#! https://zhuanlan.zhihu.com/p/575366978
This paper reviews the most recent models of multi-channel PIT, investigating spatial features formed by mic pairs and their underlying impact and issue, presenting a multi-band architecture for effective feature encoding, and conduct a model integration between single-channel and multi-channel PIT for resolving the spatial overlapping problem.
The far field speech processing suffers from the reverberation which blurs speech spectral cues and degrades the single-channel speech separation.
An array of mics provides multiple recordings, which contain information indicative of the spatial origin of a sound source. The use of spatial info afforded by an array as features in DL is a straightforward extension to the DL models originally designed for monaural speech separation.
3 contributions:
- Reveal a "spatial overlapping" issue existed in the conventional multi-channel end-to-end PIT framework that multi-channel approaches fail when source speakers are closely located.
- By considering phase wrapping issue in spatial features, propose a multi-band PIT in which multi-band embeddings are generated with a multi-tower neural network in which each tower is trained for encoding features in an individual sub-band.
- Present a model that integrates the single-channel and multi-channel utt-based PIT for solving the spatial overlapping problem.
In general, the two most prominent ways for extending to multi-channel PIT are either converting the multi-channel inputs to single-channel features by means of beamformers so that they could fit the single-channel PIT model, or incorporating spatial features together with spectral features for the separation model training as an end-to-end approach.
Recent studies in [Multi-microphone neural speech separation for farfield multi-talker speech recognition, Integrating Spectral and Spatial Features for Multi-Channel Speaker Separation] compute phase differences between mic pairs and incorporate spatial features in the training scheme to discriminate one source from another through their location differentials.
Spectral features (e.g. LPS) of a ref mic can be tightly integrated with spatial features to improve the system's robustness to the "spatial overlapping" problem when speakers are closely located, in which case the spatial features fail for source discrimination. Unfortunately, even equipped with spectral features, we found out that multi-channel PIT does not perform well in spatial overlapping scenarios when the two speakers' directions are less that 15$^{\circ}$ apart from each other. This situation is even worse when the number of enrolled mic pairs increases. The monaural model's performance may serve as the upper-bound for the multi-channel models under this circumstance. It indicates from the observation that spatial features may play an overwhelming role in the model training as the source separation task is easier while relying on spatial difference of speaker sources than their spectral characteristics in most cases. Therefore, the model is over adapted to fit spatial features rather than pursuing a balance between the two, and thus fails at the spatial overlapping case. Increasing the size of training set in the category 0$^{\circ}$ ~ 15$^{\circ}$, i.e. with more spatial overlapped speakers in the training set, does not help to achieve better performance.
A variety of inter-channel spatial features including IPD, cosIPD & sinIPD and GCC have been utilized for the multi-channel model training. The main disadvantage of the estimated phase difference is the potential phase wrapping in high frequencies, particularly when the microphone spacing is not sufficiently small. The occurrence of phase wrapping is common when the mic spacing exceeds
In practice, wide spacing of microphones is required to enhance DOA resolution. For two mics of 7cm spacing as an example, phase wrapping occurs at around 2.5kHz [More detail]. This implies that IPDs in high freq bands, no matter in which form they are operated, may have ambiguities and thus are not effective for discriminating sources in terms of their spatial info.
As shown in Fig. 1, multiple RNN towers are jointly trained to generate individual subband embeddings from the corresponding subband input features. Therefore, those subbands with reliable spatial features could leverage them to boost the embedding learning, while high freq subbands learn to attend more on their spectral features. The dimension of each subband embedding remains the same as the conventional full-band embedding's.
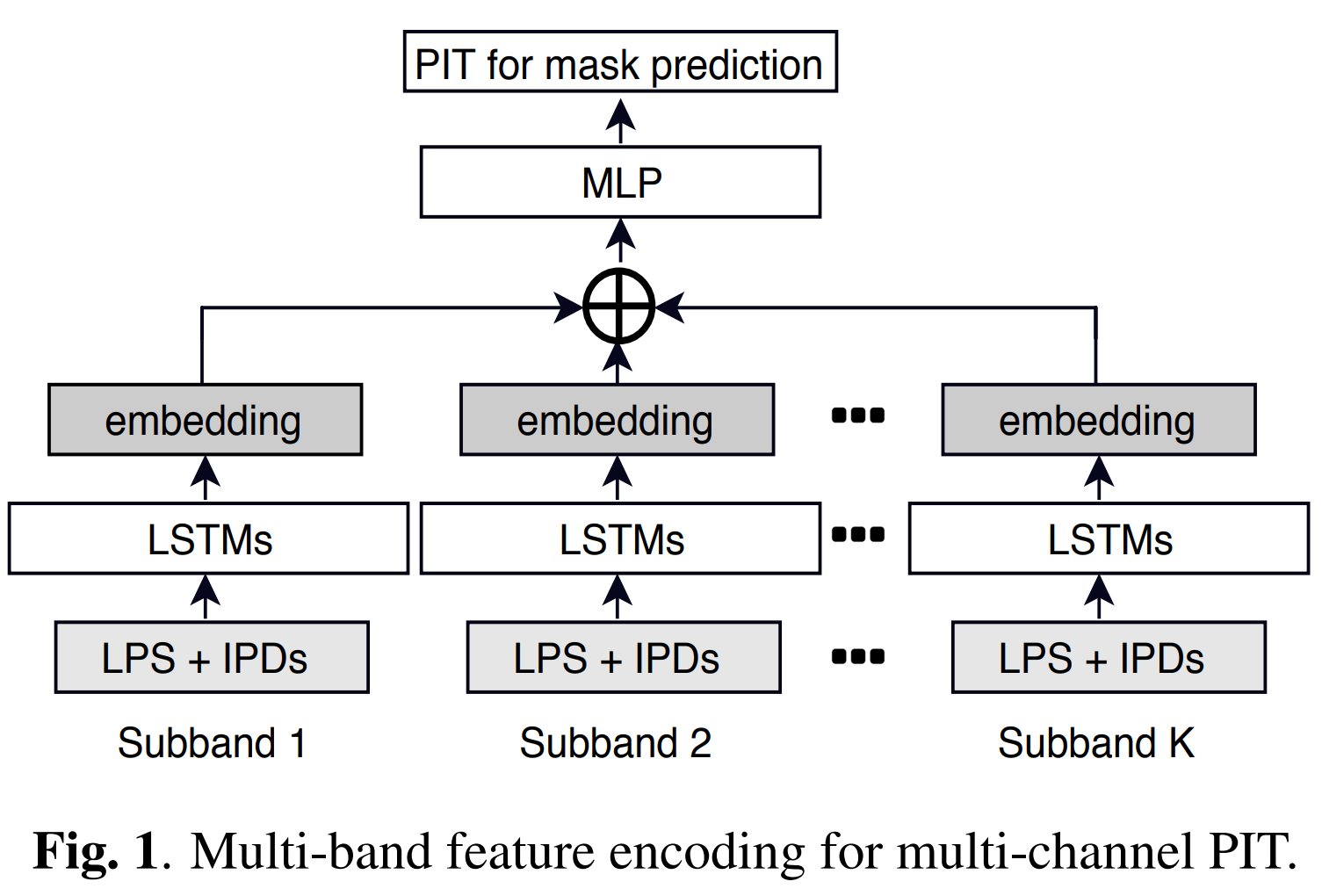
Conventional multi-channel training does not generalize well to the spatial overlapping cases in which spatial cues are ineffective while spectral cues are not selectively attended. Propose a simple yet effective algorithm to address the spatial overlapping issue existing in the multi-channel feature encoding and model training. In a multi-task learning framework, the prediction of speakers' relative location is jointly trained on the shared embedding with the multi-channel speech separation model to infer if the included angle of two speakers on the horizontal plane is less than 15$^{\circ}$, i.e., spatial overlapping.
As shown in Fig. 2, with multi-band feature encoding, multi-channel PIT has its own objective while its embedding with spatial features encoded benefits the task of spatial overlapping prediction. Straightforwardly, the monaural PIT is employed if an utt is identified with spatial overlapped speakers in the testing phase, otherwise the integrated system switches to operate on the multi-channel PIT.
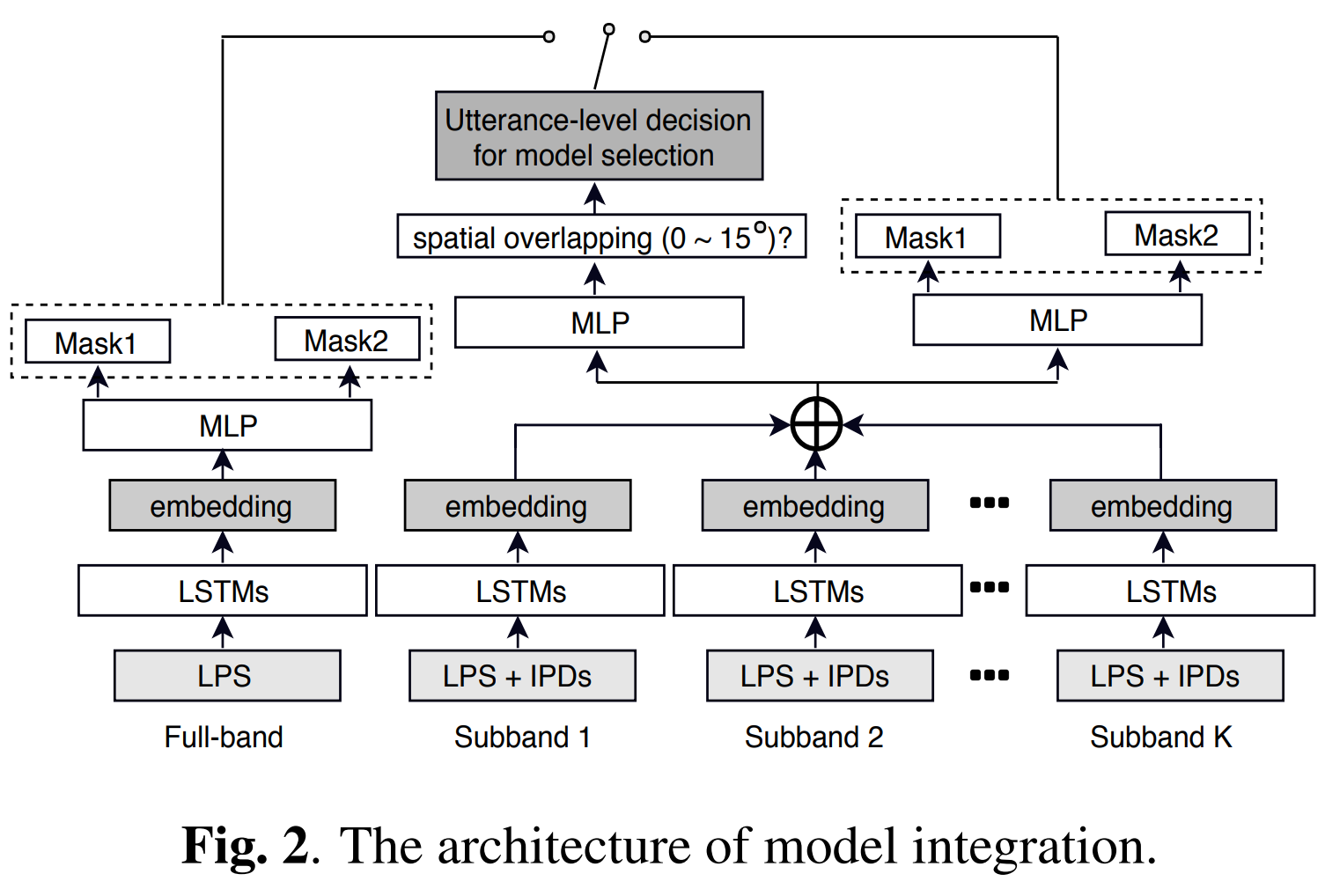
The limitation of the conventional multi-channel PIT employed in [Multi-microphone neural speech separation for farfield multi-talker speech recognition, Integrating Spectral and Spatial Features for Multi-Channel Speaker Separation] on spatial overlapping cases can be observed from the results in category 0$^{\circ}$~15$^{\circ}$.
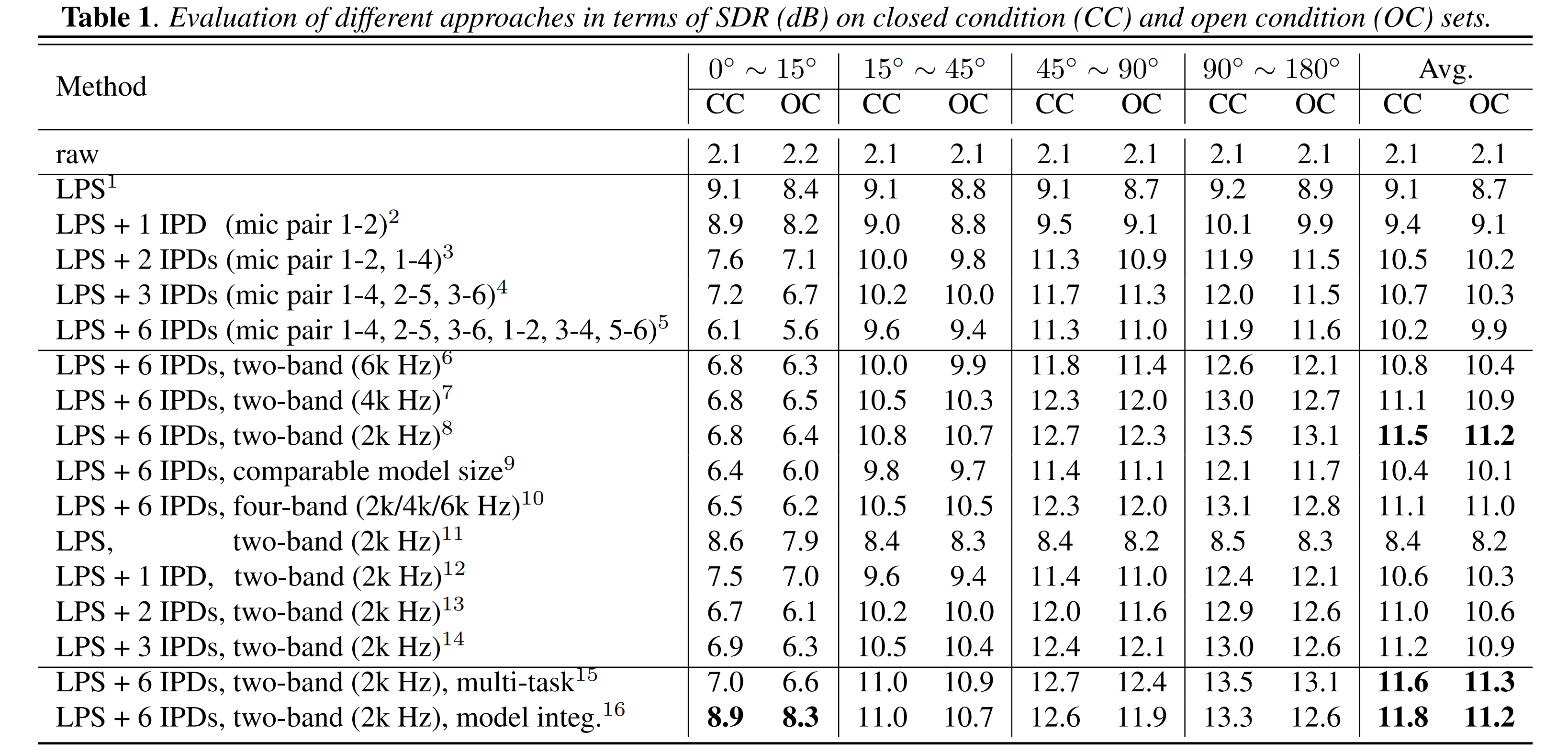
Reveal 2 underlying issues in the end-to-end multi-channel PIT: phase wrapping and spatial overlapping. A multi-band PIT for effective feature encoding is proposed to minimize the impact of phase wrapping in spatial features. Furthermore, an integrated PIT system leverages both single-channel and multi-channel models, leading to the significantly improved performance, particularly for the multi-talker mixtures of the spatial overlapped sources.