-
监督学习
- 给机器训练的数据有标记(结果/答案),即给了机器答案的划分,这种正确的划分就是一种监督
-
例如医院拥有了大量病人患病的信息和确诊信息,通过这些数据训练机器来确定病人患病情况(再具体点:肿瘤是恶性还是良性)
-
监督学习主要处理两大问题:
- 分类
- 回归
-
非监督学习
-
反之,给机器训练的数据没有任何标记(结果/答案)
-
聚类分析:对没标记的数据进行分类
- 应用:社交网络分析,市场划分,天文数据分析等
- 例如淘宝用户随着浏览购买商品产生的数据我们可以对顾客数据进行分析分成许多类别
-
非监督学习的作用一:降维,方便可视化
- 特征提取:扔掉无关的特征
- 特征压缩(PCA算法):不扔掉任何特征,从中提取部分特征也可正确得出结果,提高运行效率。即尽量少损失信息,将高维特征向量压缩为低维特征向量
-
非监督学习的作用二:异常检测
-


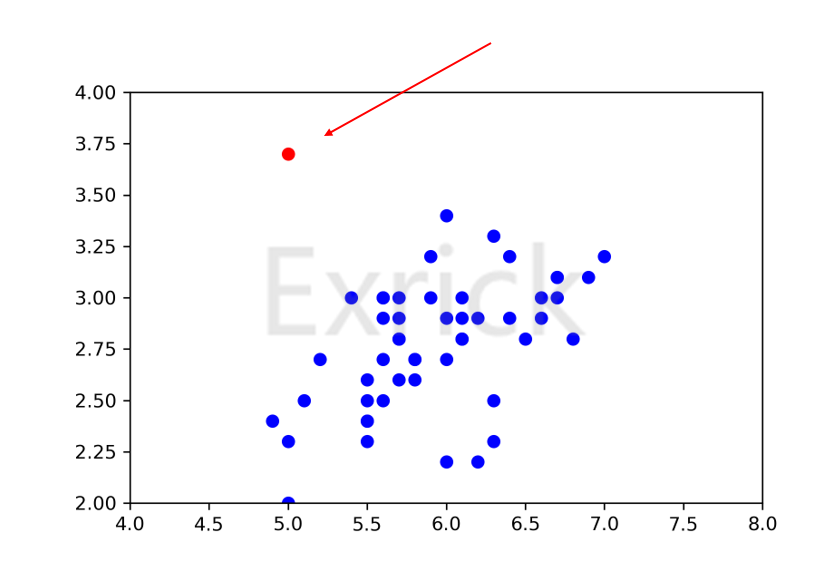
无监督学习本身的特点使其难以得到如分类一样近乎完美的结果。假设两个人刷高考题,一个正常刷题,而另一人做的所有题目没有答案,那么想必第一个人高考会发挥更好,第二个人会发疯。
-
半监督学习
- 一部分数据有标记,一部分没有
- 这种情况在实际场景下很常见,通常使用无监督学习先对数据处理,再使用监督学习进行模型训练
-
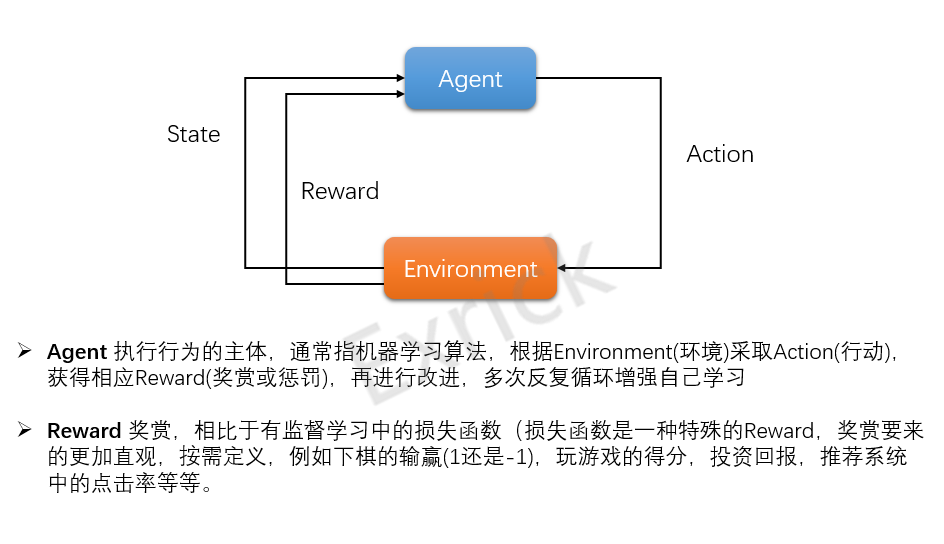
增强学习
- AlphaGo、无人驾驶都是增强学习的应用,监督学习、半监督学习依然是基础
- 批量学习(离线学习)
- 一次性批量将数据喂给算法(填鸭式学习),训练后的模型不再变化
- 优缺点:简单,但如果要适应新环境变化需要重新批量学习,由于运算量巨大,例如在股市每时每刻都在变化,这种情况显然不可行
- 在线学习
- 输入样例后马上能得到正确的结果(股市),再根据得到的结果改进机器学习算法。即循环学习,不断修正优化模型
- 优缺点:能及时反映新环境变化,但新数据是好是坏(异常数据?),因此需要对异常数据进行检查(非监督学习应用)
- 参数学习
- 假设线性关系,例如最简单的
f(x)=ax+b,机器学习的本质就是找到最优的参数a和b(基本的线性回归),一旦通过大量数据集学到参数后,数据集即没用了。
- 假设线性关系,例如最简单的
- 非参数学习
- 不对模型进行过多假设,但不代表没参数,区别于参数学习,不对问题建模,不把问题理解为学习参数
- 监督学习(supervised learning):分类和回归
- 无监督学习(unsupervised learning):聚类
- 聚类(clustering):把训练集中的对象分为若干组
- 半监督学习(Semi-Supervised Learning):使用大量的未标记数据,同时使用标记数据,来进行模式识别工作
- 增强学习(Reinforcement Learning):解决一个能感知环境的自治 agent,怎样通过学习选择能达到其目标的最优动作问题。
- 批量学习(Batch Learning):一次性批量输入给学习算法,可以被形象的称为填鸭式学习
- 在线学习(Online Learning):按照顺序,循序的学习,不断的去修正模型,进行优化
- 参数学习(Parametric Learning):假设可以最大程度地简化学习过程,与此同时也限制可以学习到是什么。这种算法简化成一个已知的函数形式
- 非参数学习(Nonparametric Learning):不对目标函数的形式作出强烈假设的算法。通过不做假设,它们可以从训练数据中自由地学习任何函数形式
- 作者:Exrick
- Github地址:https://github.com/Exrick/Machine-Learning
- 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处。