#! https://zhuanlan.zhihu.com/p/532595774
Some single-channel source separation methods utilize downsampling to either make the separation process faster or make the NNs bigger and increase accuracy. The problem of downsampling is that the upsampling to reconstruct the audio source estimations in the original sampling rate usually comes with information loss.
Tackle this problem by introducing SFSRNet enclosing a super-resolution (SR) network. Any separation method where the length of the sequence is a bottleneck in speed and memory can be made faster or more accurate by using the SR network.
The audio source separation system takes the given audio mixture as its input and outputs
estimations: the estimations of the recovered single audio source
Downsampling has the advantages of speeding up and lowering the memory usage of the separation process. However, the issue with downsampling the input signal is that the later required upsampling process to get the original audio signal frequencies are unable to fully restore the information that gets lost during the downsampling process.
Propose a separate super-resolution (SR) network to achieve better upsampling results. Aside from the downsampled estimations, the input audio mixture in its original sampling rate is used as an additional input to improve the upsampling process.
Let us note that our SR network can be added to most existing separation methods to speed them up and make them more accurate.
Since the SR network only consists of a few convolutional layers, it is highly parallelized and its cost can be neglected compared to the overall cost of the separation. In addition, we can increase accuracy by adding more layers to the separation network to improve the separation since the downsampling process does not only save time, but also memory.
Propose the SFSRNet approach enclosing a super-resolution network to address the single-channel audio source separation problem. Our approach adopts the downsampling technique of the existing SepFormer architecture.
Main contributions:
- Improving the existing SepFormer by calculating intermediate estimations after each block to reduce the loss of information
- Introducing the SR network which can be used to improve most existing separation architectures.
T-F domain methods take the magnitude as the input of the NN and calculate a mask for each source. The resulting magnitude (mask multiplied with the magnitude of the mixture) combined with the phase of the mixture is brought back into the time-domain using the iSTFT.
Time-domain methods replace the STFT and iSTFT steps with a convolutional encoder and decoder. They operate on the waveform directly which means that magnitude and phase info are no longer decoupled.
Challenge: the sequences are too long for the NNs to cope with. DPRNN turns the seq into overlapping chunks and treats both the neighboring samples inside the chunks and the neighboring chunks themselves, as two sequences.
Tranformers consume considerably more memory when seq length increases. One recent solution is downsampling the input. We build on the downsampling solution while addressing its problem of information loss.
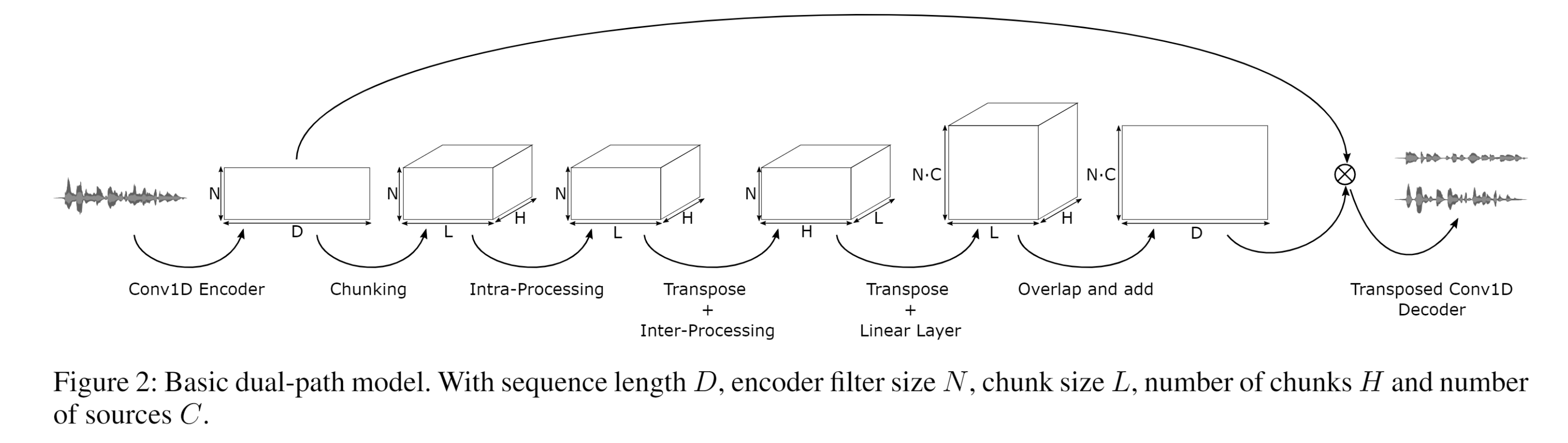
The encoder adds a second dimension to the one dimensional sequence. The idea from this step, initially introduced in TasNet, is to mimic a similar function as the STFT.
Split up one long seq into a number of shorter seqs and then stack them together. (Chunks overlap each other so that the contextual info of the sequence between each chunk can be utilized)
Intra-processing: working on the neighboring samples inside each chunk.
Inter-processing: working on the sequence of the chunks.
Intra-processing step captures local patterns, while the inter-processing step captures long term patterns.
After intra- and inter-processing, the encoder dimension size is increased by
Next, the tensor is split among the encoder dimension into
Our SFSRNet architecture is based on the dual-path model SepFormer using an encoder - separation - decoder pipeline.
Instead of using RNNs, the SepFormer uses Transformers based on Multi-Head Attention for the intra- and inter-processing. In SepFormer, downsampling is used during the encoding.
Two differences between the SepFormer and SFSRNet: calculating intermediate estimations after each block of intra- and inter-processing and including these estimations for the loss calculation; the additional step of SR.
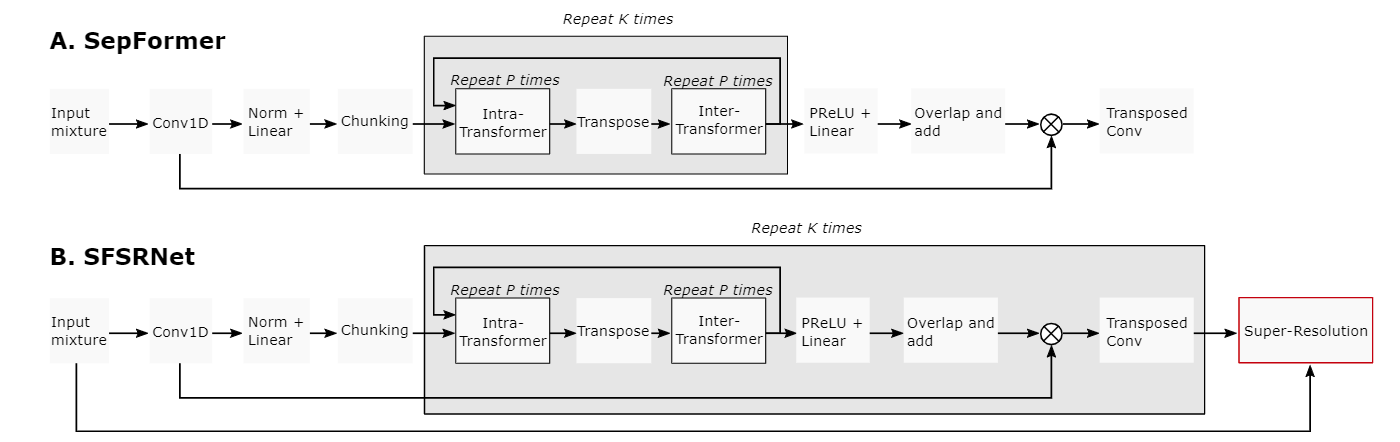
After the encoding and the chunking, the separation process begins. Both Transformer blocks are repeated
After each SepFormer block, intermittent results are calculated. This is done by multiply the channel size by
The sources these intermittent results are compared to, are increasing in resolution, meaning the first output is compared to the original source at a low sampling rate, while the last output is compared to the original source at the full sampling rate.
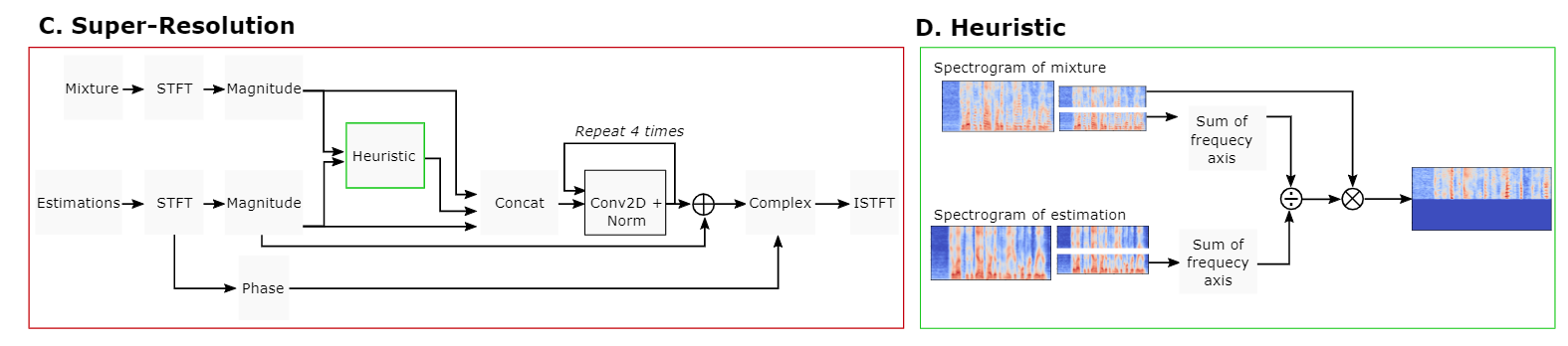
The SR step is added after the decoder. All the necessary info is contained within the mixture. Some of this info gets lost in the separation process since downsampling is used and can be reversed by taking the mixture as an input for the SR process.
The SR process operates in the freq-domain. (STFTs of the estimations for each source and the original mixture)
First, heuristics are used in an attempt to correct the magnitude of the higher frequencies.
Spectrograms are split into low and high frequencies.
For both the low and high frequency matrices, all the freq bins at each timestep are added together. This results in a sequence for the low and high frequencies. By dividing the low frequency sequence mixture by the low frequency sequence of each estimation, it can be estimated, which estimation is contributing to the mixture at each timestep. After dividing the two sequences, the next step is to take the resulting sequences and multiply them with the higher frequency matrix of the mixture. This is how the higher frequency of the corrected magnitudes of each estimation is calculated.
Then, the mag spectrograms of the mixture, the estimations and the corrected estimations are concatenated in the channel dimension and fed into the network.
Dynamic Mixing
Chunk size: 50
Adding the SR network to the SepFormer is a clear improvement in the frequencies above 1kHz.
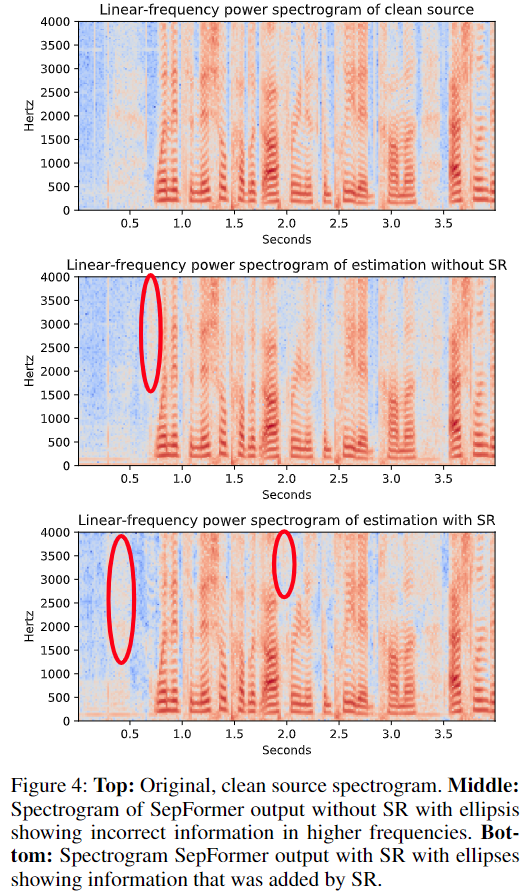
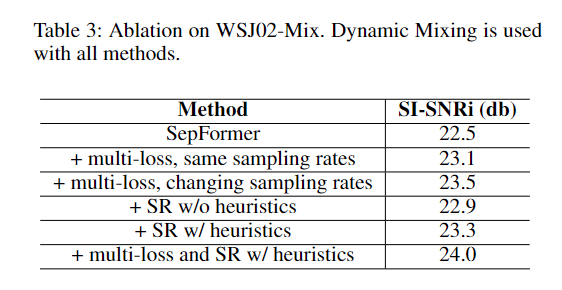
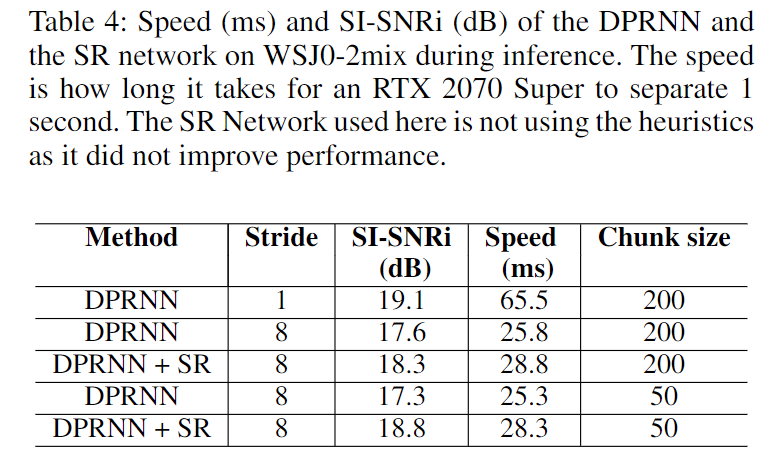 These results suggest that it is not necessary to work with the full resolution for the source separation. It makes sense to work with a downsampled representation for the separation and upsample the separated estimations using SR.
These results suggest that it is not necessary to work with the full resolution for the source separation. It makes sense to work with a downsampled representation for the separation and upsample the separated estimations using SR.
Main contribution: the SR process can improve any separation network.
Secondary contribution: the multi-loss system where the sampling rate of the solutions increases after each separation block.
A limitation of our SR implementation is operating on only the magnitude and not the phase. Finding a source separation compatible SR network which operates in the time-domain or uses phase reconstruction would be a logical next step.