channel is often zeroed out it will be normalized to batch statistic during training, but in testing/play moving averages are used instead. If the channel is rarely activated the moving variance will be very low since the output is often zeroed and it will be multiplied with very large value in testing/play to get it to unit variance which causes the observed issue. |
|
For reference, the Batch Renormalization paper: https://arxiv.org/abs/1702.03275 |
|
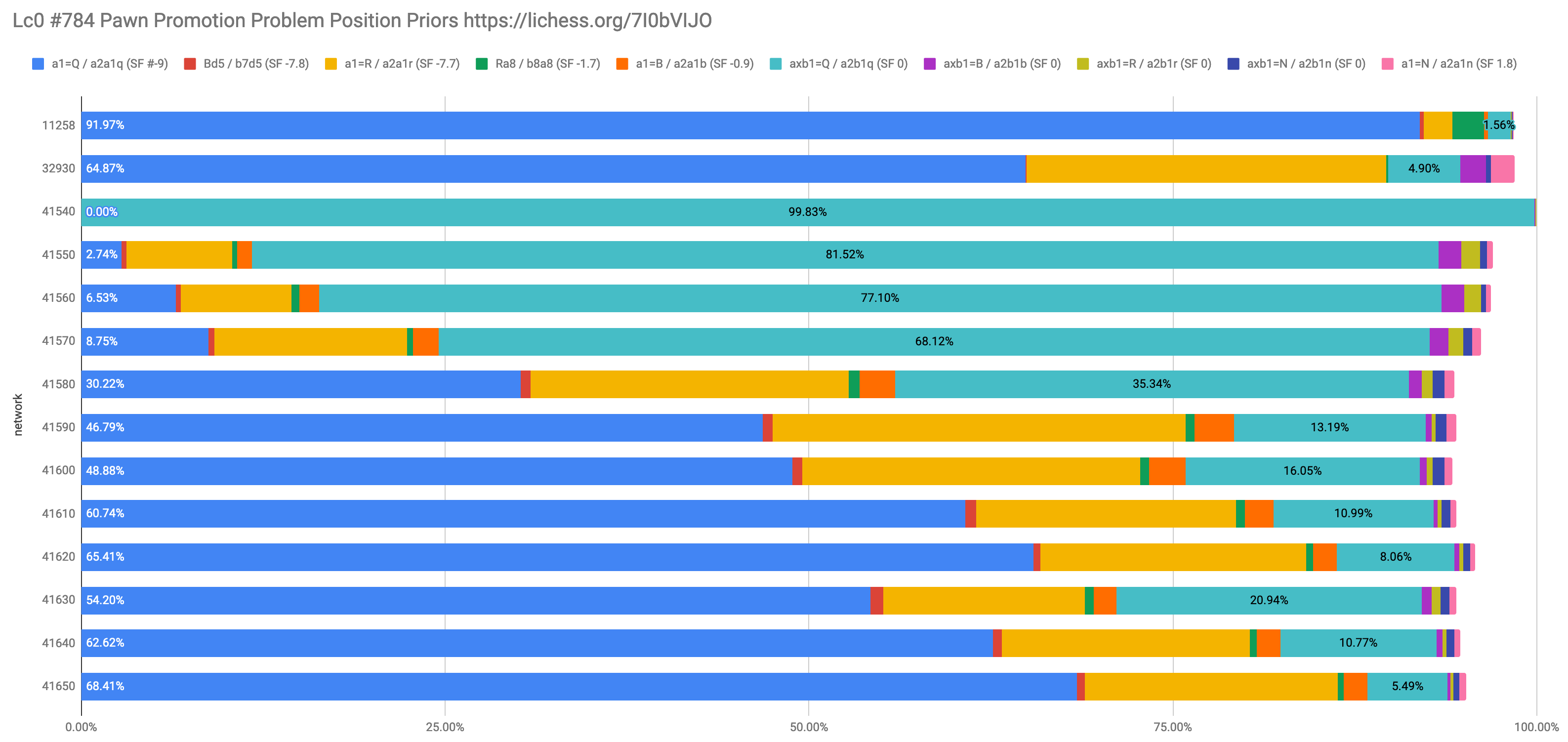
Looks like something good got in the training window (or something got pushed out?)… starting from 41581 now has the top prior move as the winning move and keeps increasing for 41590 but slows down for 41600… and keeps going!
|
|
Things are going in the right direction. |
T40 tends to put too much Policy on capture+promote (axb1=Q) and not enough Policy on simple push to promote (a1=Q, ignoring the possibility of capturing). Usually this is correct, but in some cases not capturing is correct. Other net series do not have this problem.
Here is an example position and Policy of the wrong move for several T40 nets. It quickly moves to near 100% even before the first LR drop.
https://lichess.org/7I0bVIJO#95
The text was updated successfully, but these errors were encountered: