You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Interrupted and Cascaded Permutation Invariant Training for Speech Separation 阅读笔记
Abstract
PIT has long been a stepping stone method for training speech separation model in handling the label ambiguity problem. With PIT selecting the minimum cost label assignments dynamically, very few studies considered the separation problem to be optimizing both model parameters and label assignments, but focused on searching for good model architecture and parameters.
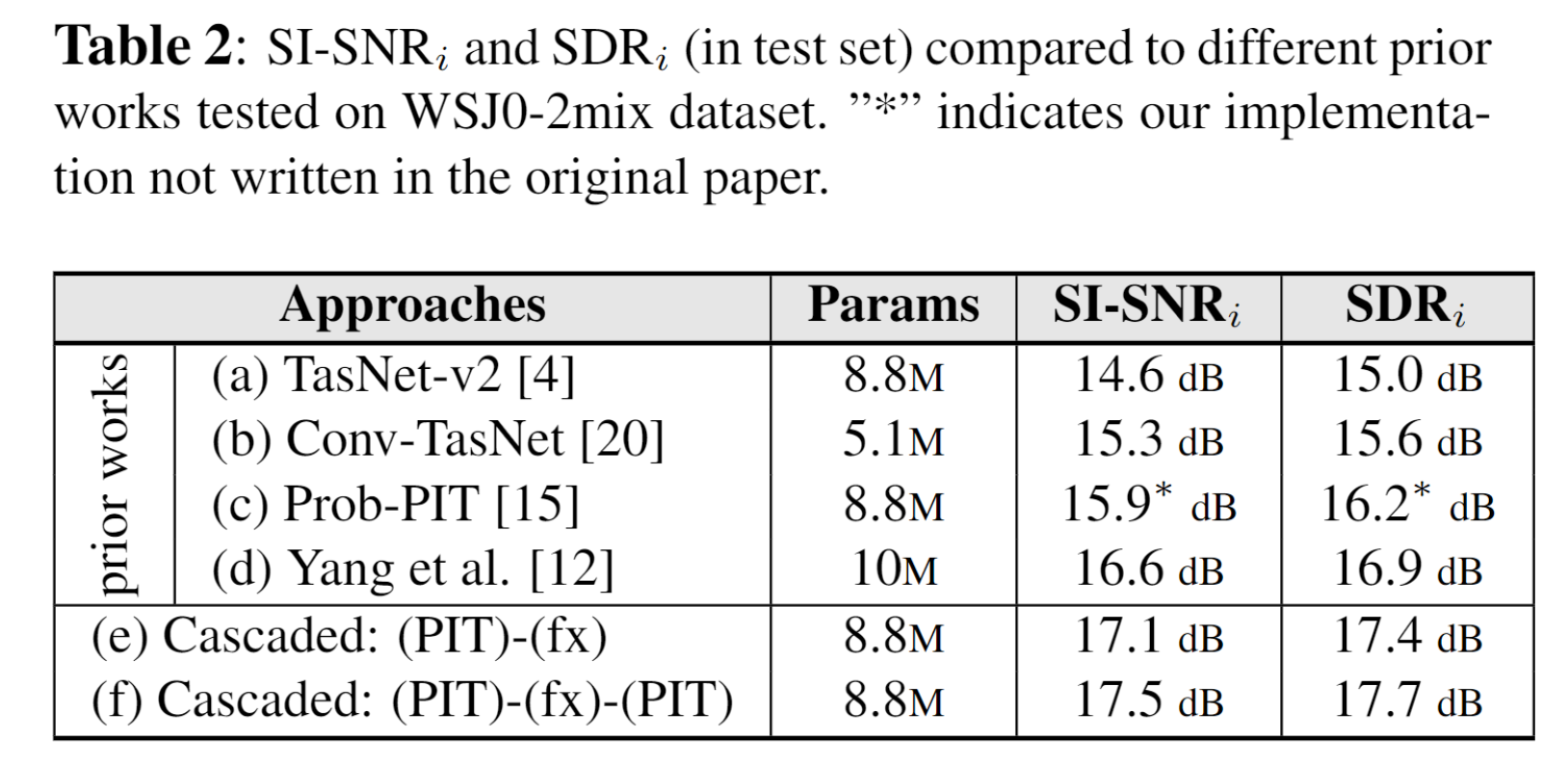
Investigate for a given model architecture the various flexible label assignment strategies for training the model, rather than directly using PIT. With fixed label training cascaded between two sections of PIT, we achieved the SOTA performance on WSJ0-2mix without changing the model architecture at all.
1. Introduction
An often used approach is to infer a mask for each individual speaker, and multiply the masks element-wise with the mixture feature map to obtain the individual feature maps.
However, these mask-inferring models often suffer from the label ambiguity problem. When the machine gives two output signals $y_{i1}(t)$ and $y_{i2}(t)$ for $x_{i}(t)$, there are two possible label assignments: $[y_{i1}(t) \rightarrow s_{i1}(t), y_{i2}(t) \rightarrow s_{i2}(t)]$ and $[y_{i1}(t) \rightarrow s_{i2}(t), y_{i2}(t) \rightarrow s_{i1}(t)]$. For computing the objective function for supervised learning, the label assignments are needed in evaluating the distances between the outputs and the ground truth. This is the label ambiguity problem.
Although DPCL seemed to have avoided this label ambiguity problem by optimizing the similarities between the embeddings of each t-f bin, Chimera++ network achieves better performance.
We verify experimentally that PIT is not a good solution, because it dynamically assigns the label to each training mixture in an epoch, and such assignments are changed from epoch to epoch. We therefore propose various strategies for more flexible label assignment, and find there can be different ways to do better than PIT.
2. PIT and its problems
In PIT, the loss function for each of the 2 (or $N!$) label assignments are computed for each mixture signal and the one with the minimum loss is chosen. The model parameters may be updated after seeing every $M$ mixtures based on the $M$ loss functions computed from the minimum loss labels for the $M$ mixtures, and the model updated $T/M$ times in each epoch ($T$ utts in the training set). In the next epoch the minimum loss label assignment for each mixture will be re-selected again. So PIT adopts dynamically selected rather than fixed label assignment from epoch to epoch.
Other inevitable problems with PIT. For example, very often in the early stage of training the relatively poor output signals may make the loss values of $N!$ possible label assignments very close in most of the training mixtures, which means the label assignment may be very random even if they were selected based on the minimum loss criterion. Also, it was found that even after 20 or 30 epochs the minimum loss label assignments for quite a high percentage of training mixtures may be reversed in two consecutive epochs, and switched back-and-forth from epoch to epoch, which implies the model parameters may be tuned toward opposite directions repeatedly.
3. Flexible label assignment strategies
Propose here to make the label assignment more flexible in various ways. A few example strategies are listed below.
3.1. Energy-based Label Assignment
Evaluate the avg energy for the two individual signals of each mixture. Simply assign the higher-energy ground truth to the first model output channel, and the lower-energy ground truth to the other, and this label assignment is fixed throughout all epochs.
3.2. Speaker-embedding-based Label Assignment
Clustering all $T\times 2$ speaker embedding vectors for single speaker utts in the training set into 2 clusters, with the constraint that the single speaker utts which are mixed into a mixture in the training set must have speaker embedding vectors belonging to different clusters since they are expected to be observed at the 2 different output channels of the separation model.
$c1, c2$: the two clusters with mean vectors $m_1, m_2$
$s_1, s_2$: the embedding vectors of two single speaker utts
$d(s, m)$: the distance between vector $s$ and $m$
The above constraint can be easily realized by assigning $[s_1 \rightarrow c_1, s_2 \rightarrow c_2]$ if $d(s_1, m_1) + d(s_2, m_2) < d(s_1, m_2) + d(s_2, m_1)$, otherwise the other way, and updating the mean vectors after all single speaker utts in the training set are assigned. This process can be iterated until converged. With the clustering results, we simply assign the single speaker utts in cluster 1 to the first model output channel, and the other to the second, and this assignment is fixed throughout all epochs.
3.3. Fixed Label Assignments Obtained with PIT
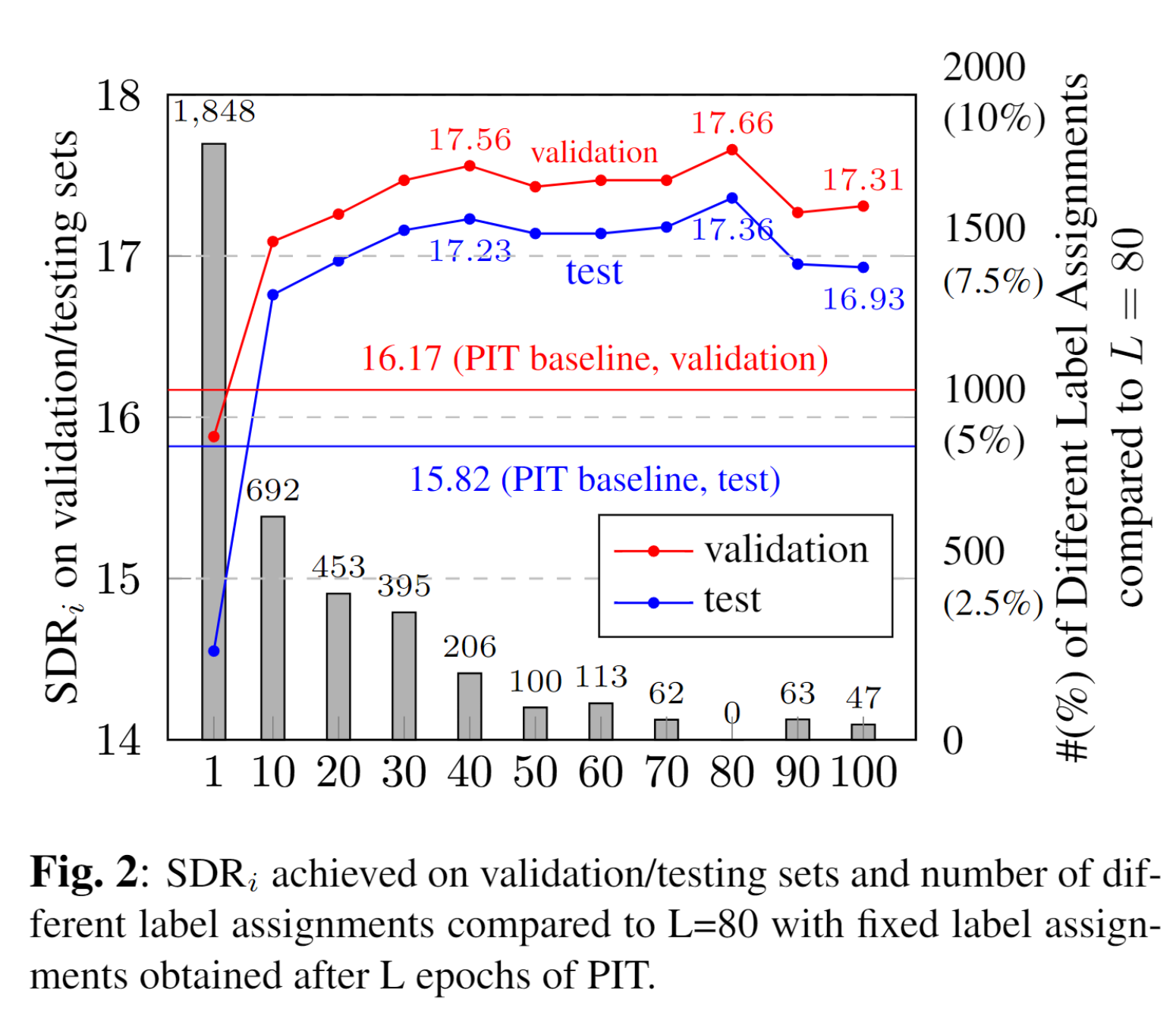
In PIT the label assignment for each mixture can be dynamically changed from epoch to epoch, here the huge number of assignment permutations are in fact an additional set of unknown parameters to be learned, and as a result with updated model parameters the label assignments can be changed. So we propose to train a model with PIT for $L$ epochs first, and record the label assignments for each mixture at the $L$-th epoch. These label assignments can be considered as good enough labels for training model parameters. So we re-initialize the model parameters and train a new separation model, but with the labels fixed as obtained above with $L$ epochs of PIT.
3.4. Interrupted PIT with Inserted Section of Fixed Label Training
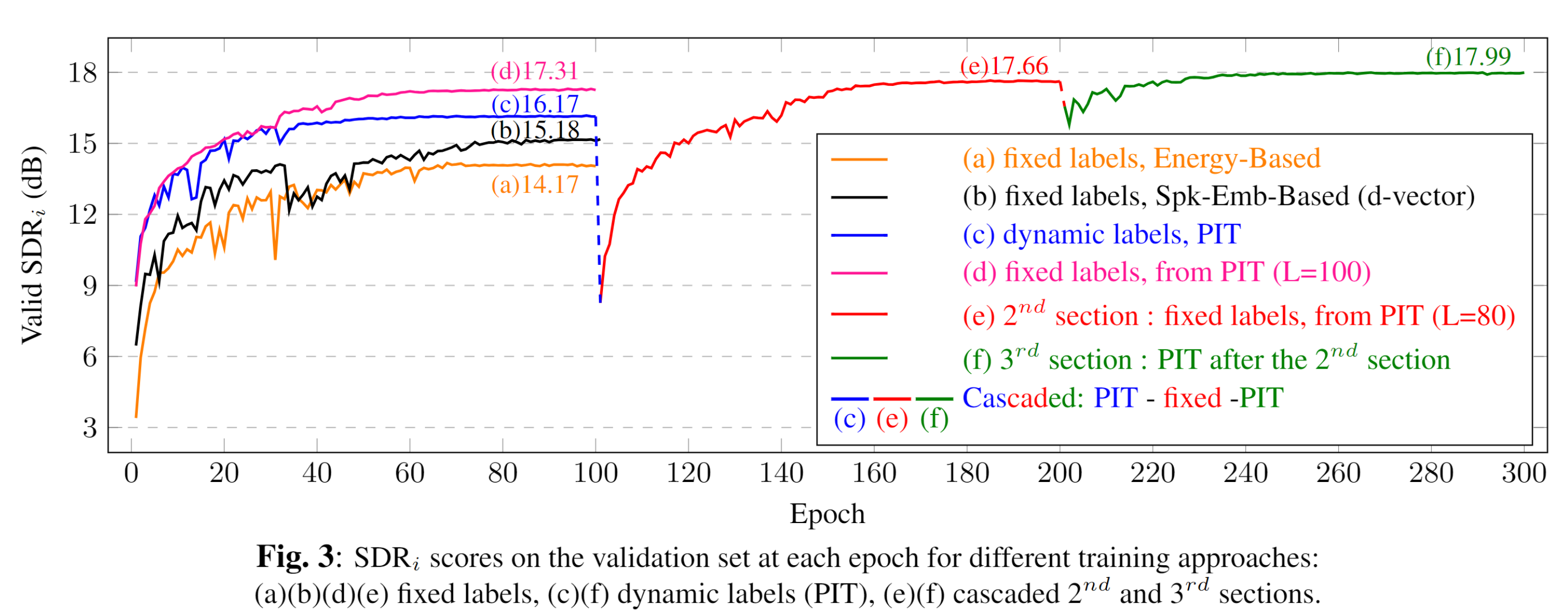
PIT followed by fixed label training as proposed in Sec. 3.3 sounds reasonable, but the set of fixed labels obtained with $L$ epochs of PIT may become inadequate after the model parameters are properly updated by the fixed label training. Therefore, we can perform a new section of PIT again to allow the label assignments to be changed dynamically again after the section of fixed label training. This may solve the poor initialization problem of PIT (during the early stage of training PIT the relatively poor outputs make the label assignments more or less random).
In this way, the training process actually includes three cascaded sections: PIT - fixed label training - PIT, or the PIT process is interrupted after the first section of $L$ epochs and inserted with the second section of fixed label training.
$\langle\cdot,\cdot\rangle$ represents the dot product
$||s||^2$ denotes the signal power
4.2. Label Assignment Switches for PIT
"Label Assignment Switches" refers to the situation that the label assignment of the same mixture was different within two consecutive epochs. We use this to analyze the problems of PIT.
We can see SDRi drops very often synchronized with jumps in label switches.
This verified those mentioned earlier that inconsistent label assignments caused unstable training, specially in the early stage of training. This is why the various flexible label assignment strategies mentioned above make sense.
4.3. Fixed Label Training
Fig. 3 (a), (b) < (c), shows fixed labels alone are inadequate, and PIT is clearly better even with unstable training due to serious label switches.
Tested different ways of obtaining the fixed labels, by PIT after $L$ epochs ($L=1,10,20,30,...,100$) in Fig. 2.
4.4. PIT cascaded with Fixed Label Training
The cascaded three sections of PIT - fixed label training - PIT is actually curves Fig. 3(c)(e)(f)
4.5. Summary of the Results
The last column is the percentages of labels out of all the $T$ training mixtures for which the fixed labels or finally obtained labels are different from the best results (epoch 300 at the end of curve (f)).
Propose to train a separation model by interrupted and cascaded PIT with a fixed label training section inserted in the middle, whose label assignments are obtained by the first section of PIT training. This verified that the label assignments obtained by PIT are good for fixed label training, and a well trained model is also beneficial for further PIT training.

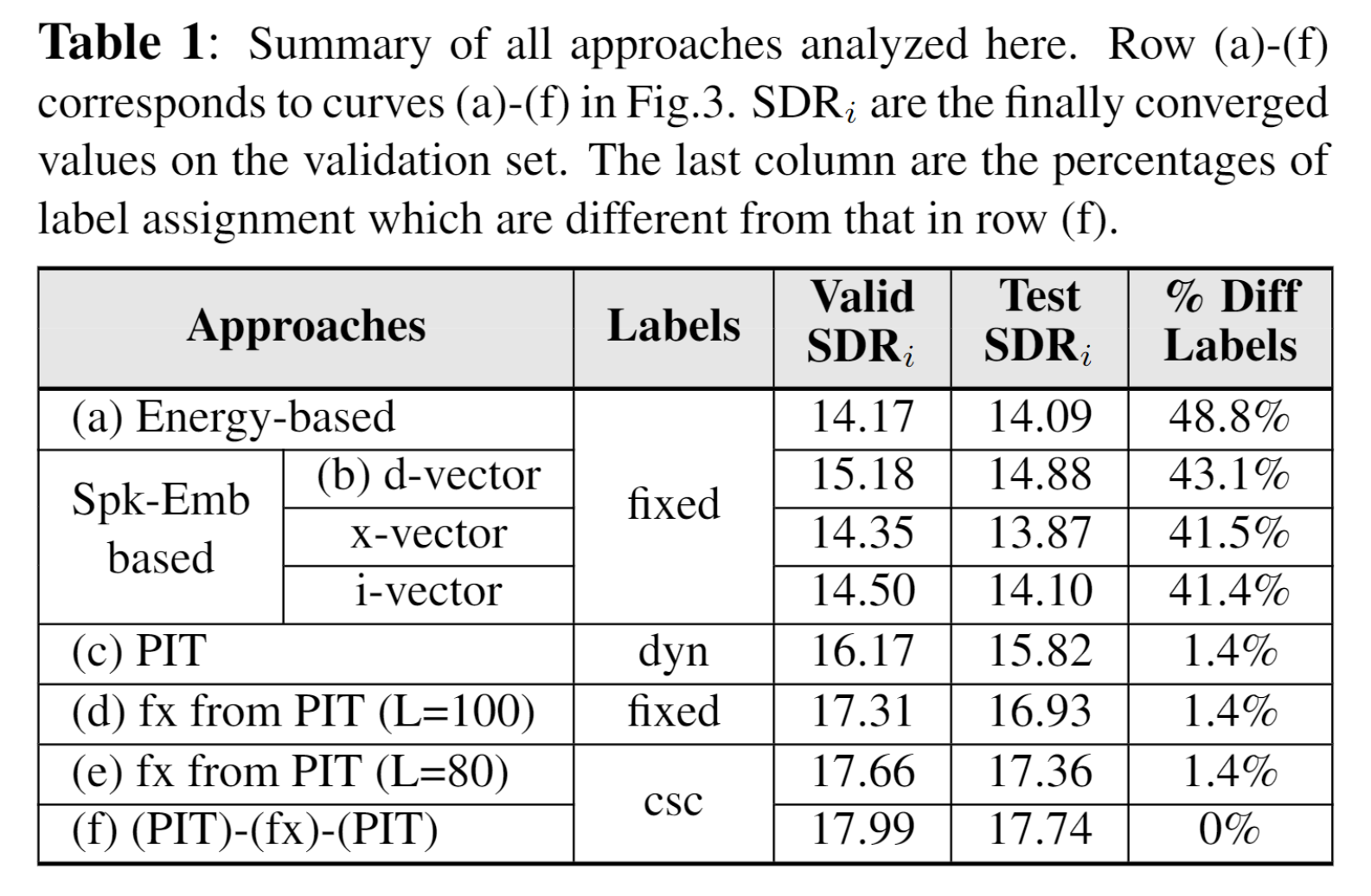 The last column is the percentages of labels out of all the
The last column is the percentages of labels out of all the