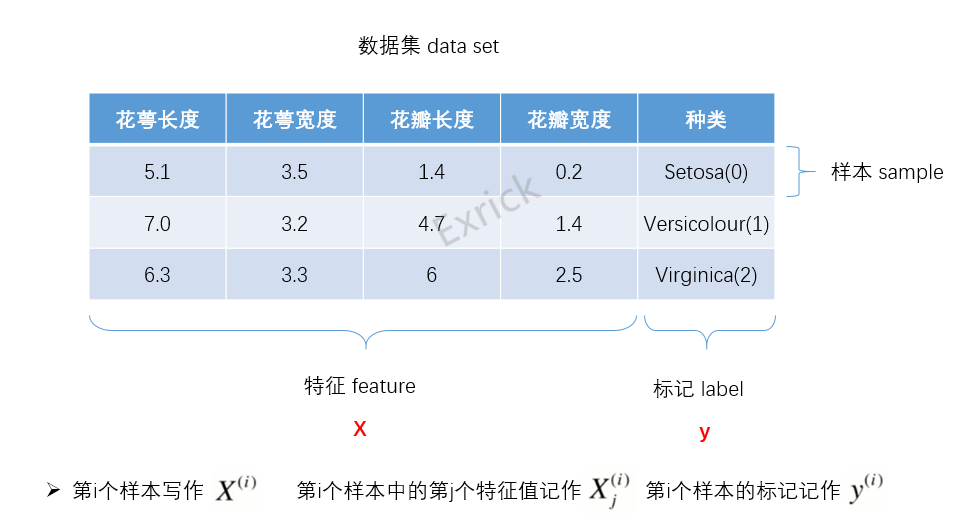
Iris(鸢尾花卉)数据集是非常著名且常用的分类实验数据集,由Fisher, 1936收集整理。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
该数据集包含了5个属性:Sepal.Length(花萼长度);Sepal.Width(花萼宽度);Petal.Length(花瓣长度);Petal.Width(花瓣宽度); 种类:Setosa(山鸢尾)、Versicolour(杂色鸢尾),以及Virginica(维吉尼亚鸢尾)
- 下面表中用0、1、2代表三个种类,计算机中对数据处理,我们先学会采取数字化
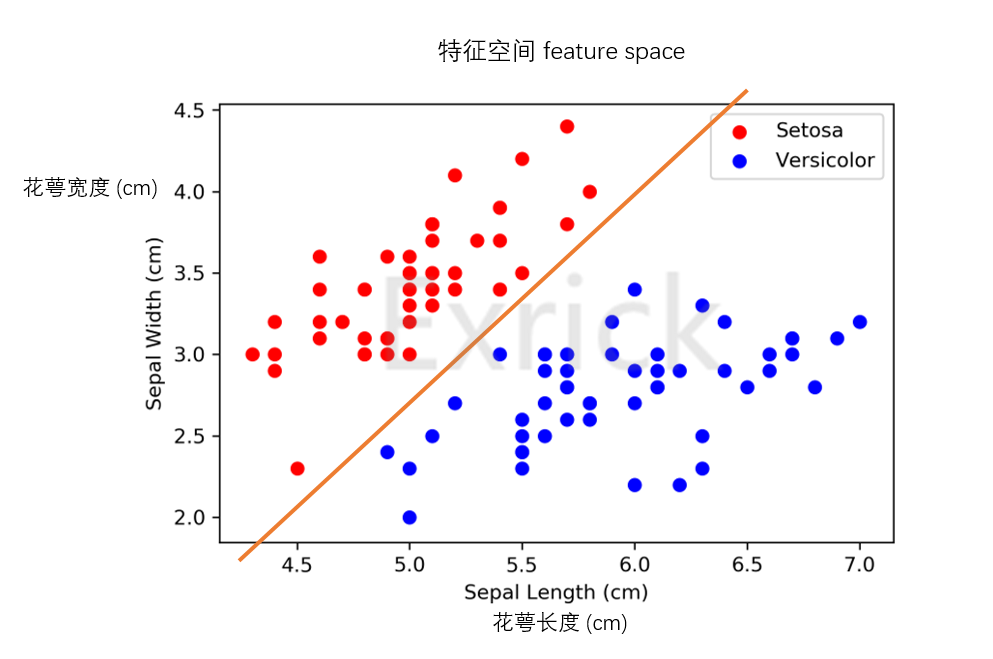
- 为可视化方便,我们只选取前两种花的前两个特征绘制出的其各个样本在平面二维图中的分布,即所有样本的两个特征组成了该特征空间,如下图所示
- 举一反三:选取3个特征即可在3维空间中表示,n个特征即可在n维空间表示
- 由上图我们可以清晰地看到每种花的特征在特征空间中的分布是不同的,我们简单地划两条直线将特征空间分成两部分
- 得出结论:分类任务的本质就是在特征空间中的切分,高维空间同理
- 思维:实际数据特征不止两个这么简单,我们应学会将高维空间先降维至低维空间思考
MNIST 数据集是一个最大的手写字符数据集,其经常被应用在机器学习领域,用于训练和测试。
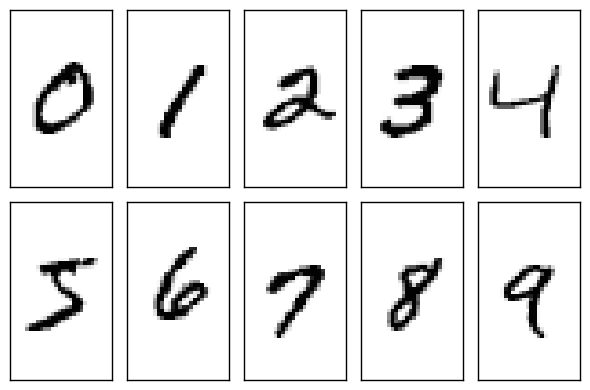
-
每个手写数字图像中每个像素点都可以看作为一个特征,因此可以用28*28=784个像素点的灰度值即特征来描述该图像,那么彩色图像特征如RGB值也更多,因此特征可以很抽象
-
特征数据很大程度将决定算法运行的结果,如何挖掘特征大家可以另外深入学习
- 数据集(data set):一组记录的合集
- 样本(sample):也叫示例,对于某个对象的描述
- 特征(feature):也叫属性,对象的某方面表现或特征
- 特征空间(feature space):特征张成的空间
- 样本空间/输入空间(sample space):同特征空间
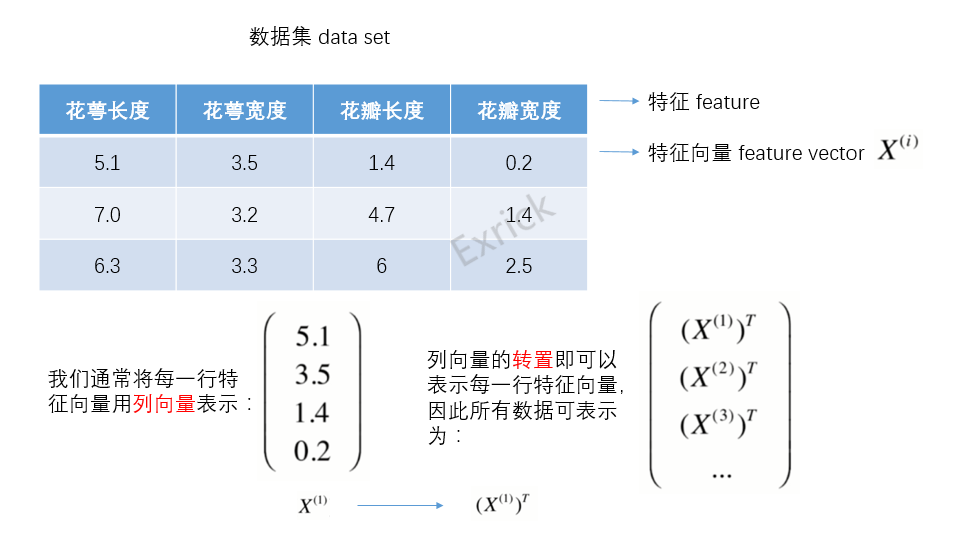
- 特征向量(feature vector):在特征空间里每个点对应一个坐标向量,把一个样本称作特征向
- 维数(dimensionality):描述样本参数的个数(也就是空间是几维的)
- 作者:Exrick
- Github地址:https://github.com/Exrick/Machine-Learning
- 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处。