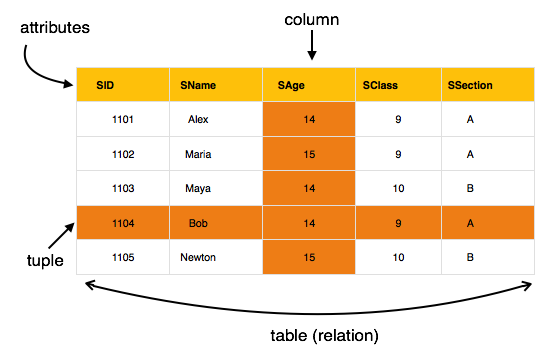
Relational Model represents the database as a collection of relations. A relation is nothing but a table of values. Every row in the table represents a collection of related data values. These rows in the table denote a real-world entity or relationship. This model is based on first-order predicate logic and defines a table as an n-ary relation.
The schema of a relation specifies:
- the name of the relation,
- the name and type of each field/attribute/column.
Data is stored in tables called relations. Each row in a relation contains a unique value. Each column in a relation contains values from a same domain.
The relation schema: Movie(mid: string, title: string, director: string, year: integer)
The instance of the Movie relation(the whole table):

A relational database is a collection of relations with distinct names. A relational database schema is collection of schemas for the relations in the database A database instance is a collection of relation instances, one / relational schema in the database schema. It must be legal, i.e., it must satisfy all the specified integrity constraints
- Attribute: Each column in a Table. Attributes are the properties which define a relation. e.g., Student_Rollno, NAME,etc.
- {A1, A2, ..., An} - a set of attributes
- Di = Dom(Ai) U {?} .
- Dom(Ai) is the domain of possible values for attribute Ai.
- the undefined (null) value is denoted here by {?}. It means unknown / not applicable. It can be used to check if a value has been assigned to an attribute (the attribute could have the undefined value). This value doesn't have a certain data type; attribute values of different types can be compared against this value (numeric, string, etc.)
- Tables – In the Relational model, the relations are saved in the table format. It is stored along with its entities. A table has two properties: rows and columns. Rows represent records and columns represent attributes.
- Tuple – It is nothing but a single row of a table, which contains a single record.
- Relation Schema: A relation schema represents the name of the relation with its attributes.
- Degree: The total number of attributes which in the relation is called the degree of the relation.
- Cardinality: Total number of rows present in the Table.
- Column: The column represents the set of values for a specific attribute.
- Relation instance – Relation instance is a finite set of tuples in the RDBMS system. Relation instances never have duplicate tuples.
- Relation key – Every row has one, two or multiple attributes, which is called relation key.
- Attribute domain – Every attribute has some pre-defined value and scope which is known as attribute domain

Information Integrity is the trustworthiness and dependability of information. More specifically, it is the accuracy, consistency and reliability of the information content, processes and systems. If certain information cannot be trusted and has a low level of integrity, than a business has a low chance of success. You need information integrity to have a successful business.
Relational Integrity constraints are conditions specified on the database schema, restricting the data that can be stored in the database. These constraints are checked when the data is changed; operations that violate the constraints are not allowed (e.g., introducing a student with a CNP identical to a different student's CNP, entering data of the wrong type in a column, etc.) These Relational constraints in DBMS are derived from the rules in the mini-world that the database represents. They are sets of rules that can help maintain the quality of information that is put up.
Integrity constraints are mostly used when trying to promote accuracy and consistency of data that is found in a relational database. This is very important to companies because information can be considered as an asset to certain organizations and it must be protected.
There are many types of Integrity Constraints in DBMS. Constraints on the Relational database management system is mostly divided into three main categories are:
- Domain Constraints
- Key Constraints
- Referential Integrity Constraints
Domain constraints are conditions that must be satisfied by every relation instance: a column's values belong to its associated domain.
A domain integrity constraint is a set of rules that restricts the kind of attributes or values a column or relation can hold in the database table.
For example, we can specify if a particular column can hold null values or not, if the values have to be unique or not, the data type or size of values that can be entered in the column, the default values for the column, etc.
Example:
Create DOMAIN CustomerName
CHECK (value not NULL)
The example shown demonstrates creating a domain constraint such that CustomerName is not NULL
An attribute that can uniquely identify a tuple in a relation is called the key of the table. The value of the attribute for different tuples in the relation has to be unique.
From course: Key constraint is a constraint stating that a subset of the attributes in a relation is a unique identifier for every tuple in the relation; this subset of attributes is minimal. Two different records are not allowed to have identical values in all the fields that constitute a key, hence specifying a key is a restriction for the database.
Example:
In the given table, CustomerID is a key attribute of Customer Table. It is most likely to have a single key for one customer: CustomerID=1 is only for the CustomerName=”Google”. We are not allowed to add another customer with the same ID.
| CustomerID | CustomerName | Status |
|---|---|---|
| 1 | Active | |
| 2 | Amazon | Active |
| 3 | Apple | Inactive |
Referential Integrity Constraint ensures that there always exists a valid relationship between two tables. This makes sure that if a foreign key exists in a table relationship, then it should always reference a corresponding value in the second table or it should be null.
A FOREIGN KEY is a field (or collection of fields) in one table, that refers to the PRIMARY KEY in another table. Example of foreign key:
| PersonID | LastName | FirstName | Age |
|---|---|---|---|
| 1 | Hansen | Ola | 30 |
| 2 | Svendson | Tove | 23 |
| 3 | Pettersen | Kari | 20 |
| OrderID | OrderNumber | PersonID |
|---|---|---|
| 1 | 77895 | 3 |
| 2 | 44678 | 3 |
| 3 | 22456 | 2 |
| 4 | 24562 | 1 |
- The table with the foreign key is called the child table, and the table with the primary key is called the referenced or parent table.
- Notice that the "PersonID" column in the "Orders" table points to the "PersonID" column in the "Persons" table.
- The "PersonID" column in the "Persons" table is the PRIMARY KEY in the "Persons" table. (=>parent table)
- The "PersonID" column in the "Orders" table is a FOREIGN KEY in the "Orders" table. (=> child table)
The FOREIGN KEY constraint prevents invalid data from being inserted into the foreign key column, because it has to be one of the values contained in the parent table.
- A foreign key can be used to store 1:n associations among entities: a person can correspond to several orders, and an order can be associated with at most one person
- Foreign keys can be used to store m:n associations among entities: a student can enroll in several courses; multiple students can take a course; storing such associations requires an additional table

- Any value that appears in the student field of the Contracts relation must appear in the cnp field of the Students relation, but there may be students who haven't enrolled in any courses yet (i.e., cnp values in Students that don't appear in the student column from Contracts)
- The foreign key in the Contracts relation must have the same number of columns as the referenced key from Students (preferably, the primary key); the data types of the corresponding columns must be compatible, however, the column names can be different
If you want to delete a Student that appears in Contracts, the operation will be rejected(because it violates the specified integrity constraints). However, in some cases, instead of rejecting the operation, the DBMS will make additional changes to the data, so in the end all integrity constraints are satisfied. For example, you can cascade the operation: the Students row and the referencing rows in Contracts are deleted. See the CREATE TABLE statement to see other options.
Read more about Integrity Constraints in DBMS
- Data needs to be represented as a collection of relations
- Each relation should be depicted clearly in the table
- Rows should contain data about instances of an entity
- Columns must contain data about attributes of the entity
- Cells of the table should hold a single value
- Each column should be given a unique name
- No two rows can be identical
- The values of an attribute should be from the same domain
- Simplicity: A Relational data model in DBMS is simpler than the hierarchical and network model.
- Structural Independence: The relational database is only concerned with data and not with a structure. This can improve the performance of the model.
- Easy to use: The Relational model in DBMS is easy as tables consisting of rows and columns are quite natural and simple to understand
- Query capability: It makes possible for a high-level query language like SQL to avoid complex database navigation.
- Data independence: The Structure of Relational database can be changed without having to change any application.
- Scalable: Regarding a number of records, or rows, and the number of fields, a database should be enlarged to enhance its usability.
- Few relational databases have limits on field lengths which can’t be exceeded.
- Relational databases can sometimes become complex as the amount of data grows, and the relations between pieces of data become more complicated.
- Complex relational database systems may lead to isolated databases where the information cannot be shared from one system to another.
Information taken from here