#! https://zhuanlan.zhihu.com/p/566211230
Learning-based beamforming methods, sometimes called neural beamformers, have achieved signiticant improvements in both signal quality (e.g. SNR) and speech recognition (e.g. WER). Such systems are generally non-causal and require a large context for robust estimation of inter-channel features, which is impractical in applications requiring low-latency responses.
Propose filter-and-sum network (FaSNet), a time-domain, filter-based beamforming approach suitable for low-latency scenarios. FaSNet has a two-stage system design that first learns frame-level time-domain adaptive beamforming filters for a selected reference channel, and then calculate the filters for all remaining channels. The filtered outputs at all channels are summed to generate the final output. Experiments show that FaSNet outperforms several oracle beamformers with respect to SI-SNR in reverberant speech enhancement and separation tasks.
Beamforming, also known as spatial filtering, is a powerful microphone array processing technique that extracts the signal-of-interest in a particular direction and reduces the effect of noise and reverberation from a multi-channel signal.
Neural beamformers can be broadly categorized into three main categories.
- filtering-based (FB) approach, aims at learning a set of beamforming filters to perform filter-and-sum (FaS) beamforming in either time-domain or freq domain. FaS beamforming applies the beamforming filters to each channel and then sums them up to generate a single-channel output, within which the filters can be either fixed or adaptive depending on the model design
- masking-based (MB) beamforming, estimates the FaS beamforming filters in freq domain by estimating TF masks for the sources of interest. The TF masks specify the dominance of each TF bin and are used to calculate the spatial covariance features required to obtain optimal weights for beamformers such as MVDR and GEV BF.
- regression-based (RB) approach, implicitly incorporates beamforming within a neural network without explicitly generating the beamforming filters [Wave-u-net]. In this framework, the input channels are directly passed to a (convolutional) neural network and the training objective is to learn a mapping between the multi-channel inputs and the target source of interest. The beamforming operation is thus assumed to be implicitly included in the mapping function defined by the model.
Previous studies have shown that freq-domain neural beamformers significantly outnumber time-domain neural beamformers for several reasons.
- neural beamformers are typically designed and applied to ASR tasks in which freq-domain methods are still the most common approaches.
- freq-domain beamformers are known to be more robust and effective than time-domain beamformers in various tasks. However, in applications and devices where online, low-latency processing is required, freq-domain methods have the disadvantage that the freq resolution and the input signal length needed for a reasonable performance might result in a large, perceivable system latency.
To address the limitation of previous neural beamformers, propose FaSNet, a time-domain adaptive FaS beamforming framework suitable for real-time, low-latency applications. It consists of two stages where the first stage estimates the beamforming filter for a selected reference channel, and the second stage utilizes the output from the first stage to estimate beamforming filters for all remaining channels. The input for both stages consists of the target channel to be beamformed as well as the use of the normalized cross-correlation (NCC) between channels as the inter-channel feature. Both stages make use of TCNs for low-resource, low-latency processing. Moreover, depending on the actual task to solve, the training objective of FaSNet can be either a signal-level criterion (e.g. SNR) or ASR-level criterion (e.g. mel-spectrogram), which makes FaSNet a flexible framework for various scenarios.
The problem of time-domain FaS beamforming is defined as estimating a set of time-domain filters for a mic array of
We first split the signals
Use frame-level normalized cross-correlation (NCC) as the inter-channel feature. NCC feature contains both the TDOA info and the content-dependent info of the signal of interest in the reference mic and the other mics.

For tasks that take signal quality as an evaluation measure, we use SI-SNR as the training objective.
For tasks where freq-domain output is favored (e.g. ASR), use mel-spectrogram with scale-invariant mean-square-error (SI-SME) as the training objective:
$$
\begin{aligned}
\left{\mathbf{Y}_c\right.&=\left|\operatorname{STFT}\left(\frac{\mathbf{y}_c}{\left|\mathbf{y}_c\right|_2}\right)\right| \
\mathbf{Y}_c^* &=\left|\operatorname{STFT}\left(\frac{\mathbf{y}c^}{\left|\mathbf{y}_c^\right|2}\right)\right| \
\mathcal{L}{o b j} &=\frac{1}{C} \sum{c=1}^C \operatorname{MSE}\left(\mathbf{Y}_c \mathbf{M}, \mathbf{Y}_c^* \mathbf{M}\right)
\end{aligned}
$$
Utterance-level permutation invariant training (uPIT) is applied.
3 exps:
- Echoic noisy speech enhancement
- Echoic noisy speech separation
- Multichannel noisy ASR
Compared against time-domain beamformers [multi-channel Wiener filter (TD MWF) and TD MVDR], freq-domain beamformers [speech distortion weighted MWF (SDW-MWF) and MVDR], masked-based beamformers [MVDR and GEV beamformers using IBM to estimate the beamforming filters]
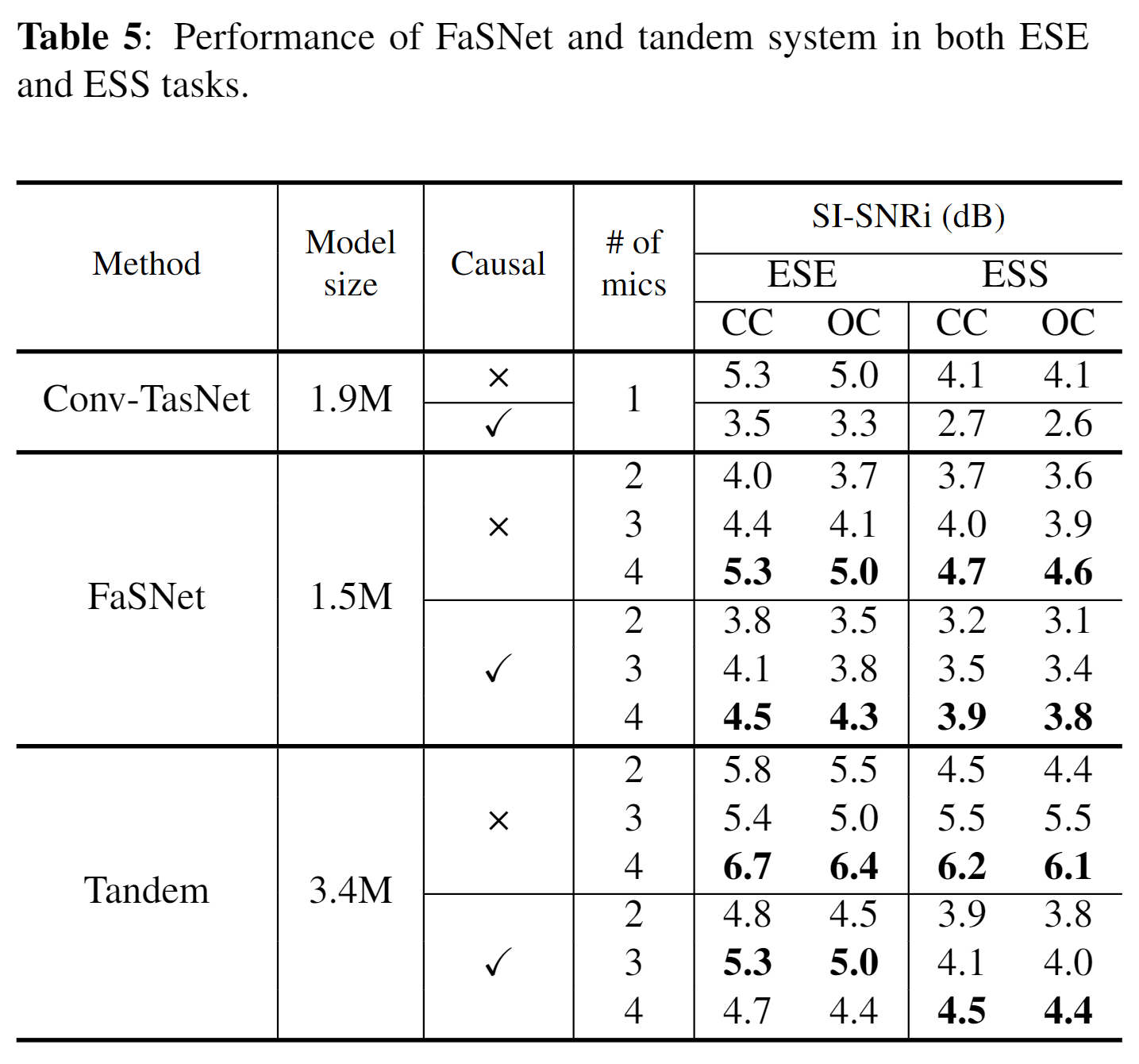

In this paper, proposed FaSNet, a time-domain adaptive beamforming method especially suitable for online, low-latency applications. FaSNet was designed as a two-stage system, where the first stage estimated the beamforming filter for a randomly selected reference mic, and the second stage used the output of the first stage to calculate the filters for all the remaining mics. FaSNet can also be concatenated with any other single-channel system for further performance improvement. Exp results showed that FaSNet achieved better or on par performance than several oracle traditional beamformers on both echoic noisy speech enhancement (ESE) and echoic noisy speech separation (ESS) tasks.