数据库设计是指对于一个给定的应用环境,构造优化的数据库逻辑模式与物理结构,并且据此建立数据库机器应用系统,是之能够有效的存储于管理数据
数据库有两个要求:
- 信息管理要求:数据库中应该存储和管理哪些书库对象
- 数据操作要求:数据对象需要进行哪些操作
数据库设计的目标在于为用户和各种应用系统提供一个信息基础设施和高效率的运行环境(存取效率高、存储空间利用率高、数据库系统运行管理效率高)
数据库建设的基本规律:三分基数,七分管理,十二分基础数据
- 管理:数据库建设项目管理与企业的业务管理
- 基础技术:基数的收集、整理、组织、不断更新
数据库的数据结构设计与处理行为设计应该要互相结合
这个时期的方法的缺点有:
- 设计质量与设计人员的经验与水平有直接关系
- 缺乏科学理论和工程方法的支持,工程质量难以保证
- 维护代价特别高
这个时期的基本思想是:过程迭代与逐步求精
这个时期的典型方法有:
- 新奥尔良法 New Orleans
- 基于 E-R 图模型的数据库设计方法
- 3NF 的设计方法
- 面向对象的数据库设计方法
- 统一建模语言方法 UML
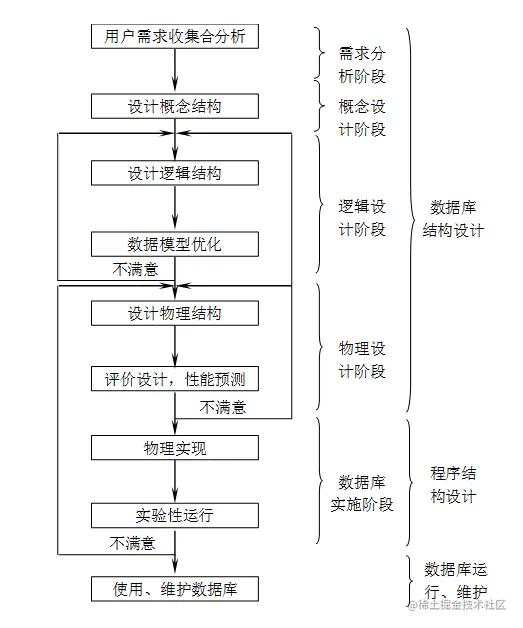
数据库设计一般分为 6 个步骤:
- 需求分析:了解用户需求,这个阶段是否做的充分决定了构建数据库的速度与质量
- 概念结构设计:对用户需求进行总结、归纳、抽象,形成一个独立于具体数据库管理系统的概念模型(ER 图)
- 逻辑结构设计:将概念结构转换成 DBMS 支持的数据模型,并对其进行优化
- 物理结构设计:为逻辑数据结构选取一个最适合的应用环境物理结构,包括存储结构与存取方法
- 数据库实施:根据逻辑设计与物理设计的结果构建数据库,编写与调试以ing用程序,组织数据入库并进行试运行
- 数据库运行与维护:投入正式运行,在运行过程需要对其评估、调整、修改
说明:
- 需求分许与概念设计独立于任何数据库管理系统
- 逻辑设计和物理设计与选用的数据库管理系统有密切联系
- 设计一个完善的数据库往往需要上述 6 个步骤反复执行
需求分析的主要目的是:调查清楚用户的时机需求并进行初步分析,最终与用户达成一致
- 详细调查现实世界要处理的对象
- 充分了解对象原来系统的概况
- 明确用户的各种需求
- 确定新系统的功能(需要考虑之后的扩张性)
这个阶段的重点是“数据”与“处理”,获得用户对数据库在信息处理、安全性、完整性的要求
结构化的分析方法 Structured Analysis:自顶向下,逐步求精
数据字典是关于数据库中数据的描述(也就是元数据)
数据字典是在需求分析阶段建立,经过详细数据收集与数据分析获得的,并缺在数据库设计过程中不断修改、充实、完善
数据字典的内容包括:
- 数据项
- 数据结构
- 数据流
- 数据存储
- 处理过程
数据项是不可再分的数据单位
数据项包含了:
- 数据名
- 数据含义说明
- 数据别名
- 数据类型
- 数据长度
- 取值范围
- 取值含义
- 数据与其他数据项的逻辑关系
- 数据项之间的联系
其中,取值范围和与其他数据项的逻辑关系定义了数据的完整性约束条件
数据结构反映了数据之间的组合关系
数据结构包含了:
- 数据结构名
- 含义说明
- 数据之间的组合
数据流是数据结构在系统内传输的路径、
数据流包含了:
- 数据流名字
- 数据流说明
- 数据流来源
- 数据流去向
- 数据流组成
- 平均流量
- 高峰流量
数据存储是数据结构停留或保存的地方,也是数据流的来源或去向之一
数据存储包含:
- 数据存储名
- 数据存储说明
- 数据存储编号
- 输入输出的数据流
- 数据存储的组成
- 数据量
- 存取频度
- 存取方式
处理过程是指数据的操作,一般使用判定表或判定树来描述
数据字典中只需要描述处理过程的说明性信息
概念结构设计是将需求分析阶段得到的用户需求抽象成为信息结构(概念模型)的过程
概念模型有如下特点:
- 能真实、充分的反映现实世界,是现实世界的一个真实模型
- 易于理解,可以用它和不熟悉计算机的用户交换意见
- 易于更改,如果环境或要求改变时,方便修改与扩充
- 易于项关系、网状、层次模型转换
概念模型的描述工具:ER 图
逻辑结构设计的主要任务是将概念结构设计阶段设计好的 ER 图转换为与选用 DBMS 产品所支持的数据模型相符合的逻辑结构
ER 图主要由实体型、实体的属性、实体型之间的联系三个要素组成
所以我们可以把工作分解成将这三个要素转换为关系模式
- 一个实体型应该转换成一个关系模式
- 关系的属性是实体的属性
- 关系的码是实体的码
一对一的关系可以有两种转换方式:
-
转换为一个独立的关系模式
关系的属性:与该联系相连的哥哥实体的码以及联系本身的属性
关系的候选码:每个实体的码都是候选码
-
【优先】与某一段实体对应的关系模式合并
合并后的关系属性:加入对应关系的码和联系本身的属性
合并后关系的码:不变
这种方式可以减少系统中关系个数,所以优先推荐使用
一对多关系也有两种转换方式:
-
转换成一个独立的关系模式
关系的属性:与该联系相连的哥哥实体的码以及联系本身的属性
关系的候选码:n 端实体的码都是候选码
-
【优先】与 n 端对应的关系模式合并
合并后的关系属性:在 n 端关系中加入一端关系的码和联系本身的属性
合并后关系的码:不变
这种方式可以减少系统中关系个数,所以优先推荐使用
多对多关系只能转换为一个关系模式
- 关系的属性:与该联系相连的各个实体的码级联系本身的属性
- 关系的候选码:各个实体码的组合
数据库逻辑设计的结果并不是唯一的
为了进一步提高数据库应用系统的性能,应该适当的调整数据模型结构,这个过程被称为数据模型的优化
- 确定数据依赖
- 对数据依赖做极小化处理,消除冗余联系
- 考察是否存在部分函数依赖、传递函数依赖、多值函数依赖等,确定哥哥关系模式分别属于第几范式
- 按照用户需求,分析在需求的应用环境下这些需求是否合适,是否需要合并或分解
- 根据数据操作效率和储存空间利用率对关系模式进行必要分解
需要注意的是,并不是规范化程度越高关系就越好,比如查询如果涉及到多个关系模式属性是,需要进行连接运算,代价较高,此时可以考虑是否用低级范式就可以满足需求
定义数据库模式应该从系统的时间、空间、易维护等角度出发
但是定义用户子模式的时候应该考虑用户的习惯与方便,包括:
- 使用更加符合用户习惯的别名
- 针对不同级别的用户定义不同的视图
- 简化用户对系统的使用
上述可以通过建立视图来实现
数据库的物理结构指的是数据库在物理设备上的储存结构和存取方法
数据库的物理结构设计主要是为了给逻辑数据模型选取一个最适合应用要求的物理结构,是数据库的物理设计
- 确定物理结构:包括存取方法与储存结构
- 对物理结构进行评价:主要评价时间与空间效率,如果必要可以返回逻辑设计阶段修改数据模型
- 充分了解应用环境,分析要运行的事物
- 充分了解所用关系性数据库管理系统的内部特征,特别是系统提供的存取方法与存储结构
- 对于数据查询,需要得到以下信息:
- 查询的关系
- 查询条件涉及的属性
- 连接条件涉及的属性
- 查询的投影属性
- 对于数据更新事物,需要得到以下信息:
- 被更新的关系
- 每个关系的更新条件所涉及的属性
- 修改操作要更改的属性
- 对于事务在各个关系上运行的频率与性能要求
设计主要是选择关系模式的存取方法,以及存储结构
DBMS 常用的存取方法有:
- B+ 树索引存取方法
- Hash 索引存取方法:删改代价大
- 聚簇存取方法:在物理上连续存放
选择索引群去方法的一般规则:
- 如果一个/一组属性经常在查询中出现,则可以考虑建立索引
- 如果一个属性经常做为最大值/最小值等聚集函数的参数,则可以考虑建立索引
- 如果一个/一组属性经常在连接操作中初选,则考虑建立索引