我也维护了一个学习深度学习框架(PyTorch和OneFlow)的仓库 https://github.com/BBuf/how-to-learn-deep-learning-framework 以及一个如何学习深度学习编译器(TVM/MLIR/LLVM)的学习仓库 https://github.com/BBuf/tvm_mlir_learn , 有需要的小伙伴可以点一点star
本工程记录如何基于 cuda 优化一些常见的算法。请注意,下面的介绍都分别对应了子目录的代码实现,所以想复现性能的话请查看对应子目录下面的 README 。
- 课程的 Slides 和 脚本:https://github.com/cuda-mode/lectures
- 课程地址:https://www.youtube.com/@CUDAMODE
- 我的课程笔记:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode
一直想系统看一下某个课程系统和科学的学习下 CUDA ,感觉 CUDA-MODE 这个课程能满足我的需求。这个课程是几个 PyTorch 的 Core Dev 搞的,比较系统和专业。不过由于这个课程是 Youtube 上的英语课程,所以要学习和理解这个课程还是需要花不少时间的,我这里记录一下学习这个课程的每一课的笔记,希望可以通过这个笔记帮助对这个课程以及 CUDA 感兴趣的读者更快吸收这个课程的知识。这个课程相比于以前的纯教程更加关注的是我们可以利用 CUDA 做什么事情,而不是让读者陷入到 CUDA 专业术语的细节中,那会非常痛苦。伟大无需多言,感兴趣请阅读本文件夹下的各个课程的学习笔记。
记录如何手动编译 PyTorch 源码,学习 PyTorch 的一些 cuda 实现。
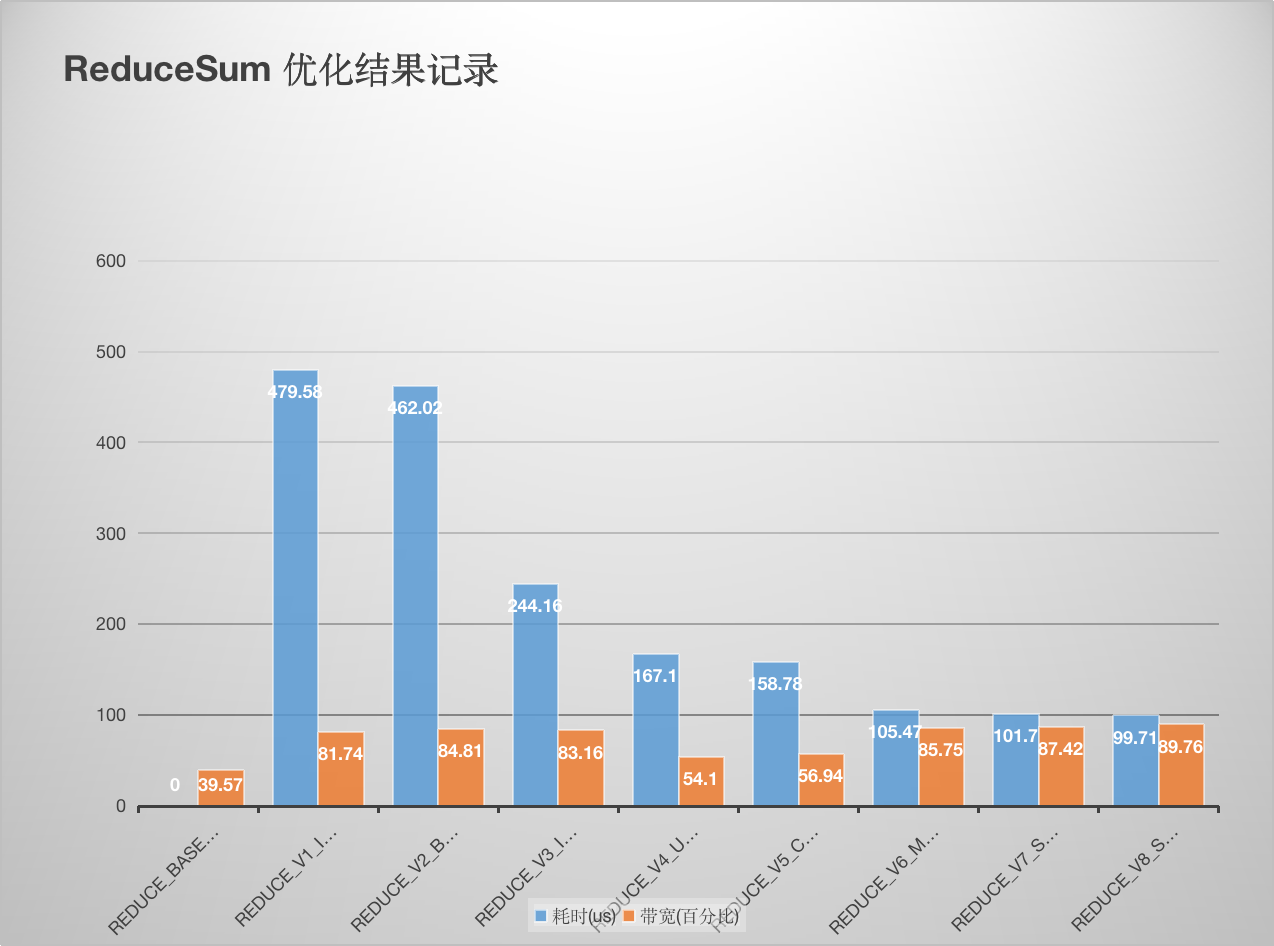
这里记录学习 NIVDIA 的reduce优化官方博客 做的笔记。完整实验代码见这里 , 原理讲解请看:【BBuf的CUDA笔记】三,reduce优化入门学习笔记 。后续又添加了 PyTorch BlockReduce 模板以及在这个模板的基础上额外加了一个数据 Pack ,又获得了一些带宽的提升。详细数据如下:
性能和带宽的测试情况如下 (A100 PCIE 40G):
将 oneflow 的 elementwise 模板抽出来方便大家使用,这个 elementwise 模板实现了高效的性能和带宽利用率,并且用法非常灵活。完整实验代码见这里 ,原理讲解请看:【BBuf 的CUDA笔记】一,解析OneFlow Element-Wise 算子实现 。这里以逐点乘为例,性能和带宽的测试情况如下 (A100 PCIE 40G):
| 优化手段 | 数据类型 | 耗时(us) | 带宽利用率 |
|---|---|---|---|
| naive elementwise | float | 298.46us | 85.88% |
| oneflow elementwise | float | 284us | 89.42% |
| naive elementwise | half | 237.28us | 52.55% |
| oneflow elementwise | half | 140.74us | 87.31% |
可以看到无论是性能还是带宽,使用 oneflow 的 elementwise 模板相比于原始实现都有较大提升。
实现的脚本是针对half数据类型做向量的内积,用到了atomicAdd,保证数据的长度以及gridsize和blocksize都是完全一致的。一共实现了3个脚本:
- https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/FastAtomicAdd/atomic_add_half.cu 纯half类型的atomicAdd。
- https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/FastAtomicAdd/atomic_add_half_pack2.cu half+pack,最终使用的是half2类型的atomicAdd。
- https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/FastAtomicAdd/fast_atomic_add_half.cu 快速原子加,虽然没有显示的pack,但本质上也是通过对单个half补0使用上了half2的原子加。
性能和带宽的测试情况如下 (A100 PCIE 40G):
| 原子加方式 | 性能(us) |
|---|---|
| 纯half类型 | 422.36ms |
| pack half2类型 | 137.02ms |
| fastAtomicAdd | 137.01ms |
可以看到使用pack half的方式和直接使用half的fastAtomicAdd方式得到的性能结果一致,均比原始的half的原子加快3-4倍。
upsample_nearest_2d.cu 展示了 oneflow 对 upsample_nearest2d 的前后向的优化 kernel 的用法,性能和带宽的测试情况如下 (A100 PCIE 40G):
| 框架 | 数据类型 | Op类型 | 带宽利用率 | 耗时 |
|---|---|---|---|---|
| PyTorch | Float32 | UpsampleNearest2D forward | 28.30% | 111.42us |
| PyTorch | Float32 | UpsampleNearest2D backward | 60.16% | 65.12us |
| OneFlow | Float32 | UpsampleNearest2D forward | 52.18% | 61.44us |
| OneFlow | Float32 | UpsampleNearest2D backward | 77.66% | 50.56us |
| PyTorch | Float16 | UpsampleNearest2D forward | 16.99% | 100.38us |
| PyTorch | Float16 | UpsampleNearest2D backward | 31.56% | 57.38us |
| OneFlow | Float16 | UpsampleNearest2D forward | 43.26% | 35.36us |
| OneFlow | Float16 | UpsampleNearest2D backward | 44.82% | 40.26us |
可以看到基于 oneflow upsample_nearest2d 的前后向的优化 kernel 可以获得更好的带宽利用率和性能。注意这里的 profile 使用的是 oneflow 脚本,而不是 upsample_nearest_2d.cu ,详情请看 UpsampleNearest2D/README.md 。
在 PyTorch 中对 index_add 做了极致的优化,我这里将 PyTorch 的 index_add 实现 进行了剥离,方便大家应用于其它框架。具体请看 indexing 文件夹的 README 。其中还有和 oneflow 的 index_add 实现的各个 case 的性能比较结果。整体来说 PyTorch 在 index Tensor元素很小,但Tensor很大的情况下有较大的性能提升,其它情况和 OneFlow 基本持平。详情请看 indexing/README.md 。
OneFlow 深度学习框架中基于 cuda 做的优化工作,动态更新中。
总结 FastTransformer 相关的 cuda 优化技巧。README_BERT.md 总结了 BERT 相关的优化技巧。
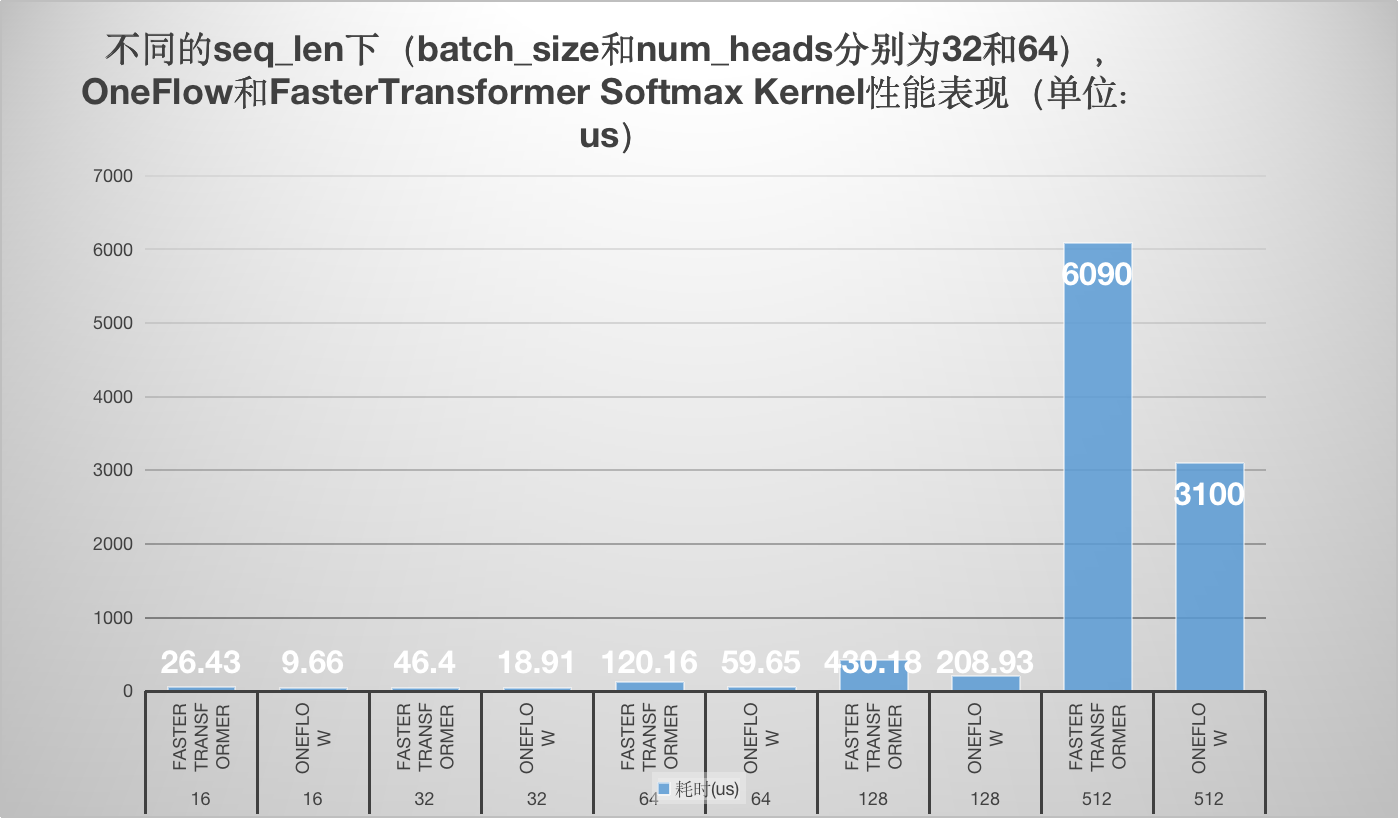
学习了oneflow的softmax kernel实现以及Faster Transformer softmax kernel的实现,并以个人的角度分别解析了原理和代码实现,最后对性能做一个对比方便大家直观的感受到oneflow softmax kernel相比于FasterTransformer的优越性。
学习一些 linear attention 的 cuda 优化技巧。
收集了和大语言模型原理,训练,推理,数据标注的相关文章。
前研的大模型训练相关 AI-Infra 论文收集以及阅读笔记。
Triton 学习过程中的代码记录和学习笔记。
Meagtron-LM 学习笔记。
Triton 中国举办的 Meetup 的slides汇总。点卡这个文件夹也可以找到对应的Meetup的视频回放。
对 CUDA PTX ISA 文档的一个翻译和学习。
对 PyTorch 团队发布的 cuda 技术的一些学习笔记。
cutlass 相关的学习笔记。
cuda 相关的 paper 的阅读。
- 【BBuf的CUDA笔记】一,解析OneFlow Element-Wise 算子实现
- 【BBuf的CUDA笔记】二,解析 OneFlow BatchNorm 相关算子实现
- 【BBuf的CUDA笔记】三,reduce优化入门学习笔记
- 【BBuf的CUDA笔记】四,介绍三个高效实用的CUDA算法实现(OneFlow ElementWise模板,FastAtomicAdd模板,OneFlow UpsampleNearest2d模板)
- 【BBuf的CUDA笔记】五,解读 PyTorch index_add 操作涉及的优化技术
- 【BBuf的CUDA笔记】六,总结 FasterTransformer Encoder(BERT) 的cuda相关优化技巧
- 【BBuf的CUDA笔记】七,总结 FasterTransformer Decoder(GPT) 的cuda相关优化技巧
- 【BBuf的CUDA笔记】八,对比学习OneFlow 和 FasterTransformer 的 Softmax Cuda实现
- 【BBuf的CUDA笔记】九,使用newbing(chatgpt)解析oneflow softmax相关的fuse优化
- CodeGeeX百亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
- 【BBuf的cuda学习笔记十】Megatron-LM的gradient_accumulation_fusion优化
- 【BBuf的CUDA笔记】十,Linear Attention的cuda kernel实现解析
- 【BBuf的CUDA笔记】十一,Linear Attention的cuda kernel实现补档
- 【BBuf的CUDA笔记】十二,LayerNorm/RMSNorm的重计算实现
- 【BBuf的CUDA笔记】十三,OpenAI Triton 入门笔记一
- 【BBuf的CUDA笔记】十四,OpenAI Triton入门笔记二
- 【BBuf的CUDA笔记】十五,OpenAI Triton入门笔记三 FusedAttention
- AI Infra论文阅读之通过打表得到训练大模型的最佳并行配置
- AI Infra论文阅读之将流水线并行气泡几乎降到零(附基于Meagtron-LM的ZB-H1开源代码实现解读)
- AI Infra论文阅读之LIGHTSEQ(LLM长文本训练的Infra工作)
- AI Infra论文阅读之《在LLM训练中减少激活值内存》
- 系统调优助手,PyTorch Profiler TensorBoard 插件教程
- 在GPU上加速RWKV6模型的Linear Attention计算
- flash-linear-attention的fused_recurrent_rwkv6 Triton实现精读
- flash-linear-attention中的Chunkwise并行算法的理解
- 硬件高效的线性注意力机制Gated Linear Attention论文阅读
- GQA,MLA之外的另一种KV Cache压缩方式:动态内存压缩(DMC)
- vAttention:用于在没有Paged Attention的情况下Serving LLM
- 大模型KV Cache节省神器MLA学习笔记(包含推理时的矩阵吸收分析)
- CUDA-MODE 课程笔记 第一课: 如何在 PyTorch 中 profile CUDA kernels
- CUDA-MODE 第一课课后实战(上)
- CUDA-MODE 第一课课后实战(下)
- CUDA-MODE 课程笔记 第二课: PMPP 书的第1-3章速通
- CUDA-MODE 课程笔记 第四课: PMPP 书的第4-5章笔记
- CUDA-MODE课程笔记 第6课: 如何优化PyTorch中的优化器
- CUTLASS 2.x & CUTLASS 3.x Intro 学习笔记
- CUDA-MODE课程笔记 第7课: Quantization Cuda vs Triton
- TRT-LLM中的Quantization GEMM(Ampere Mixed GEMM)CUTLASS 2.x 课程学习笔记
- CUDA-MODE课程笔记 第8课: CUDA性能检查清单
- TensorRT-LLM 中的 Hopper Mixed GEMM 的 CUTLASS 3.x 实现讲解
- 通过微基准测试和指令级分析(Instruction-level Analysis)揭秘英伟达Ampere架构
- CUDA-MODE课程笔记 第9课: 归约(也对应PMPP的第10章)
- 【翻译】Accelerating Llama3 FP8 Inference with Triton Kernels
- 【PyTorch 奇淫技巧】Python Custom Operators翻译
- 【翻译】教程:在PyTorch中为CUDA库绑定Python接口
- 【翻译】教程:CUTLASS中的矩阵转置 (使用CuTe把矩阵转置优化到GPU内存带宽上下限)
- CUDA-MODE课程笔记 第11课: Sparsity
- 【PyTorch 奇淫技巧】Async Checkpoint Save
- CUDA-MODE课程笔记 第12课,Flash Attention
- 【翻译】在 GPU 上如何加速 GPTQ Triton 反量化kernel
- 基于o1-preview解读 Optimized GPTQ INT4 Dequantization Triton Kernel
- 一文读懂nvidia-smi topo的输出
- 如果你是一个C++面试官,你会问哪些问题?
- 推理部署工程师面试题库
- [C++特性]对std::move和std::forward的理解
- 论文阅读:Mimalloc Free List Sharding in Action
- 在 C++ 中,RAII 有哪些妙用?
- AI/HPC面试问题整理
- Roofline Model与深度学习模型的性能分析
- FlashAttention核心逻辑以及V1 V2差异总结
- flash attention 1和flash attention 2算法的python和triton实现
- Flash Attention 推公式
- 图解大模型计算加速系列:FlashAttention V1,从硬件到计算逻辑
- flash attention完全解析和CUDA零基础实现
- FlashAttention图解(如何加速Attention)
- FlashAttention:加速计算,节省显存, IO感知的精确注意力
- FlashAttention 反向传播运算推导
- 比标准Attention提速5-9倍,大模型都在用的FlashAttention v2来了
- FlashAttention 的速度优化原理是怎样的?
- FlashAttention 的速度优化原理是怎样的?
- FlashAttention2详解(性能比FlashAttention提升200%)
- FlashAttenion-V3: Flash Decoding详解
- 速通PageAttention2
- PageAttention代码走读
- 大模型推理加速之FlashDecoding++:野生Flash抵达战场
- 学习Flash Attention和Flash Decoding的一些思考与疑惑
- 大模型推理加速之Flash Decoding:更小子任务提升并行度
- FlashAttention与Multi Query Attention
- 动手Attention优化1:Flash Attention 2优化点解析
- Flash Attention推理性能探究
- 记录Flash Attention2-对1在GPU并行性和计算量上的一些小优化
- [LLM] FlashAttention 加速attention计算[理论证明|代码解读]
- FlashAttention核心逻辑以及V1 V2差异总结
- 【手撕LLM-FlashAttention】从softmax说起,保姆级超长文!!
- 动手Attention优化2:图解基于PTX的Tensor Core矩阵分块乘法实现
- flash attention 的几个要点
- GPU内存(显存)的理解与基本使用
- 图文并茂,超详细解读nms cuda拓展源码
- 大模型的好伙伴,浅析推理加速引擎FasterTransformer
- LLM Inference CookBook(持续更新)
- NVIDIA的custom allreduce
- [论文速读] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- CUDA随笔之Stream的使用
- 简单读读FasterTransformer
- cutlass FusedMultiheadAttention代码解读
- 简单谈谈CUDA Reduce
- GridReduce - CUDA Reduce 部分结果归约
- CUTLASS: Fast Linear Algebra in CUDA C++
- cutlass源码导读(1)——API与设计理念
- cutlass源码导读(2)——Gemm的计算流程
- CUDA GroupNorm NHWC优化
- 传统 CUDA GEMM 不完全指北
- 怎么评估内存带宽的指标,并进行优化?
- TensorRT Diffusion模型优化点
- NVIDIA GPU性能优化基础
- 一文理解 PyTorch 中的 SyncBatchNorm
- 如何开发机器学习系统:高性能GPU矩阵乘法
- CUDA SGEMM矩阵乘法优化笔记——从入门到cublas
- Dropout算子的bitmask优化
- 面向 Tensor Core 的算子自动生成
- PICASSO论文学习
- CUDA翻译:How to Access Global Memory Efficiently in CUDA C/C++ Kernels
- CUDA Pro Tips翻译:Write Flexible Kernels with Grid-Stride Loops
- [施工中] CUDA GEMM 理论性能分析与 kernel 优化
- CUDA Ampere Tensor Core HGEMM 矩阵乘法优化笔记 —— Up To 131 TFLOPS!
- Nvidia Tensor Core-CUDA HGEMM优化进阶
- CUDA C++ Best Practices Guide Release 12.1笔记(一)
- CUDA 矩阵乘法终极优化指南
- 如何用CUDA写有CuBLAS 90%性能的GEMM Kernel
- 如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?
- 如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?
- 如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?
- 使用FasterTransformer实现LLM分布式推理
- 细粒度GPU知识点详细总结
- https://siboehm.com/articles/22/CUDA-MMM
- 【CUDA编程】OneFlow Softmax算子源码解读之BlockSoftmax
- 【CUDA编程】OneFlow Softmax 算子源码解读之WarpSoftmax
- 【CUDA编程】OneFlow Element-Wise 算子源码解读
- 【CUDA编程】Faster Transformer v1.0 源码详解
- 【CUDA编程】Faster Transformer v2.0 源码详解
- FasterTransformer Decoding 源码分析(七)-FFNLayer MoE(上篇)
- FasterTransformer Decoding 源码分析(八)-FFNLayer MoE(下篇)
- 从roofline模型看CPU矩阵乘法优化
- 性能优化的终极手段之 Profile-Guided Optimization (PGO)
- 有没有大模型推理加速引擎FasterTransformer入门级教程?
- 深入浅出GPU优化系列:gemv优化
- NVIDIA Hopper架构TensorCore分析(4)
- GPU host+device的编译流程
- Tensor Core 优化半精度矩阵乘揭秘
- 无痛CUDA实践:μ-CUDA 自动计算图生成
- CUDA(三):通用矩阵乘法:从入门到熟练
- 自己写的CUDA矩阵乘法能优化到多快?
- 高效CUDA Scan算法浅析
- 一次 CUDA Graph 调试经历
- CUDA中的radix sort算法
- NVIDIA Tensor Core微架构解析
- cutlass cute 101
- 在GPU避免分支的方法
- Pytorch-CUDA从入门到放弃(二)
- 腾讯机智团队分享--AllReduce算法的前世今生
- cute 之 Layout
- cute Layout 的代数和几何解释
- cute 之 GEMM流水线
- Using CUDA Warp-Level Primitives
- CUDA Pro Tip: Increase Performance with Vectorized Memory Access
- cute 之 简单GEMM实现
- cute 之 MMA抽象
- cute 之 Tensor
- cute Swizzle细谈
- 基于 CUTE 的 GEMM 优化【2】—— 高效 GEMM 实现,超越 Cublas 20%
- CUDA单精度矩阵乘法(sgemm)优化笔记
- HPC(高性能计算第一篇) :一文彻底搞懂并发编程与内存屏障(第一篇)
- GPU CUDA 编程的基本原理是什么? 怎么入门?
- 如何入门 OpenAI Triton 编程?
- CUDA(二):GPU的内存体系及其优化指南
- nvitop: 史上最强GPU性能实时监测工具
- 使用Triton在模型中构建自定义算子
- CUDA笔记 内存合并访问
- GPGPU架构,编译器和运行时
- GPGPU的memory 体系理解
- nvlink那些事……
- 对NVidia Hopper GH100 的一些理解
- 黑科技:用cutlass进行低成本、高性能卷积算子定制开发
- 乱谈Triton Ampere WMMA (施工中)
- 可能是讲的最清楚的WeightonlyGEMM博客
- GPU 底层机制分析:kernel launch 开销
- GPU内存(显存)的理解与基本使用
- 超越AITemplate,打平TensorRT,SD全系列模型加速框架stable-fast隆重登场
- [手把手带你入门CUTLASS系列] 0x00 cutlass基本认知---为什么要用cutlass
- [手把手带你入门CUTLASS系列] 0x02 cutlass 源码分析(一) --- block swizzle 和 tile iterator (附tvm等价code)
- [手把手带你入门CUTLASS系列] 0x03 cutlass 源码分析(二) --- bank conflict free 的shared memory layout (附tvm等价pass)
- [深入分析CUTLASS系列] 0x04 cutlass 源码分析(三) --- 多级流水线(software pipeline)
- [深入分析CUTLASS系列] 0x03 cutlass 源码分析(二) --- bank conflict free 的shared memory layout (附tvm等价pass)
- GPU 内存概念浅析
- NV_GPU tensor core 算力/带宽/编程模型分析
- Nsight Compute - Scheduler Statistics
- NVidia GPU指令集架构-前言
- 搞懂 CUDA Shared Memory 上的 bank conflicts 和向量化指令(LDS.128 / float4)的访存特点
- 窥探Trition的lower(二)
- 窥探Trition的lower(三)
- ops(2):SoftMax 算子的 CUDA 实现与优化
- cuda学习日记(6) nsight system / nsight compute
- ops(3):Cross Entropy 的 CUDA 实现
- cuda的ldmatrix指令的详细解释
- 揭秘 Tensor Core 底层:如何让AI计算速度飞跃
- NCCL(NVIDIA Collective Communication Library)的来龙去脉
- ldmatrix与swizzle(笔记)
- GPU上GEMM的边界问题以及优化
- NV Tensor Core and Memory Accelerator 理论分析
- CUTLASS CuTe GEMM细节分析(一)——ldmatrix的选择
- Triton到PTX(1):Elementwise
- 由矩阵乘法边界处理引起的CUDA wmma fragment与原始矩阵元素对应关系探究
- NVIDIA Hopper架构TensorCore分析(4)
- NVidia GPU指令集架构-Load和Cache
- NVidia GPU指令集架构-寄存器
- Async Copy 及 Memory Barrier 指令的功能与实现
- tensorcore中ldmatrix指令的优势是什么?
- 使用cutlass cute复现flash attention
- 1. Cuda矩阵乘法GeMM性能优化
- 一步步优化 GEMM by Tensorcore
- CUTLASS 3.x 异构编程随感
- Triton到PTX(1):Elementwise
- Triton到SASS(2):Reduction
- cuda的ldmatrix指令的详细解释
- 基于 CuTe 理解 swizzle, LDSM, MMA