近年来基于深度学习方法的 postfilter 的工作大致有以下几种:
- 通过训练目标等设计 encoder-decoder 结构中的 decoder 起到 postfilter 的作用 [1];
- 先进行预分离,再通过基于 NN 的 postfilter 进行进一步分离 [2,3];
- 在 AEC 的任务中,讲传统的 postfilter 模块替换成 NN 的 [4,5];
- 添加额外网络进行后处理 [6];
- 用 GAN 的判别器对增强后的语谱进行后处理 [7,8]。
下面是这些文章的详细介绍
Inplace Gated Convolutional Recurrent Neural Network for Dual-Channel Speech Enhancement, Interspeech 2021
Decoder: signal filtering & reconstruction (两个 encoder 分别对 mag 和 phase 进行 masking 和 mapping)
先在时频域预分离,然后将混合语音和预分离的语音同时作为输入,通过 一维卷积和 attention 进行特征融合,融合的特征送入 TCN-based postfilter
Dual-Path Filter Network: Speaker-Aware Modeling for Speech Separation, Interspeech 2021
先预分离,再根据 speaker 信息进一步分离 笔记
$Y^2$-Net FCRN for Acoustic Echo and Noise Suppression, Interspeech 2021
用两个全卷积循环网络 FCRN,首先是 AEC 模块估计回声,再用后置滤波模块进行残留回声抑制。
Follow
decoder 后面接上超分网络 + 渐进学习恢复降采样带来的信息损失 笔记
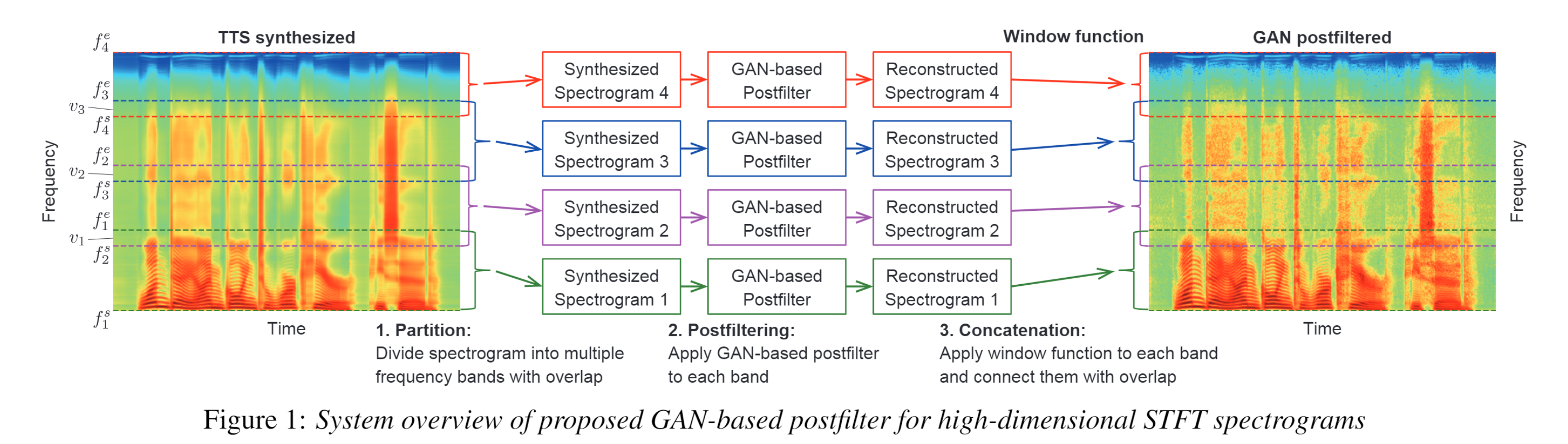
Generative Adversarial Network-Based Postfilter for STFT Spectrograms, Interspeech 2017
Generated spectra typically lack the fine structures that are close to those of the true data. Propose a GAN-based postfilter that is implicitly optimized to match the true feature distribution in adversarial learning.
GAN cannot be easily trained for very high-dimensional data such as STFT spectra. Thus take divide-and-concatenate strategy: first divide the spectrograms into multiple freq bands with overlap, reconstruct the individual bands using the GAN-based postfilter trained for each band, and connect th bands with overlap.
Improving Perceptual Quality by Phone-Fortified Perceptual Loss Using Wasserstein Distance for Speech Enhancement, Interspeech 2021
利用音素相关的信息计算 enhanced speech 和 clean speech 之间的loss (PFPL)
Multiple inputs (features extracted from far-end reference and the echo estimated by the Linear Adaptive Filter) are weighted by a feature attention module.

加入 feature attention module 来更好地融合远端参考信号、LAF输出的
如题
Filterbank design for end-to-end speech separation, Manuel Pariente et al., ICASSP 2020