作为一个国内的前端搬砖工程师,在面试国内公司的时候免不了要被问到各种模版式的问题(虽然本人在面试的时候特别不喜欢被问,但架不住它确实是一个高效的筛选出能 “搬砖” 的人的小技巧)而且这些问题往往有着与之相对的模版答案,因此就起了想把他们收集起来的想法,下面的题目我会根据我自己过往的项目经验把他们分成若干模块,模块中的内容优先级不分先后,各位可以找到自己感兴趣的模块准备就可
个人能力有限,只能准备我遇到的/看到的题目,如果有朋友能帮助补充,烦请提一个 issue,我看到就会处理
每个问题我都附带了我自己的解答,大家可以参考,如果觉得我的解答有误也请提一个 issue,互相交流学习
-
let:块级作用域,提升变量声明
-
const:声明常变量
-
symbol():返回唯一值,用于对象属性标识符
-
arrow function:
()⇒{} -
解构赋值:
[a,b]=[b,a] -
模版文字:
let string=`i am ${variable}`;
-
...运算子 -
模组化:export、import
-
异步:Promise、async
-
Map()
-
generator:function*、next、yield
-
class:static、extend、constructor
例子:
function getClosure() {
// 函数的内部变量
const innerParam = "joyee";
function closure() {
console.log("Hi! " + innerParam);
}
return closure;
}
const closure = getClosure();
// 这个方法就是闭包,因为它拿到了其他函数(getClosure)的内部变量
closure(); // Hi! joyee特性:
- 可以读取其他函数内部变量的函数,等于变相封装局部变量
- 优点:保护变量、实现模块化封装
- 缺点:性能损耗(闭包涉及较长的作用域链查找)
- 闭包子函数在调用时父函数不会被回收
- 优点:延长变量生命周期、保持变量状态
- 缺点:内存占用
一句话描述:柯里化使函数只接受第一个参数,返回其余参数到一个函数中,目的是为了参数复用
详情见:Javascript 中的柯里化(Currying)
https://developer.mozilla.org/zh-CN/docs/Learn/JavaScript/Objects/Object_prototypes
https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Promise
async/await 是 promise 的语法糖
事件循环介绍:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Event_loop
简介:
- macro-task:宏任务tasks
- micro-task:微任务jobs
script(主程序代码)—>process.nextTick—>Promises...——>setTimeout——>setInterval——>setImmediate——> I/O——>UI rendering
事件流包含了三个阶段,依次是:
- 事件捕获 Capturing pharse:此时事件从
document往下走到触发事件的元素 - 目标阶段 Target pharse:此时事件到达目标元素(可以通过
event.target来获取目标元素) - 冒泡阶段 Bubbling phase:此时事件从目标元素往上走回到
document
监听事件可以使用 addEventListener, 其中第三个参数 useCapture 可以决定是否要在捕获阶段触发监听函数
如果要阻止事件继续传播,可以使用 event.stopPropagation;但是这个不会阻止元素的默认事件,阻止默认事件使用 event.stopPropagation 方法
一句话描述:事件委托将本来要绑定在子元素的事件响应函数委托给父元素处理,以简化初始化过程与减少内存占用
例子:
<body>
<ul id="list">
<li>list1</li>
<li>list2</li>
<li>list3</li>
<li>list4</li>
<li>list5</li>
<li>list6</li>
</ul>
<script>
var ul_list = document.getElementById('list');
var list = ul_list.getElementsByTagName('li');
// 没有用事件委托需要给每一个子元素都绑上监听方法
for (var i = 0; i < list.length; i++) {
list[i].onclick = function () {
this.style.color = 'red';
};
}
</script>
</body>事件委托例子:
<body>
<ul id="list">
<li>list1</li>
<li>list2</li>
<li>list3</li>
<li>list4</li>
<li>list5</li>
<li>list6</li>
</ul>
<script>
var ul_list = document.getElementById('list');
var list = ul_list.getElementsByTagName('li');
// 将事件的处理方法委托到了父元素,只需要绑定一次
ul_list.onclick = function (event) {
event.target.style.color = 'red';
};
</script>
</body>- 创建一个空对象
- 继承构造函数的 prototype 与 prototype 的属性
- 最后将新创建的对象 return
//定义的new方法
let newMethod = function (Parent, ...rest) {
// 1.以构造器的 prototype 属性为原型,创建新对象;
let child = Object.create(Parent.prototype);
// 2.将 this 和调用参数传给构造器执行
let result = Parent.apply(child, rest);
// 3.如果构造器没有手动返回对象,则返回第一步的对象
return typeof result === 'object' ? result : child;
};用法:
func.call(this,arg1,arg2...)func.apply(this,arg[])variable=func.bind(this,arg1,arg2,...)
bind 实现:
Function.prototype.bind = function (context) {
var _this = this
var args = Array.prototype.slice.call(arguments, 1)
return function() {
return _this.apply(context, args)
}
}- 节流:规定相同事件在一段时间内最多只能触发一次事件handle
- 防抖:规定在事件触发后设定一个延迟时间才执行事件handle,如果重复触发,以最后一次为准
- 对于基本类型:会传递值,形参是实参的一个拷贝
- 对于复杂类型:会传递该类型的地址值,虽然会是一个新的,但是对于地址引用的修改会反映到实参本身
-
全局对象中的this指向:window
-
全局作用域或者普通函数中的this:window
-
this 永远指向最后调用它的那个对象:函数的 this 是运行时决定的
-
new 关键词:改变了this的指向
-
apply,call,bind:可以改变函数的 this 指向
-
箭头函数中的 this:箭头函数的 this 指向在定义时决定,指向外层函数(如果没有就是 window)
-
匿名函数中的 this:永远指向了window,匿名函数的执行环境具有全局性,因此this指向window
requestAnimationFrame(callback) 方法,可以按照浏览器的刷新频率来调用回调函数,调用时机在浏览器重绘之前
这个方法会返回一个 id,开发者可以通过这个 id 调用 window.cancelAnimationFrame() 来取消动画
requestIdleCallback(callback) 会在浏览器空闲的状态下执行回调函数
回调函数中可以编写一些比较不紧急的方法(比如埋点上报)用来保证用户的体验(卡顿)不会被这种不紧急的方法影响
worker 介绍:https://developer.mozilla.org/en-US/docs/Web/API/Worker
worker 本质上是浏览器启动了一个单独的线程,用来执行一些特殊的任务
注意点:
- 同源限制:分配给 Worker 线程运行的脚本文件,必须与主线程的脚本文件同源。
- 文件限制:为了安全,Worker 线程无法读取本地文件,即不能打开本机的文件系统(file://),它所加载的脚本必须来自网络,且需要与主线程的脚本同源。
- DOM操作限制:worker 线程在与主线程的 window 不同的另一个全局上下文中运行,其中无法读取主线程所在网页的 DOM 对象,也不能获取 document、window 等对象,但是可以获取 navigator、location(只读)、XMLHttpRequest、setTimeout 等浏览器API。
- 通信限制:worker 线程与主线程不在同一个上下文,不能直接通信,需要通过 postMessage 方法传递消息来通信。
- 脚本限制:worker 线程不能执行 alert、confirm,但可以使用 XMLHttpRequest 对象发出 ajax 请求。
使用场景:
- 加密数据:有些加解密的算法比较复杂,或者在加解密很多数据的时候,这会非常耗费计算资源,导致 UI 线程无响应,因此这是使用 Web Worker 的好时机,使用Worker 线程可以让用户更加无缝的操作 UI。
- 预取数据:有时候为了提升数据加载速度,可以提前使用 Worker 线程获取数据,因为 Worker 线程是可以是用 XMLHttpRequest 的。
<!-- 内联 -->
<html>
<head>
<script>
console.log("Hello");
</script>
</head>
</html><!-- 外置脚本 -->
<html>
<head>
<script src="a.js"></script>
<!-- 只有加载完并执行完 a.js 后,才开始加载 b.js -->
<script src="b.js"></script>
</head>
<body>
<!-- 只有加载完并执行完 b.js 后,才开始加载 c.js -->
<script src="c.js"></script>
</body>
</html>// 动态引入
var myScript = document.createElement("script");
myScript.src = 'c.js';
document.head.appendChild(myScript);- 把 script 标签放到 body 标签底部
- defer 属性:该脚本是要在文档被解析后,但在触发
DOMContentLoaded事件之前执行的 - async 属性:脚本会被并行请求,并尽快解析和执行
- 降低请求量:合并资源,减少请求数,压缩
- 加快请求速度:与解析DNS,CDN分发
- 缓存:HTTP缓存、页面离线缓存manifest、离线数据缓存localStorage
- 渲染:代码优化,pipeline
- 优点:嵌入页面,灵活性强
- 缺点:不易管理、不利于SEO、增加HTTP请求
- 传统/静态布局:固定像素尺寸,不能根据荧幕尺寸调整,可以使用meta标签applicable-device标示移动设备
- 流式布局:元素大小会变化但是布局不变,适应不同尺寸屏幕
- 自适应布局:创建多个静态布局,使用@media切换样式,元素位置会变大小不变
- 响应式布局:自适应+流式布局,元素大小与位置都会变
- 弹性布局:使用rem、em布局
- 确保设计稿一样的基础上
- 使用设备宽度/font-size得到一个倍率
- 使用新设备的宽度/倍率得到新设备需要的font-size
- link用于html中,加载页面时加载,样式权重高于import
- import用于css中,会等到页面加载结束后才加载
- transition:在不同状态之间切换的过渡效果
- animation:用来指定一组或多组动画
形成条件:
-
浮动元素(float不等于none)
-
定位元素(position为fixed或absolute)
-
display为inline-block,table-cell,table-caption,flex,inline-flex的元素
-
overflow除了visible以外的值
特性:
-
会一个一个垂直摆放
-
每个bfc互不干涉
opacity:0 & visibility:hidden & display:none区别
- opacity:0 只是将元素隐藏,但是会触发点击事件
- visibility:hidden 将元素隐藏,不会触发点击事件
- display:none 将元素从布局中“抽离”
- !important
- 行间样式
- 内部样式
- 外部样式
- id选择器
- class选择器
- 元素选择器
- 伪类,伪元素
主要是两种:
- 标记清除算法
目前在 JavaScript 引擎 里这种算法是最常用的,到目前为止的大多数浏览器的 JavaScript 引擎都在采用标记清除算法。此算法分为标记和清除两个阶段,这使得一位二进制位(0和1)就可以为其标记,非常简单。
标记清除算法有一个很大的缺点,就是在清除之后,剩余的对象内存位置是不变的,也会导致空闲内存空间是不连续的,出现了内存碎片并且由于剩余空闲内存不是一整块,它是由不同大小内存组成的内存列表,这牵扯出了内存分配的问题
- 引用计数算法
这其实是早先的一种垃圾回收算法,它把对象是否不再需要简化定义为对象有没有其他对象引用它。例如定义一个变量赋值时 1,当它被另一个变量覆盖时会被 -1,当这个值的引用次数变为 0 的时候,说明没有变量在使用,清理掉内存
对比:
- 引用计数一变 0 就会被回收,所以它可以立即回收垃圾;标记是隔一段时间得执行一下 gc 程序去标记及清除
- 引用计数的存储的引用次数的这个值可能是很大的
- cookies:存放用户讯息,不安全,保存在客户端,在C/S中来回传递,保存字符串,只有4kB,同源窗口共享,有过期时间
- local storage
- 优点:H5 加入的以键值对为标准的方式,操作方便,永久存储,兼容性较好
- 缺点:保存值的类型被限定,浏览器在隐私模式下不可读取,不能被爬虫
- session storage:当前页面关闭后就会立刻清理,会话级别的存储方式
- indexedDB:H5标准的存储方式,他是以键值对进行存储,可以快速读取,适合WEB场景
跨域是指浏览器允许向服务器发送跨域请求,为什么有这个跨域,主要是同源策略。同源策略是浏览器的一个核心的安全策略,主要指"协议+域名+端口”三种需要相同,不同的话会被限制发请求、cookie 、localstorage 、dom等也无法读取
跨域方式
- jsonp 的原理就是利用 <script> 标签没有跨域限制,通过 script 标签 src 属性,发送带有 callback 参数的 GET 请求,服务端将接口返回数据拼凑到 callback 函数中,返回给浏览器,浏览器解析执行。
- Web Socket:建立永久连接。
- 前端代理
- 跨域资源共享(CORS)(Cross-origin resource sharing)。 它允许浏览器向跨源服务器,发出 XMLHttpRequest 请求,从而克服了 AJAX 只能同源使用的限制。
浏览器将CORS跨域请求分为简单请求和非简单请求。
- 请求方式 head get post
- header 头 content-type限于 application/x-www-form-urlencoded、multipart/form-data、text/plain
简单请求里会新增加一个 Origin 字段。需要传递你接口的源的信息,后端判断是否同意这次请求,对应的相应头里也会返回 Access-Control 开头的字段,Access-Control-Allow-Origin。Allow-Credentials,默认是不带 cookie,如果需要带设置成 true
不是简单请求,会多发一个预请求,预检"请求用的请求方法是 OPTIONS,表示这个请求是用来询问的。请求头信息里面,关键字段是 Origin,表示请求来自哪个源。除了 Origin 字段,预检请求的头信息包括两个特殊字段:
- Access-Control-Request-Method
- Access-Control-Request-Headers
- Nginx代理跨域和nodejs中间件跨域原理都相似
token:验证身份的令牌,一般就是用户通过账号密码登录后,服务端把这些凭证通过加密等一系列操作后得到的字符串
-
存 localStorage 里,后期每次请求接口都需要把它当作一个字段传给后台,如果存在localstorage中,容易被XSS攻击,但是如果做好了对应的措施,那么是利大于弊
-
存cookie中,会自动发送,缺点就是不能跨域 ,如果存在cookie中会有CSRF攻击
- 客户端用账号密码请求登录
- 服务端收到请求后,需要去验证账号密码
- 验证成功之后,服务端会签发一个token,把这个token发送给客户端
- 客户端收到 token 后保存起来,可以放在 cookie 也可以是 localstorage
- 客户端每次向服务端发送请求资源的时候,都需要携带这个token
- 服务端收到请求,接着去验证客户端里的 token,验证成功才会返回客户端请求的数据

- useEffect 不会 block 浏览器渲染(因为是异步执行的)而 useLayoutEffect 会(因为是同步执行的)
- useEffect 会在浏览器渲染结束后执行,useLayoutEffect 则是在 DOM 更新完成后,浏览器绘制之前执行。
- 如果页面因为转台更新导致组件重复渲染导致闪动,就可以考虑使用 useLayoutEffect
- 代码可读性更强,原本同一块功能的代码逻辑被拆分在了不同的生命周期函数中,容易使开发者不利于维护和迭代,通过 React Hooks 可以将功能代码聚合,方便阅读维护
- 不再需要去处理复杂的 this 指向问题,绑定事件
- 所有 hooks 详细介绍见:https://github.com/Joyee691/blog/tree/main/articles/React/hooks
import { lazy } from 'react';
const MarkdownPreview = lazy(() => import('./MarkdownPreview.js'));
<Suspense fallback={<Loading />}>
<h2>Preview</h2>
<MarkdownPreview />
</Suspense>
- PureComponent 用于类组件,本质上是重写了
shouldComponentUpdate方法,用来浅比较 props 和 state,如果想通则不触发更新 - memo 用于函数组件
- 它会返回包裹组件的记忆化组件,这个返回的组件会在渲染前浅比较 props 是否有变化,如果没有则不会触发更新
- memo 的记忆化与 state 与 context 无关(这两者变更仍会触发更新)
- memo 的第二个参数可以用来自定义比较函数,但是需要比较性能
-
useCallback:通过 useCallback 获得一个记忆后的函数,避免函数组件在每次渲染的时候如果有传递函数的话,重新渲染子组件。用来做性能优化。
-
useMemo:记忆组件,和 useCallback 类似,不同的是:useCallback 不会执行第一个参数函数,而是将它返回给你,而 useMemo 会执行第一个函数并且将函数执行结果返回给你
react 的 ref 有个特点,他可以贯穿组件的渲染周期,我们使用这个特性,可以把一些跟渲染无关的值使用 ref 来保存,这样更新的时候就不会触发渲染
详情见:https://github.com/Joyee691/blog/blob/main/articles/React/hooks/useRef.md
用法:子组件将自身的方法添加到父组件使用 useRef 定义的对象中
function Parent() {
const counterRef = useRef();
return (
<>
<button onClick={() => counterRef.current.click()}>Parent add one</button>
<Counter ref={counterRef} />
</>
)
}
// 加上 forwardRef
const Counter = forwardRef((props, ref) => {
const [count, setCount] = useState(1);
return (
<div>
<div>{count}</div>
<button
ref={ref}
onClick={() => setCount(prev => prev + 1)}
>
Counter add one
</button>
</div>
);
})
详情请见:https://github.com/Joyee691/blog/blob/main/articles/React/hooks/useImperativeHandle.md
- computed
- 需要重复使用的数据,可以放入computed中计算完会缓存起来
- 当computed中数据没有发生变化时只会直接取缓存
- 当需要的数据依赖于其他数据时,可以把该数据设计在computed中
- watch
- watch是data数据的监听回调
- watch在页面第一次初始化不会监听,只有数据发生改变时才会执行(除非使用immediate: true)
- deep属性:深度监听属性,他会给对象的每个属性添加监听器
- 主要功能:组件缓存,能在在组件切换过程中将状态保留在内存中避免重复渲染
- 参数:
- include:正则或数组或字符串,只有包含的会被缓存,使用正则或数组需要使用v-bind
- exclude:正则或数组或字符串,任何匹配的都不会被缓存,使用正则或数组需要使用v-bind
- max:缓存组件的最大值
- 被keep-alive包含的组件不会被再次初始化,不会重走生命周期函数
- 被包含在keep-alive中的组件会多出两个钩子函数:
- activated:keep-alive包含的组件被再次渲染时调用
- deactivated:keep-alive包含的组件被销毁时触发
- 父传子:props
- 子传父:emit
自定义事件:$emit传递,$on接
- vuex
- beforeCreate
- created
- beforeMount
- mounted
- beforeUpdate
- updated
- beforeDestroy
- destroyed
- hash模式
- 基于锚点,通过hash值的变化感知路由的变化,兼容性高,只需要客户端支持
- hash值的变化不会导致浏览器向server发出请求
- hash的改变会触发hashchange事件
- hashchange只能改变#后面的url片段
- hash是用于页面定位的
- hash传参是基于url,会收到长度的限制
- history模式
- 需要客户端与伺服器一起支持,使用history刷新会重新向后端请求,如果后端不支持页面跳转会翻404
- 切换api:back, forward, go
- 切换api无法调转到指定url,切会触发window.onpopstate事件
- 修改状态api:pushState(stateObj, title, url), replaceState(stateObj, title, url)
- 修改状态api可以跳转到指定url,如果需要监听需要自定义window.dispatchEvent()
- 加载渲染过程:父beforeCreate→父created→父beforeMount→子beforeCreate→子created→子beforeMount→子mounted→父mounted
- 子组件更新过程:父beforeUpdate→子beforeUpdate→子updated→父updated
- 父组件更新过程:父beforeUpdate→父updated
- 销毁过程:父beforeDestroy→子beforeDestroy→子destroyed→父destroyed
- 应用(DNS,DHCP,ftp,http)
- 传输(tcp,udp,监听端口提供服务)
- 网络(路由器,IP协议)
- 数据链路(信道)
- 物理(接口)
- 无状态的
- URL格式:
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag> - HTTP报文格式:起始行+首部+主体
- 请求报文:起始行(方法+请求url+版本)
- 响应报文:起始行(版本+状态码+原因)
- 首部:name:value,两个换行符结束
- 常用方法:GET,HEAD,POST,PUT,TRACE,OPTIONS,DELETE
- 状态码:1xx:信息提醒、2xx:成功、3xx:重定向、4xx:客户端错误、5xx:服务器错误
- 100:继续客户端的请求
- 200:成功
- 300:资源可包括多个位置(多语言)
- 301:永久重定向
- 302:临时重定向
- 304:资源未修改
- 400:请求语法错误
- 401:需要授权
- 404:资源未找到
- 502:网关或代理收到无效响应
- 504:网关或代理等待响应超时
#3## GET & POST
- GET 通过 url 传递、POST 放在主体中
- GET 有长度限制(浏览器做的限制)、POST 没有
- GET 不安全(被浏览器缓存,被别人查看到浏览记录)、POST 安全
- GET 只能 url 编码、POST 多种编码方式
- GET 会留下历史记录、POST 不会被保留
- GET 用户信息获取,应该是安全(只做查询)而幂等(多次请求返回相同结果)的,但还是可以增删改查
- GET 有可能导致 CSRF 攻击
- 0.9:仅支持GET
- 1.0:短连接(connection:keep-alive开启长)、支持GET,POST,HEAD
- 1.1:长连接(connection:close关闭长)、支持其余请求、增加host头部
- 2.0:多路复用(一个信道同时传输多个请求)、基于HTTPS、二进制编码
- 3.0:google开发、QUIC(Quick UDP Internet Connection)、TLS1.3、快速建立连接(区别于三次握手)、连线迁移(wifi to cellular)
- 加了SSL安全套接字(应用层与传输层之间)
- 建立安全信道
- 需要CA证书
- 端口443
- 鉴别与加密
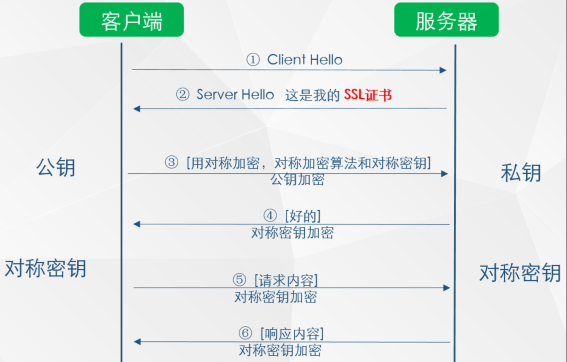
- 加密过程:
- SSL证书中包含CA,证书有效期,公钥,证书所有者,签名
- 客户端校验证书所有者,有效期,查找CA并进行比对,找到的话用CA的公钥对签名解密
- 客户端将解密的签名与证书计算hash值做对比,如果一致则可以使用正式中的公钥
- 客户端用公钥加密对称密钥,对称密钥算法
- 服务器用私钥解密并将响应用对称密钥加密
- 客户端用对称密钥解密确保上述流程没有错误
- 客户端与伺服器使用对称加密方式发送请求响应
- GET
- POST
- HEAD
- PUT
- DELETE
- CONNECT
- OPTIONS
- TRACE
- PATCH:对已知资源做局部更新
-
强缓存:直接从副本比对,不请求server,返回200
-
协商缓存:与server比对,如果相同请求副本,返回304 资源未修改
- TCP特色:无差错(可靠)、按序、数据流不分段
- 面向字节流
- 可靠传输原理:停止等待,连续自动重传(滑动窗口)
- 流量控制:滑动窗口
- 拥塞控制:慢开始(逐渐增大窗口)与拥塞避免(线性增大窗口)、快重传(对不连续发送三次重传)、快恢复(不执行慢开始)
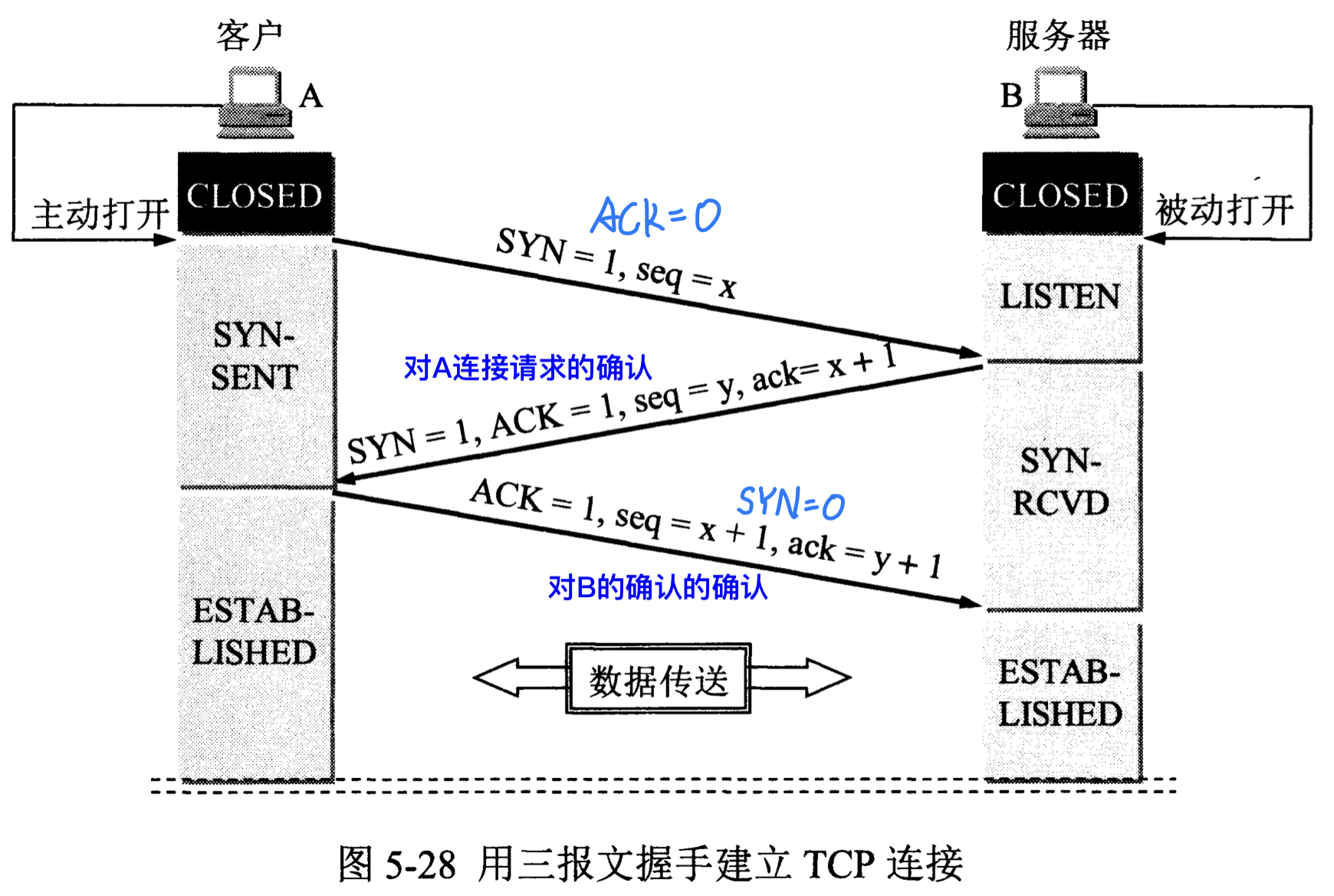
- 三次握手:
- 同步1,确认号0
- 同步1,确认号1
- 同步0,确认号1
- 面向报文
- 不可靠传输
- 常用于游戏、通话等对速度要求较高场景
- 通过植入脚本窃取信息
- 防御:对特殊字符过滤、对用户输入进行过滤、set-cookie:httponly(禁止JS访问cookie)
- 攻击者伪造网站信任的用户向网站发送恶意请求
- 防御:验证HTTP头部的Reffer(请求来源地址)、在请求地址url加上验证token、在HTTP头部添加自定义属性并验证
- 根据url去缓存寻找ip位置
- 寻找缓存(浏览器缓存→系统缓存→路由器缓存)
- 查找系统hosts文件看是否有记录
- 都没有的话查询DNS服务器取得IP地址
- 构造请求,封装至TCP包
- 如果使用PAC代理需要先跟PAC伺服器请求PAC文件后将请求发至代理
- 经过传输层→网络层→数据链路层→物理层到达伺服器
- 伺服器构造响应给浏览器
- 浏览器根据html构造DOM树,加载JS代码
- 根据css文件构造CSSOM树,与DOM树合并为渲染树
- 根据渲染树渲染页面
- 在所有请求中需要关注是否有缓存
- 反向代理可以假扮web伺服器:接受连接请求并转发给伺服器,并将server的响应返回给client
- 反向代理可以发起与多个不同server的通信,以便按需定位请求内容
- 反向代理还能提高慢速server的性能
- 正向代理例子:VPN
- PAC 文件是一个JS文件
- 其中有一个函数 FindProxyForURL
- 浏览器为请求的每条URL调用这个函数
- 函数返回的字符串说明浏览器应该到哪里请求这个URL
- 返回字符串可以是代理名称列表或者“DIRECT"字符串表示直接链接原始伺服器
网络劫持分为两种:
-
DNS劫持:(输入京东被强制跳转到淘宝这就属于dns劫持)
-
DNS强制解析:通过修改运营商的本地DNS记录,来引导用户流量到缓存服务器
-
302跳转的方式:通过监控网络出口的流量,分析判断哪些内容是可以进行劫持处理的,再对劫持的内存发起302跳转的回复,引导用户获取内容
-
DNS劫持由于涉嫌违法,已经被监管起来,现在很少会有DNS劫持
-
HTTP劫持:(访问谷歌但是一直有贪玩蓝月的广告),由于http明文传输,运营商会修改你的http响应内容(即加广告)
- 解决方法:全站HTTPS
- 能缓存的,尽量强缓存。
- 引入外部资源时不要出现超时、404的状况
- 减少HTTP请求数。
- 合理设置cookie的大小以及过期时间。
- 合理利用懒加载
- 合理利用 CDN
- 避免使用@import。 使用@import相当于将引入的css放在了页面底部,因为使用@import引用的文件只有在引用它的那个css文件被下载、解析之后,浏览器才会知道还有另外一个css需要下载,这时才去下载,然后下载后开始解析、构建render tree等一系列操作。因此使用@import会拖慢渲染的过程。
- 将样式表放在head中。 如果放在body中,可能出现在浏览器下载好css样式表之前,组件就已经加载好了的情况,这可能会导致重新渲染。
- 尽量避免使用css表达式。 如:expression((new Date()).getHours()%2 ? “#B8D4FF” : “#F08A00” ); 解析表达式和计算都需要时间。
-
尽量减少 DOM 访问
-
使用事件代理(减少 DOM 操作)
-
把脚本放在底部(加载脚本时会阻塞页面渲染)
-
合理使用节流函数和防抖函数
针对webpack打包优化主要是减少打包后的代码体积,主要的措施有:
1、进行tree-shaking
2、使用UglifyJS等插件压缩代码
3、分割代码、按需加载
我们可以使用 webpack-bundle-analyzer 这个插件来查看每部分代码的加载耗时,进而分析可以优化的地方
// TODO
- ES6 的 import 语法可以完美使用 tree shaking,因为可以在代码不运行的情况下就能分析出不需要的代码。
- ES6 Module 引入进行静态分析,故而编译的时候正确判断到底加载了那些模块
- 静态分析程序流,判断那些模块和变量未被使用或者引用,进而删除对应代码
- 核心就是去除 dead code
- 不可达代码
- 执行结果并用不到
- 某个变量只有写,但没有读
- 步骤
- Make 阶段,收集导出变量并记录到模块依赖图 ModuleGraph 变量中。
- Seal 阶段,遍历 ModuleGraph 标记模块导出变量有没有被使用。
- 生成产物时,若变量没有被其他模块使用时则删除对应的导出语句。
- 这个部门主要是做什么的?规模多大?
- 这个岗位的 hc 之后会负责哪一个部分的工作呢?有哪些技术栈?挑战在哪里?