前段时间面试的时候被问了一题 HTTP 缓存,当时勉强回答了强缓存与协商缓存,但是面对追问什么时候用强缓存,强缓存怎么更新的时候我就只能阿巴阿巴了🥹
面试完后我翻了一圈中文的博客,发现大多都在强调强缓存用什么 header、协商缓存用什么 header,返回了什么状态码
神奇的是,当我看了外国的博客,却根本找不到这两个名词相关的说明
于是,我就去看了一下 mdn 对 HTTP cache 的解释,就有了这篇学习笔记
要回答这个问题,我们要先回答一个问题:缓存能做什么?
mdn 对此的解释是:The HTTP cache stores a response associated with a request and reuses the stored response for subsequent requests.
翻译过来的大白话就是,缓存帮我们把上一次请求的响应保存起来,这样在下次相同请求发生时可以直接从缓存中获取
归根结底,就是以空间换取时间,浏览器通过在内存或者本地磁盘保存返回信息,减少资源请求耗时,进而加快页面的渲染速度
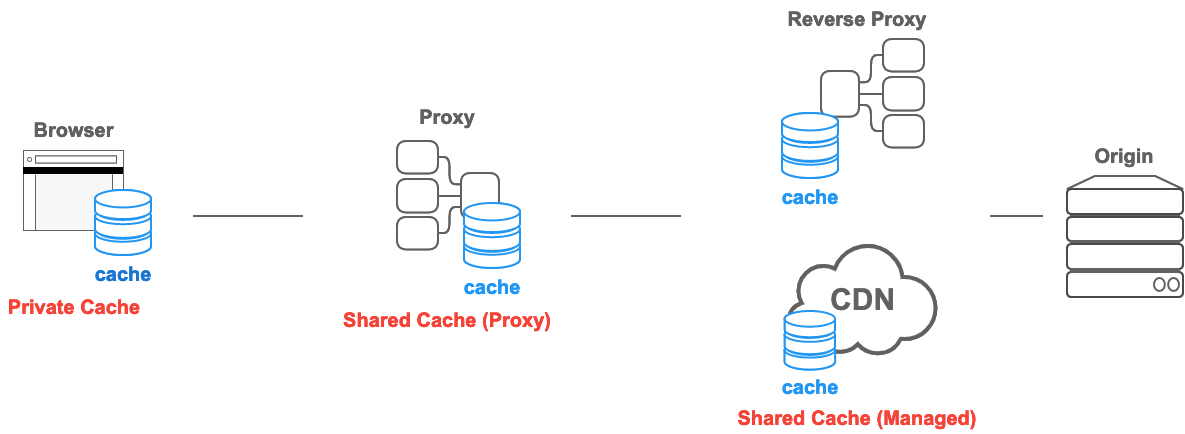
其实对于 HTTP 这个协议来说,缓存被分成两大类:
- Private caches:也是我们常说的浏览器缓存,因为是保存在浏览器,所以这个缓存一般保存的是与特定用户相关的响应,这样才能保证用户相关的信息不会被泄漏出去,一般用户相关的数据会使用
Cache-Control: private这个 header 来保证只在浏览器中缓存 - Shared caches:指的是浏览器到 server 之间的缓存,可以是代理缓存,也可以是 cdn 缓存,这类缓存是不区分用户的,所以可以在不同的用户之中共享
对于 HTTP 的缓存来说,存在两种状态:
- fresh:新鲜状态。代表当前缓存还未过期,此时浏览器会直接用当前缓存来响应相同的请求(状态码可能是
200 from disk cache或者200 from memory cache) - stale:腐朽状态。代表当前缓存已经到期了,到期的缓存并不会被马上丢弃,而是会需要向 server 进行验证,如果验证通过,缓存会被重新标记成 fresh
如果熟悉强缓存与协商缓存的读者是不是感觉似曾相识?
是的,这两种状态的处理其实恰巧就对应了 “这两种缓存” 的处理方式,但是问题是,这是一套缓存机制,而不是两个可以选择的缓存方式
随着 HTTP 协议从 1.0 演进到 1.1,判断 fresh 的方法也发生了改变
在 1.0 时期,一般是使用 header 中的 Expires 表示缓存到期的时刻:
Expires: Tue, 23 Jul 2024 07:01:04 GMT可以看到 Expires 使用的是绝对时间,这个看似简单方便的方案其实在现实中会有很多意想不到的坑,比如:
- 绝对时间会要求客户端与 server 时间必须要个同步,不然任何偏差都可能造成意料之外的表现
- 一个由客户端来判断的绝对时间,会受到客户端获取的系统时间的影响,如果有用户改了系统时间,可能导致预期之外的 bug
所以在 1.1 之后,更加推荐的使用方法是使用 header 中的 Cache-Control,使用方式如下:
Cache-Control: max-age=604800它告诉浏览器这个缓存还可以使用 604800 秒(就是一周)
当然,如同上文所述,有些缓存是保存在 Shared caches 中的,那么他们有义务去告知客户端当前缓存已经多少岁了,他们一般会使用 header 中的 Age 字段来标识,如下:
Age: 86400浏览器接收到这两个信息后,就可以得到这个缓存的 fresh 时间还有 604800 - 86400 = 518400(还有 6 天)
如果同时使用,max-age 与 Expires,max-age 的优先级更高
当然,在应用中还有一个特殊的场景,如果一个网站的 js 资源 url 是 https://example.com/script.js,但是想要根据用户地区实现多语言资源的下发,那么可以通过 header 中的 Accept-Language 来区分 server 要下发的资源,达到同一个 url 定位多个资源的效果,但是这个解决方案对于我们上述的缓存方案其实并不友好,因为缓存是根据请求来区分的,这个时候我们就需要请出 Vary 这个 header 来兼容了,它的使用方法如下:
Vary: Accept-Language这样我们可以告诉浏览器,判断缓存除了使用请求的 url 之外,还要查看 header 中的 Accept-Language 是否一致,如果一致才能够使用对应缓存
如同上文所述,经过 max-age 判断为过期的缓存并不会被浏览器直接抛弃,浏览器会通过一个校验机制来重新判断当前缓存是否在过期后仍然可用
这个机制包含了两个方法,分别是:If-Modified-Since 与 If-None-Match,下文会分别介绍这两种方式
之所以会用这个小标题,是因为这个验证方法是由浏览器与 server 双边协作才能完成的,让我们一步步来揭秘:
首先,浏览器正常发送了一个资源请求,然后 server 正常返回了一个资源,并且带上了一些 header 如下:
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 1024
Date: Tue, 22 Feb 2022 22:22:22 GMT
Last-Modified: Tue, 22 Feb 2022 22:00:00 GMT
Cache-Control: max-age=3600
<!doctype html>
…可以看到,这个 header 中包含了几个重要信息:
- max-age 是一个小时,说明这个缓存在 23:22:22 之前是 fresh 的
- Last-Modified 表示这个资源最后被更新的时间是当天的 22:00:00
然后我们来看看当浏览器在 23:22:22 后发送请求会发生什么事:
首先,浏览器会判断当时的缓存已经 stale 了,这个时候,浏览器会向 server 发送一个请求,并且带上资源的最后更新时间,请求的 header 如下:
GET /index.html HTTP/1.1
Host: example.com
Accept: text/html
If-Modified-Since: Tue, 22 Feb 2022 22:00:00 GMT这个请求的功能就是咨询 server:你现在最新的 index.html 有没有更新过呢?
这个时候 server 可能有两种响应:
- 如果资源发生了更新,则直接返回最新的资源,这个时候 http 的状态码就会显示为 200
- 如果资源没有发生更新,则会返回给浏览器一个简单的响应,响应的 header 范例如下:
HTTP/1.1 304 Not Modified
Content-Type: text/html
Date: Tue, 22 Feb 2022 23:22:22 GMT
Last-Modified: Tue, 22 Feb 2022 22:00:00 GMT
Cache-Control: max-age=3600浏览器接受到这个这个请求,就会把缓存刷新为 fresh 的状态,并且重新把缓存过期时间设置到 1 小时后
当然,这个方案仍然使用了时间格式,所以仍然会有一些与上述 Expires 类似的坑:
- 时间格式能够表达的最小时间间隔是秒,如果有些资源在同一秒之间更新了多次,这套方案无法及时修正
- 如果资源保存在分布式服务器中,服务器的时间同步问题可能导致一些意想不到的 bug
所以就有如下的 ETag 方案……
这个方案的思路与上述 If-Modified-Since 基本大同小异,区别在于,用时间格式来表示资源的方式被一个 ETag 替代了
ETag 可以看成一个 “资源+版本” 的唯一标识符,这个标识符的生成 http 协议没有做强制约束,但一般的解决方案是使用资源的 hash 来标识
浏览器验证资源有效性的流程如下:
首先是接受到一开始的资源……
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 1024
Date: Tue, 22 Feb 2022 22:22:22 GMT
ETag: "33a64df5"
Cache-Control: max-age=3600
<!doctype html>
…当缓存过期了,浏览器会发送一个携带有 If-None-Match header 的请求并带上资源的 Etag……
GET /index.html HTTP/1.1
Host: example.com
Accept: text/html
If-None-Match: "33a64df5"server 经过与当前最新资源的 Etag 进行对比,如果相同,则返回 304;如果不同,则返回最新资源并带上最新的 Etag
上述我们在说 max-age 与 expires 的时候,我们直接无脑推荐使用 max-age,那么在 Last-Modified 与 ETag 之间呢?
首先根据 RFC9110 的规定,如果同时使用 ETag 与 Last-Modified,ETag 拥有较高的优先级,而且如果只站在缓存管理这个角度,Last-Modified 其实是不推荐使用的
但是如果读者仔细观察当前网站请求的 header,还是能看到 Last-Modified 被频繁使用,甚至在请求中能同时看到 Last-Modified 与 ETag,这是为什么呢?
因为 Last-Modified 除了用来管理缓存,还肩负着其他的任务,比如:
- Last-Modified 有利于网站的 SEO:有些爬虫会根据 Last-Modified 来判断是否需要重新爬取相对应的页面
- Last-Modified 有助于资源的追踪管理:Last-Modified 有助于网站管理员在问题发生的时候去追踪资源的状态,以便更快的丁文问题
结论:建议同时使用 Last-Modified 与 ETag
在了解了浏览器缓存机制后,我们知道缓存能够大大的提升页面加载速度,但是在实际的应用场景中,如果一个资源会被快速更新,那么我们自然不希望浏览器从缓存中拿到之前的资源版本,这个时候 no-cache 就派上用场啦~
server 可以通过如下 header 告知浏览器对此资源使用 no-cache 的策略:
Cache-Control: no-cache但是有一点需要强调一下,no-cache 并不是告诉浏览器不要缓存的意思
相反,浏览器还是会将这个资源缓存起来
no-cache 与一般的缓存策略的区别在于,当浏览器下次请求同一资源时,必定会给 server 发一个请求来询问当前资源缓存是否过期(也就是每次请求都会把当前缓存当成 stale 校验一次)
而如果 server 返回了一个 304 Not Modified,浏览器则仍会使用该缓存
总结:no-cache 并不是要求不要缓存,而是要求在每次使用缓存之前必须经过验证
http 协议确实提供了一种完全避免资源被缓存的方案,no-store,它的使用方法如下:
Cache-Control: no-store根据 mdn 的描述,使用 no-store 的目的一般有两种:
- 隐私安全:不希望请求的响应被任何除了目标用户之外的地方保存
- 保持更新:希望用户获取到的资源保证是最新的
下面我们逐个来分析
在这个 case 下,其实如下 header 就可以保证用户的隐私安全:
Cache-Control: private其中 private 可以保证缓存只保存在 private cache 中
想要保持用户能时刻拿到最新的资源,我们可以用如下方式:
Cache-Control: no-cacheno-cache 可以保证用户时刻拿到最新的资源
使用了 no-store,相当于完全抛弃了 http 缓存带来的所有优点,也完全抛弃了浏览器对于资源缓存的优化
其次,no-store 带来的优势完全可以有别的方案来替代
所以如果一般情况下,不建议使用 no-store
上面我们说了浏览器缓存的用法与优点,但是随着业务的发展,我们时常会需要不定期的更新资源,如果 server 资源的更新的时候缓存还是 fresh 的状态,用户将没办法获得最新的资源,如果出现部分资源更新导致的 breaking change,有可能会让页面发生预期之外的事故
上文我们说过,如果要让浏览器直接使用缓存当成请求的响应,需要满足两个条件:
- 相同请求发生了
- 缓存没有过期
为了达成我们业务不定期更新资源的诉求,显然是没办法从第二个条件下手了,那么我们只能在第一个条件中找找解决方案
我们知道每一个资源其实都有一个特定的 url 来标识其位置,那么我们其实只需要更新所需资源的 url,就可以迫使浏览器 “抛弃” 原缓存重新向 server 请求最新的资源了
举个例子:
<html lang="en-US">
<head>
<link rel="stylesheet" href="/assets/css/styles.bshe60a.css">
<script charset="utf-8" src="/assets/js/sh1947lz.js"></script>
</head>
<body>
<!-- body examples.... -->
</body>
</html>例子中的 css 与 js 资源其实都是通过内容摘要算法算出 hash 之后命名的,这个算法能保证当资源内容更新时,资源路径也会相对应变化
有了这套机制之后,我们还需要做两步才能完成及时动态资源更新:
首先针对页面(比如例子中的 html 文件),我们希望它在每次都能用上最新的版本,所以我们要求 server 在 header 加上:
Cache-Control: no-cache其次,我们希望资源在部署的时候是非覆盖式的,也就是,线上能够同时并存多个版本的资源
做到了这两点之后,我们的上线流程如下:
- 首先部署资源,把最新版本的资源部署到 server 中,让其与旧版本的资源并存
- 灰度下发页面,并及时监控线上数据
- 确认灰度没问题后全量下发页面
这样一来既可以用上 HTTP 缓存的所有好处,也能实现资源的及时更新