#! https://zhuanlan.zhihu.com/p/583476450
Previously proposed SpeakerBeam exploits an adaptation utt of the target speaker to extract his voice characteristics that are then used to guide a neural network towards extracting speech of that speaker. SpeakerBeam presents a practical alternative to speech separation as it enables tracking speech of a target speaker across utts, and achieves promising speech extraction performance. However, it sometimes fails when speakers have similar voice characteristics, such as in same-gender mixtures.
In this paper, we investigate strategies for improving the speaker discrimination capability of SpeakerBeam. First, propose a time-domain implementation of SpeakerBeam similar to TasNet. Besides, we investigate (1) the use of spatial features to better discriminate speakers when mic array recordings are available, (2) adding an auxiliary speaker identification loss for helping to learn more discriminative voice characteristics. We show experimentally that these strategies greatly improve speech extraction performance, especially for same-gender mixtures, and outperform TasNet in terms of target speech extraction.
Despite the great success of neural network-based speech separation, it requires knowing or estimating the number of sources in the mixture and still suffers from a global permutation ambiguity issue, i.e., an arbitrary mapping between source speakers and outputs. These limitations arguably limit the practical usage of speech separation. In contrast, target speech extraction exploits an auxiliary clue to identify the target speaker in the mixture and extracts only speech of that speaker. It naturally avoids the global permutation ambiguity issue and does not require knowing the number of sources in the mixtures.
FD-SpeakerBeam (Freq domain) cannot discriminate same-gender mixtures.
In this paper,
First, propose TD-SpeakerBeam and use a convolutional network to obtain richer speaker embedding vectors.
Moreover, to further improve speaker discrimination capability, we extend TD-SpeakerBeam to accept spatial info from mic array recordings as additional input features and proposed an alternative approach, called internal combination, for exploiting spatial info more effectively within the SpeakBeam framework.
Finally, to enforce learning more discriminative speaker embedding vectors, we propose using a multi-task loss for training SpeakerBeam, which combines a speech reconstruction loss with a speaker identification loss (SI-loss).
SpeakerBeam is composed of two networks, an extraction network, and an auxiliary network.
 Insert an adaptation layer between the first and second convolution blocks to drive the network towards extracting the target speech. The adaptation layer accepts a speaker embedding vector of the target speaker,
Insert an adaptation layer between the first and second convolution blocks to drive the network towards extracting the target speech. The adaptation layer accepts a speaker embedding vector of the target speaker,
The target speaker embedding vector,
IPD features provide spatial info related to the direction of sources in the mixture. Speaker embedding may represent spectral info about the target spk. Consequently, it is not obvious how to efficiently combine IPDs with target spk embeddings as they represent different info. We consider two schemes, input combination and internal combination.
Input combination: IPD features concatenated to the ouput of encoder layer of the extraction network (Early Fusion). This combine spatial info from IPD features with spectral info from the mixture signal
Fig. 1(b) shows internal combination, which combines the IPD features after the adaptation layer. Therefore, the spk selection operate based only on the spectral info, and the spatial info can be exploited by the upper layers without being obstructed by the adaptation layer.
Si-SDR and cross-entropy-based SI-loss
The SI-loss is used to obtain more discriminative speaker embedding vectors.
Weight on SI-loss is 10.
Deep attractor network [] performs speech separation followed by target speaker selection from the separated signals. We compare TD-SpeakerBeam with TasNet separation followed by x-vector-based speaker selection, which can be considered as a strong baseline for target speech extraction.
[Direction-aware speaker beam for multi-channel speaker extraction], where a set of fixed beamformers combined with an attention module on the output of the beamformers was used to perform a rough initial target speech extraction followed by a refinement step with FD-SpeakerBeam.
 FM: female-male
FM: female-male
Performance dropped greatly when using x-vector-based speaker selection (row (4) and (5)). X-vector extractor is affected by reverberation, which may partly contribute to the poor performance.
The proposed TD-SpeakerBeam (row (7)) outperformed all systems but TasNet with oracle speaker selection.


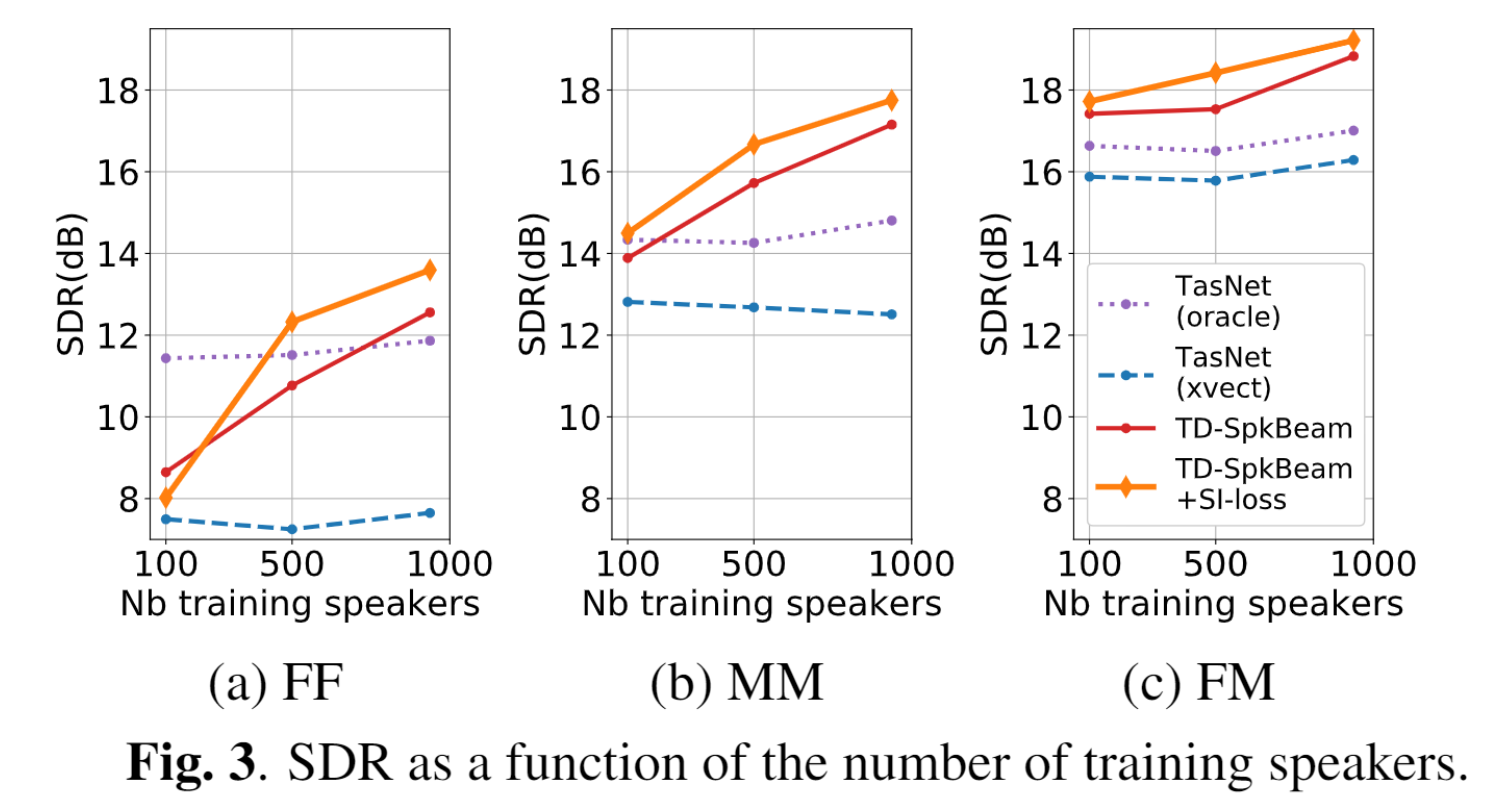 We observe that increasing the number of spks has little effect on TasNet performance, but greatly improves the performance of SpeakerBeam (Fig. 3). This suggests that, for SpeakerBeam, separating signals is somewhat easier than identifying spks.
We observe that increasing the number of spks has little effect on TasNet performance, but greatly improves the performance of SpeakerBeam (Fig. 3). This suggests that, for SpeakerBeam, separating signals is somewhat easier than identifying spks.
Proposed different strategies for improving the target speech discrimination capability of SpeakerBeam. We showed that a time-domain implementation greatly improved performance. Moreover, the performance gap between same-gender and different-gender mixtures could be reduced further by exploiting spatial info, using an additional SI-loss.