#! https://zhuanlan.zhihu.com/p/577690946
https://arxiv.org/abs/1905.06286
Contributions:
- an integrated waveform-in-waveform-out separation system in a single neural network architecture.
- reformulate the traditional STFT and IPD (inter-channel phase difference) as a function of time-domain convolution with a special kernel.
- relaxed those fixed kernels to be learnable, so that the entire architecture becomes purely data-driven and can be trained from end-to-end.
We demonstrate on the WSJ0 far-field speech separation task that, with the benefit of learnable spatial features, our proposed end-to-end multi-channel model significantly improved the performance.
Due to the difficulty on phase retrieval and human ears are insensitive to phase distortion to some extent, magnitude spectrogram is then a general choice for separation network to work with.
To incorporate the phase into modeling, lots of efforts have been devoted to end-to-end methods which are conducted in time-domain.
Although close-talk speech separation model achieves great progress, the performance of far-field speech separation is still far from satisfactory due to the reverberation.
Correlation clues among multi-channel signals, such as inter-channel time difference, phase difference, level difference (ITD, IPD, ILD), can indicate the sound source position.
Propose to extract the spatial information from time domain using neural networks. This work can be viewed as a multi-channel extension to the Conv-TasNet for time-domain far-field speech separation.
Conv-TasNet & Wave-U-Net
In section 3.1 we first try to incorporate the IPD features extracted from freq domain into the TasNet. Then a cross-domain joint training is performed.
In section 3.2 we reformulate the STFT and IPD as a function of time-domain convolution with special kernel. Then we relaxed those fixed kernels to be learnable.
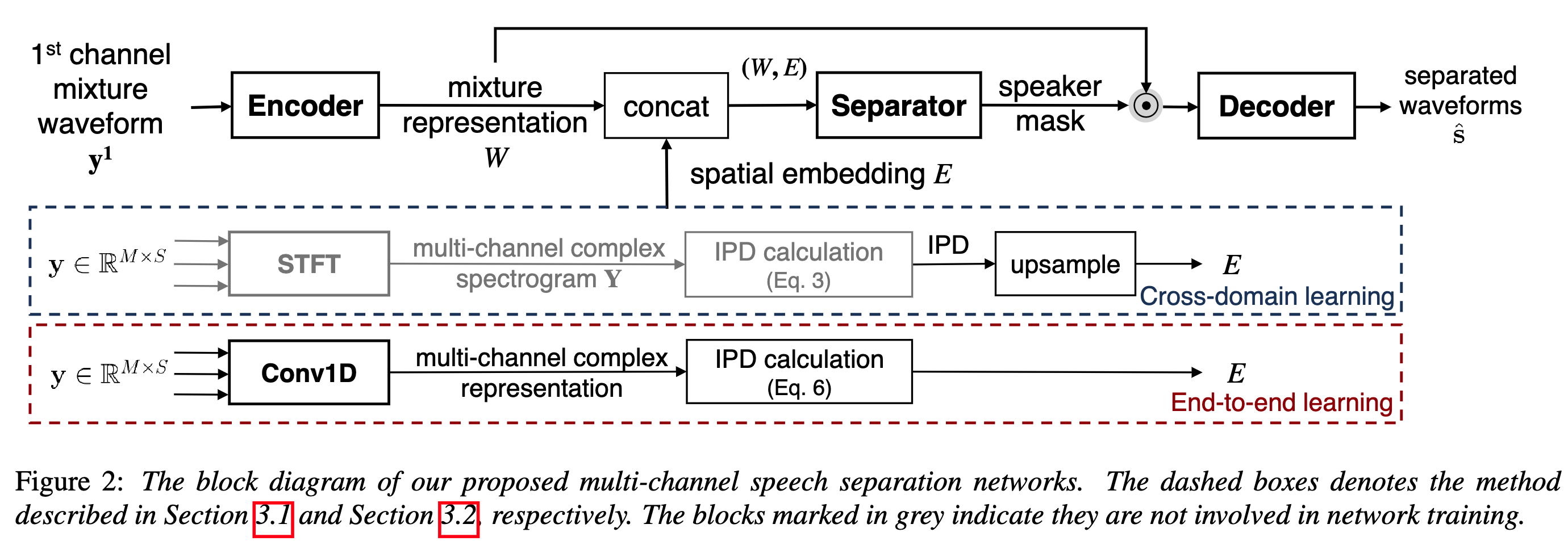 Perform STFT on each individual channel of the mixture waveform to compute the complex spectrogram and then compute IPD by the phase difference between channels of complex spectrogram.
Perform STFT on each individual channel of the mixture waveform to compute the complex spectrogram and then compute IPD by the phase difference between channels of complex spectrogram.
Since the window length
Fusion strategy: early fusion illustrated in Figure 2, which concatenates spatial embedding
The convolution kernels enable IPD calculation inside the network, thus makes it an end-to-end approach.
