#! https://zhuanlan.zhihu.com/p/516114006
This paper examines the use of Conformer architecture in lieu of recurrent neural networks for the separation model. Conformer allows the separation model to efficiently capture both local and global context info, which is helpful for speech separation.
When applied to acoustically and linguistically complicated scenarios such as conversation transcription, the ASR systems still suffer from the performance limitation due to overlapped speech and quick speaker turn-taking. The overlapped speech causes the so-called permutation problem.
LibriCSS (continuous speech separatoin) dataset consists of real recordings of long-form multi-talker sessions that were created by concatenating and mixing LibriSpeech utterances with various overlap ratios.
Speech separation's goal: estimate individual speaker signals from their mixture, where the source signals may be overlapped with each other wholly or partially.
$$
y(t) = \sum_{s=1}^Sx_s(t)
$$
Multi-channel setting:
$$
Y(t,f) = Y^1(t,f) \oplus IPD(2)... \oplus IPD(C)
$$
IPD$(i)$: the inter-channel phase difference between the
Estimated masks
Estimated source STFT
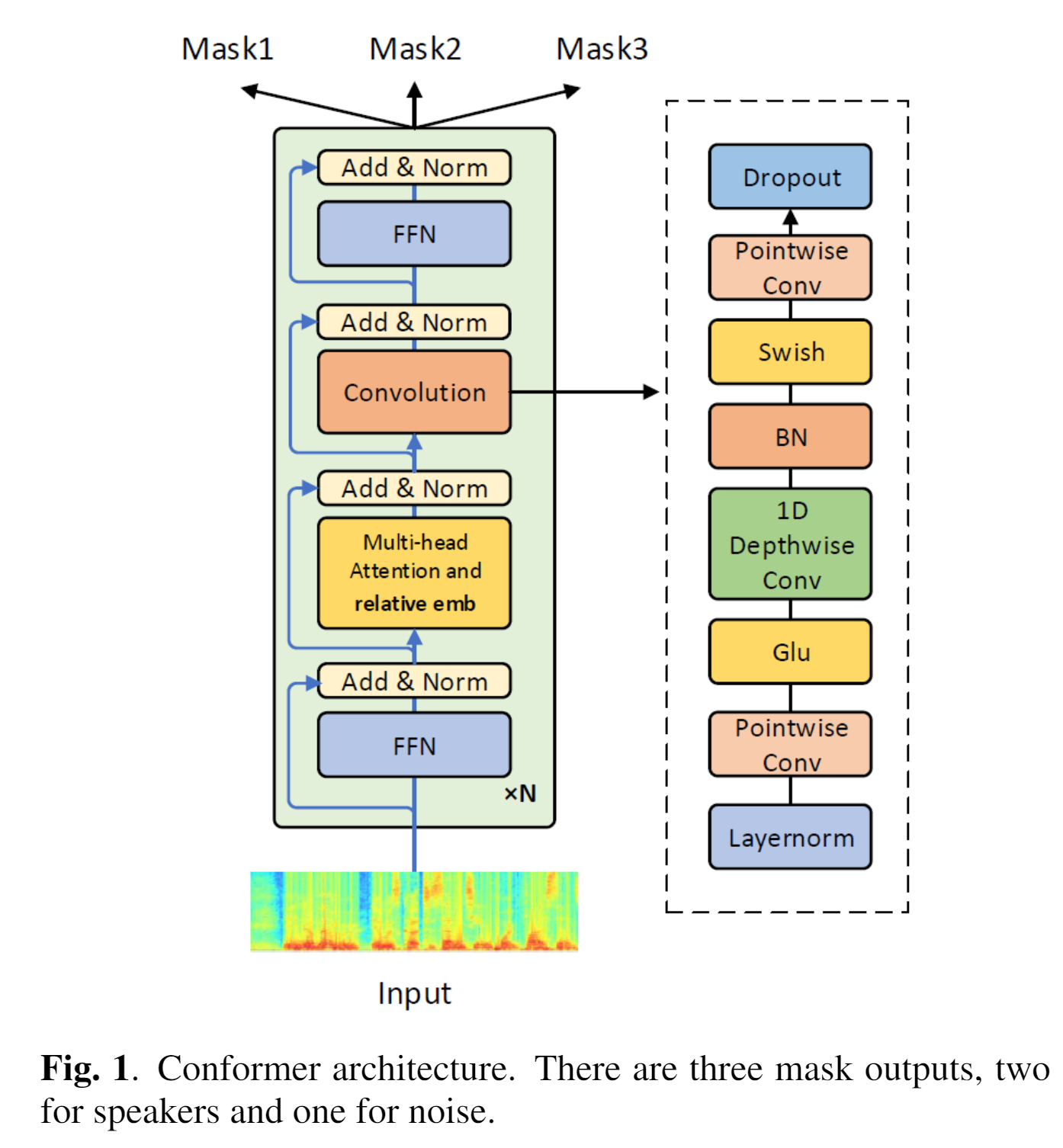
Each conformer block consists of a self-attention module, a convolution module, and a macron-feedforward module. A chunk of
To deal with such long input signals, CSS generates a predefined number of signals where overlapped utterances are separated and then routed to different output channels.
To enable this, we employ the chunk-wise processing proposed in [Recognizing overlapped speech in meetings: A multichannel separation approach using neural networks] at test time. A sliding-window is applied as illustrated in Fig.2, which contains 3 sub-windows, representing the history (

Follow the LibriCSS setting for chunk-wise CSS processing, where
To further consider the history info beyond the current chunk, we also take account of the previous chunks in the self-attention module.
7-channel The average overlap ratio of the training set is around 50%.

Conformer-base yielded substantial WER gains and outperformed Transformer-base, which indicates Conformer's superior local modeling capability. Larger models achieved better performance in the highly overlapped settings.
The Conformer-base obtained better WER gains for continuous input because they are good at using global info while the chunk-wise processing limits the use of context info.
Because the speech overlap happens only sporadially in real conversations, it is important for the separation model not to hurt the performance for less overlap cases.