#! https://zhuanlan.zhihu.com/p/573453709
The multi-channel approaches have attracted much research attention due to the benefit of spatial information. In this paper, integrated with the power spectra and inter-channel spatial features at the input level, we explore to leverage directional features, which imply the speaker source from the desired target direction, for target speaker separation. In addition, we incorporate an attention mechanism to dynamically tune the model's attention to the reliable input features to alleviate spatial ambiguity problem when multiple speakers are closely located.
Speech separation, which is to isolate an observed mixture speech signal to an individual, contiguous and intelligible stream for each speaker, has been widely studied for decades.
In most of these works, speaker-independent features such as spectral features (e.g., log power spectra) and spatial features (e.g., IPD) are fed into the network. The output speakers' identities remain unknown. However, in most of real applications, only one or a few desired speakers are of interest. The speaker-dependent information is thereby needed for separating interested speakers from the mixture.
A simple yet effective feature is the voice characteristics. VoiceFilter separates the voice of a target speaker from multi-speaker signals, by making use of a reference signal from the target speaker. Although the voice characteristics based methods have been proven successful for extracting target speaker, a common limitation is that they all require the prior knowledge about the ref signal.
Another speaker-dependent info is sound location. The phase ambiguities creates difficulties for precisely discriminate one speaker from another in certain frequency bands.
With the DOA info, beamforming techniques can be applied to enhance the speaker from the desired direction. Although impressive improvement is achieved with the directional features, it is a 2-stage system with high computational complexity.
In this paper, we perform target speaker separation by making use of directional features in a neural network model, named Neural Spatial Filter. Two novel directional features are properly designed based on fixed beamformer outputs, which are then integrated with the conventional multi-channel speech separation training features (e.g., power spectra and IPD) at the input level for target speaker separation training. Furthermore, we introduce an attention mechanism to alleviate the spatial ambiguity issue that the performance of multi-channel speech separation drastically degrades when the speakers locate close to each other. In this case, the spatial and directional features become less discriminative.
With some or all of the target speaker directions, features of specific speaker-dependent direction could be extracted to improve the performance of separation further.
This paper assumed that the oracle location of each speaker is known by the separation system, this is a reasonable assumption in some real applications, for example, the speaker location could be detected by face detection techniques with very high accuracy.
A location-guided feature for speech separation was introduced in [Multi-channel overlapped speech recognition with location guided speech extraction network], which measures the cosine distance between the steering vector, which is formed according to the direction of target speaker and IPD:
$$
\mathrm{AF}\theta(t, f)=\sum{k=1}^K \frac{\mathbf{e}{\theta, k 1}(f) \frac{\mathbf{Y}{k 1}(t, f)}{\mathbf{Y}{k 2}(t, f)}}{\left|\mathbf{e}{\theta, k 1}(f) \frac{\mathbf{Y}{k 1}(t, f)}{\mathbf{Y}{k 2}(t, f)}\right|}
$$
where $\mathbf{e}{\theta, k 1}(f)$ is the steering vector coefficient for target speaker from $\theta$ at frequency $f$ for first mic of $k$-th pair, and $\mathbf{Y}{k 1}(t, f) / \mathbf{Y}_{k 2}(t, f)$ is the IPD between
We propose two new directional features, Directional Power Ratio (DPR) and Directional Signal-to-Noise Ratio (DSNR), based on the output power of multi-look fixed beamformers. For a given mic array and a pre-defined direction grid
We can use the processing output power of $\mathbf{w}p(f)$ as a reasonable estimation of the signal power from direction $\theta_p$. Therefore, the DPR can be considered as an indicator of how well is a T-F bin $(t,f)$ dominated by the signal from direction $\theta_p$, defined as follows:
$$
\operatorname{DPR}{\theta_p}(t, f)=\frac{\left|\mathbf{w}_p^H(f) \mathbf{Y}(t, f)\right|2^2}{\sum{k=1}^P\left|\mathbf{w}_k^H(f) \mathbf{Y}(t, f)\right|_2^2}
$$
In most of the beam-pattern design techniques, there are multiple nulling areas by each fixed spatial filter. E.g., signals from the neighborhood of
 The proposed DPR and DSNR can clearly provide cues for separating target speech from the interference.
The proposed DPR and DSNR can clearly provide cues for separating target speech from the interference.
Spatial overlapp issue is mainly caused by the increasing dependency that network has on spatial features, since spatial features are more discriminative than spectral features under large angle difference (AD).
To tackle this issue, we apply an attention mechanism to guide the network to selectively focus on spectral, spatial or directional features under different ADs. The attention is a function of the angle difference 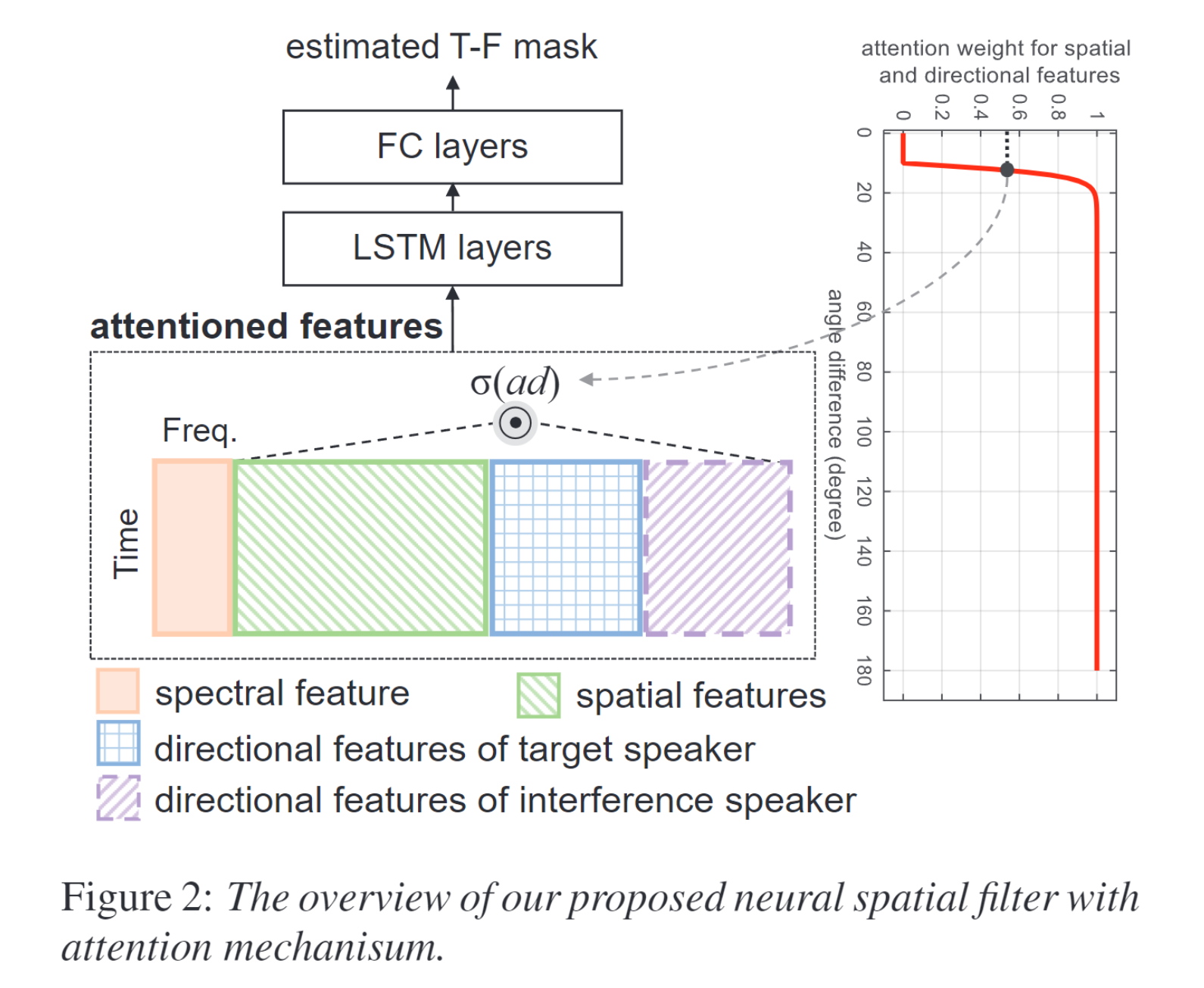 Figure 2 illustrates our proposed neural spatial filter and feature formulation with attention mechanism. On the right is the attention curve under different ADs. Spectral, spatial and directional features are concatenated along freq axis.
Figure 2 illustrates our proposed neural spatial filter and feature formulation with attention mechanism. On the right is the attention curve under different ADs. Spectral, spatial and directional features are concatenated along freq axis.
It's difficult to assign reference labels for the network outputs, and the order of which can be arbitrary. PIT tackled this problem by calculating spectrogram estimation errors between all pairs (
While for single target extraction, we exploit target extraction training (TET). When there are more than one targets, the order of directional features can indicate the output order of target speakers.
IPDs are extracted between mic pairs (1, 4), (2, 5), (3, 6), (1, 2), (3, 4), (5, 6). These pairs are selected considered that the distance between each pair is either the furthest or nearest. For DPR and DSNR computation, we use 36 fixed spatial filters and the
The reverberant speech of each source is used as reference to compute the metric. The performances are evaluated under different range of ADs between speakers.
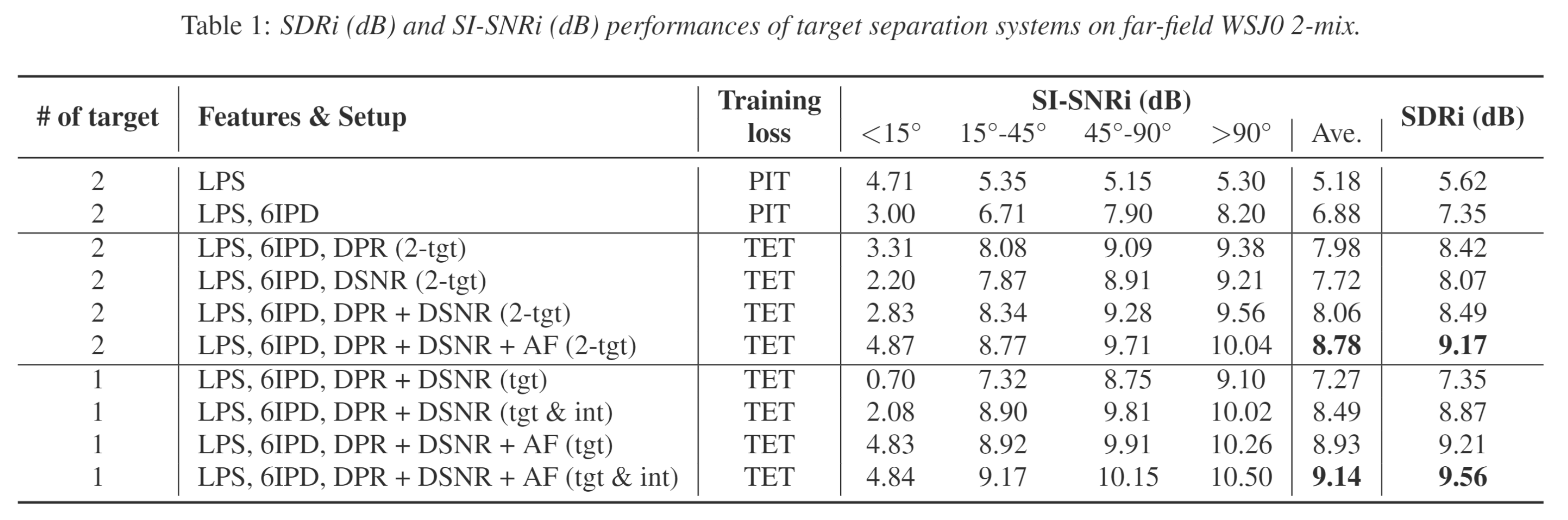
worth further reading for writing.
In this paper, directional information is used to separate the target voice given its direction. Two directional features are designed and incorporated with spatial and spectral features to provide more complementary info for training our separation network. Furthermore, an attention mechanism is proposed to improve performance when multiple speakers are closely located.