为什么巨大的原始视频可以编码成很小的视频呢?这其中的技术是什么呢? 核心思想就是去除冗余信息:
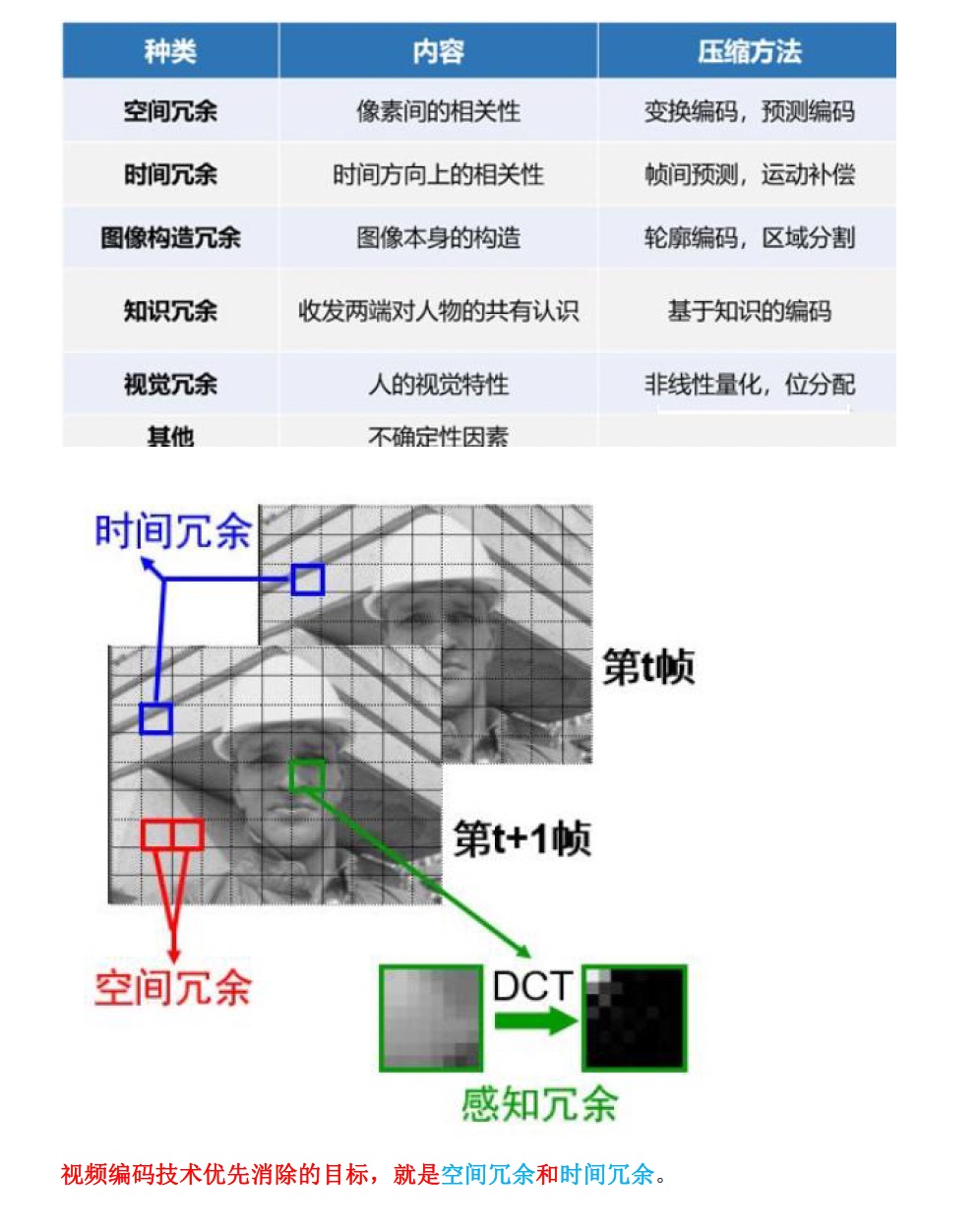
- 空间冗余: 图像相邻像素之间有较强的相关性
- 时间冗余:视频序列的相邻图像之间内容相似
- 编码冗余:不同像素值出现的概率不同
- 视觉冗余:人的视觉系统对某些细节不敏感
- 知识冗余:规律性的结构可由先验知识和背景知识得到
视频本质上讲是一系列图片连续快速的播放,最简单的压缩方式就是对每一帧图片进行压缩,例如比较古老的MJPEG编码就是这种编码方式,这种编码方式只是帧内编码,利用空间上的取样预测来编码。 但是帧与帧之间因为时间的相关性,后续开发出了一些比较高级的编码器可以采用帧间编码,简单点说就是通过搜索算法选定了帧上的某些区域,然后通过计算当前帧和前后参考帧的向量差进行编码的一种形式,例如一个人滑雪,前后两帧画面的差异就是人的位置移动了。
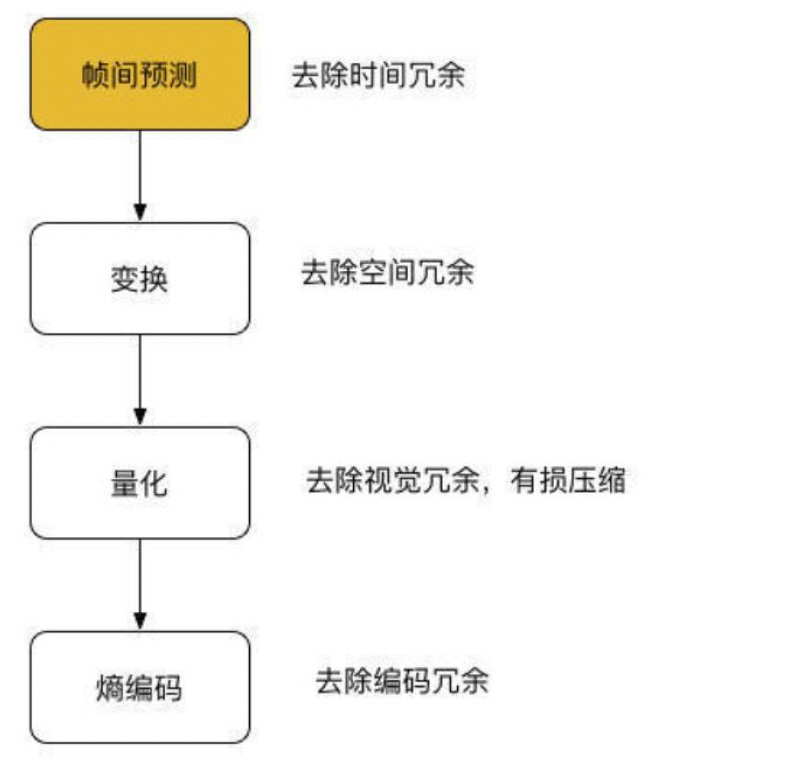
- 预测: 预测编码可以用于处理视频中的时间和空间域的冗余,主要分为两大类:帧内预测和帧间预测。
- 帧内预测: 预测值与实际值位于同一帧内,用于消除图像的空间冗余。帧内预测的特点是压缩率相对较低,然而可以独立解码,不依赖其他帧的数据。通常视频中的关键帧都采用帧内预测。
- 帧间预测: 帧间预测的实际值位于当前帧,预测值位于参考帧,用于消除图像的时间冗余。帧间预测的压缩率高于帧内预测,然而不能独立解码,必须在获取参考帧数据之后才能重建当前帧。 通常在视频码流中,I帧全部使用帧内编码,P帧、B帧中的数据可能使用帧内或帧间编码。
- 变换: 变化编码是指将给定的图像变换到另一个数据域如频域上,使得大量的信息能用较少的数据来表示,从而达到压缩的目的。目前主流的视频编码算法均属于有损编码,通过对视频造成有限而可以容忍的损失,获取相对更高的编码效率。而造成信息损失的部分即在于变换量化这一部分。在进行量化之前,首先需要将图像信息从空间域通过变换编码变换至频域,并计算其变换系数供后续的编码。
- 量化
- 熵编码: 视频编码中的熵编码方法主要用于消除视频信息中的统计冗余。由于信源中每一个符号的出现概率并不一致,这就导致使用同样长度的码字表示所有的符号会造成浪费。通过熵编码,针对不同的语法元素分配不同长度的码元,可以有效消除视频信息中由于符号概率导致的冗余。
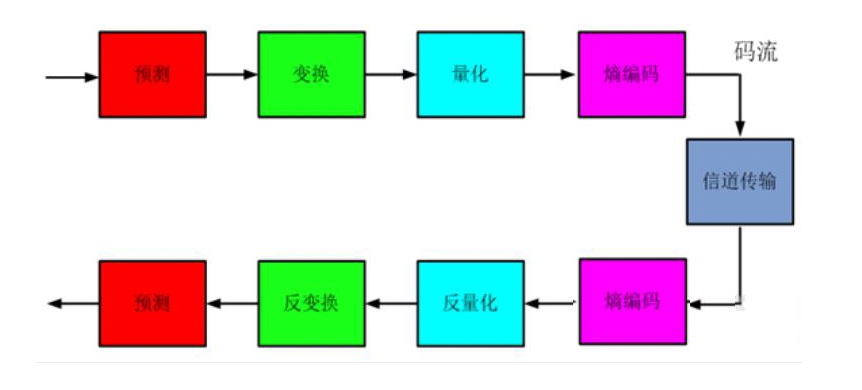
- 对I帧的处理,是采用帧内编码方式,只利用本帧图像内的空间相关性。
帧内编码虽然只有空间相关性,但整个编码过程并不简单,主要如下:
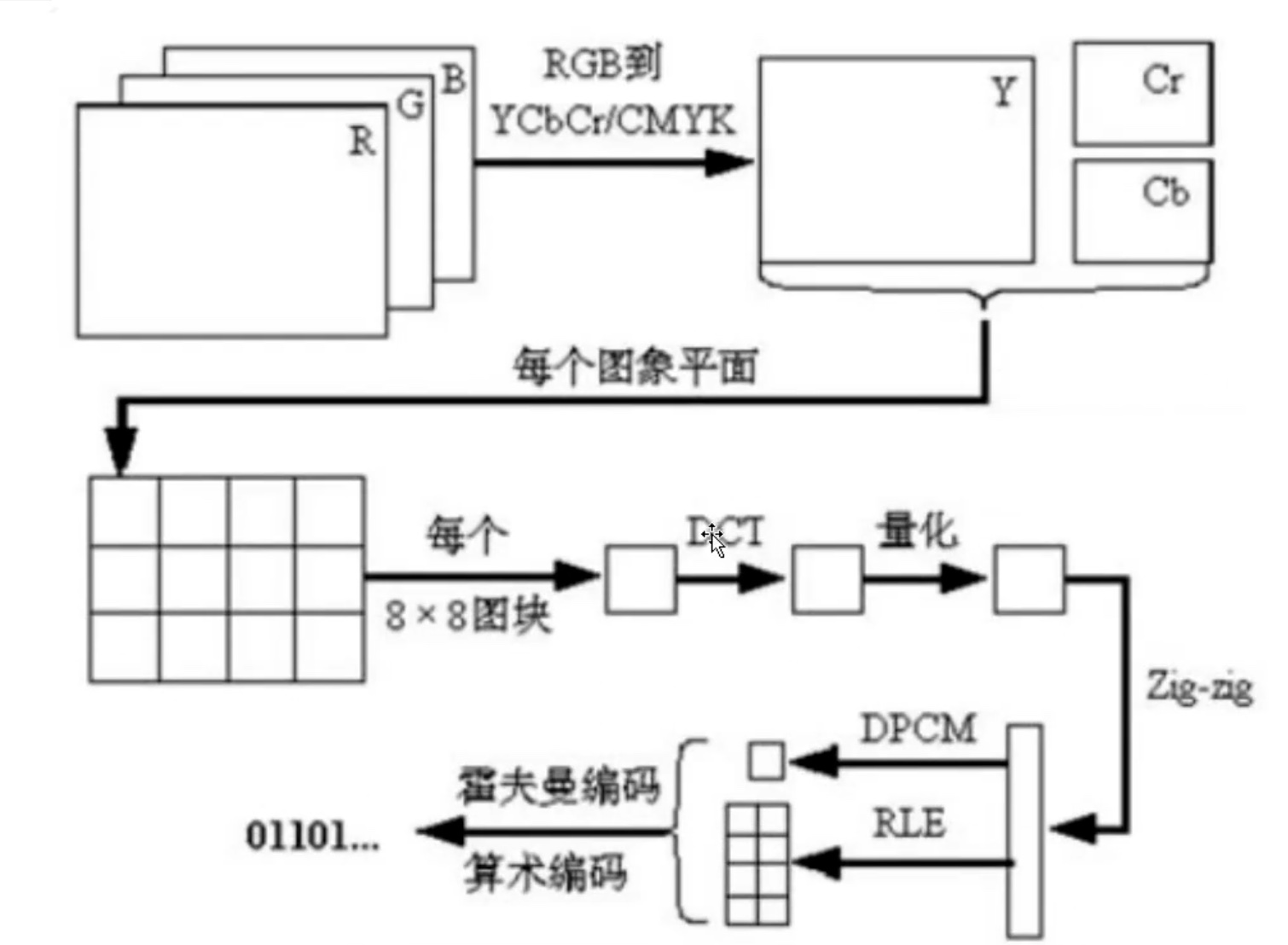
- RGB转YUV:固定公式
- 图片宏块切割:宏块16*16
- DCT:离散余弦变换
- 量化:取样
- ZigZag:扫描
- DPCM:差值脉冲编码调制
- RLE:游程编码
- 霍夫曼编码
- 算数编码
- 对P帧的处理,采用帧间编码(前向运动估计),同时利用空间和时间上的相关性。 简单来说,采用运动补偿(motion compensation)算法来去掉冗余信息。