一、说明
对官方文档进行翻译工作
网站标题:dataview 官方文档
网站地址:https://blacksmithgu.github.io/obsidian-dataview/docs/intro
网站说明:
入门介绍
Dataview 是一个在你的知识库中生成数据的动态视图的高级查询引擎 / 索引。你可以通过使用任意和页面相关联的值,如标签 (tag),文件夹(folder), 内容(content),或者字段(field) 来生成视图。一个使用 dataview 的页面一般像这样:
# 每天回顾
# 每天
日期:: 2020-08-15
评级:: 7.5
起床:: 10:30am
睡觉:: 12:30am如果你有许多这样的页面,你可以通过下述代码轻松的创建一个表格:
```dataview
table 日期, 评级, 起床, 睡觉 from #每天
```这将会生成一个像这样好看的表格:
你还可以通过过滤这个视图,仅展示高评分 (rating) 的一天;或者按评分对每天进行排序,亦或者按醒来的时间进行排序,诸如此类。
页面和字段
dataview 的核心数据抽象是页面 (page) ,指在你的库中包含字段 (field) 的 markdwon 页面。字段 是一段任意命名的数据 ——文本,日期,时间段,链接。 这些可被 dataview 理解,展示,筛选。字段可以通过三种方式定义:
- 扉页 (Frontmatter): 所有的 YAML 扉页内容都将自动的转换成 dataview 字段。
- 内联字段 (inline field): 一行格式为
<Name>:: <Value>的内容将自动的被 dataview 解析为一个字段,请注意,你可以对<Name>使用标准的 Markdown 格式,但以后将不再支持。 - 隐含字段 (implicit): dataview 自带大量的元数据对页面进行注释,如文件的创建日期、任何相关的日期、文件中的链接、标签等。
用前两种方法创建的一个有相关字段的示例页面如下:
---
duration: 4 hours
reviewed: false
---
# Movie X
**Thoughts**:: It was decent.
**Rating**:: 6字段类型
dataview 支持数种不同的字段类型:
- 文本 (Text): 全局默认为文本。如果一个字段不匹配其它具体的类型,默认为一段纯文本。
- 数字 (Number): 数字类似于'6' 和 '3.6'。
- 布尔值 (Boolean): true/false, 就像编程中的概念。
- 日期 (Date): ISO8601 标准定义的通用日期格式
YYYY-MM[-DDTHH:mm:ss]. 月份后面的内容都是可选的。 - 时间段 (Duration): 时间段的格式为
<time> <unit>, 就像6 hours或者4 minutes。支持常见的英文缩写如6hrs或者2m。 - 链接 (Link): 普通的 Obsidian 链接如
[[Page]]或者[[Page|Page Display]]。 - 列表 (List): YAML 中,其它 dataview 字段组成的列表将作为普通的 YAML 列表定义;对于内联字段,它们就只是逗号分隔的列表。
- 对象 (Object):名称 (name) 到 dataview 字段的映射。这仅能在 YAML 扉页中利用通用的 YANML 对象语法进行定义。 对象语法:
field: value1: 1 value2: 2 ...
不同的字段类型非常重要。这能确保 dataview 理解怎样合理的对值进行比较和排序,并提供不同的操作。
隐含字段
dataview 能自动的对每个页面添加大量的元数据。
file.name: 该文件标题 (字符串)。file.folder: 该文件所在的文件夹的路径 (字符串)。file.path: 该文件的完整路径 (字符串)。file.link: 该文件的一个链接 (链接)。file.size: 该文件的大小 (bytes)(数字)file.ctime: 该文件的创建日期 (日期和时间)。file.cday: 该文件的创建日期 (仅日期)。file.mtime: 该文件最后编辑日期 (日期和时间)。file.mday: 该文件最后编辑日期 (仅日期)。file.tags: 笔记中所有标签组成的数组。子标签按每个级别进行细分,所以#Tag/1/A将会在数组中储存为[#Tag, #Tag/1, #Tag/1/A]。file.etags: 笔记中所有显式标签组成的数组;不同于file.tags,不包含子标签。file.outlinks: 该文件所有外链 (outgoing link) 组成的数组。file.aliases: 笔记中所有别名组成的数组。
如果文件的标题内有一个日期(格式为 yyyy-mm-dd 或 yyyymmdd),或者有一个 Date 字段 / inline 字段,它也有以下属性:
file.day: 一个该文件的隐含日期。
创建查询
一旦你给相关的页面添加了有用的数据,你就可以在某一个地方展示它或者操作它。dataview 通过dataview代码块建立内联查询,写下查询代码,将会动态运行并在笔记的预览窗口展示。写这样的查询,有三种方式:
- dataview 的查询语言是一个用于快速创建视图,简化的,类 SQL 的语言。它支持基本的算术和比较操作,对基础应用很友好。
- 查询语言也提供内联查询,允许你直接在一个页面内嵌入单个值——通过
= date(tody)创建今天的日期,或者通过= [[Page]].value来嵌入另一个页面的字段。 - dataview JavaScript API 为你提供了 JavaScript 的全部功能,并为拉取 Dataview 数据和执行查询提供了 DSL,允许你创建任意复杂的查询和视图。
与 JavaScript API 相比,查询语言的功能往往比较滞后,主要是因为 JavaScript API 更接近实际代码;相反,查询语言更稳定,在 Dataview 的重大更新中不太可能出现故障。
使用查询语言
你可以在任意笔记中使用下列语法创建查询语言代码块:
```dataview
... query ...
```怎样写一个查询的细节在查询语言文档中有详细阐述;如果你更倾向于学习实例,可以参看查询示例。
使用内联查询
你可以通过下列语法创建内联查询:
`= <query language expression>`其中表达式 (expression) 在查询语言和表达式中有阐述。你可以在 dataview 设置中,通过使用不同的前缀 (如dv:或~) 设置内联查询。
使用 JavaScript API
你可以在任意笔记中使用下列语法创建 JS dataview 代码块:
```dataviewjs
... js code ...
```在 JS dataview 代码块里,你可以通过dv变量访问所有 dataview 的 API。关于你能用它做什么,见 API 文档,或 API 实例。
语言查询
查询
dataview 查询语言是一种简单的、结构化的、自定义的查询语言,用于快速创建数据的视图。支持:
- 提取与标签、文件夹、链接等相关的页面。
- 通过对字段的简单操作过滤页面 / 数据,如比较、存在性检查等。
- 根据字段对结果进行排序。
该查询语言支持以下视图类型,描述如下:
- 表格 (TABLE):传统的视图类型;每个数据点为一行,字段数据为一列。
- 列表 (LIST):匹配查询页面的列表。你可以为每个页面输出一个单一的关联值。
- 任务列表 (TASK):匹配给定查询的任务列表。
通用格式
查询的通用格式如下:
```dataview
TABLE|LIST|TASK <field> [AS "Column Name"], <field>, ..., <field> FROM <source> (like #tag or "folder")
WHERE <expression> (like 'field = value')
SORT <expression> [ASC/DESC] (like 'field ASC')
... other data commands
```只有 "select" 语句(描述什么视图和什么字段)是必需的。如果省略了 FROM 语句,会自动查询你在库中的所有 markdown 页面。如果其他语句(如 WHERE 或 SORT)存在,它们将按照顺序运行。重复的语句是允许的(例如,多个 WHERE 语句)。
- 对于不同的视图类型,只有第一行("select" 部分,在这里你指定要显示的视图类型和字段)是不同的。你可以在任何查询中应用数据命令 (data commands) 如WHERE和SORT,你也可以通过使用FROM来选择来源。
### 查询类型
列表查询
列表是最简单的视图,它简单地呈现了一个匹配查询的页面(或自定义字段)的列表。 要获得与查询相匹配的页面的列表,只需使用:
LIST FROM <source>举个例子,运行list from #每天 会呈现:

你可以通过在LIST后面添加一个表达式,在每个匹配的文件之外呈现一个单一的计算值。
LIST <expression> FROM <source>举个例子,运行list "文件:路径" + file.path from #每天 会呈现:

表格查询
表格提供页面数据的表格化视图。你可以通过给出一个逗号分隔的 YAML 字段列表来构建一个表格,像这样:
TABLE file.cday, file.mtime FROM #每天
你可以通过使用AS语法,选择一个标题名称来表示已计算的字段。
TABLE (file.mtime + dur(1 day)) AS next_mtime, ... FROM <source>
一个表格查询的例子:
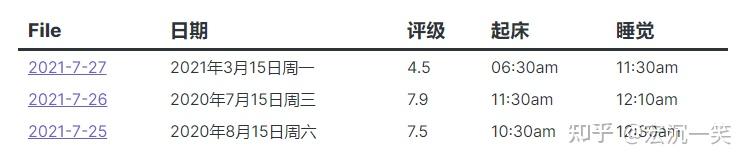
table 日期, 评级, 起床, 睡觉 from #每天
SORT 评级 DESC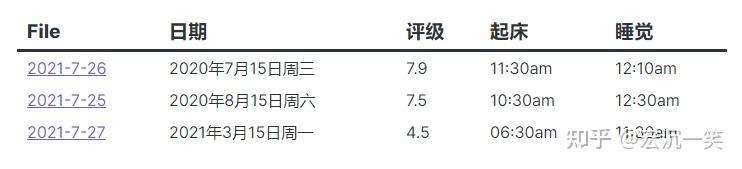
任务列表查询
任务视图呈现所有其页面符合给定谓词的任务。
TASK from <source>举个例子, task from #task会呈现:

数据命令
dataview 查询可以由不同的命令组成。命令是按顺序执行的,你可以有重复的命令(例如,多个WHERE块或多个GROUP BY块)。
FROM
FROM语句决定了哪些页面在初始被收集并传递给其他命令进行进一步的筛选。你可以从任何来源中选择,来源可选择文件夹,标签,内链和外链。
- 标签 (Tags): 从标签 (包含子标签) 中选择,使用
FROM #tag。 - 文件夹 (Folders): 从文件夹 (包含子文件夹) 中选择,使用
FROM "folder"。 - 链接 (Links): 你可以选择一个链接到该文件的链接,也可以选择该文件链接到其它页面的链接:
- 获得链接到
[[note]]的所有页面,使用FROM [[note]]。 - 获得从
[[note]]链接的所有页面 (如,文件中的所有链接),使用FROM outgoing([[note]])。
你可以对过滤器进行组合,以便使用 "and" 和 "or" 获得更高级的来源。 - 举个例子,#tag and "folder"将返回在folder中和包含#tag的所有页面。 - [[Food]] or [[Exercise]] 将给出任何链接到[[Food]]或[[Exercise]]的页面。
WHERE
根据字段过滤页面。只有 clause 计算为 "true" 的页面才会被显示:
WHERE <clause>- 获得所有在最近 24 小时内修改的文件。
LIST WHERE file.mtime >= date(today) - dur(1 day)- 找到所有未标明完成且超过一个月的 project。
LIST FROM #projects
WHERE !completed AND file.ctime <= date(today) - dur(1 month)SORT
按一个或多个字段对所有结果进行排序。
SORT date [ASCENDING/DESCENDING/ASC/DESC]你也可以给出多个字段来进行排序。排序将在第一个字段的基础上进行。接着,如果出现相等,第二个字段将被用来对相等的字段进行排序。如果仍然有相等,将用第三个字段进行排序,以此类推。
SORT field1 [ASCENDING/DESCENDING/ASC/DESC], ..., fieldN [ASC/DESC]GROUP BY
对一个字段的所有结果进行分组。每个唯一的字段值产生一行,它有两个属性:一个对应于被分组的字段,一个是rows数组字段,包含所有匹配的页面。
GROUP BY field
GROUP BY (computed_field) AS name为了使rows数组工作更容易,Dataview 支持字段的 "调配 (swizzling)"。如果你想从rows数组中的每个对象获取test字段,那么rows.test将自动从rows中的每个对象获取test字段,产生一个新的数组。 你可以在产生的数组上应用聚合运算符,如sum()。
FLATTEN
对一个数组的每一行进行扁平化处理,在数组中的每个条目产生一个结果行。
FLATTEN field
FLATTEN (computed_field) AS name例如,将每个文献注释中的 "作者" 字段扁平化处理,使每个作者占一行。
table authors from #LiteratureNote
flatten authors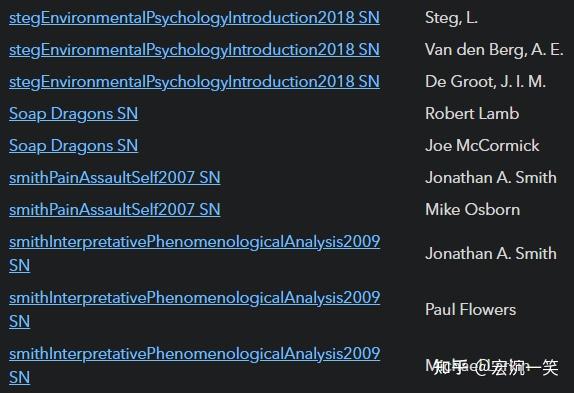
表达式
Dataview 查询语言表达式 可以是任何能产生一个值的量,所有字段都是表达式,字面值如6,已计算的值如field - 9都是一个表达式,做一个更具体的总结:
# 常规
field (directly refer to a field)
simple-field (refer to fields with spaces/punctuation in them like "Simple Field!")
a.b (if a is an object, retrieve field named 'b')
a[expr] (if a is an object or array, retrieve field with name specified by expression 'expr')
f(a, b, ...) (call a function called `f` on arguments a, b, ...)
# 算术运算
a + b (addition)
a - b (subtraction)
a * b (multiplication)
a / b (division)
# 比较运算
a > b (check if a is greater than b)
a < b (check if a is less than b)
a = b (check if a equals b)
a != b (check if a does not equal b)
a <= b (check if a is less than or equal to b)
a >= b (check if a is greater than or equal to b)
# 特殊操作
[[Link]].value (fetch `value` from page `Link`)下面是对每项内容的更详细阐述。
表达式类型
字段是表达式
最简单的表达式是直接引用一个字段的表达式。如果你有一个叫做 "field" 的字段,那么你可以直接引用它的名字 - field。如果字段名有空格、标点符号或其他非字母 / 数字的 字符,那么你可以使用 Dataview 的全小写且空格被替换为 “-” 简化名称来引用它。例如,this is a field变成this-is-a-field;Helo!变成hello,以此类推。
算术运算
你可以使用标准算术运算符来组合字段:加法(+),减法(-),乘法(*)。 和除法 (/)。例如,field1 + field2是一个计算两个字段之和的表达式。
比较运算
你可以使用各种比较运算符来比较大多数数值。<, >, <=, >=, =, !=. 这产生了一个布尔的真或假值,可以在查询中的 `WHERE'块中使用。
数组 / 对象索引
你可以通过索引操作符array[<index>]从数组中索引数据,其中<index>是任何已计算的表达式。 数组是以 0 为索引的,所以第一个元素是索引 0,第二个元素是索引 1,以此类推。 例如,list(1, 2, 3)[0] = 1.
你也可以使用索引操作符从对象(将文本映射到数据值)中检索数据,此时的索引是字符串 / 文本而不是数字。你也可以使用快捷方式object.<name>,其中<name>是值的索引。例如object("yes", 1).yes = 1。
函数调用
Dataview 支持各种用于操作数据的函数,这些函数在函数文档中有完整描述。它们的一般语法是function(arg1, arg2, ...) - 即lower("yes")或 regexmatch("text", ".+")。
特定类型的交互 & 值
大多数 dataview 类型与运算符有特殊的相互作用,或者有额外的字段可以使用索引操作符索引。
日期
你可以通过索引来检索一个日期的不同组成部分:date.year,date.month,date.day,date.hour。 date.minute, date.second, date.week。你也可以将时间段添加到日期中以获得新的日期。
时间段
时间段可以相互添加,也可以添加到日期。你可以通过索引来检索一个时间段的各种组成部分。duration.years, duration.months, duration.days, duration.hours, duration.minutes, duration.seconds.
链接
你可以 "通过索引" 一个链接来获得相应页面上的值。例如,[[Link]].value将获得来自Link页面上的value值。
来源
dataview 中的来源指的是标识一组文件,任务或者其它数据对象的东西。来源是由 dataview 内部索引的,所以可以快速进行查询。dataview 目前支持三种来源类型:
- 标签 (Tages):格式为
#tag的来源。 - 文件夹 (Folders):格式为
“folder”的来源。 - 链接 (Links):你可以选择内链和外链。
- 获得链接到
[[note]]的所有页面,使用FROM [[note]]。
- 获得从
[[note]]链接的所有页面 (如,文件中的所有链接),使用FROM outgoing([[note]])。
你可以对这些过滤器进行组合,以便使用 "and" 和 "or" 获得更高级的来源。
- 举个例子,
#tag和 "folder"将返回在folder中和包含#tag的所有页面。 [[Food]] or [[Exercise]]将给出任何链接到[[Food]]或[[Exercise]]的所有页面。
来源既用于 FROM 查询语句,也用于各种 JavaScript API 查询调用。
函数
dataview 的函数提供了更高级操作数据的方法。
函数矢量化
大多数函数可以应用于单个值(如数字,字符串,日期等)或这些值的列表。如果一个函数被应用于一个列表,在函数被应用于列表中的每个元素后,它也会返回一个列表。如:
lower("YES") = "yes"
lower(list("YES", "NO")) = list("yes", "no")
replace("yes", "e", "a") = "yas"
replace(list("yes", "ree"), "e", "a") = list("yas", "raa")构造器
构造器创建值
object(key1, value1, ...)
用给定的键和值创建一个新的对象。在调用中,键和值应该交替出现,键应该总是字符串 / 文本。
object() => empty object
object("a", 6) => object which maps "a" to 6
object("a", 4, "c", "yes") => object which maps a to 4, and c to "yes"list(value1, value2, ...)
用给定的值创建一个新的列表。
list() => empty list
list(1, 2, 3) => list with 1, 2, and 3
list("a", "b", "c") => list with "a", "b", and "c"date(any)
从提供的字符串、日期或链接对象中解析一个日期,解析不出返回 null。
date("2020-04-18") = <date object representing April 18th, 2020>
date([[2021-04-16]]) = <date object for the given page, refering to file.day>number(string)
从给定的字符串中抽出第一个数字,并返回该数字。如果字符串中没有数字,则返回 null。
number("18 years") = 18
number(34) = 34
number("hmm") = nulllink(path, [display])
从给定的文件路径或名称构建一个链接对象。如果有两个参数,第二个参数是链接的显示名称。
link("Hello") => link to page named 'Hello'
link("Hello", "Goodbye") => link to page named 'Hello', displays as 'Goodbye'elink(url, [display])
构建一个指向外部网址的链接(如www.google.com)。如果有两个参数,第二个参数是该链接的显示名称。
elink("www.google.com") => link element to google.com
elink("www.google.com", "Google") => link element to google.com, displays as "Google"数值操作
round(number, [digits])
将一个数字四舍五入到指定的位数。如果没有指定第二个参数,则舍入到最接近的整数。 否则,四舍五入到给定的位数。
round(16.555555) = 7 round(16.555555, 2) = 16.56
--
对象,数组和字符串操作
对容器对象内部的值进行操作的操作。
contains(object|list|string, value)
检查给定的容器类型中是否有给定的值。这个函数的行为稍有不同,它基于第一个参数是一个对象,一个列表,还是一个字符串。
- 对于对象,检查该对象是否有一个给定名称的键。如:
contains(file, "ctime") = true contains(file, "day") = true (if file has a date in its title, false otherwise) - 对于列表,检查数组中是否有元素等于给定的值。如:
contains(list(1, 2, 3), 3) = true contains(list(), 1) = false - 对于字符串,检查给定的值是否是字符串的子串。
contains("hello", "lo") = true contains("yes", "no") = false
extract(object, key1, key2, ...)
从一个对象中抽出多个字段,创建一个抽出字段的新对象。
extract(file, "ctime", "mtime") = object("ctime", file.ctime, "mtime", file.mtime)
extract(object("test", 1)) = object()sort(list)
排序列表,返回一个排序好的新列表。
sort(list(3, 2, 1)) = list(1, 2, 3)
sort(list("a", "b", "aa")) = list("a", "aa", "b")reverse(list)
反转列表,返回一个反转好的新列表。
reverse(list(1, 2, 3)) = list(3, 2, 1)
reverse(list("a", "b", "c")) = list("c", "b", "a")length(object|array)
返回一个对象中的字段数量,或一个数组中的元素数量。
length(list()) = 0
length(list(1, 2, 3)) = 3
length(object("hello", 1, "goodbye", 2)) = 2sum(array)
数组中数值元素求和。
sum(list(1, 2, 3)) = 6all(array)
只有当数组中的所有值都为真,才会返回 "true"。你也可以给这个函数传递多个参数,只有当所有的参数都为真时,它才会返回 `true'。
all(list(1, 2, 3)) = true
all(list(true, false)) = false
all(true, false) = false
all(true, true, true) = trueany(array)
只要数组中有值为真,便返回true。也可以给这个函数传递多个参数,只要有参数为真,便返回true。
any(list(1, 2, 3)) = true
any(list(true, false)) = true
any(list(false, false, false)) = false
all(true, false) = true
all(false, false) = falsenone(array)
如果数组中没有元素,返回none。
join(array)
将一个数组中的元素连接成一个字符串(即在同一行呈现所有的元素)。如果有第二个参数,那么每个元素将被给定的分隔符分开。
join(list(1, 2, 3)) = "1, 2, 3"
join(list(1, 2, 3), " ") = "1 2 3"
join(6) = "6"
join(list()) = ""字符串操作
regexmatch(pattern, string)
检查给定的字符串是否与给定的模式相匹配(使用 JavaScript regex 引擎)。
regexmatch("\w+", "hello") = true
regexmatch(".", "a") = true
regexmatch("yes|no", "maybe") = falseregexreplace(string, pattern, replacement)
用 "replacement" 替换所有在 "string" 中匹配regex pattern的实例。这使用了 JavaScript 的替换方法,所以你可以使用特殊字符如$1来指代第一个捕获组,以此类推。
regexreplace("yes", "[ys]", "a") = "aea"
regexreplace("Suite 1000", "\d+", "-") = "Suite -"replace(string, pattern, replacement)
用replacement替换string中的所有pattern实例。
replace("what", "wh", "h") = "hat"
replace("The big dog chased the big cat.", "big", "small") = "The small dog chased the small cat."
replace("test", "test", "no") = "no"lower(string)
将一个字符串所有字符转换为小写字符。
lower("Test") = "test"
lower("TEST") = "test"upper(string)
将一个字符串所有字符转换为大写字符。
upper("Test") = "TEST"
upper("test") = "TEST"工具函数
default(field, value)
如果field为空,返回value;否则返回field。对于用默认值替换空值很有用。例如,要显示尚未完成的项目,使用"incomplete"作为其默认值。
default(dateCompleted, "incomplete")默认值在两个参数中都是矢量;如果你需要在一个列表参数中明确使用默认值,请使用ldefault,它与默认值相同,但没有被矢量化。
default(list(1, 2, null), 3) = list(1, 2, 3)
ldefault(list(1, 2, null), 3) = list(1, 2, null)choice(bool, left, right)
一个原始的 if 语句 -- 如果第一个参数为真,则返回第二个参数的内容;否则,返回第三个参数的内容。
choice(true, "yes", "no") = "yes"
choice(false, "yes", "no") = "no"
choice(x > 4, y, z) = y if x > 4, else zstriptime(date)
剥离日期中的时间部分,只留下年、月、日。如果你在比较日期的时候不在乎时间,这种方式挺好。
striptime(file.ctime) = file.cday
striptime(file.mtime) = file.mday例子
一个简单的 dataview 查询语言使用的小集合。
利用一些元数据,显示所有 games 文件夹下的文件,按评分排序:
```dataview
TABLE time-played, length, rating FROM "games"
SORT rating DESC
```
列表列举所有 MOBA 游戏或 CRPG 游戏:
```dataview
LIST FROM #game/moba or #game/crpg
```
任务列表列举所有未完成项目的
```dataview
TASK FROM #projects/active
```
表格列举所有在books文件夹下的文件,按最后编辑时间排序:
```dataview
TABLE file.mtime FROM "books"
SORT file.mtime DESC
```列表列举所有标题中有日期的文件 (格式为yyyy-mm-dd),按日期排序:
```dataview
LIST file.day WHERE file.day
SORT file.day DESC
```JavaScipt API
概述
dataview 的 JavaScript API 允许执行任意的 JavaScript,可以访问 dataview 的索引和查询引擎。引擎,这对于复杂的视图或与其他插件的互操作是很好的。该 API 有两种形式:面向插件和面向用户(或 "内联 API 使用方式")。面向插件的方式目前还不能使用,所以本文档将专注于面向用户的查询,任意的 JS 都可以在 markdown 页面中执行。
JavaScript Codeblocks
你可以通过下述操作创建一个 Dataview JS 代码块:
```dataviewjs
<code>
```在这种代码块中执行的代码可以访问dv变量,它提供了与代码块相关的全部 dataview API(如dv.table(),dv.pages(),等等)。更多信息,请查看代码块 API 参考。
数据数组
在 Dataview 中,列表的结果一般抽象为DataArray,它是一个具有额外功能的代理数组。数据数组支持就像普通数组一样索引和迭代(通过 "for" 和 "for ... of" 循环),但也包括许多数据操作符,如 "sort"、"groupBy"、"distinct"、"where" 等,使表格数据的处理变得简单。
创建
数据数组是大部分情况是由可以返回多个结果的 Dataview API 返回的,比如dv.pages()。你也可以使用dv.array(<array>)明确地将一个普通的 JavaScript 数组转换成 Dataview 数组。如果你想把一个数据数组转换为普通数组,请使用DataArray#array()。
索引和调配 (Swizzling)
数据数组像普通数组一样支持常规索引(如array[0]),但重要的是,它还支持查询语言风格的 "swizzling":如果你用字段名索引到一个数据数组(如array.field),它会自动将数组中的每个元素映射到field,如果field本身也是一个数组,则会将其扁平化。
例如,dv.pages().file.name将返回库中所有包含文件名的数据数组。 dv.pages("#books").genres将返回 books 中所有类型的扁平化列表。
原始接口
下面提供了数据数组实现的完整接口以供参考。
/** A function which maps an array element to some value. */
export type ArrayFunc<T, O> = (elem: T, index: number, arr: T[]) => O;
/** A function which compares two types (plus their indices, if relevant). */
export type ArrayComparator<T> = (a: T, b: T) => number;
/**
* Proxied interface which allows manipulating array-based data. All functions on a data array produce a NEW array
* (i.e., the arrays are immutable).
*/
export interface DataArray<T> {
/** The total number of elements in the array. */
length: number;
/** Filter the data array down to just elements which match the given predicate. */
where(predicate: ArrayFunc<T, boolean>): DataArray<T>;
/** Alias for 'where' for people who want array semantics. */
filter(predicate: ArrayFunc<T, boolean>): DataArray<T>;
/** Map elements in the data array by applying a function to each. */
map<U>(f: ArrayFunc<T, U>): DataArray<U>;
/** Map elements in the data array by applying a function to each, then flatten the results to produce a new array. */
flatMap<U>(f: ArrayFunc<T, U[]>): DataArray<U>;
/** Mutably change each value in the array, returning the same array which you can further chain off of. */
mutate(f: ArrayFunc<T, any>): DataArray<any>;
/** Limit the total number of entries in the array to the given value. */
limit(count: number): DataArray<T>;
/**
* Take a slice of the array. If `start` is undefined, it is assumed to be 0; if `end` is undefined, it is assumbed
* to be the end of the array.
*/
slice(start?: number, end?: number): DataArray<T>;
/** Concatenate the values in this data array with those of another data array. */
concat(other: DataArray<T>): DataArray<T>;
/** Return the first index of the given (optionally starting the search) */
indexOf(element: T, fromIndex?: number): number;
/** Return the first element that satisfies the given predicate. */
find(pred: ArrayFunc<T, boolean>): T | undefined;
/** Find the index of the first element that satisfies the given predicate. Returns -1 if nothing was found. */
findIndex(pred: ArrayFunc<T, boolean>): number;
/** Returns true if the array contains the given element, and false otherwise. */
includes(element: T): boolean;
/**
* Return a sorted array sorted by the given key; an optional comparator can be provided, which will
* be used to compare the keys in leiu of the default dataview comparator.
*/
sort<U>(key: ArrayFunc<T, U>, direction?: 'asc' | 'desc', comparator?: ArrayComparator<U>): DataArray<T>;
/**
* Return an array where elements are grouped by the given key; the resulting array will have objects of the form
* { key: <key value>, rows: DataArray }.
*/
groupBy<U>(key: ArrayFunc<T, U>, comparator?: ArrayComparator<U>): DataArray<{ key: U, rows: DataArray<T> }>;
/**
* Return distinct entries. If a key is provided, then rows with distinct keys are returned.
*/
distinct<U>(key?: ArrayFunc<T, U>, comparator?: ArrayComparator<U>): DataArray<T>;
/** Return true if the predicate is true for all values. */
every(f: ArrayFunc<T, boolean>): boolean;
/** Return true if the predicate is true for at least one value. */
some(f: ArrayFunc<T, boolean>): boolean;
/** Return true if the predicate is FALSE for all values. */
none(f: ArrayFunc<T, boolean>): boolean;
/** Return the first element in the data array. Returns undefined if the array is empty. */
first(): T;
/** Return the last element in the data array. Returns undefined if the array is empty. */
last(): T;
/** Map every element in this data array to the given key, and then flatten it.*/
to(key: string): DataArray<any>;
/**
* Recursively expand the given key, flattening a tree structure based on the key into a flat array. Useful for handling
* heirarchical data like tasks with 'subtasks'.
*/
expand(key: string): DataArray<any>;
/** Run a lambda on each element in the array. */
forEach(f: ArrayFunc<T, void>): void;
/** Convert this to a plain javascript array. */
array(): T[];
/** Allow iterating directly over the array. */
[Symbol.iterator](): Iterator<T>;
/** Map indexes to values. */
[index: number]: any;
/** Automatic flattening of fields. */
[field: string]: any;
}代码块参考
Dataview JavaScript Codeblocks 是使用dataviewjs语言规范创建的一个代码块。
```dataviewjs
dv.table([], ...)
```API 是通过隐含提供的dv(或dataview)变量来实现的,通过它可以查询信息,渲染 HTML,并配置视图。
查询
dv.current()
获取脚本当前执行的页面信息(dv.page())。
dv.pages(source)
接受一个字符串参数,source,与查询语言来源的形式相同。返回一个数据数组的页面对象,它是以所有页面字段为值的普通对象。
dv.pages("#books") => all pages with tag 'books'
dv.pages('"folder"') => all pages from folder "folder"
dv.pages("#yes or -#no") => all pages with tag #yes, or which DON'T have tag #nodv.pagePaths(source)
和dv.pages一样,但只是返回一个数据数组,其中包括符合给定来源的页面路径。
dv.pagePaths("#books") => the paths of pages with tag 'books'dv.page(path)
将一个简单的路径映射到完整的页面对象,其中包括所有的页面字段。自动进行链接解析,如果不存在,会自动进行扩展。
dv.page("Index") => The page object for /Index
dv.page("books/The Raisin.md") => The page object for /books/The Raisin.md渲染
dv.header(level, text)
用给定的文本渲染 1 - 6 级标题。
dv.header(1, "Big!");
dv.header(6, "Tiny");dv.paragraph(text)
在段落中渲染任意文本。
dv.paragraph("This is some text");Dataviews
dv.list(elements)
渲染一个 dataview 的元素列表;接受 vanilla 数组和数据数组。
dv.list([1, 2, 3]) => list of 1, 2, 3
dv.list(dv.pages().file.name) => list of all file names
dv.list(dv.pages().file.link) => list of all file links
dv.list(dv.pages("#book").where(p => p.rating > 7)) => list of all books with rating greater than 7dv.taskList(tasks, groupByFile)
渲染一个由page.file.tasks获得的Task对象的 dataview 任务列表。第一个参数是必需的;如果提供第二个参数groupByFile(须为真),那么将会按照文件的来源对任务列表进行分组。
// List all tasks from pages marked '#project'
dv.taskList(dv.pages("#project").file.tasks)
// List all *uncompleted* tasks from pages marked #project
dv.taskList(dv.pages("#project").file.tasks
.where(t => !t.completed))
// List all tasks tagged with '#tag' from pages marked #project
dv.taskList(dv.pages("#project").file.tasks
.where(t => t.text.includes("#tag")))dv.table(headers, elements)
用给定的标题列表和 2 维数组渲染一个 dataview 表格。
// Render a simple table of book info sorted by rating.
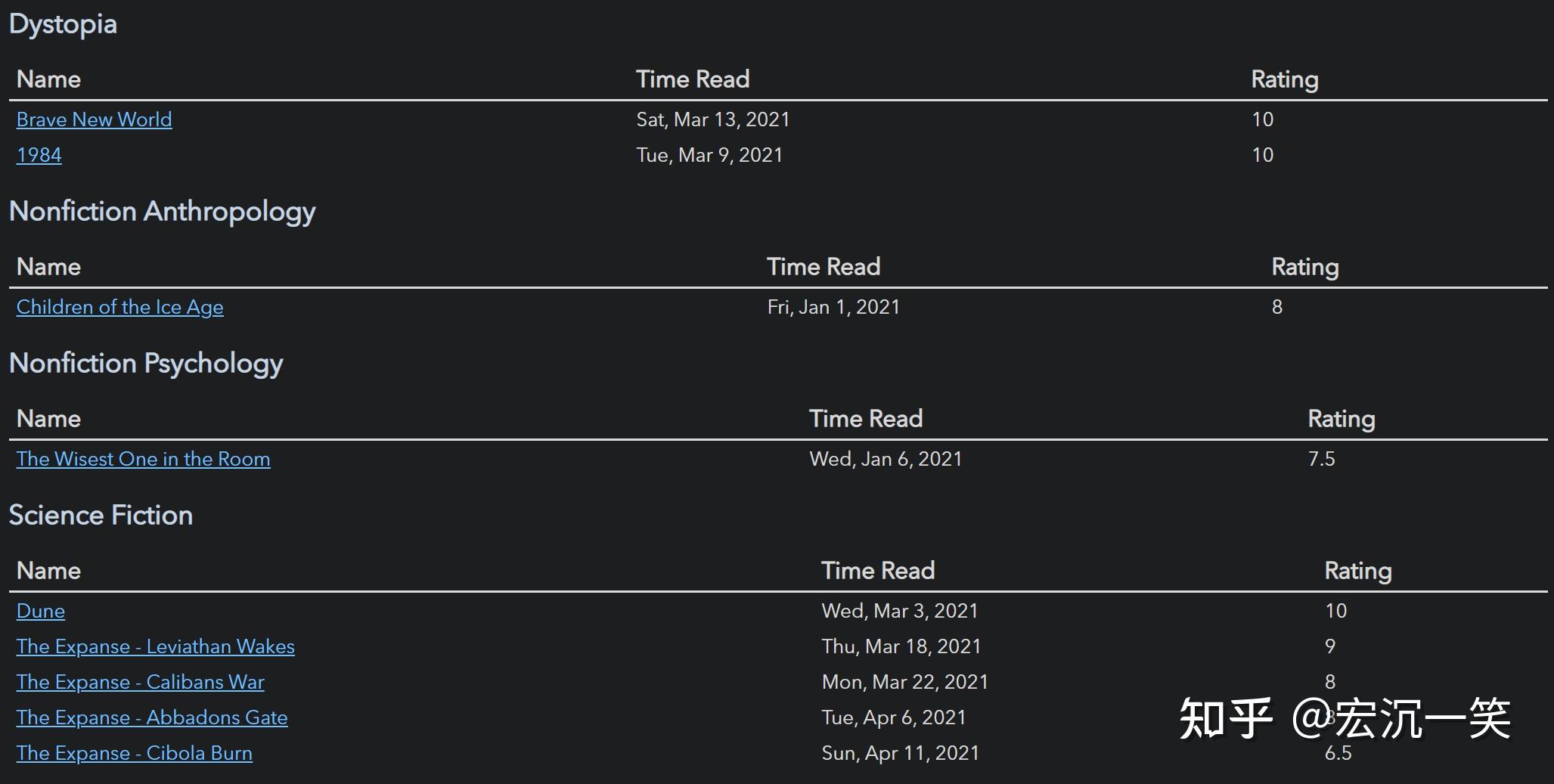
dv.table(["File", "Genre", "Time Read", "Rating"], dv.pages("#book")
.sort(b => b.rating)
.map(b => [b.file.link, b.genre, b["time-read"], b.rating]))工具
dv.array(value)
将一个给定的值或数组转换成 Dataview 数据数组。如果该值已经是一个数据数组,则返回它,不作任何改变。
dv.array([1, 2, 3]) => dataview data array [1, 2, 3]dv.compare(a, b)
根据 dataview 的默认比较规则,比较两个任意的 JavaScript 值;如果你打算写一个自定义的比较器并且不想影响正常代码,那非常有用。如果a < b返回 - 1,如果a = b返回 0,如果a > b返回 1。
dv.compare(1, 2) = -1
dv.compare("yes", "no") = 1
dv.compare({ what: 0 }, { what: 0 }) = 0dv.equal(a, b)
比较两个任意的 JavaScript 值,如果根据 Dataview 的默认比较规则是相等的,则返回 true。
dv.equal(1, 2) = false
dv.equal(1, 1) = true代码块例程
书籍分组
按体裁对你的书籍进行分组,然后为每本书创建一个按评级分类的表格。
for (let group of dv.pages("#book").groupBy(p => p.genre)) {
dv.header(3, group.key);
dv.table(["Name", "Time Read", "Rating"],
group.rows
.sort(k => k.rating, 'desc')
.map(k => [k.file.link, k["time-read"], k.rating]))
}