
Incentivamos equipes de engenharia a fazer um investimento inicial durante o Sprint 0 de um projeto para estabelecer um pipeline automatizado e repetível que integre continuamente o código e libere executáveis do sistema para ambientes de nuvem específicos. Cada integração deve ser verificada por um processo de compilação automatizado que assegura que um conjunto de testes de validação seja aprovado e identifica quaisquer erros para toda a equipe de desenvolvedores.
Encorajamos as equipes a implementar os pipelines de CI/CD antes que qualquer código de serviço seja escrito para os clientes, o que geralmente acontece no Sprint 0(N). Dessa forma, a equipe de engenharia pode desenvolver e testar seu trabalho de forma isolada sem impactar outros desenvolvedores e promover um fluxo de trabalho DevOps consistente ao longo do envolvimento.
Esses princípios estão diretamente alinhados com as práticas do ciclo de vida de desenvolvimento de software ágil.
A automação de integração contínua é uma parte integral do ciclo de desenvolvimento de software destinada a reduzir erros de integração de compilação e maximizar a velocidade em uma equipe de desenvolvimento.
Um pipeline de automação de compilação robusto deve:
- Acelerar a velocidade da equipe
- Evitar problemas de integração
- Evitar caos de última hora durante as datas de lançamento
- Fornecer um ciclo de feedback rápido para o impacto em todo o sistema das mudanças locais
- Separar as etapas de compilação e implantação
- Medir e relatar métricas sobre falhas/sucessos de compilação
- Aumentar a visibilidade entre a equipe, facilitando a comunicação
- Reduzir erros humanos, que é provavelmente a parte mais importante da automação de compilações
Código / artefatos de manifesto necessários para compilar seu projeto devem ser mantidos dentro de seus repositórios Git de projeto
- As definições de pipeline de compilação específicas do provedor de CI devem residir dentro dos repositórios Git de projeto.
Uma compilação automatizada deve abranger os seguintes princípios:
- Uma etapa única dentro do seu pipeline de compilação que compila o projeto de código em um único artefato de compilação.
- Sua definição de compilação inclui etapas de validação para executar um conjunto de testes unitários automatizados para garantir que os componentes da aplicação atendam ao seu design e se comportem conforme o esperado.
- O código em toda a equipe de engenharia deve estar formatado de acordo com os padrões de codificação acordados. Esses padrões mantêm o código consistente e, o mais importante, fácil para a equipe e os clientes lerem e refatorarem. A consistência de estilo de código incentiva a propriedade coletiva das equipes de scrum do projeto e nossos parceiros.
- Existem várias ferramentas de validação de estilo de código de código aberto disponíveis para escolher (verificações de estilo de código, StyleCop). A seção Receitas de Revisão de Código do guia tem sugestões de linters e estilos preferidos para várias linguagens.
- Seu código e documentação devem evitar o uso de linguagem não inclusiva sempre que possível. Siga a seção Verificação Inclusiva para garantir que seu projeto promova um ambiente de trabalho inclusivo tanto para a equipe quanto para os clientes.
- Recomendamos incorporar ferramentas de análise de segurança na fase de compilação de seu pipeline, como scanner de credenciais de código, detecção de riscos de segurança, análise estática, etc. Para o Azure DevOps, você pode adicionar uma tarefa de análise de segurança ao seu pipeline instalando a Extensão de Análise de Código de Segurança da Microsoft. O GitHub Actions suporta uma extensão semelhante com a solução de análise de segurança RIPS.
- Os padrões de código são mantidos dentro de um único arquivo de configuração. Deve haver uma etapa em seu pipeline de compilação que assegure que o código no último commit esteja em conformidade com a definição de estilo conhecida.
- Um único comando deve ter a capacidade de compilar o sistema. Isso também é verdade para compilações em um servidor de CI ou em uma máquina local de desenvolvedores.
- É essencial ter uma compilação que possa ser executada por meio de scripts independentes e não seja dependente de uma IDE específica. Os alvos do pipeline de compilação podem ser acionados localmente em suas estações de trabalho por meio da IDE de sua escolha. O processo de compilação deve manter flexibilidade suficiente para ser executado em um servidor de CI também. Como exemplo, a dockerização do processo de compilação oferece esse nível de flexibilidade, já que o VSCode e o IntelliJ suportam extensões de plugin Docker.
- Introduza segurança em seu projeto nas fases iniciais. Siga a seção DevSecOps para introduzir práticas de segurança, automação, ferramentas e estruturas como parte do CI.
- Incentivamos manter uma experiência de desenvolvedor consistente para todos os membros da equipe. Deve haver um manifesto/processo automatizado central que simplifica a instalação e configuração de quaisquer dependências de software. Isso permite que os desenvolvedores repliquem o mesmo ambiente de compilação localmente que o ambiente em execução em um servidor de CI.
- Os scripts de automação de compilação frequentemente requerem pacotes de software específicos e versões pré-instaladas dentro do ambiente de tempo de execução do sistema operacional. Isso apresenta alguns desafios, já que os processos de compilação geralmente travam essas dependências em uma versão específica.
- Todos os desenvolvedores da equipe devem ser capazes de emular o ambiente de compilação de suas estações de trabalho locais, independentemente do sistema operacional.
- Para projetos que usam o VS Code, aproveitar Contêineres de Desenvolvedor pode realmente ajudar a padronizar a experiência de desenvolvimento local em toda a equipe.
- Ferramentas de empacotamento de software bem estabelecidas, como Docker, Maven, npm, etc., devem ser consideradas ao projetar sua cadeia de ferramentas de automação de compilação.
- O processo de configuração para configurar um ambiente de compilação local deve ser bem documentado e de fácil acompanhamento para os desenvolvedores.
Gerencie o máximo possível dos seguintes como código:
- Arquivos de Configuração
- Gerenciamento de Configuração (automação de variáveis de ambiente via terraform)
- Gerenciamento de Segredos (criação de segredos Azure via terraform)
- Provisionamento de Recursos de Nuvem
- Atribuições de Funções
- Cenários de Teste de Carga
- Alertas de Disponibilidade / Regras e Condições de Monitoramento
Desacoplar a infraestrutura do código da aplicação simplifica a transição das equipes de engenharia para aplicativos nativos em nuvem.
Provedores de recursos do Terraform, como Azure DevOps, estão tornando mais fácil para os desenvolvedores gerenciar variáveis de pipeline de compilação, conexões de serviço e definições de pipeline de CI/CD.
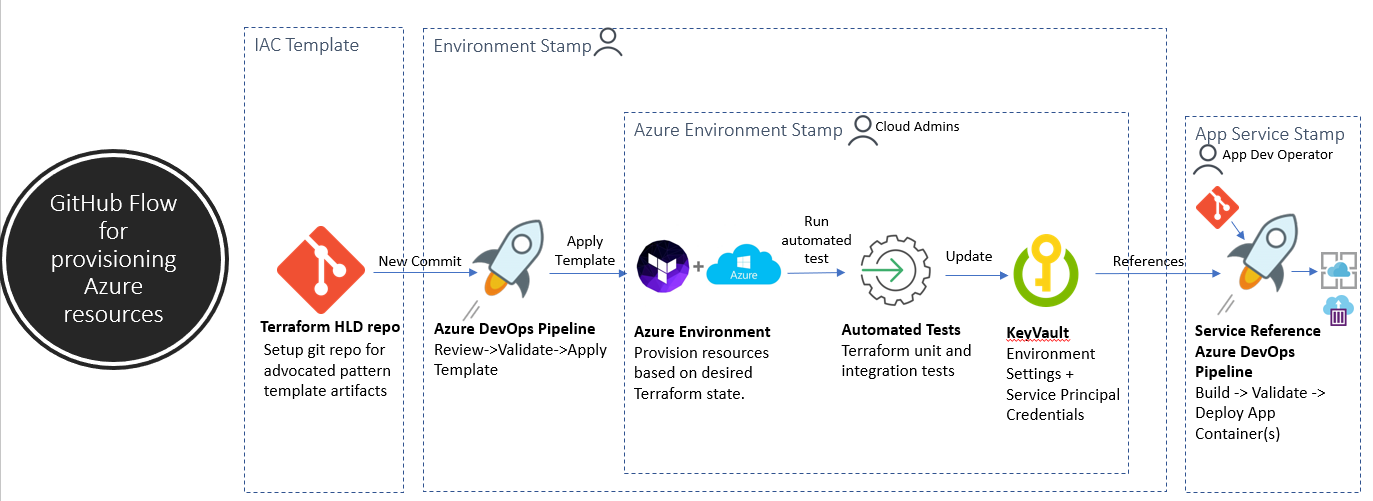
- Alterações repetíveis e auditáveis na infraestrutura facilitam o retorno a configurações conhecidas e a expansão rápida para novos estágios e regiões sem a necessidade de configurar manualmente os recursos da nuvem.
- Projetos de referência testados e com modelos de IAC, como Cobalt e Bedrock, permitem que equipes de engenharia implementem soluções seguras e escaláveis de forma muito mais rápida.
- Simplificar cenários de "migrar e executar" abstraindo as complexidades da computação nativa em nuvem das equipes de desenvolvimento de aplicativos.
- O processo de implantação de infraestrutura é baseado em um repositório que mantém o estado atual esperado do ambiente do sistema / ambiente Azure.
- As mudanças operacionais são feitas no sistema em execução, fazendo commits neste repositório.
- O Git também fornece um modelo simples para auditoria de implantações e retorno a um estado anterior.
- Defina a infraestrutura como código em modelos Terraform / ARM / Ansible.
- Os modelos são pilhas repetíveis de recursos de nuvem com foco em conjuntos de configurações alinhados com escalabilidade e necessidades de throughput da aplicação.
- Todos os recursos de nuvem são provisionados por meio de um conjunto de modelos de infraestrutura como código. Isso inclui segredos, configurações de serviço, atribuições de função e condições de monitoramento.
- O Portal Azure deve fornecer uma visualização somente leitura dos recursos do ambiente. Qualquer alteração aplicada ao ambiente deve ser feita apenas por meio da cadeia de ferramentas de IAC.
- Quando os arquivos de modelo IAC mudam por meio de um fluxo de trabalho baseado em git, um pipeline de compilação CI constrói, valida e concilia o estado atual do ambiente de infraestrutura de destino com o estado esperado. O plano de execução de infraestrutura candidato para esses ambientes fixos é revisado por um administrador de nuvem como uma verificação de porta antes da etapa de implantação do pipeline aplicar o plano de execução.
- Contas de desenvolvedores no portal Azure devem ter acesso somente leitura aos recursos de ambiente IAC no Azure.
- Model
os IAC são implantados por meio de um sistema CI/CD que possui automação de segredos integrada. Evite aplicar alterações a segredos e/ou certificados diretamente no Portal Azure.
- Testes de integração de ponta a ponta são executados como parte de seu processo de CI IAC para inspecionar e validar que um ambiente Azure está pronto para uso.
- A implantação e a topologia de modelo de recurso em nuvem devem ser documentadas e bem compreendidas dentro do README do repositório git IAC.
- As etapas de configuração do ambiente local e do fluxo de trabalho de CI devem ser documentadas.
As aplicações usam configurações para permitir diferentes comportamentos em tempo de execução e é bastante comum usar arquivos para armazenar essas configurações. Como desenvolvedores, podemos introduzir erros ao editar esses arquivos, o que causaria problemas para a inicialização e/ou execução correta da aplicação. Aplicando técnicas de validação na sintaxe e semântica de nossa configuração, podemos detectar erros antes que a aplicação seja implantada e executada, melhorando a experiência do desenvolvedor (usuário).
- JSON, com suporte para tipos de dados complexos e estruturas de dados complexas.
- YAML, um superconjunto de JSON com suporte para tipos de dados e estruturas complexas.
- TOML, um superconjunto de JSON e um formato de arquivo de configuração formalmente especificado.
- Facilita a Depuração e Economiza Tempo - Com uma etapa de validação de configuração em nosso pipeline, podemos evitar a execução da aplicação apenas para descobrir que ela falha. Isso economiza tempo ao evitar a implantação e execução, esperar e, em seguida, perceber que algo está errado na configuração. Além disso, economiza tempo ao passar pelos registros para descobrir o que deu errado e por quê.
- Melhor experiência do usuário/desenvolvedor - Um lembrete simples para o usuário de que algo na configuração não está no formato correto pode fazer toda a diferença entre a alegria de um processo de implantação bem-sucedido e a intensa frustração de ter que adivinhar o que deu errado. Por exemplo, quando se espera um valor booleano, ele pode ser uma string como "True" ou "False" ou um valor inteiro como "0" ou "1". Com a validação da configuração, garantimos que o significado esteja correto para nossa aplicação.
- Evitar corrupção de dados e violações de segurança - Como os dados vêm de uma fonte não confiável, como um usuário ou um serviço externo, é especialmente importante validar a entrada. Caso contrário, ele correrá o risco de executar erros, corromper dados ou, pior ainda, ser vulnerável a uma série de ataques de injeção.
JSON-Schema é o padrão de documentos JSON que descreve a estrutura e os requisitos dos seus dados JSON. Embora seja chamado de JSON-Schema, também é comum usar esse método para YAMLs, já que ele é um superconjunto do JSON. O esquema é muito simples: aponta quais campos podem existir, quais são obrigatórios ou opcionais, que formato de dados eles usam. Outras regras de validação podem ser adicionadas a essa premissa básica, juntamente com informações legíveis por humanos. Os metadados ficam nos esquemas, que são arquivos .json também. Além disso, o esquema tem a maior adoção entre todos os padrões de validação JSON, pois cobre uma grande parte dos cenários de validação. Ele usa documentos JSON fáceis de analisar para esquemas e é facilmente extensível.
A implementação da validação de esquema é dividida em duas partes: a geração dos esquemas e a validação de arquivos YAML/JSON com esses esquemas.
Existem duas opções para gerar um esquema:
-
A partir do código - podemos aproveitar os modelos e objetos existentes no código e gerar um esquema personalizado.
-
A partir de dados - podemos pegar amostras de yaml/json que refletem a configuração em geral e usar várias ferramentas online para gerar um esquema.
O esquema possui mais de 30 validadores para diferentes linguagens, incluindo mais de 10 para JavaScript, portanto, não é necessário codificá-lo você mesmo.
Validação de Integração
Uma maneira eficaz de identificar erros em sua compilação rapidamente é investir cedo em um conjunto confiável de testes automatizados que validem a funcionalidade básica do sistema:
Testes de Integração de Ponta a Ponta
- Inclua testes em seu pipeline para validar que o candidato à compilação está em conformidade com as asserções automatizadas de funcionalidade de negócios. Quaisquer erros ou código quebrado devem ser relatados nos resultados dos testes, incluindo o teste falhado e o rastreamento de pilha relevante. Todos os testes devem ser invocados por meio de um único comando.
- Mantenha a compilação rápida. Considere o tempo de execução dos testes automatizados ao decidir trazer dependências como bancos de dados, serviços externos e carga de dados fictícios para o seu conjunto de testes. Compilações lentas frequentemente se tornam um gargalo para equipes de desenvolvimento quando compilações paralelas em um servidor de Integração Contínua não são uma opção. Considere adicionar limites máximos de tempo para validações demoradas para falhar rapidamente e manter uma alta velocidade em toda a equipe.
Evite enviar compilações quebradas
- Verificações automatizadas de compilação, testes, execuções de análise de código etc. devem ser validadas localmente antes de enviar suas alterações para o repositório de controle de versão. A Desenvolvimento Orientado a Testes é uma prática que equipes de desenvolvimento devem considerar para ajudar a identificar erros e falhas o mais cedo possível no ciclo de desenvolvimento.
Relatando falhas de compilação
- Se a etapa de compilação falhar, o status da execução do pipeline de compilação deve ser relatado como falho, incluindo logs relevantes e rastreamentos de pilha.
Dependências de Dados de Automação de Teste
- Qualquer conjunto de dados fictícios usado para testes unitários e de integração de ponta a ponta deve ser incluído no repositório principal. Minimize quaisquer dependências de dados externos no processo de compilação.
Verificações de Cobertura de Código
- Recomendamos integrar ferramentas de cobertura de código em sua etapa de compilação. A maioria das ferramentas de cobertura de código falha nas compilações quando a cobertura de teste fica abaixo de um limite mínimo (80% de cobertura). O relatório de cobertura deve ser publicado em seu sistema de Integração Contínua para acompanhar uma série temporal de variações.
Fluxo de Trabalho Orientado pelo Git
Compilação na Confirmação
- Cada confirmação no repositório base deve acionar o pipeline de Integração Contínua para criar um novo candidato à compilação.
- Os artefatos de compilação são criados, empacotados, validados e implantados continuamente em um ambiente não produtivo por confirmação. Cada confirmação no repositório resulta em uma execução de Integração Contínua que verifica as fontes na máquina de integração, inicia uma compilação e notifica o autor da confirmação sobre o resultado da compilação.
Evite comentar testes falhados
- Evite comentar testes na ramificação principal. Ao comentar testes, obtemos uma indicação incorreta do estado da compilação.
Aplicação da Política de Ramificação
- Políticas de ramificação protegidas devem ser configuradas na ramificação principal para garantir que as etapas de Integração Contínua tenham sido concluídas antes de iniciar uma revisão de código. Os aprovadores de revisão de código só iniciarão a revisão de uma solicitação de pull quando a execução do pipeline de Integração Contínua for bem-sucedida para a confirmação mais recentemente enviada para o Git.
- Compilações quebradas devem bloquear revisões de solicitações de pull.
- Evite confirmações diretas na ramificação principal.
Estratégia de Ramificação
- Ramificações de lançamento devem acionar automaticamente a implantação de um artefato de compilação em seu ambiente de nuvem de destino. Você pode encontrar orientações adicionais no site de documentação do Azure DevOps na seção Gerenciar implantações.
Entregar Rapidamente e Diariamente
"Ao confirmar regularmente, cada colaborador pode reduzir o número de alterações conflitantes. Fazer confirmações semanais de trabalho corre o risco de entrar em conflito com outras funcionalidades e pode ser muito difícil de resolver. Conflitos iniciais e pequenos em uma área do sistema fazem com que os membros da equipe se comuniquem sobre a alteração que estão fazendo."
No espírito da transparência e da comunicação frequente em uma equipe de desenvolvimento, incentivamos os desenvolvedores a confirmar o código diariamente. Essa abordagem fornece visibilidade ao progresso das funcionalidades e acelera a programação em pares em toda a equipe. Aqui estão alguns princípios a serem considerados:
Todos confirmam no repositório git todos os dias
- No final do dia, o código confirmado deve conter testes unitários no mínimo.
- Execute a compilação localmente antes de confirmar para evitar a saturação do pipeline de Integração Contínua. Você deve verificar o que causou o erro e tentar resolvê-lo o mais rápido possível, em vez de confirmar o código. Incentivamos os desenvolvedores a seguir princípios de Desenvolvimento Lean.
- Isolar o trabalho em pequenos pedaços que se relacionam diretamente com o valor comercial e refatorar incrementalmente.
Ambientes Isolados
Um dos principais objetivos da validação de compilação é isolar e identificar falhas em ambientes de preparação e minimizar qualquer interrupção no tráfego de produção ao vivo. Nossos testes automatizados de ponta a ponta devem ser executados em um ambiente que reproduza nosso ambiente de produção (o máximo possível). Isso inclui versões de software consistent
es, SO, simulações de volume de dados de teste, paridade de tráfego de rede com produção, etc.
Teste em um clone da produção
- O ambiente de produção deve ser duplicado em um ambiente de preparação (QA e/ou Pré-Produção) no mínimo.
Atualizações de solicitação de pull acionam lançamentos em estágios
- Novas confirmações relacionadas a uma solicitação de pull devem acionar uma compilação/liberação em um ambiente de integração. O ambiente de produção deve ser totalmente isolado desse processo.
Promover alterações de infraestrutura em ambientes fixos
- Alterações de infraestrutura como código devem ser testadas em um ambiente de integração e promovidas para todos os ambientes de preparação, depois migradas para produção sem tempo de inatividade para os usuários do sistema.
Testando em produção
- Existem várias abordagens para realizar testes automatizados para implantações em produção com segurança. Algumas dessas abordagens podem incluir:
- Sinalização de recursos
- Teste A/B
- Deslocamento de tráfego
Acesso do Desenvolvedor aos Últimos Artefatos de Lançamento
Nosso fluxo de trabalho de DevOps deve permitir que os desenvolvedores obtenham, instalem e executem o executável do sistema mais recente. Os executáveis de lançamento devem ser gerados automaticamente como parte de nossos pipelines de CI/CD.
Os desenvolvedores podem acessar o executável mais recente
- O executável do sistema mais recente está disponível para todos os desenvolvedores da equipe. Deve haver um local conhecido onde os desenvolvedores possam consultar o artefato de lançamento.
O artefato de lançamento é publicado para cada solicitação de pull ou mesclagem na ramificação principal
Observabilidade da Integração
As mudanças de estado aplicadas à compilação principal devem estar disponíveis e ser comunicadas em toda a equipe. Centralizar logs e status de falhas de pipeline de compilação e lançamento é essencial para desenvolvedores que investigam compilações quebradas.
Recomendamos integrar Teams ou Slack com as execuções de pipeline de CI/CD, o que ajuda a manter a equipe constantemente informada sobre falhas e status de candidatos à compilação.
Painel de nível superior de Integração Contínua
- Os provedores modernos de CI têm a capacidade de consolidar e relatar status de compilação em um painel específico.
- Seu painel de CI deve ser capaz de correlacionar uma falha de compilação com um commit do Git.
Emblema de status de compilação no README do projeto
- Deve haver um emblema de status de compilação incluído no README raiz do projeto.
Notificações de compilação
- Seu processo de CI deve ser configurado para enviar notificações para plataformas de mensagens como Teams/Slack assim que a compilação for concluída. Recomendamos criar um canal separado para ajudar a consolidar e isolar essas notificações.
Recursos
- Melhores Práticas de Integração Contínua de Martin Fowler
- Guia Rápido de Início do Bedrock
- Guia Rápido do Cobalt
- Provedor Azure DevOps do Terraform
- Pipelines de Vários Estágios do Azure DevOps
- Conceitos Chave do Azure Pipeline
- Ambientes do Azure Pipeline
- Artefatos no Azure Pipelines
- Permissões e Funções de Segurança do Azure Pipeline
- Aprovações e Verificações de Ambiente do Azure
- Guia de Início Rápido do Terraform com Azure
- Configuração Remota do Estado do Terraform no Azure
- Terratest - Framework de Infraestrutura de Testes Unitários e de Integração