#! https://zhuanlan.zhihu.com/p/465365146
Present a multi-mic speech separation algorithm based on masking inferred from the speakers DOA. Each TF bin is dominated by a single speaker, therefore associated with a single DOA. (W-disjoint orthogonality)
Apply a DNN with a U-net architecture to infer the DOA of each TF bin from a concatenated set of the spectra of the microphone signals. Separation is obtained by multiplying the reference microphone by the masks associated with the different DOAs.
Spatial information, namely the attenuation and the time-delay between each of the sources' positions and a microphone pair, were utilized to estimate the separation mask in the degenerate unmixing estimation techinique (DUET) approach.
In [Distant speech separation using predicted time–frequency masks from spatial features] a DNN is applied to spatial features to infer a DOA-based mask, which is then used as a post-filtering stage at the output of a delay-and-sum beamformer.
In [Localization based stereo speech source separation using probabilistic time-frequency masking and deep neural networks] a group of DNNs, each applied in a different frequency band, is trained to predict a mask from spatial features. This info is then aggregated to generate a soft mask which is used for the final speech separation.
In [Unsupervised deep clustering for source separation: Direct learning from mixtures using spatial information] an unsupervised deep clustering approach was applied to multiple mixtures of sources in a training stage. The trained DNN was then applied to the test mixture to predict the separating masks.
In [Bootstrapping single-channel source separation via unsupervised spatial clustering on stereo mixtures], a single-channel deep clustering network was trained in a supervised manner, where the supervision was obtained by a multichannel segmentation network.
We train a U-net to classify each TF bin of the multichannel STFT image to one of the DOA candidates.
(The NN uses the microphone signals to infer the DOA at each TF bin of a given time-frequency image.)
A. The separation algorithm
The crux of our speech separation method is to estimate the DOA for each TF bin by a neural network and then separate the speakers by grouping these bins according to their estimated DOA.
Usually, network input is a
We have chosen to substitute the raw microphone signals with the phase of the instantaneous relative transfer function (RTF) estimate, calculated as the phase of the bin-wise ratio between the $m$th microphone signal and the reference microphone signal.
Input: Phase map of the RTF between each mic pair (an
ref: the reference microphone
Overlap between successive STFT frames is set to 75%. Used an average of three consecutive frames for
Form the DOA estimation as a classification task by discretizing the possible angles to be in the set
image-to-image DOA prediction task is implemented by a U-net.
The estimated mask of the $i$th speaker is the U-net output
Estimating the DOA is modeled as a classification problem instead of a regression task. We are not interested in finding the exact DOAs of the speakers in the scenario but rather, grouping them into distinct directions. That is, even with inaccurate DOA estimate, the speech separation can still work, provided that most TF bins are clustered to a mutually exclusive classes.
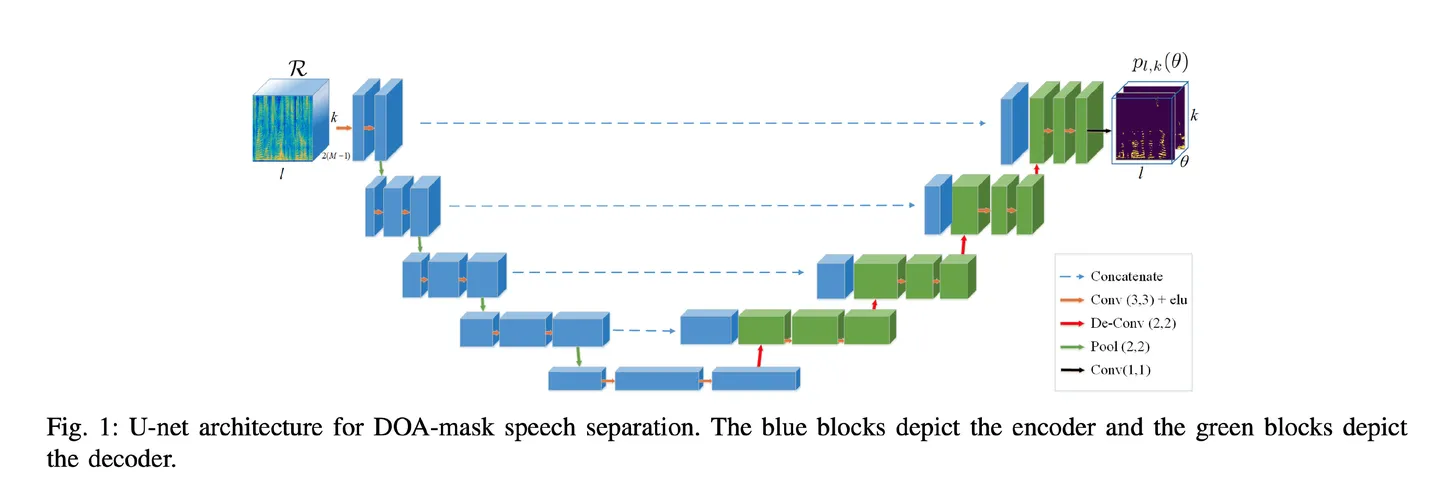
B. The U-net for DOA estimation
The input to the network is the feature matrix
The U-net connects between mirrored layers in the encoder and decoder by passing the information without going through the bottleneck (pooling / downsample operations) and thus, alleviating the information loss problem.
To train the network we use a simulated data where both the location and a clean recording of each speaker are given. We can thus easily find for each TF bin
The network is trained to minimize the cross entropy between the correct and the estimated DOA. The cross entropy cost function is summed over all the images in the training set.
A. Training database
Randomly selected two clean signals from WSJ database
Randomly selected two different DOAs from the possible values in the range
Locate the speakers in a radius of
Training set: 2 hrs of recordings with 6000 different scenarios of mixtures of two speakers.
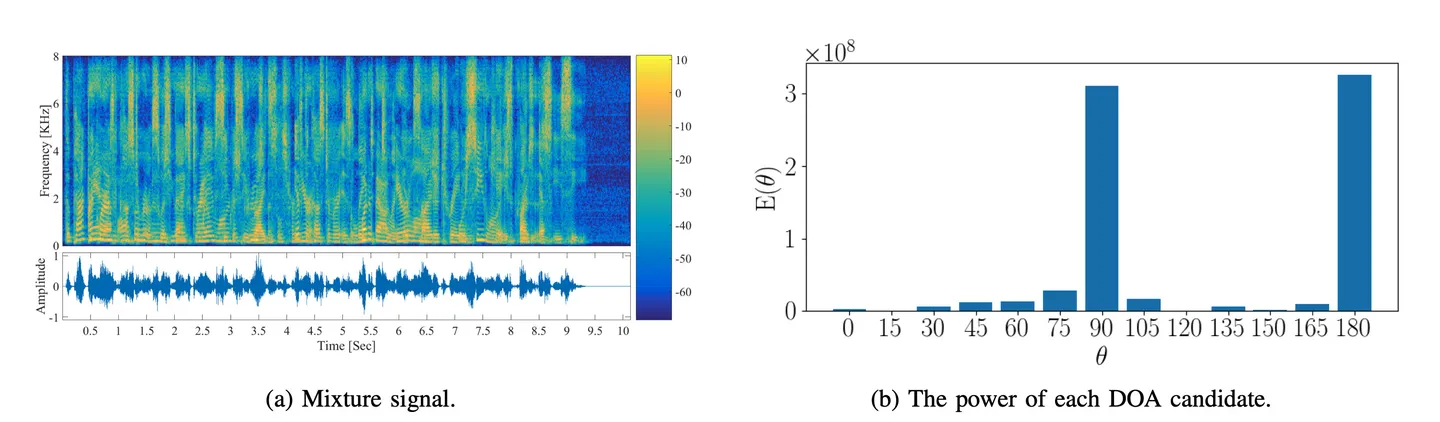
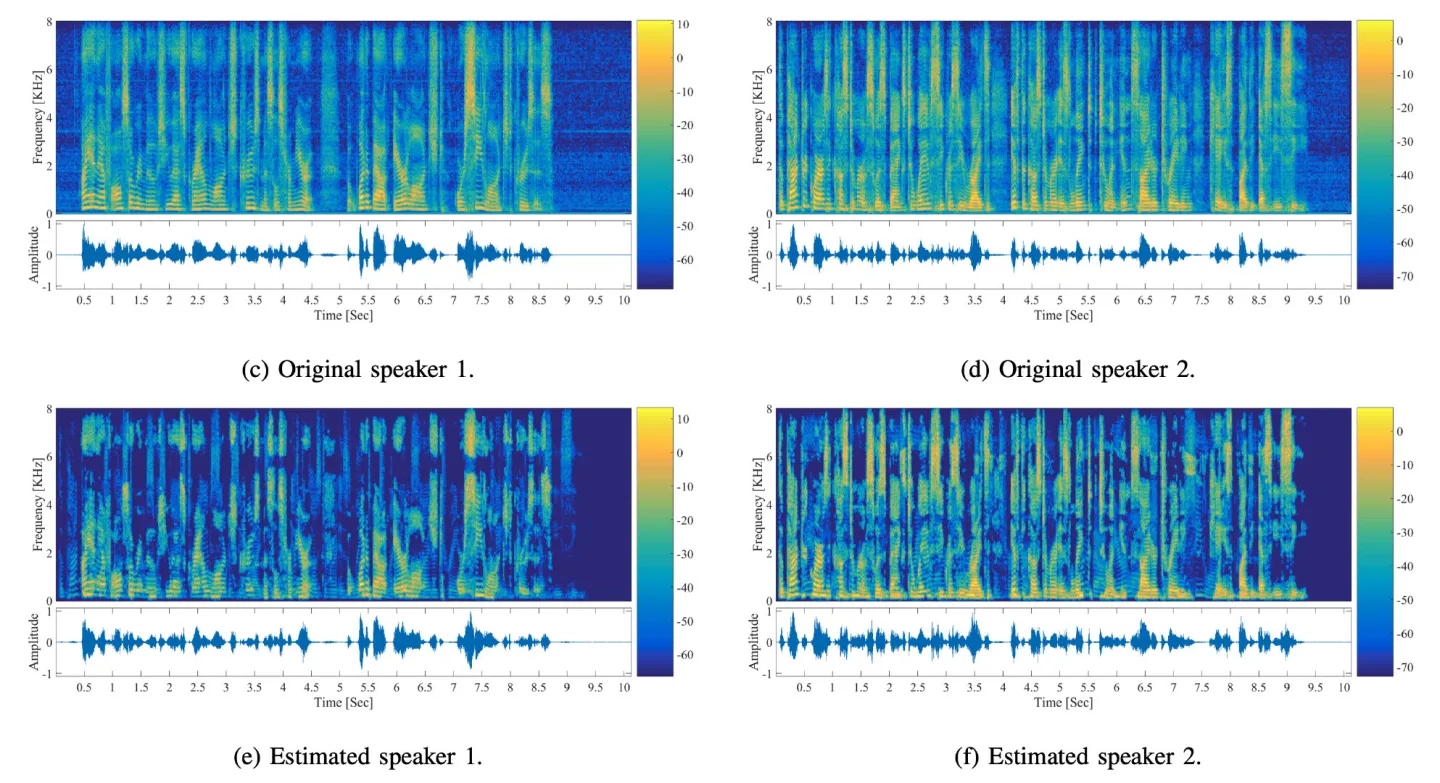
B. Separation Results
For each test scenario, we selected two speakers (male or female) from the test set of the TIMIT database, placed them in two different angles between 0° and 180° relative to the mic array, at the distance of either 1m or 2m.